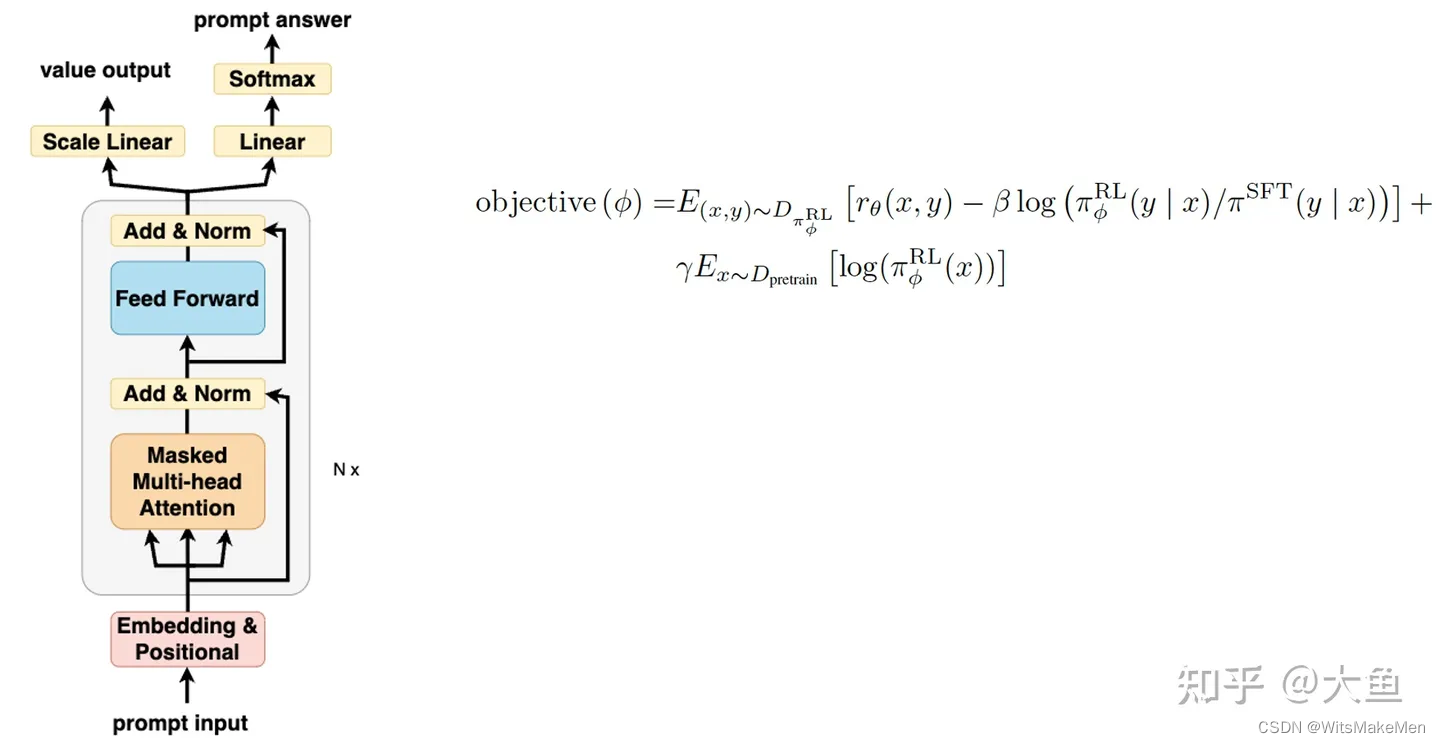ChatGPT概述:从模型训练到基本应用的介绍
目录
本文是对ChatGPT的由来、训练过程以及实际落地场景的解释,主要内容包括如下三个方面:
1、ChatGPT是什么
2、ChatGPT的原理
3、ChatGPT的思考
4、ChatGPT的应用

ChatGPT是什么
ChatGPT可能是近期深度学习领域,讨论非常频繁的一个概念。但ChatGPT到底是一个什么,怎么给出一个定义呢。可以看下ChatGPT对自己的定义,如下图:
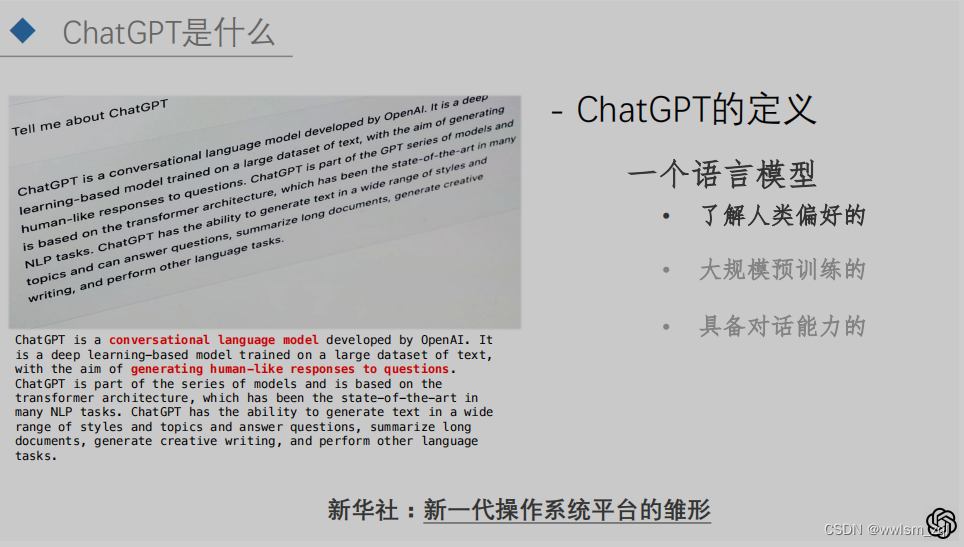
从定义以及我们使用过程中的感受,可以得到如下的结论:
- ChatGPT是一个语言模型
- 了解人类偏好的语言模型
- 是一个大规模预训练的模型
- 表现形式是具备高智能的对话能力
对此,新华社也给出了“新一代操作系统平台的雏形的”评价,可见ChatGPT的横空出世确实带来了一些改变。
模型具有对话能力不是很新奇的事,之前腾讯的混元、百度的ERNIE等大模型都具备对话能力,让ChatGPT出圈并持续火爆的是ChatGPT在如下的测试中也取得了让人惊讶的成绩:

上述的测试不是简单的对话能够解决的,但ChatGPT同样表现得非常出彩,那为什么ChatGPT能够这么优秀?
ChatGPT的原理
过往大模型的发展方向,不外乎:更多的数据、更大的模型结构、更精细的处理方式以及更统一的输入输出等等。但这样训练的大模型,更像是一个图书馆,或者搜索引擎,只具备知识的储存能力和简单的检索能力。
我们以“女朋友生气了怎么办”这个问题为例,过往大模型从网络数据中经过预训练,得到许许多多的答案:你也生气;讲道理;沉默是金;快速认错……但具体哪个答案更符合人类的偏好和认知,模型是不知道的,模型只能根据网络上答案给出反馈。
但可能上述的答案上下文是故意作答、心理测试题、乱写等等情况下的答案,但这些过往的大模型是不知道的。
所以历史的大模型,在训练和使用阶段是没有人工参与的,没有学习到人类的认知和偏好:仅仅是历史数据(网络数据)是存储和检索。

ChatGPT出世前,OpenAI已经进行了一系列的探索,包括生成代码的codex系列和text-davinci系列。这一系列模型的探索过程,构成了指示学习,和RLHF学习方式叠加后,ChatGPT模型才终于横空出世。
监督学习+人工反馈+强化学习 -> ChatGPT
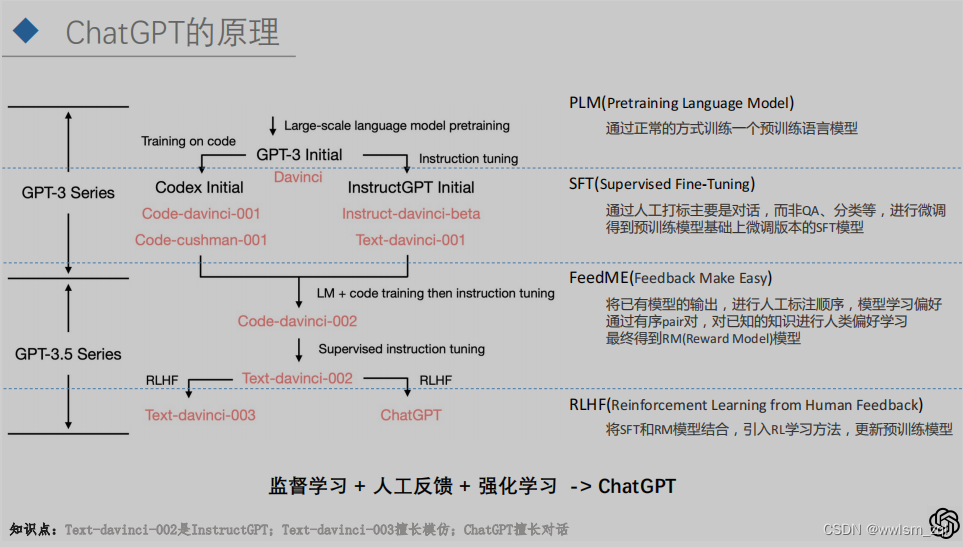
从OpenAI的官方博客,可以看出InstrctGPT和ChatGPT的训练过程如下,存在的差异非常细微:
- 训练数据上的差异
- base模型的差异

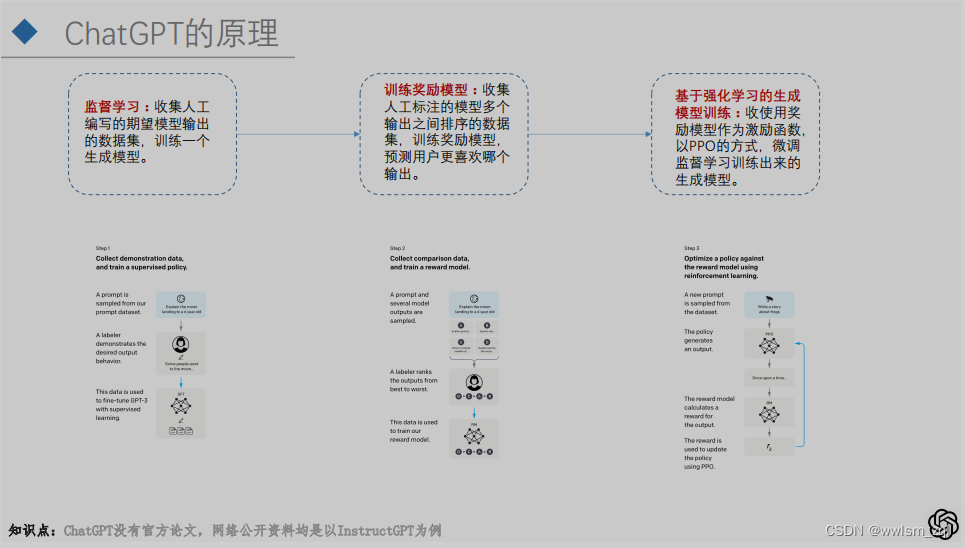
整体的训练思路,InstrctGPT和ChatGPT是相同的,均包括三个步骤:
- 微调模型:监督学习下的微调,通过收集问题后,进行人工答案的书写,来微调GPT基模型,得到SFT模型
- 模型模型:在微调的基础上,通过模型对同一个问题产出不同答案,人工标注答案之间的优劣排序,得到RM模型
- RLHF:在SFT模型和RM模型的辅助下,通过强化学习的PPO策略,最终得到终极模型ChatGPT/InstrctGPT
微调
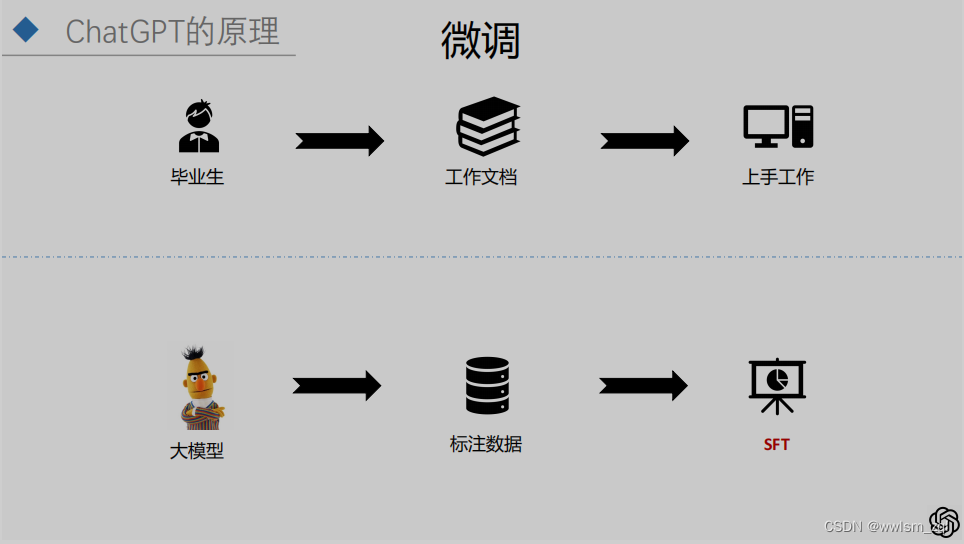
训练过程的第一步:微调。问题来源于早起的Platground的API,人工对问题进行答案的生成。和其他大模型的微调过程是一样的。
这一步的目的是得到后续优化的基模型,以及在强化学习过程中,提供损失函数的约束。

反馈模型
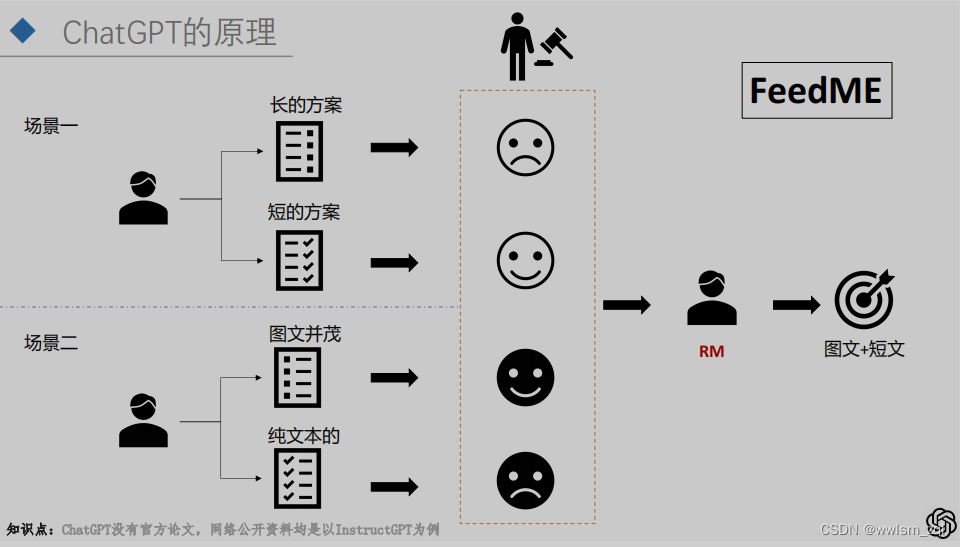
训练过程第二步:RM模型。在已经微调的SFT模型上,通过同一个问题的不同输出,进行人工优劣得分的标注,生成对应的序列。
例如对于问题P,得到的答案为A、B、C和D,人工对答案进行排序为:D>C>B=A,通过模型学习人工排序的结果。也就是让模型模仿人类排序的过程:对SFT模型的输出能够给出优劣的判断。
GPT是字粒度的输出,输出过程的每一步都是在概率分布上的采样,因此,同一个问题多次输入后,会得到不同的输出

RLHF
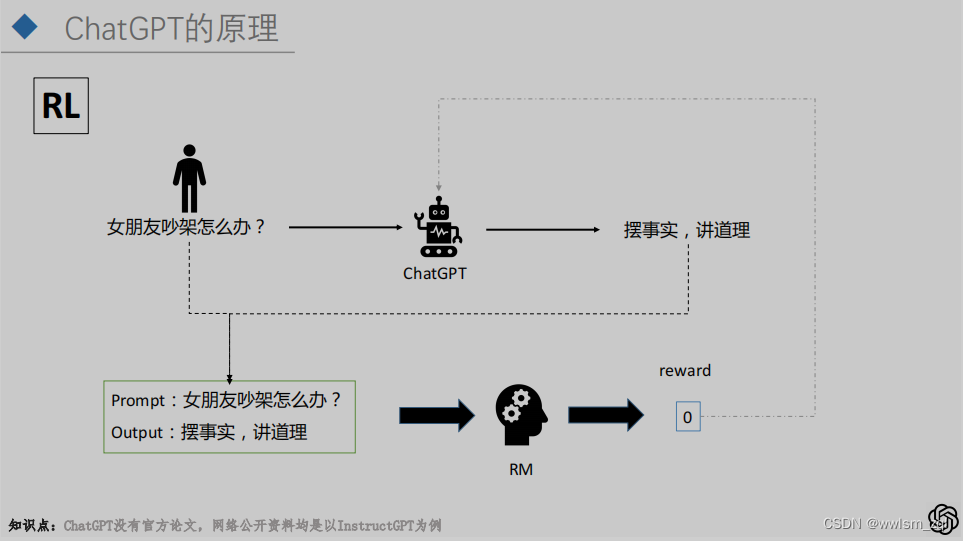
