前言
在chatGPT如火如荼的时候,OpenAI又上演了王者归来的戏码,重磅发布了GPT-4。GPT-4是作为“帮你写代码”和你“肆意聊天”的chatGPT的基础模型GPT-3的升级版,是一个新的里程碑。
GPT-4 是一个大型多模态模型,虽然很多能力还不能达到人类水平,但是某些专业和学术领域的表现已经可以媲美人类高水平了。
GPT-4 是 OpenAI 花了 6 个月的时间,利用对抗性测试程序和 ChatGPT 中积累的经验迭代调整,模型尽管远非完美,但该模型“比以往任何时候都更具创造性和协作性”,并且“可以更准确地解决难题”。
本文主要内容参考自官方Blog和技术报告,具体参考:
官方 Blog 地址:GPT-4
https://openai.com/research/gpt-4
官方 ChatGPT Plus 体验地址
https://chat.openai.com/auth/login?next=/chat
官方技术报告地址
https://cdn.openai.com/papers/gpt-4.pdf
官方视频案例地址
https://www.youtube.com/live/outcGtbnMuQ?feature=share
GPT-4官宣
3 月 14 日晚间,OpenAI 宣布发布 GPT-4。
OpenAI 联合创始人 Sam Altman 表示,它是“迄今为止功能最强大、最一致的模型”,能够使用图像和文本。
OpenAI表示在过去两年里,他们重构了整个深度学习堆栈,并与Azure合作,共同设计了一台超级计算机。一年前,OpenAI训练了GPT-3.5,作为整个系统的首次 "试运行",具体来说,我们发现并修复了一些错误,并改进了之前的理论基础。因此,我们的GPT-4训练、运行空前稳定,成为我们首个训练性能可以进行提前准确预测的大模型。随着我们继续专注于可靠扩展,以帮助OpenAI能够持续提前预测未来,并且为未来做好准备,我们认为这一点,对安全至关重要。
在油管的视频演示中,我们可以看到GPT-4 可以总结文章、写代码、报税、写诗、写网页,十八般武艺样样精通的模样让人震撼。
大模型与多模态
GPT-4这次发布的一大亮点就是不仅能理解文字,还能识别图片内容、看得懂图梗,让人不禁拍案叫绝。至于为什么能识别图片内容,还能进行理解和推理,就得聊聊多模态。
多模态:简单来说,就是指模型可以处理多种结构/类型的数据,可接收多种类型的数据源,例如GPT-4,它既可以处理你输入的文本,也可以处理你上传的图片。

大模型:大模型又被称作基础模型,最大的特点是大规模,参数量大,数据集庞大,多架构框架复杂,训练机器和维护的成本都很高。
大模型现今的参数量级应该能到千亿级别的,例如GPT,从GPT-1到GPT-3,模型的参数量从1.1亿个增长到了1750亿个,几年的时间内增长了一千多倍。

