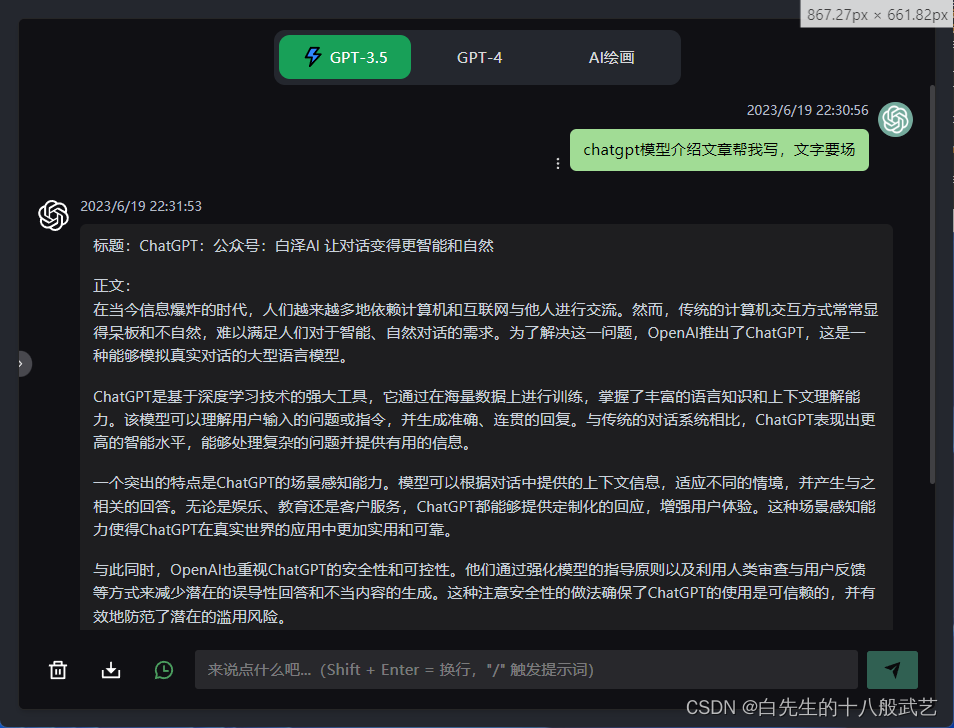
ChatGPT作为最接近强人工智能的系统,具有强大的信息理解和信息抽象总结能力,在这个信息过剩的时代,为我们提供了一个非常好的智能辅助工具。在我们日常的工作中,怎么充分的利用ChatGPT等类似的智能系统,会给我们生活和工作带来不一样的体验。
后面我们将从chatGPT算法流程作为切入点,分别介绍ChatGPT背后的三个深度学习模型,正是这三个基础的模型铸就了ChatGPT强大的文本信息理解表达能力。
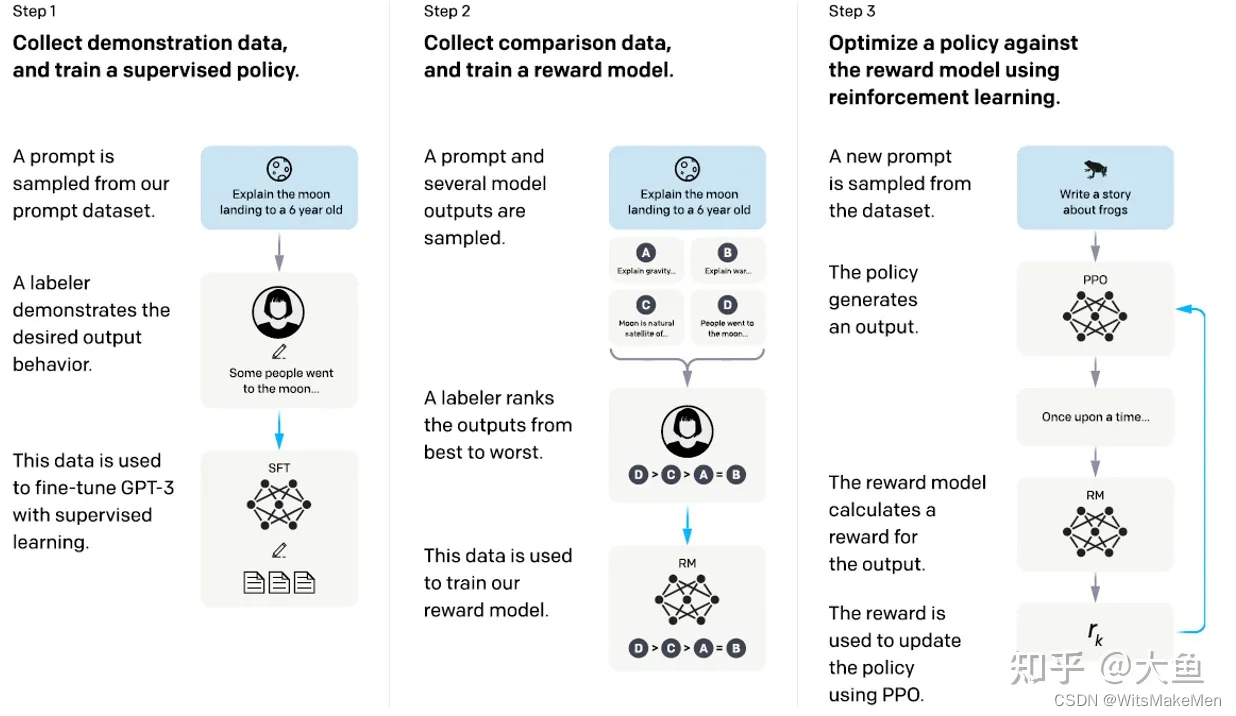
书归正传,让我们来体验下chatGPT大道至简的神奇算法。
首先从数据库中采样一批prompt提示,然后让人工标注人员编写对应prompt答案。我们利用<prompt,prompt答案>来微调预训练好的GPT-3模型,微调后的模型SFT模型。
第二步,随机采样的一个prompt,让我们微调好的GPT-3模型预测多个答案【<prompt, 答案1>, <prompt, 答案2>…】,人工对比排序同一个prompt好坏情况,然后排序。在利用微调后的GPT-3模型构造一个RM奖励模型,利用人工标注答案顺序,训练RM奖励模型,类似于LambdaRank思想。
第三步,构造一个双头PPO模型,对于一个新采样的prompt提示,生成对应的答案,然后利用RM奖励模型,评测当前生成答案的得分score,并用score反向更新优化PPO模型。
SFT监督模型
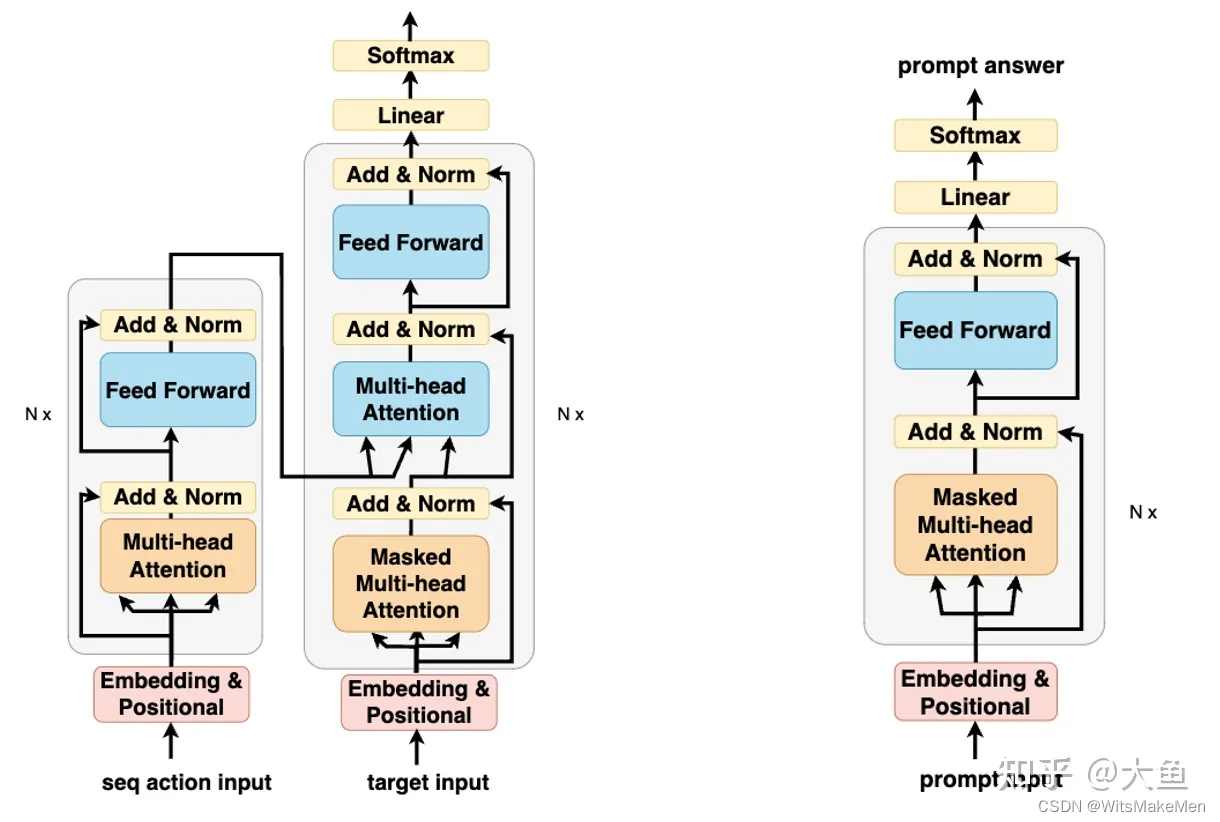
SFT模型是微调后的GPT模型,说到GPT模型就不能介绍下大名鼎鼎的Transformer模型,Transformer模型是一个典型的encode-decode模型结构,模型是为了解决LSTM等序列生成模型训练速度慢的问题。
