Redis实现高可用的方案有很多中,先了解下高可用和分区的概念:
高可用是指系统在面对硬件故障、网络故障、软件错误等意外问题时,仍能给客户端提供正常的服务,尽量的减少服务的阻塞、终端现象。在高可用的方案中一般会采用冗余备份、故障转移、和自动切换技术,来保障系统的可用性和稳定性。
比如Redis中高可用的架构体现:
1、主从复制(replication)
将一个主节点设置多个从节点,从节点会有数据备份的功能,当主节点故障了可以通过人工进行故障转移,将从节点接替主节点
2、哨兵模式(sentinel)
Redis哨兵模式,可以用来监控集群中主从节点状态信息,当发生主节点故障时,会进行自动故障转移工作。
3、Redis集群(cluster)
Cluster是Redis官方提供的分布式解决方式,它可以实现数据分区 和 自动故障转移。保障了稳定性和可用性。
4、第三方解决方案
Redis集群 Cluster
集群Cluster使Redis官方提供的一直分布式高可用分区集群解决方案。它实现了数据分片、故障转移、以及方便客户端的路由功能,保障了高可用性和扩展能力。
Redis Cluster使用了分区槽(slots)概念来管理数据分片和迁移的功能。
特性:
1、数据分区:Cluster将数据分割成16384个槽位,每个槽位可以映射一对key-value,这些数据将被不同的Redis节点管理。
2、自动的分区和迁移:Cluster根据Redis节点平均分配不同的槽位范围,数据通过hash算法,确定映射在哪个分区,从而确定由哪个Redis实例存储和处理。当完成故障转移工作,会自动的完成从节点的数据槽位迁移工作。
3、故障转移高可用性:Cluster实现了类似于Sentinel的故障转移功能,当主节点发生故障时,会进行故障转移操作,将从节点顶替主节点,实现了高可用性。
4、gossip协议:Cluster不像Sentinel是一个独立的redis实例去监控和故障转移,主从节点会被以Cluster模式启动,集群节点之前通过流言协议(gossip)进行交互、信息交换和监控,比如当发现主节点出现故障时,各个节点通过流言协议判断并进行故障转移操作。
5、客户端路由:用户客户端和集群的交互是通过集群客户端进行的,集群客户端会通过key的hash值来判断并转发到指定的redis实例上。实现了方便客户端的路由功能。
数据分区:
Redis集群没有使用到一致性Hash,而是引入了Hash槽的概念:
Redis集群一共拥有16384个槽位,每个key通过crc16hash算法校验后对16384取模来决定放入哪个槽,集群的每个Redis节点负责一部分槽位,如下:
比如有3个redis节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这样的结构很容进行删除和新增操作,比如新增一个节点D,只需要将A,B,C三个节点中部分节点迁移到D节点中;如果想删除一个节点A,则将A节点的槽位分摊到B,C节点上即可。在整个槽位迁移过程中,不能导致服务停止状态,所以不会造成集群不可用。但是涉及到迁移的节点会有短暂的不可用窗口,一般会提示客户端 数据在迁移过程中:
面对这种问题,可以通过一些手段将影响降到最低:
1、确保迁移速度,比如加大带宽的硬件配置,提高迁移速度,减少不可用时间。
2、逐步迁移:将被迁移的数据进行分批处理,减少不可用窗口。
3、监控和控制:可以做好一些监控措施,当返现服务不可用时,进行响应的对应措施,降低影响。
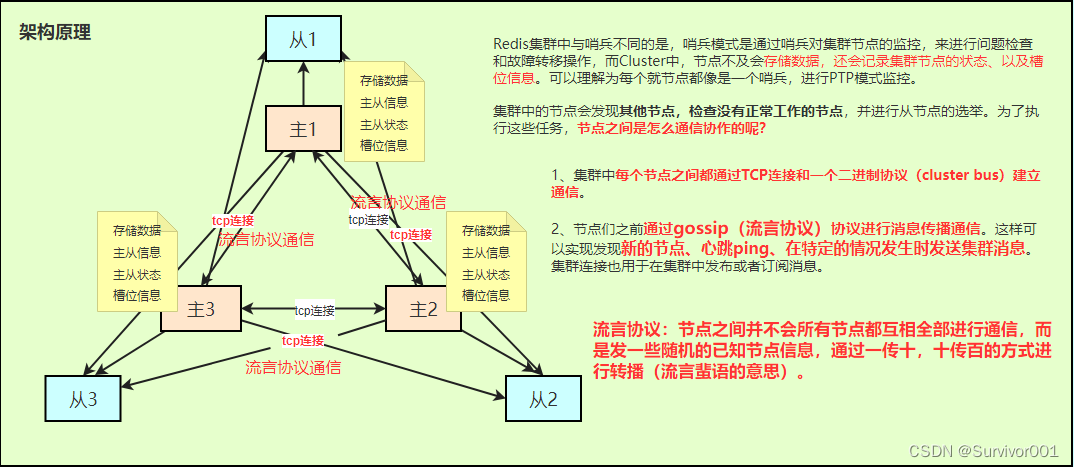
故障转移 :
上面了解到,Redis集群中节点之间会通过流言协议进行通信,当多个节点都认定某个节点ping失败时,就认定其发生故障Fail,并开始从其从节点中选举一个适合从节点来进行故障转移,如果没有可用的从节点来替换,则集群将被置为错误状态,并停止客户端使用。详细过程如下:



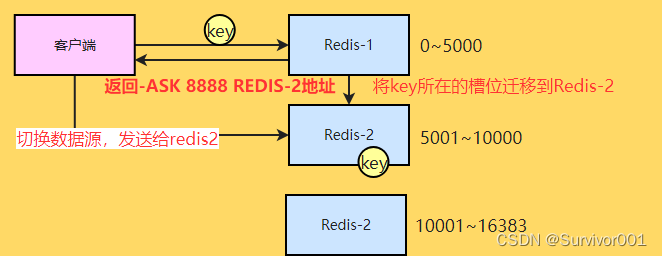
MOVED重定向
集群中会存在多个节点负责管理不同槽位的数据,但是对于客户端来说,只会连接到其中一个节点,当客户端请求的数据key不再当前连接的
Redis实例时,当前节点会返回 -MOVED 8888 127.0.0.1:6381 信息,其中包括了当前key所在的槽位和IP地址

ASK重定向
Ask重定向发生于集群伸缩是,集群伸缩会导致槽位的迁移,当我们去源节点访问时,此时数据可能已经迁移到了昕的目标节点了,此时会ASK重定向来解决此种情况。
什么情况会导致集群down
1、主节点发生故障时,且没有可用的从节点。
2、启动集群时,因为某些原因,导致存在槽位没有正常分配除去
3、集群启动时,存在主节点没有正常启动等
集群down时,问题定位
问题描述:启动集群节点后,进入7379主中进行set请求,报错:(error) CLUSTERDOWN The cluster is down
查看集群拓扑信息,返现有槽位没有分配完

进入到7379节点中,查看槽位信息, 发现槽位分配中存在0~1999槽位分配给了未知redis实例
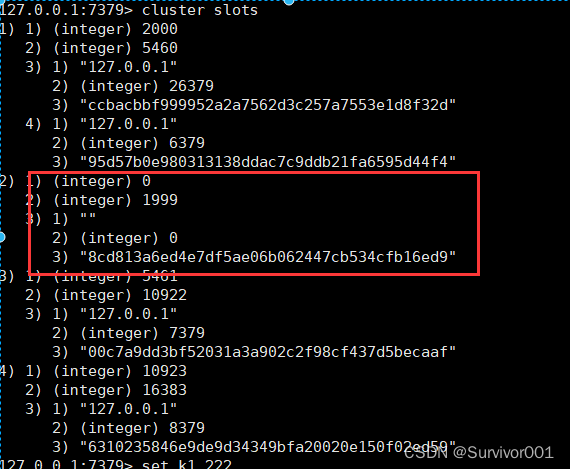
通过nodes-7379.conf 配置文件查看,确实发现了存在位置IP的实例和0~2000槽位
解决办法:将未知实例删除 ,可以直接删除配置中的记录。同时手动修改槽位分配信息(当然可以通过指令操作)

原图地址: