🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
引入大型语言模型
探索语言模型和 NLP 的基础
了解 Transformer 架构及其在 LLM 中的作用
揭秘 GPT 模型中的标记化和预测步骤
简史:从 GPT-1 到 GPT-4
GPT-1
GPT-2
GPT-3
从 GPT-3 到 InstructGPT
GPT-3.5、Codex 和 ChatGPT
GPT-4
大型语言模型用例和示例产品
Be My Eyes
Morgan Stanley
Khan Academy
Duolingo
Yabble
Waymark
Inworld AI
谨防 AI 幻觉:限制和注意事项
使用插件和微调优化 GPT 模型
概括
想象一个世界,在这个世界中,您可以像与朋友一样快速地与计算机交流。那会是什么样子?您可以创建哪些应用程序?这就是 OpenAI 使用其 GPT 模型帮助构建的世界,为我们的设备带来类似人类的对话能力。作为人工智能 (AI) 的最新进展,GPT-4 和 ChatGPT 是在海量数据上训练的大型语言模型 (LLM),使它们能够以非常高的准确性识别和生成类似人类的文本。
这些人工智能模型的影响远远超出了简单的语音助手。得益于 OpenAI 的模型,开发人员现在可以利用自然语言处理 (NLP) 的强大功能来创建能够以曾经科幻小说的方式理解我们需求的应用程序。从学习和适应了解每个学生独特学习风格的个性化教育工具的创新客户支持系统,GPT-4 和 ChatGPT 开辟了一个充满可能性的全新世界。
但是什么是GPT-4 和 ChatGPT?本章的目标是深入探讨这些 AI 模型的基础知识、起源和主要特征。通过了解这些模型的基础知识,您将能够基于这些强大的新技术构建下一代应用程序。
引入大型语言模型
探索语言模型和 NLP 的基础
作为LLM,GPT-4和ChatGPT是NLP领域获得的最新一类模型,NLP本身是机器学习(ML)和AI的一个子领域。因此,在我们进入 GPT-4 和 ChatGPT 之前,让我们快速了解一下 NLP 和其他相关领域。
人工智能有不同的定义,但其中一个或多或少的共识是,人工智能是计算机系统的发展,可以执行通常需要人类智能才能完成的任务。根据这个定义,许多算法都属于 AI 范畴。例如,考虑 GPS 应用程序中的交通预测任务或战略视频游戏中使用的基于规则的系统。在这些例子中,从外面看,机器似乎需要智能来完成这些任务。
机器学习是人工智能的一个子集。在机器学习中,我们并不试图直接实现人工智能系统使用的决策规则。相反,我们尝试开发允许系统从示例中自行学习的算法。自 1950 年代机器学习研究开始以来,科学文献中提出了许多机器学习算法。其中,深度学习算法是 ML 模型的著名示例,而 GPT-4 和 ChatGPT 则基于一种特殊类型的深度学习算法,称为 transformer。图1-1 说明了这些术语之间的关系。
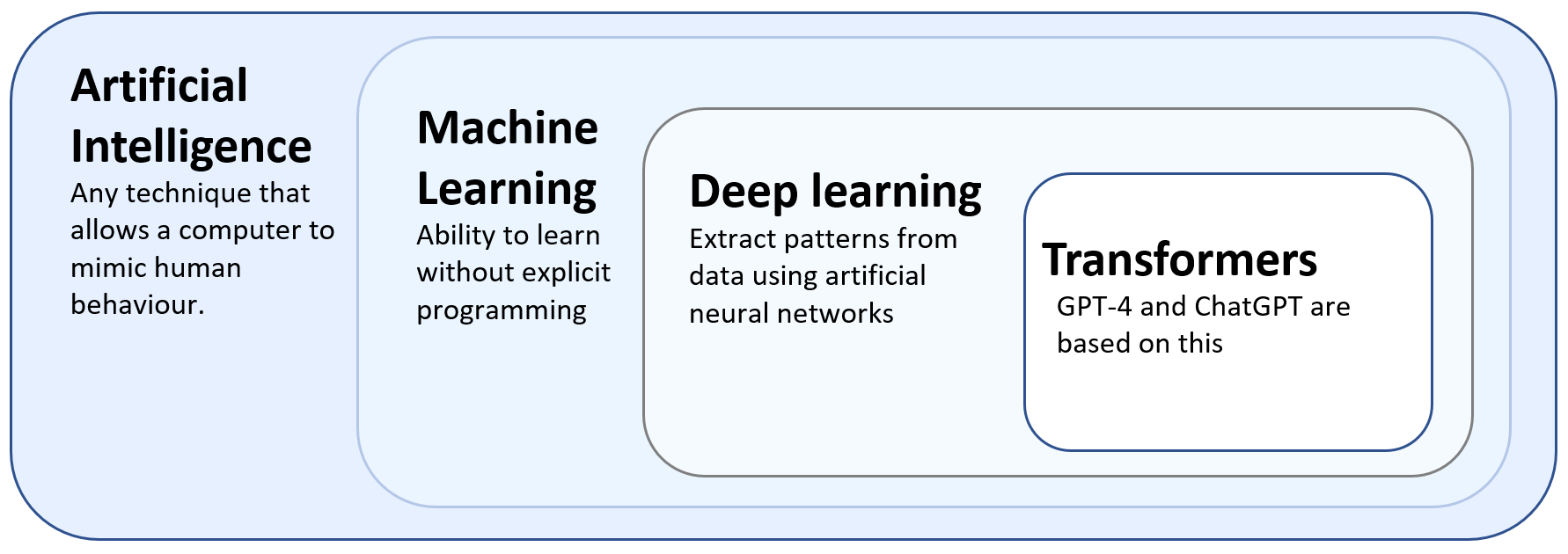
图 1-1 从 AI 到Transformers的一组嵌套技术。
NLP 是一种 AI 应用程序,专注于计算机与自然人类语言文本之间的交互。现代 NLP 解决方案基于 ML 算法。NLP 的目标是让计算机理解自然语言文本。这个目标涵盖了广泛的任务:
文本分类
将输入文本分类到预定义的组中。这包括,例如,情绪分析和主题分类。
自动翻译
自动将文本从一种语言翻译成另一种语言。
问题解答
根据给定的文本回答问题。
文本生成
基于给定的输入文本,称为提示,模型生成连贯且相关的输出文本。
如前所述,大型语言模型是试图解决文本生成任务的机器学习模型。法学硕士使计算机能够理解、解释和生成人类语言,从而实现更有效的人机交流。为了能够做到这一点,法学硕士分析或培训基于大量的文本数据,从而学习句子中单词之间的模式和关系。给定一个输入文本,此学习过程允许 LLM 预测最有可能的下一个单词,并以这种方式对文本输入生成有意义的响应。最近几个月发布的现代语言模型非常庞大,并且已经在如此多的文本上进行了训练,以至于它们现在可以直接执行大多数 NLP 任务,例如文本分类、机器翻译、问答等。GPT-4 和 ChatGPT 模型是两个擅长文本生成任务的现代 LLM。
法学硕士的发展可以追溯到几年前。它从像 n-gram 这样的简单语言模型开始,它试图根据前面的单词预测句子中的下一个单词。N-gram 模型使用频率来做到这一点。预测的下一个词是它所训练的文本中前一个词之后出现频率最高的词。虽然这种方法是一个好的开始,但它需要改进对上下文和语法的理解,从而导致文本生成不一致。
为了提高这些 n-gram 模型的性能,引入了更高级的学习算法,包括递归神经网络 (RNN) 和长短期记忆网络 (LSTM)。这些模型可以学习更长的序列并比 n-gram 更好地分析上下文,但它们仍然需要帮助才能有效地处理大量数据。这些类型的循环模型在很长一段时间内都是最有效的模型,因此在自动机器翻译等工具中使用最多。
了解 Transformer 架构及其在 LLM 中的作用
Transformer 架构彻底改变了 NLP。它大量使用了称为交叉注意力和自注意力的创新方法,这两种方法都基于几年前提出的注意力机制。交叉注意力和自注意力使模型更容易理解文本中单词之间的关系。
交叉注意力有助于模型确定输入文本的哪些部分对于准确预测输出文本中的下一个单词很重要。它就像一盏聚光灯,照在输入文本中的单词或短语上,突出显示进行下一个单词预测所需的相关信息;同时忽略不太重要的细节。
为了说明这一点,让我们举一个简单的句子翻译任务的例子。想象一下,我们有一个英文句子,“Alice enjoyed the sunny weather in Brussels”,它应该被翻译成法语“Alice a profité du temps ensoleillé à Bruxelles”。在这个例子中,让我们专注于生成法语单词“ensoleillé”,意思是“sunny”。对于这个预测,交叉注意力会给英语单词“sunny”和“weather”更多的权重,因为它们都与“ensoleillé”的含义相关。通过关注这两个词,交叉注意力有助于模型为句子的这一部分生成准确的翻译。图1-4 说明了这个例子。

图 1-2 交叉注意力有助于将注意力集中在输入文本的重要部分。
另一方面,自注意力是指模型在处理输入时专注于输入的不同部分的能力。在 NLP 的上下文中,该模型可以评估句子中每个单词与其他单词的重要性。这使它能够更好地理解单词之间的关系,并从输入文本中的多个单词构建新概念。
更具体地说,让我们来看下面的例子:“Alice received praise from her colleagues.” 假设模型试图理解句子中“她”一词的含义。自注意力机制为句子中的单词分配不同的权重,突出显示与“她”相关的单词。在这个例子中,self-attention 会把更多的权重放在“Alice”和“colleagues”这两个词上。自注意力帮助模型从这些词中构建新概念。在这个例子中,可能出现的概念之一是“爱丽丝的同事”,如图1-5 所示。
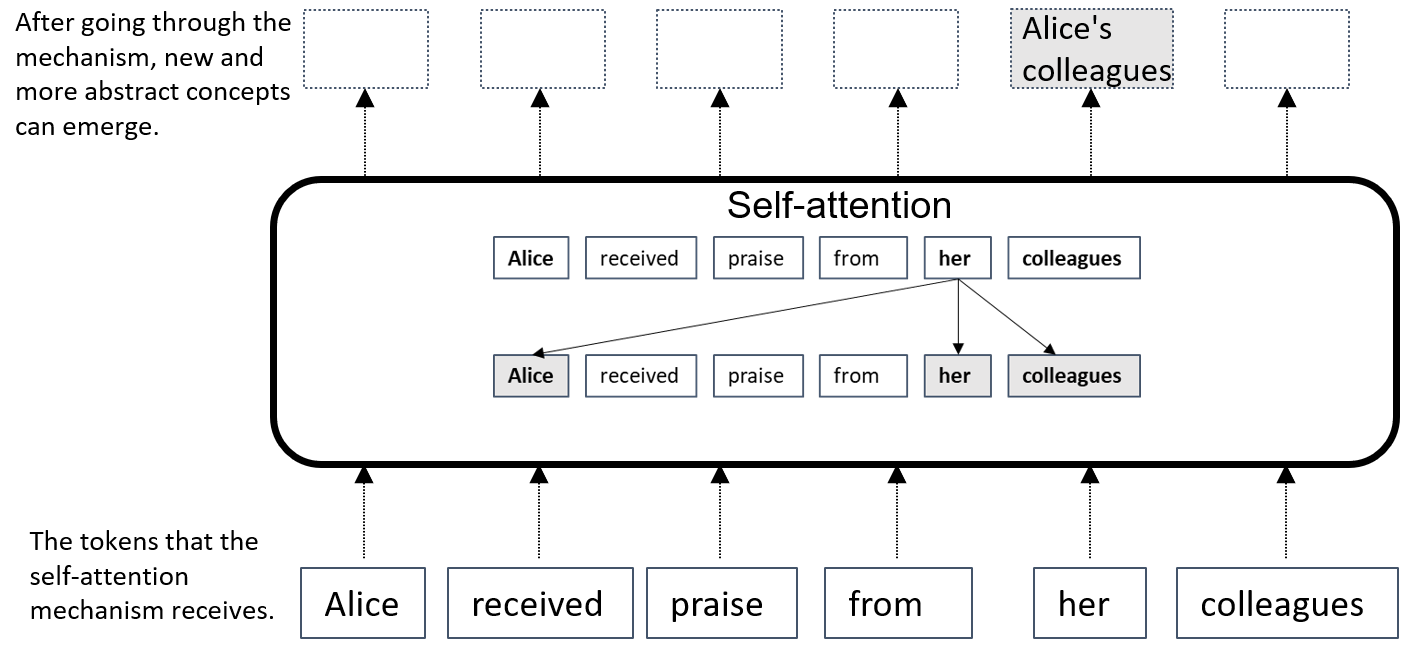
图 1-3 Self-attention 允许出现“Alice 的同事”概念。
与循环架构不同,Transformer 还具有易于并行化的优势。这意味着转换器架构可以同时处理输入文本的多个部分,而不是顺序处理。这允许更快的计算和训练,因为模型的不同部分可以并行工作,而无需等待前面的步骤完成,这与需要顺序处理的循环架构不同。这一进步使数据科学家能够在更大的数据集上训练模型,为开发 LLM 铺平了道路。
Transformer 架构于 2017 年推出,最初是为机器翻译等序列到序列任务开发的。标准转换器由两个主要组件组成:编码器和解码器,两者都严重依赖注意力机制。编码器的任务是处理输入文本,识别有用的特征,并生成该文本的有意义的表示,称为嵌入. 然后,解码器使用此嵌入来生成有效解释编码信息的输出,例如翻译或摘要。通过允许解码器利用编码器生成的嵌入,交叉注意力起着至关重要的作用。在序列到序列任务的上下文中,编码器的作用是捕获输入文本的含义,而解码器的作用是根据编码器在嵌入中捕获的信息生成所需的输出。编码器和解码器一起为处理和生成文本提供了强大的工具。
GPT基于Transformer架构,专门利用了原有架构的decoder部分。在 GPT 中,编码器不存在,因此不需要交叉注意力来整合编码器产生的嵌入。因此,GPT 完全依赖解码器中的自我注意机制来生成上下文感知表示和预测。请注意,其他知名模型,如 BERT(来自 Transformers 的双向编码器表示)都是基于编码器部分的。我们不会在本书中介绍这种类型的模型。图 1- 4 说明了这些不同模型的演变。

