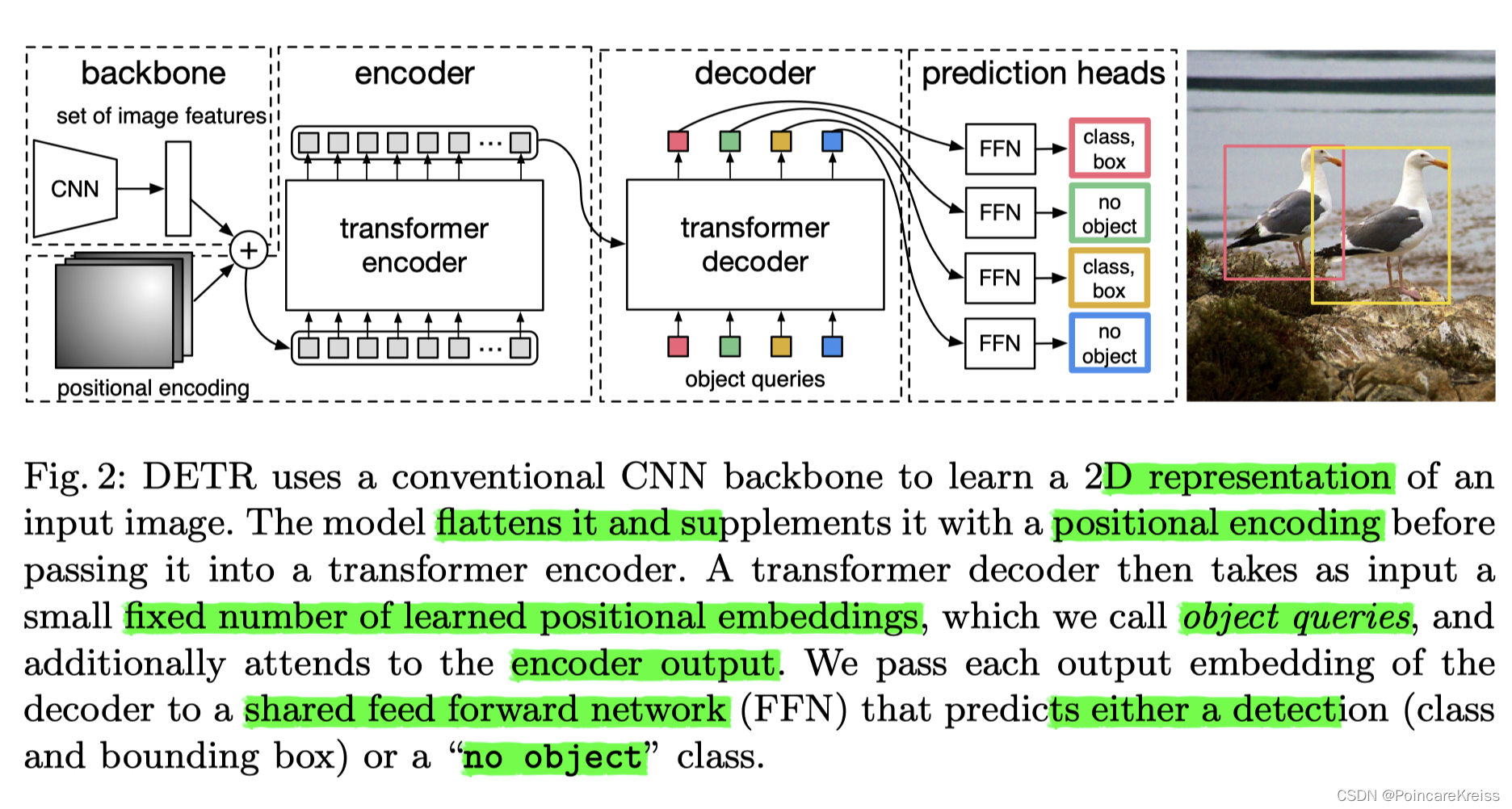
- 一个cnn的backbone, 提图像的feature, 比如, HWC.
- 同时对这个feature做position_embedding.
- 然后二者相加 (在Transformer里面就是二者相加)
- 输入encoder,
- 输入decoder (这里有object queries.)
- 然后接Prediction Heads, 比如分类和回归.
下面的代码参考自: https://github.com/facebookresearch/detr
commit-id: 3af9fa8

