在做目标检测,训练数据集的时候,可以先看前段时间的一篇基础文章:
计算机视觉之目标检测(object detection)《1》![]() https://blog.csdn.net/weixin_41896770/article/details/128062645先熟悉一些基本知识,如:锚框,预测框,类别,偏移量之类的,然后再回到本节,可能会更好点,这里我们使用皮卡丘的数据集来训练目标检测。
https://blog.csdn.net/weixin_41896770/article/details/128062645先熟悉一些基本知识,如:锚框,预测框,类别,偏移量之类的,然后再回到本节,可能会更好点,这里我们使用皮卡丘的数据集来训练目标检测。
训练之前我们先来看下多尺度生成锚框,还是使用上一次的猫狗图片,高宽分别是596像素和605像素。
需要知道什么是特征图:有兴趣的可以查阅:MXNet卷积神经网络对图像边缘的检测
定义:二维卷积层输出的二维数组可以看做输入在空间维度(宽和高)上某一级的表征,这个就是特征图(feature map)。这句话是什么意思呢,就是说卷积运算之后的输出,我们反过来看,其中的一个元素对应着输入中的一块区域是吧,假设多加几层卷积层,输出的数组中的一个元素,对应输入中的区域会变大,也就是说单个元素的感受野变得更加广阔,这样更能捕捉到更大尺寸的特征。(这段需要好好想想,上面的图像边缘检测,可以让你更明白)
代码如下:
import d2lzh as d2l
from mxnet import contrib, gluon, image, nd
import numpy as npd2l.set_figsize()
img = image.imread('dogcat.png').asnumpy() # 高、宽、通道数(596, 605, 3)
h, w = img.shape[0:2]def display_anchors(fmap_w, fmap_h, s):'''根据特征图的宽高与来生成'''fmap = nd.zeros((1, 10, fmap_h, fmap_w)) # 前两维的取值不影响输出结果# MultiBoxPrior生成锚框(输入、大小、宽高比),生成个数:大小个数+宽高比个数-1anchors = contrib.nd.MultiBoxPrior(fmap, sizes=s, ratios=[1, 2, 0.5])bbox_scale = nd.array((w, h, w, h))d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0]*bbox_scale)
# 每个中心点有锚框个数:1+3-1=3,有4行4列,所以总共是3*16=48个锚框
# display_anchors(fmap_w=4,fmap_h=4,s=[0.15])# 将特征图的高度减半,锚框增大
# display_anchors(fmap_w=4,fmap_h=2,s=[0.4])# 将特征图的高宽都减半到1,锚框继续增大
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
d2l.plt.show()
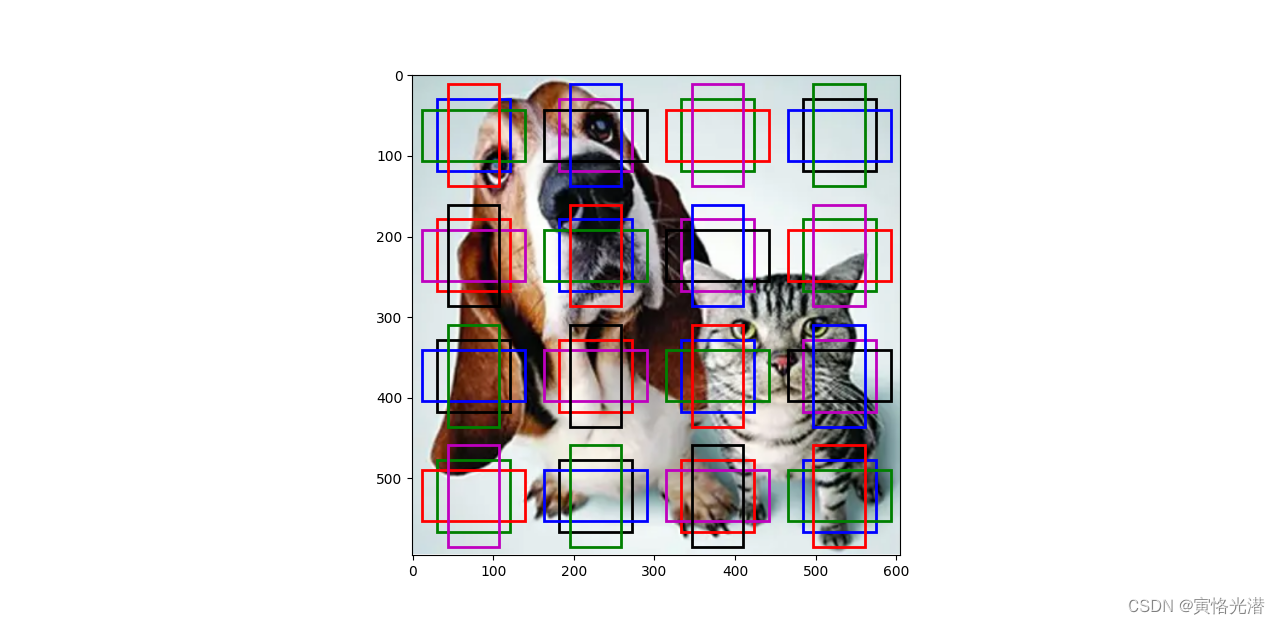

 可以看到,特征图变小,覆盖输入图像的面积就越大。既然我们已在多个尺度上生成了不同大小的锚框,相应的就需要在不同尺度下检测不同大小的目标。
可以看到,特征图变小,覆盖输入图像的面积就越大。既然我们已在多个尺度上生成了不同大小的锚框,相应的就需要在不同尺度下检测不同大小的目标。
皮卡丘数据集检测
