背景
随着chatgpt的爆火,各种开源大模型以及聊天机器人开始涌现。最近公司也想训练一个具有公司业务特色的聊天机器人,类似一个客服的角色。本人是一个java开发,对python也不是很懂,顺便把这几天的摸索的心得记录下来,如有不对或者可以改进的地方,欢迎评论指出。
方案选型
首先,在众多的开源大模型里面我们选择了口碑较好,下载量和排名都靠前的vicuna。vicuna是一个可以自己训练的开源模型,关于它的搭建,比较推荐知乎上大模型也内卷,Vicuna训练及推理指南,效果碾压斯坦福羊驼这篇文章,按照这片文章一步一步来可以搭建起来。值得注意的是,如果要训练,一定要买英伟达A100 80G的显卡,如果是单卡的话,基于7B模型来训练的话,CPU内存要大于170G,同时采用文章中提到的offload的方式将训练数据保存在CPU内存。我是在阿里云上购买按时收费的A100实例,大概150元一个小时,最后通过dummy.json的方式微调模型,训练出来自己的业务模型,又将模型导出放到英伟达T4的机器上去运行。
vicuna这个方案确实可以训练出自己的模型并运行自己的业务聊天机器人。可能自己对机器学习这块涉及较少,训练出来的模型总是出现过拟合的情况。回答dummy.json内相关的问题还是很不错的,但是如果是跟这个json文件不相关的问题,它的回答也是文件内的答案。
这让人很头疼!
经过一番调研,最终决定用chatgpt-3.5的API来搭建。查了很多资料后,利用比较方便的langchain+gpt的方式能快速搭建一个自己的业务机器人,对于我这种python小白来说,还是很友好的,相关的博客、帖子也都挺多的。
环境介绍
1、本地windows环境搭建
操作系统:win11 64位
python版本:3.11.4
llama_index版本:0.5.27
langchain版本:0.0.216
一个可以使用的chatgpt的OPENAI_API_KEY
网络要求:能够访问外网的VPN(这里就各显神通了)
安装Python
首先就是要安装python,这个我在python官网直接下载的
打开python官网:Welcome to Python.org ,点击 “Download”下载最新python版本。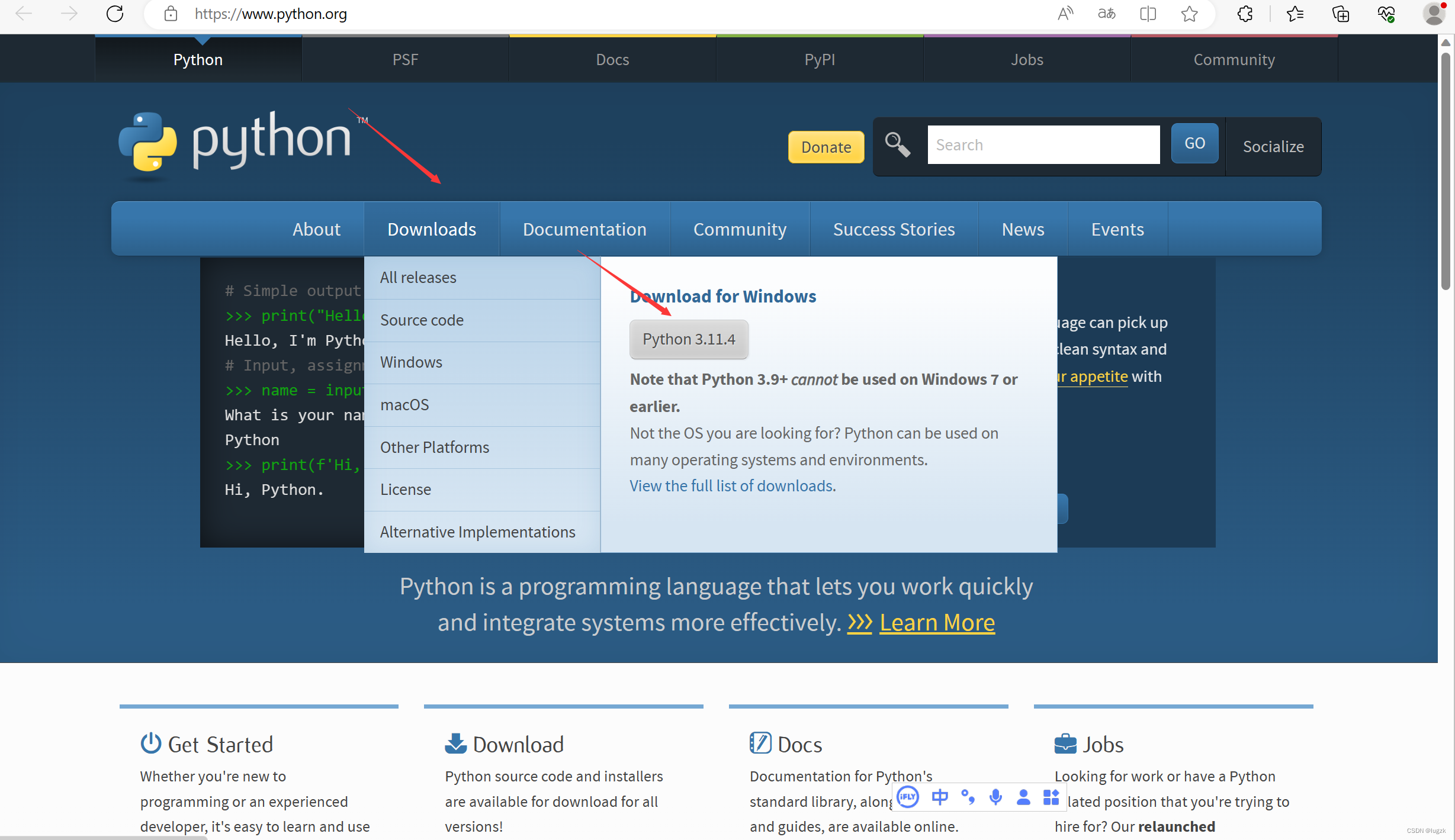
下载完成后自动弹出安装界面,我们直接选择lnstall Now安装路径,在安装时务必先把下方两个对勾打上。
此时要注意默认安装路径在哪个位置!好在后面环境配置做好准备工作。

然后一直下一步,关于python的安装环境这里不再累述。
安装好python后 打开windows的cmd终端,输入python --version,出现如下显示说明环境变量也配好了。
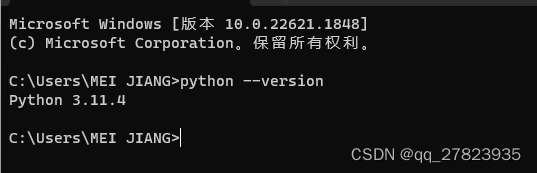
python装好后可能会遇到openssl相关的问题,这里要求安装了openssl1.1以上,可以百度一下。
开始搭建
那么接下来,咱们就开始安装搭建聊天机器人的必要模块。
主要用到了两个python模块 llama_index 和langchain
用pip安装这些模块选的是阿里云的镜像源,关于pip配置永久配置阿里云源的方法百度上很多,我这里用以下命令临时指定安装即可:
pip install llama_index==0.5.27 -i http://mirrors.aliyun.com/pypi/simple/ pip install langchain==0.0.216 -i http://mirrors.aliyun.com/pypi/simple/ 这两个安装好后其实基本上就可以了。我在本地电脑F盘新建了一个ai文件夹,用来存放python代码,然后在ai文件夹内新建app.py文件和docs文件夹。app.py文件为python脚本文件,实现调用langchain模块,并学习在docs文件夹下txt文件的知识。这里docs中txt文件的内容是今天的热搜新闻《女子不穿内裤试衣隔天要求退换遭拒》
app.py的文件内容如下:
from llama_index import SimpleDirectoryReader, GPTVectorStoreIndex, ServiceContext, LLMPredictor, PromptHelper, download_loader, StorageContext, load_index_from_storage
from langchain import OpenAI
import gradio as gr
import sys
import os# 设置工作文件路径
os.chdir(r'F:\ai') #设置全局变量 OPENAI_API_KEY,从openAI管理后台获取
os.environ["OPENAI_API_KEY"] = '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'index_file = "index.json"### step1:读取内容文件 ######
def read_documents():documents = SimpleDirectoryReader('docs').load_data() return documents### step2: 构建索引 #######
def construct_index(refresh_index = False):max_input_size = 4096num_outputs = 2000max_chunk_overlap = 1.0chunk_size_limit = 600#prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)#定义一个 LLM 模板llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.7, model_name="gpt-3.5-turbo", max_tokens=2048))#配置 service 上下文service_context = ServiceContext.from_defaults(llm_predictor = llm_predictor)# 如果本地磁盘上有已经构建的索引 优先用本地索引persist_dir="index_dir"persist_file = persist_dir + "/vector_store.json"if not refresh_index and os.path.exists(persist_file):storage_context = StorageContext.from_defaults(persist_dir=persist_dir)index = load_index_from_storage(storage_context, service_context=service_context)else:#获取文档知识documents = read_documents()#build indexindex = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)# save index to diskindex.storage_context.persist(persist_dir=persist_dir)return index### step3: 查询索引 #########
def query_index(query_str):#获取索引文件index = construct_index()#查询引擎query_engine = index.as_query_engine()#查询问题response = query_engine.query(query_str)print(response)return responsequery_index("女子不穿内裤试衣隔天要求退换遭拒");然后运行python app.py后,打印出来gpt的回答如下:

我们将问题改成“请用中文简单介绍下女子不穿内裤试衣事情来龙去脉”,下面是回答结果:

看上去总结的还不错。到这里基本上就已经实现了将自己的专业知识灌输给chatGPT,来搭建自己的聊天机器人了。事实上我们的数据信息一般都不是txt文件的,而是存放在数据库的。当然llama_index提供的远不止文本连接器,还有很多的数据格式的解析器,包括PDF文件,PPT文件,具体可以在llamaHub上来找自己需要的连接器Llama Hub (llama-hub-ui.vercel.app)
因为我们公司的业务数据都是存在MySQL里的,所以我在这里使用了database连接器。读取了员工信息表的内容
# 从数据库读取文档信息方法
def _read_documents_from_db():DatabaseReader = download_loader('DatabaseReader')reader = DatabaseReader(scheme = "mysql",host = "rm-uf687684hm5oaouhgmo.mysql.rds.aliyuncs.com",port = "3306",user ="*****",password = "**********",dbname = "gpt-ai",)query = f"""select CONCAT('姓名:', name,' 工号:',jobnumber, ' 手机号:', mobile, ' 职位:', position, ' 部门:
', department_name, ' 入职时间:', left(hired_date, 10)) as text from om_org_employee where flag = 1 """documents = reader.load_data(query=query)return documents特别提醒:用数据库连接的方式要特别注意数据泄露的可能性,虽然chatgpt协议里说调用API不会存储用来训练,在官网页面提问的会,还是自己决定吧。
然后为了能在页面上用交互的方式提问,我又引入了gradio组件,这个家伙相当方便,提供了各种自定义样式的输入和输出格式,还生成了一个可供别人在线访问的临时url。核心就是将我们的提问chatgpt的方法作为一个回调函数,然后将返回结果显示在页面的输出。
### 使用gradio页面模板嵌入查询引擎
iface = gr.Interface(fn=query_index,inputs=[gr.Textbox(lines=7, label="请输入您的问题")],outputs=gr.Textbox(lines=7, label="这是我的回答"),title="有家GPT",description="<h3>我会将我知道的都告诉你</h3>")iface.launch(share=True, server_port=9090,auth=("admin", "123456"))改进后的app.py全部代码如下,里面的注释写的很清晰,在第一次学习到知识生成索引文件和启动后提问都是会消耗chatgpt的token的,所以在学习知识后我把索引文件存在本地,后续运行时候如果本地有索引文件,就不需要重新生成,可以直接读取。但是如果想学习新的知识,需要删除本地的索引文件,或者更改app.py里的代码。
from llama_index import SimpleDirectoryReader, GPTVectorStoreIndex, ServiceContext, LLMPredictor, PromptHelper, download_loader, StorageContext, load_index_from_storage
from langchain import OpenAI
import gradio as gr
import sys
import os# 指定工作目录
os.chdir(r'/amo')# 定义全局变量 OPENAI_API_KEY
os.environ["OPENAI_API_KEY"] = '这里填你从chatgpt后台拿到的key'index_file = "index.json"# 从数据库读取文档信息方法
def _read_documents_from_db():DatabaseReader = download_loader('DatabaseReader')reader = DatabaseReader(scheme = "mysql",host = "rm-uf687684hm5oaouhgmo.mysql.rds.aliyuncs.com",port = "3306",user ="*****",password = "*********",dbname = "gpt-ai",)query = f"""select CONCAT('姓名:', name,' 工号:',jobnumber, ' 手机号:', mobile, ' 职位:', position, ' 部门:', department_name, ' 入职时间:', left(hired_date, 10)) as text from om_org_employee where flag = 1 """documents = reader.load_data(query=query)return documents### step1:读取内容文件 ######
def read_documents(read_source = 'docs'):if read_source == 'database':documents = _read_documents_from_db()else:documents = SimpleDirectoryReader('docs').load_data() return documents### step2: 构建索引 #######
def construct_index(refresh_index = False):max_input_size = 4096num_outputs = 2000max_chunk_overlap = 1.0chunk_size_limit = 600#prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)#定义一个 LLM 模板llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.8, model_name="gpt-3.5-turbo-0613", max_tokens=2048))#配置 service 上下文service_context = ServiceContext.from_defaults(llm_predictor = llm_predictor)# 如果本地磁盘上有已经构建的索引 优先用本地索引persist_dir="index_dir"persist_file = persist_dir + "/vector_store.json"if not refresh_index and os.path.exists(persist_file):storage_context = StorageContext.from_defaults(persist_dir=persist_dir)index = load_index_from_storage(storage_context, service_context=service_context)else:#获取文档知识documents = read_documents(read_source = 'database')#build indexindex = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)# save index to diskindex.storage_context.persist(persist_dir=persist_dir)return index### step3: 查询索引 #########