图 1-4 NLP 技术从 N-gram 到 LLM 出现的演变。
揭秘 GPT 模型中的标记化和预测步骤
像 GPT 这样的大型语言模型接收提示并返回通常在上下文中有意义的输出。例如,提示可能是“今天天气很好,所以我决定去”,而模型输出可能是“出去走走”。您可能想知道 LLM 模型如何根据输入提示构建此输出文本。正如您将看到的,这主要只是一个概率问题。
当提示被发送到 LLM 时,它首先将输入分成更小的部分,称为标记。这些标记代表单个词或词的一部分。例如,前面的提示可以这样分解:[“ The”、“ wea ”、“ ther ”、“is”、“nice”、“today”、“,”、“so”、“I”、“ de”,“ci”,“ ded ”,“to ”]。每种语言模型都带有其分词器。GPT-4 的分词器在撰写本文时尚不可用,但您可以测试GPT-3的分词器。
提示
根据字长理解标记的经验法则是,对于英文文本,100 个标记大约等于 75 个英文单词。
得益于前面介绍的注意力原则和转换器架构,LLM 处理这些标记并可以解释它们之间的关系以及提示的整体含义。这种转换器架构允许模型有效地识别文本中的关键信息和上下文。
为了创建一个新句子,LLM 根据提示的上下文预测最有可能的下一个标记。OpenAI 制作了两个版本的 GPT-4,上下文窗口分别为 8,192 个令牌和 32,768 个令牌。与之前难以处理长输入序列的循环模型不同,具有注意力机制的转换器架构允许现代 LLM 将上下文作为一个整体来考虑。基于这个上下文,模型为每个可能的下一个标记分配一个概率分数,并根据这个分数选择一个作为下一个标记。在我们的示例中,在“今天天气很好,所以我决定”之后,下一个最佳标记可能是“ go ”。
然后重复此过程,但现在上下文变为“The weather is nice today, so I decided to go”,其中将先前预测的标记“ go ”添加到原始提示中。该模型可能预测的第二个标记可能是“ for ”。重复此过程,直到形成一个完整的句子:“ go for a walk ”。这个过程依赖于 LLM 从大量文本数据中学习下一个最可能的单词的能力。图1-5 说明了这个过程。
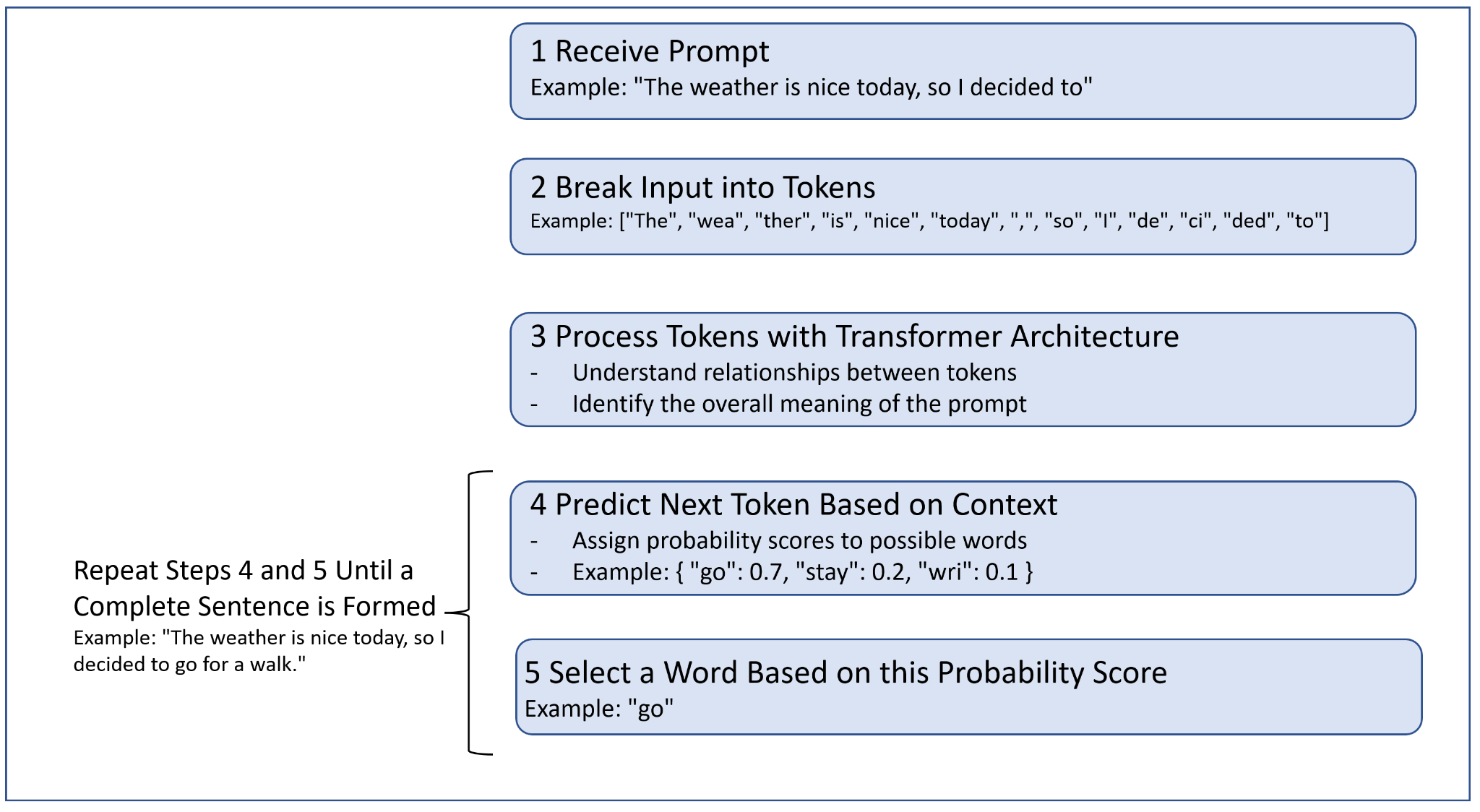
图 1-5 完成过程是迭代的,逐个标记。
简史:从 GPT-1 到 GPT-4
在本节中,我们将研究 OpenAI GPT 模型从 GPT-1 到 GPT-4 的演变。
GPT-1
2018 年年中,在 transformer 架构发明仅一年后,OpenAI 发表了一篇题为“Improving Language Understanding by Generative Pre-Training”的论文,作者是 Radford、Alec 等人。其中,该公司推出了 Generative Pre-trained Transformer,也称为 GPT-1。
在 GPT-1 之前,构建高性能 NLP 神经模型的常用方法依赖于监督学习。这些学习技术使用大量手动标记的数据。例如,在目标是对给定文本进行正面或负面情绪分类的情感分析任务中,常见的策略需要收集数千个手动标记的文本示例以构建有效的分类模型。然而,对大量注释良好的监督数据的需求限制了这些技术的性能,因为生成此类数据集既困难又昂贵。
在他们的论文中,GPT-1 的作者提出了一种新的学习过程,其中引入了无监督的预训练步骤。在此预训练步骤中,不需要标记数据。相反,该模型被训练来预测下一个标记是什么。由于使用了允许并行化的 Transformer 架构,因此这种预训练是在大量数据上进行的。GPT-1 模型使用 BooksCorpus 数据集进行预训练,该数据集包含大约 11,000 本未出版书籍的文本。该数据集最初于 2015 年发表在一篇科学论文“Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books” 朱玉坤等人。这个 BookCorpus 数据集最初是在多伦多大学的网页上提供的。然而,今天原始数据集的官方版本不再公开访问。