训练过程第三部:PPO策略的强化学习。在已有的SFT模型和RM模型上,结合PPO策略的强化学习,获得最终的ChatGPT/InstrctGPT。该步的大概流程如下:
- 输入问题后,目标模型(以SFT模型初始化获取)得到答案
- 将问题和答案输入RM模型中,得到该答案的得分
- 将该答案通过PPO策略,反馈给目标模型
- 进行模型的更新
通过损失函数可以看出,在实际的训练过程中,RM模型和最终的目标模型,均存在参数的更新

上面的三个步骤,就是InstrctGPT/ChatGPT的大概训练流程。总结起来就是下图:
ChatGPT的思考
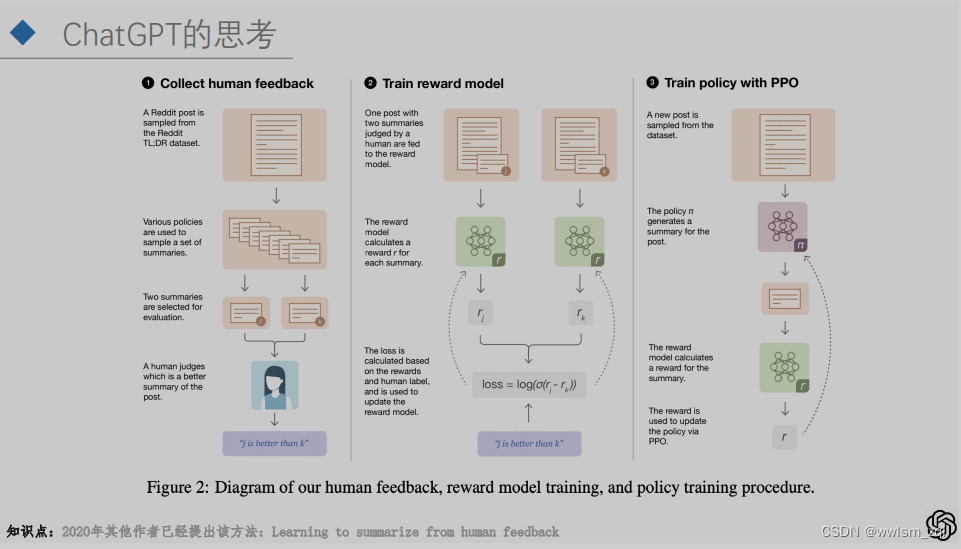
将人类的偏好和认知引入模型训练,并不是ChatGPT或者OpenAI的首创,在2020年一篇做摘要的论文就提出了该思想。只能说是OpenAI的“钞能力”将该方法发扬光大了。
针对ChatGPT,目前其在聊天、翻译、脚本、代码、文案……等诸多领域已经崭露头角了,在ChatGPT表现其“无所不能”的同时,我们也可以考虑下其目前存在的问题有哪些呢。