参数量级爆炸式的增长的根因在于Transformer网络提出后,研究人员惊讶地发现,模型参数量的不断提升,会让模型的能力持续提高。于是在人们偏执地笃信下模型中加入越来越多的参数,导致模型规模屡创新高,甚至于参数在底层模型中的意义具体是什么也无法得知,模型准确率提升也依赖于后期的参数的不断调优,被戏称为调参工作。
大模型的另一个特点——“无监督预训练”。大模型参数量大、结构大,还需要大量的数据集进行训练,而对如此庞大的数据进行人工标注显然是困难的。因此,针对大模型的特性,往往会采用“无监督预训练”(亦称“自监督学习”)模式,可以让模型在海量数据中自行学习,无需人类干预,这让模型可以快速地在训练中成长,提高了训练效率。在预训练后,还会对大模型进行RLHF(人类反馈强化学习),在这个阶段则引入了大量的人工校准,通过数据标注等方式帮助模型进化,进一步提升模型的推理能力。
GPT-4能力
在这一环节我们将见证GPT-4的强大,在专业考试、图像理解、漫画理解等方面的强大之处。同时GPT-4的强大也有些微妙之处,在简单闲聊时,也许不容易发现GPT-3.5和GPT-4之间的区别。但当任务复杂度达到一定阈值时,GPT-4的可靠,创造力和强大的理解能力就突出出来了。
下面我们就来看下在各种不同的基准上的测试结果,包括模拟最开始那些为人类设计的考试,通过使用最新的公开测试(就奥数和AP等等考试)还包括购买2022-2023年版的练习考试来进行,OpenAI官方表示他们并没有为这类考试给模型做专门的培训,但考试中小部门的问题会在模型训练过程中存在的,但他们认为下列结果是有代表性的。
模拟考试
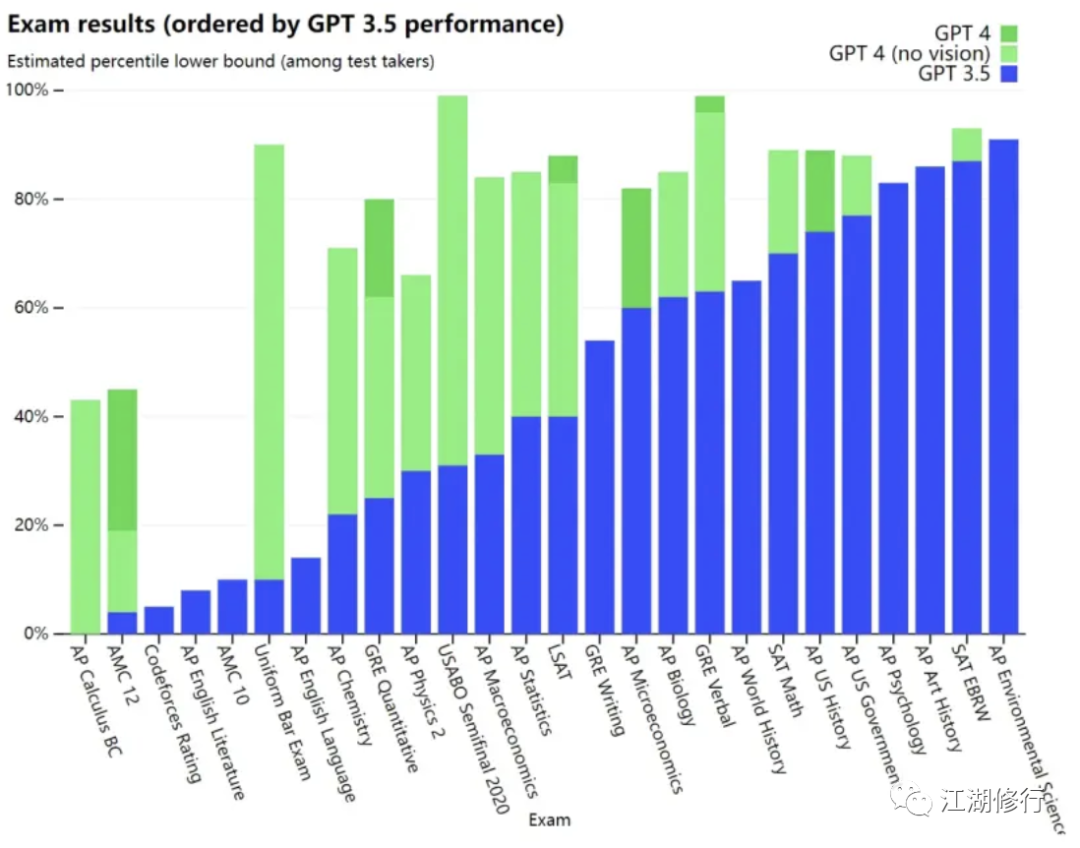
传统基准测试
GPT-4大大超过现有的大语言模型,与多数最先进的(SOTA)模型并驾齐驱,详细指标如下:

