目录
- 前言
- 冒泡排序(Bubble Sort)
- 一、概念
- 二、实现思路
- 三、图示过程
- 四、案例分析
- 1、图示过程
- 2、第一趟排序示例
- 五、代码
- 1、代码示例
- 2、代码解释
- 3、运行结果
- 六、复杂度
- 快速排序(QuickSort)
- 一、概念
- 二、实现思路
- 三、图示过程
- 四、代码
- 1、代码示例
- 2、代码解释
- 3、运行结果
- 五、复杂度
- 归并排序(MergeSort)
- 一、概念
- 二、实现思路
- 三、图示过程
- 四、代码
- 1、代码示例
- 2、代码解释
- 3、运行结果
- 五、复杂度
- 基数排序(Radix Sort)
- 一、概念
- 二、实现思路
- 三、图示过程
- 四、代码
- 1、代码示例
- 2、代码解释
- 3、运行结果
- 五、复杂度
- 结构化:各个排序对比表格
- 如果本篇博客对您有一定的帮助,请您留下宝贵的三连:==留言+点赞+收藏==哦。
前言
八大排序-直接插入排序、希尔排序、直接选择排序、冒泡排序、堆排序、快速排序、归并排序、基数排序(上)
书接上回,咱们继续来看下面四个排序。
下面所有代码段都以升序为例,数组的下标均从0开始。
排序的稳定性即:任意两个相等的数据,排序前后的相对位置不发生变化。
冒泡排序(Bubble Sort)
一、概念
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
二、实现思路
• 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
• 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
• 针对所有的元素重复以上的步骤,除了最后一个;
• 重复步骤1~3,直到排序完成。
三、图示过程

四、案例分析
将几个无序的数:3,6,4,2,11,10,5 使用冒泡排序法将其排成一个从小到大的有序数列。
1、图示过程

2、第一趟排序示例
第1次比较:3与6进行比较,3 < 6 所以不交换位置。得到3,6,4,2,11,10,5
第2次比较:6与4比较,6 > 4,6与4交换位置,如果相邻的元素逆序就交换。得到3,4,6,2,11,10,5
第3次比较:交换完位置后两个索引又同时移动让 6 与 2比较,6 > 2,6与2交换位置。得到3,4,2,6,11,10,5
第4次比较:6与11进行比较,6 < 11 所以不交换位置。得到 3,4,2,6,11,10,5
第5次比较:11与10进行比较,11 > 10 所以进行位置交换。得到 3,4,2,6,10,11,5
最后将11与5进行比较,11 > 5 所以进行位置交换。得到3,4,2,6,10,5,11
五、代码
1、代码示例
public class BubbleSort {public static void main(String[] args) {int[] arr = { 64, 34, 25, 12, 22, 11, 90 };int n = arr.length;// 外层循环控制排序轮数for (int i = 0; i < n - 1; i++) {// 内层循环控制每轮排序的次数for (int j = 0; j < n - i - 1; j++) {// 如果前面的元素大于后面的元素,则交换它们的位置if (arr[j] > arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}// 输出排序后的结果System.out.println("排序后的结果为:");for (int i = 0; i < n; ++i) {System.out.print(arr[i] + " ");}}
}
2、代码解释
1、int[] arr = { 64, 34, 25, 12, 22, 11, 90 }; 定义了一个数组 arr,用于存储待排序的数据。
2、int n = arr.length; 获取数组的长度,即待排序数据的个数。
3、for (int i = 0; i < n - 1; i++) 外层循环控制排序轮数,i 的取值范围是 0 到 n-2。
4、for (int j = 0; j < n - i - 1; j++) 内层循环控制每轮排序的次数,j 的取值范围是 0 到 n-i-2。
5、if (arr[j] > arr[j + 1]) 如果前面的元素大于后面的元素,则交换它们的位置。