def query_index(query_str):#获取索引文件index = construct_index()#查询引擎query_engine = index.as_query_engine()#查询问题response = query_engine.query(query_str)print(response)return response### step4: 使用gradio页面模板嵌入查询引擎
iface = gr.Interface(fn=query_index,inputs=[gr.Textbox(lines=7, label="请输入您的问题")],outputs=gr.Textbox(lines=7, label="这是我的回答"),title="有家GPT",description="<h3>我会将我知道的都告诉你</h3>")iface.launch(share=True, server_port=9090,auth=("admin", "123456"))好了,我们再次运行 python app.py
 这里提示本地url已经生成了,但是share link(可以给别人在线访问的临时url)没有生成,这个是因为我本地windows环境的原因,在linux系统上不会有问题的。我们先用127.0.0.1:9090来访问,输入账号admin 密码123456
这里提示本地url已经生成了,但是share link(可以给别人在线访问的临时url)没有生成,这个是因为我本地windows环境的原因,在linux系统上不会有问题的。我们先用127.0.0.1:9090来访问,输入账号admin 密码123456

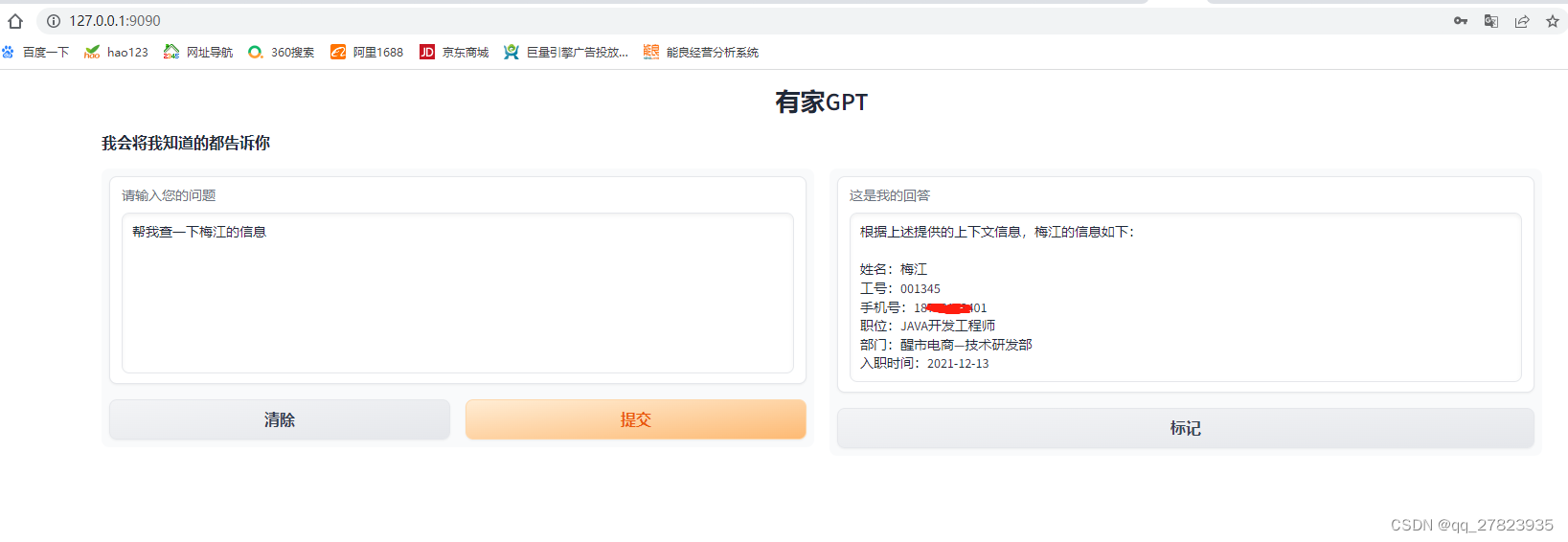 完美!已成功在本地windows系统上搭建自己的业务聊天机器人。
完美!已成功在本地windows系统上搭建自己的业务聊天机器人。
linux服务器搭建
为了减少在服务器上翻墙的麻烦,特意买了一台临时的阿里云ECS海外服务器。
搭建和windows基本一样,先安装python3.11,然后用pip安装llama_index、langchain和gradio。如果要用mysql作为数据连接源的话还要安装mysqlclient。值得注意的是,安装mysqlclient时候坑你会报一些错误,然后就是一顿解决。
为此,我将服务器上搭建的环境全部打包成了一个docker镜像。推荐大家直接用我的镜像,运行docker容器。工作目录在/amo下面。运行容器后,进入/amo,然后执行python app.py。安装docker后详细步骤如下
1、下载镜像
docker pull meijiang/langchain-gpt:v12、运行容器
docker run -dt --name mygpt -p 9090:9090 meijiang/langchain-gpt:v13、查看容器id
docker ps 4、进入容器
docker exec -it <你刚刚启动的容器id> bash如下图,进入容器后再进入/amo目录,运行python app.py 就跟在windows上执行一样的步骤了。
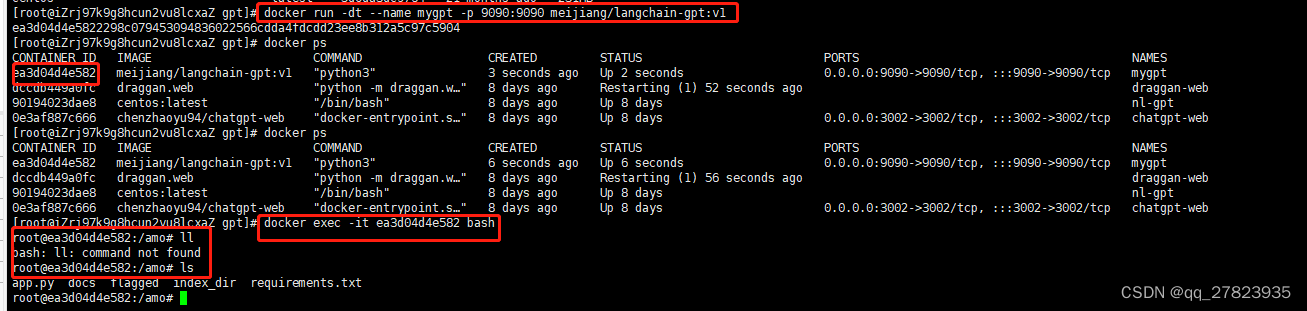
执行python app.py后可以访问在线gradio的链接体验。
注意:容器内的数据库host和账号都已经失效,请更改成自己的数据库连接信息
大家也可以根据自己的情况,写一个Dockerfile,启动容器时候就运行python app.py和将app.py替换成自己的文件。
就写到这里,如果有不对的地方欢迎指正。