目录
- 二、唯一性
- 语法
- 3.1命名规则
- 3.2表达式
- 3.3命名规则和作用域
- 3.4参数
- 3.5操作符
- 3.6模式(Pattern)
- 3.6.1,节点模式
- 3.6.2,关系模式
- 3.6.3,路径模式
- 3.7投射和过滤
- 3.7.1,Return子句
- 3.7.2,with 子句
- 3.7.3,unwind子句
- 3.7.4,Where子句
- 3.7.5,排序
- 3.7.6,SKIP和LIMIT
- 三、删除数据库
- 四、neo4j导入文件
- 4.1 CSV文件
#一、 背景
Neo4j是高新能的NoSQL图数据库,是目前使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,
但唯一的不足就是不支持准分布式,相反,OrientDB和JanusGraph支持分布式,通常来讲对于10亿节点以下规模的图谱来说Neo4j已经足够了。
Neo4j呈现形式:Neo4j中不存在表的概念,只有两类:节点(Node)和关系(Relation),可以理解为图里边的点和边。结点一般用小括号( ),关系用中括号 []。neo4j中隐含路径的概念,使用节点和关联表示的,如:(a)->[relation]->(b),表示一条节点a通过关系relation关联到节点b的路径。关系:neo4j中是单向关系,严格的来说不具备双向或者无向的关系。但是merge (a)-[r]-(b)这样的语句创建的关系可以理解为是双向的,neo4j中比较尴尬的一点是这样可以理解为无向关系的关系,在web呈现时是带着单向箭头的。属性:节点和关系都可以具备属性。标签:代表节点的类型,一个节点可以有0个、1个或者多个标签。类型:代表关系的类型,一条关系可以有0个或者1个,一条边不能有多个类型
二、唯一性
在模式匹配时,neo4j确保不会在单个模式中多次找到相同图形关系的匹配。
例如,在寻找a的朋友的朋友时,不会找到a自身。
create (a:Person{name:'A'}),(b:Person{name:'B'}),(c:Person{name:'C'}),(a)-[:FRIEND]->(b),(b)-[:FRIEND]->(c)
寻找A朋友的朋友
Match(p:Person{name:'A'})-[r1:FRIEND]-()-[r2:FRIEND]-(friend_of_a_friend) return friend_of_a_friend.name AS fof_name
返回结果是C
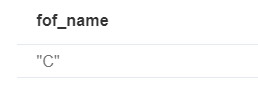
因为r1和r2在同一个模式中,又是不同的变量名,所以不会返回同一条关系。检验 :在两个字句中用不同的变量名就不具有上述效果
match (p:Person{name:'A'})-[r1:FRIEND]-(friend) match (friend)-[r2:FRIEND]-(friend_of_a_friend) return friend_of_a_friend.name AS fof_name
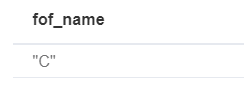
但是只要在同一个模式中,即使拆分了多个子模块也不会匹配到同一关系,如下图:
match (p:Person{name:'A'})-[r1:FRIEND]->(friend),(friend)-[r2:FRIEND]->(friend_of_a_friend) return friend_of_a_friend.name AS fof_name
语法
Cypher是一种非常简洁的图查询语言,可以在shell与浏览器端直接执行。其基本语法包含以下四个部分:
Ø START:在图中的开始点,通过元素的ID或所以查找获得。
Ø MATCH:图形的匹配模式,束缚于开始点。
Ø WHERE:过滤条件。
Ø RETURN:返回所需要的。
注意:在新版本neo4j中 start 可以省略
3.1命名规则
必须以字母开头,不能以数字开头。
结点标签:驼峰式命名:theMatrix;,关系类型:全大写命名:FRIEND。
3.2表达式
Cypher支持的类型系统分为三类:属性类型,复合类型和结构类型。
1,属性类型
属性类型:Integer、Float、String和Boolean
Boolean类型:true, false, TRUE, FALSE
String类型:‘Hello’, “World”
2,复合类型
复合类型:List和Map,List是有序的值的集合,Map是无序的Key/Value对的集合,通常用于存储节点和关系的属性。
List类型:[‘a’, ‘b’], [1, 2, 3], [‘a’, 2, n.property, $param], [ ]
Map类型:n是节点,prop是节点的属性键,引用属性的值的格式:n.prop,
3,结构类型
结构类型:Node类型、关系类型、Path类型:
其中Node类型表示一个节点,由Id、Label和Map构成;
关系类型表示一个关系,由Id、Type、Map和 关系两端的两个节点的Id构成;
Path类型表示路径,是节点和关系的序列。Path模式:(a)–>()<–(b)
4,List类型
由标量类型构成的List,例如,[‘a’, ‘b’], [1, 2, 3]
由函数range函数生成的List对象,例如,range(0,10),从start到end的有序数字,Range函数包含两端。
列表(List comprehension):[x IN range(0,10) WHERE x % 2 = 0 | x^3]
5,Map类型
列表的常量表示:{ key: ‘Value’, listKey: [{ inner: ‘Map1’ }, { inner: ‘Map2’ }]}
Map投影,用于从节点、关系和其他Map对象中投影特定元素或变量的值,
3.2.1 字符串常用的转义序列
\t Tab键 \b 后退键 \n 新起一行 \r 回车符 \f 制表符 \’ 单引号 \’’双引号
\ 反斜杠的转义
3.2.2 CASE表达式
Cypher支持case条件表达式,它的逻辑类似于C语言中的if/else语句。一个CASE语句包含一个或多个WHEN-THEN子句,每个子句都是一个表达式。 case语句也可以包含一个ELSE子句,当之前的条件都不为真时,则执行该ELSE子语句,类似于C语言中的default。
CASE语句有两种语法:其中的一种语法等效于if-else语句,而另一种则类似于SWITCH语句。对于等效于IF-ELSE语句来说,系统会计算每个WHEN子句中的布尔条件,并执行条件为真的第一个语句块,即使有多个满足条件的WHEN子句,也只会执行第一个。仅当所有WHEN子句条件均为假时,才会执行末尾的ELSE子句(如果有)。如果所有WHEN子句的布尔条件都为假,且没有ELSE语句,则返回null。Cypher的case语法和gsql的case语法用法一样。end后面也可以接as语句。
1、第一种写法
MATCH (n)
RETURN
CASE
WHEN n.eyes == 'blue'
THEN 1
WHEN n.age < 40
THEN 2
ELSE 3 END AS result
2、第二种写法
类似于switch用法
return
case 3
when 2 then 2
when 3 then 3
when 4 then 4
else 0
end
返回 3
create (A:Person {name:'Alice', eyes:"brown",age:38}),(B:Person {name:"Bob", eyes:"blue", age:25}),(C:Person {name:"Charlie", eyes:'green',age:53}),(D:Person {name:"Daniel", eyes:'brown'}),(E:Person {name:'Eskil',eyes:"blue",age:41,array:['one','two','three']}),(A)-[:KNOWS]->(B),(A)-[:KNOWS]->(C),(B)-[:KNOWS]->(D),(C)-[:KNOWS]->(D),(B)-[:MARRIED]->(E)
结果图:
MATCH (n:Person) RETURN n.name, CASE n.eyes WHEN 'blue' THEN 1 WHEN 'brown' THEN 2 ELSE 3 END AS result
MATCH (n:Person) RETURN n.name, CASE WHEN n.eyes = 'blue' THEN 1 WHEN n.age < 40 THEN 2 ELSE 3 END AS result
当存在一些结点没有age属性,我们希望返回一个 age_10_years_ago的值,假设不存在age属性,将该值返回-1.我们按照如下方式写查询语句,当age不存在时返回-1,但是事实并不如我们想象的那样。
MATCH (n:Person)
RETURN n.name,
CASE n.age
WHEN n.age IS NULL THEN -1
ELSE n.age - 10 END AS age_10_years_ago

原因 :n.age是一个整型,而n.age IS NULL是一个bool值,所以不会走到WHEN n.age IS NULL THEN -1这个对应的分支。需要换成如下写法:
MATCH (n:Person)
RETURN n.name,
CASE
WHEN n.age IS NULL THEN -1
ELSE n.age - 10 END AS age_10_years_ago

3.3命名规则和作用域
对变量进行命名,变量的命名要遵守一定的规则,并且变量具有特定的作用域。
1,命名规则
名称以英语字符开头,能够包含数字,但是数字不能作为首字符,除了下划线和$,不能包含其他符号,
