文章目录
- 基本概念
- 什么是全文检索技术
- 全文检索的应用场景
- 搜索引擎
- 站内搜索(关注)
- 文件系统的搜索
- Lucene & solr & es
- 介绍
- 区别
- Solr与Lucene对比
- ES与Lucene的区别
- ES与Solr对比
- Lucene实现全文检索的流程
- 入门程序
- 需求
- 环境准备
- 数据库脚本初始化
- Lucene下载
- 工程搭建
- 索引流程
- 为什么采集数据
- 采集数据的方式
- 网页爬虫采集
- 数据库采集
- 索引文件的逻辑结构
- 采集数据
- 创建索引
- 创建Document
- 分词
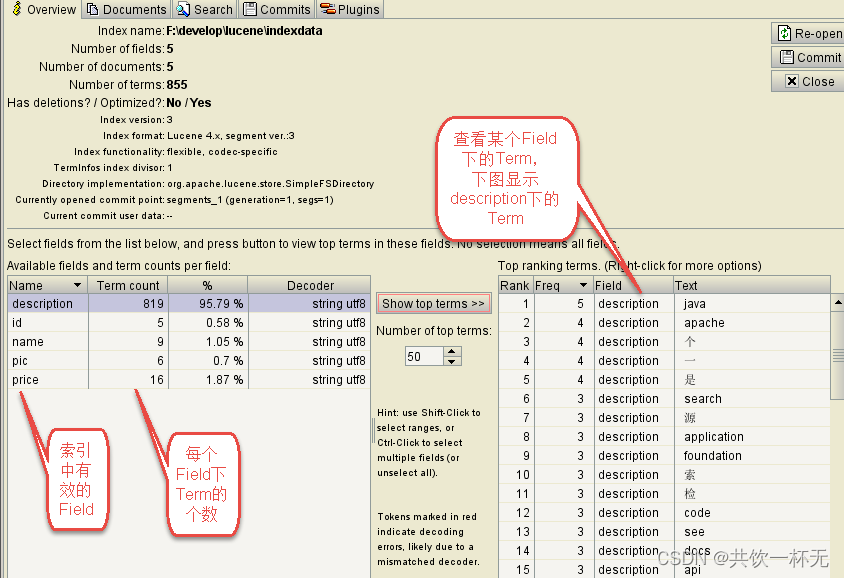
- 使用luke工具查看索引
- 搜索流程
- 输入查询语句
- 搜索索引
基本概念
什么是全文检索技术
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如 互联网数据、邮件,word文档等。非结构化数据又有一种叫法叫全文数据
按照数据的分类,搜索也分为两种:
- 对结构化数据的搜索: 如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 对非结构化数据的搜索: 如用Google和百度可以搜索大量内容数据。
对非结构化数据也即全文数据的搜索主要有两种方法:顺序扫描法和反向索引法。
- **顺序扫描法:**所谓顺序扫描法,就是顺序扫描每个文档内容,看看是否有要搜索的关键字,实现查找文档的 功能,也就是根据文档找词。
- **反向索引法:**所谓反向索引,就是提前将搜索的关键字建成索引,然后再根据索引查找文档,也就是根据词 找文档。
全文检索首先对要搜索的文档进行分词,然后形成索引,通过查询索引来查询文档。这种先建立 索引 ,再对索引进行 搜索文档的过程就叫 全文检索(Full-text Search) 。
全文检索的应用场景
搜索引擎
如用Google和百度可以搜索大量内容数据。
站内搜索(关注)
京东、淘宝等购物网站的站内搜索。

文件系统的搜索
Lucene & solr & es
介绍
- Lucene
Lucene是apache下的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene是一个工具包,它不能独立运行,不能单独对外提供服务。搜索引擎可以独立运行对外提供搜索服务。官网地址:https://lucene.apache.org/
- Solr
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。官网地址:http://lucene.apache.org/solr/
- Elasticsearch
Elasticsearch跟Solr一样,也是一个基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java开发并且是当前最流行的开源的企业级搜索引擎,支持多种语言。官网地址:https://www.elastic.co/products/elasticsearch
区别
Solr与Lucene对比
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
ES与Lucene的区别
Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它 是如何工作的。lucene有很多缺陷,es并不存在。
- 只能在Java项目中使用,并且要以jar包的方式直接集成项目中
- 使用非常复杂-创建索引和搜索索引代码繁杂
- 不支持集群环境-索引数据不同步(不支持大型项目)
- 索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬 盘.共用空间少.
