搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源)

专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源)
前人栽树后人乘凉,本专栏提供资料:
- 推荐系统算法库,包含推荐系统经典及最新算法讲解,以及涉及后续业务落地方案和码源
- 本专栏会持续更新业务落地方案以及码源。同时我也会整理总结出有价值的资料省去你大把时间,快速获取有价值信息进行科研or业务落地。帮助你快速完成任务落地,以及科研baseline
相关文章推荐:
推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐,业界广告推荐技术最新进展
推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF/TDM/Airbnb Embedding/Item2vec等)、召回路径简介、多路召回融合]
推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,Wide&Deep等模型)以及前沿技术
推荐系统[四]:精排-详解排序算法LTR (Learning to Rank): poitwise, pairwise, listwise相关评价指标,超详细知识指南。
推荐系统[五]:重排算法详解相关概念、整体框架、常用模型;涉及用户体验[打散、多样性],算法效率[多任务融合、上下文感知]等
推荐系统[六]:混排算法简介、研究现状混排技术以及MDP-DOTA信息流第三代混排调控框架,高质量项目实战。
推荐系统[七]:推荐系统通用技术架构(Netfilx等)、API服务接口
推荐系统[八]:推荐系统常遇到问题和解决方案[物品冷启动问题、多目标平衡问题、数据实时性问题等]
实战案例:
推荐系统[八]算法实践总结V0:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
推荐系统[八]算法实践总结V1:腾讯音乐全民K歌推荐系统架构及粗排设计
推荐系统[八]算法实践总结V2:排序学习框架(特征提取标签获取方式)以及京东推荐算法精排技术实战
推荐系统[八]算法实践总结V3:重排在快手短视频推荐系统中的应用and手淘信息流多兴趣多目标重排技术
推荐系统[八]算法实践总结V4:混排算法在淘宝信息流第四代混排调控框架实战,提升推荐实时性捕捉实时兴趣。
更多更新请查看专栏内容
1.前言:召回排序流程策略算法简介
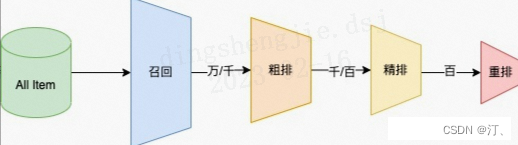
推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:
- 召回是源头,在某种意义上决定着整个推荐的天花板;
- 粗排是初筛,一般不会上复杂模型;
- 精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;
- 重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;
-
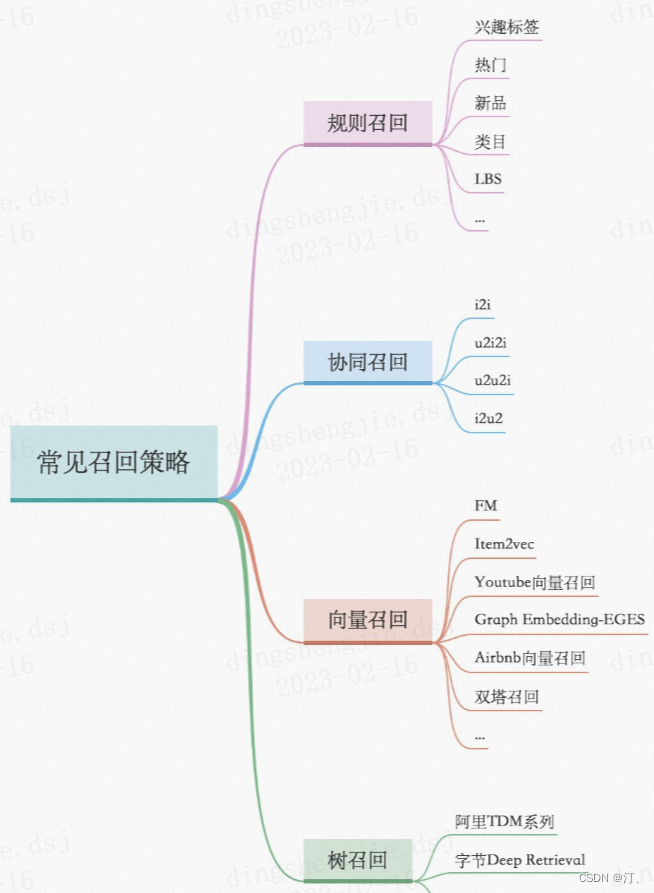
召回层:召回解决的是从海量候选item中召回千级别的item问题
- 统计类,热度,LBS;
- 协同过滤类,UserCF、ItemCF;
- U2T2I,如基于user tag召回;
- I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);
- U2I类,如DSSM、YouTube DNN、Sentence Bert;
-
模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回
-
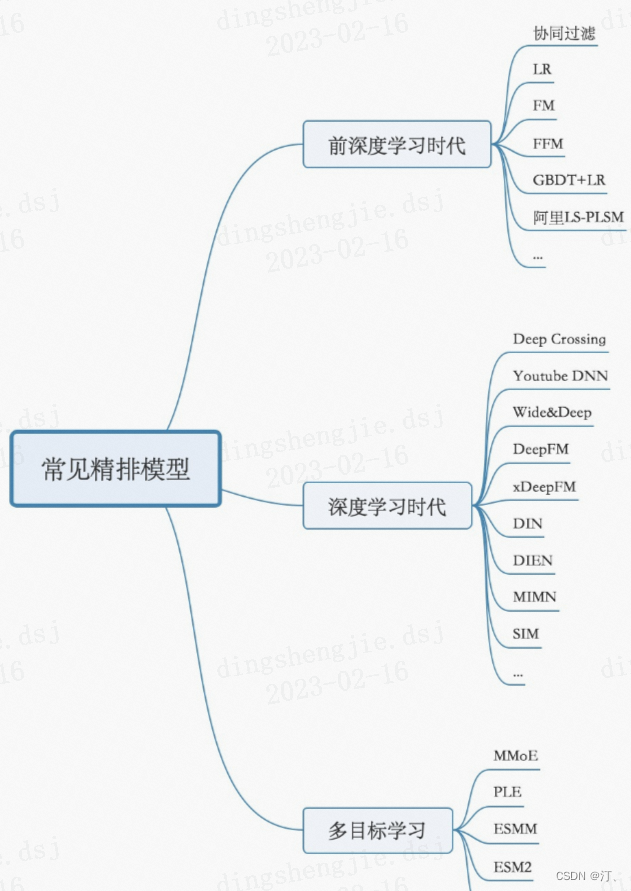
排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
- 常见的特征挖掘(user、item、context,以及相互交叉);
- 精排层:精排解决的是从千级别item到几十这个级别的问题
- CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN
- 多目标:MOE,MMOE,MTL(多任务学习)
- 打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
-
重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)
-
展示层:
- 推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等
- 首图优选:CNN抽特征,汤普森采样
-
探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等
-
产品层:交互式推荐、分tab、多种类型物料融合
2.召回算法简介
召回区分主路和旁路,主路的作用是个性化+向上管理,而旁路的作用是查缺补漏
推荐系统的前几个操作可能就决定了整个系统的走向,在初期一定要三思而后行
做自媒体,打广告,漏斗的入口有多大很重要。
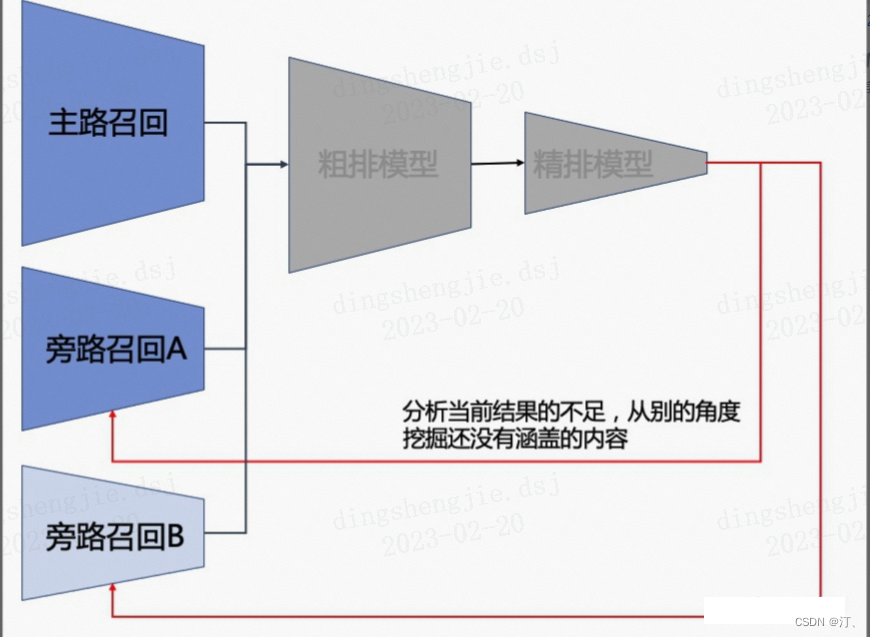
召回这里稍微有些复杂,因为召回是多路的。首先我们要解释主路和旁路的差别,主路的意义和粗排类似,可以看作是一个入口更大,但模型更加简单的粗排。主路的意义是为粗排分担压力。但是旁路却不是这样的,旁路出现的时机往往是当主路存在某种机制上的问题,而单靠现在的这个模型很难解决的时候。举个例子,主路召回学的不错,但是它可能由于某种原因,特别讨厌影视剧片段这一类内容,导致了这类视频无法上升到粗排上。那这样的话整个系统推不出影视剧片段就是一个问题。从多路召回的角度来讲,我们可能需要单加一路专门召回影视剧的,并且规定:主路召回只能出3000个,这一路新加的固定出500个,两边合并起来进入到粗排中去。这个栗子,是出现旁路的一个动机。
2.1 召回路径介绍
推荐系统中的i2i、u2i、u2i2i、u2u2i、u2tag2i,都是指推荐系统的召回路径。
-
第一种召回,是非个性化的。比如对于新用户,我们要确保用最高质量的视频把他们留住,那么我们可以划一个“精品池”出来,根据他们的某种热度排序,作为一路召回。做法就是新用户的每次请求我们都把这些精品池的内容当做结果送给粗排。这样的召回做起来最容易,用sql就可以搞定。
-
第二种召回,是i2i,i指的是item,严格意义上应该叫u2i2i。指的是用用户的历史item,来找相似的item。比如说我们把用户过去点过赞的视频拿出来,去找画面上,BGM上,或者用户行为结构上相似的视频。等于说我们就认为用户还会喜欢看同样类型的视频。这种召回,既可以从内容上建立相似关系(利用深度学习),也可以用现在比较火的graph来构建关系。这种召回负担也比较小,图像上谁和谁相似完全可以离线计算,甚至都不会随着时间变化。
-
第三种召回是u2i,即纯粹从user和item的关系出发。我们所说的双塔就是一个典型的u2i。在用户请求过来的时候,计算出user的embedding,然后去一个实现存好的item embedding的空间,寻找最相似的一批拿出来。由于要实时计算user特征,它的负担要大于前面两者,但这种召回个性化程度最高,实践中效果也是非常好的。
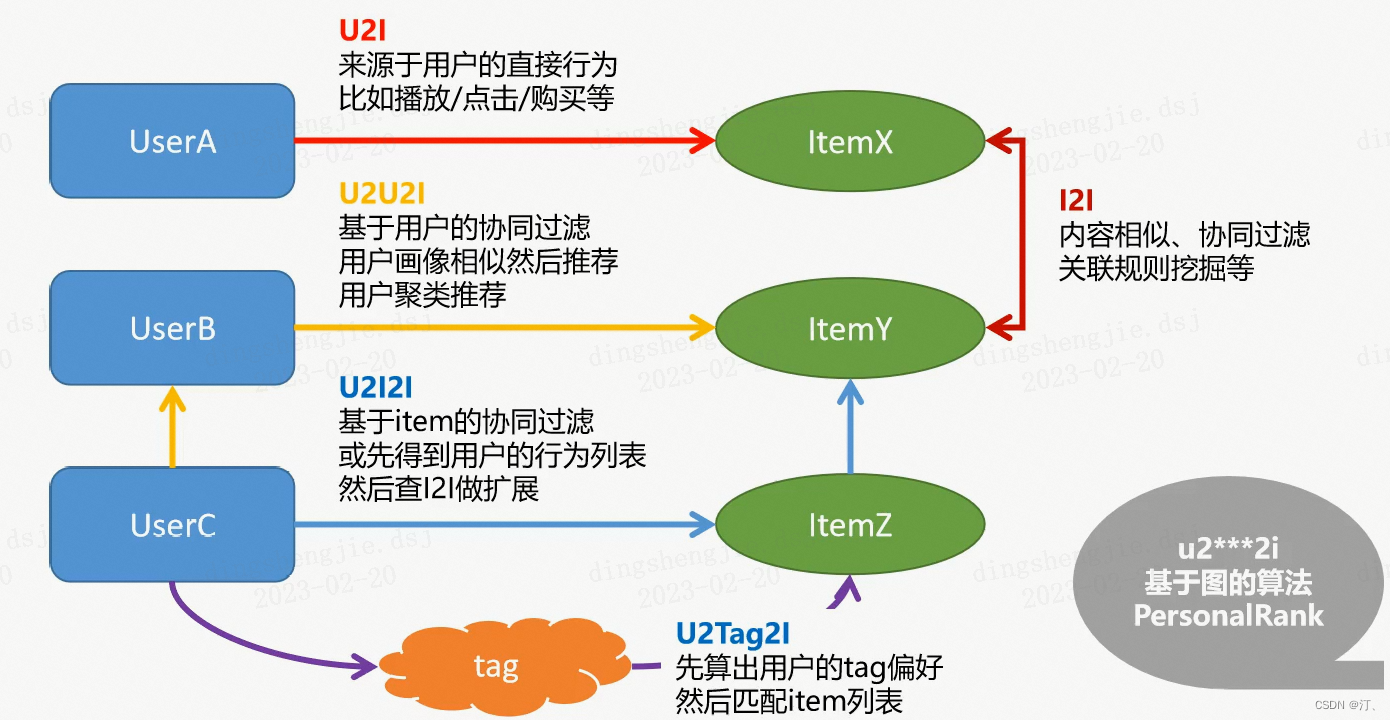
通过上图理解什么是召回路径:
- u、i、tag是指图中的节点
- 2是指图中的线(关系)
i2i:指从一个物品到达另外一个物品,item 到 item
- 应用:头条,在下方列出相似的、相关的文章;
- 算法:
- 内容相似,eg:文章的相似,取标题的关键字,内容相似
- 协同过滤
- 关联规则挖掘等
- 两个物品被同时看的可能性很大,当一个物品被查看,就给他推荐另一个物品
u2i:指从一个用户到达一个物品,user 到item
- 一般指用户的直接行为,比如播放、点击、购买等;
- 用户查看了一个物品,就会再次给它推荐这个物品
- 结合i2i一起使用,就是用户查看以合物品,就会给他推荐另一个相似的物品,就是u2i2i路径;
u2i2i:从一个用户,通过一个物品,到达另一个物品
- 用户查看了一个耳机(u2i),找出和这个耳机相似或者相关的产品(i2i)并推荐给用户
- 对路径的使用,已经从一条线变成两条线
- 方法:就是把两种算法结合起来,先得到u2i的数据,再利用i2i的数据进行扩展,就可以从第一个节点,越过一个节点,到达第三个节点,实现推荐
- 中间的桥梁是item
u2u2i:从一个用户,到达另一个用户,到达一个物品
- 先计算u2u:两种方法
- 一是:取用户的性别、年龄、职业等人工属性的信息,计算相似性,得到u2u;
- 一是:从行为数据中进行挖掘,比如看的内容和视频大部分很相似,就可以看作一类人;
- 也可以使用聚类的方法进行u2u计算
- u2u一般用在社交里,比如微博、Facebook,推荐感兴趣的人
- userB和UserC相似,如果userB查看了某个商品,就把这个商品推荐给userC;
- 中间的桥梁是user
u2tag2i:中间节点是Tag标签,而不是 u 或者 i
-
京东,豆瓣,物品的标签非常丰富、非常详细;比如统计一个用户历史查看过的书籍,就可以计算标签偏好的向量:标签+喜欢的强度。
-
用户就达到了tag的节点,而商品本身带有标签,这就可以互通,进行推荐
-
先算出用户的tag偏好,然后匹配item列表
-
这种方法的泛化性能比较好(推荐的内容不那么狭窄,比如喜欢科幻,那么会推荐科幻的所有内容)
-
今日头条就大量使用标签推荐
基于图的算法:u22i*
-
起始于U,结束于I,中间跨越很多的U、很多的I,可以在图中不停的游走
-
例如:PersonalRank,不限制一条还是两条线,在图中到处的游走,游走带着概率,可以达到很多的item;但是相比前面一条、两条边的路径,性能不是很好
2.2 多路召回融合排序
2.2.1 多路召回
推荐服务一般有多个环节(召回、粗排序、精排序),一般会使用多个召回策略,互相弥补不足,效果更好。比如说:
- 实时召回- U2I2I,
- 几秒之内根据行为更新推荐列表。
- 用U2I得到你实时的行为对象列表,再根据I2I得到可能喜欢的其他的物品
- 这个是实时召回,剩下3个是提前算好的
- 基于内容 - U2Tag2I
- 先算好用户的偏好tag,然后对tag计算相似度,获取可能感兴趣的item
- 矩阵分解 - U2I
- 先算好User和Item的tag矩阵,然后叉乘,给每个user推荐item
- 提前存储好进行推荐
- 聚类推荐 - U2U2I
- 根据用户信息对用户进行聚类,然后找到最相似的user,推荐最相似user喜欢的物品;或者找到聚类中大家喜欢的物品,进行推荐
写程序时,每个策略之间毫不相关,所以:
1、一般可以编写并发多线程同时执行
2、每一种策略输出结果,都有一个顺序,但最后要的结果只有一个列表,这就需要融合排序
2.2.2 融合排序
多种召回策略的内容,取TOPN合并成一个新的列表。这个新的列表,可以直接返回给前端,进行展示;也可以发给精排,进行排序。
精排模型非常耗时,所以召回的内容,会经过粗排之后,把少量的数据给精排进行排序
几种多路召回结果融合的方法
举个例子:几种召回策略返回的列表(Item-id,权重)分别为:
| 召回策略 | 返回列表 | ||
|---|---|---|---|
| 召回策略X | A:0.9 | B:0.8 | C:0.7 |
| 召回策略Y | B:0.6 | C:0.5 | D:0.4 |
| 召回策略Z | C:0.3 | D:0.2 | E:0.1 |
融合策略:
1、按顺序展示
- 比如说实时 > 购买数据召回 > 播放数据召回,则直接展示A、B、C、D、E
2、平均法
- 分母为召回策略个数,分子为权重加和
- C为(0.7+0.5+0.3)/3,B为(0.8+0.6)/3
3、加权平均
- 比如三种策略自己指定权重为0.4、0.3、0.3,则B的权重为(0.40.8 + 0.60.3 + 0*0.2)/ (0.4+0.3+0.2),这个方法有个问题就是,每个策略的权重是自己设置的,并不准确,所以,有动态加权法
4、动态加权法
- 计算XYZ三种召回策略的CTR,作为每天更新的动态加权
- 只考虑了点击率,并不全面
- 每种召回源CTR计算方法:
- 展现日志-带召回源:X,Y,Z,X,Y,Z
- 点击日志-带召回源:点击X
- 则每种召回的CTR = 点击数/展现数
5、机器学习权重法
- 逻辑回归LR分类模型预先离线算好各种召回的权重,然后做加权召回
- 考虑更多的特征以及环境因素,会更准确
以上融合排序的方法,成本逐渐增大,效果依次变好,按照成本进行选择
3.推荐场景中召回模型的演化过程
3.1 传统方法:基于协同过滤
协同过滤可分为基于用户的协同过滤、基于物品的协同过滤,基于模型的协同过滤 ( 比如 MF 矩阵分解等 )。这部分不详细讲解,网上资料很多。这里说下基于 item 的协同过滤方法吧,主要思想是:根据两个 item 被同时点击的频率来计算这两个 item 之间的相似度,然后推荐用户历史行为中各个 item 的相似相关 item。虽然基于用户的协同过滤召回方法具有简单、性能较高,因此在实际的推荐场景中用途十分广泛。不过也是有天然的缺陷:召回结果的候选集 item 限定在用户的历史行为类目中,并且难以结合候选 item 的 Side Information ( 比如 brand,品类一些 id 信息 ),导致其推荐结果存在发现性弱、对长尾商品的效果差等问题,容易导致推荐系统出现 “越推越窄” 的问题,制约了推荐系统的可持续发展。
3.2 单 Embedding 向量召回
这部分工作主要介绍单 embedding 向量召回 ( 每个 user 和 item 在一个时刻只用一个 embedding 向量去表示 ) 的一些经典方法,其主要思想为:将 user 和 item 通过 DNN 映射到同一个低维度向量空间中,然后通过高效的检索方法去做召回。
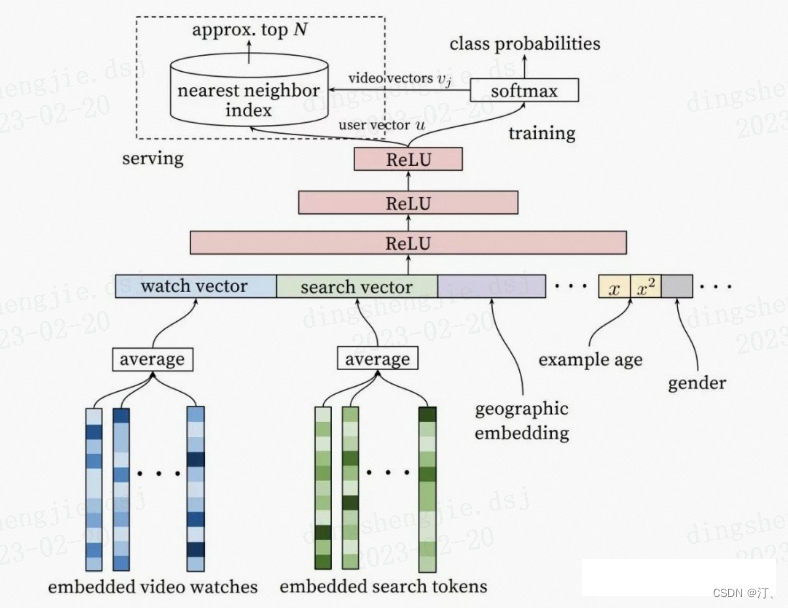
3.2.1 Youtube DNN 召回
-
使用特征:用户观看过视频的 embedding 向量、用户搜索词的 embedding 向量、用户画像特征、context 上下文特征等。
-
训练方式:三层 ReLU 神经网络之后接 softmax 层,去预测用户下一个感兴趣的视频,输出是在所有候选视频集合上的概率分布。训练完成之后,最后一层 Relu 的输出作为 user embedding,softmax 的权重可当做当前预测 item 的 embedding 表示。
-
线上预测:通过 userId 找到相应的 user embedding,然后使用 KNN 方法 ( 比如 faiss ) 找到相似度最高的 top-N 条候选结果返回。
3.2.2 双塔模型召回
双塔模型基本是:两侧分别对 user 和 item 特征通过 DNN 输出向量,并在最后一层计算二个输出向量的内积。
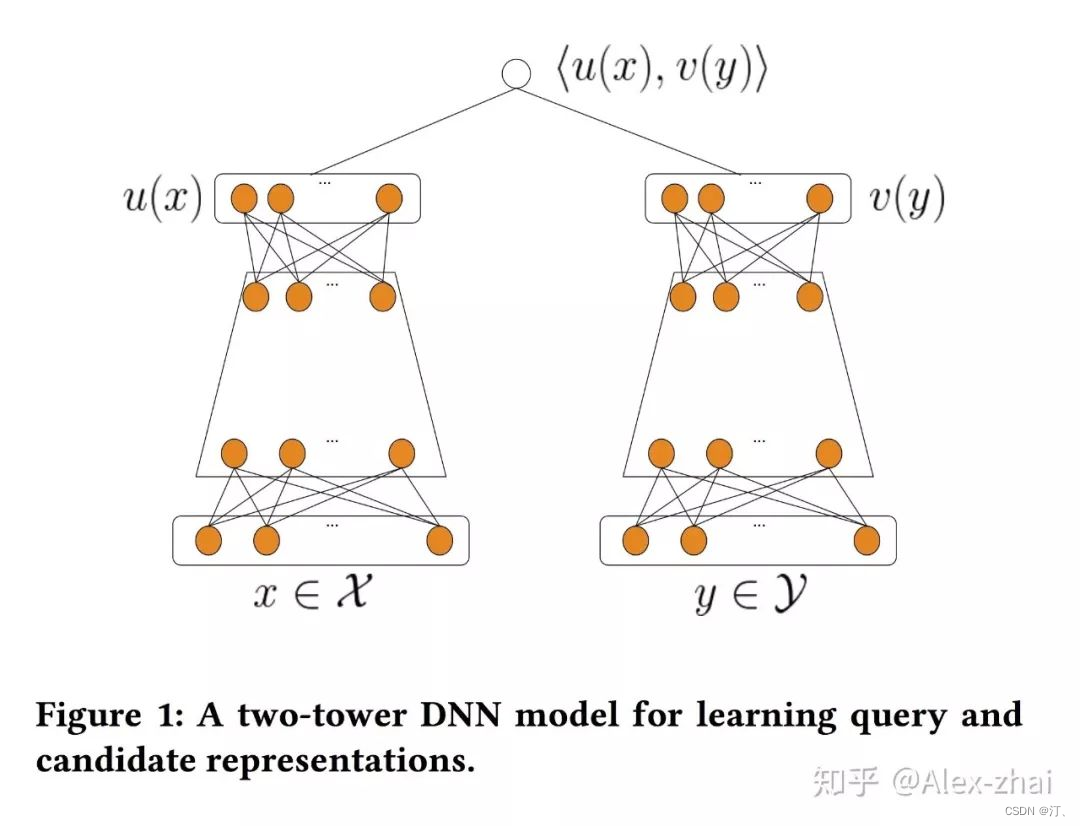
例如 YouTube 今年刚发的一篇文章就应用了经典的双塔结构:
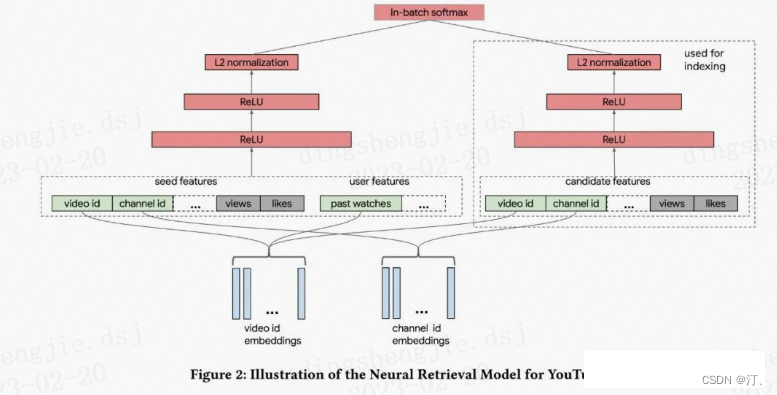
3.2 多 Embedding 向量召回-用户多兴趣表达
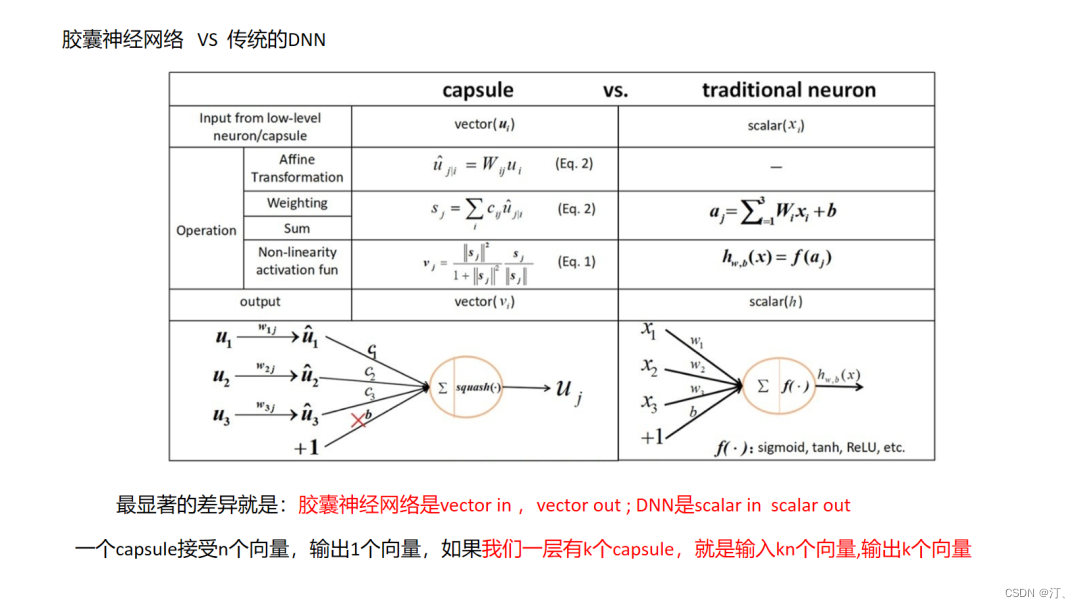
3.2.1 Multi-Interest Network with Dynamic Routing 模型
背景:电商场景下用户行为序列中的兴趣分布是多样的,如下图用户 A 和 B 的点击序列商品类别分布较广,因此如果只用一个 embedding 向量来表示用户的兴趣其表征能力是远远不够的。所以需要通过一种模型来建模出用户多个 embedding 的表示。
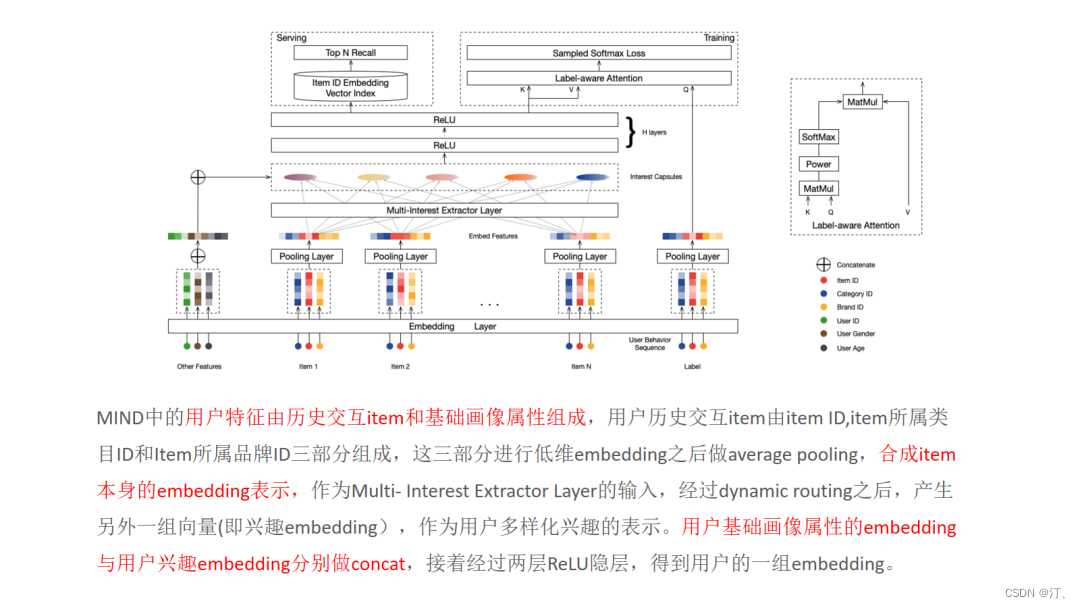
MIND 模型通过引入 capsule network 的思想来解决输出多个向量 embedding 的问题,具体结构如下图:
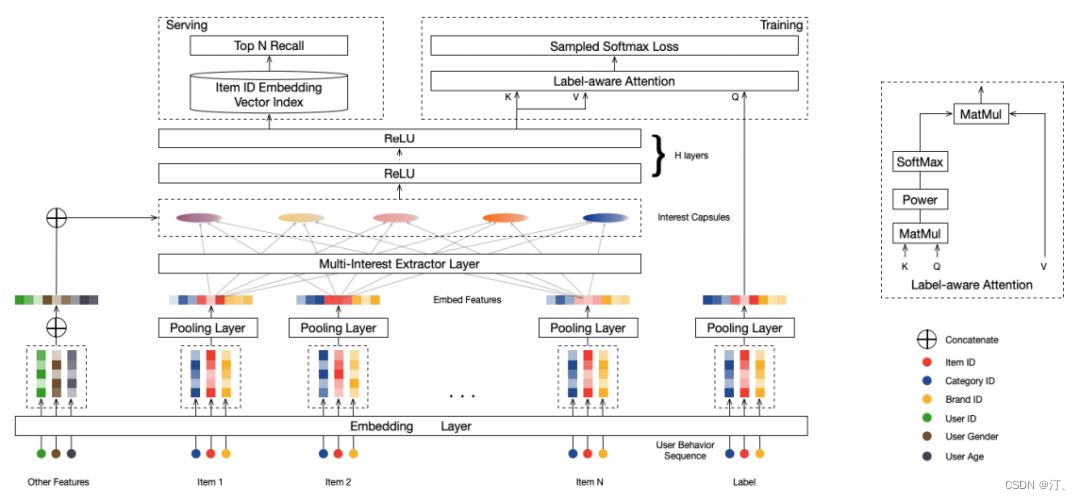
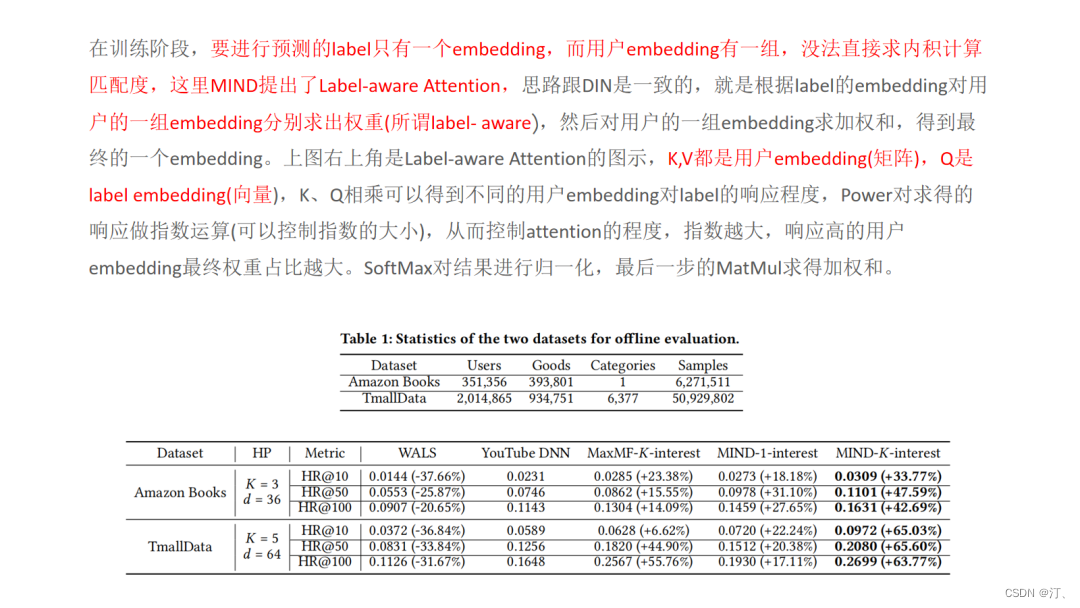
训练:Multi-Interest 抽取层负责建模用户多个兴趣向量 embedding,然后通过 Label-aware Attention 结构对多个兴趣向量加权。这是因为多个兴趣 embedding 和待推荐的 item 的相关性肯定不同 ( 这里的思想和 DIN 模型如出一辙 )。其中上图中的 K,V 都表示用户多兴趣向量,Q 表示待推荐 item 的 embedding 表示,最终用户的 embedding 表示为:
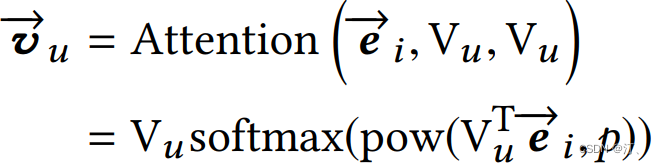
公式中的 ei 表示 item embedding,Vu 表示 Multi-Interest 抽取层输出的用户多个兴趣向量 embedding。
然后使用 Vu 和待推荐 item embedding,计算用户 u 和商品 i 交互的概率,计算方法和 YouTube DNN 一样:
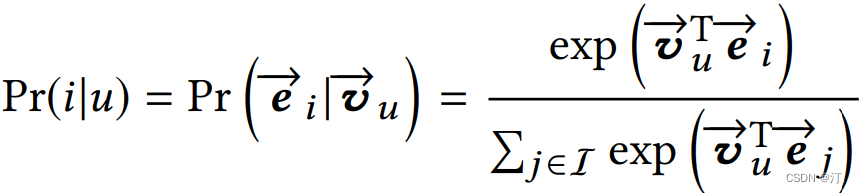
线上 serving:在线计算用户的多个兴趣向量后,每个兴趣向量 embedding 通过 KNN 检索得到最相似的 Top-N 候选商品集合。这里有个问题大家思考下?得到多个兴趣向量后通过权重将这些向量的 embedding 累加起来成为一个 ( 表示为多个向量的加权和 ),然后只去线上检索这一个 embedding 的 Top-N 相似。
3.3 Graph Embedding
3.3.1 阿里 Graph Embedding with Side information
传统的 graph embedding 过程如下图:
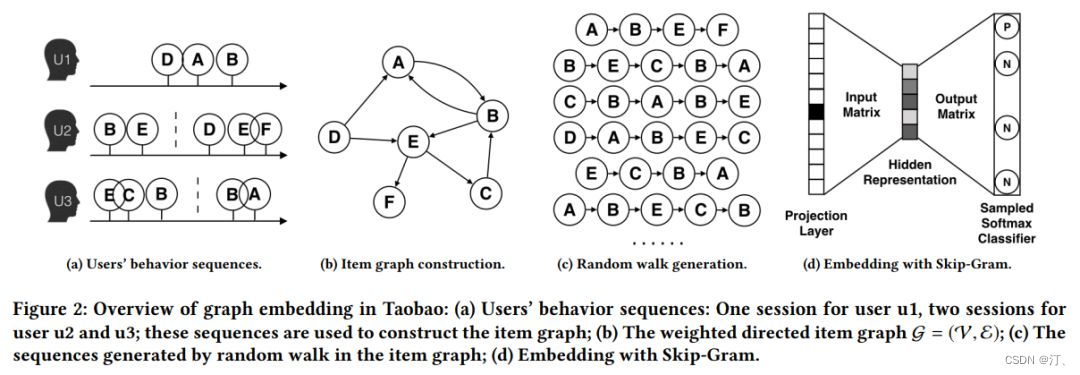
其实就是通过 “构图 -> 随机游走得到序列 -> word2vec 训练” 三部曲得到每个 item 的 embedding 表示。但是这样训练出来的模型会存在冷启动问题。就是那些出现次数很少或者从来没在序列中出现过的 item embedding 无法精确的表征。本文通过添加 side information ( 比如商品的种类、品牌、店铺 id 等 ) 等辅助类信息来缓解该问题,如下图 SI 1 - SI n 表示 n-1 个辅助 id 特征的 embedding 表示。
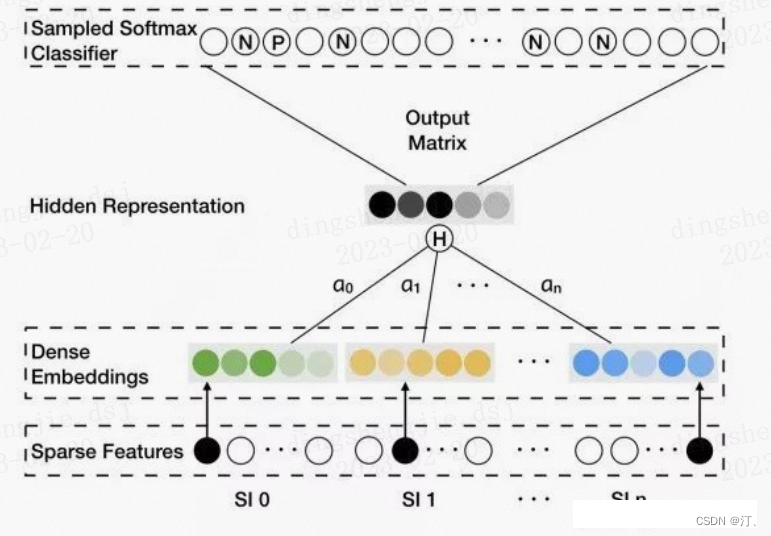
该模型的亮点是考虑了不同的 side information 在最终的 aggregated embeddings 中所占的权重是不同的,最后 aggregated embeddings 计算公式如下,其中分母用来归一化。
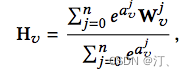
3.3.2 GraphSAGE:Inductive representation learning on large graphs
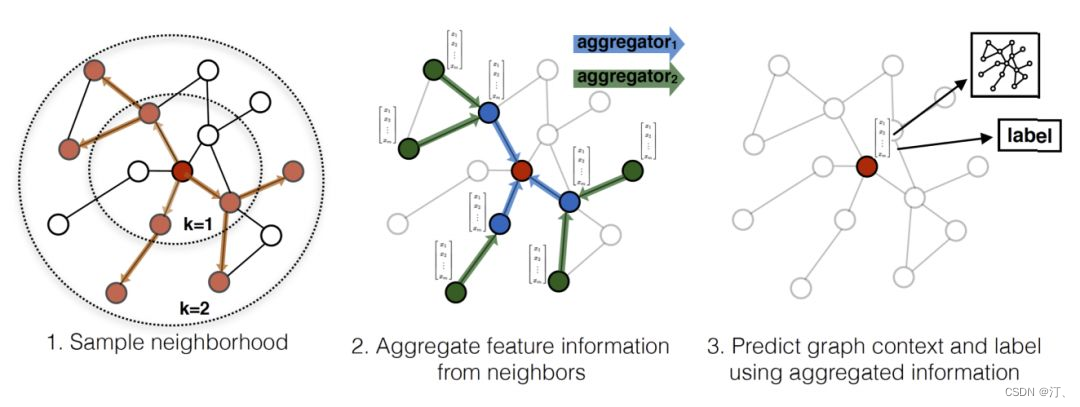
经典的图卷积神经网络 GCN 有一个缺点:需要把所有节点都参与训练才能得到 node 的 embedding,无法快速得到新 node 的 embedding。这是因为添加一个新的 node,意味着许多与之相关的节点的表示都应该调整。所以新的 graph 图会发生很大的变化,要想得到新的 node 的表示,需要对新的 graph 重新训练。
GraphSAGE 的基本思想:学习一个 node 节点的信息是怎么通过其邻居节点的特征聚合而来的。算法如下:

大致流程是:对于一个 node 需要聚合 K 次,每次都通过聚合函数 aggregator 将上一层中与当前 node 有邻接关系的多个 nodes 聚合一次,如此反复聚合 K 次,得到该 node 最后的特征。最下面一层的 node 特征就是输入的 node features。
3.4 结合用户长期和短期兴趣建模
3.4.1 SDM: Sequential Deep Matching Model for Online Large-scale Recommender System
背景:在电商场景中,用户都会有短期兴趣和长期兴趣,比如在当前的浏览session内的一个点击序列,用户的需求往往是明确的,这属于用户短期的兴趣。另外用户还有一些长期的兴趣表达,比如品牌、店铺的偏好。因此通过模型分别建模用户的长、短期兴趣是有意义的。
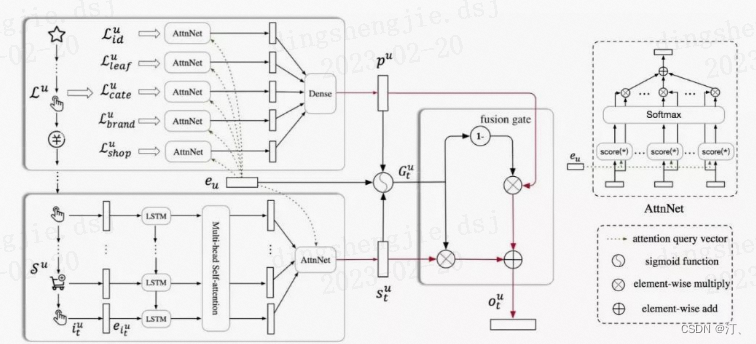
上图中 P u P_u Pu表示用户短期兴趣向量, s t u s^u_t stu表示用户的长期兴趣向量,这里需要注意的是,在求长期和短期用户兴趣向量时都使用了 Attention 机制,Attention 的 Query 向量 e u e_u eu表示 user 的 embedding,用的是基本的用户画像,如年龄区间、性别、职业等。得到长期和短期用户向量后,通过 gru 中的 gate 机制去融合两者:
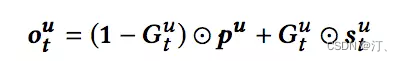
上面的公式输出表示用户的 embedding 表示,而 item 的 embedding 表示和 YouTube DNN 一样,可以拿 softmax 层的权重。其实也可用 graph embedding 先离线训练好 item 的 embedding 表示。
线上预测:通过 user id 找到相应的 user embedding,然后使用 KNN 方法 ( 比如 faiss ) 找到相似度最高的 top-N 条候选结果返回。
3.4.2 Next Item Recommendation with Self-Attention
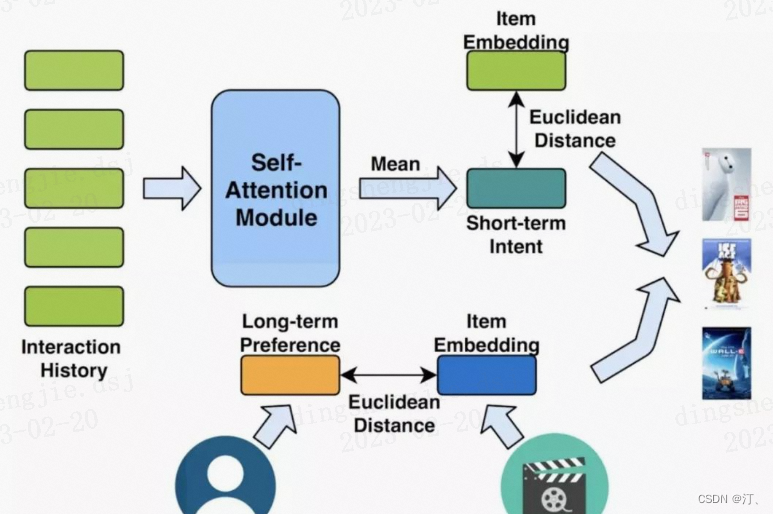
本文亮点是同时建模用户短期兴趣 ( 由 self-attention 结构提取 ) 和用户长期兴趣。其短期兴趣建模过程:使用用户最近的 L 条行为记录来计算短期兴趣。可使用 X 表示整个物品集合的 embedding,那么,用户 u 在 t 时刻的前 L 条交互记录所对应的 embedding 表示如下:
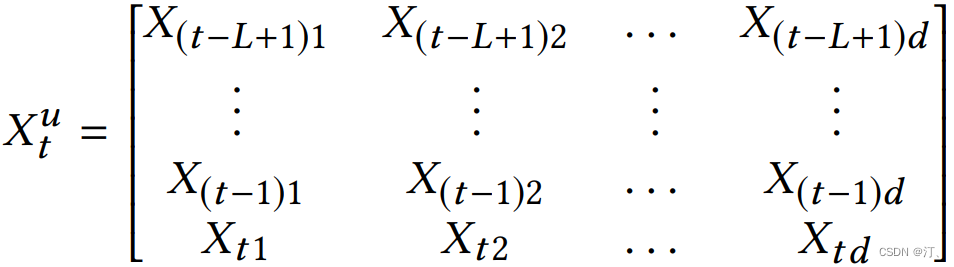
其中每个 item 的 embedding 维度为 d,将 图片作为 transformer 中一个 block 的输入:
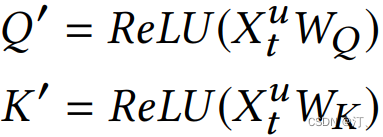
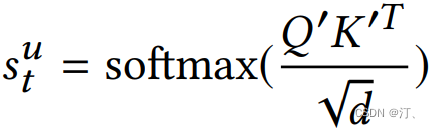
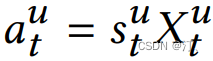
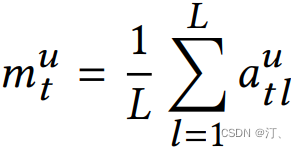
这里需要注意和传统 transformer 的不同点:
-
计算 softmax 前先掩掉 Q ′ K ′ t \quad Q' K'^t Q′K′t矩阵的对角线值,因为对角线其实是 item 与本身的一个内积值,容易给该位置分配过大的权重。
-
没有将输入 X t u X^u_t Xtu乘以图片得到 V t V^t Vt,而是直接将输入 X t u X^u_t Xtu 乘以 softmax 算出来的 score。
-
直接将 embedding 在序列维度求平均,作为用户短期兴趣向量。
Self-attention 模块只使用用户最近的 L 个交互商品作为用户短期的兴趣。那么怎么建模用户的长期兴趣呢?可认为用户和物品同属于一个兴趣空间,用户的长期兴趣可表示成空间中的一个向量,而某物品也可表示为成该兴趣空间中的一个向量。那如果一个用户对一个物品的评分比较高,说明这两个兴趣是相近的,那么它们对应的向量在兴趣空间中距离就应该较近。这个距离可用平方距离表示:
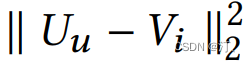
其中 U 是用户的兴趣向量,V 是物品的兴趣向量
综合短期兴趣和长期兴趣,可得到用户对于某个物品的推荐分,推荐分越低,代表用户和物品越相近,用户越可能与该物品进行交互。
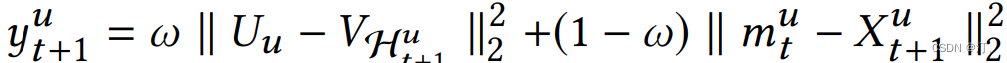
3.5 TDM 深度树匹配召回
TDM 是为大规模推荐系统设计的、能够承载任意先进模型 ( 也就是可以通过任何深度学习推荐模型来训练树 ) 来高效检索用户兴趣的推荐算法解决方案。TDM 基于树结构,提出了一套对用户兴趣度量进行层次化建模与检索的方法论,使得系统能直接利高级深度学习模型在全库范围内检索用户兴趣。其基本原理是使用树结构对全库 item 进行索引,然后训练深度模型以支持树上的逐层检索,从而将大规模推荐中全库检索的复杂度由 O(n) ( n 为所有 item 的量级 ) 下降至 O(log n)。
3.5.1 树结构
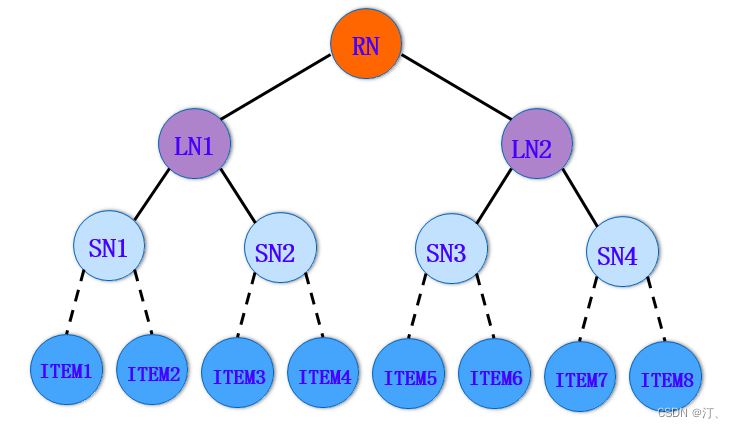
如上图所示,树中的每一个叶节点对应一个 item;非叶节点表示 item 的集合。这样的一种层次化结构,体现了粒度从粗到细的 item 架构。此时,推荐任务转换成了如何从树中检索一系列叶节点,作为用户最感兴趣的 item 返回。
3.5.2 怎么基于树来实现高效的检索?