注意,下划线应用于名称的中间或结尾,例如,my_variable,[Math Processing Error]myParam。
名称是大小写敏感的,:PERSON 和 :Person 是不同的。
2,作用域
节点的Lable、关系类型和属性键是不同的作用域(Scope),在相同的Scope下,名称是不允许重复的;但是,在不同的Scope中,名称是允许重复的,并且表示不同的含义。
CREATE (a:a {a: 'a'})-[r:a]→(b:a {a: 'a'})
3.4参数
Cypher支持带参数的查询,它允许开发者不需要do string building to create a query,同时它能使执行计划的缓存更容易。
参数可以用在WHERE子句的literals和expressions、可以用在START子句或索引查询的索引键值上、节点/关系的ID上。但是参数不能用在属性名上(如:MATCH(n)WHERE n.$ param =‘something’),因为属性是查询结构的一部分,是要编译成执行计划的。
参数名称只能是字母和数字,以及这些参数的任意组合,但不能以数字或货币符号开头。
查看当前的所有参数::params
3.4.1 参数定义
参数仅仅对当前会话有效,网页刷新变量消失。变量为一个K/V的键值对。
:param a:1, b:2或者:param {a: 1, b: 2}以这样的形式来定义参数,注意前面是有冒号的。
MATCH (n:Person)WHERE n.name = $nameRETURN nMATCH (n:Person { name: $name })RETURN n
3.4.2 可以使用参数的各种场景
正则表达式:
:param {"regex":".*VM.*"}match (n:VM) where n.name=~ $regex return n.name
大小写敏感的字符串匹配:
:params { "name" : "Michael"}MATCH (n:Person)WHERE n.name STARTS WITH $nameRETURN n.name
创建多个带属性带标签的节点:
:param {"props" : [ {"awesome" : true,"name" : "Andy","position" : "Developer"}, {"children" : 3,"name" : "Michael","position" : "Developer"} ]}UNWIND $props AS propertiesCREATE (n:Person)SET n = propertiesRETURN n
判断某个变量在或者不在变量列表中:
:param "ids" : [ 0, 1, 2 ]//判断变量在列表中,如何判断变量不在对应的列表中?not in会报错,<>达不到想要的结果
MATCH (n)WHERE id(n) IN $idsRETURN n.name
//判断变量不存在于列表中match(n:VM) where size([l in [id(n)] where l in $ids ])=0 return n
调用函数:
:param "value" : "Michaela"START n=node:people(name = $value)RETURN n
3.5操作符
操作符是对Cypher查询进行算术运算,逻辑运算等。
1,通用操作符
distinct 用于移除重复值, n.property 用于访问属性,[]是变量的列表
CREATE (a:Person { name: 'Anne', eyeColor: 'blue' }),(b:Person { name: 'Bill', eyeColor: 'brown' }),(c:Person { name: 'Carol', eyeColor: 'blue' })
WITH [a, b, c] AS ps
UNWIND ps AS p
RETURN DISTINCT p.eyeColor
2,数学操作符
加减乘除:+,-,*,/
取模:%
取幂:^
3,比较运算符
等于:=
不等于:<>
小于、大于、小于等于、大于等于:<、>、<=、>=
IS NULL和 IS NOT NULL
4,逻辑运算符
与(AND),或(OR),异或(XOR),非(NOT)
WITH [2, 4, 7, 9, 12] AS numberlist
UNWIND numberlist AS number
WITH number
WHERE number = 4 OR (number > 6 AND number < 10)
RETURN number
5,字符串
字符串拼接:+
匹配正则:=~
WITH ['mouse', 'chair', 'door', 'house'] AS wordlist
UNWIND wordlist AS word
WITH word
WHERE word =~ '.*ous.*'
RETURN word
对于字符串,使用 STARTS WITH、ENDS WITH和CONTAINS 过滤字符串:
WITH ['John', 'Mark', 'Jonathan', 'Bill'] AS somenames
UNWIND somenames AS names
WITH names AS candidate
WHERE candidate STARTS WITH 'Jo'
RETURN candidate
6,列表操作
+,列表追加
IN:检查成员
[]:索引,特殊地,[start .. end],从start开始,递增1,但是不包括end
RETURN [1,2,3,4,5]+[6,7] AS myListWITH [2, 3, 4, 5] AS numberlist
UNWIND numberlist AS number
WITH number
WHERE number IN [2, 3, 8]
RETURN numberWITH ['Anne', 'John', 'Bill', 'Diane', 'Eve'] AS names
RETURN names[1..3] AS result
3.6模式(Pattern)
模式和模式匹配是Cypher的核心,使用模式来描述所需数据的形状,该模式使用属性图的结构来描述,通常使用小括号()表示节点,–>表示关系,-[]->表示关系和关系的类型,箭头表示关系的方向。
3.6.1,节点模式
用小括号表示节点模式:(a),a是节点变量的名称,用于引用图中的某一个节点a。
对于匿名的节点,可以使用()来表示,匿名的节点无法引用,通常用来表示路径中的占位节点。
3.6.1.1,标签模式
在节点变量的后面,使用 :Lable 来表示标签,标签是节点的分组,一个节点可以有一个标签,也可以有多个标签,
比如,
(a:User),(a:User:Admin)
3.6.1.2,指定属性
节点和关系都有属性,属性模式可以使用Map结构来表示,属性模式的格式是{ key:value,…},使用大括号表示一个字典,包含一个或多个键/值对:
(a {name: ‘Andres’, sport: ‘Brazilian Ju-Jitsu’})
(a)-[{blocked: false}]->(b)
3.6.2,关系模式
关系模式是由节点和路径来描述的,最简单的关系模式两个节点和一个路径:
(a)–(b)
该模式表示节点a和节点b之间存在关系,不指定关系的方向
3.6.2.1,关系的名称和方向
关系也可以被命名,Cypher使用[r]来表示关系变量:
关系是有方向的,使用箭头指定关系的方向:
(a)-[r]-(b)
关系是有方向的,使用箭头指定关系的方向:
(a)-[r]->(b)
注意:图中关系的方向是在创建关系时指定的,在执行Cypher查询时,如果指定关系的方向,那么沿着关系的方向进行模式匹配。
3.6.2.2,关系类型
就像节点具有标签,可以对节点进行分组,关系也可以分组,Neo4j按照关系的类型对关系进行分组
(a)-[r:REL_TYPE]->(b)
但是不像节点可以有多个标签,关系只能由一个关系类型,但是,关系的类型可以属于一个集合,这使用 | 来分割,表示关系输入集合中的任意一个类型:
(a)-[r:TYPE1|TYPE2]->(b)
3.6.3,路径模式
路径是由节点和关系构成的序列,在路径中节点和关系是交替相连的,不可中断。路径的长度是指关系的数量,固定长度的路径是指:路径中关系的数量是固定不变的,可变长度的路径是:指路径中关系的数量是可变的。关系的数量有两种表示方式:固定长度和变长。
固定长度的关系,使用[* n]来表示
变长的关系,使用[*start..end]来表示,其中 .. 表示关系的长度是可变的,start表示关系数量的最小值,end表示关系数量的最大值。
注:start和end都可以省略,如果省略start,那么关系的长度 <= end;如果省略end,那么关系的长度>=start;如果同时省略start和end,那么关系的长度是任意的。
在变长关系模式中,也可以指定关系的类型:[Type * start … end ],变长关系只能用于MATCH查询语句中,不能用于CREATE和MERGE语句中。
3.6.3.1,固定长度的关系
在关系[]中,使用*2表示关系的长度为2,使用该模式来表示路径,路径两端的节点是a和b,路径中间的节点是匿名的,无法通过变量来引用。
(a)-[*2]->(b)
该模式描述了3个节点和2个关系,路径两端的节点是a和b,中间节点是匿名节点,等价于以下的模式:
(a)–>()–>(b)
3.6.3.2,变长关系
在关系[]中,使用[*start … end]来表示变长关系
(a)-[*3…5]->(b)
(a)-[*3…]->(b)
(a)-[*…5]->(b)
(a)-[*]->(b)
3.6.3.3,路径变量
Cypher允许对Path命名,把Path赋值给变量p,路径模式可以使用p来表示:
p = (a)-[*3…5]->(b)
3.6.3.4,举个例子
有如下的有向图数据,按照有向图来计算路径,最长的路径长度是2;按照无向图来计算路径,最长的路径长度是6。

分析以下Cypher查询,在路径模式中,路径是无向的,路径的长度是1或2,关系的类型是KNOWS,节点Filipa和节点remote_friend在同一条路径中,
MATCH (me)-[:KNOWS*1…2]-(remote_friend)
WHERE me.name = ‘Filipa’
RETURN remote_friend.name
3.7投射和过滤
投射子句用于定义如何返回数据集,并可以对返回的表达式设置别名,而过滤子句用于对查询的结果集按照条件进行过滤。
3.7.1,Return子句
使用return子句返回节点,关系和关系。
1,返回节点
MATCH (n { name: ‘B’ }) RETURN n
2,返回关系
MATCH (n { name: ‘A’ })-[r:KNOWS]->© RETURN r
3,返回属性
MATCH (n { name: ‘A’ }) RETURN n.name
4,返回所有元素
MATCH p =(a { name: ‘A’ })-[r]->(b) RETURN *
5,为属性设置别名
MATCH (a { name: ‘A’ }) RETURN a.age AS SomethingTotallyDifferent
6,返回谓词(predicate),文本(literal)或模式(pattern)
MATCH (a { name: ‘A’ }) RETURN a.age > 30, “I’m a literal”,(a)–>()
7,使用distinct关键字返回不重复值
MATCH (a { name: ‘A’ })–>(b) RETURN DISTINCT b
3.7.2,with 子句
一个查询(Query)语句有很多查询子句,每一个查询子句按照特定的顺序执行,每一个子句是查询的一部分(Part)。with子句的作用是把上一个查询的结果进行处理,作为下一个查询的数据源,也就是说,在上一个查询的结果输出到客户端之前,把结果传递到后续的子句中去。
1,对聚合的结果进行过滤
聚合的结果必须通过with子句才能被过滤,例如,with子句保留otherPerson,并新增聚合查询count(*),通过where子句过滤,返回查询结果:Anders。
MATCH (david { name: ‘David’ })–(otherPerson)–>()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name

2,限制返回的结果
MATCH (n { name: ‘Anders’ })–(m) WITH m ORDER BY m.name DESC LIMIT 1
MATCH (m)–(o) RETURN o.name
3.7.3,unwind子句
unwind子句用于把list格式的字符串拆开为行的序列
1,拆开列表
UNWIND [1, 2, 3, NULL ] AS x RETURN x, ‘val’ AS y
2,拆开嵌套列表
WITH [[1, 2],[3, 4], 5] AS nested UNWIND nested AS x UNWIND x AS y
RETURN y
3,Collect函数
collect函数用于把值组装成列表
WITH [1, 1, 2, 2] AS coll UNWIND coll AS x WITH DISTINCT x RETURN
collect(x) AS setOfVals
3.7.4,Where子句
使用Where子句对查询的结果进行过滤
1,按照逻辑表达式来过滤
MATCH (n) WHERE n.name = ‘Peter’ XOR (n.age < 30 AND n.name =
‘Tobias’) OR NOT (n.name = ‘Tobias’ OR n.name = ‘Peter’) RETURN
n.name, n.age
2,按照节点的标签来过滤
MATCH (n) WHERE n:Swedish RETURN n.name, n.age
3,按照节点的属性来过滤
MATCH (n) WHERE n.age < 30 RETURN n.name, n.age
4,按照关系的属性来过滤
MATCH (n)-[k:KNOWS]->(f) WHERE k.since < 2000 RETURN f.name, f.age,
f.email
5,按照动态计算的属性来计算
WITH ‘AGE’ AS propname MATCH (n) WHERE n[toLower(propname)]< 30 RETURN
n.name, n.age
6,是否存在属性
MATCH (n) WHERE exists(n.belt) RETURN n.name, n.belt