GPT模型和BERT模型是一对孪生兄妹,BERT模型使用了Transformer模型的encoder部分,而GPT模型使用的正好是Transformer模型的decoder部分(改造去掉了第二层multi-head attention),为什么GPT要使用decoder部分而不是encoder部分呢?这就要说到GPT设计之初要解决的问题,和BERT用来抽取文本序列信息不同,GPT生来就是为了生成序列,为了结合前序提示,生成我们后续的答案,所以我们要用Masked Attention,不能让模型看到答案,这就是GPT和BERT的本质区别。
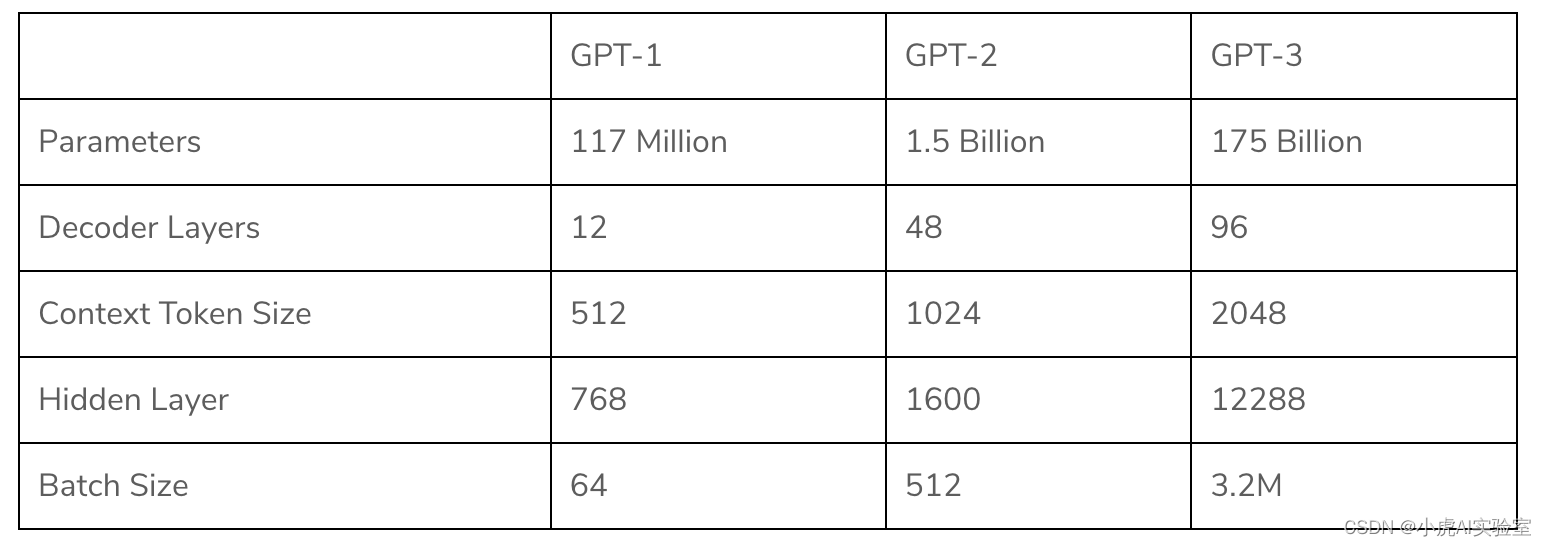
GPT模型结构如下图所示,GPT-3将模型层数升级到了百层,模型参数升级到几千亿,在这千亿的参数中,总会储存想要的信息。
RM模型
如果我们是有SFT模型,那模型对于我们输入的prompt提示或者问题,是不会给出我们满意答案的,为什么呢?因为SFT模型训练的目标并不是让人类满意,所以他诞生和成长之初,压根也没有打算让人类满意,他训练自身的目的就是更大概率的生成下一个字符,这显然不能完全代表人类的喜好。
