ChatGPT工作原理与技术细节
自ChatGPT发布以来,ChatGPT的能力一直在刷新大家对人工智能的认知,但 ChatGPT究竟是如何工作的呢?虽然其内部运作的细节尚未公布,但我们可以从最近的研究中拼凑出它的工作原理。

ChatGPT 的工作原理
ChatGPT 是 OpenAI 的最新语言模型,比其前身 GPT-3 有了重大改进。与许多大型语言模型类似,ChatGPT 能够为不同任务生成多种样式的文本,且具有更高的精确度、细节和连贯性。它代表了 OpenAI 大型语言模型系列的下一代产品,其设计非常注重交互式对话。
通过结合使用监督学习和强化学习来微调学习ChatGPT,其中强化学习是使得 ChatGPT 独一无二的关键。创作者使用一种称为人类反馈强化学习 (RLHF) 的特殊技术,该技术在训练循环中使用人类反馈来最大限度地减少有害、不真实和/或有偏见的输出。
在了解 RLHF 的工作原理和 ChatGPT 如何使用 RLHF 来克服这些问题之前,我们将研究ChatGPT 的前身 GPT-3 的局限性以及这些局限性如何源于其训练过程。
大型语言模型中的"准确性(alignment)与精确度(capability)"
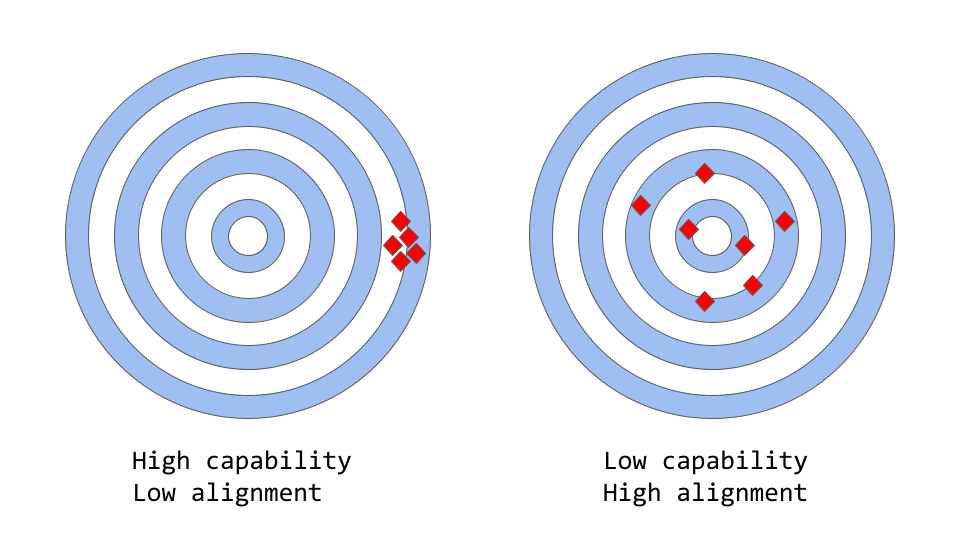
"alignment vs capability"可以被认为是"准确性与精确度"的更抽象的类比
In the context of machine learning, the term capability refers to a model's ability to perform a specific task or set of tasks. A model's capability is typically evaluated by how well it is able to optimize its objective function, the mathematical expression that defines the goal of the model. For example, a model designed to predict stock market prices might have an objective function that measures the accuracy of the model's predictions. If the model is able to accurately predict the movement of stock prices over time, it would be considered to have a high level of capability for this task.