7,字符串匹配
对字符串进行匹配:starts with、ends with,contains
MATCH (n)
WHERE n.name STARTS WITH 'Pet'
RETURN n.name, n.ageMATCH (n)
WHERE n.name ENDS WITH 'ter'
RETURN n.name, n.ageMATCH (n)
WHERE n.name CONTAINS 'ete'
RETURN n.name, n.age
8,正则匹配
使用 =~ ‘regexp’ 匹配正则 ,如果正则表达式以(?i)开头,表示整个正则是大小写敏感的。
MATCH (n)
WHERE n.name =~ 'Tob.*'
RETURN n.name, n.ageMATCH (n)
WHERE n.name =~ '(?i)ANDR.*'
RETURN n.name, n.age
9,匹配路径模式
MATCH (tobias { name: ‘Tobias’ }),(others) WHERE others.name IN
[‘Andres’, ‘Peter’] AND (tobias)<–(others) RETURN others.name,
others.age
使用not来排除路径模式:
MATCH (persons),(peter { name: ‘Peter’ }) WHERE NOT
(persons)–>(peter) RETURN persons.name, persons.age
使用属性来匹配路径:
MATCH (n) WHERE (n)-[:KNOWS]-({ name: ‘Tobias’ }) RETURN n.name, n.age
使用关系类型来匹配路径:
MATCH (n)-[r]->() WHERE n.name=‘Andres’ AND type®=~ ‘K.*’ RETURN
type®, r.since
10,列表
使用IN操作符表示匹配列表中的元素
MATCH (a) WHERE a.name IN [‘Peter’, ‘Tobias’] RETURN a.name, a.age
11,缺失值
如果属性值缺失,那么属性值默认值是null,null和任何值比较都是false;可以使用is not null 或 is null来判断是否为null
MATCH (person) WHERE person.name = ‘Peter’ AND person.belt IS NULL
RETURN person.name, person.age, person.belt
3.7.5,排序
使用order by对查询的结果进行排序,默认是升序,使用关键字desc使Cypher按照降序进行排序。
1,按照节点的属性进行升序排序
MATCH (n) RETURN n.name, n.age ORDER BY n.name
2,按照节点的属性值进行降序排序
MATCH (n) RETURN n.name, n.age ORDER BY n.name DESC
3.7.6,SKIP和LIMIT
SKIP是跳过前N行,LIMIT是限制返回的数量
1,跳过前3行
MATCH (n) RETURN n.name ORDER BY n.name SKIP 3
2,跳过前3行,返回第4和5行
MATCH (n) RETURN n.name ORDER BY n.name SKIP 3 LIMIT 2
三、删除数据库
当我们发现数据库中有些问题需要删除数据库时,有两种方法:
第一种,对于数据量比较少的情况:
MATCH (n) DETACH DELETE n
这种方法还是比较简单的,但是不适用于大量的数据。
第二种,对于大量的数据,官方还是比较推荐删库的方法:
Win中:停掉neo4j服务:bin中进入cmd输入neo4j stop找到data文件夹中graph.db直接删除即可。
Linux中执行以下指令,也可以直接删除:
rm -rf graph.db
当然,如果忘记密码,也可以删库。删库之后重新打开neo4j服务器会自动新建数据库。届时可以重新输入新密码。
四、neo4j导入文件
4.1 CSV文件
比如说有这样一个CSV的文件,编码为UTF-8

将它放在neo4j的import文件夹下

我们打开neo4j网页版
输入以下语句:
LOAD CSV WITH HEADERS FROM 'file:///book.csv' AS line MERGE (p:book{bookId:toInteger(line.bookID),bookName:line.bookname,writer:line.writer})
其中每次会读取其中的一行数据。
运行完上述语句后,neo4j中会出现一些结点,他们的类型就是book类型与(p:book)有关

Neo4j导入RDF
参考文章一
参考文章二
本文仅供学习用,作为KG学习过程中笔记。
Keep up and Carry on.