本文介绍一篇来自英国巴斯大学(University of Bath)与微软合作完成的工作,研究者从频率域角度入手探究视觉Transformer结构中的频域注意力和多头注意力在视觉任务中各自扮演的作用。

论文链接:
https://arxiv.org/abs/2304.06446
项目主页:
https://badripatro.github.io/SpectFormers/
代码链接:
https://github.com/badripatro/SpectFormers
近来,AI圈中以ChatGPT、GPT-4为代表的大语言模型(Large Language Models,LLMs)火起来后,全球科研机构、行业大厂纷纷入局大模型军备竞赛。在当下背景,深入探索GPT系列模型背后的基础结构Transformer仍然具有非常重要的意义,目前Transformer架构在自然语言理解任务和视觉感知认知任务上都有非常广泛的应用,此外也有学者在原有架构的基础上加入频域层(spectral layers)来提高Transformer的全局建模能力。
本文介绍一篇来自英国巴斯大学(University of Bath)与微软合作完成的工作,本文从频率域角度入手探究视觉Transformer结构中的频域注意力和多头注意力在视觉任务中各自扮演的作用。通过实验作者发现,在Transformer架构中同时设置频域层和多头注意力层可以有效的提升模型的特征建模能力,因此作者提出了一种新型视觉Transformer模型,称为Spectformer。Spectformer在多项视觉任务中均展示出了优越的性能。相比于其他transformer架构,Spectformer在ImageNet等数据集上的top-1准确率提高了2%。此外,Spectformer在其他视觉下游任务(例如目标检测和实例分割)中都表现出了SOTA效果。因此作者得出一个结论,“Frequency and Attention is what you need in a Vision Transformer”!

一、介绍
原始的Transformer模型是2017年由谷歌大脑Vaswani等人[1]提出的一项自然语言处理开创性工作。在Transformer爆火的当年,其被认为是替代传统序列建模模型LSTM和RNN的最佳选择。Transformer的第二次爆火是源于2020年到2021年间视觉领域Transformer模型(ViT) 的提出。而最近的引爆AI社区的大型语言模型(GPT-3,ChatGPT)以及大型多模态模型(GPT-4)则可以被认为是Transformer模型发展的高潮。目前Transformer原始论文在谷歌学术的引用量已经达到了七万三千多次。

非常有趣的一点是,研究者们在将Transformer中的概念扩展到其他领域时,并没有太多的修改其原本的结构。通常来说将一个模型迁移到一个陌生的领域时,可能需要针对新领域来调整模型的结构,而Transformer却天然表现出了一种惊人的通用能力。例如自然语言领域常用的两大模型Bert和GPT模型,分别照搬了Transformer中的Encoder和Decoder部分。但是相对于语言数据,图像数据的分布存在更强的无边界性和不确定性,因此想要使用Transformer来处理图像,需要先将输入图像进行基于图像块的token化处理。随后研究者们还对Transformer的内部机理进行探索,例如后续提出的GFNet[2]就表明,傅里叶变换就可以替换Transformer中原有的多头注意力层,并且可以获得更好的性能,他们认为在Transformer中加入频域特征建模,可以更有效的捕捉图像中的细粒度特征。因此本文做出了一个大胆的假设:“在图像领域中,频域层和多头自注意力同时发挥着重要的作用”。

受频域特征建模的启发,本文作者提出了一种新型的SpectFormer模型,该模型首先使用傅里叶变换操作实现了一个频域层用来在网络的浅层位置提取图像特征,随后在网络的深层进一步使用多头自注意力模块来进行特征建模。SpectFormer与其他分层Transformer(例如DeiT[3]和GFNet[2])的对比如上图所示。其中DeiT完全使用自注意力层来构建网络,而GFNet则完全使用频域层来进行建模。SpectFormer同时整合了频域建模层和多头自注意力层的结构,先将图像tokens转换到傅里叶域,然后优化网络参数来获取高质量特征,最后再通过逆傅里叶变化来获取最终的特征信号。
二、本文方法
2.1 频域层和自注意力层混合建模的合理性验证
为了验证SpectFormer架构设计的合理性,作者首先对这种混合建模形式进行实验验证。首先对频域层和多头自注意层的不同组合进行性能对比,这些组合包括:(1)全注意力层,(2)全频域层,(3)频域层在前、注意力层在后,即本文提出的SpectFormer架构,(4)注意力层在前,频域层在后,作者将这种设置称为反向SpectFormer。这四种组合设置的性能对比如下图所示。可以看出,先使用频域层对图像提取浅层特征,然后再使用多头自注意力层进行深层次的特征建模效果更好。因此可以证明本文提出的SpectFormer的架构合理性。

2.2 SpectFormer架构
SpectFormer架构的整体框架如下图所示,在下图左侧作者首先放置了DeiT的分层结构图。可以看出,SpectFormer整体也呈现出分层Transformer的设计,相比于DeiT,SpectFormer划分了四个特征提取stage,每个stage中由多个SpectFormer块堆叠而成,每个SpectFormer块又由若干频域块和注意力块构成。除此之外,SpectFormer与其他Transformer结构类似,包括一个线性图像块嵌入层,后跟一个位置编码嵌入层。并且在注意力建模之后设置一个分类头(分类数量为1000的MLP层)。如果我们仔细观察的话可以发现,在四个特征提取stage中,频域层只出现在了较为浅层的stage1和stage2中,而在stage3和stage4中则完全通过自注意力层完成操作。

2.3 频域层设计
频域层的设计目标是从复数角度审视输入图像,来捕获图像的不同频率分量来提取图像中的局部频域特征。这一操作可以通过一个频域门控网络来实现,该网络由一个快速傅里叶变换层(FFT)、一个加权门控层和一个逆傅里叶层(IFFT)构成。首先通过FFT层来将图像的物理空间转到频域空间中,然后使用具有可学习权重参数的门控层来确定每个频率分量的权重,以便适当地捕获图像的线条和边缘,门控层可以使用网络的反向传播进行参数更新。随后IFFT层再将频域空间转回物理空间中。此外作者提到,在频域层中除了使用FFT和IFFT操作,还可以使用小波变换和逆小波变换来实现。
2.4 自注意力层设计
SpectFormer的自注意力层是一个标准的注意力层实现,由层归一化层、多头自注意力层(multiheaded self-attention,MHSA)和MLP层堆叠构成。SpectFormer中的MHSA使用与DeiT相同的结构,即在自注意力建模阶段先使用MHSA进行token融合,然后再通过MLP层进行通道融合。
2.5 整合后的SpectFormer层
为了实现频域层和自注意力层之间的性能平衡,作者引入了一个 α 参数来控制SpectFormer层中频域层和自注意力层之间的比例。如果α=0,代表SpectFormer层完全使用自注意力层实现,此时的SpectFormer等价于DeiT。当 α=12 时,SpectFormer等价于GFNet,即完全使用频域层构成。需要注意的是,所有的注意力层都存在局部特征捕捉不精确的缺点,而所有的频域层都存在无法准确处理全局图像属性或语义特征的缺点。因此,SpectFormer的这种混合设计具有灵活性,可以动态的改变频域层和注意力层的数量,从而有助于准确捕捉全局属性和局部特征。
三、实验
本文的实验在多个计算机视觉benchmark上进行,包括ImageNet图像分类、COCO目标检测和实例分割。为了能够在多个角度对SpectFormer提取到的特征进行评估,作者设置了以下四个实验:
-
在ImageNet-1K数据集上从头开始训练SpectFormer来完成图像分类任务。
-
使用 SpectFormer(在ImageNet-1K上预训练后)模型在CIFAR-10、CIFAR-100、Oxford-IIIT flower、Standford Car数据集上进行图像识别任务的迁移学习。
-
微调SpectFormer(在ImageNet-1K上预训练后)用于下游任务,例如在COCO上进行目标检测和实例分割。
-
对SpectFormer优化后的权重参数进行可视化分析。
3.1 ImageNet-1K上的图像分类任务
在ImageNet-1K图像分类任务上,作者对比了众多经典的视觉backbone网络,包括卷积网络ResNet、SE-ResNet和视觉ViT模型TNT、CaiT、CrossViT、Swin-ViT等。具体的实验结果如下表所示。