这里的数据集使用了MXNet提供的im2rec工具将图像转成了二进制的RecordIO格式,该格式既可以降低数据集在磁盘上的存储开销,又能提高读取效率。其中.rec文件是80多M,虽然不大,但是下载速度很慢,可以手动下载:皮卡丘数据集
import d2lzh as d2l
from mxnet import gluon, image
from mxnet.gluon import utils as gutils
import osdef _download_pikachu(data_dir):'''下载皮卡丘数据集'''root_url = ('https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/pikachu/')dataset = {'train.rec': 'e6bcb6ffba1ac04ff8a9b1115e650af56ee969c8','train.idx': 'dcf7318b2602c06428b9988470c731621716c393','val.rec': 'd6c33f799b4d058e82f2cb5bd9a976f69d72d520'}for k, v in dataset.items():gutils.download(root_url + k, os.path.join(data_dir, k), sha1_hash=v)# d2l包已有
def load_data_pikachu(batch_size, edge_size=256):data_dir = '../data/pikachu'#_download_pikachu(data_dir)#这种方式下载很慢,不想手动下载可以去掉注释train_iter = image.ImageDetIter(path_imgrec=os.path.join(data_dir, 'train.rec'),path_imgidx=os.path.join(data_dir, 'train.idx'),batch_size=batch_size, data_shape=(3, edge_size, edge_size),shuffle=True, rand_crop=1, min_object_covered=0.95, max_attempts=200)val_iter = image.ImageDetIter(path_imgrec=os.path.join(data_dir, 'val.rec'),batch_size=batch_size, data_shape=(3, edge_size, edge_size), shuffle=False)return train_iter, val_iterbatch_size,edge_size=32,256
train_iter,_=load_data_pikachu(batch_size,edge_size)
batch=train_iter.next()
#(批量大小,通道数,高,宽)和(批量大小,边界框个数,(这里长度5,第一个元素是边界框所含目标,-1是填充的非法框,其余4个是对角坐标))
print(batch.data[0].shape,batch.label[0].shape)#(32, 3, 256, 256) (32, 1, 5)#显示图像
imgs=(batch.data[0][0:10].transpose((0,2,3,1)))/255
axes=d2l.show_images(imgs,2,5).flatten()
for ax,label in zip(axes,batch.label[0][0:10]):d2l.show_bboxes(ax,[label[0][1:5]*edge_size],colors=['w'])
d2l.plt.show()