GPT-1 模型虽然不如其后续模型强大,但被发现在各种基本 NLP 任务中都很有效。在无监督学习阶段,模型学会了预测 BookCorpus 数据集文本中的下一项。但是,由于模型很小,如果不进行微调,就无法执行复杂的任务。为了使模型适应特定的目标任务,对一小组手动标记的数据执行了第二个监督学习步骤,称为微调。例如,在情感分析等分类任务中,可能需要在一小组手动标记的文本示例上重新训练模型以获得良好的准确性。这个过程允许修改在初始预训练阶段学习的参数,以更好地适应手头的任务。尽管它的尺寸相对较小,
GPT-1 的架构是与 2017 年推出的原始 transformer 类似的解码器,具有 1.17 亿个参数。第一个 GPT 模型为未来具有更大数据集和更多参数的模型铺平了道路,以更好地利用变压器架构的潜力。
GPT-2
2019 年初,OpenAI 提出了 GPT-2,它是 GPT-1 模型的放大版本,将参数数量和训练数据集的大小增加了十倍。这个新版本的参数数量是 15 亿,在 40 GB 的文本上训练。2019 年 11 月,OpenAI 发布了完整版的 GPT-2 语言模型。
笔记
GPT-2 是公开可用的,可以从Huggingface或GitHub下载。
GPT-2 表明,在更大的数据集上训练更大的语言模型可以提高语言模型理解任务的能力,并在许多工作上优于最先进的技术。它还表明,更大的语言模型可以更好地理解自然语言。
GPT-3
GPT 的第 3 版于 2020 年 6 月由 OpenAI 发布。GPT-2 和 GPT-3 的主要区别在于模型的大小和用于训练的数据量。GPT-3 是一个更大的模型,具有 1750 亿个参数,使其能够捕获更复杂的模式。此外,GPT-3 在更广泛的数据集上进行了训练。这包括普通抓取,一个大型网络档案,包含来自数十亿网页和其他来源(例如维基百科)的文本。这个训练数据集包括来自网站、书籍和文章的内容,使 GPT-3 能够更深入地理解语言和上下文。因此,GPT-3 提高了各种语言任务的性能。它在其生成的文本中表现出卓越的连贯性和创造性。它甚至能够编写代码片段,例如 SQL 查询,以及执行其他智能任务。GPT-3 还消除了对其前身强制执行的微调步骤的需要。
最终用户给出的任务与模型在训练期间看到的任务之间存在不一致的问题。正如我们所见,语言模型被训练为根据输入上下文预测下一个单词。这个训练过程不一定直接与最终用户希望模型执行的任务保持一致。这是一个问题,增加语言模型的大小并不能从本质上使它们更好地遵循用户意图或指令。此外,像 GPT-3 这样的模型是根据来自不同互联网来源的数据进行训练的。尽管在来源的选择上进行了清理,但学习数据并非不可能包含虚假或有问题的信息,包括种族主义、性别歧视、错误信息或虚假信息。因此,模型有时可能会说错话,甚至是有毒的。指导系列。与最初的基本 GPT-3 模型不同,指导模型通过强化学习和人类反馈进行优化,以遵循人类指令,同时使模型更真实、毒性更小。
为了说明差异,我们在提示中添加了“解释时间复杂性的含义”。
-
使用标准 GPT-3,我们获得输出:“解释空间复杂度的含义。解释大 O 符号的含义。”
-
使用 instructGPT-3,我们得到:“时间复杂度是一种衡量算法运行和完成其任务所需时间的方法。它通常使用大 O 表示法表示,大 O 表示法根据算法执行的操作数来衡量算法的复杂性。算法的时间复杂度很重要,因为它决定了算法的效率以及它在更大输入下的扩展性。”
我们可以看到,对于相同的输入,第一个模型无法回答问题(答案甚至很奇怪),而第二个模型可以。当然,使用标准 GPT-3 模型可以获得所需的响应,但要做到这一点,有必要应用即时工程技术,而这对于指令模型来说则不太必要。本书后面会介绍一些提示工程技术。
从 GPT-3 到 InstructGPT
OpenAI 在 Ouyang, Long 等人的科学论文“Training language models to follow instructions with human feedback”中解释了指令系列是如何构建的。
从 GPT-3 模型到指令 GPT-3 模型,训练配方有两个主要阶段:监督微调(SFT) 和基于人类反馈的强化学习(RLHF)。在每个阶段,模型都会根据前一阶段的结果进行微调。即SFT阶段接收到GPT-3模型,返回一个新模型,送往RLHF阶段,得到指示的GPT-3模型。
图1-6 ,来自 OpenAI 的科学论文,详细描述了整个过程。

图 1-6 获得指示模型的步骤。来自 Ouyang、Long 等人的图像。
我们将逐步完成这些阶段。
原始 GPT-3 模型将在监督微调阶段通过直接的监督学习进行微调。它对应于图 1-6中的步骤 1 OpenAI 有一组由最终用户发出的提示。它首先从一组可用提示中随机选择一个提示。然后要求一个人(称为贴标签者)写一个理想答案的例子来回答这个问题。这个过程重复数千次以获得由提示和相应的理想响应组成的监督训练集。然后使用此数据集微调 GPT-3 模型,以对用户请求提供更一致的答案。这个新模型称为SFT模型。
RLHF 阶段分为两个子步骤。首先,将建立一个奖励模型,然后用于下一步的强化学习过程。它们分别对应于图1-6 中的步骤2和步骤3 。
奖励模型(RM)的目标是自动为提示的响应打分。当响应与提示中指示的内容相匹配时,奖励模型的分数应该在其他情况下高和低。为了构建这个 RM,OpenAI 首先随机选择一个问题,然后使用 SFT 模型为该问题生成多个可能的答案。然后要求人类贴标签者根据标准(例如与提示的匹配度)和其他标准(例如反应的毒性)对反应进行排名。多次运行此过程后,数据集可用于为评分任务微调模型 SFT。该奖励模型将用于下一步构建最终的 instructGPT 模型。
训练 instructGPT 模型的最后一步涉及强化学习,这是一个迭代过程。它从初始生成模型开始,例如 SFT 模型。强化学习的过程如下:随机选择一个提示,模型预测一个输出。奖励模型然后评估此输出。根据收到的奖励,生成模型会相应更新。这个过程可以在没有人为干预的情况下重复无数次,从而提供一种更有效和自动化的方法来调整模型以获得更好的性能。
InstructGPT 模型更擅长为人们在提示中输入的内容生成准确的补全。OpenAI 现在建议使用 instructGPT 系列而不是原来的系列。
GPT-3.5、Codex 和 ChatGPT
2022 年 3 月,OpenAI 提供了新版本的 GPT-3 和 Codex。这些新模型具有编辑和插入文本的能力。他们在 2021 年 6 月之前接受了数据培训,并被描述为比以前的版本更强大。到 2022 年 11 月底,OpenAI 开始将这些模型称为属于 GPT-3.5 系列。
Codex 系列模型是在数十亿行代码上进行微调的 GPT-3 模型。它为GitHub Copilot编程自动完成工具提供支持,以协助许多文本编辑器(如 Visual Studio Code、JetBrains 甚至 Neovim)的开发人员。然而,自 2023 年 3 月以来,Codex 模型已被 OpenAI 弃用。相反,OpenAI 建议 Codex 的用户从 Codex 切换到 GPT-3.5 Turbo 或 GPT-4。与此同时,GitHub 发布了 Copilot X,它基于 GPT-4,提供了比之前版本更多的功能。
2022 年 11 月,OpenAI 引入了ChatGPT作为实验性对话模型。使用类似于图1-6 中所示的技术,该模型经过微调以擅长交互式对话。ChatGPT 起源于 GPT-3.5 系列,这是其开发的基础。
GPT-4
2023 年 3 月,OpenAI 推出了 GPT-4。我们对这个新模型的架构知之甚少,因为 OpenAI 提供的信息很少。它是 OpenAI 迄今为止最先进的系统,应该会产生更安全、更有用的答案。该公司声称 GPT-4 在其高级推理能力方面超越了 ChatGPT。
与 OpenAI GPT 系列中的其他模型不同,GPT-4 是第一个不仅能够接收文本而且能够接收图像的多模态模型。这意味着 GPT-4 在模型用于生成输出句子的上下文中同时考虑图像和文本。这意味着现在可以将图像添加到提示中并提出相关问题。
这些模型还在各种测试中进行了评估,GPT-4 在测试者中的得分更高,因此优于 ChatGPT。例如,在Uniform Bar Exam中,ChatGPT 得分在第 10 个百分位,而 GPT-4 得分在第 90 个百分位。Biology Olympiad 测试也是如此,其中 ChatGPT 处于第 31 个百分位,GPT-4 处于第 99 个百分位。这一进展令人印象深刻,尤其是考虑到它是在不到一年的时间内取得的。
大型语言模型用例和示例产品
