项目需求分析
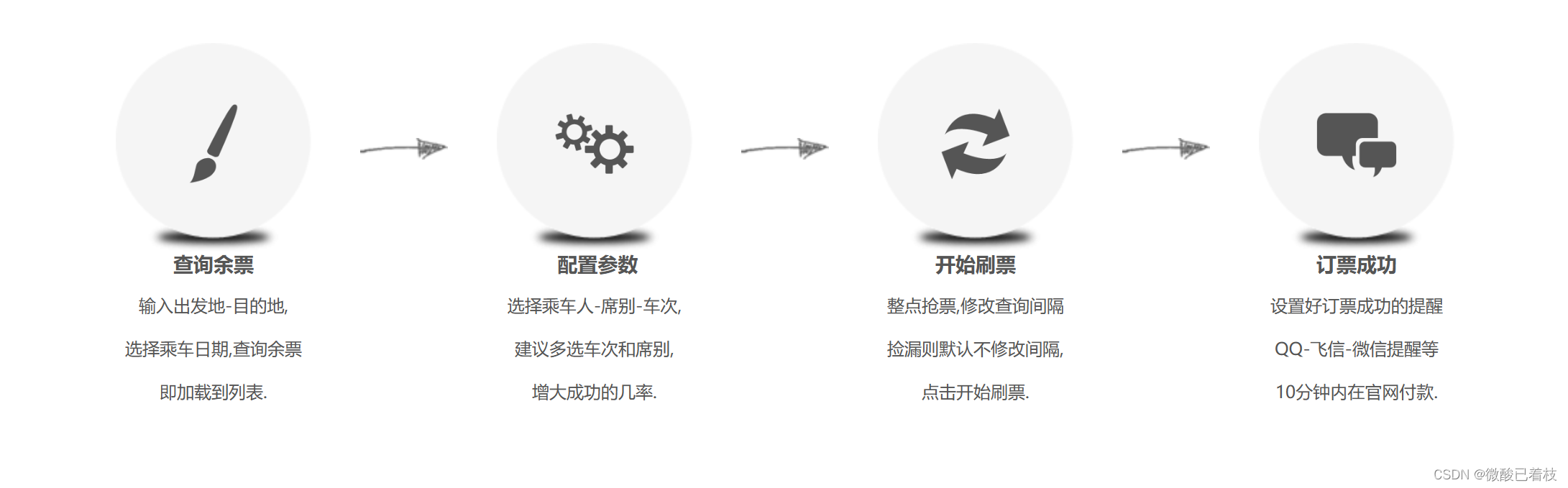
整个项目应实现:浏览器自动登录12306网站,查询余票,车票预订,到自动提交系统支付的功能。
具体包括:登录界面的cookie处理(保持登录界面)、登录时的验证码处理、余票查询、提交订单等部分。
分析:
借助工具fiddler,作为整个数据传输的记录环节。整个登录环节包括六个部分的验证才能实现。
用到的模块:
urllib.request:获取网页
re:正则
ssl:提供https支持
urllib.parse.urlencode:数据转换
http.cookiejar:cookie处理
datetime:日期函数
time:可作时间延迟
登录模块
cookie处理:
为保持登录界面的,需要提前进行cookie处理。
功能实现:
#建立cookie处理
print('cookie 处理中')
cjar=http.cookiejar.CookieJar()
opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar)) #先声明使用cookiejar对象,再建立opener
urllib.request.install_opener(opener) #将opener安装为全局1.验证码处理
关键点:
如何进行验证码的识别?通过fiddler抓包分析可推出:验证码的每张图片都代表着一个"坐标值",并且每个坐标在一定的范围内变动。
验证码网址:
https://kyfw.12306.cn/passport/captcha/captcha-check
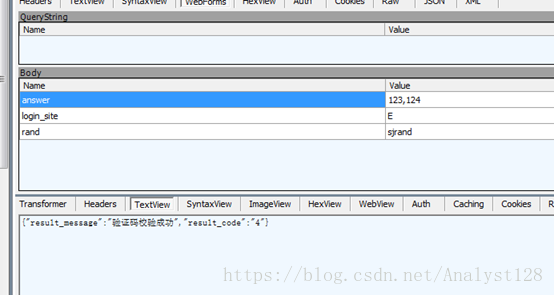
此过程进行的是Post请求,下面是需要提交的"报表数据":
answer :123,124
login_site:E
rand:sjrand
功能实现:
#验证码处理并验证
#验证码网址
yzmurl='https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand'
#验证码的处理,避免验证码出错,再次输入
while True:urllib.request.urlretrieve(yzmurl,'D:/爬虫工程师/yzm.png')yzm=input('请输入验证码,输入第几张图片即可')if (yzm!='regain'):break
#输入图片坐标位置格式:'1','2','3','4','5'
#验证码图片处理,图片序号转坐标
pat1='"(.*?)"' #提取数字
allpic=re.compile(pat1).findall(yzm) #匹配所有图片数字位置
#定义数字转坐标函数
def getxy(pic):if(pic==1):xy=(30,40) #横纵坐标在一定范围内变动,不是固定不变的if(pic==2):xy=(110,45)if(pic==3):xy=(190,45)if(pic==4):xy=(250,42)if(pic==5):xy=(36,110)if(pic==6):xy=(112,120)if(pic==7):xy=(190,120)if(pic==8):xy=(265,114)return xy allpicpos=""
for i in allpic:thisxy=getxy(int(i))for j in thisxy:allpicpos=allpicpos+str(j)+"," #把坐标拼接起来,并以逗号作为分割#print(str(j))#print(thisxy)
#print(allpicpos)
#print(type(allpicpos))
allpicpos2=re.compile("(.*?).$").findall(allpicpos)[0] #从开始一直匹配到最后为止,并且不包含最后一个字符串逗号
print(allpicpos2)
'''验证码的验证'''
yzmposturl='https://kyfw.12306.cn/passport/captcha/captcha-check'
yzmpostdata=urllib.parse.urlencode({'answer':allpicpos2,'login_site':'E','rand':'sjrand',}).encode('utf-8')
req1=urllib.request.Request(yzmposturl,yzmpostdata)
req1.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')
req1data=urllib.request.urlopen(req1).read().decode('utf-8','ignore') #请求完成2.账户密码处理
表单提交网址:
https://kyfw.12306.cn/passport/web/login