多语言能力
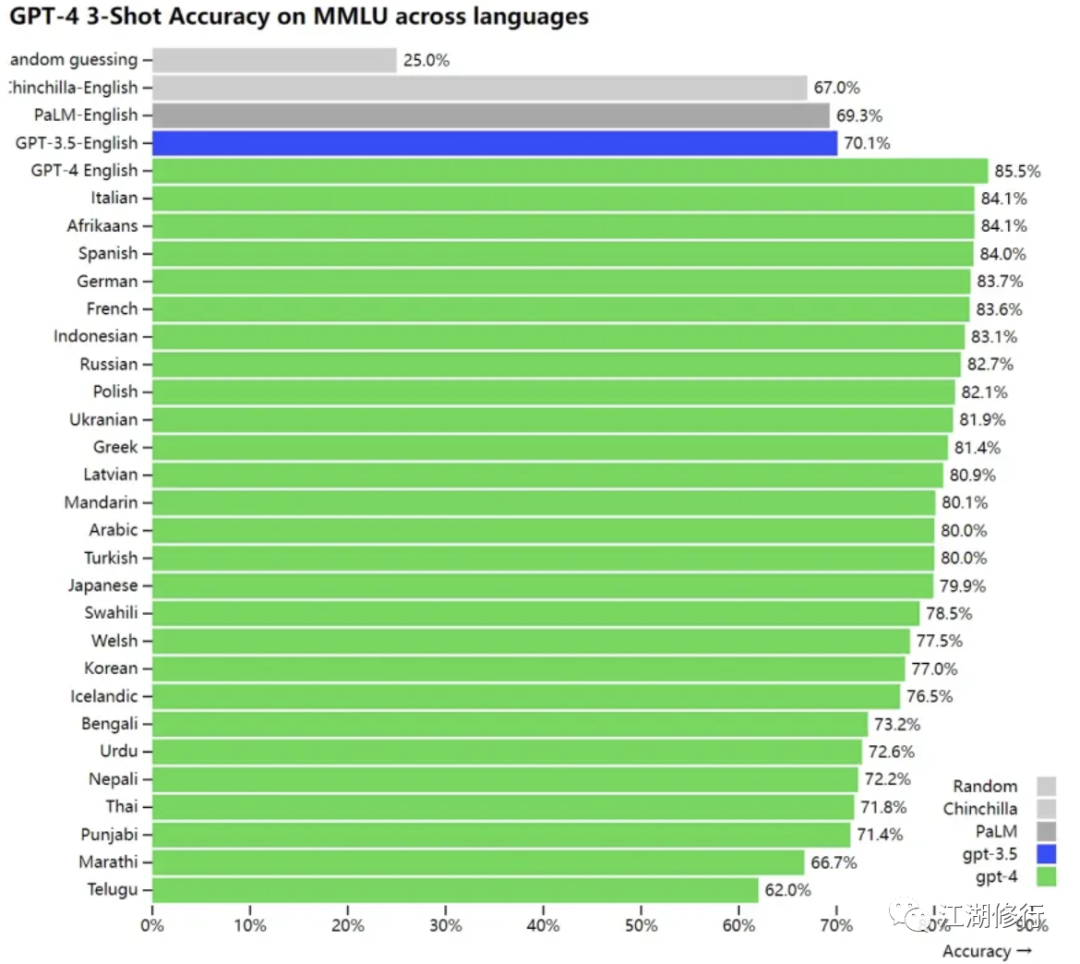
由于现有的大多数ML基准是用英语编写的,为了初步了解其他语言的能力,我们使用Azure Translate将MMLU基准:一套涵盖57个主题的14000个选择题,翻译成了各种语言。在测试的26种语言中的24种语言中,GPT-4的表现优于GPT-3.5和其他大模型(Chinchilla,PaLM)的英语表现,这种优秀表现还包括类似拉脱维亚语、威尔士语和斯瓦希里语等等。
视觉理解
GPT-4 可以接受文本和图像输入,允许用户指定任何视觉或语言任务,包括带有文本和照片的文档、图表或屏幕截图等,GPT-4 展示了与纯文本输入类似的功能,生成文本输出。官网提到了还可以通过为纯文本语言模型开发的测试技术(包括 few-shot 和 prompt)来增强。图像输入仍然是处于研究阶段没有公开,我们来看下几个官方的案例:
能理解图中的梗

理解法语题目,并完整解答

看纸质论文总结摘要


看懂漫画

局限性
尽管能力惊人,不过幻觉、推理错误等问题在GPT-4上仍存在。但与早期的GPT 模型相比,经过多轮的迭代和优化已显著减少幻觉问题的产生,在 OpenAI 的内部对抗性真实性评估中,GPT-4 的得分比最新的 GPT-3.5 模型高 40%,如下图所示(绿色代表GPT-4):

GPT-4 在 TruthfulQA 等外部基准测试方面也取得了进展,OpenAI 测试了模型将事实与错误陈述的对抗性选择区分开的能力,结果如下图所示:

实验结果表明:GPT-4 基础模型在此任务上比GPT-3.5略好,但经过 RLHF 后训练之后,GPT4 效果更显著。
GPT-4 数据集还是2021 年 9 月的,所以其对之后发生的事件了解有限,也不会从其经验中学习。它有时会犯一些简单的推理错误,这似乎与这么多领域的能力不相符,或者过于轻信用户的明显虚假陈述。有时它也会像人类一样在困难的问题上失败,比如在它生成的代码中引入安全漏洞。
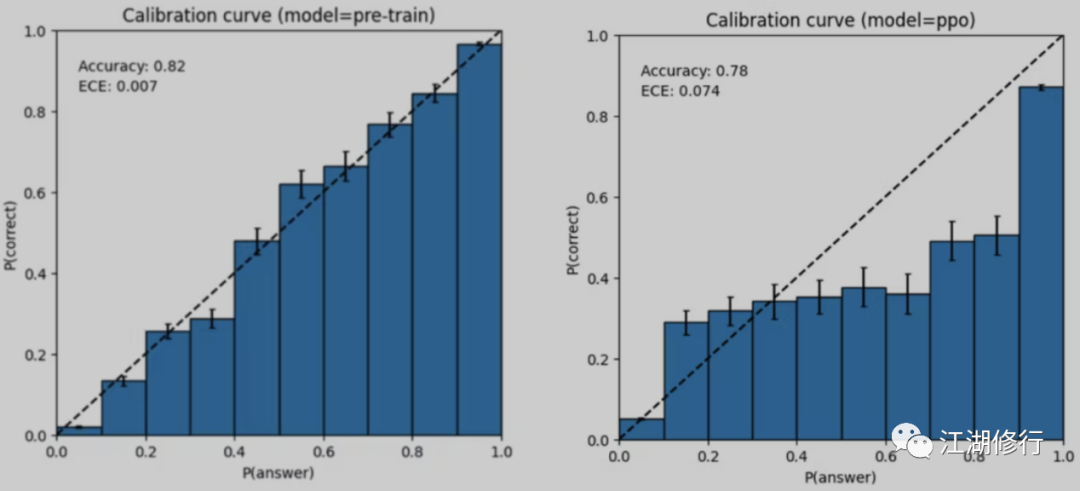
GPT-4 预测出错时依然很自信,在可能出错时也不会再次确认。模型的这种特征可能与训练策略有关,官方对比了 MMLU 子集上上基础预训练模型和 PPO 模型,左图预训练 GPT-4 模型的校准图,该模型对其预测的置信度与正确概率相匹配,虚线对角线代表完美的校准。右图训练后 PPO GPT-4 模型的校准图,训练后对校准造成很大的影响。
风险及缓解措施
GPT-4 引入的图片识别等新能力方面也带来了新的隐藏风险,为了了解这些风险的程度,团队聘请了 50 多位来自人工智能安全、网络安全、生物风险、信任和安全以及国际安全等领域的专家,对该模型在高风险领域的行为进行对抗性测试。这些领域需要专业知识来评估,来自这些专家的反馈和数据为缓解措施和模型的改进提供了依据。
GPT-4 在 RLHF 训练中加入了一个额外的安全奖励信号,通过训练模型拒绝对此类内容的请求来减少有害的输出。奖励模型是 GPT-4 零样本分类器,根据安全相关提示判断安全边界和完成方式。为了防止模型拒绝有效的请求,团队从各种来源(例如,标注的生产数据、人类的红队、模型生成的 prompt)收集多样化的数据集,在允许和不允许的类别上应用安全奖励信号(有正值或负值)。
这些措施大大在许多方面改善了 GPT-4 的安全性能。与 GPT-3.5 相比,模型对不允许内容的请求的响应倾向降低了 82%,并对敏感内容请求的符合安全监管提高了 29% 。

训练过程
官方资料没有讲模型参数和数据规模,没有讲任何技术原理。简单讲了一下 GPT-4 基础模型与 GPT 系列模型一致,GPT-4基础模型的训练是为了预测文档中的下一个单词,并使用公开可用的数据(例如互联网数据)以及我们已获得许可的数据进行训练。这些数据是来自于极大规模的语料库,包括数学问题的正确和错误的解决方案,弱的和强的推理,自相矛盾的和一致的声明,以及种类繁多的意识形态和想法。模型的能力主要来自预训练过程,RLHF 不会提高模型测试的考试成绩,有时实际上会降低考试成绩。模型一些意图对齐及风格转变等来自于 RLHF 和工程设计。
可预测扩展的深度学习栈
GPT-4项目的一大重点是建立一个可预测扩展的深度学习栈。主要原因是对于像GPT-4这样非常大的训练模型,做大量的特定模型调整是不可行的。OpenAI开发团队对基础设施进行了开发和优化,在多种规模下都有非常可预测的行为。为了验证这种可扩展性,通过使用相同的方法训练的模型进行推断,提前准确地预测了GPT-4在我们内部代码库(不属于训练集)中的最终损失,但使用的计算量要少10000倍:

准确预测未来的机器学习能力是安全的一个重要部分,让人们了解对未来系统的期望,这应该成为领域的一个共同目标。
总结
这一次OpenAI对GPT-4的公开内容并未涉及模型参数、数据集、技术原理等核心部分,仅公开了评测结果,识图能力的演示和一些优化后的数据,总体来讲并不是很open。但GPT-4在多模态上的惊艳表现,识图能力,更具创造性和逻辑性的回答又实实在在地圈了一波粉。GPT-4在智能方面的大幅能力跃迁也是让人眼前一亮,在某些专业领域的能力已达到人类高水平表现,比如托福考试,奥赛等。当然还有10秒内造出一个网站,60秒内完成一个游戏开发的神作。
GPT-4发布的时间点也比较有意思,正好是百度文心一言的发布会前夕,不知是否是刻意为之,但文心一言的一个立足点是最理解汉语的大模型,让我们对文心一言的能力拭目以待。
最后我还想问各位老板和开发者,GPT-4产出的代码我们是否还关心是高质量代码呢,还是只关心它的产出效率???
微信公众号首发,欢迎关注:江湖修行。第一时间与本人技术交流。