在机器学习中,术语 capability 是指模型执行特定任务或一组任务的能力。模型的 capability 通常通过优化其目标函数来评估,目标函数是定义模型目标的数学表达式。例如,设计用于预测股票市场价格的模型可能具有衡量模型预测准确性的目标函数。如果该模型能够准确预测股票价格随时间的变化,则可以认为它具有完成此任务的高水平能力。
另一方面,Alignment 关注的是我们实际希望模型做什么而不是训练它做什么。它问的问题是"目标函数是否符合我们的意图?并指模型的目标和行为与人类价值观和期望相一致的程度。举一个简单的具体例子,假设我们训练一个鸟类分类器将鸟类分类为"麻雀"或"知更鸟",我们使用 log loss(衡量模型预测概率分布与真实分布之间的差异)作为训练目标,即使我们的最终目标是高分类精度。该模型可能具有低对数损失,即模型的能力很高,但在测试集上的准确性很差。事实上,log loss与分类任务的准确性并不完全相关。这是一个misalignment的例子,模型能够优化训练目标,但与我们的最终目标不一致。
原始的GPT-3模型就存在"misaligned"问题
大型语言模型(例如 GPT-3)根据来自互联网的大量文本数据进行训练,能够生成类似人类的文本,但它们可能并不总是产生与人类期望或理想值一致的输出。事实上,他们的目标函数是单词序列(或标记序列)的概率分布,使他们能够预测序列中的下一个单词是什么(下面有更多详细信息)。
然而,在实际应用中,这些模型旨在执行某种形式的有价值的认知工作,并且这些模型的训练方式与我们希望使用它们的方式之间存在明显差异。尽管从数学上讲,机器计算出的单词序列的统计分布可能是对语言建模的一种非常有效的选择,但作为人类,我们通过选择最适合给定情况的文本序列来生成语言,并使用我们的背景知识和常识来指导这个流程。当语言模型用于需要高度信任或可靠性的应用程序(例如对话系统或智能个人助理)时,这可能会成为一个问题。
虽然这些强大、复杂的模型在过去几年中经过大量数据训练变得非常有能力,但当用于生产系统以使人类生活更轻松时,它们往往无法发挥这种潜力。 Large Language Models 中的对齐问题通常表现为:
缺乏提示:不遵循用户的明确指示。
事实错误:模型编造了不存在的或错误的事实。
缺乏可解释性:人类很难理解模型是如何做出特定决定或预测的。
生成有偏见或的输出:在有偏见/有害数据上训练的语言模型可能会在其输出中重现该结果,即使没有明确指示这样做。
但是这个"alignment"问题具体是从哪里来的呢?语言模型的训练方式是否天生就容易出现错位?
语言模型训练策略如何产生错位misalignment
Next-token-prediction 和 masked-language-modeling 是用于训练语言模型的核心技术,例如 transformers 。在第一种方法中,模型被赋予一个单词序列(或"tokens",即单词的一部分)作为输入,并被要求预测序列中的下一个单词。例如,如果给模型输入句子
"The cat sat on the"
它可能会预测下一个词是"mat"、"chair"或"floor",因为在给定先前上下文的情况下,这些词出现的可能性很高;语言模型实际上能够估计给定先前序列的每个可能单词(在其词汇表中)的可能性。
掩码语言建模方法是下一个标记预测的变体,其中输入句子中的某些单词被替换为特殊标记,例如 [MASK] 。然后要求模型预测应该插入的正确单词来代替掩码。例如,如果模型给出了句子
"The [MASK] sat on the"
作为输入,它可能会预测下一个单词为 "cat", "dog", 或者 "rabbit"。
这些目标函数的一个优点是它允许模型学习语言的统计结构,例如常见的单词序列和单词使用模式。这通常有助于模型生成更自然、更流畅的文本,是每个语言模型预训练阶段必不可少的步骤。然而,这些目标函数也会导致问题,主要是因为模型无法区分重要错误和不重要错误。举个很简单的例子,如果给模型输入句子:
"The Roman Empire [MASK] with the reign of Augustus."
它可能会预测 "began" 或*"ended"*,因为这两个词出现的可能性都很高(事实上,这两个句子在历史上都是正确的),即使第二个选择为完全不同的含义。更一般地说,这些训练策略可能会导致语言模型在某些更复杂的任务中出现偏差,因为仅经过训练以预测文本序列中的下一个词(或掩码词)的模型可能不一定会学习一些其含义的更高层次的表示。因此,该模型难以泛化到需要更深入地理解语言的任务或上下文。
研究人员和开发人员正在研究各种方法来解决大型语言模型中的对齐问题。 ChatGPT 基于原始的 GPT-3 模型,但通过使用人工反馈来指导学习过程,以减轻模型的错位问题为特定目标,进一步进行了训练。所使用的具体技术,称为从人类反馈中强化学习(RLHF)。 ChatGPT 代表了将此技术用于生产模型的第一个案例。
下面介绍ChatGPT是如何利用人类反馈来解决对齐问题的呢?