此过程进行的是post请求,下面为提交的表单数据:
username :xxxxxx@qq.com
password :xxxxxx
appid:otn
功能实现:
'''post账户密码验证'''
loginposturl='https://kyfw.12306.cn/passport/web/login'
loginpostdata=urllib.parse.urlencode({'username':' xxxxxxxx@qq.com','password':'xxxxxxxxx','appid':'otn',
}).encode('utf-8')
req2=urllib.request.Request(loginposturl,loginpostdata)
req2.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')
req2dta=urllib.request.urlopen(req2).read().decode('utf-8','ignore')3.进一步验证:
验证网址:
https://kyfw.12306.cn/otn/login/userLogin
_json_att:" "

功能实现:
'''第三个验证,get'''
loginposturl2="https://kyfw.12306.cn/otn/login/userLogin"
loginpostdata2 =urllib.parse.urlencode({
"_json_att":"",
}).encode('utf-8')
req2_2 = urllib.request.Request(loginposturl2,loginpostdata2)
req2_2.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')
req2data_2=urllib.request.urlopen(req2_2).read().decode("utf-8","ignore")4.接着,第四步验证:
验证网址:
https://kyfw.12306.cn/passport/web/auth/uamtk
appid :otn

网页数据:
{"result_message":"验证通过","result_code":0,"apptk":null,"newapptk":"ABjHqP-aejeNjN6ddNvCrNxNsb2MzejW3-VKQG5Z502ZObX5pl2220"}
功能实现:
'''第四个验证post'''
loginposturl3="https://kyfw.12306.cn/passport/web/auth/uamtk"
loginpostdata3 =urllib.parse.urlencode({
"appid":"otn",
}).encode('utf-8')
req2_3 = urllib.request.Request(loginposturl3,loginpostdata3)
req2_3.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')
req2data_3=urllib.request.urlopen(req2_3).read().decode("utf-8","ignore")
pat_req2='"newapptk":"(.*?)"' #提取下一步验证需要的tk值
tk=re.compile(pat_req2,re.S).findall(req2data_3)[0]5.第五步验证:
验证网址:
https://kyfw.12306.cn/otn/uamauthclient
tk :ABjHqP-aejeNjN6ddNvCrNxNsb2MzejW3-VKQG5Z502ZObX5pl2220
注意到:tk取值在上一个页面中!