那我们怎么解决这样的一个问题呢?那就构造一个可以代替人来评估生成结果好坏的RM模型,这个模型结构和SFT模型是完全一样的,只不过将输出层改造成输出张量的模型层。对于同一个prompt输出的多个答案,人工评测排序后,使用lambdarank的思想,优化RM奖励模型。RM模型学习的就是对于一个prompt,人类对答案的喜好程度。
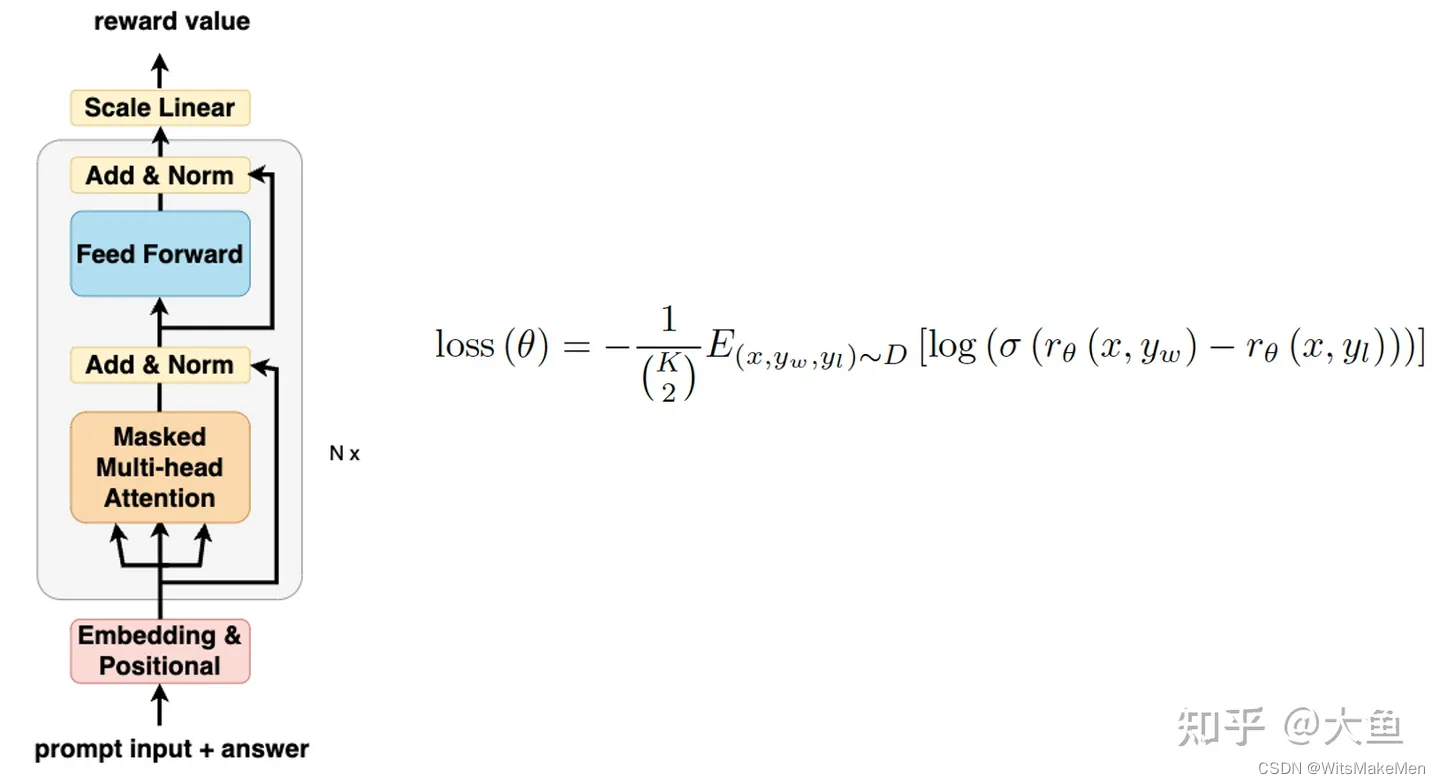
PPO模型
上面我们花了这么大力气,训练了代表人类喜好的RM模型,这样一个喜好函数有什么用呢?这就要说到我们的PPO模型,我们之前微调的SFT模型,虽然也能够生成prompt answer,但是这是一个没有感情的answer,完全是根据海量文本中上下文共现概率生成的,没有加入任何的人类喜好和意志。