Reinforcement Learning from Human Feedback(RLHF)
该方法总体上由三个不同的步骤组成:
有监督的微调:预训练语言模型在标记者策划的相对少量的演示数据上进行微调,以学习从选定的提示列表生成输出的监督策略(SFT 模型)。这表示基线模型。
"模仿人类偏好":标注者被要求对相对大量的 SFT 模型输出进行投票,这样就创建了一个由比较数据comparison data组成的新数据集。在此数据集上训练了一个新模型。这被称为奖励模型 (RM)。
Proximal Policy Optimization (PPO) 步骤:奖励模型用于进一步微调和改进 SFT 模型。这一步的结果就是所谓的策略模型(policy model)。
第一步只训练一次,而第二步和第三步可以不断迭代:在当前最好的策略模型上收集更多的比较数据,用于训练新的奖励模型,然后训练新的策略。
现在让我们深入了解每个步骤的细节!
注意:本文的其余部分基于 InstructGPT (https://arxiv.org/pdf/2203.02155.pdf) 论文的内容。根据 OpenAI 的说法,ChatGPT "使用与 InstructGPT 相同的方法进行训练,但数据收集设置略有不同"(来源)。不幸的是,ChatGPT 的确切定量报告尚未公开。
Step 1: The Supervised Fine-Tuning (SFT) model
第一步包括收集示范数据以训练监督政策模型,称为 SFT 模型。
数据收集:选择prompts列表,并要求一组人工标记者写下预期的输出响应。对于 ChatGPT,使用了两种不同的提示来源:一些是人工数据标注的,一些是从 OpenAI 的 API 请求(即来自他们的 GPT-3 客户)中采样的。由于整个过程缓慢且昂贵,结果是一个相对较小的高质量精选数据集(大概有大约 12-15k 个数据点),用于微调预训练语言模型。
模型选择:ChatGPT 的开发人员没有微调原始 GPT-3 模型,而是选择了所谓的 GPT-3.5 系列中的预训练模型。据推测,使用的基线模型是最新的 text-davinci-003 ,这是一个 GPT-3 模型,主要在编程代码上进行了微调。
有趣的是,为了创建像 ChatGPT 这样的通用聊天机器人,开发人员决定在"代码模型"而非纯文本模型之上进行微调。
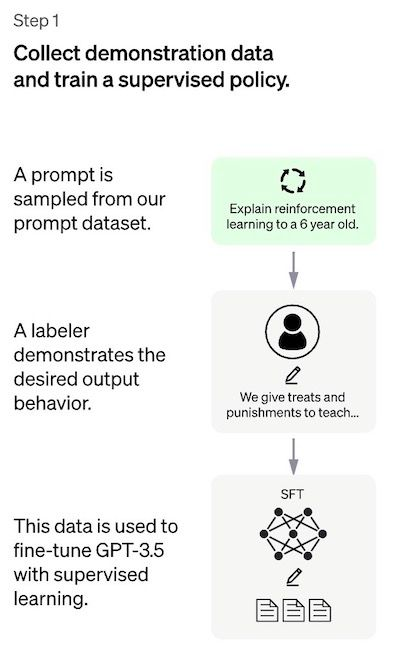
由于此步骤的数据量有限,在此过程之后获得的 SFT 模型可能会输出仍然(概率上)不是用户关注的文本,并且通常会出现上文所述意义上的错位。这里的问题是监督学习步骤具有高可扩展性成本(high scalability costs)。
为了克服这个问题,策略是通过人工对 SFT 模型的不同输出进行排序以创建奖励模型。
Step 2: 奖励模型(RM)
目标是直接从数据中学习目标函数(奖励模型)。此函数的目的是为 SFT 模型输出打分,与这些输出对人类的期望程度成正比。在实践中,这将强烈反映选定的人类标签组的特定偏好以及他们同意遵循的共同准则。最后,这个过程将从数据中提取一个应该模仿人类偏好的自动系统。
工作流程如下:
选择提示(prompts),SFT 模型为每个提示生成多个输出(4 到 9 之间)。
人工将输出从最好到最差排序。结果是一个新的标记数据集,其中排名是标签。该数据集的大小大约是用于 SFT 模型的精选数据集的 10 倍。
此新数据用于训练奖励模型 (RM)。该模型将一些 SFT 模型输出作为输入,并按优先顺序对它们进行排序。
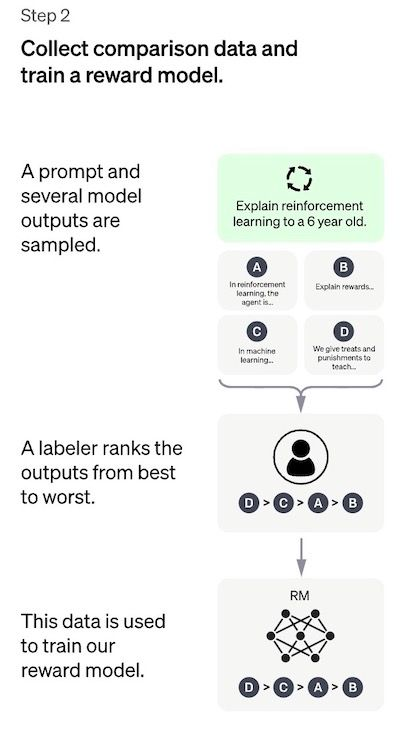
对于人工标签来说,对输出进行排序比从头开始生产要容易得多,这个过程可以更有效地扩大规模。在实践中,这个数据集是从 30-40k 提示的选择中生成的,并且在排名阶段将可变数量的生成输出(对于每个提示)呈现给每个标注者。
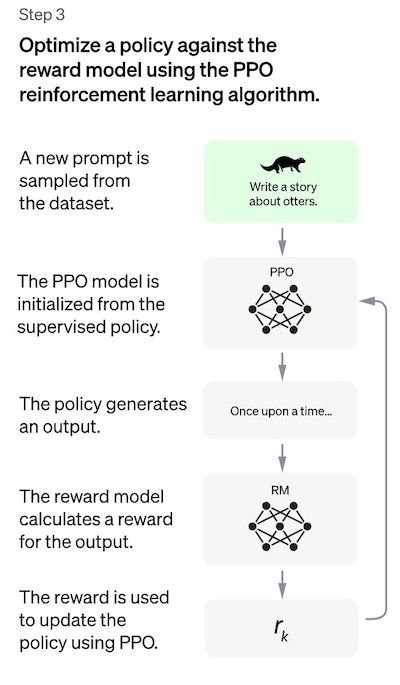