ES与Solr对比
- 单纯对已有数据进行搜索时,solr更快;但是实时简历索引时,solr会产生io阻塞,查询性能较差。而es不会
- solr利用zk进行分布式管理,而es自身带有分布式协调管理功能。
- solr支持更多的数据格式,如json、xml、csv等,而es仅支持json文件格式
- solr在传统的搜索应用中表现好于es,但在处理实时搜索应用时效率明显低于es。
Lucene实现全文检索的流程
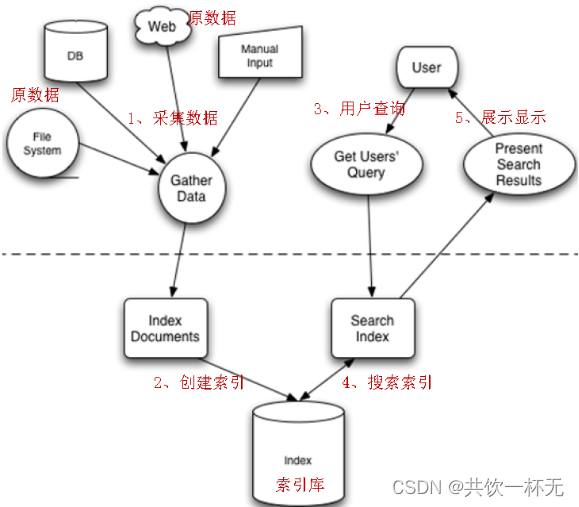
全文检索的流程:索引流程、搜索流程
索引流程:采集数据—》文档处理à存储到索引库中
搜索流程:输入查询条件—》通过lucene的查询器查询索引—》从索引库中取出结—》视图渲染
PS:Lucene本身不能进行视图渲染。
入门程序
需求
使用lucene完成对数据库中图书信息的索引和搜索功能。
环境准备
Jdk:1.7及以上
Lucene:9.4.2
数据库:mysql 5.7
数据库脚本初始化
create table `book` (`id` int (11),`name` varchar (192),`price` float ,`pic` varchar (96),`description` text
);
insert into `book` (`id`, `name`, `price`, `pic`, `description`) values('1','java 编程思想','71.5','23488292934.jpg','作者简介 Bruce Eckel,是MindView公司的总裁,该公司向客户提供软件咨询和培训。他是C++标准委员会拥有表决权的成员之一,拥有应用物理学学士和计算机工程硕士学位。除本书外,他还是《C++编程思想》的作者,并与人合著了《C++编程思想第2卷》。\r\n\r\n《计算机科学丛书:Java编程思想(第4版)》赢得了全球程序员的广泛赞誉,即使是最晦涩的概念,在BruceEckel的文字亲和力和小而直接的编程示例面前也会化解于无形。从Java的基础语法到最高级特性(深入的面向对象概念、多线程、自动项目构建、单元测试和调试等),本书都能逐步指导你轻松掌握。\r\n 从《计算机科学丛书:Java编程思想(第4版)》获得的各项大奖以及来自世界各地的读者评论中,不难看出这是一本经典之作。本书的作者拥有多年教学经验,对C、C++以及Java语言都有独到、深入的见解,以通俗易懂及小而直接的示例解释了一个个晦涩抽象的概念。本书共22章,包括操作符、控制执行流程、访问权限控制、复用类、多态、接口、通过异常处理错误、字符串、泛型、数组、容器深入研究、JavaI/O系统、枚举类型、并发以及图形化用户界面等内容。这些丰富的内容,包含了Java语言基础语法以及高级特性,适合各个层次的Java程序员阅读,同时也是高等院校讲授面向对象程序设计语言以及Java语言的绝佳教材和参考书。\r\n 《计算机科学丛书:Java编程思想(第4版)》特点:\r\n 适合初学者与专业人员的经典的面向对象叙述方式,为更新的JavaSE5/6增加了新的示例和章节。\r\n 测验框架显示程序输出。\r\n 设计模式贯穿于众多示例中:适配器、桥接器、职责链、命令、装饰器、外观、工厂方法、享元、点名、数据传输对象、空对象、代理、单例、状态、策略、模板方法以及访问者。\r\n 为数据传输引入了XML,为用户界面引入了SWT和Flash。\r\n 重新撰写了有关并发的章节,有助于读者掌握线程的相关知识。\r\n 专门为第4版以及JavaSE5/6重写了700多个编译文件中的500多个程序。\r\n 支持网站包含了所有源代码、带注解的解决方案指南、网络日志以及多媒体学习资料。\r\n 覆盖了所有基础知识,同时论述了高级特性。\r\n 详细地阐述了面向对象原理。\r\n 在线可获得Java讲座CD,其中包含BruceEckel的全部多媒体讲座。\r\n 在网站上可以观看现场讲座、咨询和评论。\r\n 专门为第4版以及JavaSE5/6重写了700多个编译文件中的500多个程序。\r\n 支持网站包含了所有源代码、带注解的解决方案指南、网络日志以及多媒体学习资料。\r\n 覆盖了所有基础知识,同时论述了高级特性。\r\n 详细地阐述了面向对象原理。\r\n\r\n\r\n');
insert into `book` (`id`, `name`, `price`, `pic`, `description`) values('2','apache lucene','66.0','77373773737.jpg','lucene是apache的开源项目,是一个全文检索的工具包。\r\n# Apache Lucene README file\r\n\r\n## Introduction\r\n\r\nLucene is a Java full-text search engine. Lucene is not a complete\r\napplication, but rather a code library and API that can easily be used\r\nto add search capabilities to applications.\r\n\r\n * The Lucene web site is at: http://lucene.apache.org/\r\n * Please join the Lucene-User mailing list by sending a message to:\r\n java-user-subscribe@lucene.apache.org\r\n\r\n## Files in a binary distribution\r\n\r\nFiles are organized by module, for example in core/:\r\n\r\n* `core/lucene-core-XX.jar`:\r\n The compiled core Lucene library.\r\n\r\nTo review the documentation, read the main documentation page, located at:\r\n`docs/index.html`\r\n\r\nTo build Lucene or its documentation for a source distribution, see BUILD.txt');
insert into `book` (`id`, `name`, `price`, `pic`, `description`) values('3','mybatis','55.0','88272828282.jpg','MyBatis介绍\r\n\r\nMyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis。 \r\nMyBatis是一个优秀的持久层框架,它对jdbc的操作数据库的过程进行封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动、创建connection、创建statement、手动设置参数、结果集检索等jdbc繁杂的过程代码。\r\nMybatis通过xml或注解的方式将要执行的statement配置起来,并通过java对象和statement中的sql进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射成java对象并返回。\r\n');