怎么让这个SFT模型按照人类的喜好,生成人类喜欢的prompt呢?这就我们RM模型的作用,RM模型通过上一步人工排序标注的方式,学习到了每对<prompt, prompt answer>人类评测的好坏程度。我们利用SFT模型对输出进行改造,构造一个双头PPO模型,模型一头输出一个张量,代表生成序列每个元素的价值value;另一头将输出映射成prompt answer词典答案。
我们将<prompt, prompt answer>输入到RM模型中,获得一个评估当前prompt对的奖励R,然后用R作为奖励,反向更新每个元素的价值value,这也就是所谓的PPO强化学习算法。
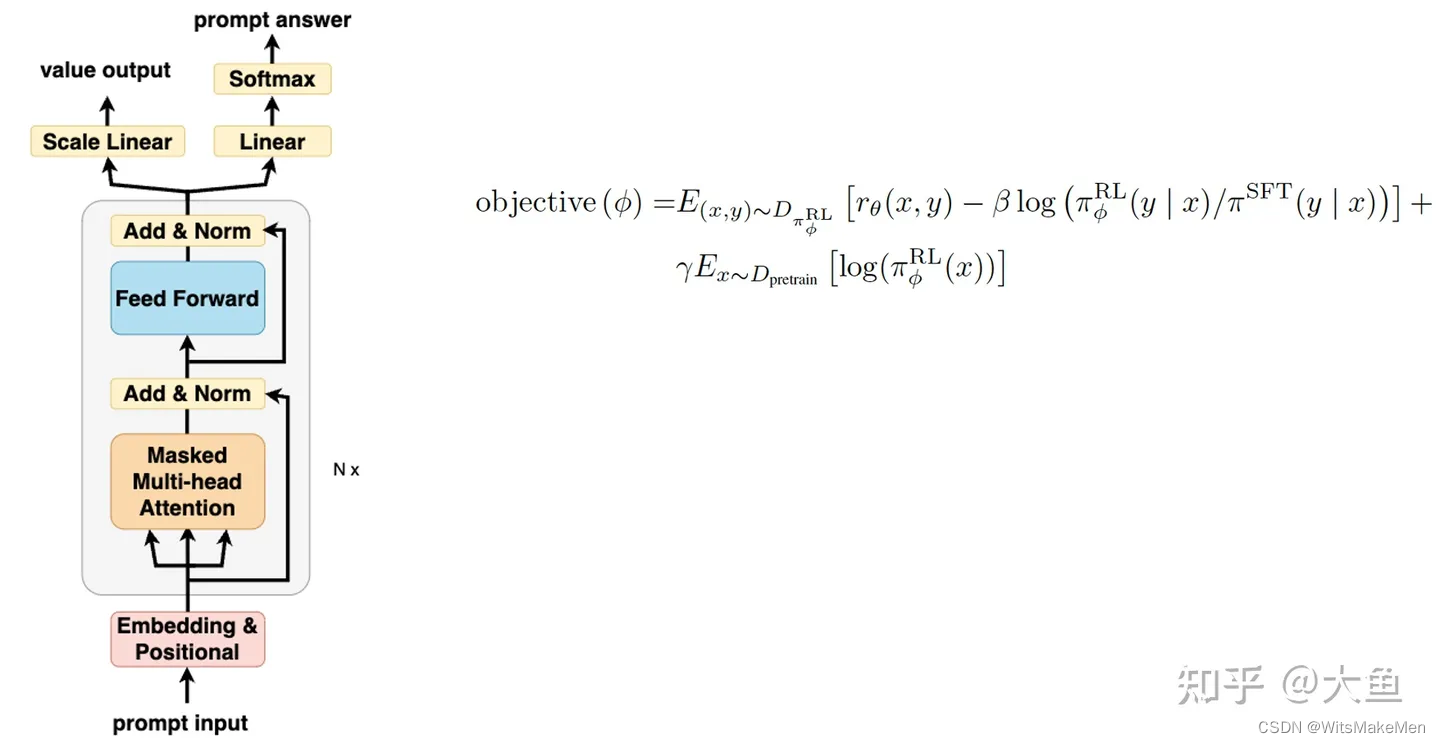
以上就是ChatGPT基本的模型算法和背后的三个主要的算法模型,其实模型基本的结构和背后的算法并是不第一次提出和应用,但是ChatGPT创新的应用,将强化学习和NLP文本生成很好的结合在了一起,将生成的文本序列融入了人类的喜好,生成的内容更像是一个人在回答我们的prompt,这也就是为什么生成的内容,让我们看起来更舒服更自然。