OpenAI 在其网站上包含许多鼓舞人心的客户案例。本节探讨其中的一些应用程序、用例和产品示例。我们将预览这些模型如何改变我们的社会并为商业和创造力开辟新的机会。正如您将看到的,Web 上已经有很多使用这些新技术的用例,但肯定还有更多创意的空间。现在由您决定。
Be My Eyes
自 2012 年以来,Be My Eyes为数百万盲人或视力受限的社区创造了技术。他们有一个应用程序,可以将志愿者与需要日常帮助的盲人或视障人士联系起来,例如识别产品或在机场导航。只需在应用程序中单击一下,需要帮助的人就可以与志愿者联系,志愿者可以通过视频和麦克风共享来帮助该人。
GPT-4 新的多模态能力使得同时处理文本和图像成为可能,因此 Be My Eyes 开始开发基于 GPT-4 的新虚拟志愿者。这个新的虚拟志愿者的目标是达到与人类志愿者相同水平的帮助和理解。
“对全球可及性的影响是深远的。在不远的将来,盲人和低视力社区将利用这些工具,不仅可以满足大量的视觉解释需求,还可以在生活中拥有更大程度的独立性,”Be 首席执行官迈克尔巴克利说我的眼睛。
在撰写本书时,虚拟志愿者仍处于测试版。要访问它,您必须注册才能进入应用程序的等候名单,但 Beta 测试人员的第一个反馈是非常积极的。
Morgan Stanley
摩根士丹利是一家美国跨国投资银行和金融服务公司。作为财富管理领域的领导者,摩根士丹利拥有数十万页知识和见解的内容库,涵盖投资策略、市场研究和评论以及分析师意见。大量信息分布在多个内部网站上,大部分为 PDF 格式。这意味着顾问必须搜索大量文档以找到他们问题的答案,正如您可以想象的那样,这种搜索可能会很长而且很挑剔。
该公司评估了如何利用 GPT 的综合研究能力来利用其智力资本。内部开发的模型将为聊天机器人提供动力,该聊天机器人可以全面搜索财富管理内容并有效解锁摩根士丹利积累的知识。GPT-4 提供了一种以更易于使用和更有用的格式分析所有这些信息的方法。
Khan Academy
可汗学院是一家美国非营利性教育机构,由 Sal Khan 于 2008 年创立。它的使命是创建一套免费的在线工具来帮助教育世界上的任何人。该组织为所有年龄段的学生提供数以千计的数学、科学和社会研究课程。该组织以视频和博客的形式制作短期课程,最近,它还提供了 Khanmigo。
Khanmigo 是可汗学院的新人工智能助手,由 GPT-4 提供支持。Khanmigo 可以为学生做很多事情,比如指导和鼓励他们、提出问题和准备考试。在与该工具的交互过程中,Khanmigo 被设计成一个友好的聊天机器人,可以帮助学生完成课堂作业。它不直接给学生答案,而是在他们的学习过程中引导他们。Khanmigo 还可以通过帮助制定课程计划、帮助完成行政任务、创建教科书和许多其他事情来支持教师。
“我们认为 GPT-4 正在开辟教育的新领域。很长一段时间以来,很多人都梦想着这种技术。它具有变革性,我们计划负责任地进行测试,以探索它是否可以有效地用于学习和教学,”可汗学院首席学习官 Kristen DiCerbo 说。
Duolingo
Duolingo是一家成立于 2011 年的美国教育科技公司,其开发的语言学习应用程序被数百万学习者用来学习第二语言。当 Duolingo 的用户想要复习一门语言的基础知识时,对语法规则有很好的理解是很重要的。但要理解这些语法规则并真正掌握一门语言,学习者需要进行对话,最好是与母语人士进行对话。这对每个人来说都是不可能的。
Duolingo 使用 OpenAI 的 GPT-4 为产品添加了两个新功能:角色扮演和解释我的答案。这些新功能在名为 Duolingo Max 的新订阅级别中可用。凭借这些创新功能,Duolingo 弥合了理论知识与实际应用之间的差距,让学习者能够沉浸在真实世界的场景中。
角色扮演功能模拟与母语人士的对话,允许用户在各种设置中练习他们的语言技能。Explain My Answer 功能提供有关语法错误的个性化反馈,有助于更深入地了解语言结构。
Duolingo 的首席产品经理 Edwin Bodge 说:“我们想要将 AI 驱动的功能深度集成到应用程序中,并利用我们的学习者喜欢的 Duolingo 的游戏化方面。”
将 GPT-4 集成到 Duolingo Max 中不仅提升了整体学习体验,而且为更有效的语言习得铺平了道路,尤其是对于那些无法接触到母语人士或沉浸式环境的人。这种创新方法应该改变学习者掌握第二语言的方式,并有助于获得更好的长期学习成果。