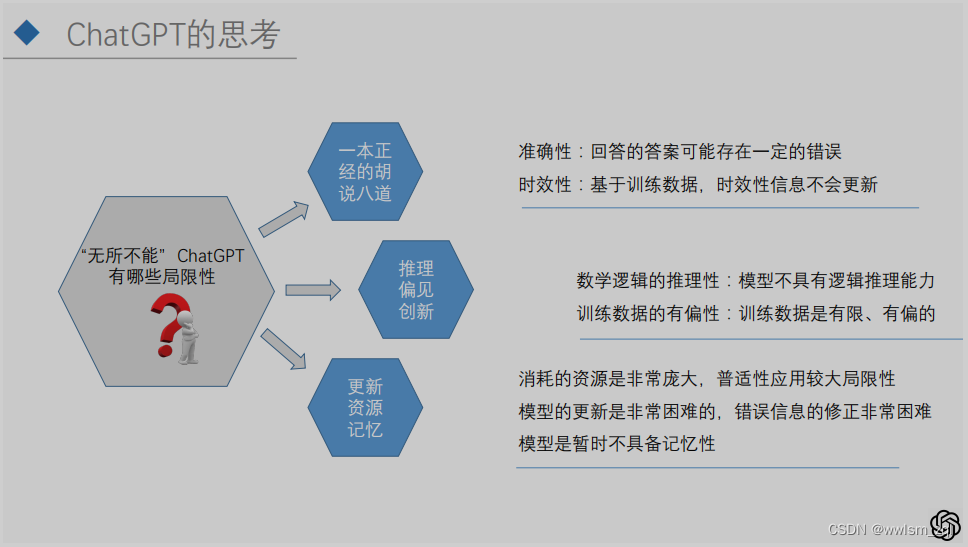
目前来说,
- ChatGPT的准确性已经非常高,但对于特定问题可能在一本正经的胡说八道,当然目前其不具备联网更新能力,训练语料为2021年之前的,最新的知识可能更新是一方面的问题;
- 关于逻辑性和数据的偏见,是目前大模型普遍存在的问题,期待后续模型能够在这方面带来惊艳的表现
- 资源是限制ChatGPT普适性推广的核心关键,其训练数据规模、推理依赖的资源,都是海量的,在这些成本没有降低前,大模型应该还仅仅是固定厂商的利器。
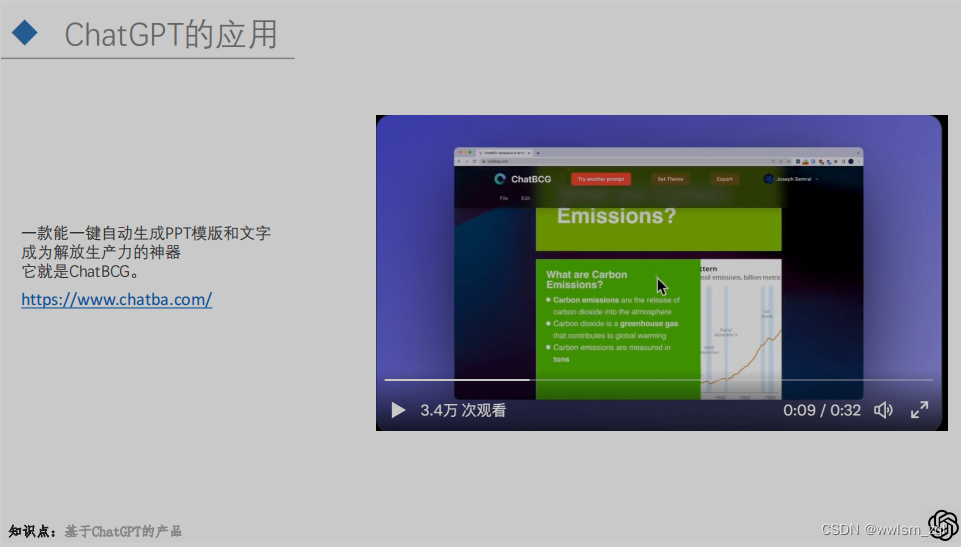
ChatGPT的应用
随着ChatGPT的爆火,也带来了一些实际的落地应用,例如下面的几个应用,都是非常有意思的:
- 对话式PDF阅读助手:通过上传文档,然后对话沟通的方式,获取论文、文献的内容要点
- AI PPT生成:ChatGPT和AIGC结合产生的质变
- 写作:写故事、写文案、写小说、写PPT,只要是文字范围的,一切皆有可能


总的来说,期待ChatGPT后续的表现。