insert into `book` (`id`, `name`, `price`, `pic`, `description`) values('4','spring','56.0','83938383222.jpg','## Spring Framework\r\nspringmvc.txt\r\nThe Spring Framework provides a comprehensive programming and configuration model for modern\r\nJava-based enterprise applications - on any kind of deployment platform. A key element of Spring is\r\ninfrastructural support at the application level: Spring focuses on the \"plumbing\" of enterprise\r\napplications so that teams can focus on application-level business logic, without unnecessary ties\r\nto specific deployment environments.\r\n\r\nThe framework also serves as the foundation for\r\n[Spring Integration](https://github.com/SpringSource/spring-integration),\r\n[Spring Batch](https://github.com/SpringSource/spring-batch) and the rest of the Spring\r\n[family of projects](http://springsource.org/projects). Browse the repositories under the\r\n[SpringSource organization](https://github.com/SpringSource) on GitHub for a full list.\r\n\r\n[.NET](https://github.com/SpringSource/spring-net) and\r\n[Python](https://github.com/SpringSource/spring-python) variants are available as well.\r\n\r\n## Downloading artifacts\r\nInstructions on\r\n[downloading Spring artifacts](https://github.com/SpringSource/spring-framework/wiki/Downloading-Spring-artifacts)\r\nvia Maven and other build systems are available via the project wiki.\r\n\r\n## Documentation\r\nSee the current [Javadoc](http://static.springsource.org/spring-framework/docs/current/api)\r\nand [Reference docs](http://static.springsource.org/spring-framework/docs/current/reference).\r\n\r\n## Getting support\r\nCheck out the [Spring forums](http://forum.springsource.org) and the\r\n[Spring tag](http://stackoverflow.com/questions/tagged/spring) on StackOverflow.\r\n[Commercial support](http://springsource.com/support/springsupport) is available too.\r\n\r\n## Issue Tracking\r\nSpring\'s JIRA issue tracker can be found [here](http://jira.springsource.org/browse/SPR). Think\r\nyou\'ve found a bug? Please consider submitting a reproduction project via the\r\n[spring-framework-issues](https://github.com/springsource/spring-framework-issues) repository. The\r\n[readme](https://github.com/springsource/spring-framework-issues#readme) provides simple\r\nstep-by-step instructions.\r\n\r\n## Building from source\r\nInstructions on\r\n[building Spring from source](https://github.com/SpringSource/spring-framework/wiki/Building-from-source)\r\nare available via the project wiki.\r\n\r\n## Contributing\r\n[Pull requests](http://help.github.com/send-pull-requests) are welcome; you\'ll be asked to sign our\r\ncontributor license agreement ([CLA](https://support.springsource.com/spring_committer_signup)).\r\nTrivial changes like typo fixes are especially appreciated (just\r\n[fork and edit!](https://github.com/blog/844-forking-with-the-edit-button)). For larger changes,\r\nplease search through JIRA for similiar issues, creating a new one if necessary, and discuss your\r\nideas with the Spring team.\r\n\r\n## Staying in touch\r\nFollow [@springframework](http://twitter.com/springframework) and its\r\n[team members](http://twitter.com/springframework/team/members) on Twitter. In-depth articles can be\r\nfound at the SpringSource [team blog](http://blog.springsource.org), and releases are announced via\r\nour [news feed](http://www.springsource.org/news-events).\r\n\r\n## License\r\nThe Spring Framework is released under version 2.0 of the\r\n[Apache License](http://www.apache.org/licenses/LICENSE-2.0).\r\n');
insert into `book` (`id`, `name`, `price`, `pic`, `description`) values('5','solr','78.0','99999229292.jpg','solr是一个全文检索服务\r\n# Licensed to the Apache Software Foundation (ASF) under one or more\r\n# contributor license agreements. See the NOTICE file distributed with\r\n# this work for additional information regarding copyright ownership.\r\n# The ASF licenses this file to You under the Apache License, Version 2.0\r\n# (the \"License\"); you may not use this file except in compliance with\r\n# the License. You may obtain a copy of the License at\r\n#\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n#\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\n\r\n\r\nWelcome to the Apache Solr project!\r\n-----------------------------------\r\n\r\nSolr is the popular, blazing fast open source enterprise search platform\r\nfrom the Apache Lucene project.\r\n\r\nFor a complete description of the Solr project, team composition, source\r\ncode repositories, and other details, please see the Solr web site at\r\nhttp://lucene.apache.org/solr\r\n\r\n\r\nGetting Started\r\n---------------\r\n\r\nSee the \"example\" directory for an example Solr setup. A tutorial\r\nusing the example setup can be found at\r\n http://lucene.apache.org/solr/tutorial.html\r\nor linked from \"docs/index.html\" in a binary distribution.\r\nAlso, there are Solr clients for many programming languages, see \r\n http://wiki.apache.org/solr/IntegratingSolr\r\n\r\n\r\nFiles included in an Apache Solr binary distribution\r\n----------------------------------------------------\r\n\r\nexample/\r\n A self-contained example Solr instance, complete with a sample\r\n configuration, documents to index, and the Jetty Servlet container.\r\n Please see example/README.txt for information about running this\r\n example.\r\n\r\ndist/solr-XX.war\r\n The Apache Solr Application. Deploy this WAR file to any servlet\r\n container to run Apache Solr.\r\n\r\ndist/solr-<component>-XX.jar\r\n The Apache Solr libraries. To compile Apache Solr Plugins,\r\n one or more of these will be required. The core library is\r\n required at a minimum. (see http://wiki.apache.org/solr/SolrPlugins\r\n for more information).\r\n\r\ndocs/index.html\r\n The Apache Solr Javadoc API documentation and Tutorial\r\n\r\n\r\nInstructions for Building Apache Solr from Source\r\n-------------------------------------------------\r\n\r\n1. Download the Java SE 7 JDK (Java Development Kit) or later from http://java.sun.com/\r\n You will need the JDK installed, and the $JAVA_HOME/bin (Windows: %JAVA_HOME%\\bin) \r\n folder included on your command path. To test this, issue a \"java -version\" command \r\n from your shell (command prompt) and verify that the Java version is 1.7 or later.\r\n\r\n2. Download the Apache Ant binary distribution (1.8.2+) from \r\n http://ant.apache.org/ You will need Ant installed and the $ANT_HOME/bin (Windows: \r\n %ANT_HOME%\\bin) folder included on your command path. To test this, issue a \r\n \"ant -version\" command from your shell (command prompt) and verify that Ant is \r\n available. \r\n\r\n You will also need to install Apache Ivy binary distribution (2.2.0) from \r\n http://ant.apache.org/ivy/ and place ivy-2.2.0.jar file in ~/.ant/lib -- if you skip \r\n this step, the Solr build system will offer to do it for you.\r\n\r\n3. Download the Apache Solr distribution, linked from the above web site. \r\n Unzip the distribution to a folder of your choice, e.g. C:\\solr or ~/solr\r\n Alternately, you can obtain a copy of the latest Apache Solr source code\r\n directly from the Subversion repository:\r\n\r\n http://lucene.apache.org/solr/versioncontrol.html\r\n\r\n4. Navigate to the \"solr\" folder and issue an \"ant\" command to see the available options\r\n for building, testing, and packaging Solr.\r\n \r\n NOTE: \r\n To see Solr in action, you may want to use the \"ant example\" command to build\r\n and package Solr into the example/webapps directory. See also example/README.txt.\r\n\r\n\r\nExport control\r\n-------------------------------------------------\r\nThis distribution includes cryptographic software. The country in\r\nwhich you currently reside may have restrictions on the import,\r\npossession, use, and/or re-export to another country, of\r\nencryption software. BEFORE using any encryption software, please\r\ncheck your country\'s laws, regulations and policies concerning the\r\nimport, possession, or use, and re-export of encryption software, to\r\nsee if this is permitted. See <http://www.wassenaar.org/> for more\r\ninformation.\r\n\r\nThe U.S. Government Department of Commerce, Bureau of Industry and\r\nSecurity (BIS), has classified this software as Export Commodity\r\nControl Number (ECCN) 5D002.C.1, which includes information security\r\nsoftware using or performing cryptographic functions with asymmetric\r\nalgorithms. The form and manner of this Apache Software Foundation\r\ndistribution makes it eligible for export under the License Exception\r\nENC Technology Software Unrestricted (TSU) exception (see the BIS\r\nExport Administration Regulations, Section 740.13) for both object\r\ncode and source code.\r\n\r\nThe following provides more details on the included cryptographic\r\nsoftware:\r\n Apache Solr uses the Apache Tika which uses the Bouncy Castle generic encryption libraries for\r\n extracting text content and metadata from encrypted PDF files.\r\n See http://www.bouncycastle.org/ for more details on Bouncy Castle.\r\n');
Lucene下载
官方网站:http://lucene.apache.org/
目前最新版本:9.5.0
下载地址:http://archive.apache.org/dist/lucene/java/
工程搭建
新建maven工程,添加如下jar
<!--lucene核心包--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>8.3.1</version></dependency><!--查询解析器包--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>8.3.1</version></dependency><!--分析器通用包--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>8.3.1</version></dependency><!--mysql驱动包--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.32</version></dependency><!--单元测试--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency>
索引流程
为什么采集数据
全文检索搜索的内容的格式是多种多样的,比如:视频、mp3、图片、文档等等。对于这种格式不同的数据,需要先将他们采集到本地,然后统一封装到lucene的文档对象中,也就是说需要将存储的内容进行统一才能对它进行查询。
采集数据的方式
- 对于互联网中的数据,使用爬虫工具(http工具)将网页爬取到本地
- 对于数据库中的数据,使用jdbc程序进行数据采集
- 对于文件系统的数据,使用io流采集
网页爬虫采集
因为目前搜索引擎主要搜索数据的来源是互联网,搜索引擎使用一种爬虫程序抓取网页(通过http抓取html网页信息),以下是一些爬虫项目:
- Solr(https://solr.apache.org/),solr是apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
- jsoup(http://jsoup.org/ ),jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
- heritrix(http://sourceforge.net/projects/archive-crawler/files/),Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
数据库采集
针对电商站内搜索功能,全文检索的数据源在数据库中,需要通过jdbc访问数据库中book表的内容。
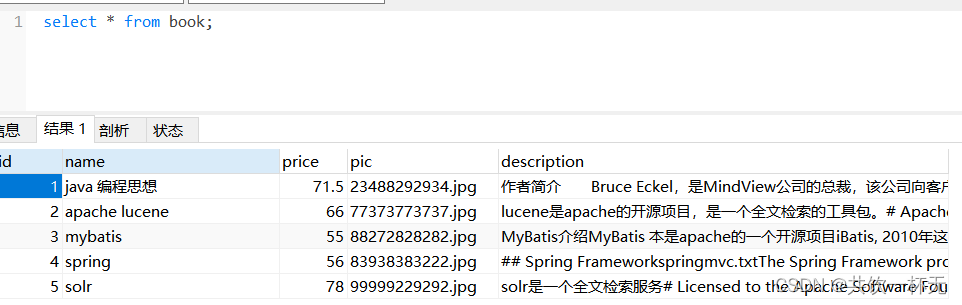
索引文件的逻辑结构
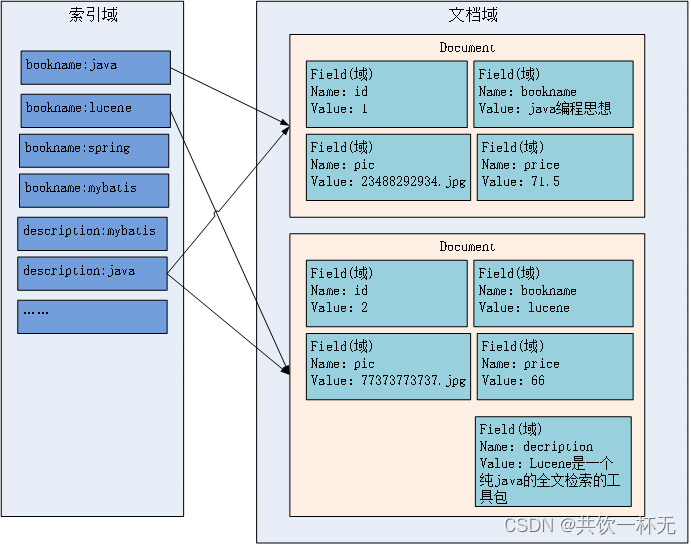
- 文档域
文档域存储的信息就是采集到的信息,通过Document对象来存储,具体说是通过Document对象中field域来存储数据。
比如:数据库中一条记录会存储一个Document对象,数据库中一列会存储成Document中一个field域。
文档域中,Document对象之间是没有关系的。而且每个Document中的field域也不一定一样。
- 索引域
索引域主要是为了搜索使用的。索引域内容是经过lucene分词之后存储的。
- 倒排索引表
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。
** 倒排索引结构**是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。
采集数据
public class BookDaoImpl implements BookDao {@Overridepublic List<Book> queryBooks() {// 数据库链接Connection connection = null;// 预编译statementPreparedStatement preparedStatement = null;// 结果集ResultSet resultSet = null;// 图书列表List<Book> list = new ArrayList<Book>();try {// 加载数据库驱动Class.forName("com.mysql.jdbc.Driver");// 连接数据库connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");// SQL语句String sql = "SELECT * FROM book";// 创建preparedStatementpreparedStatement = connection.prepareStatement(sql);// 获取结果集resultSet = preparedStatement.executeQuery();// 结果集解析while (resultSet.next()) {Book book = new Book();book.setId(resultSet.getInt("id"));book.setName(resultSet.getString("name"));book.setPrice(resultSet.getFloat("price"));book.setPic(resultSet.getString("pic"));book.setDescription(resultSet.getString("description"));list.add(book);}} catch (Exception e) {e.printStackTrace();}return list;}}
创建索引
创建索引流程:
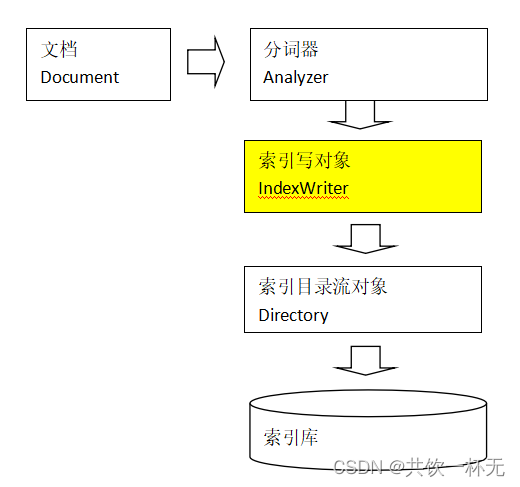
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
创建Document
采集数据的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档(Document)中包括一个一个的域(Field)。
代码实现:
@Testpublic void createIndex() throws Exception {// 采集数据BookDao dao = new BookDaoImpl();List<Book> list = dao.queryBooks();// 将采集到的数据封装到Document对象中List<Document> docList = new ArrayList<>();Document document;for (Book book : list) {document = new Document();// store:如果是yes,则说明存储到文档域中// 图书IDField id = new TextField("id", book.getId().toString(), Field.Store.YES);// 图书名称Field name = new TextField("name", book.getName(), Field.Store.YES);// 图书价格Field price = new TextField("price", book.getPrice().toString(), Field.Store.YES);// 图书图片地址Field pic = new TextField("pic", book.getPic(), Field.Store.YES);// 图书描述Field description = new TextField("description",book.getDescription(), Field.Store.YES);// 将field域设置到Document对象中document.add(id);document.add(name);document.add(price);document.add(pic);document.add(description);docList.add(document);}// 创建分词器,标准分词器StandardAnalyzer analyzer = new StandardAnalyzer();// 创建IndexWriterIndexWriterConfig cfg = new IndexWriterConfig(analyzer);// 指定索引库的地址Path path = Paths.get("D:\\usr\\lucene\\");Directory directory = FSDirectory.open(path);IndexWriter writer = new IndexWriter(directory, cfg);// 通过IndexWriter对象将Document写入到索引库中for (Document doc : docList) {writer.addDocument(doc);}// 关闭writerwriter.close();}
执行后可以看到对应目录已生成相关索引库文件。
分词
Lucene中分词主要分为两个步骤:分词、过滤
分词:将field域中的内容一个个的分词。过滤:将分好的词进行过滤,比如去掉标点符号、大写转小写、词的型还原(复数转单数、过去式转成现在式)、停用词过滤。- 停用词:单独应用没有特殊意义的词。比如的、啊、等,英文中的this is a the等等。
Lucene作为了一个工具包提供不同国家的分词器,如下图:

案例:
要分词的内容
Lucene is a Java full-text search engine.
-
分词
Lucene
is
a
Java
Full
text
search
engine
. -
过滤
去掉标点符号
Lucene
is
a
Java
Full
text
search
engine
- 去掉停用词
Lucene
Java
Full
text
search
engine
- 大写转小写
lucene
java
full
text
search
engine
如下是org.apache.lucene.analysis.standard.StandardAnalyzer的部分源码:
protected TokenStreamComponents createComponents(String fieldName) {StandardTokenizer src = new StandardTokenizer();src.setMaxTokenLength(this.maxTokenLength);TokenStream tok = new LowerCaseFilter(src);TokenStream tok = new StopFilter(tok, this.stopwords);return new TokenStreamComponents((r) -> {src.setMaxTokenLength(this.maxTokenLength);src.setReader(r);}, tok);}
Tokenizer是分词器,负责将reader转换为语汇单元即进行分词,Lucene提供了很多的分词器,也可以使用第三方的分词,比如IKAnalyzer一个中文分词器。
org.apache.lucene.analysis.TokenFilter
如下图是语汇单元的生成过程:

从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。
比如下边的文档经过分析器分析如下:
原文档内容:
Lucene is a Java full-text search engine.
分析后得到的语汇单元:
lucene、java、full、text、search、engine
同一个域中相同的语汇单元(Token)对应同一个Term(词),它记录了语汇单元的内容及所在域的域名等,还包括来该token出现的频率及位置。
- 不同的域中拆分出来的相同的单词对应不同的term。
- 相同的域中拆分出来的相同的单词对应相同的term。
例如:图书信息里面,图书名称中的java和图书描述中的java对应不同的term
代码实现:
// 创建分词器,标准分词器StandardAnalyzer analyzer = new StandardAnalyzer();// 创建IndexWriterIndexWriterConfig cfg = new IndexWriterConfig(analyzer);// 指定索引库的地址Path path = Paths.get("D:\\usr\\lucene\\");Directory directory = FSDirectory.open(path);IndexWriter writer = new IndexWriter(directory, cfg);// 通过IndexWriter对象将Document写入到索引库中for (Document doc : docList) {writer.addDocument(doc);}// 关闭writerwriter.close();
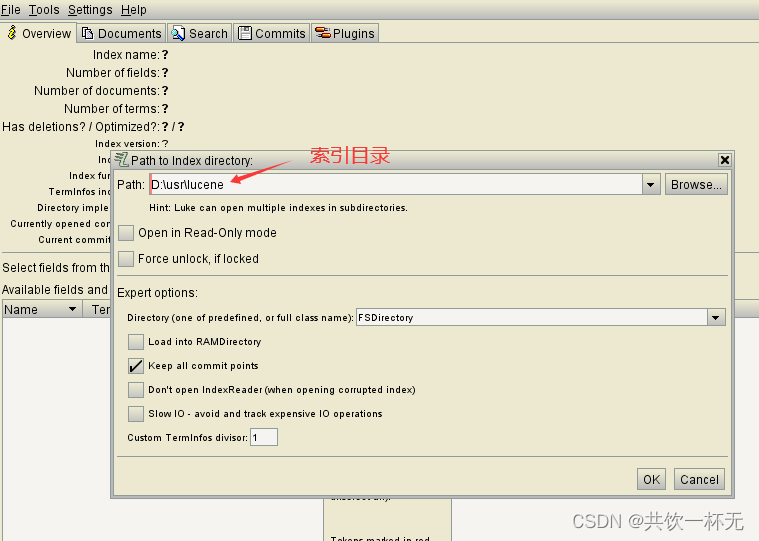
使用luke工具查看索引
Luke作为Lucene工具包中的一个工具(http://www.getopt.org/luke/),可以通过界面来进行索引文件的查询、修改。
打开Luke方法:
- 命令运行:cmd运行:java -jar lukeall-4.10.3.jar
- 手动执行:双击lukeall-4.10.3.jar
搜索流程
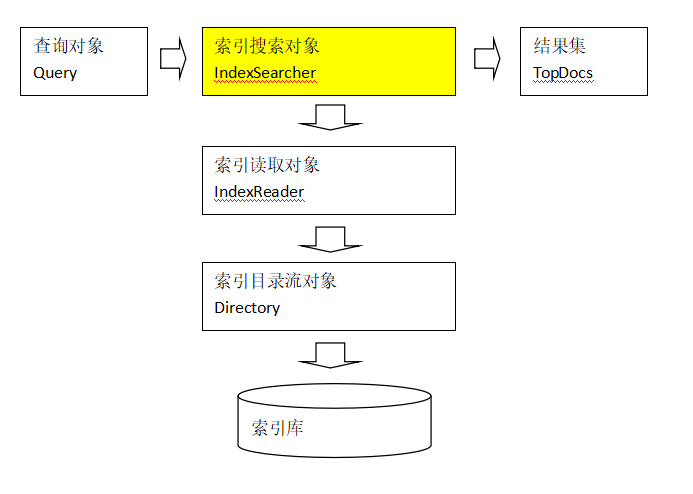
- 用户定义查询语句,用户确定查询什么内容(输入什么关键字)
指定查询语法,相当于sql语句。
- IndexSearcher索引搜索对象,定义了很多搜索方法,程序员调用此方法搜索。
- IndexReader索引读取对象,它对应的索引维护对象IndexWriter,IndexSearcher通过IndexReader读取索引目录中的索引文件