从表中我们可以看出,SpectFormer的Top-1准确率达到了85.1%,超过了之前最好方法Wave-ViT-B,其中Wave-ViT-B内部使用可逆下采样和小波变换进行自注意力学习。
3.2 迁移学习对比
为了评估SpectFormer所提取到的视觉特征的鲁棒性,作者在多个迁移学习benchmark上进行了实验,包括CIFAR-10、CIFAR-100、Stanford Cars 和 Flowers-102,在进行迁移之前,SpectFormer先经过了ImageNet-1K的预训练。下表展示了SpectFormer在这些数据集上的迁移学习性能对比。
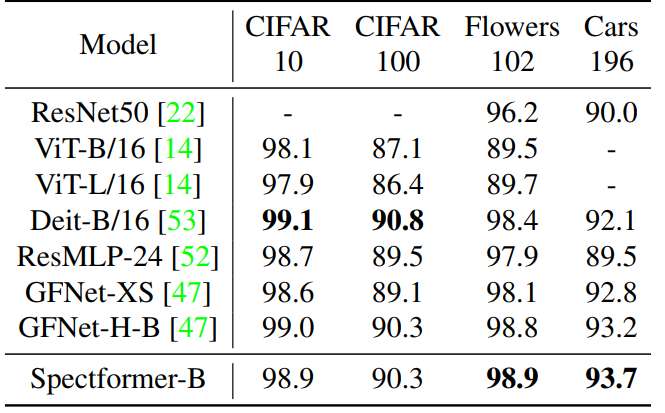
可以看出,SpectFormer在下游数据集上表现良好,明显优于ResMLP模型,并且取得了与频域网络GFNet相媲美的迁移性能。
3.3 目标检测和实例分割
除了简单的分类迁移任务之外,作者还在目标检测和实例分割下游任务上评估了SpectFormer的特征迁移能力。同样在经过ImageNet预训练之后,作者在COCO数据集上对SpectFormer的目标定位能力进行了评估,实验结果如下表所示。

作者选取了目标检测经典模型RetinaNet和Mask R-CNN,以及其他基于Transformer的目标检测网络例如RegionViT和PVT作为对比方法,可以看出,SpectFormer在目标定位AP指标方面明显优于其他方法。
3.4 SpectFormer权重可视化分析
为了进一步分析SpectFormer内部频域层和自注意力层的作用机理,作者对网络内部的滤波器表征进行了可视化分析,通过对学习到的滤波器参数进行可视化,可以帮助我们更好的理解Transformer到底是如何处理输入图像的。在这一部分的实验中,作者重点对比了SpectFormer与GFNet的前四层滤波器参数,如下图所示。

上图展示了SpectFormer和GFNet的每一层的初始24个滤波器,可以观察到,SpectFormer比GFNet更清晰地捕获了局部滤波特征,例如图像的线条和边缘。这表明SpectFormer能够更好地捕获局部图像细节,因此可能更适合对高分辨率图像进行处理。
四、总结
本文对传统Transformer的核心架构进行了分析,并且分别探索了频域和多头自注意力层的作用效果。之前的Transformer网络要么只使用全注意力层,要么只使用频域层,在图像特征提取方面存在各自的局限性。本文提出了一种新型的混合Transformer架构,即将这两个方面结合起来,提出了Spectformer模型。Spectformer显示出比先前模型更加稳定的性能。除了在传统的视觉任务上可以获得SOTA性能之外(在ImageNet-1K数据集上实现了85.7%的Top-1识别准确率),作者还认为,将Spectformer应用到一些频域信息更加丰富的领域上(例如遥感和医学图像数据),可能会激发出混合频域层和注意力层更大的潜力。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Go ez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[2] Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for image classification. Advances in Neural Information Processing Systems, 34:980–993, 2021.
[3] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve J ´ egou. Training ´data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021
作者:seven_
Illustration by IconScout Store from IconSco
点击阅读原文