🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:深度学习语义分割篇——FCN原理详解篇
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
深度学习语义分割篇——FCN源码解析篇
写在前面
本篇文章参考霹雳吧啦Wz在B站上的视频进行讲解,点击☞☞☞下载FCN源码。阅读本文之前建议先阅读上篇对FCN原理讲解的文章。
本文将从数据集读取、模型训练、模型推理和模型搭建几部分为大家讲解,每次做代码的讲解我都要说一句话,就是不管是看视频还是看文章只是对你了解代码起辅助的作用,你应花更多的时间自己调试,这样你会对整个代码的流程无比熟悉!!!🥝🥝🥝
废话也不多说了,让我们一起来看看FCN的源码吧。🥂🥂🥂
数据集读取——my_dataset.py
在读取数据集部分,我们定义了一个VOCSegmentation类,首先我们需要获取输入(image)和标签(target)的路径,相关代码如下:
class VOCSegmentation(data.Dataset):def __init__(self, voc_root, year="2012", transforms=None, txt_name: str = "train.txt"):super(VOCSegmentation, self).__init__()assert year in ["2007", "2012"], "year must be in ['2007', '2012']"root = os.path.join(voc_root, "VOCdevkit", f"VOC{year}")assert os.path.exists(root), "path '{}' does not exist.".format(root)image_dir = os.path.join(root, 'JPEGImages')mask_dir = os.path.join(root, 'SegmentationClass')txt_path = os.path.join(root, "ImageSets", "Segmentation", txt_name)assert os.path.exists(txt_path), "file '{}' does not exist.".format(txt_path)with open(os.path.join(txt_path), "r") as f:file_names = [x.strip() for x in f.readlines() if len(x.strip()) > 0]self.images = [os.path.join(image_dir, x + ".jpg") for x in file_names]self.masks = [os.path.join(mask_dir, x + ".png") for x in file_names]
这部分非常简单啦,voc_root我们应该传入VOCdevkit所在的文件夹,以我的数据路径为例,我应指定voc_root="D:\数据集\VOC\VOCtrainval_11-May-2012"
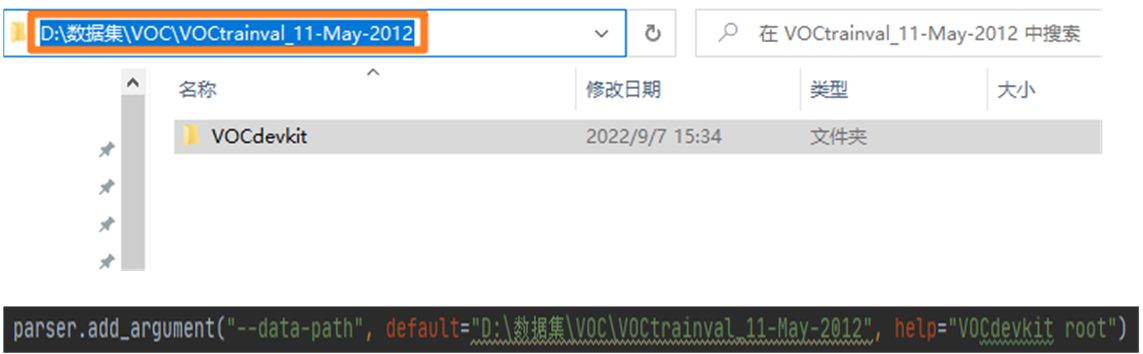
最终self.image和self.masks里存储的就是我们输入和标签的路径了。接着我们对输入图片和标签进行transformer预处理,本代码主要进行了随机缩放、水平翻转、随机裁剪、toTensor和Normalize【训练集采用了这些,验证集仅使用了随机缩放、toTensor和Normalize】,相关代码如下:【这部分代码其实是在train.py文件中的,这里放在了此部分讲解】
#训练集所用预处理方法
class SegmentationPresetTrain:def __init__(self, base_size, crop_size, hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):min_size = int(0.5 * base_size)max_size = int(2.0 * base_size)trans = [T.RandomResize(min_size, max_size)]if hflip_prob > 0:trans.append(T.RandomHorizontalFlip(hflip_prob))trans.extend([T.RandomCrop(crop_size),T.ToTensor(),T.Normalize(mean=mean, std=std),])self.transforms = T.Compose(trans)def __call__(self, img, target):return self.transforms(img, target)# 验证集所用预处理方法
class SegmentationPresetEval:def __init__(self, base_size, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):self.transforms = T.Compose([T.RandomResize(base_size, base_size),T.ToTensor(),T.Normalize(mean=mean, std=std),])def __call__(self, img, target):return self.transforms(img, target)
上述代码中crop_size设置为480,即训练图片都会裁剪到480*480大小,而验证时没有使用随机裁剪方法,因此验证集的图片尺寸是不一致的。
在数据集读取类中,还定义了collate_fn方法,其实在训练过程中加载数据时用到的,定义了我们数据是如何打包的,代码如下:
def collate_fn(batch):images, targets = list(zip(*batch))batched_imgs = cat_list(images, fill_value=0)batched_targets = cat_list(targets, fill_value=255)return batched_imgs, batched_targetsdef cat_list(images, fill_value=0):# 计算该batch数据中,channel, h, w的最大值max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))batch_shape = (len(images),) + max_sizebatched_imgs = images[0].new(*batch_shape).fill_(fill_value)for img, pad_img in zip(images, batched_imgs):pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)return batched_imgs
这个方法即是将我们一个batch的数据打包到一块儿,一起输入网络。这里光看代码可能不好理解,打上断点调试调试吧!!!🌿🌿🌿
模型训练——train.py
其实,模型的训练步骤大致都差不多,不熟悉的可以先参考我的这篇博文:使用pytorch自己构建网络模型实战🥫🥫🥫
下面一起来看看FCN的训练过程吧!!!🍚🍚🍚
数据集读取和加载
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> train.txt
train_dataset = VOCSegmentation(args.data_path,year="2012",transforms=get_transform(train=True),txt_name="train.txt")# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> val.txt
val_dataset = VOCSegmentation(args.data_path,year="2012",transforms=get_transform(train=False),txt_name="val.txt")train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,num_workers=num_workers,shuffle=True,pin_memory=True,collate_fn=train_dataset.collate_fn)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=1,num_workers=num_workers,pin_memory=True,collate_fn=val_dataset.collate_fn)
我想这部分大家肯定没什么问题啦,每个网络训练基本都是这样的数据读取和加载步骤,我就不过多介绍了。☘☘☘
创建网络模型
model = create_model(aux=args.aux, num_classes=num_classes)
这里大家现在大家就可以理解为是FCN原理部分所创建的模型,即以VGG为backbone构建的网络。有关网络模型的搭建我会在下文讲述。🥦🥦🥦
设置损失函数、优化器
# 设置优化器
optimizer = torch.optim.SGD(params_to_optimize,lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay) 此代码损失函数的设置是在训练一个epoch数据时定义的,使用的是cross_entropy损失函数,后文会重点解释。🥗🥗🥗
网络训练✨✨✨
for epoch in range(args.start_epoch, args.epochs):mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch,lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
上面定义了一个train_one_epoch方法,我们一起来看看:
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler, print_freq=10, scaler=None):model.train()metric_logger = utils.MetricLogger(delimiter=" ")metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))header = 'Epoch: [{}]'.format(epoch)for image, target in metric_logger.log_every(data_loader, print_freq, header):image, target = image.to(device), target.to(device)with torch.cuda.amp.autocast(enabled=scaler is not None):output = model(image)loss = criterion(output, target)optimizer.zero_grad()if scaler is not None:scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:loss.backward()optimizer.step()lr_scheduler.step()lr = optimizer.param_groups[0]["lr"]metric_logger.update(loss=loss.item(), lr=lr)return metric_logger.meters["loss"].global_avg, lr
这部分是不是很难看懂呢,大家动起手来调试调试吧,其实这部分和其它网络训练过程也基本差不多。我重点讲一下 loss = criterion(output, target),即损失函数的部分,criterion函数的定义如下:
def criterion(inputs, target):losses = {}for name, x in inputs.items():# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)if len(losses) == 1:return losses['out']return losses['out'] + 0.5 * losses['aux']
关于损失函数部分要讲解的内容还是很多的,因此我放在了附录–>损失函数cross_entropy详解中,大家可去查看。🍵🍵🍵
网络测试
confmat = evaluate(model, val_loader, device=device, num_classes=num_classes)
网络测试部分原视频中介绍的很详细,用到了混淆矩阵,我就不带大家进evaluate中一行一行的看了。但这里我来说一下这部分的调试小技巧,因为测试是在网络训练一个epoch后执行的,但我们肯定很难等训练一个epoch后再调试测试部分,因此我们在调试前先注释掉训练部分,这样就可以很快速的跳到测试部分啦,快去试试吧!!!🥤🥤🥤
模型保存
save_file = {"model": model.state_dict(),"optimizer": optimizer.state_dict(),"lr_scheduler": lr_scheduler.state_dict(),"epoch": epoch,"args": args}torch.save(save_file, "save_weights/model_{}.pth".format(epoch))
模型预测——predict.py✨✨✨
这部分有很多和训练部分重复的代码哈,我就不一一的去分析了。重点看一下如何由模型输出的结果得到最终的P模式的图片,相关代码如下:
output = model(img.to(device))
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
mask = Image.fromarray(prediction)
mask.putpalette(pallette)
mask.save("test_result.png")
上述代码中我认为这句prediction = output['out'].argmax(1).squeeze(0)是最重要的,其主要作用是在输出中的chanel维度求最大值对应的类别索引,为方便大家理解,作图如下:
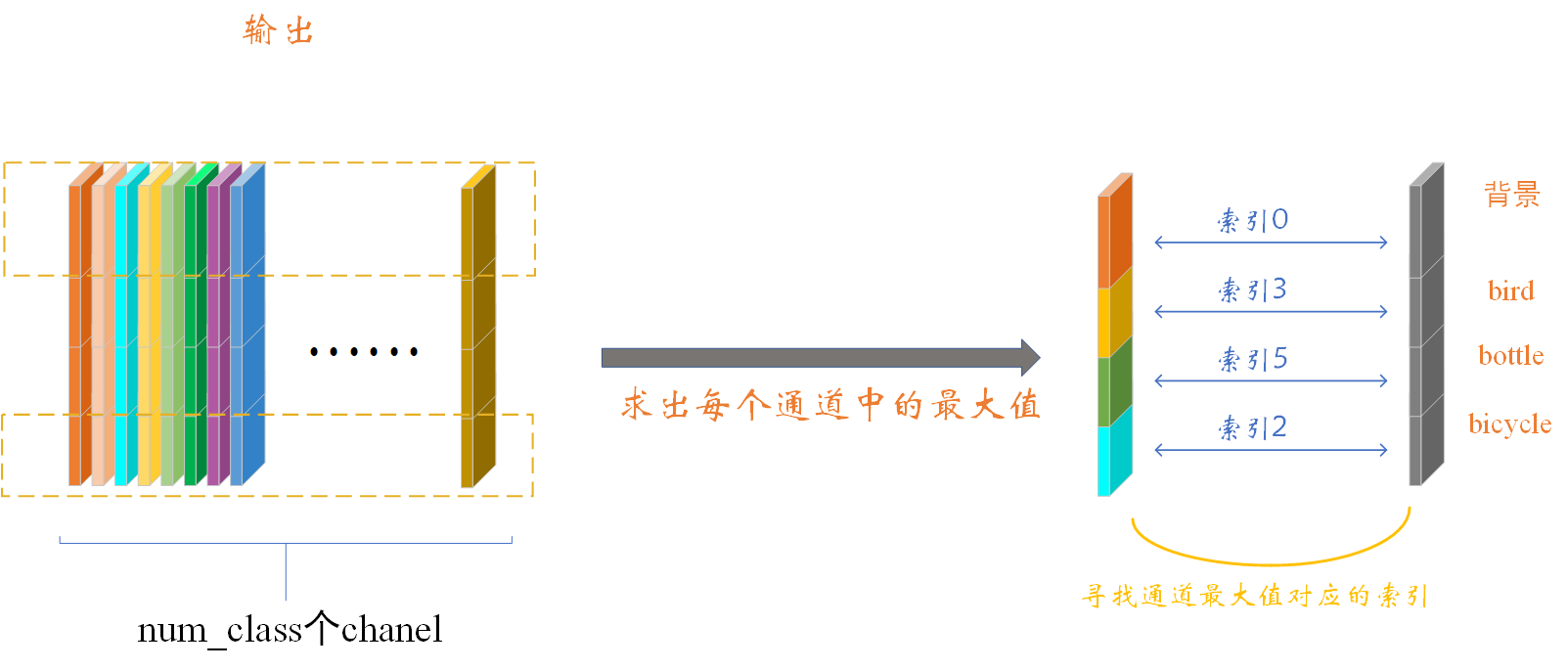
我们来解释一下上图,输出为 1 × c × h × w 1×c×h×w 1×c×h×w,因为这是预测,故batch=1,这里使用的是VOC数据,故这里的c=num_class=21。【包含一个背景类】首先我们会取输出中每个像素在21个通道中的最大值,如第一个像素在21个通道的最大值在通道0上取得,即上图橙色的通道。这个通道对应的索引是0,在VOC中是背景类,故这个像素所属类别为背景。其它像素同理。
我们可以来看看模型预测的结果,如下图所示:

是不是发现这只可爱的小猫咪被分割出来了呢,大家快去试试吧!!!🌼🌼🌼
模型搭建
这部分我之所以放在最后一部分,是因为我觉得这部分是相对最好理解的。我们只要照着我们理论部分一步步的搭建就好。需要注意的是理论部分我们介绍时采用的时VGG做为backbone,这是因为当时论发表在15年,resnet网络也是15出来的,所以论文中没用到,但是很多年过去,resnet的有效性得到实践证明,pytorch官方也采用了resnet作为FCN的backbone,并且使用了空洞卷积。对空洞卷积不了解的请点击☞☞☞查看相关解释。这里放上backbone的整体结构图,大家作为参考,剩下的时间就去调试吧!!!🌹🌹🌹
图片来自霹雳吧啦Wz
参考链接
FCN源码解析(Pytorch)🍁🍁🍁
附录
损失函数cross_entropy详解✨✨✨
在讲解损失函数之前,我有必要在为大家分析一波VOC的标注,在FCN原理详解篇的附录我向大家说明说明了标注是单通道的P模式图片,不清楚的请点击☞☞☞了解详情。
单仅知道标注是单通道的图片还不够,我们先来看看这张标注图片:

这张图片大致可以分为三部分,一部分是蓝框框住的人,一部分是绿框框住的飞机,还有一部分是黄框框住的神秘物体。我先来说说人和飞机部分,你可以发现,它们一个是粉红色(人),一个是大红色(飞机),这是因为在我们调色板中人和飞机索引对应的类别分别为粉红色和大红色,如下图所示:
我们也可以来看看标注图片的背景,它是黑色的,背景类别为0,因此在调色板中0所对应的RGB值为[0,0,0],为黑色,如下图所示:

接着我们来看看这个白色的神秘物体,这是什么呢?我们可以看看此标注图像对应的原图,如下:

通过上图可以看到,这个白色的物体其实也是一个小飞机,但很难分辨,故标注时用白色像素给隐藏起来了,最后白色对应的像素也不会参与损失计算。如果你足够细心的话,你会发现在人和飞机的边缘其实都是存在一圈白色的像素的,这是为了更好的区分不同类别对应的像素。同样,这里的白色也不会参与损失计算。【至于怎么不参与马上就会讲解,不用急】
接下来我们可以用程序来看看标注图像中是否有白色像素,代码如下:
from PIL import Image
import numpy as np
img = Image.open('D:\\数据集\\VOC\\VOCtrainval_11-May-2012\\VOCdevkit\\VOC2012\\SegmentationClass\\2007_000032.png')
img_np = np.array(img) 我们可以看看img_np里的部分数据,如下图所示:
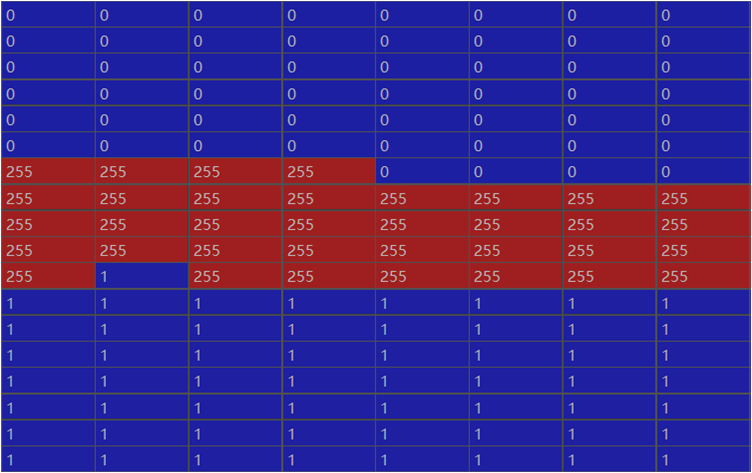
可以看到地下的像素是1,表示飞机(大红色),上面的像素为0,表示背景(黑色),中间的像素为255,这就对应着飞机周围的白色像素。我们可以看一下255对应的RGB值,如下:【这里的255需要大家记住哦,后面计算损失时白色部分不计算正是通过忽略这个值实现的】
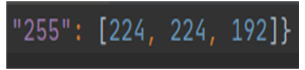
[224,224,192]表示的RGB颜色为白色。
有了上面的先验知识,就可以来介绍cross_entropy函数了。我们直接来看求损失的公式,如下:
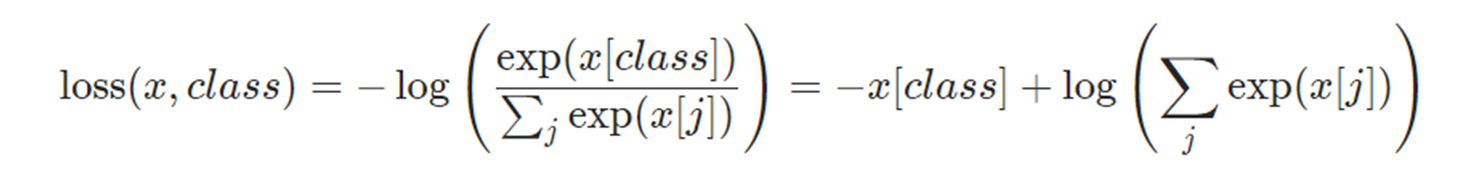
我举个例子来解释一下上面的公式。设输入为[0.1,0.2,0.3],即x=[0.1,0.2,0.3],标签为1,即class=1,则
l o s s ( x , c l a s s ) = − x [ c l a s s ] + log ( ∑ j exp ( x [ j ] ) ) = − 0.2 + l o g ( e x [ 0 ] + e x [ 1 ] + e x [ 2 ] ) = − 0.2 + l o g ( e 0.1 + e 0.2 + e 0.3 ) loss(x,class) = - x\left[ {class} \right] + \log (\sum\limits_j {\exp (x[j])})=-0.2+log(e^{x[0]}+e^{x[1]}+e^{x[2]})=-0.2+log(e^{0.1}+e^{0.2}+e^{0.3}) loss(x,class)=−x[class]+log(j∑exp(x[j]))=−0.2+log(ex[0]+ex[1]+ex[2])=−0.2+log(e0.1+e0.2+e0.3)
通过上文的例子我想你大概知道了损失的计算方法,上文的x是一维的,现在我们来看一下二维的x是怎么计算,首先先定义输入和标签,代码如下:
import torch
import numpy as np
import math
input = torch.tensor([[0.1, 0.2, 0.3],[0.1, 0.2, 0.3],[0.1, 0.2, 0.3]])
target = torch.tensor([0, 1, 2])
可以来看一下input和target的值:
接着我们可以先用函数来计算损失,如下:
loss = torch.nn.functional.cross_entropy(input, target)
计算得到的loss值如下:
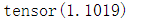
接着我们手动来计算损失,看其是否和直接用函数计算一致,即loss=1.1019。手动计算代码如下:【对于多维数据,需要计算target对应的x的损失,然后求平均】
res0 = -0.1+np.log(math.exp(0.1)+math.exp(0.2)+math.exp(0.3))
res1 = -0.2+np.log(math.exp(0.1)+math.exp(0.2)+math.exp(0.3))
res2 = -0.3+np.log(math.exp(0.1)+math.exp(0.2)+math.exp(0.3))
res = (res0 + res1 + res2)/3
计算得到的结果如下,和利用函数计算时结果一致,仅精度有差别,所以这证明了我们的计算方式是没有错的。
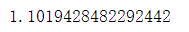
我们上文在介绍VOC标注时说,计算损失是会忽略白色的像素,其就对应着标签中的255。这里我们用这个小例子来说明程序是怎么实现忽略的,其实很简单,只要在函数调用时传入ignore_index并指定对应的值即可。如对本例来说,现我打算忽略target中标签为2的数据,即不让其参与损失计算,我们来看看如何使用cross_entropy函数来实现:
loss = torch.nn.functional.cross_entropy(input, target, ignore_index=2)
上述loss结果如下:
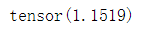
现在我们手动计算一下忽略target=2时的损失结果,如下:
res0 = -0.1+np.log(math.exp(0.1)+math.exp(0.2)+math.exp(0.3))
res1 = -0.2+np.log(math.exp(0.1)+math.exp(0.2)+math.exp(0.3))
res = (res0 + res1)/2
上述代码中target=2没有参与损失计算,其结果如下:

上述实验都证明了我们的计算方式是没有偏差的。🥂🥂🥂
相信你读了上文对cross_entropy解释,已经基本对cross_entropy这个函数了解了。但是大家可能会发现在我们程序中输入cross_entropy函数中的x通常是4维的tensor,即[N,C,H,W],这时候训练损失是怎么计算的呢?我们以x的维度为[1,2,2,2]为例为大家讲解,首先定义输入和target,如下:
import torch
import numpy as np
import math
input = torch.tensor([[[[0.1, 0.2],[0.3, 0.4]], [[0.5, 0.6],[0.7, 0.8]]]]) #shape(1 2 2 2 )
target = torch.tensor([[[0, 1],[0, 1]]])
来看看input和target的值:
接着来看看通过函数计算的loss,代码如下:
loss = torch.nn.functional.cross_entropy(input, target)
此时loss的值为:
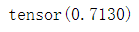
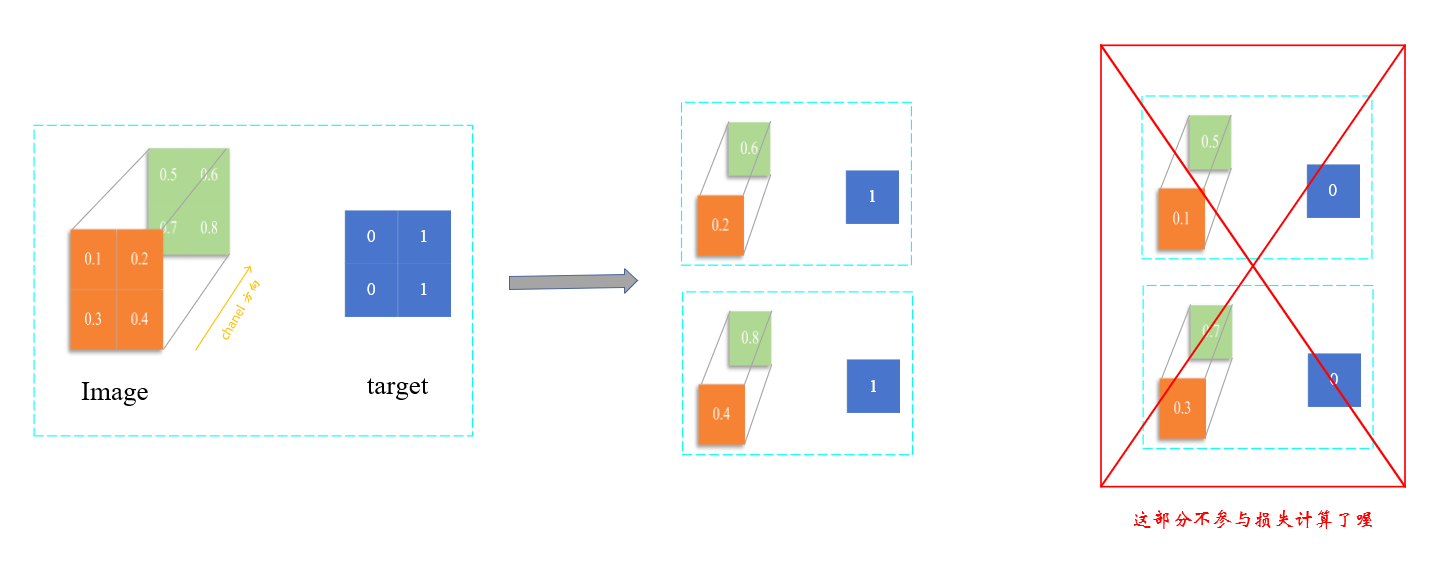
接下来我们就来看看手动计算的步骤,在用代码实现前,我先来解释下大致步骤,如下图所示:

我们会将数据按通道方向展开,然后分别计算cross_entropy,最后求平均,代码如下:
res0 = -0.1+np.log(math.exp(0.1)+math.exp(0.5))
res1 = -0.6+np.log(math.exp(0.2)+math.exp(0.6))
res2 = -0.3+np.log(math.exp(0.3)+math.exp(0.7))
res3 = -0.8+np.log(math.exp(0.4)+math.exp(0.8))
res = (res0 + res1 + res2 + res3)/4
res的结果如下,其和使用函数计算一致。
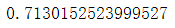
那我们不妨在来看看忽略某个target时loss的结果,以忽略target=0为例:
loss = torch.nn.functional.cross_entropy(input, target, ignore_index=0)
loss的结果如下:
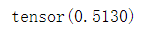
我们来看看手动计算的步骤:
代码如下:
res1 = -0.6+np.log(math.exp(0.2)+math.exp(0.6))
res3 = -0.8+np.log(math.exp(0.4)+math.exp(0.8))
res = (res0 + res3)/2
res的结果如下,同样和使用函数计算是一致的。

到这里,我们在来看FCN中的代码,如下:
losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)
我想大家就很清楚了叭,这里忽略了255像素,不让其参与到损失的计算中。
这一节我觉得是整个FCN最难理解的地方,我已经介绍的非常详细了,大家自己也要花些时间理解理解。🌱🌱🌱
如若文章对你有所帮助,那就🛴🛴🛴