点击上方“AI遇见机器学习”,选择“星标”公众号
重磅干货,第一时间送
文|羿阁 发自 凹非寺
源|量子位
2022年流行“文生图”模型,那2023年流行什么?
机器学习工程师Daniel Bourke的答案是:反过来!
这不,一个最新发布的“图生文”模型在网上爆火,其优秀的效果引发众多网友纷纷转发、点赞。

不仅是基础的“看图说话”功能,写情诗、讲解剧情、给图片中对象设计对话等等,这个AI都拿捏得稳稳的!
比如,当你在网上刷到诱人的美食时,只需把图片发给它,它就会立马识别出需要的食材和做菜步骤:

甚至图片中的一些列文虎克的细节也能“看”得清清楚楚。
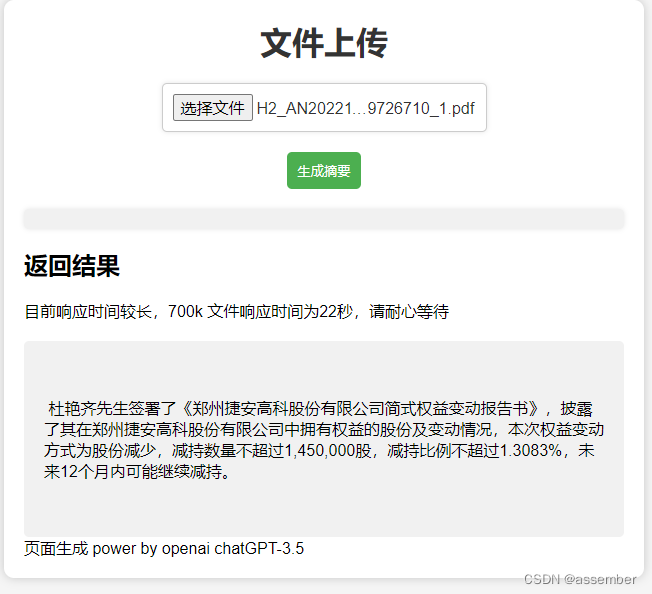
当被问到如何才能从图片中倒着的房子里离开,AI的回答是:侧面不是有滑梯嘛!
这只新AI名为BLIP-2 (Bootstrapping Language-Image Pre-training 2),目前代码已开源。
最重要的是,和以前的研究不同,BLIP-2使用的是一种通用的预训练框架,因此可以任意对接自己的语言模型。
有网友已经在畅想把接口换成ChatGPT后的强强组合了。

作者之一Steven Hoi更是放话:BLIP-2未来就是“多模态版ChatGPT”。

那么,BLIP-2神奇的地方还有哪些?一起往下看。
理解能力一流
BLIP-2的玩法可以说非常多样了。
只需提供一张图片,你就可以与它对话,让它看图讲故事、推理、生成个性化文本等各种要求都能满足。
举个例子,BLIP-2不仅能轻松识别图片中的景点是长城,还能介绍出长城的历史:
中国的长城是公元前221年秦始皇为了保护帝都不受北方侵略而建造的。

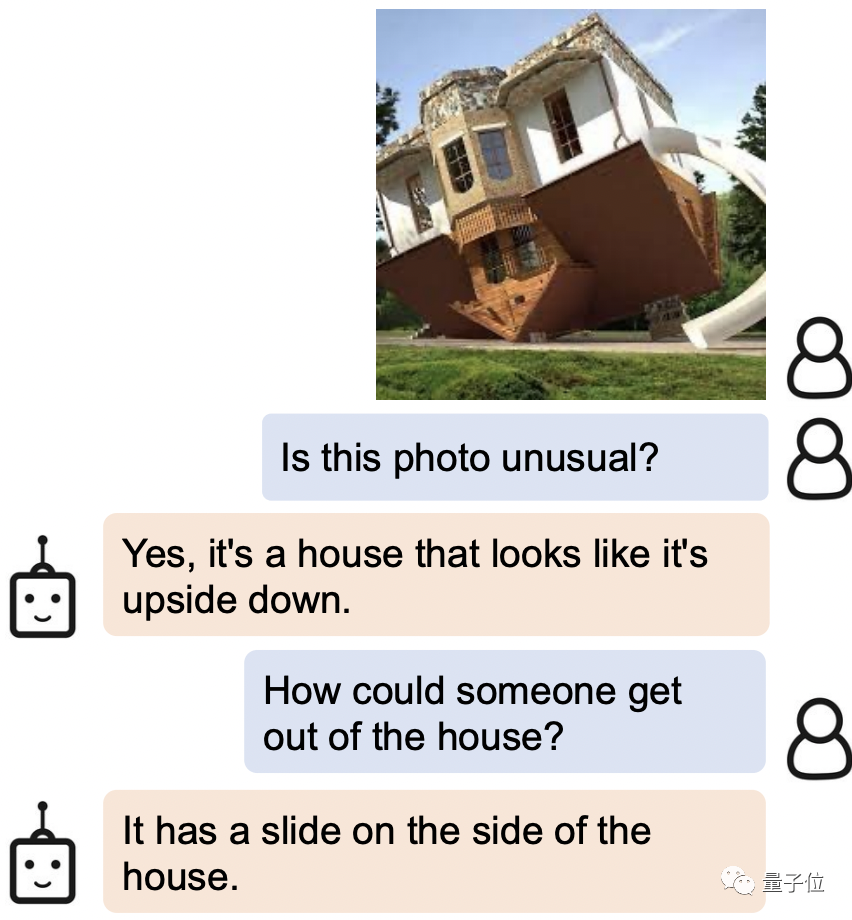
给它一张电影剧照,BLIP-2不光知道出自哪,还知道故事的结局是be:泰坦尼克号沉没,男主淹死。
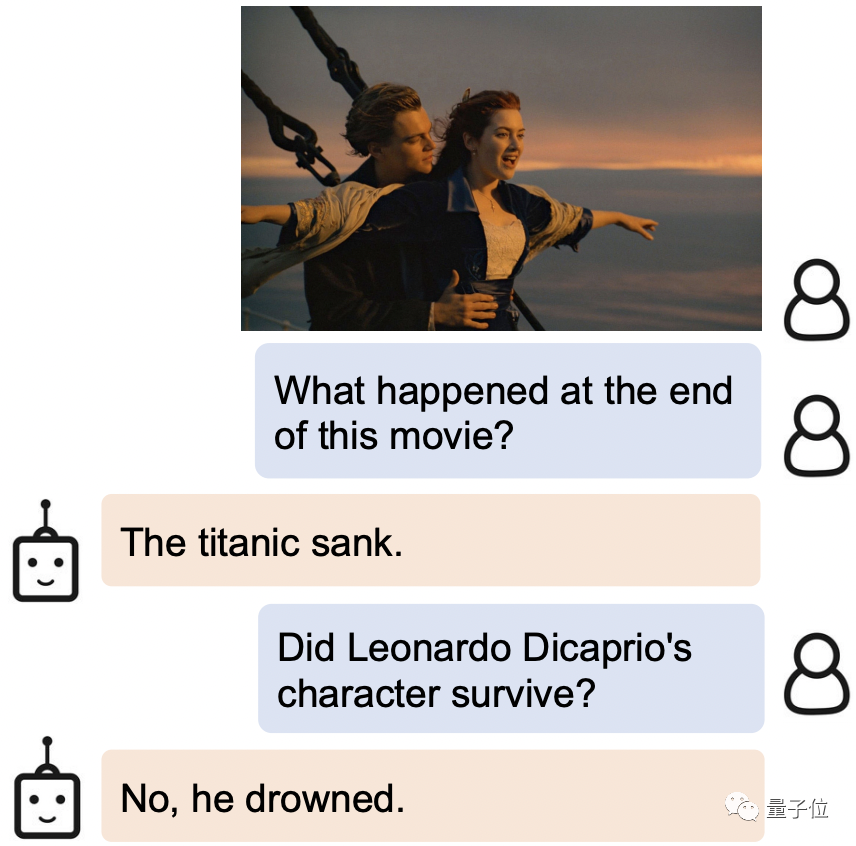
在对人类神态的拿捏上,BLIP-2同样把握得非常准确。
被问到这张图片中的男人是什么表情,他为什么这样时,BLIP-2的回答是:他害怕那只鸡,因为它正朝他飞来。
更神奇的是,在许多开放性问题上,BLIP-2的表现也很出色。
让它根据下面的图片写一句浪漫的话:

它的回答是这样的:爱情就像日落,很难预见它的到来,但当它发生时,它是如此的美丽。

这不光理解能力满分,文学造诣也相当强啊!

让它给图片中的两只动物生成一段对话,BLIP-2也能轻松拿捏傲娇猫猫x蠢萌狗狗的设定:
猫: 嘿,狗狗,我能骑在你背上吗?
狗: 当然,为什么不呢?
猫: 我已经厌倦了在雪地里行走。

那么,如此强大的理解能力背后,BLIP-2究竟是怎么做到的?
多项视觉语言任务上实现新SOTA
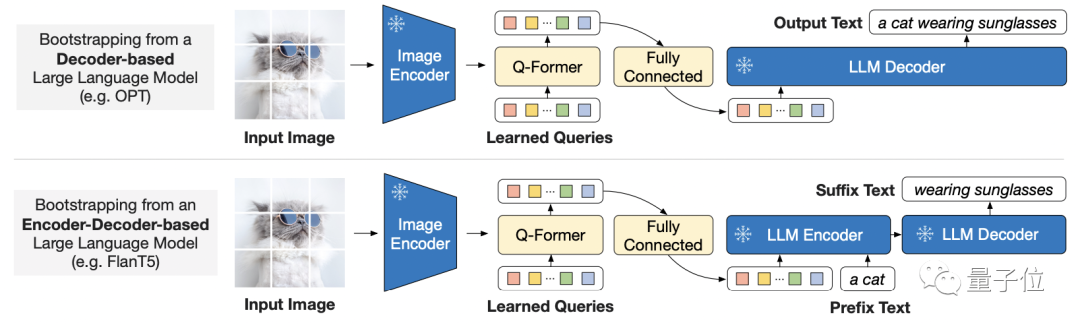
考虑到大规模模型的端到端训练成本越来越高,BLIP-2使用的是一种通用且高效的预训练策略:
从现成的冻结预训练图像编码器和冻结的大型语言模型中引导视觉语言预训练。
这也意味着,每个人都可以选择自己想用的模型接入使用。
而为了弥补了模态之间的差距,研究者提出了一个轻量级的查询Transformer。
该Transformer分两个阶段进行预训练:
第一阶段从冻结图像编码器引导视觉语言表示学习,第二阶段将视觉从冻结的语言模型引导到语言生成学习。
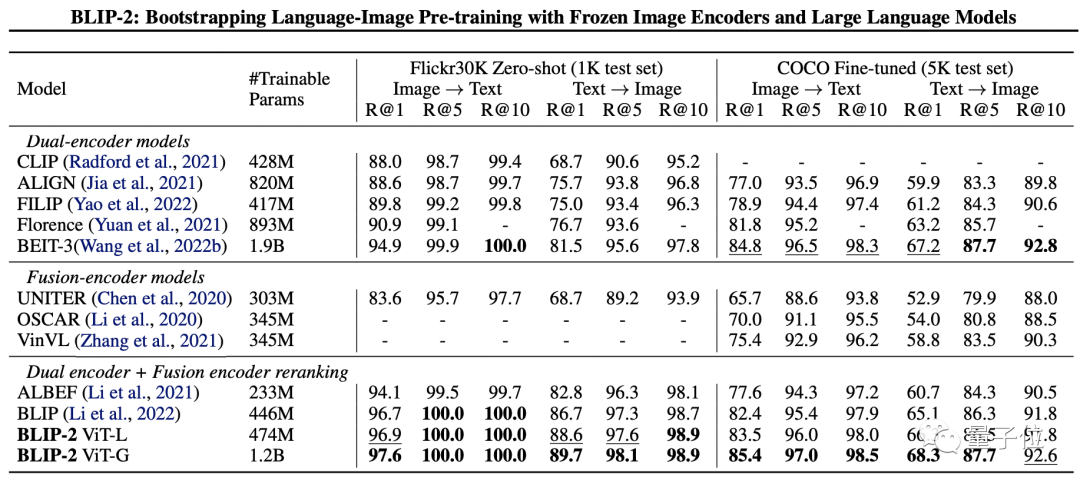
为了测试BLIP-2的性能,研究人员分别从零样本图像-文本生成、视觉问答、图像-文本检索、图像字幕任务上对其进行了评估。