- Directory索引流对象,IndexReader需要Directory读取索引库,使用FSDirectory文件系统流对象
- IndexSearcher搜索完成,返回一个TopDocs(匹配度高的前边的一些记录)
输入查询语句
同数据库的sql一样,lucene全文检索也有固定的语法:
最基本的有比如:AND, OR, NOT 等
举个例子,用户想找一个description中包括java关键字和lucene关键字的文档。
它对应的查询语句:description:java AND lucene
如下是使用luke搜索的例子:
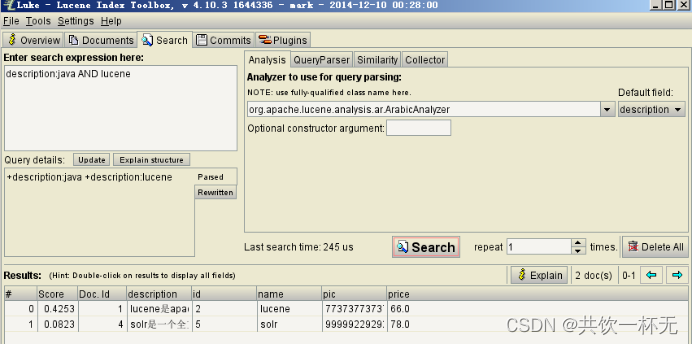
搜索索引
和索引过程的分词一样,这里要对用户输入的关键字进行分词,一般情况索引和搜索使用的分词器一致。
根据关键字从索引中找到对应的索引信息,即词term。term与document相关联,找到了term就找到了关联的document,从document取出Field中的信息即是要搜索的信息。
代码实现:
@Testpublic void indexSearch() throws Exception {// 创建query对象// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致// 第一个参数:默认搜索的域的名称QueryParser parser = new QueryParser("description",new StandardAnalyzer());// 通过queryparser来创建query对象// 参数:输入的lucene的查询语句(关键字一定要大写)Query query = parser.parse("description:java AND lucene");// 创建IndexSearcher// 指定索引库的地址Path path = Paths.get("D:\\usr\\lucene\\");Directory directory = FSDirectory.open(path);IndexReader reader = DirectoryReader.open(directory);IndexSearcher searcher = new IndexSearcher(reader);// 通过searcher来搜索索引库// 第二个参数:指定需要显示的顶部记录的N条TopDocs topDocs = searcher.search(query, 10);// 根据查询条件匹配出的记录总数long count = topDocs.totalHits.value;System.out.println("匹配出的记录总数:" + count);// 根据查询条件匹配出的记录ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {// 获取文档的IDint docId = scoreDoc.doc;// 通过ID获取文档Document doc = searcher.doc(docId);System.out.println("商品ID:" + doc.get("id"));System.out.println("商品名称:" + doc.get("name"));System.out.println("商品价格:" + doc.get("price"));System.out.println("商品图片地址:" + doc.get("pic"));System.out.println("==========================");// System.out.println("商品描述:" + doc.get("description"));}// 关闭资源reader.close();}
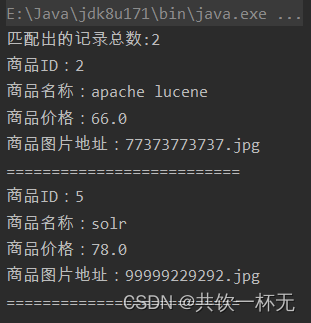
执行后输出如下:
参考:
https://www.cnblogs.com/yebuzhiqiu/p/14817079.html
https://blog.csdn.net/qq_41946557/article/details/103540619
本文内容到此结束了,
如有收获欢迎点赞👍收藏💖关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问💬欢迎各位指出。
主页:共饮一杯无的博客汇总👨💻保持热爱,奔赴下一场山海。🏃🏃🏃