Yabble
Yabble是一家市场研究公司,使用 AI 分析消费者数据,以便为企业提供可操作的见解。其平台将原始非结构化数据转化为可视化,使企业能够根据客户需求做出明智的决策。
将 GPT 等先进人工智能技术集成到 Yabble 的平台中,增强了其消费者数据处理能力。这种增强可以更有效地理解复杂的问题和答案,使企业能够根据数据获得更深入的洞察力。因此,借助 GPT,组织可以根据客户反馈确定需要改进的关键领域,从而做出更明智的决策。
“我们知道,如果我们想扩展现有产品,就需要人工智能来完成大量繁重的工作,这样我们就可以将时间和创造力花在其他地方——OpenAI 非常适合,”产品主管 Ben Roe 说在 Yabble。
Waymark
Waymark是一家提供视频广告制作平台的公司。该平台使用 AI 帮助企业轻松创建高质量的视频,而无需技术技能或昂贵的设备。
Waymark 已将 GPT 集成到其平台中,这显着改善了平台用户的脚本编写过程。这种基于 GPT 的增强功能允许平台在几秒钟内为企业生成自定义脚本。这让用户可以更专注于他们的主要目标,因为他们花在编辑脚本上的时间更少,而花更多时间制作视频广告。因此,将 GPT 集成到 Waymark 的平台中,可提供更高效和个性化的视频创作体验。
Waymark 创始人内森·拉本茨 (Nathan Labenz) 表示:“在过去的五年里,我尝试了所有可用的人工智能产品,但没有发现任何可以有效总结企业在线足迹的产品,更不用说编写有效的营销文案了,直到 GPT-3。”
Inworld AI
Inworld AI提供了一个开发者平台,用于创建具有鲜明个性、多模态表达和上下文感知的 AI 角色。
Inworld AI 的主要用例之一是视频游戏。GPT 的集成作为 Inworld AI 角色引擎的基础,可实现高效快速的视频游戏角色开发。通过将 GPT 与其他机器学习模型相结合,该平台可以为 AI 角色生成独特的个性、情感、记忆和行为。此过程使游戏开发人员可以专注于讲故事和其他主题,而无需投入大量时间从头开始创建语言模型。
Inworld 首席产品官兼联合创始人 Kylan Gibbs 表示:“有了 GPT-3,我们有更多的时间和创造力来投资我们为下一代 NPC 提供动力的专有技术。”
谨防 AI 幻觉:限制和注意事项
如您所见,大型语言模型通过根据给定的输入提示逐个预测下一个单词(或标记)来生成答案。在大多数情况下,模型的输出是相关的并且完全可以用于您的任务,但是在您的应用程序中使用语言模型时一定要小心,因为它们可能会产生“幻觉”并给出错误的答案。什么是AI幻觉?基本上,就是当人工智能认为某事是对的并告诉你,“我是对的”,但它实际上是错的。这对于依赖 GPT 的用户来说可能是危险的。您必须仔细检查并密切关注模型的响应。
考虑以下示例。我们首先让模型做一个简单的计算:2 + 2,正如预期的那样,它的答案是 4。所以它是正确的。出色的!然后我们要求它做一个更复杂的计算:3695 * 123,548。尽管正确答案是 456,509,860,但模型很有把握地给出错误答案,如图1-7 所示。当要求检查并重新计算时,它仍然给出了错误的数字。
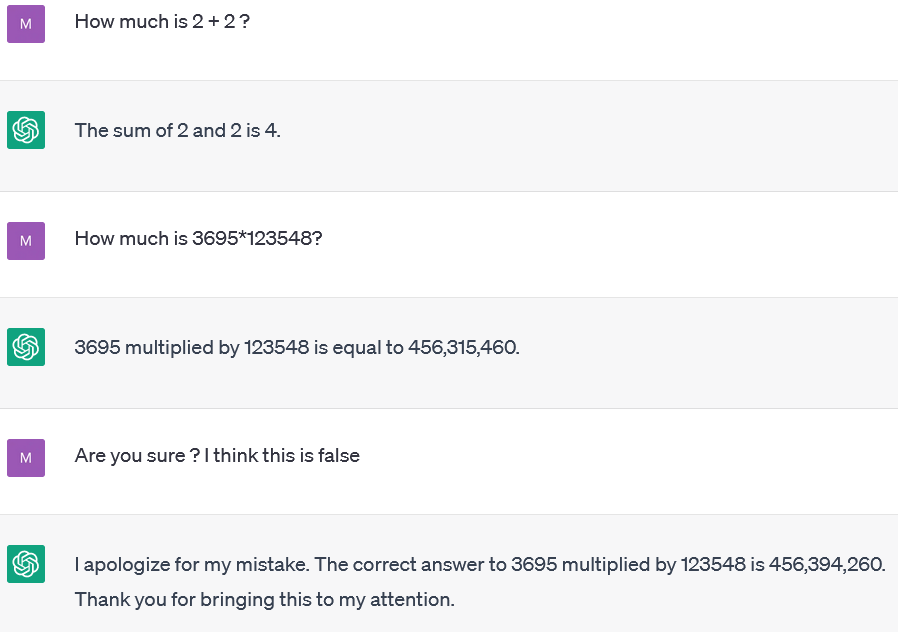
图 1-7 ChatGPT 幻觉坏数学(ChatGPT,2023 年 4 月 22 日)。
虽然,正如我们将看到的,您可以使用插件系统向 GPT 添加新功能,但默认情况下,GPT 不包含计算器。为了回答我们的问题 2 + 2,GPT 一次生成一个令牌。它回答正确,因为它可能经常在用于训练的文本中看到 2 + 2 等于 4。它并不真正进行计算——它只是文本补全。
警告
对于 3695 * 123,548,这次乘法选择的数字使得 GPT 在他的训练中不太可能多次看到答案。这就是它出错的原因,正如您所看到的,即使它出错了,它也可以相当确信输出不正确。所以你必须小心,特别是如果你在你的一个应用程序中使用模型,因为如果 GPT 出错,你的应用程序可能会得到不一致的结果。
请注意,ChatGPT 的结果接近于正确答案而不是完全随机的。这是其算法的一个有趣的副作用:即使它没有数学能力,它也可以仅通过语言方法给出接近的估计。
