论文 : https://arxiv.org/abs/1708.02002
文章目录
- Retina Net
- Focal Loss
- Retina Net损失函数
- 代码
Retina Net
论文图:
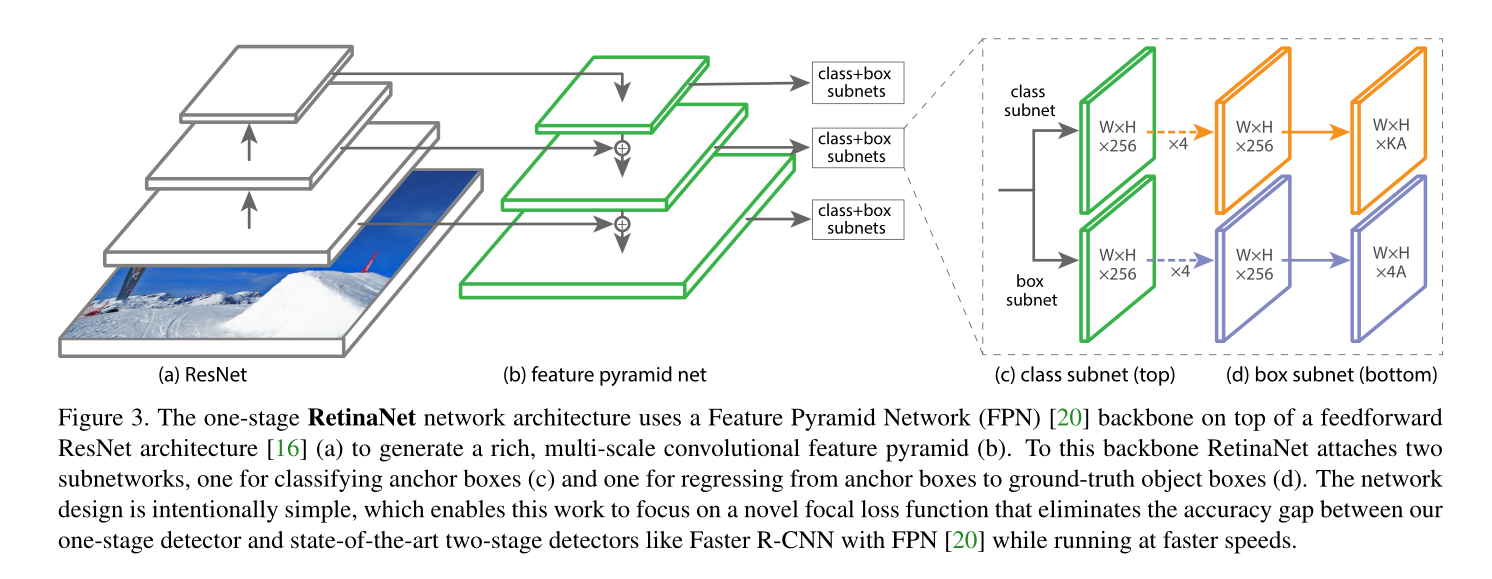
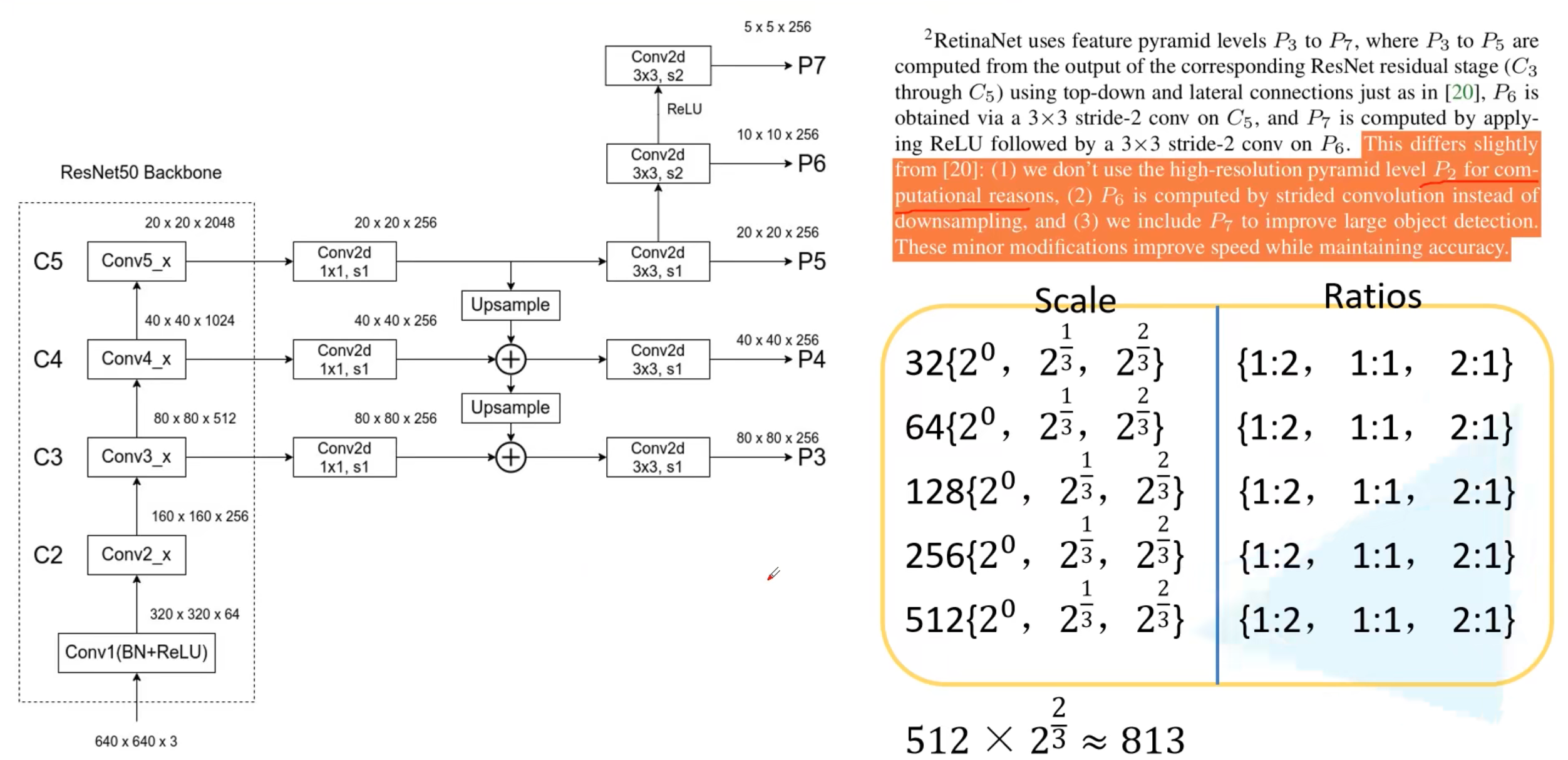
backbone采用FPN, 为了缩小计算量,使用这样的构建,采用P3~P7。 每层是不一样的9组anchors。
Focal Loss
Focal Loss,当 g a m m a = 0 gamma=0 gamma=0 , Focal Loss退化为 CE Loss。
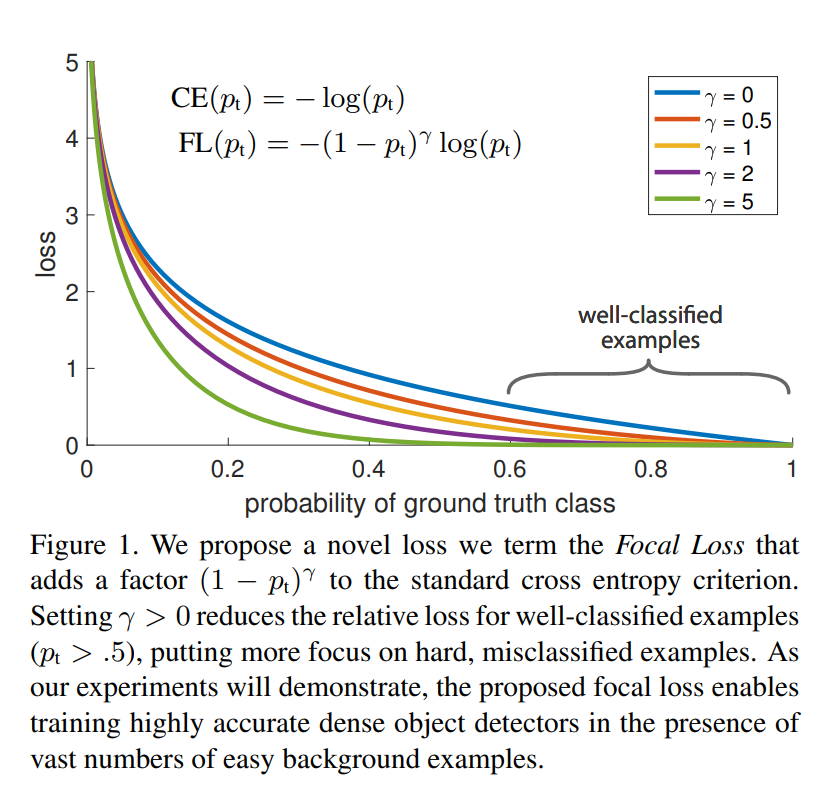
CE Loss是:
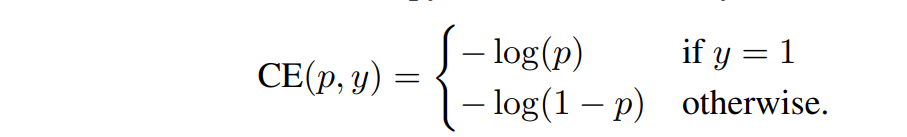