6、System.out.print(arr[i] + " "); 输出排序后的结果,每个元素之间用空格分隔。
3、运行结果
排序后的结果为:
11 12 22 25 34 64 90
六、复杂度
冒泡排序最好的时间复杂度是O(n),最坏和平均时间复杂度为O(n^2),空间复杂度为O(1)。是一种稳定排序。
快速排序(QuickSort)
一、概念
快速排序(QuickSort)是一种基于比较的排序算法,它也是最常用的排序算法之一。快速排序的基本思想是通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后再按此方法对这两部分记录分别进行快速排序,以达到整个序列有序的目的。
二、实现思路
1、选出一个key,一般是最左边或是最右边的。
2、定义一个begin和一个end,begin从左向右走,end从右向左走。(需要注意的是:若选择最左边的数据作为key,则需要end先走;若选择最右边的数据作为key,则需要bengin先走)。
3、在走的过程中,若end遇到小于key的数,则停下,begin开始走,直到begin遇到一个大于key的数时,将begin和right的内容交换,end再次开始走,如此进行下去,直到begin和end最终相遇,此时将相遇点的内容与key交换即可。(选取最左边的值作为key)
4.此时key的左边都是小于key的数,key的右边都是大于key的数
5.将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作,此时此部分已有序
三、图示过程

四、代码
1、代码示例
public class QuickSort {public static void quickSort(int[] arr, int left, int right) {if (left < right) {int pivot = partition(arr, left, right); // 分区操作,返回 pivot 的索引quickSort(arr, left, pivot - 1); // 对左边进行递归排序quickSort(arr, pivot + 1, right); // 对右边进行递归排序}}private static int partition(int[] arr, int left, int right) {int pivot = left; // 设定基准值(pivot)int index = pivot + 1;for (int i = index; i <= right; i++) {if (arr[i] < arr[pivot]) {swap(arr, i, index);index++;}}swap(arr, pivot, index - 1);return index - 1;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};int n = arr.length;quickSort(arr, 0, n-1);System.out.println("排序后的数组:");for (int i : arr) {System.out.print(i + " ");}}
}
2、代码解释
1、quickSort 方法:实现快速排序算法。参数 arr 为待排序数组,left 和 right 为待排序区间的左右端点(初始值为数组的起始和终止下标)。
2、partition 方法:实现分区操作,即将数组中小于基准值的元素放在基准值的左边,大于等于基准值的元素放在基准值的右边。参数 arr 为待排序数组,left 和 right 为待排序区间的左右端点(初始值为数组的起始和终止下标)。
3、swap 方法:实现数组中两个元素的交换。参数 arr 为待排序数组,i 和 j 分别为两个元素的下标。
4、main 方法:测试快速排序算法。先定义一个待排序数组 arr,然后调用 quickSort 方法对其进行排序,最后输出排序后的数组。
3、运行结果
排序后的数组:
1 5 7 8 9 10
五、复杂度
快速排序最好和平均的时间复杂度是O(nlogn),最坏时间复杂度为O(n^2),空间复杂度为O(logn)。是一种不稳定排序。
归并排序(MergeSort)
一、概念
归并排序是一种基于分治思想的排序算法,它将待排序序列分成若干个子序列,每个子序列都是有序的,然后再将子序列合并为整体有序的序列。
归并排序是用分治思想,分治模式在每一层递归上有三个步骤:
• 分解(Divide):将n个元素分成个含n/2个元素的子序列。
• 解决(Conquer):用合并排序法对两个子序列递归的排序。
• 合并(Combine):合并两个已排序的子序列已得到排序结果。
二、实现思路
1、申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
2、设定两个指针,最初位置分别为两个已经排序序列的起始位置
3、比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
4、重复步骤③直到某一指针到达序列尾
5、将另一序列剩下的所有元素直接复制到合并序列尾
三、图示过程

四、代码
1、代码示例
import java.util.Arrays;public class MergeSort {public static void main(String[] args) {int[] arr = { 5, 3, 7, 6, 2, 1, 4 };System.out.println("原始数组:" + Arrays.toString(arr));mergeSort(arr, 0, arr.length - 1);System.out.println("排序后数组:" + Arrays.toString(arr));}/*** 归并排序* * @param arr 待排序数组* @param left 左边界* @param right 右边界*/public static void mergeSort(int[] arr, int left, int right) {if (left < right) {int mid = (left + right) / 2; // 计算中间位置mergeSort(arr, left, mid); // 对左半部分进行归并排序mergeSort(arr, mid + 1, right); // 对右半部分进行归并排序merge(arr, left, mid, right); // 合并左右两部分}}/*** 合并左右两部分* * @param arr 待合并数组* @param left 左边界* @param mid 中间位置* @param right 右边界*/public static void merge(int[] arr, int left, int mid, int right) {int[] tmp = new int[arr.length]; // 用于存储归并后的临时数组int i = left; // 左半部分起始位置int j = mid + 1; // 右半部分起始位置int k = left; // 临时数组起始位置while (i <= mid && j <= right) {// 如果左半部分当前元素小于右半部分当前元素,就将左半部分当前元素放入临时数组中// 否则,就将右半部分当前元素放入临时数组中if (arr[i] < arr[j]) {tmp[k++] = arr[i++];} else {tmp[k++] = arr[j++];}}// 将左半部分剩余元素依次放入临时数组中while (i <= mid) {tmp[k++] = arr[i++];}// 将右半部分剩余元素依次放入临时数组中while (j <= right) {tmp[k++] = arr[j++];}// 将临时数组中的元素复制回原数组中for (int p = left; p <= right; p++) {arr[p] = tmp[p];}}
}
2、代码解释
1、首先定义了一个数组 arr,然后调用 mergeSort 函数对数组进行归并排序,最后输出排序后的数组。
2、mergeSort 函数是归并排序的主要实现,它采用递归的方式将数组分成左右两部分,分别进行归并排序,然后将左右两部分合并成一个有序数组。具体实现时,如果左边界小于右边界,就计算出中间位置 mid,然后对左半部分和右半部分分别进行归并排序,最后将左右两部分合并成一个有序数组。
3、merge 函数是将左右两部分合并成一个有序数组的实现,它先创建一个临时数组 tmp,然后将左右两部分中较小的元素放入临时数组中,直到某一部分的元素已经全部放入临时数组中为止。最后将剩余元素依次放入临时数组中,并将临时数组中的元素复制回原数组中。
3、运行结果