功能实现:
'''第五个验证'''
loginposturl4="https://kyfw.12306.cn/otn/uamauthclient"
loginpostdata4 =urllib.parse.urlencode({
"tk":tk, #此处的tk值在上一步连接中
}).encode('utf-8')
req2_4 = urllib.request.Request(loginposturl4,loginpostdata4)
req2_4.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')6.最后登录到个人中心:
个人中心所在网址:
https://kyfw.12306.cn/otn/index/initMy12306
所在网页的数据包:

功能实现:
'''爬取个人中心'''
centerurl='https://kyfw.12306.cn/otn/index/initMy12306'
req3=urllib.request.Request(centerurl)
req3.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')
req3data=urllib.request.urlopen(req3).read().decode("utf-8","ignore")
print('登录完成')
余票查询模块
车票页面网址:
https://kyfw.12306.cn/otn/leftTicket/init

数据隐藏在接口中,通过抓包分析得到对应的网址:
https://kyfw.12306.cn/otn/leftTicket/queryA?leftTicketDTO.train_date=2018-09-11&leftTicketDTO.from_station=NJH&leftTicketDTO.to_station=SHH&purpose_codes=ADULT
接口页面对应的数据集:

webforms:
purpose_codes:ADULT
leftTicketDTO.train_date:2018-09-11
leftTicketDTO.to_station:SHH
leftTicketDTO.from_station:NJH
功能实现:
'''查询余票,此步骤可放在第一步,也可放在登录后'''
#抓包分析得到三字码与站点之间的对应
areatocode={"上海":"SHH","北京":"BJP","南京":"NJH","杭州":"HZH"}
start1=input("请输入起始站:") #:例如:"南京"
start=areatocode[start1]
to1=input("请输入到站:")
to=areatocode[to1]
isstudent=input("是学生吗?是:1,不是:0") #例如:"0"
date=input("请输入要查询的乘车开始日期的年月,如2017-03-05:") #格式:2018-09-12
if(isstudent=="0"):student="ADULT"
else:student="0X00"
#构造查询页面网址
'''
https://kyfw.12306.cn/otn/leftTicket/queryA?leftTicketDTO.train_date=2018-09-11
&leftTicketDTO.from_station=NJH&leftTicketDTO.to_station=SHH&purpose_codes=ADULT
'''
url="https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date="+date+"&\
leftTicketDTO.from_station="+start+"&leftTicketDTO.to_station="+to+"&purpose_codes="+student
#date格式2018-09-10
context = ssl._create_unverified_context()
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
patrst01='"result":\[(.*?)\]' #转义符,使之匹配正常的中括号
rst01=re.compile(patrst01).findall(data)[0]
allcheci=rst01.split(",") #以逗号分隔,每一个逗号后面都是一个车次信息
checimap_pat='"map":({.*?})' #提取车次信息
checimap=eval(re.compile(checimap_pat).findall(data)[0]) #转为字典
print("车次\t出发站名\t到达站名\t出发时间\t到达时间\t一等座\t二等座\t硬座\t无座")
for i in range(0,len(allcheci)):try:thischeci=allcheci[i].split("|")#[3]---codecode=thischeci[3]#[6]---fromnamefromname=thischeci[6]fromname=checimap[fromname]#[7]---tonametoname=thischeci[7]toname=checimap[toname]#[8]---stimestime=thischeci[8]#[9]---atimeatime=thischeci[9]#[28]---yzyz=thischeci[31]#[29]---wzwz=thischeci[30]#[30]---zeze=thischeci[29]#[31]---zyzy=thischeci[26]print(code+"\t"+fromname+"\t"+toname+"\t"+stime+"\t"+atime+"\t"+str(zy)+"\t"+str(ze)+"\t\"+str(yz)+"\t"+str(wz))except Exception as err:pass
isdo=input("查票完成,请输入1继续…")
#isdo=1
if(isdo==1 or isdo=="1"):pass
else:raise Exception("输入不是1,结束执行")
print("Cookie处理中…")后续操作陆续更新中: