FusionSphere OpenStack 6.5方案介绍
OpenStack 系统架构
OpenStack是什么
OpenStack是目前最流行的开源云操作系统:
- 资源抽象
- OpenStack将各类硬件资源,通过虚拟化与软件定义的方式,抽象成资源池
- 资源分配与负载调度
- OpenStack根据管理员/用户的需求,将资源池中的资源分配给不同的用户,承载不同应用
- 应用生命周期管理
- OpenStack已经可以提供初步的应用部署/撤除、自动规模调整能力
openstack为什么是云操作系统?
openstack是不是操作系统?——》不是
操作系统有哪些功能?
- 识别、驱动硬件
- 抽象、逻辑硬件
- 分配资源应用程序
- 应用程序生命周期管理
- 人机交互界面,cli web
- 故障监控、设置
openstack有类似于操作系统的功能,有是用于管理云的,所以openstack是云操作系统。
社区项目分层
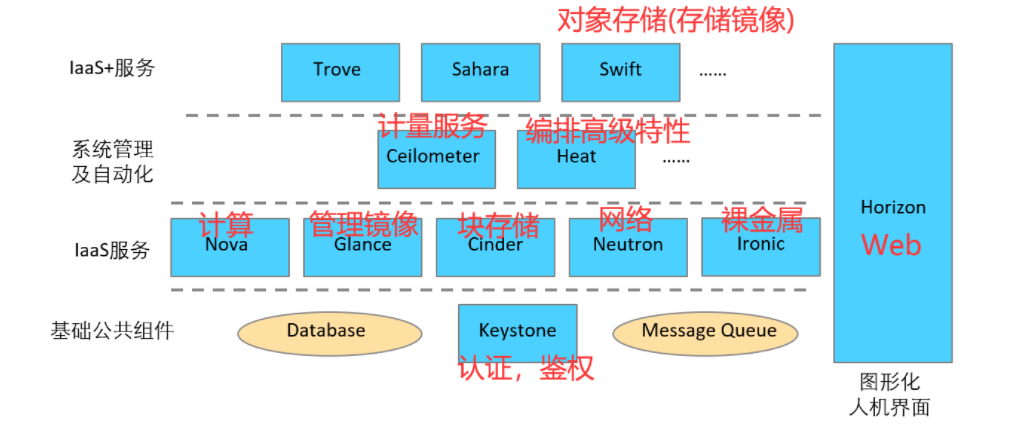
- nova:计算服务
- cinder:块存储服务
- glance:镜像服务
- swift:对象存储服务
- manila:文件存储服务
- neutron:软件定义网络服务
- ceilometer:计量、监控服务
- heat:应用编排服务
- keystone:认证鉴权服务
- ironic:裸金属服务
- horizon:图形化人机界面服务(不用)
逻辑关系图
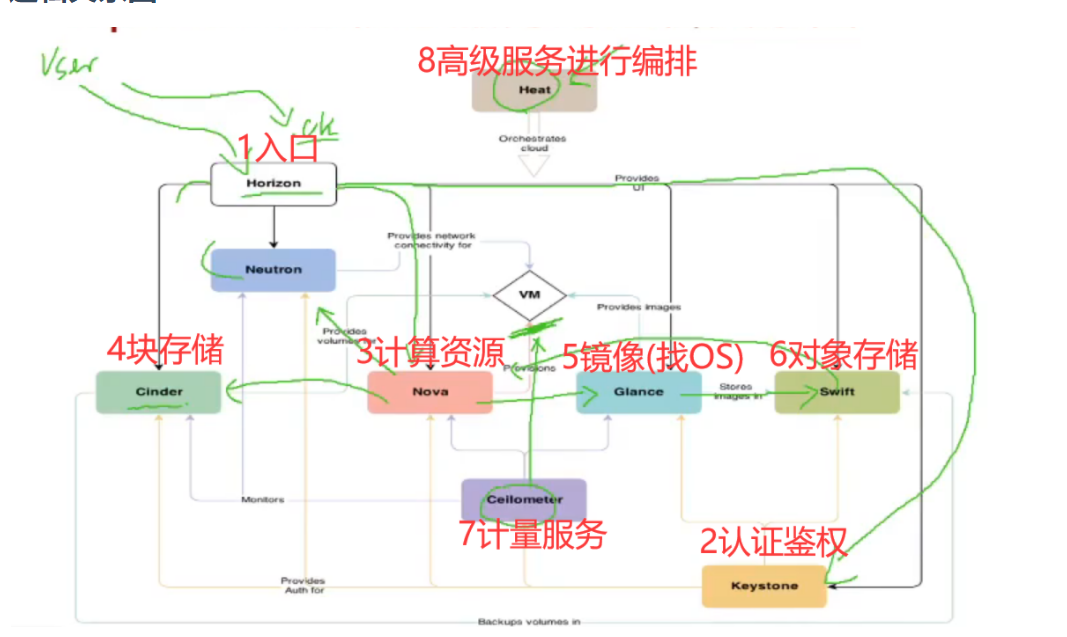
openstack中的存储:
1、cinder的块存储
2、swift的对象存储
3、manila的文件存储
4、nova的本地存储
节点的本地存储,可能是nova的本地存储,也可能是cinder的块存储(lvm)|
Nova-计算服务
由hypervisor实现计算虚拟化,Nova只负责提供计算服务。
OpenStack组件不能实现虚拟化!!!
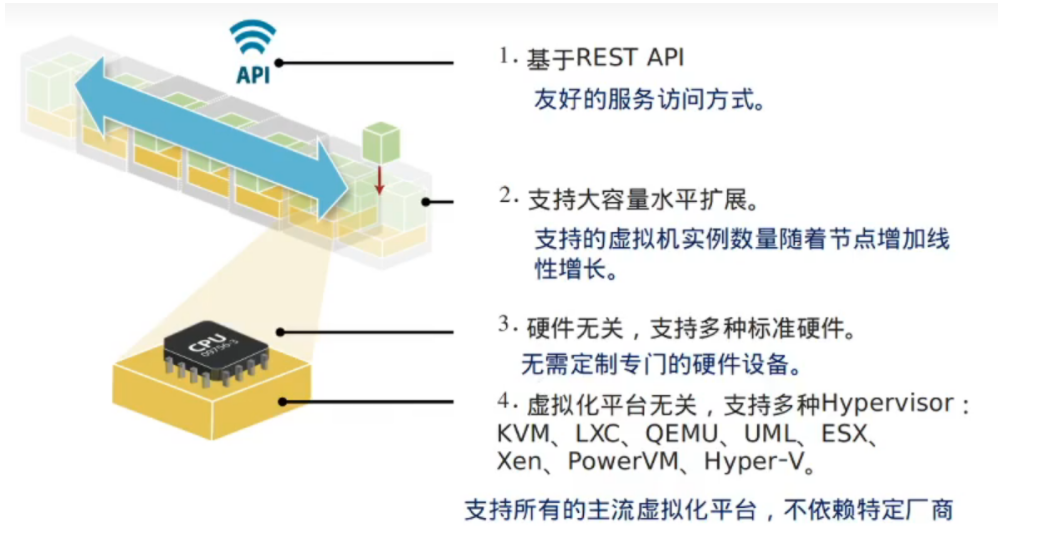
rest api(友好)
位于openstack和*人/第三方组件(keystone)*之间,类似于方向盘方便人/第三方组件和OpenStack的交互。
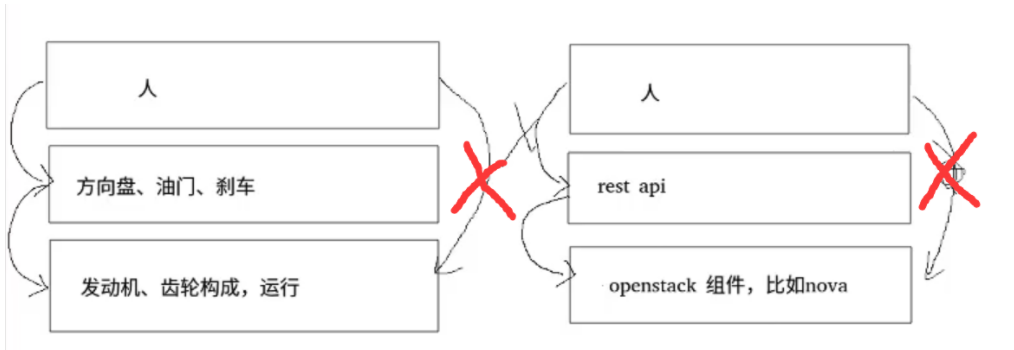
nova计算服务
- 基于rest api
- 水平扩展
- 与硬件无关(组件运行在os)
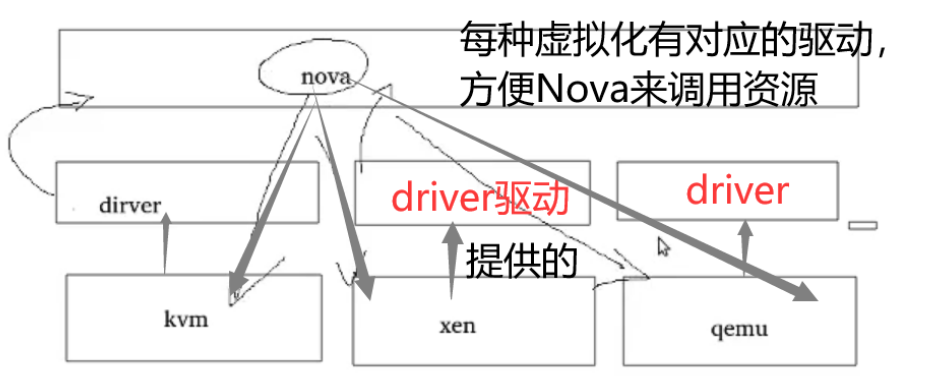
- 与虚拟化平台无关(通过dirver对接虚拟化平台)
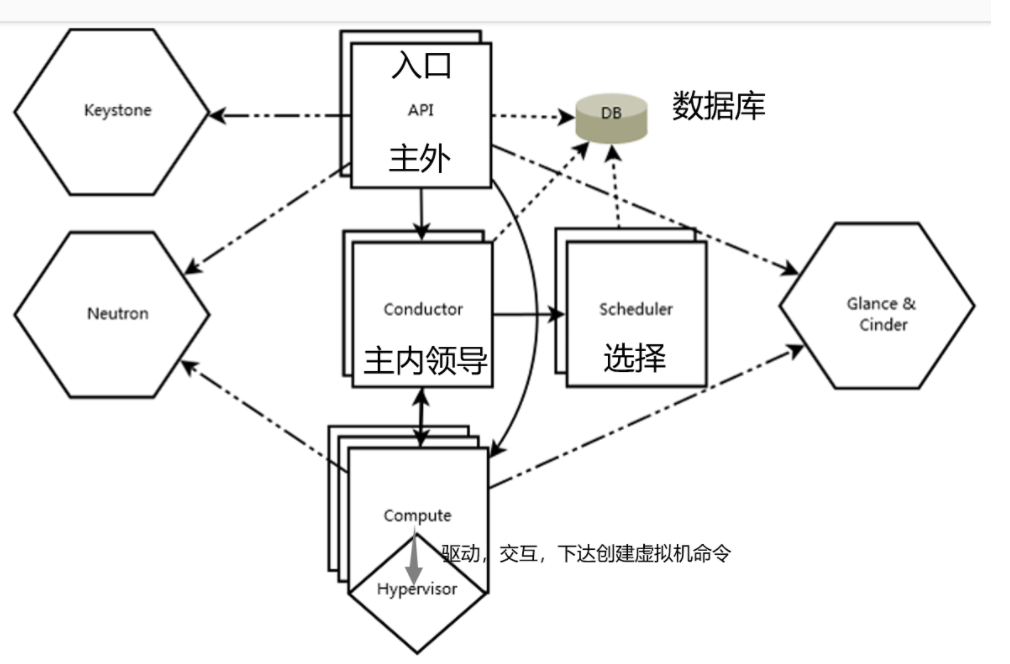
系统架构
OpenStack内部有三种组件:
1、openstack本身的服务: 比如计算nova、块存储cinder等
2、服务内部子组件: 比如nova内部的apilcompute等
3、openstack所使用的公共组件: DB(数据库)、MQ(消息队列)
三种访问方式:
1、openstack不同服务的通信,比如nova访问keystone,glance访问swift(基于http的rest api访问)
2、服务内部子组件通信,比如nova内部的api访问compute (基于MQ的rpc调用)
3、访问数据库
Nova创建一个虚拟机流程
- user向nova发出创建虚拟机的请求。
- nova-api接收,处理(1、身份认证鉴权。2、配置校验申请。3、数据库)
- nova-api组装请求+scheduler相关的信息 (flavor\az\image等)发送给conductor。
- nova-conductor转发给nova-scheduler选择主机
- nova-scheduler根据前面scheduler选择主机(1、filter。2.1、权重,默认内存、可选CPU;2.2、随机)
- nova-scheduler把主机返回给nova-conductor。
- nova-conductor调用该主机对应的nova-compute,要求创建虚拟机
- nova-compute对计算资源加锁。
- nova-compute请求neutron准备port
- nova-compute请求cinder准备disk
- 启动虚拟机
12.nova-compute向glance下载镜像 - 生成虚拟机xml
- 通过dirver调用libvirt接口拉起虚拟机。
控制节点:部署绝大部分openstack组件(及其内部子组件)
计算节点:运行虚拟机
-
nova-api: nova的入口,接受rest消息。调用其他组件完成相应的动作。——》部署在控制节点
- 1、对外提供rest接口的处理
- 2、对传入的参数进行合法性校验和约束限制
- 3、对请求的资源进行配额(quota)的校验和预留
- 4、资源的创建,更新,删除查询等
- 5、虚拟机生命周期的入口
- 6、可水平扩展部署
-
nova-scheduler:选择合适的主机。——》部署在控制节点
- 选择的过程:
- 1、filter列表
- 2.1、权重(默认是内存权重、可选择CPU权重),排序,首位选择
- 2.2、散列:在候选的一个大小范围内的主机中,随机选择一个主机。
- 3、内置周期性任务,完成资源刷新,虚拟机状态同步等功能。
-
nova-conductor:1、复杂流程控制2、帮助nova-compute访问数据库。——》部署在控制节点
- 1、数据库操作。解耦其他组件( nova-compute)数据库访问。
- 2、Nova复杂流程控制,如创建,冷迁移,热迁移,虚拟机规格调整,虚拟机重建。
- 3、其他组件的依赖。如nova-compute需要依赖nova-conductor启动成功后才能启动成功。
- 4、其他组件的心跳定时写入。
- 5、可水平扩展部署(多活)
-
nova-compute:虚拟机生命周期管理、资源管理。——》部署计算节点。(当控制节点也作为计算节点时,也需要部署黜)
- 1、虚拟机各生命周期操作的真正执行者(会调用对应的hypervisor的driver) 。
- 2、底层对接不同虚拟化的平台(kvm , vmware ,xen,Fusioncompute , hyperv等)。
-
nova-novncproxy : novnc访问虚拟机代理。——》部署在控制节点。(不重要)
-
nova- conseleauth: novnc访问虚拟机鉴权。——》部署在控制节点。(不重要)
资源池管理
开源:
- region:地理上的区域
- 可用分区:具备相同的供电、制冷的主机集合,实际上可理解为一个机房
- 主机组:具备相同属性的的主机集合,比如,具备SSD的主机的集合
华为:
- region:地理上的区域
- 可用分区:具备相同网络、存储环境的主机集合,可实现热迁移、HA。隐藏要求:必须是同种虚拟化。比如KVM,或者XEN
- 主机组:具备相同属性的的主机集合。隐藏要求:必须是同种虚拟化。比如KVM,或者XEN

FusionCloud6.3及以后使用KVM,6.3以前使用VRM (XEN)
主机到底是不是一个服务器呢?
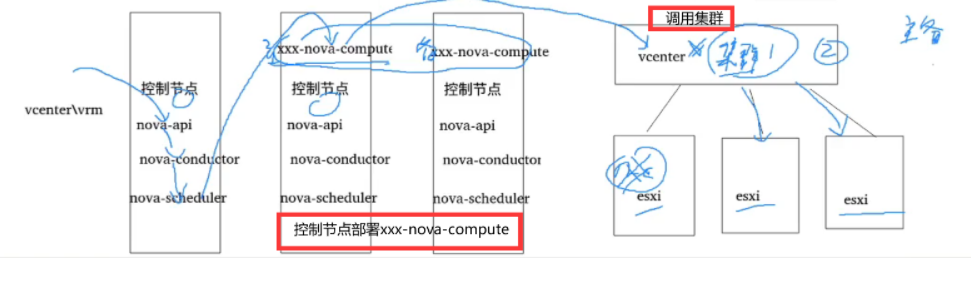
1、KVM、XEN等——》一个nova-compute对应一个主机,对应一个服务器。(如图上面的)
2、vsphere(VM公司的)、VRM(早期华为公司基于XEN开发的)——》一对nova-compute对应一套VRM或者vsphere,后端可能有多个CNA,openstack上的一个"主机"对应的是VRM或者vphere上一个集群。集群内可能包含 0~N 服务器 。(如图下面的)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ezSSIfX-1672748301373)(D:\代码笔记\HCIE—Cloud Compueing V2.0\云计算运营\image-20230102202924724.png)]](https://img-blog.csdnimg.cn/img_convert/5464db3a121f172f42f258470dd961d0.png)
单点or集群
- nova-compute部署方式、部署位置
- 对于KVM、XEN,甚至华为6.3私有云。
- 对于整套openstack来说,nova-compute是多活,scheduler是可以选择到任意nova-compute。但实际上,对于单个计算节点来说,nova-compute是单点的。
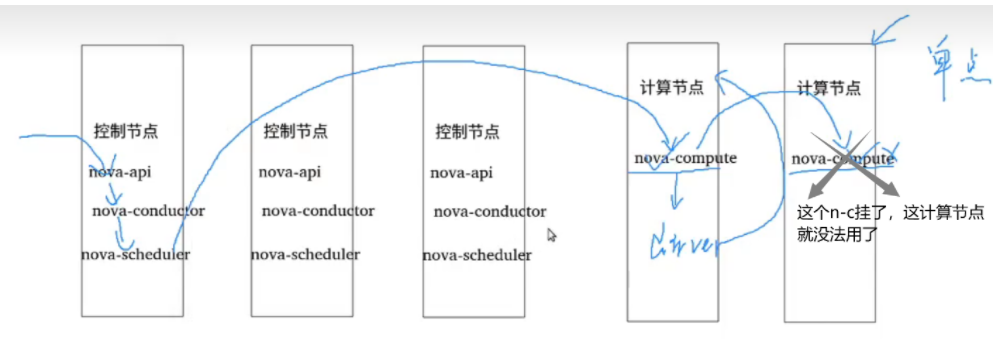
- 对于vrm\vcenter来说,部署是xxx-nova-compute。一对主备的xxx-nova-compute对应一个集群。随机部署在两个控制节点上。
- vrm是fc-nova-compute
- vcenter是vcenter-nova-compute
keystone-认证鉴权、服务目录认证鉴权
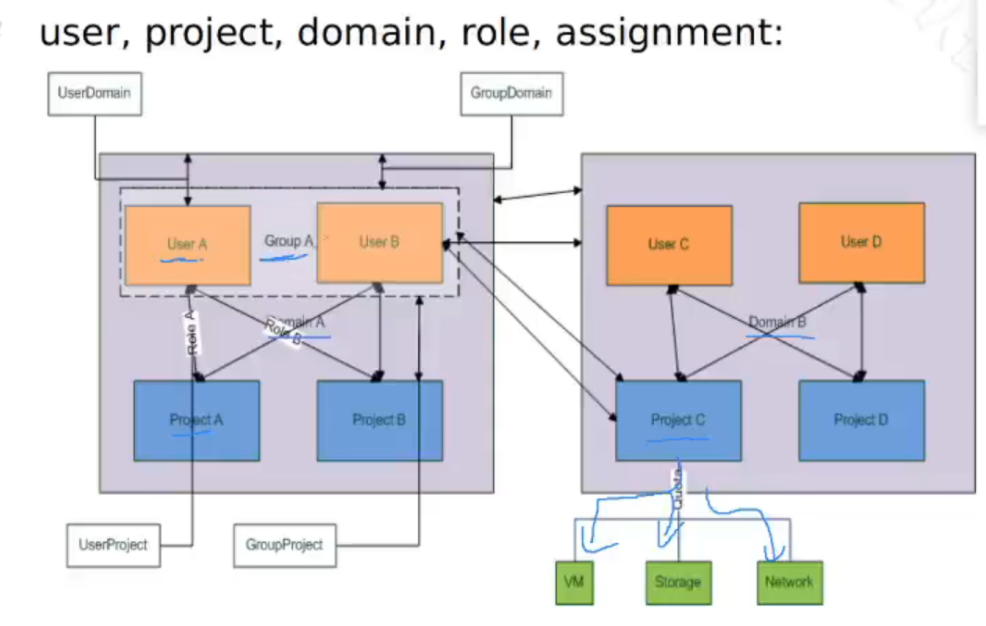
认证鉴权
- Domain:域,keystone中资源(project、user.group)的持有者
- Project:租户,其他组件中资源(计算资源、存储资源、网络资源等)的持有者《华为的区别:6.3以前,domain=组织,project=vdc、租户;6.3及以后,domain区域,project=vdc,最多可以有五级VDC》
- User:用户,云系统的使用者
- Group:用户组,可以把多个用户作为一个整体进行角色管理
- Role:角色,基于角色进行访问控制
- Trust:委托,把自己拥有的角色临时授权给别人
- Policy:访问控制策略,定义接口访问控制规则
- Assignment:授权三元组,一个(actor, target,role)三元组叫一个assignment,actor包括user、group,target包括domain、project。每个assignment代表一次赋权操作
- Token:令牌,用户访问服务的凭证,代表着用户的账户信息,一般需要包含user信息、scope信息(project、domain或者trust) . role信息。分为PKI,UUID,PKIZ,Fernet几种类型。
- Token是什么:
用户向keystone提供一组有效的用户信息,keystone向用户返回一个token。
Token包含这个用户的信息,用户的角色(role)信息,toKen的作用域(scope), token有效期(expiration)。
使用这个token可以访问其他openstack服务。为什么使用Token :
使用token访问api服务比使用用户名密码访问更加方便。
Token具有有效期,在客户端缓存token比缓存用户名密码更安全。
- Token是什么:
服务目录
- Region:区域,在keystone里基本代表一个数据中心
- Service:服务,一组相关功能的集合,比如计算服务、网络服务、镜像服务、存储服务等
- Endpoint:必须和一个服务关联,代表这个服务的访问地址,一般一个服务需要提供三种类型的访问地址:public. internal、admin
- public: 公开,可以给外部用户使用。
- internal:内部,服务与服务相互访问
- admin: openstack管理员使用
对象模型
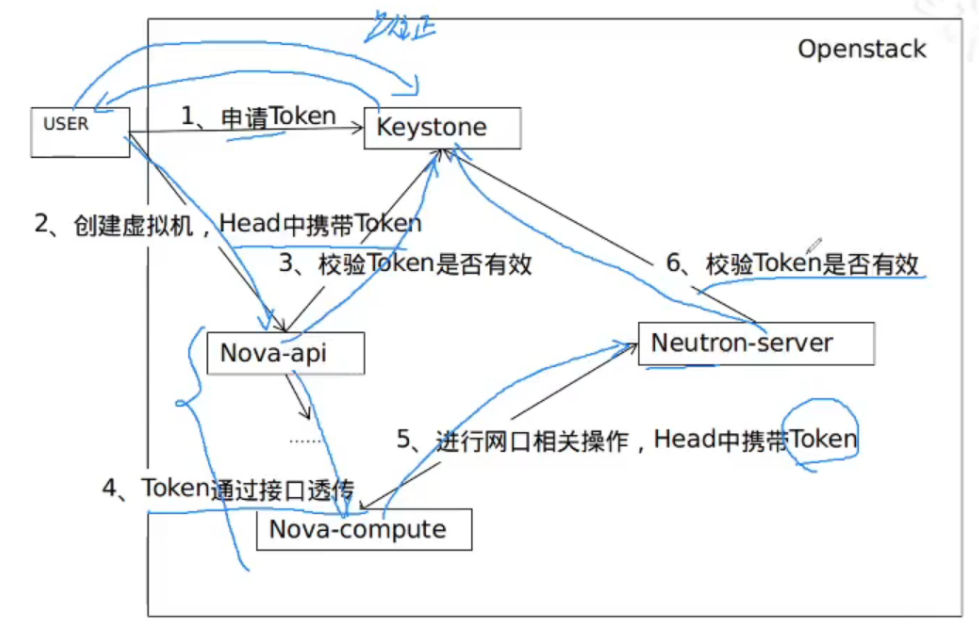
Token
token在openstack中的使用?
- 申请,用户使用用户名密码找keystone进行认证,申请
- 使用,用户携带token请求api,api剥离找keystone验证
- 在同个服务内,不需要再次验证token。如果跨服务,需要再次验证token
token记录用户名、密码、domain 作用域(domain\project)、有效期。
token类型
1、uuid
每次验证需要访问keystone服务端。
过程:
client携带用户名密码向keystone申请UUID , keystone生成本地保存一份,向client发送一份,client会保存。client向api发送请求时,会在请求头部携带token。api收到后,剥离向keystone进行验证。keystone与本地保存的token比较。正确200,错误401
优点:
- 在一定程度解决密码不安全的问题。
- 相比密码的方式,不用每次都输入密码,便利。
缺点:
- keystone需要在存储中持久保存一份token,存储压力大。
- api每次请求,均需要到keystone验证,keystone负载压力大。
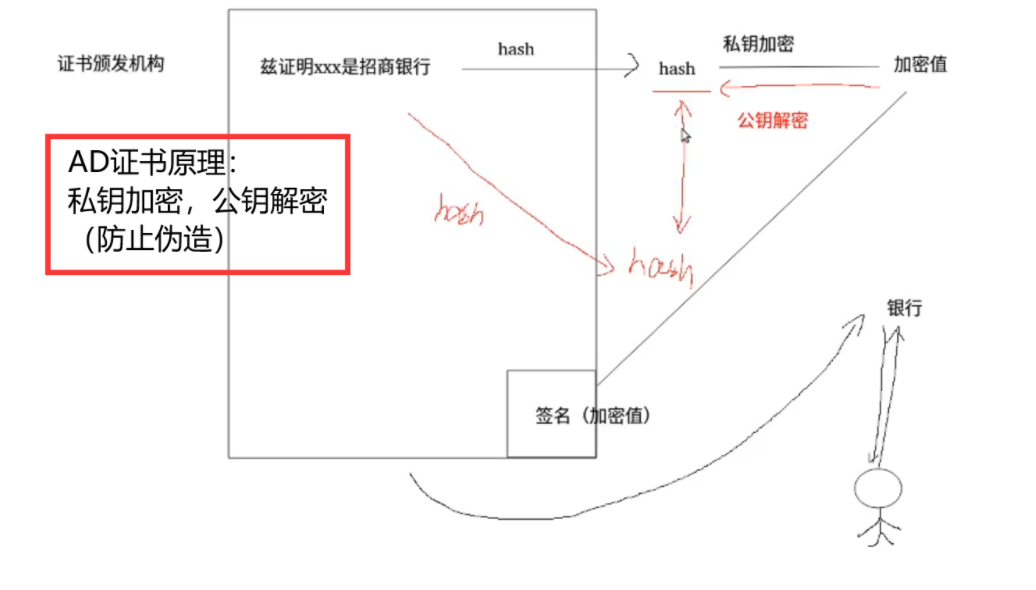
2、PKI
PKI: Token验证在客户端即可完成。
原理:非对称算法。公钥、私钥。
公钥加密,需要私钥解密(加密传输)。
私钥加密,需要公钥解密(CA证书)。
| 我 | 银行网站 | 证书颁发机构 |
|---|---|---|
| api | client(客户端) | keystone |
pki token类似于CA证书。
RabbitMQ-消息队列
注意MQ不是openstack的组件
服务内组件之间的消息全部通过MQ来进行转发,包括控制、查询、监控指标等。
跨服务就用http协议了
MQ优点:解耦服务内各子组件之间的专用连接。
部罢方式:多活部罢
cinder-持久化的块存储服务
cinder架构:
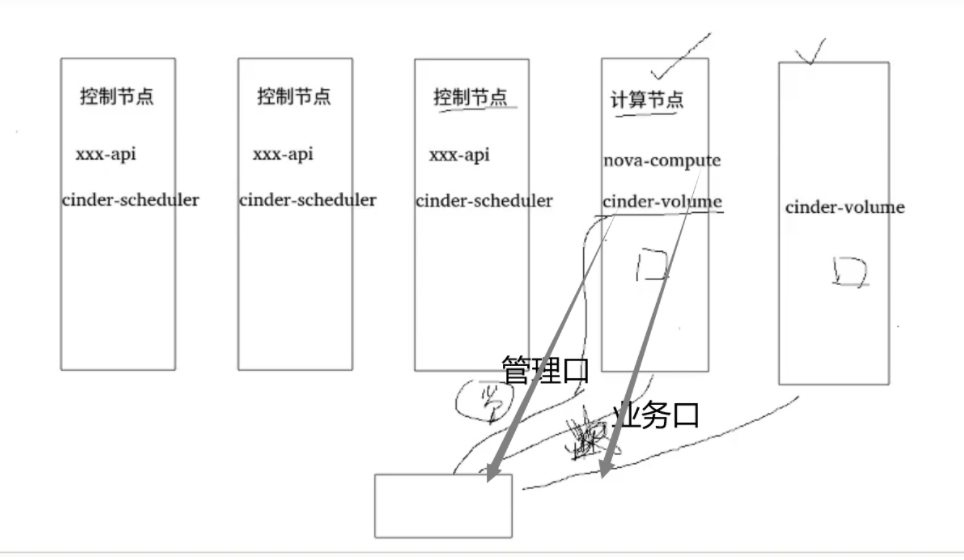
1、cinder-api:对外提供rest api入口;找keystone认证鉴权;记录DB;调用后端组件完成相应请求——》控制节点、多活部署
2、cinder-scheduler:筛选主机。——》控制节点、多活部署
filter:权重:已使用存储空间最少胜出;未使用存储空间最多胜出
3、cinder-volume:通过不同的驱动,对接不同的后端存储。——》计算节点、多活部署
4、cinder- backup:备份功能
Glance-镜像服务管理
华为里面GLance叫这个个名字——manila文件存储服务
manila-api
manila-scheduler
manila-share与cinder-volume类似,对接后端存储。
提供文件共享服务:CIFS、NFS
glance:镜像管理服务
glance-api:rest api接口,keystone认证鉴权,DB操作,调用其他组件,上传下载镜像。
glance-registy:上传镜像时查询数据库,下载镜像时记录数据库。
两个流程:
上传∶请求API,API调用registry,记录存储位置,返回结果,通过api上传镜像到后端存储中
下载:请求API,API调用registry,查询存储位置,返回结果,通过api到后端存储中下载镜像
neutron-网络服务
(软件定义服务)
Management Network
提供Openstack组件间的内部通信。该网络内的IP地址只有数据中心内部可达。
Data Network
提供云内部VM间数据通信。该网络内的IP地址取决于使用的网络插件程序。
External Network
提供VM与外部Internet间的通信。Internet上的任何人都可以访问该网络内的IP地
API Network
为租户提供包括Networking API在内的所有Openstack API。该网络内的IP地址应该被允许Internet上的任何人可达。该网络基本上与External Network一样,我们甚至可以创建一个external-network子网作为该网络。
架构
一、neutron-server(核心,实现绝大部分控制功能)
二、neutron-xxx-agent (代理,通过相应驱动驱动不同的软件、硬件实现相应的网络服务)
ceilometer-计量、监控服务
特别注意,没有计费功能
- ceilometer-api
- ceilometer-collect 收集信息,记录DB
- ceilometer-agent
1、ceilometer-agent-compute
收集VM的信息(主动调用libvirt API)
2、ceilometer-agent-hardware
收集物理服务器的信息(主动调用host os命令)
3、ceilometer-agent-central
收集openstack组件的信息(主动调用其他组件API)
4、ceilometer-agent-notification
收集MQ的信息(被动监听收集MQ的信息)