原始数组:[5, 3, 7, 6, 2, 1, 4]
排序后数组:[1, 2, 3, 4, 5, 6, 7]
五、复杂度
归并排序时间复杂度是O(nlogn),空间复杂度为O(n)。是一种稳定排序。
基数排序(Radix Sort)
一、概念
基数排序将整数按照位数逐个进行比较排序。对于有 n 个整数的数组,假设整数的最大值有 k 位数,则基数排序的时间复杂度为 O(kn),其中 k 是常数。
二、实现思路
基数排序有两种实现方式,一种是 LSD(Least Significant Digit)排序,即从最低位开始排序;
另一种是 MSD(Most Significant Digit)排序,即从最高位开始排序。LSD 是基数排序的经典实现方式,而 MSD 可以优化一些情况,比如在字符串排序中。今天主要介绍LSD排序。
基数排序的思路是从个位开始,按照位数逐个进行排序。首先按照个位数进行排序,将每个数放到对应的桶中,再从桶中依次取出每个数,重新排列为新的数组。然后按照十位数进行排序,以此类推,直到最高位排序完成,数组就变成有序的了。
三、图示过程

四、代码
1、代码示例
import java.util.Arrays;public class RadixSort {public static void main(String[] args) {int[] arr = {53, 3, 542, 748, 14, 214};radixSort(arr);System.out.println(Arrays.toString(arr));}public static void radixSort(int[] arr) {// 获取数组中最大值的位数int maxDigit = getMaxDigit(arr);// 对每一位进行排序for (int i = 1; i <= maxDigit; i++) {// 用桶来存储每个位上的数字int[][] buckets = new int[10][arr.length];int[] count = new int[10];// 将数组中的数字放入对应的桶中for (int j = 0; j < arr.length; j++) {int digit = getDigit(arr[j], i);buckets[digit][count[digit]] = arr[j];count[digit]++;}// 将桶中的数字按顺序放回原数组中int index = 0;for (int j = 0; j < count.length; j++) {for (int k = 0; k < count[j]; k++) {arr[index] = buckets[j][k];index++;}}}}// 获取数字的某一位上的数字private static int getDigit(int num, int digit) {return (num / (int) Math.pow(10, digit - 1)) % 10;}// 获取数组中最大值的位数private static int getMaxDigit(int[] arr) {int max = Integer.MIN_VALUE;for (int num : arr) {max = Math.max(max, num);}return String.valueOf(max).length();}
}
2、代码解释
1、先获取数组中最大值的位数。
2、对每一位进行排序,用桶来存储每个位上的数字。先遍历数组,将数组中的数字放入对应的桶中。
3、将桶中的数字按顺序放回原数组中。
4、重复步骤2和步骤3,直到排完最高位为止。
3、运行结果
排序后的数组:[3, 14, 53, 214, 542, 748]
五、复杂度
本示例中,时间复杂度是O(d(n+k)),其中d为位数,n为待排序元素的数量,k为桶的大小,本例中k=10。空间复杂度是O(n+k),即桶的大小加上一个计数数组。由于本例中使用的是固定大小的桶,所以空间复杂度可以简化为O(n)。
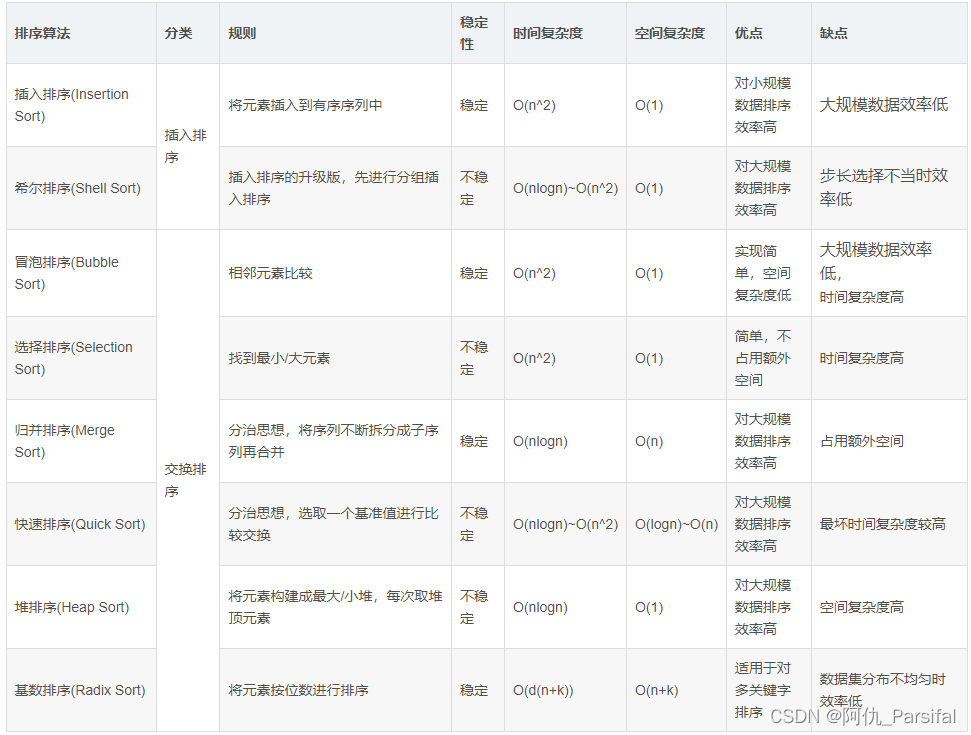
结构化:各个排序对比表格



![深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解](https://img-blog.csdnimg.cn/img_convert/fb015edd9b8c5a65b4ae01e1f76a95ea.png)