可以看到, 这里传入的有backbone, transformer, 输入的类别个数(用来确定head的输出维度), num_quries, 以及是否需要aux_loss等.
先看一下forward的解释
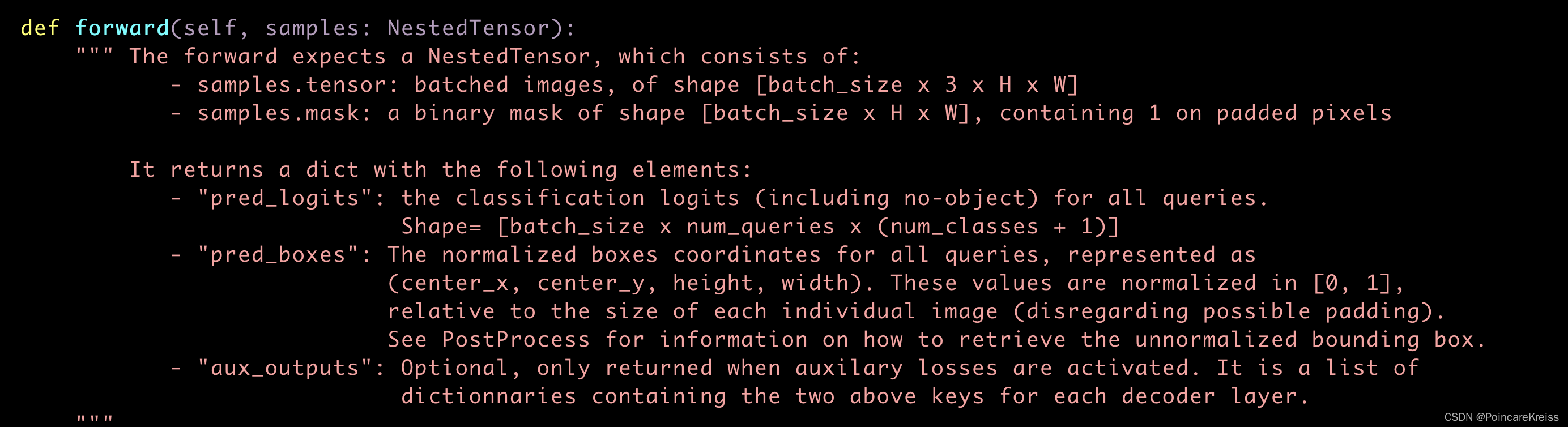
输入是一堆图片和对应的mask. 这里mask先不管. 后面再来细看其具体起的作用;