最终结果显示,BLIP-2在多项视觉语言任务上都实现了SOTA。
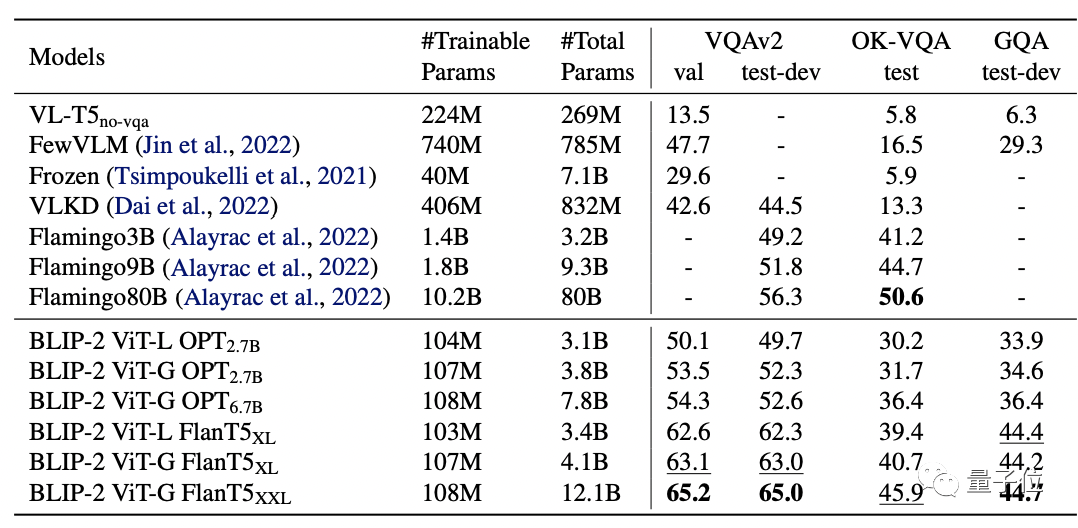
其中,BLIP-2在zero-shot VQAv2上比Flamingo 80B高8.7%,且训练参数还减少了54倍。
而且显而易见的是,更强的图像编码器或更强的语言模型都会产生更好的性能。
值得一提的是,研究者在论文最后也提到,BLIP-2还存在一个不足,那就是缺乏上下文学习能力:
每个样本只包含一个图像-文本对,目前还无法学习单个序列中多个图像-文本对之间的相关性。
研究团队
BLIP-2的研究团队来自Salesforce Research。

第一作者为Junnan Li,他也是一年前推出的BLIP的一作。
目前是Salesforce亚洲研究院高级研究科学家。本科毕业于香港大学,博士毕业于新加坡国立大学。
研究领域很广泛,包括自我监督学习、半监督学习、弱监督学习、视觉-语言。
以下是BLIP-2的论文链接和GitHub链接,感兴趣的小伙伴们可以自取~
论文链接:
https://arxiv.org/pdf/2301.12597.pdf
GitHub链接:
https://github.com/salesforce/LAVIS/tree/main/projects/blip2