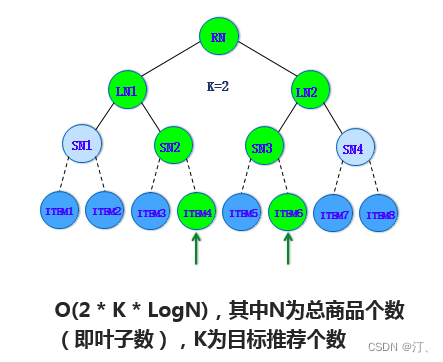
采用 beam-search 的方法,根据用户对每层节点的兴趣挑选 topK,将每层 topK 节点的子节点作为下一层挑选的候选集合逐层展开,直到最终的叶子层。比如上图中,第一层挑选的 Top2 是 LN1 和 LN2,展开的子节点是 SN1 到 SN4,在这个侯选集里挑选 SN2 和 SN3 是它的 Top2,沿着 SN2 和 SN3 它的整个子节点集合是 ITEM3 到 ITEM6,在这样一个子结合里去挑 Top2,最后把 ITEM4 和 ITEM6 挑出来。
那么为什么可以这样操作去 top 呢?因为这棵树已经被兴趣建模啦 ( 直白意思就是每个节点的值都通过 CTR 预估模型进行训练过了,比如节点的值就是被预测会点击的概率值 ),那么问题来了,怎么去做兴趣建模呢 ( 基于用户和 item 的特征进行 CTR 预估训练 )?
3.5.3 兴趣建模
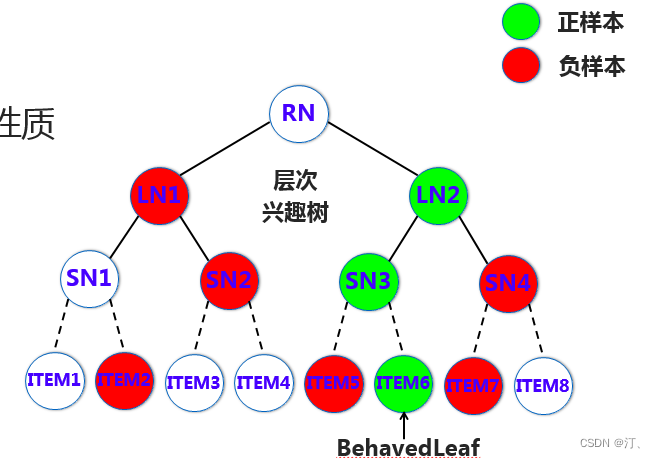
如上图,假设用户对叶子层 ITEM6 节点是感兴趣的,那么可认为它的兴趣是 1,同层其他的节点兴趣为 0,从而也就可以认为 ITEM6 的这个节点上述的路径的父节点兴趣都为 1,那么这一层就是 SN3 的兴趣为 1,其他的为 0,这层就是 LN2 的兴趣为 1,其他为 0。也就是需要从叶子层确定正样本节点,然后沿着正样本上溯确定每一层的正样本,其他的同层采样一些负样本,构建用于每一层偏序学习模型的样本。
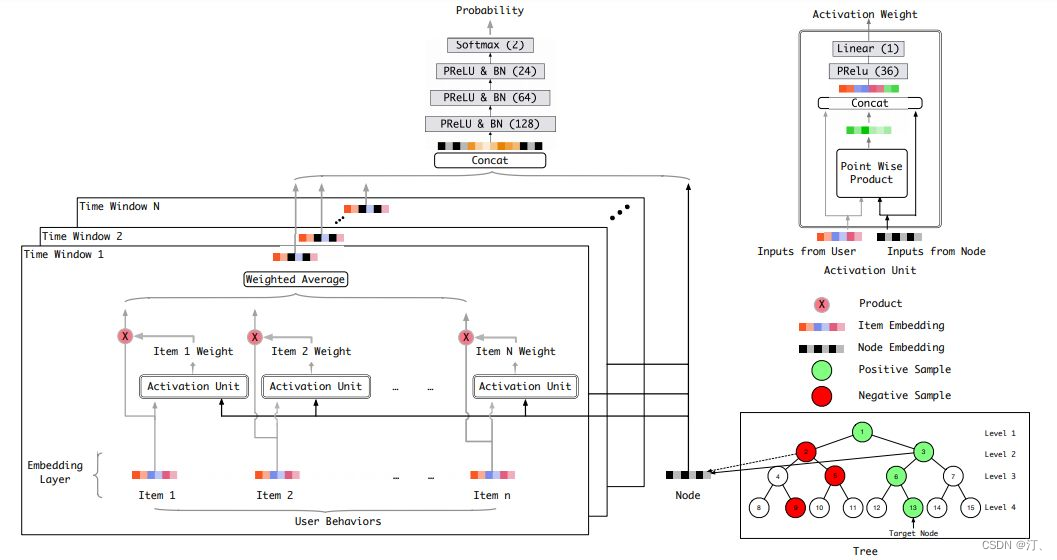
构造完训练样本后,可以利用 DIN ( 这里可以是任何先进的模型 ) 承担用户兴趣判别器的角色,输入就是每层构造的正负样本,输出的是 ( 用户,节点 ) 对的兴趣度,将被用于检索过程作为寻找每层 Top K 的评判指标。如下图:在用户特征方面仅使用用户历史行为,并对历史行为根据其发生时间,进行了时间窗口划分。在节点特征方面,使用的是节点经过 embedding 后的向量作为输入。此外,模型借助 attention 结构,将用户行为中和本次判别相关的那部分筛选出来,以实现更精准的判别。
 ### 3.5.4 兴趣树是怎么构建的?网络与树结构的联合训练
### 3.5.4 兴趣树是怎么构建的?网络与树结构的联合训练
优化模型和优化样本标签交替进行。具体过程:最开始先生成一个初始的树,根据这个初始的树去训练模型,有了模型之后,再对数据进行判别,找出哪些样本标签打错了,进行标签的调整,相当于做树结构的调整。完成一轮新的树的结构的调整之后,我们再来做新的模型学习,实现整个交替的优化。
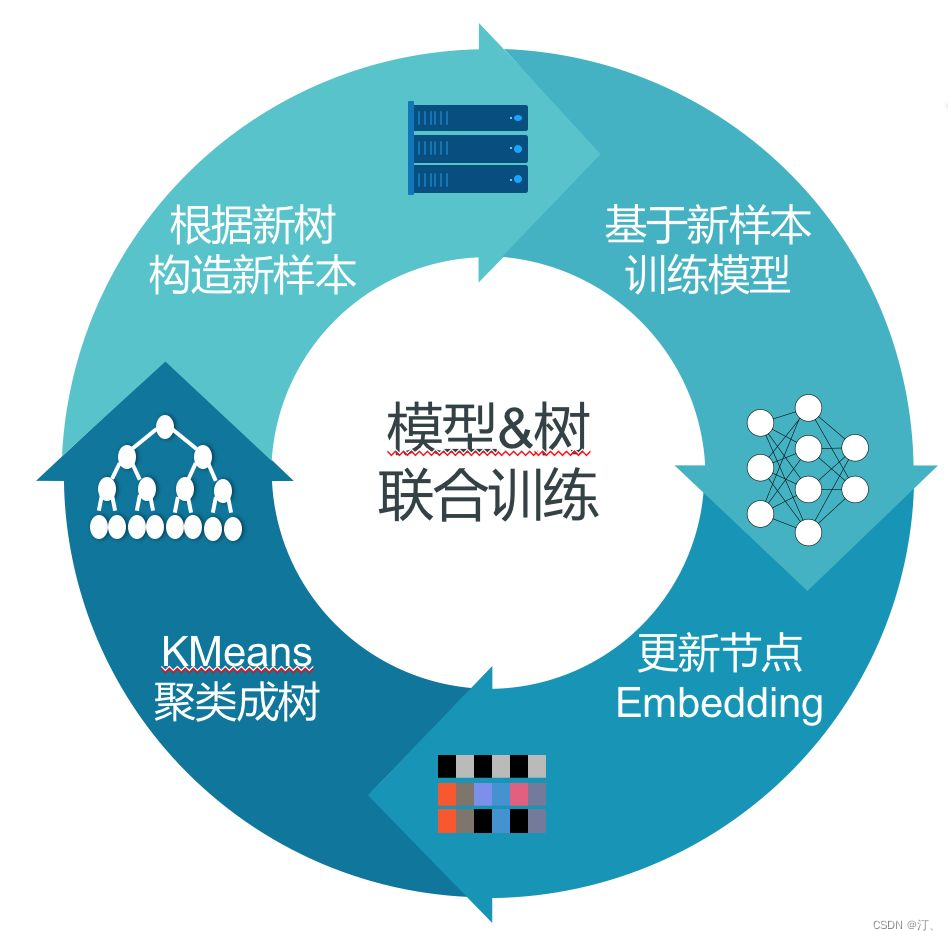
模型训练、优化样本标签过程迭代进行,最终得到稳定的结构与模型。
目前TDM模型更多承担的还是召回的工作:
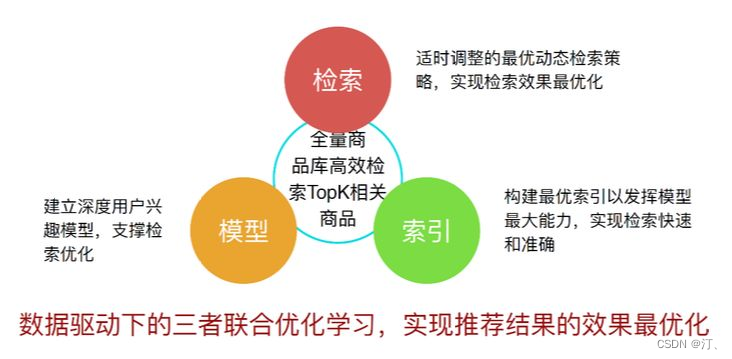
TDM初步实现了在数据驱动下的模型、检索和索引三者的联合学习。其中索引决定了整个数据的组织结构,它承载的是模型能力和检索策略,以实现检索的快速和准确。检索实际上是面向目标,它需要和索引结构相适配。模型支撑的则是整个检索效果的优化。
参考链接:
[1]https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf
[2]https://dl.acm.org/citation.cfm?id=3346996
[3]https://arxiv.org/pdf/1904.08030.pdf
[4]https://arxiv.org/pdf/1803.02349.pdf
[5]https://arxiv.org/pdf/1706.02216.pdf
[6]https://zhuanlan.zhihu.com/p/74242097
[7]https://arxiv.org/abs/1909.00385v1
[8]https://www.jianshu.com/p/9eb209343c56
[9]https://zhuanlan.zhihu.com/p/78941783
4.当前业界的主流召回算法综述
传统召回方式与新式召回在业务中互为补充,传统召回(主要是cb和cf方法)往往是最直接的,成本最低的,效果非常显著的方法. 不过出于技术探索的原因, 笔者后面会只介绍一些相对“高阶”的方法, 权当抛砖引玉了.
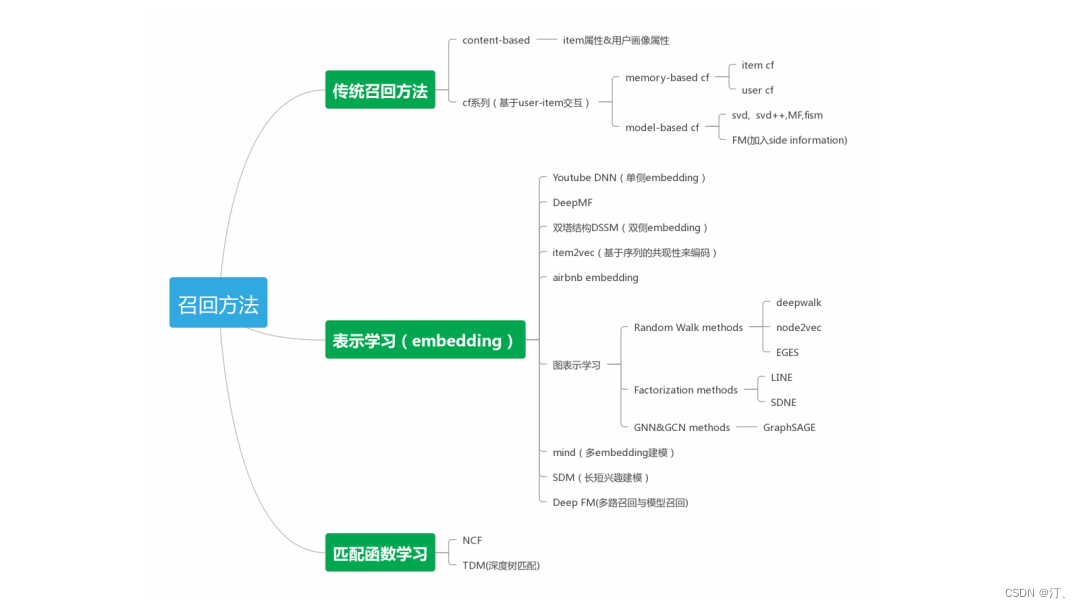
4.1 Youtube DNN
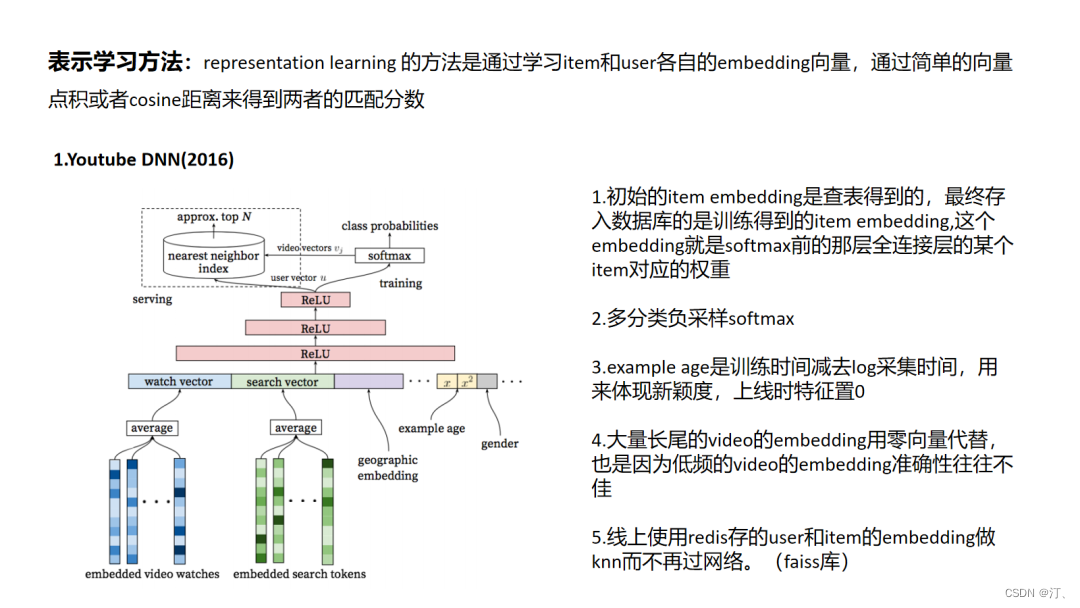
当前的主流方法的通用思路就是对于use和item的embedding的学习, 这也被称为表示学习; YoutbeDNN是经典的将深度学习模型引入推荐系统中,可以看到网络模型并不复杂,但是文中有很多工程上的技巧,比如说 word2vec对 video 和 search token做embedding后做为video初始embedding,对模型训练中训练时间和采集日志时间之间“position bias”的处理,以及对大规模多分类问题的负采样softmax。
4.2 DeepMF
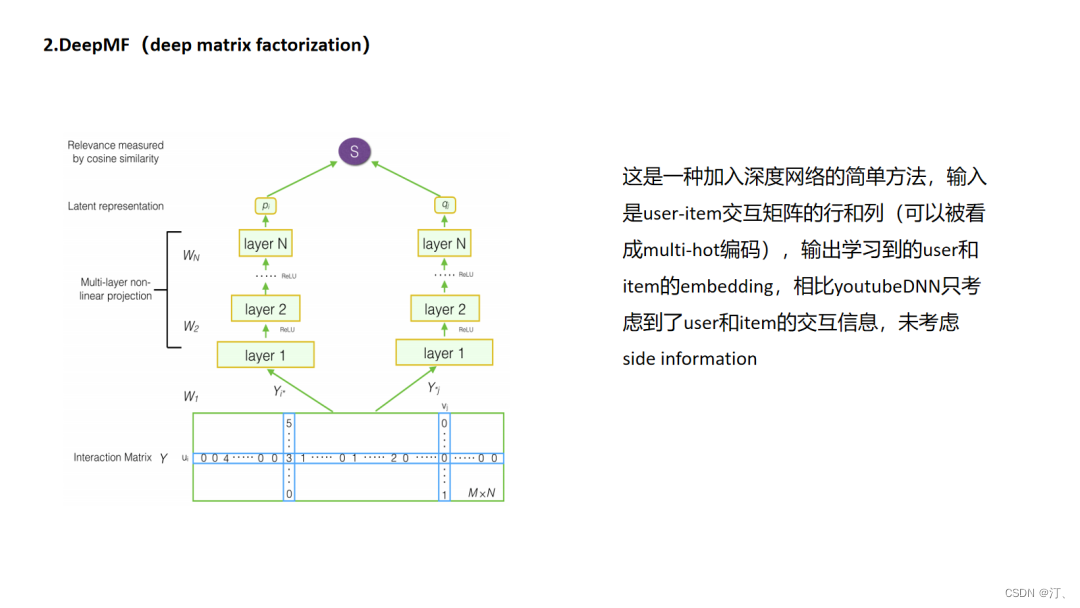
Deep MF方法与传统矩阵分解方式中的谈到的“分解”其实是有些区别的.如果把推荐视作填充矩阵的任务的话,传统MF的分解是把m(用户数)× n(物品数)的矩阵分解成m×k大小的用户抽象矩阵和n×k大小的物品抽象矩阵的乘积,实现把物品和用户分别映射到k维隐空间的目的. 而deepMF则使用了另外一种得到k维隐向量的方式,即先把用户交互矩阵分解出代表用户的行和代表物品的列,用一个NN模型去学习用户行和物品列的隐式表达.
4.3 DSSM
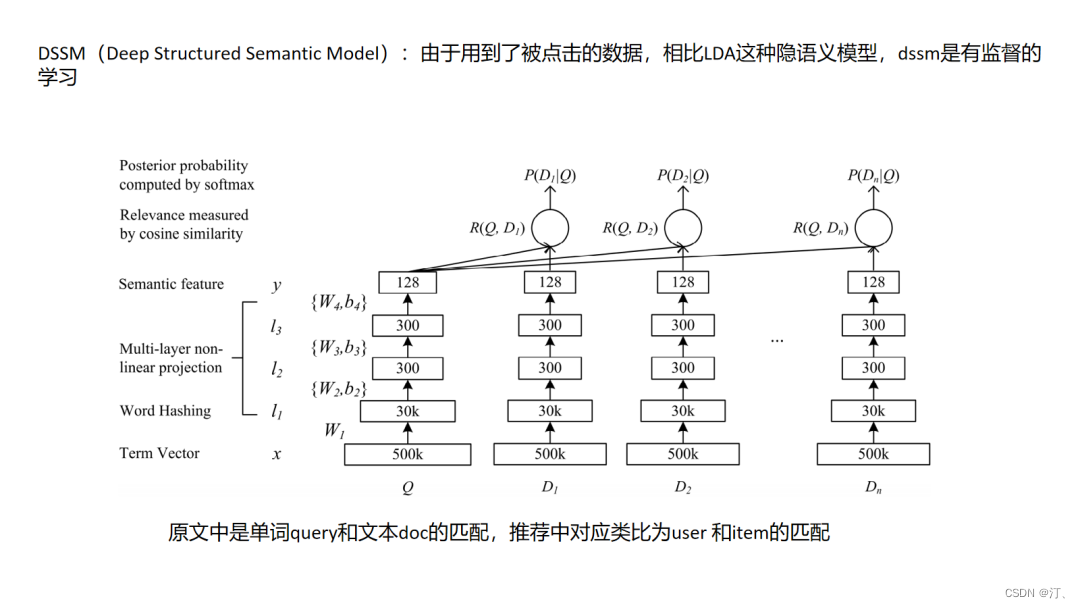
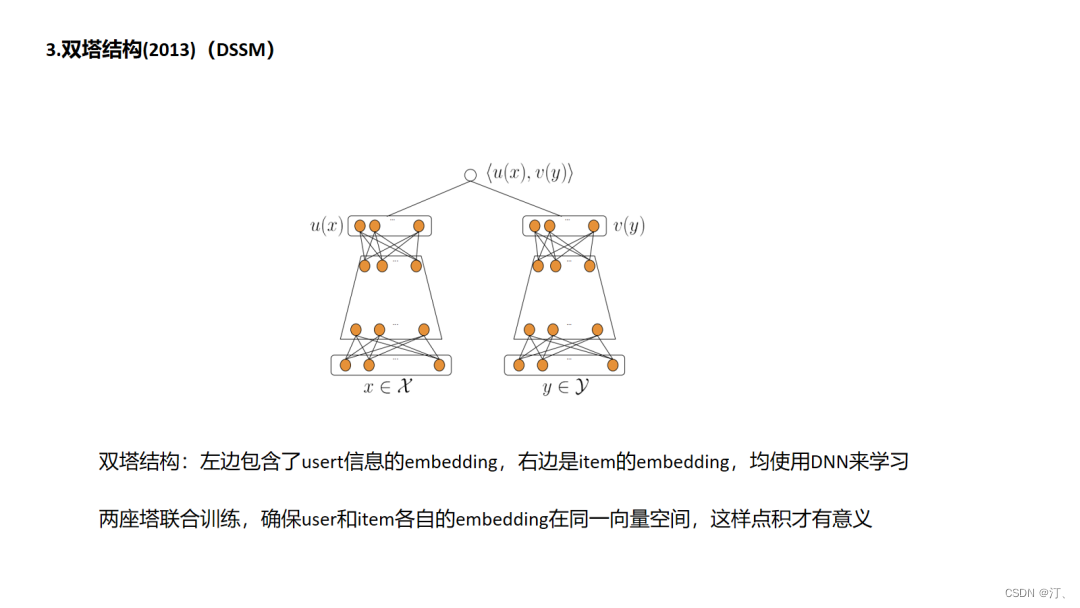

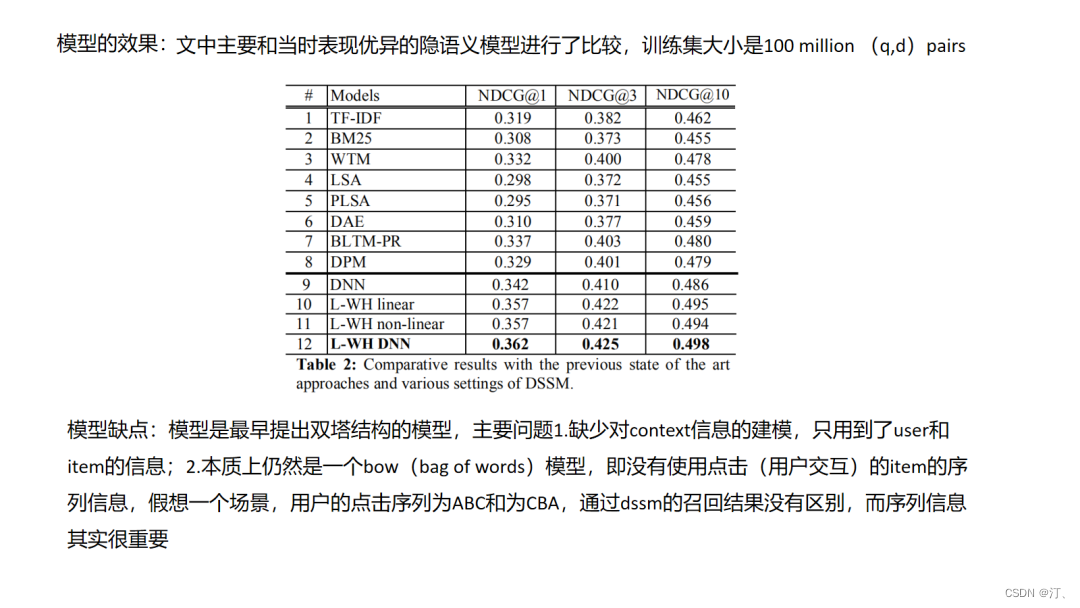
双塔结构DSSM是应用十分广泛的深度方法,搜索场景中,点击的日志中包含了用户搜索query和用户搜索当前query下点击的doc,以此来构建正样本,对每一个正样本(query,doc)对,随机选择一些该query下曝光未点击的doc构建负样本,属于有监督信息的学习,同时注意的是对于每一座doc塔的参数是共享的.在DSSM的基础上演化出一些有用的变种,如MV-DSSM,融合不同域的特征进行学习.
4.4.Item2vec


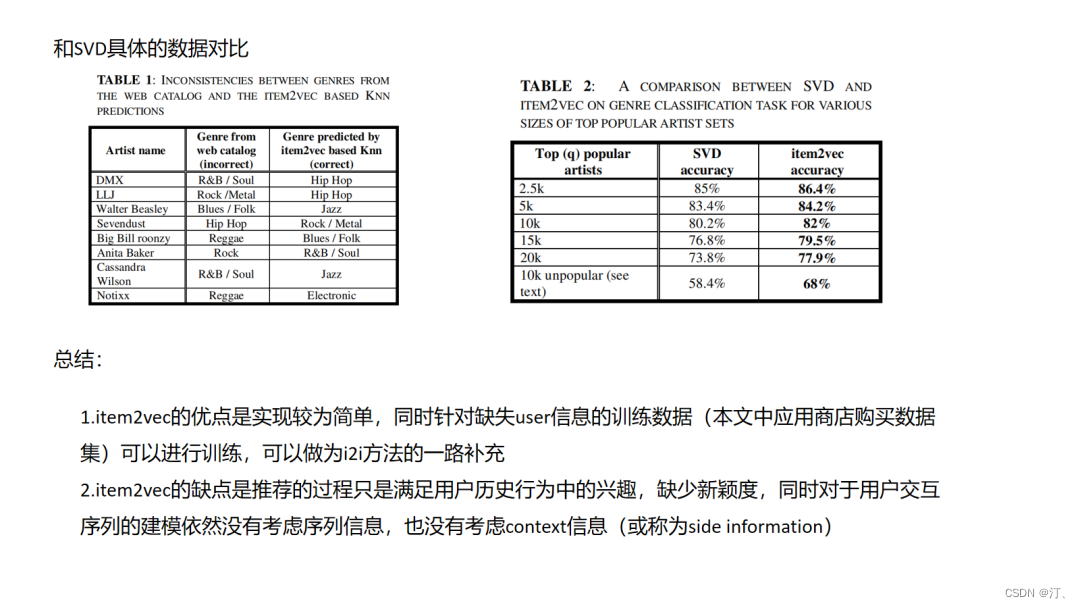
本质上来说item2vec是一种利用item彼此共现信息的缺少监督信息的学习,它的一个隐含假设是同一个session中共现的item往往是相关的,可以被互相推荐的,但实际场景中,们需要思考这种先验是否能够满足,比如session序列中是否存在多兴趣行为导致共现的item其实并没有什么联系,再比如session划分的依据该如何权衡,划分过长势必会引入不相关的item成为噪音,划分过短又会降低item在不同session序列中出现频率,也会对训练效果造成困难.
4.5.Airbnb Embedding

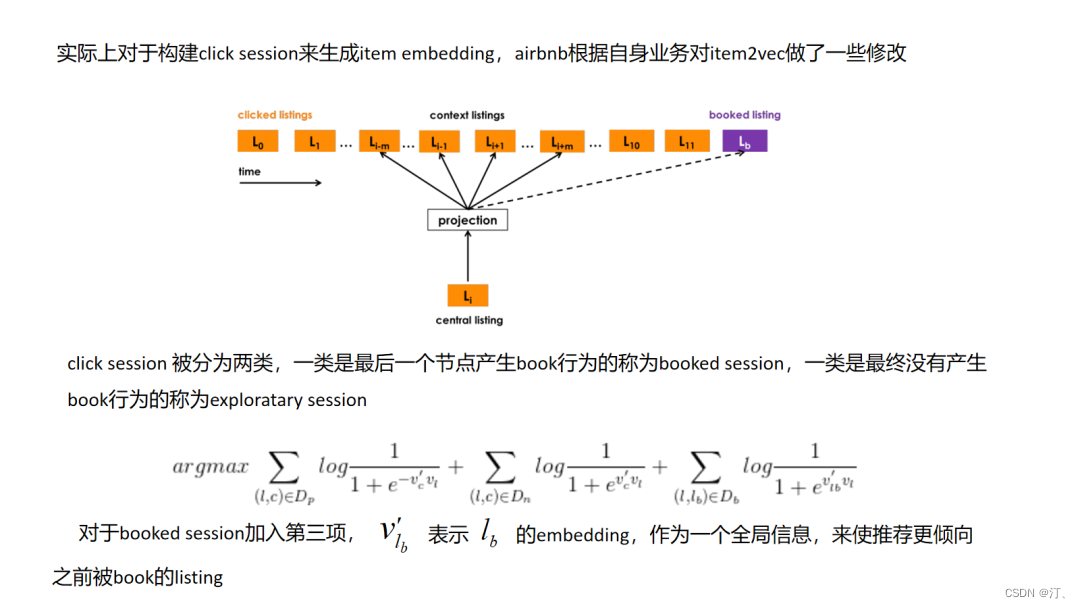

airbnb embedding实际上是一篇针对item2vec方法,结合自己业务进行创新的方式,其中让我最惊艳的是对于book 序列稀疏性的处理,一个user_id并非我起初设想的对应一个user_type,而是在user长期的book历史行为中随着划分type的那些特征的改变而改变(比如我一年前用小米,现在用苹果,那我的user_type是改变了的),同时文中提到用(user_type,item_type)元组来表示一个节点,同时在训练的时候将元组扁平化成一种“异构”序列,达到在一个空间里学习user_type和item_type的目的,这个比一般item2vec方式有很大的创新,其让我想到了后面要讲到的类似node2vec和metapath2vec同构图和异构图的关系一样,让人耳目一新.
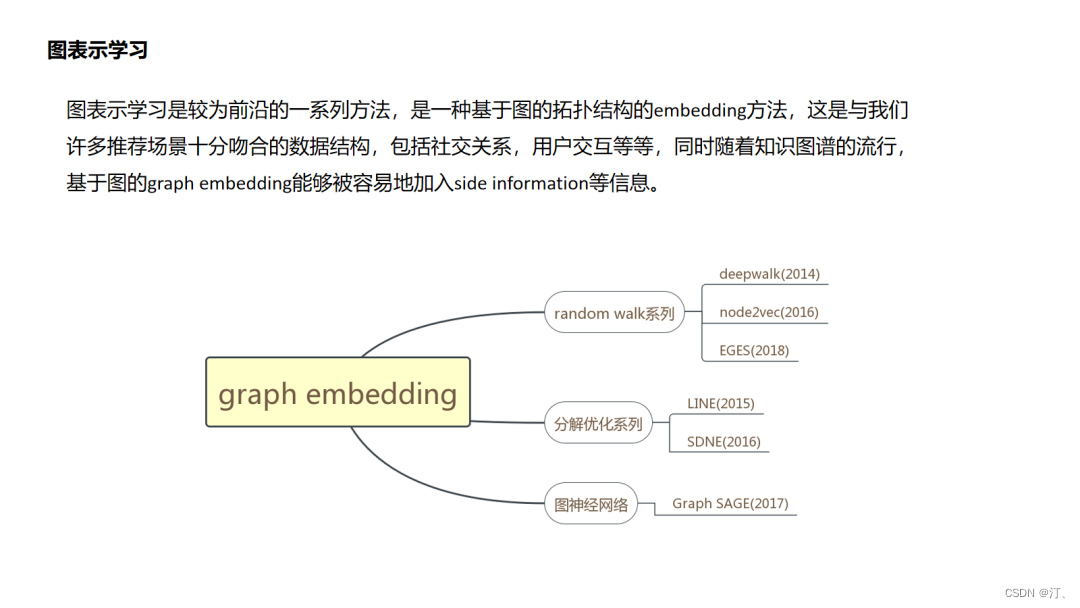
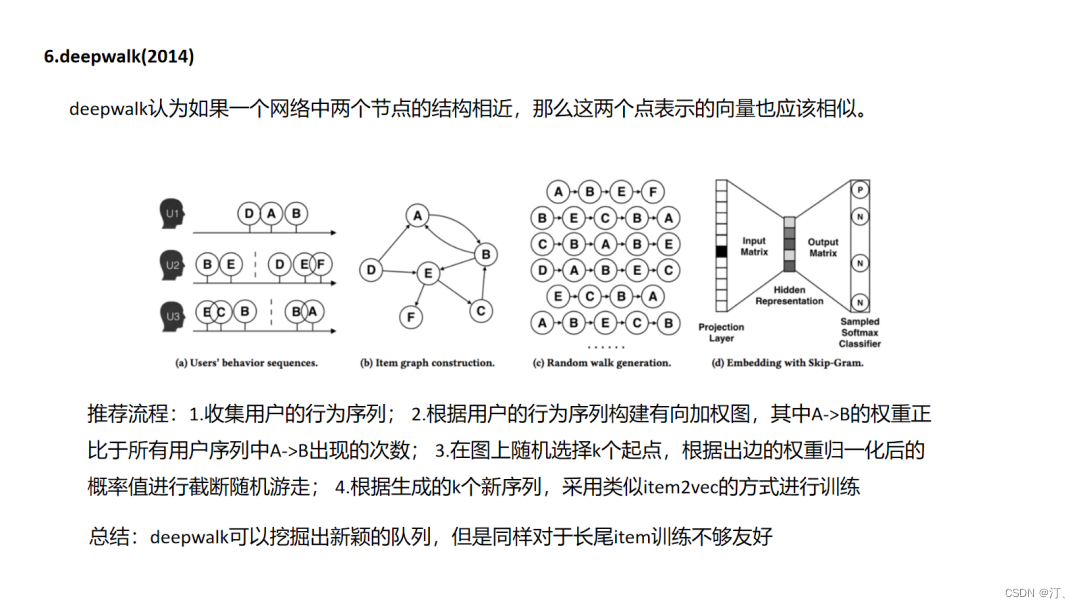
4.6.DeepWalk
4.7 Node2Vec
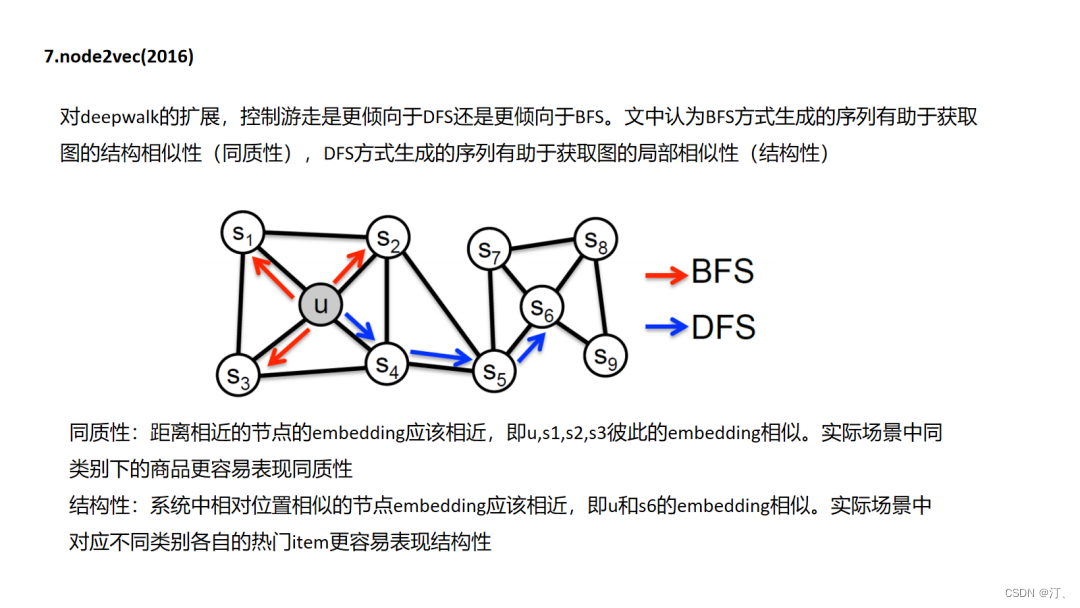
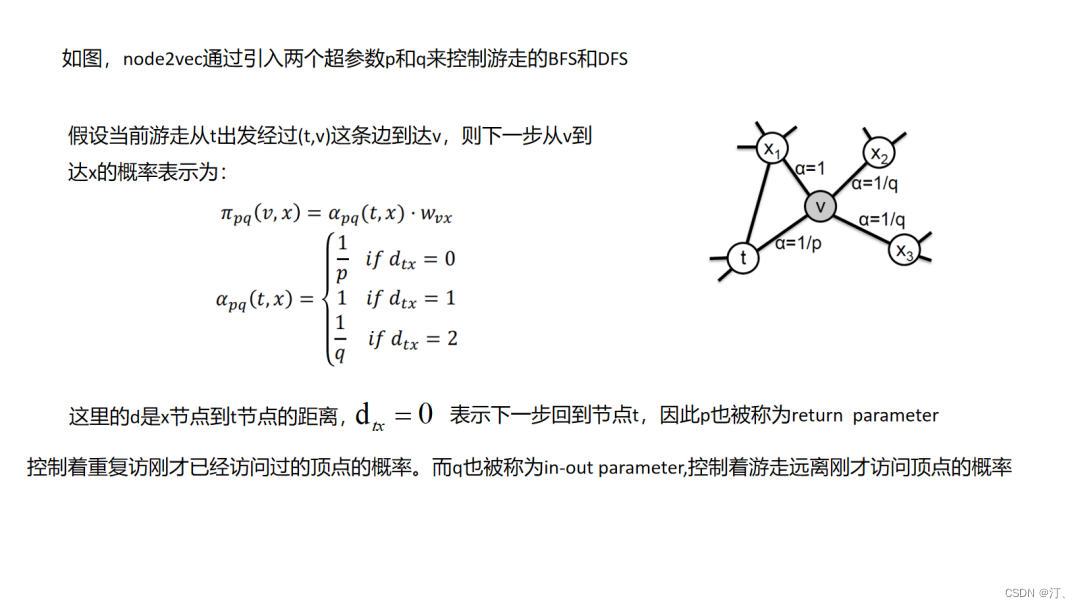

deepwalk和node2vec其实就像item2vec一样都是基于“连接即可推荐”的先验的,这里面其实没有判断“推荐是否正确”的强标签信息,在item2vec中是通过两个item在多个session中共现次数的频率来体现item的信息的,而图随机游走embedding中是通过把这种共现次数编辑成边的权重,由边权控制游走概率来反映不同item的信息(这点很重要,设想一个场景中生成的图是一个各向同性的图,那么这个图是学不出来什么东西的).图中包含的信息一个是图结构的复杂度(连接是否稠密),一个是图的边权重(item之间共现频率分布是否有大的差异),因此在实际使用中,我们往往需要对自己的场景做上面两个维度的评估和调优.
4.8.EGES
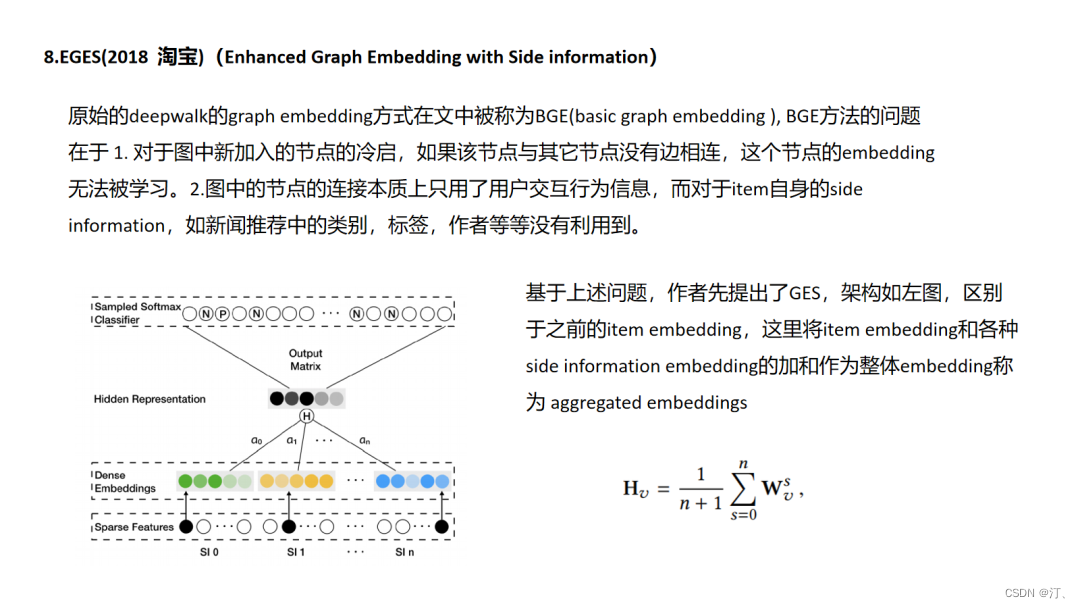

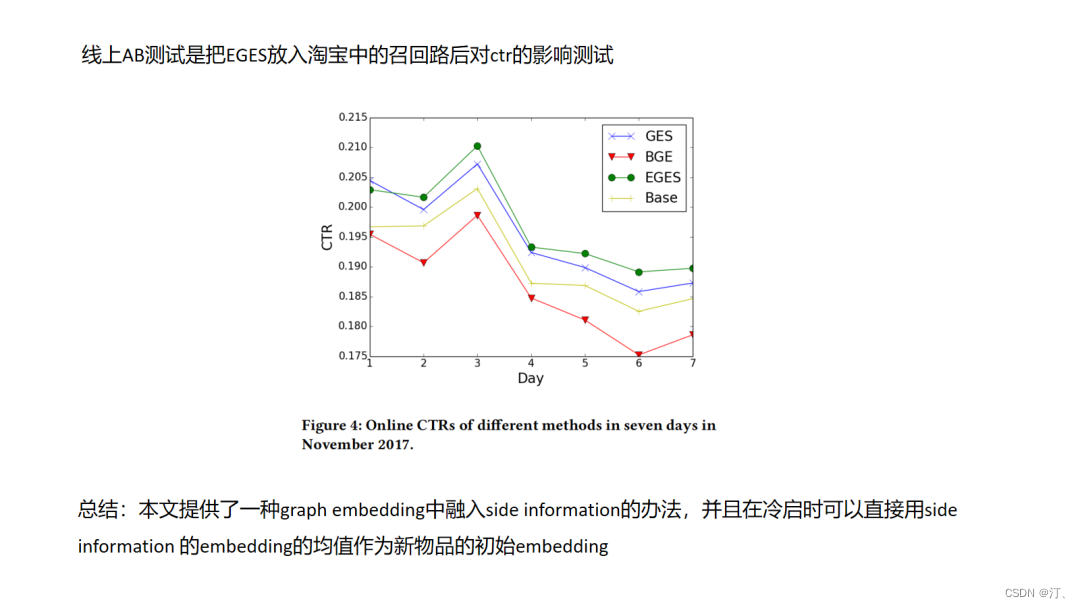
EGES主要两个创新点一个side information的融入,一个是attention机制,原始的graph embedding正如我前面说到的主要利用节点之间的共现信息,只是利用节点自身的id特征,那么像文中这样在得到id的图embedding之后如何与其它side information的embedding结合是一个很自然的想法.
4.9.LINE
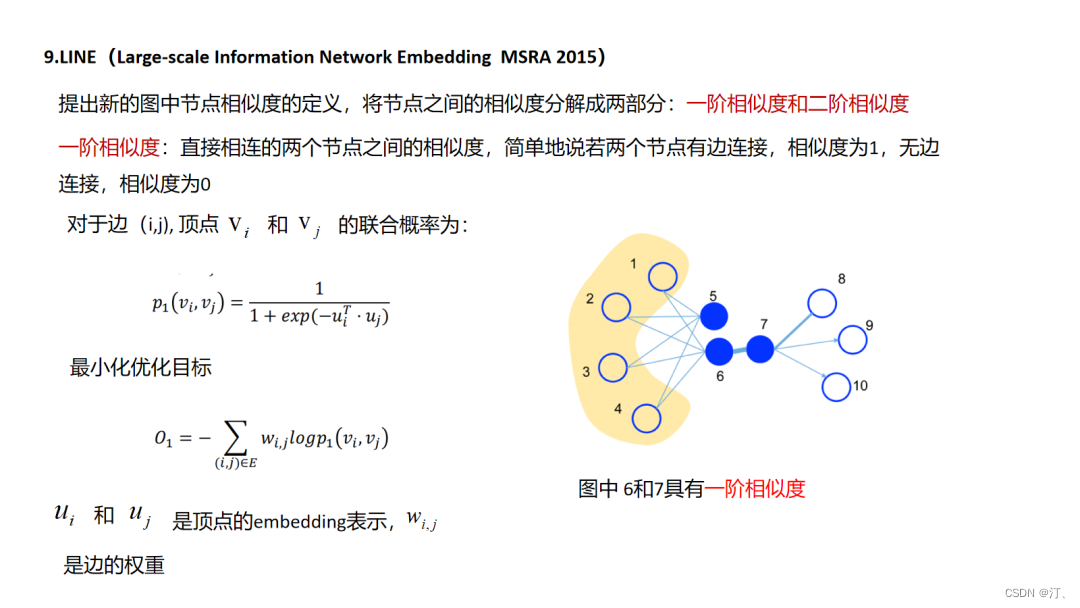
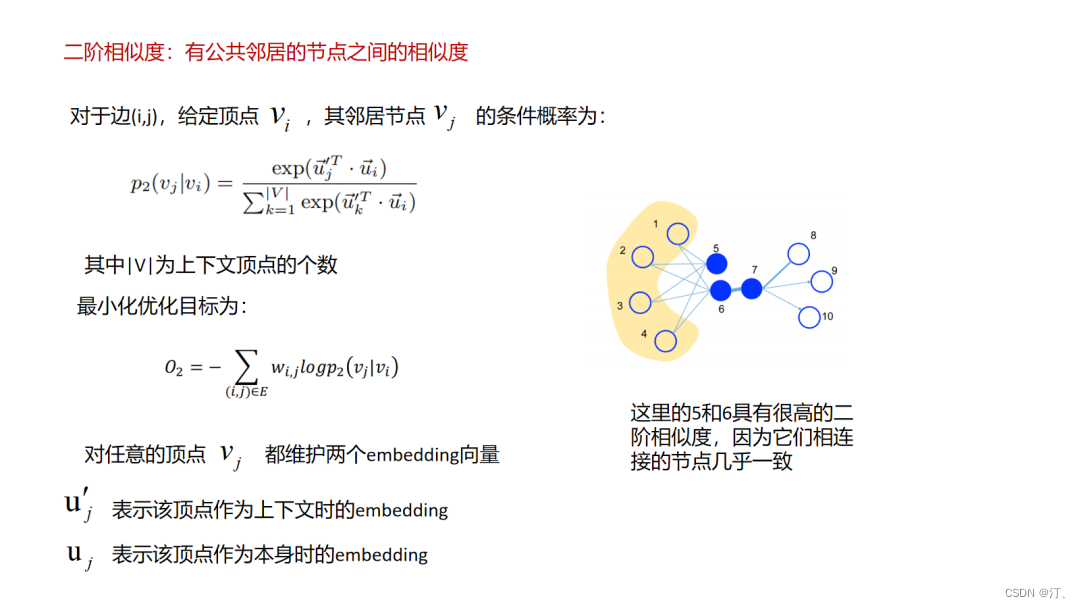

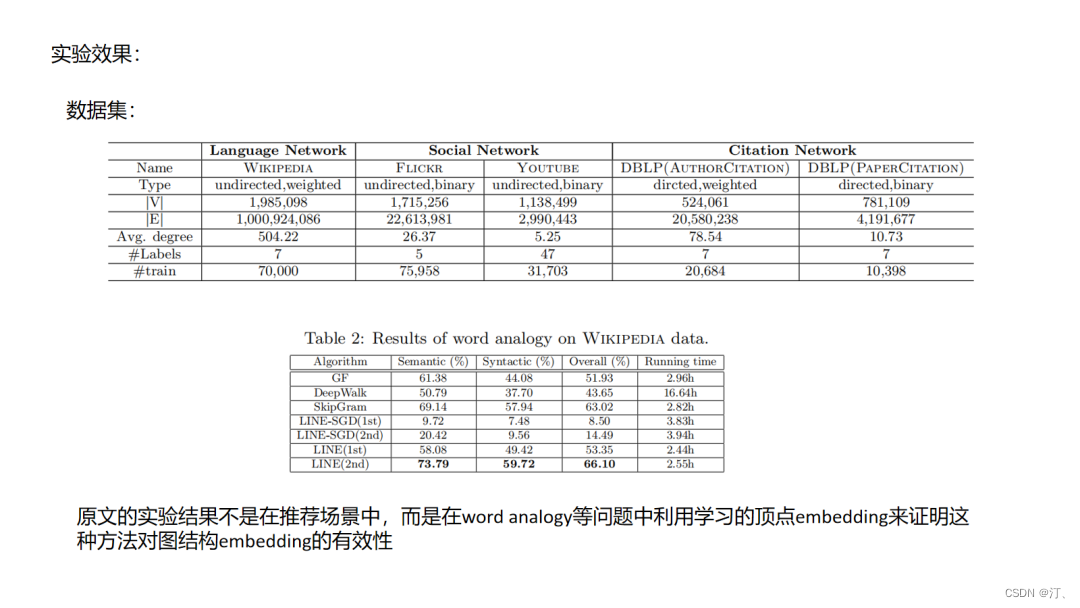
LINE方法其实是对前面所说的deepwalk这种emdedding使用“连接而推荐”的一种改进了,文中把这种直接连接的关系定义为一阶相似,引入了间接相连的二阶相似,这样的好处是提升了拓展性,使得原来不直接相连的节点也有了更直接的二阶相似度,类似的我们或许可以定义更高阶的相似性,但这样的问题就是推荐会变得发散,在如相关性推荐的场景中就会增加badcase的比例.
4.10.SDNE
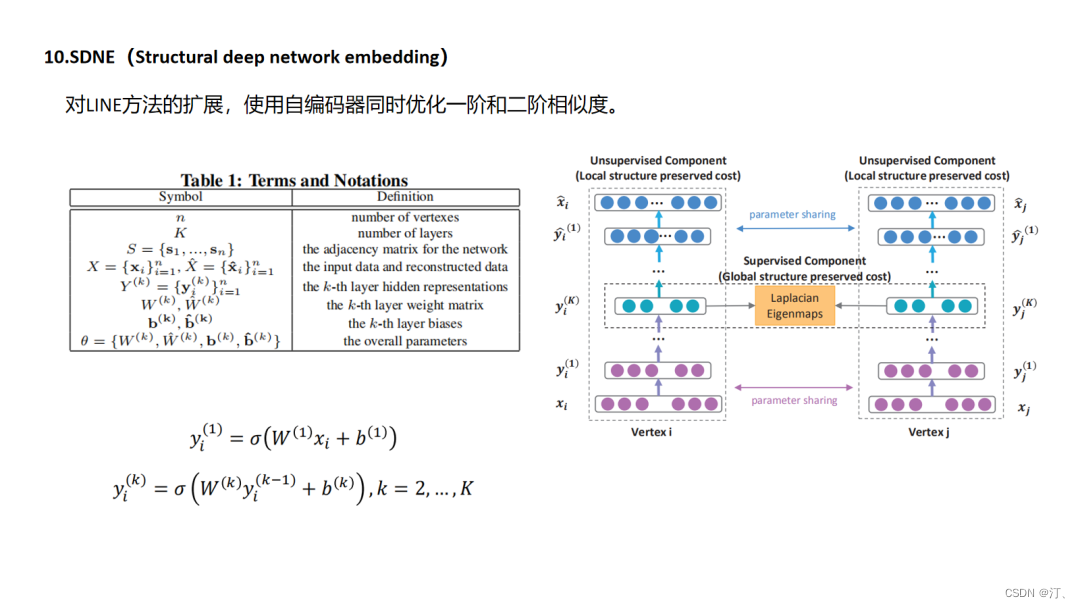
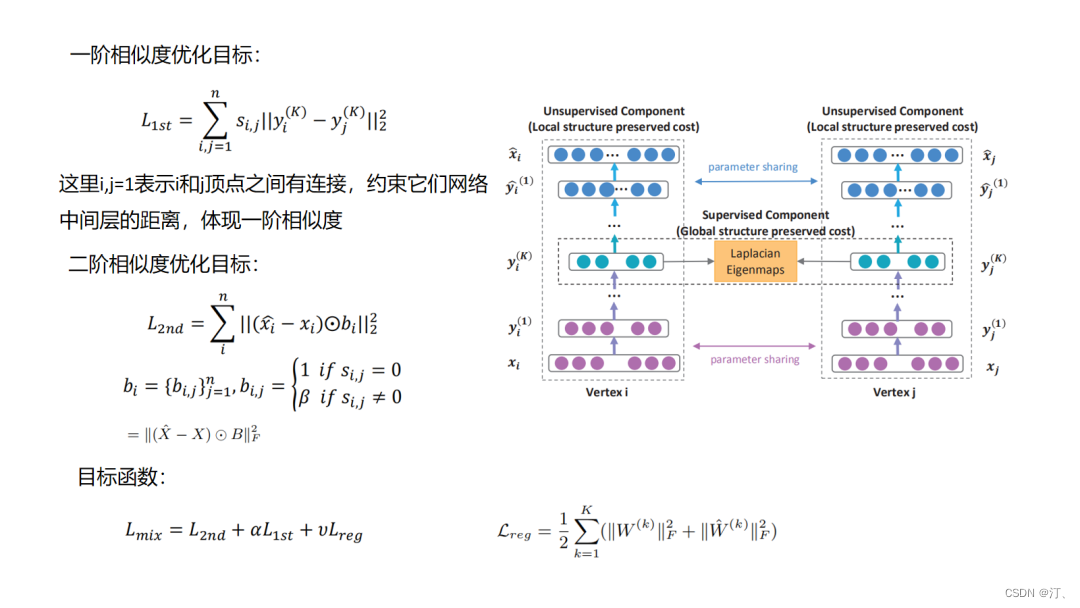
4.11.GraphSAGE
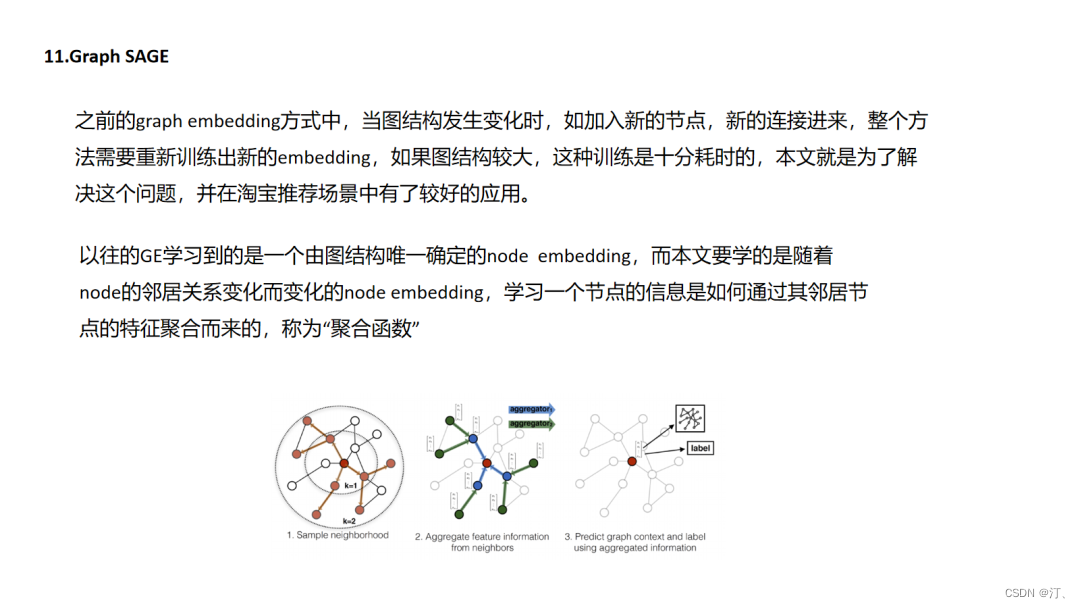

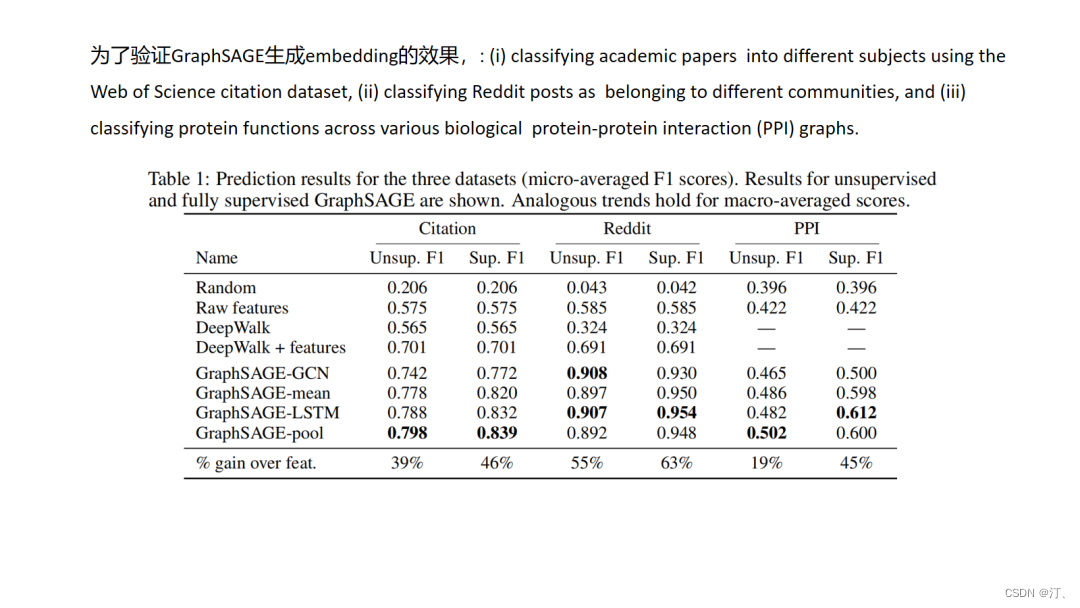
GraphSAGE非常惊艳的是转换了graph embedding问题的研究对象,以前我们是对节点建模,但是对于节点建模,而节点信息是依赖于整个图拓扑结构的,图结构的改动就会影响我们节点表征的结果,而本文则转换研究对象为对局部拓扑结构,通过学习局部拓扑结构与节点表征之间的映射函数间接的得到节点的表征,而实际场景中局部拓扑结构会相对稳定.
4.12 MIND


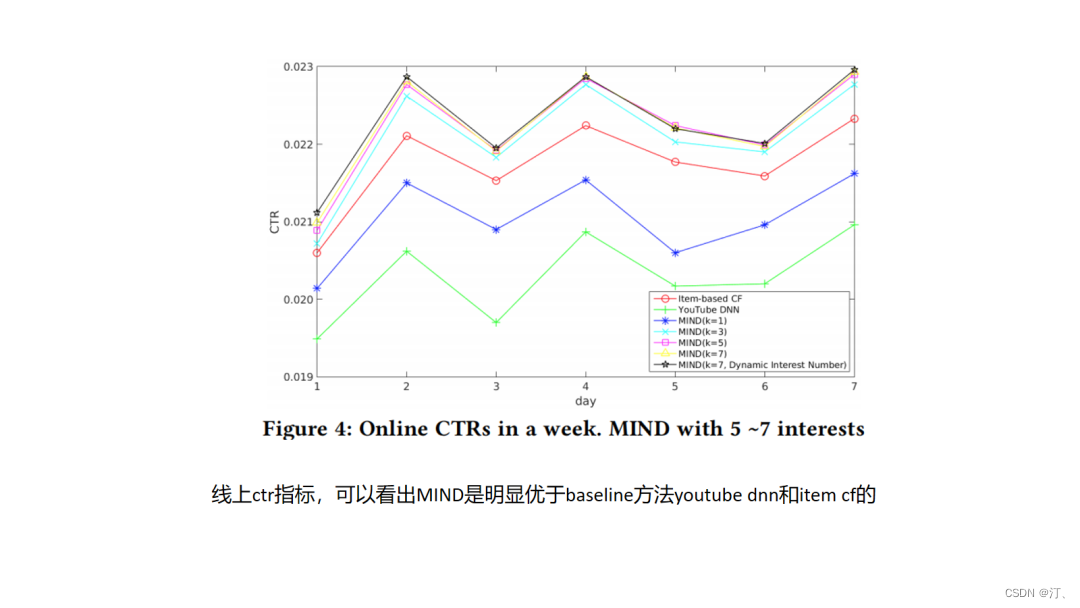
4.13.SDM

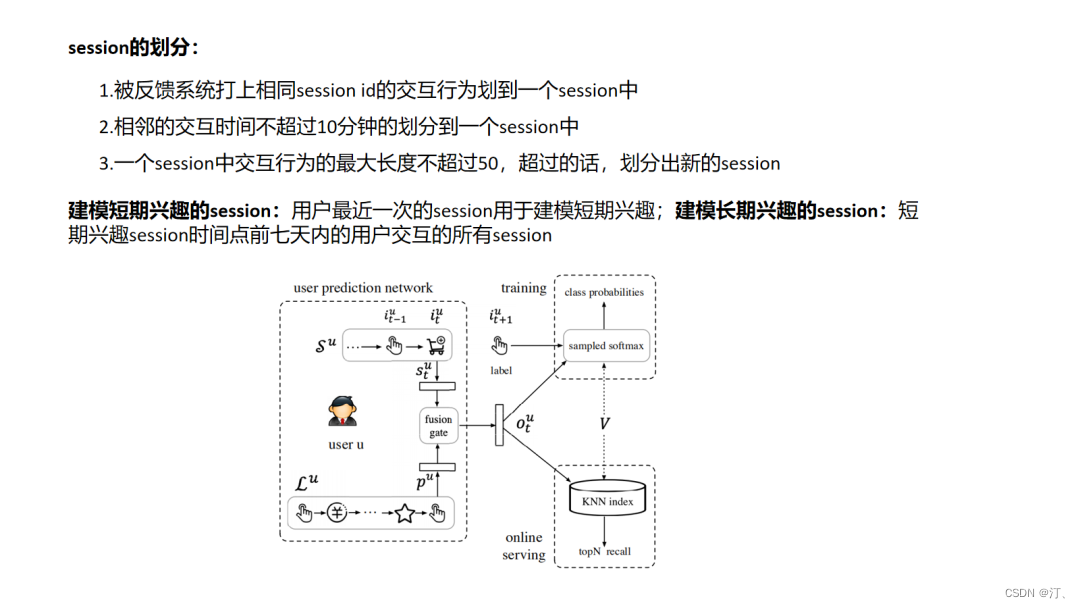
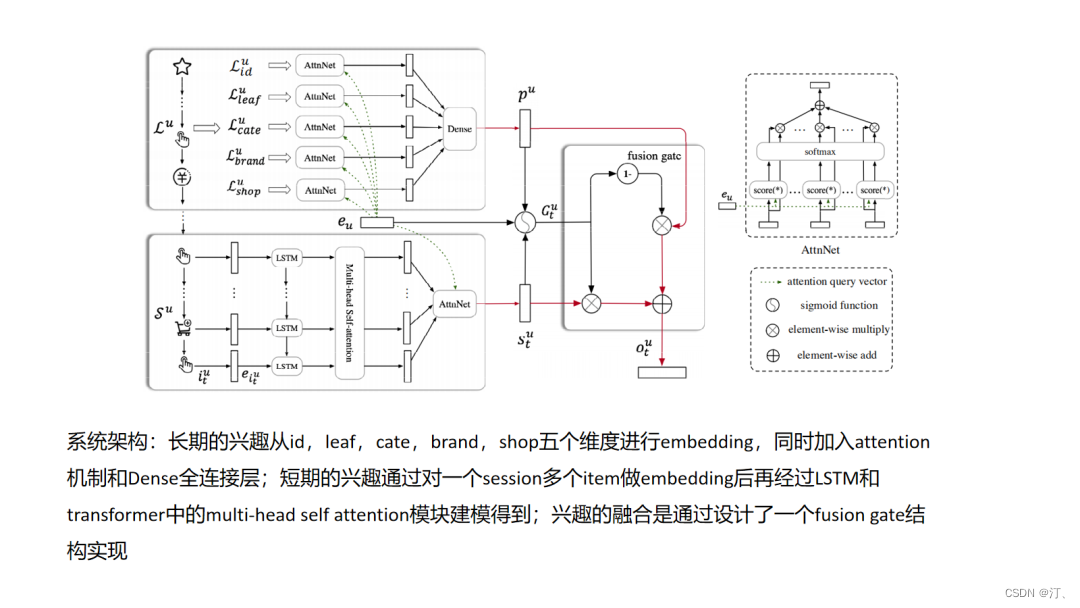
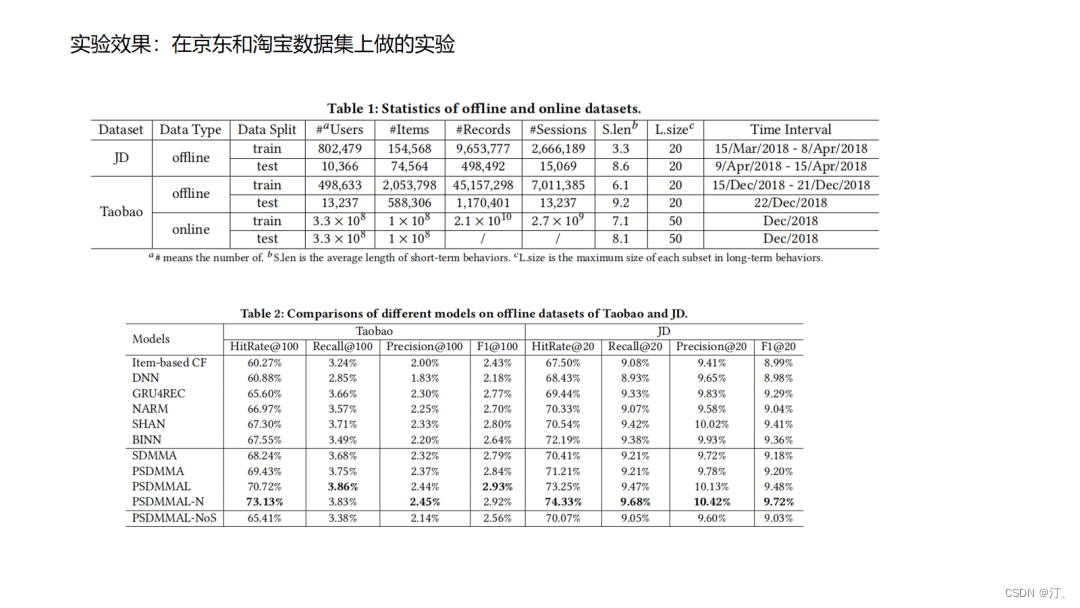
4.14.DeepFM

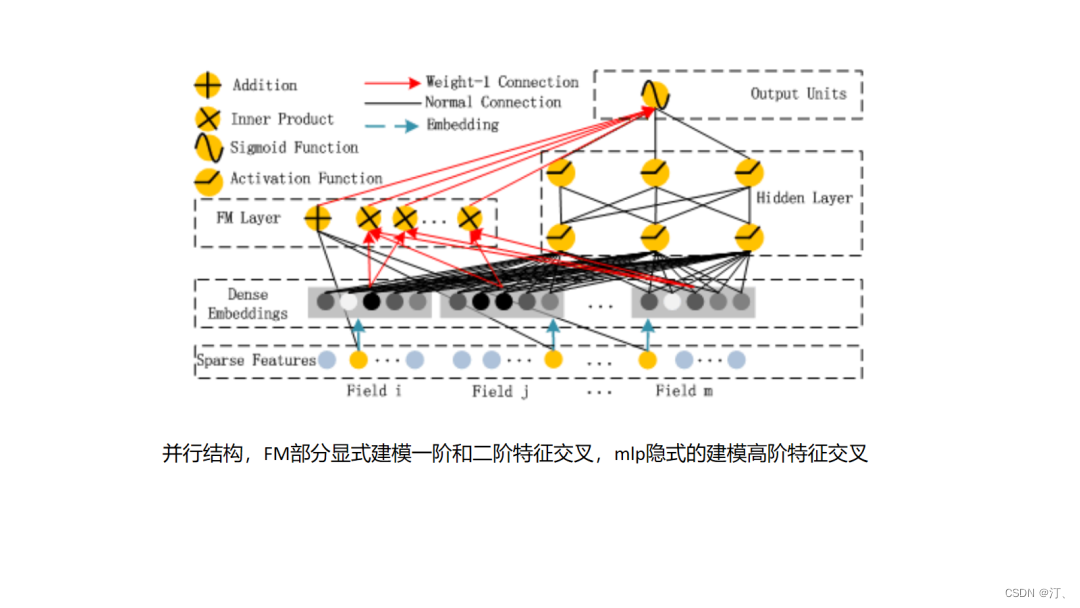
其实用FM或者说DeepFM做排序模型,大家是较为熟悉的,那么如何用FM或者DeepFM做召回有什么特别的地方,一般而言召回过程中FM可以不考虑user特征集合内部的特征之间的交叉,以及item特征集合内部的特征交叉,那么这样对于存入的user embedding 可以直接取user特征集合各个特征embedding的特征加和即可,item embedding直接取item特征集合各个特征embedding的特征加和即可,此时user embedding和item embedding的内积就已经体现了user特征和item特征之间的特征交叉,模型较排序使用的FM更为简化.
4.15.NCF
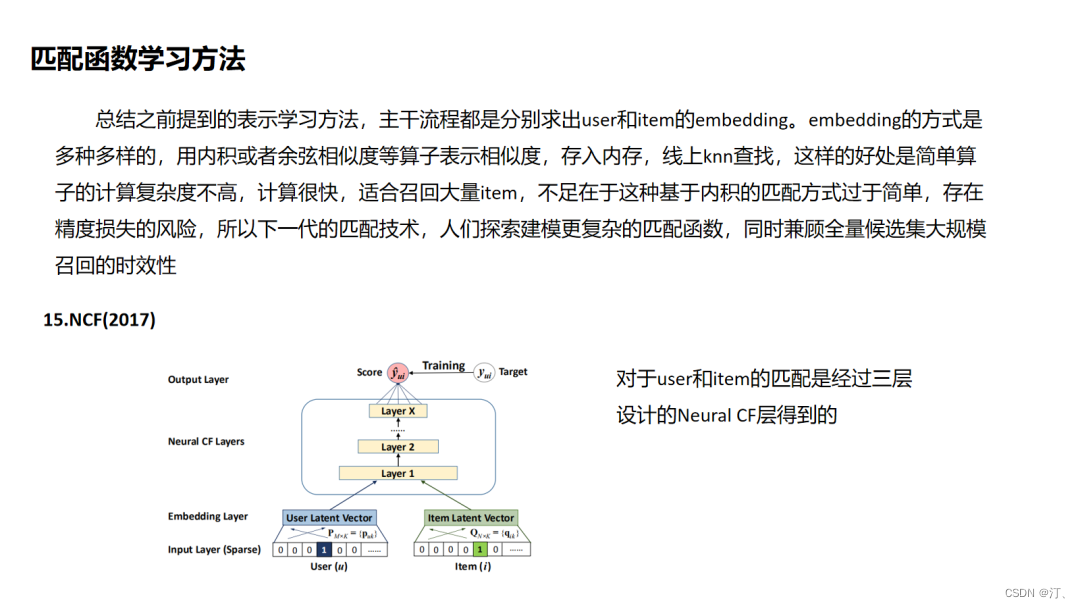
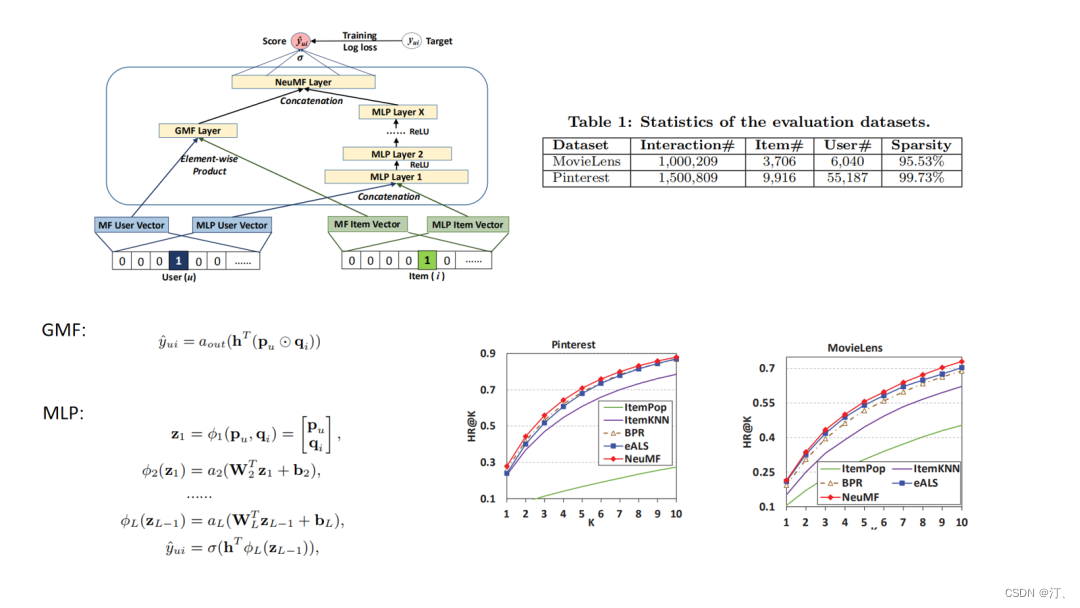
NCF是较早提出对于匹配函数进行学习的,它的技术难点是不能像基于向量内积召回方式的套路那样离线存储embedding然后线上最近邻召回,因此它的线上serving的时间复杂度成为一个痛点,这个问题在后面的阿里的TDM中提供了解决方案.
4.16.TDM
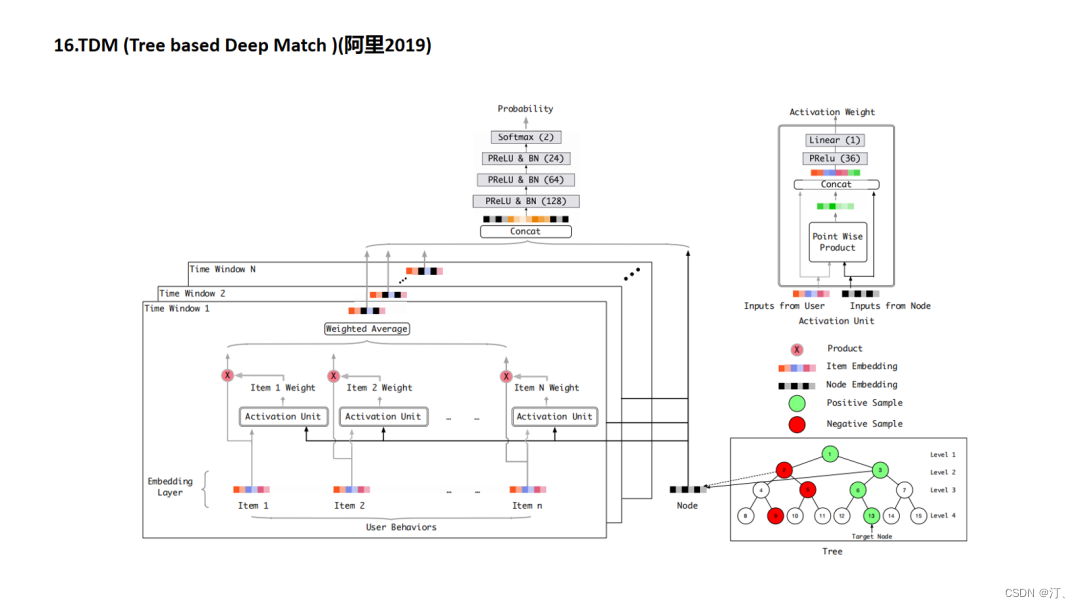



TDM提出的是对原有向量内积召回的颠覆,耳目一新,但是应用起来会涉及到检索架构的调整,有很大的工程落地成本,这方面的细节笔者尚不清楚,请大家多多指教.
参考推荐:
关于图相关学习推荐参考
https://blog.csdn.net/sinat_39620217/category_12092601.html
图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
第四范式自动化推荐系统:搜索协同过滤中的交互函数
怎样刻画用户嵌入向量(user embedding)和物品嵌入向量(item embedding)之间的交互是在评分矩阵上面做协同滤波的关键问题。随着机器学习技术的发展,交互函数(interaction function)渐渐的由最初简单的矩阵内积,发展到现在复杂的结构化神经网络。本文介绍了第四范式研究组将自动化机器学习技术引入推荐系统中的一次尝试;特别地,将交互函数的设计建模成一个结构化神经网络问题,并使用神经网络搜索(neural architecture search)技术去设计数据依赖的交互函数。