输出是logits, boxes, 还有aux_outputs(只有在用aux_loss的时候才会有这个的输出)
接下来看第一步
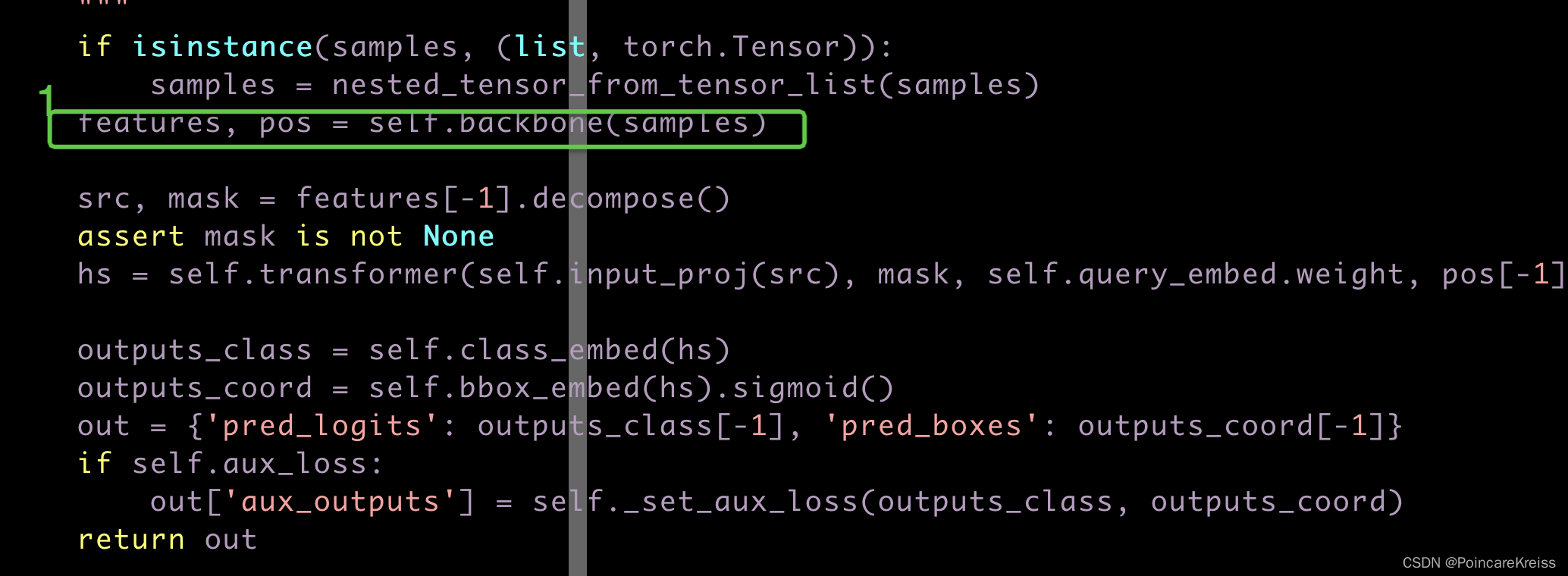
backbone部分
从这里
可以看出来, backbone是这两个的结合.
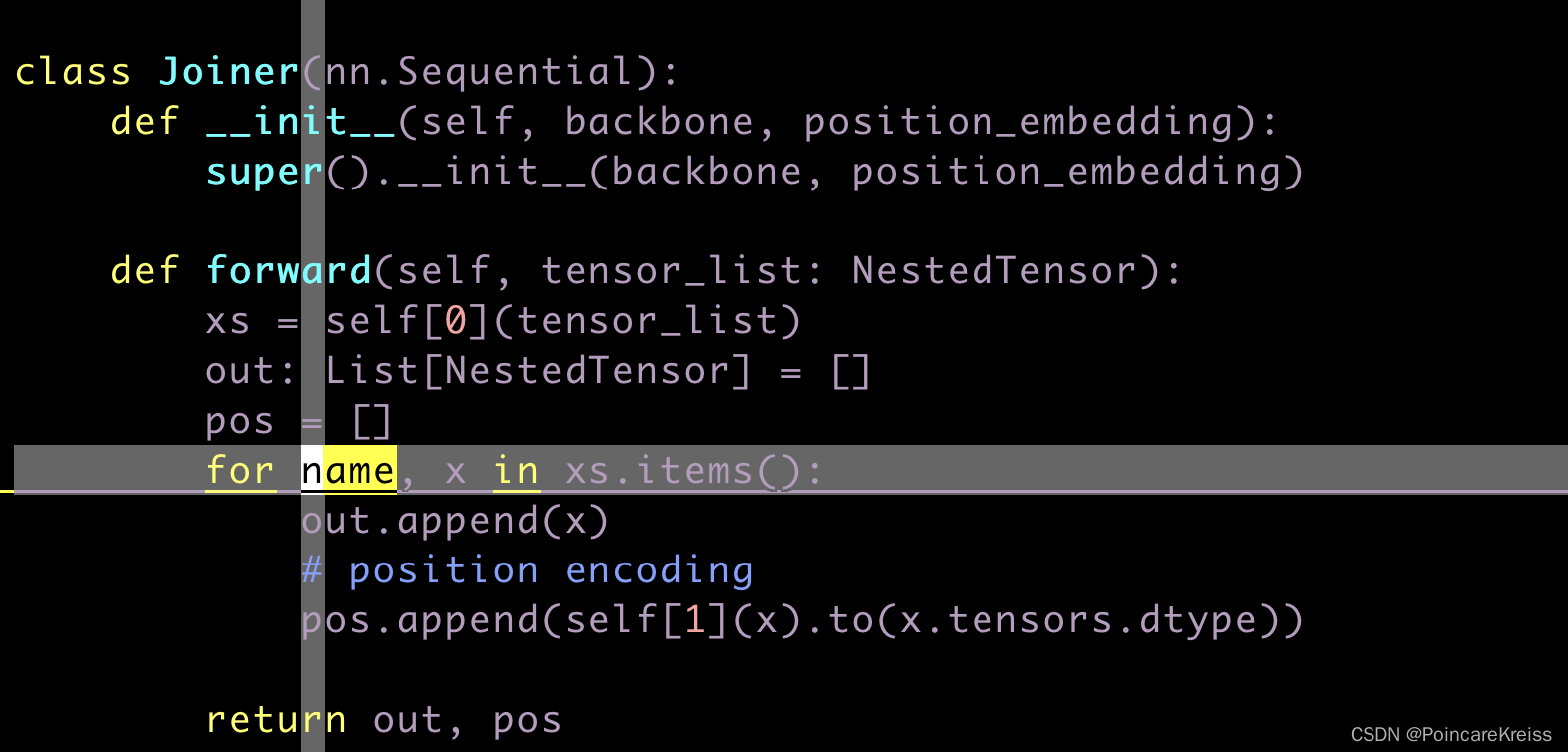
也就是说最终backbone输出的第一个其实是图像backbone提的feature, 