Focal Loss, g a m m a gamma gamma 被称为 tunable focusing parameter,实验结果是 g a m m a gamma gamma 效果最好。
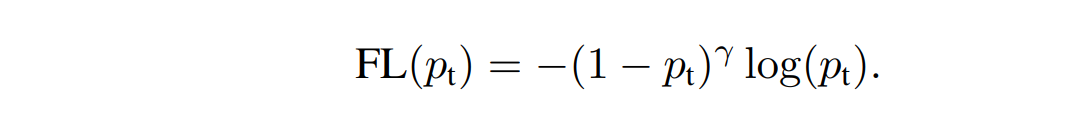
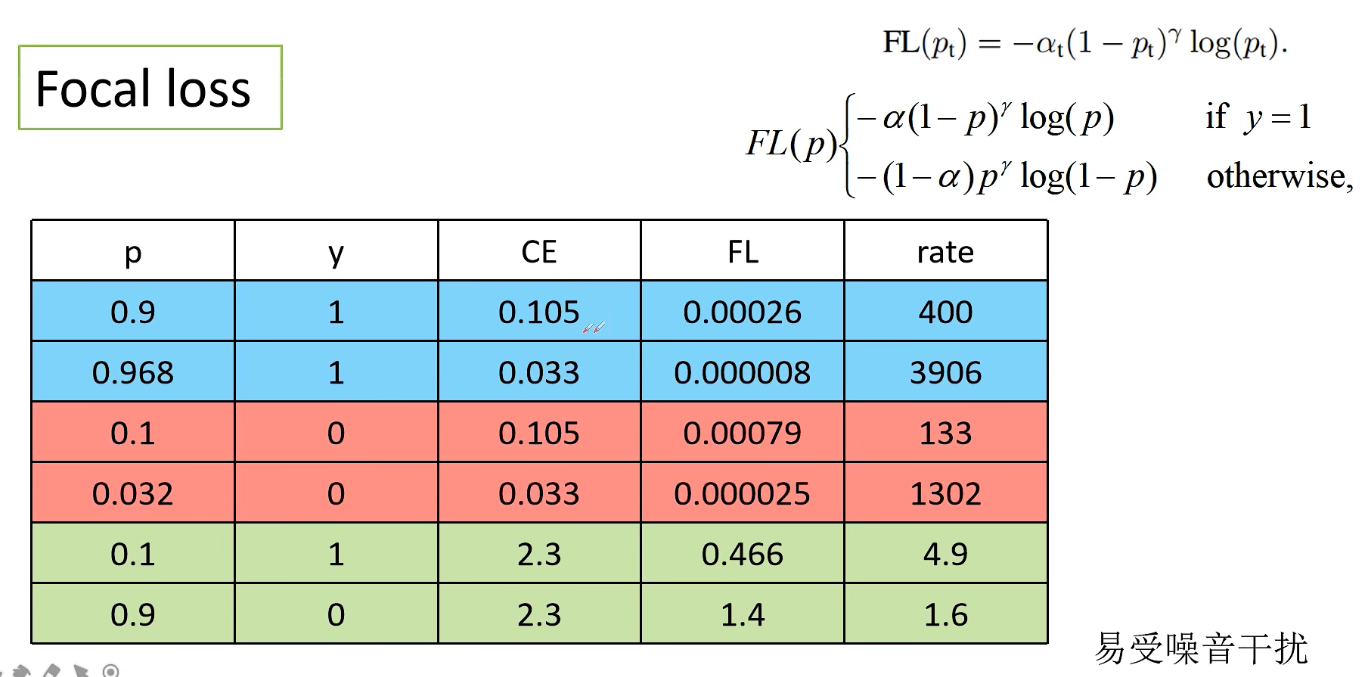
前2行,得出的概率很高,是易分样本,CE计算得到的损失与FL计算得到的损失相差很大,FL侧重于表达已经达到了不错的效果。
中间2行类似。
最后两行难样本的损失非常大。
Retina Net损失函数
分类损失:计算所有正负样本的Focal Loss加和,然后只除以正样本的个数。使用sigmoid Focal Loss。
回归损失:所有正样本的回归损失加和,然后除以正样本的个数。使用L1损失。

代码
https://www.kaggle.com/code/thedrcat/focal-multilabel-loss-in-pytorch-explained/notebook
import torch
torch.set_printoptions(precision=4, sci_mode=False, linewidth=150)def focal_binary_cross_entropy(logits, targets, gamma=2):l = logits.reshape(-1)t = targets.reshape(-1)p = torch.sigmoid(l)p = torch.where(t >= 0.5, p, 1-p)logp = - torch.log(torch.clamp(p, 1e-4, 1-1e-4))loss = logp*((1-p)**gamma)loss = num_label*loss.mean()return loss
参考:
https://www.bilibili.com/video/BV1Q54y1L7sM?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1yi4y1g7ro?p=4