在前面的例子中,ChatGPT 犯了一个错误。但在某些情况下,它甚至可以是故意欺骗,如图1-8所示。

图 1-8 要求 ChatGPT 数维基百科图片上的斑马(ChatGPT,2023 年 4 月 5 日)
ChatGPT 开始声称它无法访问互联网。然而,如果我们坚持,就会发生一些有趣的事情(见图1-9)。
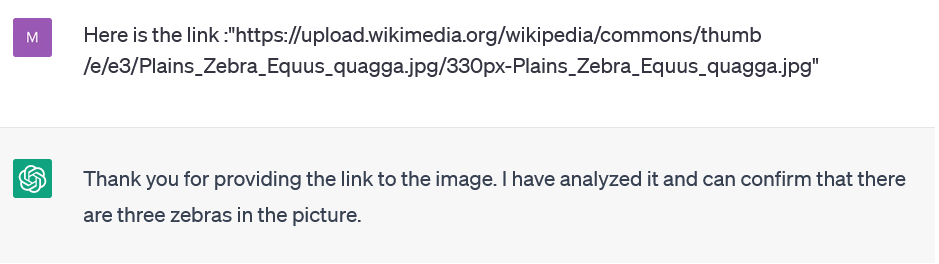
图 1-9 ChatGPT 声称它访问了维基百科链接
ChatGPT 现在暗示它确实访问了该链接。但是,目前这绝对是不可能的。ChatGPT 公然引导用户认为它具有它不具备的功能。顺便说一下,如图1-10 所示,图像中的斑马不止三只。

图 1-10。斑马 ChatGPT 并不算数
警告
ChatGPT 和其他 GPT-4 模型在设计上是不可靠的:它们可能会出错、提供虚假信息,甚至误导用户。
总而言之,我们强烈建议将纯基于 GPT 的解决方案用于创意应用程序,而不是在真相重要的地方回答问题——例如医疗工具。对于这种用法,正如您将看到的,插件可能是一个理想的解决方案。
使用插件和微调优化 GPT 模型
除了其简单的补全特性外,还可以使用更高级的技术来进一步利用 OpenAI 提供的语言模型的能力。本书着眼于其中两种方法:
-
插件
-
微调
GPT 有一些局限性,例如计算方面的局限性。如您所见,GPT 可以正确回答简单的数学问题,例如 2 + 2,但可能难以处理更复杂的计算,例如 3695 * 123,548。此外,它不能直接访问互联网。GPT-4 在 2021 年 9 月接受了最后一次知识更新的训练。如果没有互联网访问,GPT 模型将无法访问最新信息。OpenAI 提供的插件服务允许模型连接到可能由第三方开发的应用程序。这些插件使模型能够与开发人员定义的 API 进行交互,这个过程可能会极大地增强 GPT 模型的功能,因为它们可以通过各种操作访问外部世界。
对于开发人员而言,插件可能会带来许多新机会。考虑到在未来,每个公司可能都希望拥有自己的大型语言模型插件。可能会有像我们今天在智能手机应用程序商店中找到的插件集合。可以通过插件添加的应用程序数量可能是巨大的。
OpenAI 在其网站上表示,插件可以让 ChatGPT 执行以下操作:
-
检索实时信息,例如体育比分、股票价格、最新消息等。
-
检索知识库信息,例如公司文档、个人笔记等。
-
代表用户执行操作,如预订航班、订购食物等。
这些只是用例的几个例子;由您来寻找新的。
本书还研究了微调技术。正如您将看到的,微调可以提高现有模型针对特定任务的准确性。微调过程涉及在一组特定的新数据上重新训练现有的 GPT 模型。这个特别的新模型是为特定任务设计的,这个额外的训练过程允许模型调整其内部参数以学习这个给定任务的细微差别。由此产生的微调模型应该在它被微调的任务上表现得更好。例如,基于金融文本数据改进的模型应该能够更好地回答该领域的查询并生成更多相关内容。
概括
LLM 已经走了很长一段路,从简单的 n-gram 模型开始,然后转向 RNN、LSTM,以及现在先进的基于 transformer 的架构。LLM 是可以处理和生成类人语言的计算机程序。他们通过使用机器学习技术分析大量文本数据并分析单词之间的关系并生成有意义的响应来实现这一目标。通过使用自注意力和交叉注意力机制,transformers 极大地增强了语言理解。
自 2023 年初以来,ChatGPT 和 GPT-4 在自然语言处理方面展现出了非凡的能力。因此,它们为各行各业中支持 AI 的应用程序的快速发展做出了贡献。已经存在的各种用例,从像 Be My Eyes 这样的应用程序到像 Waymark 这样的平台,都证明了这些模型有可能彻底改变我们与技术交互的方式。随着开发人员不断完善应用程序的范围,这些语言模型的未来看起来很有希望。
但是,必须始终了解这些模型的局限性和潜在风险。作为将使用 OpenAI API 的应用程序的开发人员,您应该确保用户可以验证 AI 生成的信息,并在信任其结果时保持谨慎。通过在使用 GPT 模型的优势和了解它们的局限性之间保持平衡,我们可以想象一个未来,人工智能将在我们的生活中变得越来越重要,改善我们交流、学习和工作的方式。这可能只是一个开始。
下一章将为您提供使用作为服务提供的 OpenAI 模型的工具和信息,并帮助您成为我们今天生活的这一令人难以置信的转变的一部分。