第二个是每个feature所对应的 position encoding.
Transormer部分
transformer的输入如下
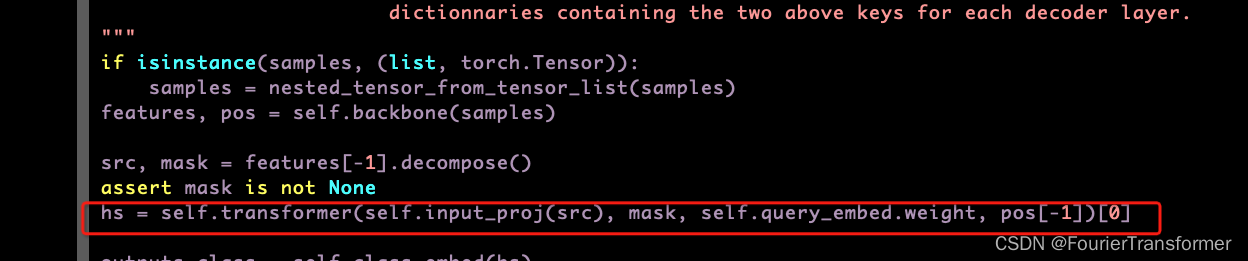
由于没有跑代码. 这里
src: 先理解成是images的feature, pos[-1], 先理解成是position-encoding
这里input_proj. 是对输入的src做了一个FC.

这里的query_embed是

可以理解成是一个query的词典表.
之后如图

encoder部分和原始transformer是一致的, 而decoder部分, 原始transformer输入的是trg_seq. 而这里是一个全0的矩阵. 大小与query_embed一样大.
之前transformer的decoder中是trg_seq 与 src_seq的encoder的output 做encoder-decoder-attention. 但是现在detr里的decoder中, 到现在还没有用到groundtruth.
head部分
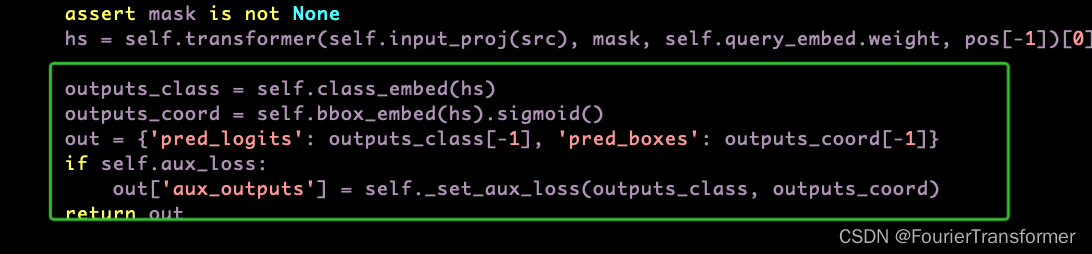
这里bbox的coord取sigmoid的原因是gt是按图像的长宽给的比例.

aux_loss
loss部分
bbox-loss. 采用的有 l1-loss 以及giou loss, 这里用giou-loss的原因是scale-不变.

SetCriterion
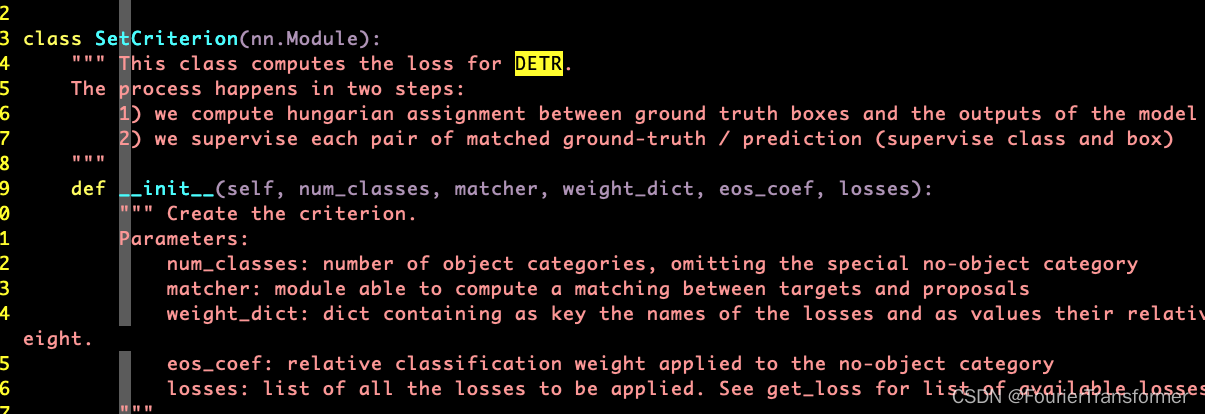
这里写得很清晰, 即对gt和dt做一次Hungarian匹配, 然后, 将匹配到的pair, 去算loss, loss包括类别和bbox.
我理解这个过程相当于label-assign, 只不过特殊的地方是这个label-assign 是一个一对一的, 这是和之前一些一阶段和二阶段检测不太一样的地方. 比如使用anchor的方法中, 可能多个anchor会对应到一个gt上面, 这也是为啥那些方法的后处理中要使用NMS, 相当于是一种搜索排查式的检测方式,先检测出一堆proposals, 再选出置信度较高的.
loss_cardinality
这其实不是一个loss, 就是为了统计预测的object的数量与ground-truth数量之间的差异. 用来观测.
HungarianMatcher
这个就是一个匈牙利匹配, 用的 from scipy.optimize import linear_sum_assignment, 这里用pytorch的方式封装了一下.
mask起的作用
二维positionEncoding的细节
paper-reading
Abstract
- 把目标检测视为一个集合预测问题. 从设计上去掉了很多的人为操作,比如anchor设定, nms 等.
- 更关注object与image context 之间的本质, 直接去预测最终的结果集合. 而非"搜索式检测"
- 不需要开发额外的库,比如roi-align, roi-pooling, 这些操作…
- 很容易换一个head就可以去做分割的任务,
pipline

整个Pipline看上去很好理解, 细节主要体现在 图像的backbone的features如何转化成为 word-embeding似的输入, 进入到transformer中.
在大目标上面要比小目标上好

这里解释说在大目标上效果比较好是因为transormer的non-local的机制, 这一点我的理解是, transformer由于内部的self-attention操作, 使得输入的一句话中每一个词彼此之间都会去算attention的加权分数。 所以哪怕是某一个词的预测,它也是依赖于整个句子的. 所以是一个non-local的操作.
而小目标, 因为占据的图像中的位置比较少. 别的位置对于这个小目标的attention不那么重要, 因此这种non-local的操作,对于小目标不太友好.
当然作者也提了可以用其他的方式来缓解小目标不好的问题, 比如FPN.
训练时间长

对于set prediction问题, 两个重要的部件
set prediction loss
这个主要用于在predictin和ground-truth之间建立one-one map.
DETR是预测N个objects, N是一个超参, 比如100.
能够预测objects以及他们之间关系的模型结构. 这里就是指的是DETR
backbone

比较好理解,就是正常的 2d-backbone.
encoder

关键的部分也都在上面标出来了.
decoder

说实话,没太理解 N个, object-query 到最后为啥能够预测 N个 final predictions. 背后的原因是啥?
prediction Heads
这个就是正常的heads.
auxiliary losses
为了帮助模型训练, 在每个decoder层后面, 加了PredictionHeads 和Hungarian loss 来做监督, 并且这些 层是share 参数的.

实验对比
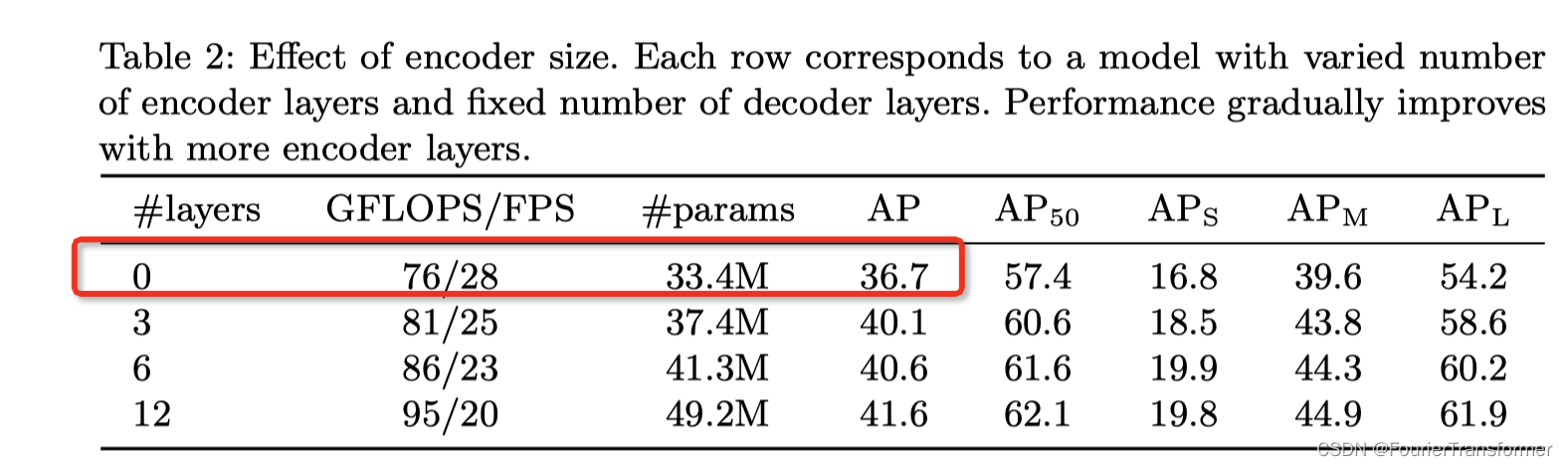
encoder层的影响
从下表可以看出来, 用encoder还是很有用的.
而且有可视化结果证明, encoder 层似乎已经把目标分离开来了.