Step 3: Fine-tuning the SFT model via Proximal Policy Optimization (PPO)
强化学习现在用于通过优化奖励模型来微调 SFT 策略。使用的特定算法称为近端策略优化(PPO),微调后的模型称为 PPO 模型。
PPO要点如下:
PPO 是一种用于在强化学习中训练代理的算法。它被称为"on-policy"算法,因为它直接从当前策略中学习和更新,而不是像 DQN(深度 Q 网络)这样的"off-policy"算法中那样从过去的经验中学习。这意味着 PPO 会根据代理正在采取的行动和收到的奖励不断调整当前策略。
PPO使用信任域优化的方法来训练策略,这意味着它将策略的变化限制在与先前策略的一定距离内,以确保稳定性。这与其他策略梯度方法形成对比,后者有时会对可能破坏学习稳定性的策略进行大量更新。
PPO 使用价值函数来估计给定状态或动作的预期回报。价值函数用于计算优势函数,它表示预期收益与当前收益之间的差异。然后使用优势函数通过比较当前策略采取的操作与先前策略将采取的操作来更新策略。这使 PPO 可以根据所采取行动的估计价值对政策进行更明智的更新。
在这一步中,PPO模型由SFT模型初始化,价值函数由奖励模型初始化。该环境是一个 bandit 环境,它呈现随机提示并期望对提示做出响应。给定提示和响应,它会产生一个奖励(由奖励模型决定)并且这一集结束。每个per-token的 SFT 模型都添加了每个token的 KL 惩罚,以减轻奖励模型的过度优化。
性能评价
由于该模型是根据人工贴标机输入进行训练的,因此评估的核心部分也基于人工输入,即通过让标注者对模型输出的质量进行评分来进行。为避免训练阶段涉及的标注者的判断过度拟合,测试集使用来自保留的 OpenAI 客户的提示,这些提示未出现在训练数据中。
该模型根据三个标准进行评估:
Helpfulness:判断模型遵循用户指令以及推断指令的能力。
真实性:判断模型在封闭域任务上的幻觉(编造事实)倾向。该模型在 TruthfulQA 数据集上进行评估。
无害性:标签者评估模型的输出是否合适,是否诋毁受保护的类别,或包含贬损内容。该模型还在 RealToxicityPrompts 和 CrowS-Pairs 数据集上进行了基准测试。
该模型还评估了传统 NLP 任务(如问答、阅读理解和摘要)的零样本性能,开发人员在其中一些任务上观察到与 GPT-3 相比的性能回归。这是一个"校准税"的例子,其中基于 RLHF 的校准程序是以降低某些任务的性能为代价的。
这些数据集的性能回归可以通过称为预训练混合的技巧大大减少:在通过梯度下降训练 PPO 模型期间,通过混合 SFT 模型和 PPO 模型的梯度来计算梯度更新。
缺点
正如 InstructGPT (https://arxiv.org/pdf/2203.02155.pdf) 论文(根据其创建者所说,ChatGPT 正是基于该论文)所讨论的,该方法的一个非常明显的局限性是,在将语言模型与人类意图对齐的过程中,用于微调模型的数据受到各种错综复杂的主观因素的影响,包括:
生成演示数据的标记者的偏好。
设计编写数据标注说明的研究人员。
选择由开发人员制作或由 OpenAI 客户提供的prompts。
标记者偏差既包含在奖励模型训练(通过对输出进行排名)中,也包含在模型评估中。
作者特别指出了一个明显的事实,即参与训练过程的标注人员和研究人员可能无法代表语言模型的所有潜在最终用户。除了这个明显的"内在"限制之外,我们还想指出该方法的其他一些可能的缺点、未明确解决的问题以及一些悬而未决的问题:
缺乏控制研究:此报告(https://arxiv.org/pdf/2203.02155.pdf)的结果衡量最终 PPO 模型的性能,以 SFT 模型为基线。这可能会产生误导:我们怎么知道改进实际上是由于 RLHF?一项适当的(但昂贵的)对照研究将包括投入与用于训练奖励模型的标记工时数完全相同的时间,以创建具有高质量演示数据的更大的精选 SFT 数据集。然后,人们就可以客观地衡量 RLHF 方法与监督方法相比的性能改进。简单来说,缺乏这样的控制研究让一个基本问题完全悬而未决:RLHF 在对齐语言模型方面真的做得很好吗?