decoder层数的影响
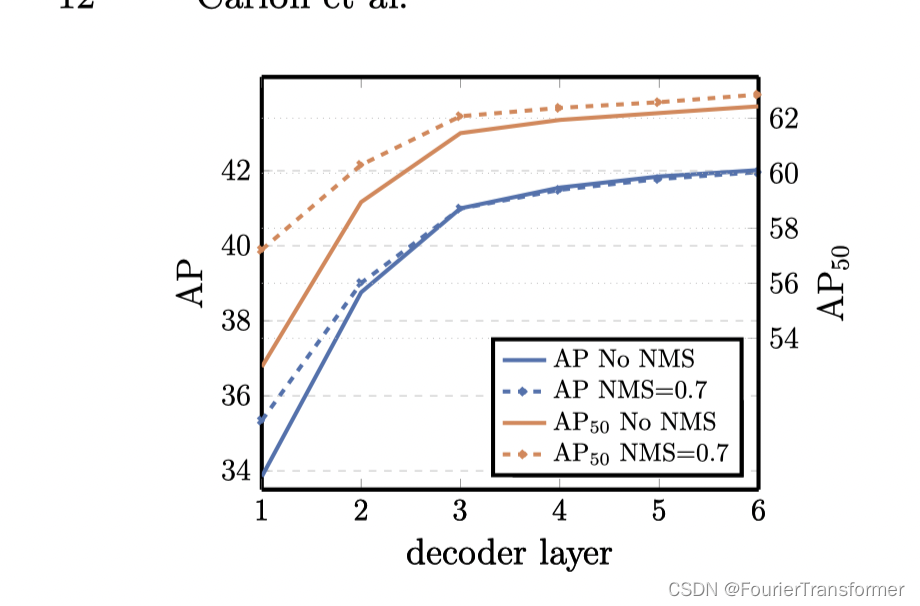
- decoder层数的增加, 效果变好,
- 当decoder层数只有一层的时候, NMS有用.
- 当decoder层数大于一层的时候, NMS几乎没有什么用.
这说明 单个decoder层不足以表现不同输出间的关系.

FFN层的重要性
去掉之后会掉点.

PositionEncoding 的重要性
- spatioal position encoding 在encoder 和decoder 中都非常重要. 没有的话会掉6个点左右.

object_query
从代码里看, 是这样的流程.
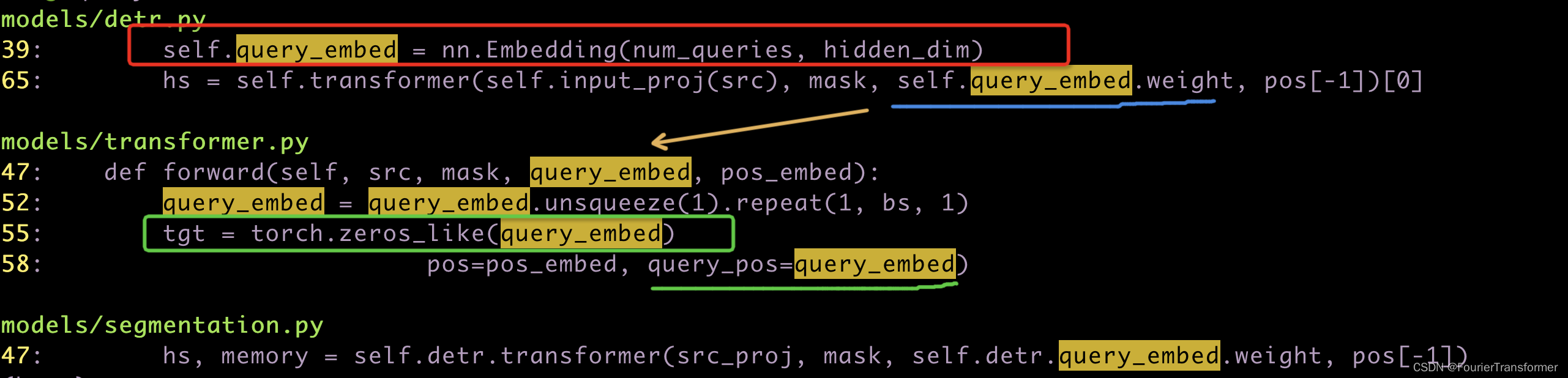
比如 num_queries 是100, 而 hidden_dim 是64的话.
那么query_embed.weight 也是 [100, 64] 维的.
这里进去encoder的, tgt 每次其实都是0. 而query_embed.weight 充当的是query_pos.
我理解这个就是上面说的, output position encodings.
因此当normalize_before=False的时候, decoder的时候会直接走forward_post,
从下面的代码可以看出
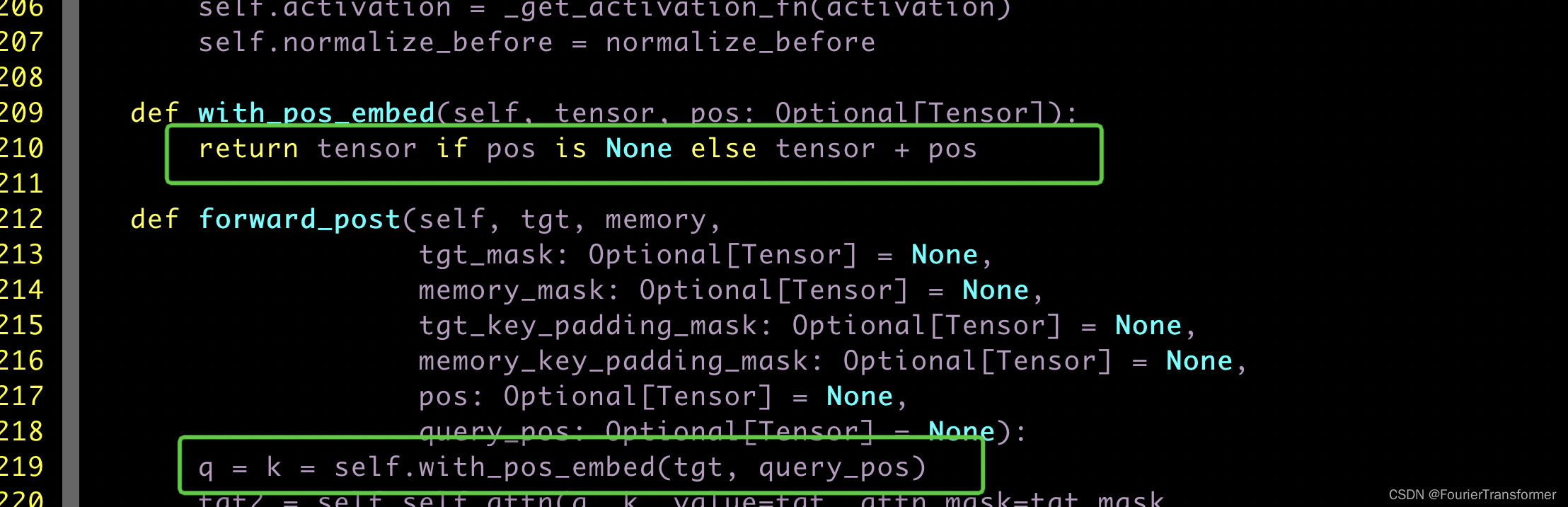
在decoder的时候, 最初的一层的输入, 因为tgt都是0, 所以 q=k=query_pos.
所以这里的object_query 其实就是随机初始化的 query_embed.weight.
这里解释下nn.embedding 是什么意思.
nn.embedding可以理解为是一个词嵌入模块. 它是有weight的. 这是一个可以学习的层, 有参数,类似于conv2d.
比如上面的例子中, query_embed 就可以理解为是一个词典, 只不过这个词典有点小, 只有100个词, 每个词的embedding的大小是64.
forward的时候,可以传入indices, 来得到对应的每个单词的embeddings. 可以传入batch的indices.