比较数据缺乏基本事实:标注者通常会对模型输出的排名持不同意见。从技术上讲,风险是在没有任何基本事实的情况下向比较数据添加高潜在方差。
人类偏好并不是同质的:RLHF 方法将人类偏好视为同质和静态的。假设所有人都拥有相同的价值观显然是一种延伸,至少在人类知识的大量主题上是这样。最近的一些研究开始以不同的方式解决这个悬而未决的问题。
奖励模型 (RM) 的提示稳定性测试:似乎没有实验调查奖励模型在输入提示变化方面的敏感性。如果两个提示在句法上不同但在语义上是等价的,RM 能否在模型输出的排名中显示出显着差异?简单来说,提示的质量对 RM 有多重要?
Wireheading 类型的问题:在 RL 方法中,模型有时可以学会操纵自己的奖励系统以达到预期的结果,从而导致"过度优化的策略"。这可以推动模型重新创建一些模式,这些模式由于某种未知原因使奖励模型得分高(请参阅 OpenAI 这篇论文中的表 29,了解语言建模中这种行为的明确示例)。 ChatGPT 在奖励函数中使用 KL 惩罚项对此进行了修补。请注意,有人试图优化 RM 输入(即 PPO 输出)以提高其输出(奖励分数),同时限制输入本身与某些参考输入(SFT 输出)相距不远.在最近的预印本中详细介绍了这种方法的局限性。
GPT及AI绘图等AI在线创作3090显在线免注册试用:https://ittutorial.top/buy/10000
深入了解参考资料
The most relevant paper about the RLHF methodology used for ChatGPT is Training language models to follow instructions with human feedback, which in fact details a model called InstructGPT, referred to by OpenAI as a "sibling model" to ChatGPT.
Anthropic published a detailed study on the effectiveness of RLHF methods for finetuning language models to act as helpful and harmless assistants.
The paper Learning to summarize from Human Feedback describes RLHF in the context of text summarization.
Proximal Policy Optimization: the PPO algorithm paper.
Deep reinforcement learning from human preferences --was one of the earliest (Deep Learning) papers using human feedback in RL, in the context of Atari games.
Alternatives to OpenAI's RLHF have been proposed by DeepMind in Sparrow and GopherCite papers.
A deep dive into the Alignment problem for language models is given in a (long) paper by Anthropic. Here's an excellent summary by Sam Ringer. Anthropic also has an open source repository (with accompanying paper) for RLHF.