前言
大数据部门现阶段ETL按同步方式分为两种:
- 实时同步:DTS、CloudCanal
- 离线同步:dataworks-DI节点
但CloudCanal在使用中出现了部分问题,归纳总结后主要为以下几点:
- 部分使用场景获取不到binlog点位
- 停止任务,修改数据源ip后,重启任务源端ip不变
- 业务库增加,会导致表数据终止增量同步任务
- 停止任务后,启动任务或进行位点回溯,任务异常无法恢复
基于以上背景,需要调研新的同步工具用于辅助或取代CloudCanal工具的使用
一 DataX 简介及架构原理
1.1 概述
DataX是阿里巴巴使用 Java 和 Python 开发的一个异构数据源离线同步工具;致力于实现包括关系型数据库MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute、DRDS等各种异结构数据源之间稳定高效的数据同步功能。下图为DataX支持的数据源:
| 类型 | 数据源 | Reader(读) | Writer(写) |
| RDBMS 关系型数据库 | MySQL | √ | √ |
| Oracle | √ | √ | |
| OceanBase | √ | √ | |
| SQLServer | √ | √ | |
| PostgreSQL | √ | √ | |
| DRDS | √ | √ | |
| 通用RDBMS | √ | √ | |
| 阿里云数仓数据存储 | ODPS | √ | √ |
| ADS | √ | ||
| OSS | √ | √ | |
| OCS | √ | √ | |
| NoSQL数据存储 | OTS | √ | √ |
| Hbase0.94 | √ | √ | |
| Hbase1.1 | √ | √ | |
| Phoenix4.x | √ | √ | |
| Phoenix5.x | √ | √ | |
| MongoDB | √ | √ | |
| Hive | √ | √ | |
| Cassandra | √ | √ | |
| 无结构化数据存储 | TxtFile | √ | √ |
| FTP | √ | √ | |
| HDFS | √ | √ | |
| Elasticsearch | √ | ||
| 时间序列数据库 | OpenTSDB | √ | |
| TSDB | √ | √ |
1.2 设计理念
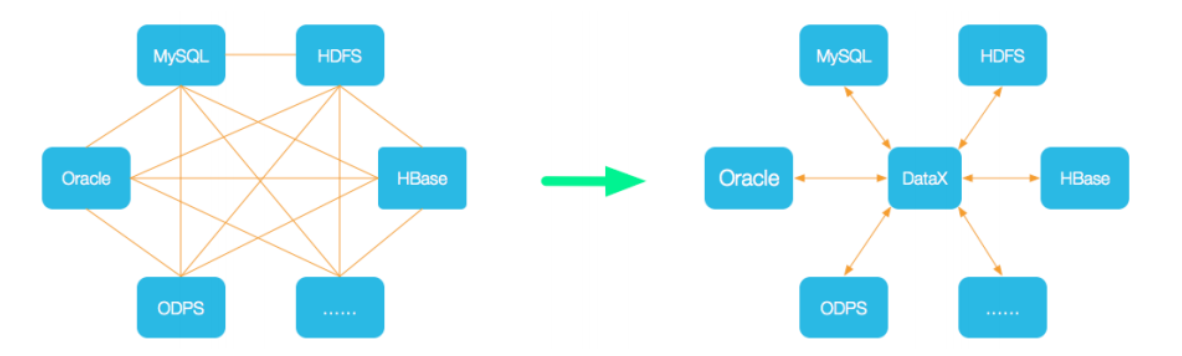
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责链接各种数据源
- 当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,就能跟已有的数据源做到无缝数据同步
1.3 框架设计
Framework 主题框架+ plugin 插件
- 将软件核心功能写入 Framework 主体框架中
- 主体框架为插件预留接口,如果后期需要什么新功能,可以再去开发插件实现,而主体框架无需改动
- 1根据同步核心功能为主题
- 不断的去新增某数据源的支持,对不同数据源的读取或写入功能,以插件的形式开发
- 如果需要新功能只需要开发插件即可,不需要动主体框架
将数据源读取和写入抽象成为 Reader/Writer 插件,纳入到整个同步框架中
1.4 架构功能
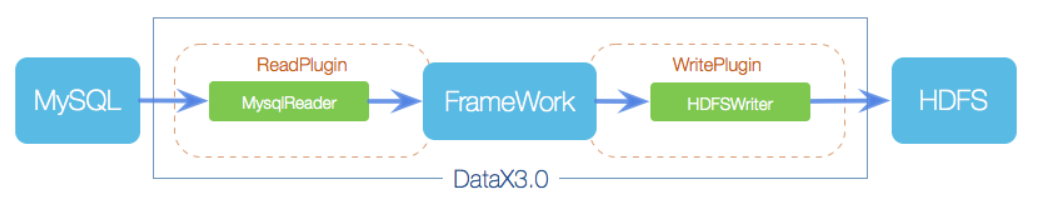
DataX采用Framework + plugin架构构建,将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中
- Reader:Reader做为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题
-
- 缓冲:Reader 和 Writer 存在读写速度不一致的情况,所以中间需要一个组件作为缓冲,缓冲的功能就位于 Framework 中
- 流控:DataX 可以随意根据需求调整数据传输速度,流控功能也位于 Framework 中
- 并发:并发同步或写入数据,也可以控制速度,想要速度快点,设置并发高一点,反之亦然
- 数据转换:Reader 的数据源与 写 Writer 的数据源 数据结构可能不同,数据转换操作也在 Framework 中完成
1.5 DataX的运行流程
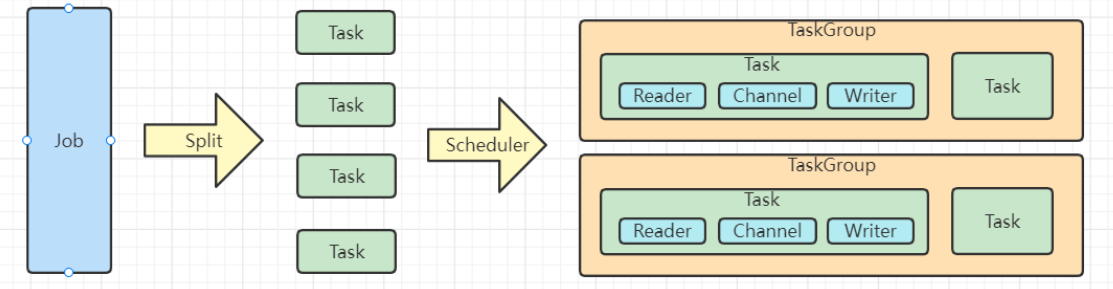
Job
- 单个数据同步的作业,称为一个Job,一个Job启动一个进程
Task
- 根据不同数据源切分策略,一个Job会切分多个Task并行执行
- Task 是DataX作业的最小单元,每个Task负责一个部分数据的同步工作
TaskGroup
- Scheduler 调度模块会对Task 进行分组,每个Task 组称为一个Task Group
- 每个Task Group 负责以一定的并发度运行其所分得的Task ,单个TaskGroup的并发为5
Reader -> Channel -> Writer
每个Task启动后,都会固定启动 Reader -> Channel -> Writer 的线程来完成工作
Channel 类似于 Flume 中的 MemoryChannel 来做数据的缓冲
1.6 DataX调度决策思路
案例
- 用户提交了一个DataX 作业,并且配置了总的并发度为 20
- 目是对一个 有100张分表的 mysql 数据源进行同步
dataX调度决策思路
- 1. DataX Job 根据分库分表切分策略,将同步工作分成 100个Task
- 2. 根据配置的总的并发度20,以及每个Task Group 的并发度 5,
- 3. DataX 计算共需要分配 4的Task Group
- 4. 4个 TaskGroup 平分 100 个Task ,每一个TaskGroup 负责运行 25个Task
注:总的并发度为20,表示整个Job 最多能同时运行 20个Task
二 DataX安装使用
环境准备
- Linux
- JDK(推荐1.8)
- Python(推荐 Python2.6x)
2.1 下载安装
1)DataX安装包下载:下载
2)将安装包上传至服务器任意节点,我这里上传至node1节点 /opt/module目录下
tar -zxvf datax.tar.gz -C /opt/module/
2)运行自检脚本
python /../bin/datax.py /../job/job.json
- 出现下图日志说明环境没有问题
- 如报错执行以下命令,删除隐藏文件
find /datax/plugin/reader/ -type f -name "._*er" | xargs rm -rf find /datax/plugin/writer/ -type f -name "._*er" | xargs rm -rf
2.2从Stream流读取数流打印到控制台
查看官方提供模板
[root@node1 datax]# python bin/datax.py -r streamreader -w streamwriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.mdPlease refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.mdPlease save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"column": [],"sliceRecordCount": ""}},"writer": {"name": "streamwriter","parameter": {"encoding": "","print": true}}}],"setting": {"speed": {"channel": ""}}}
}
根据模板修改配置
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": 10,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 1}}}
}
执行脚本(部分日志)
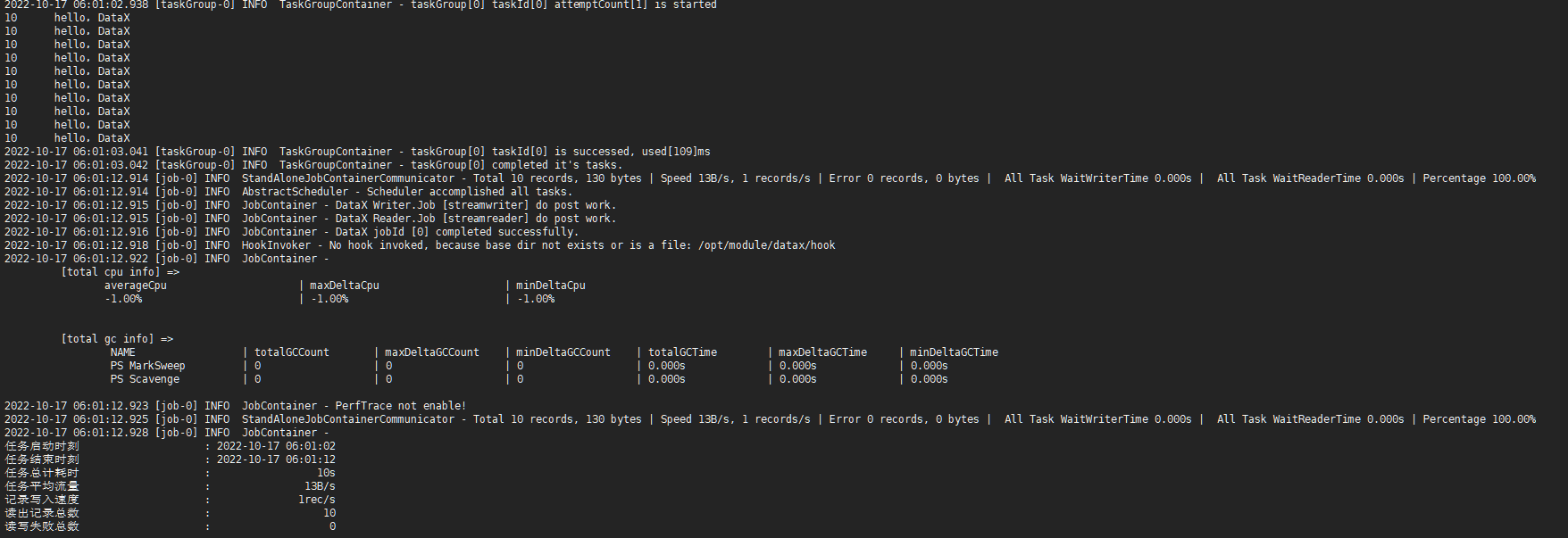
2.3 Mysql两表间的数据迁移
准备
创建数据库和表并加载测试数据
drop database test;
create database test;
use test;
CREATE TABLE `table_a` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '',`name` varchar(32) DEFAULT '' COMMENT '',`time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;INSERT INTO test.table_a (name) VALUES ('a');
INSERT INTO test.table_a (name) VALUES ('b');
INSERT INTO test.table_a (name) VALUES ('c');
INSERT INTO test.table_a (name) VALUES ('d');
INSERT INTO test.table_a (name) VALUES ('e');create database test_bck;
use test_bck;
CREATE TABLE `table_a` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '',`name` varchar(32) DEFAULT '' COMMENT '',`time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
模板
{"job": {"content": [{"reader": {"name": "源端数据库类型","parameter": {"column": [ # 同步字段"字段A","字段B"], "connection": [{"jdbcUrl": ["jdbc:mysql://xxx:3306/数据库"], "table": ["table_name1,table_name2,..."]}], "password": "数据库密码", "username": "数据库账号" }}, "writer": {"name": "目标端数据库类型", "parameter": {"print": true, "column": ["字段A","字段B"], "splitPk": "分片字段,丢给task,所以必须是整形。一般用主键即可(非必须)","connection": [{"jdbcUrl": "jdbc:mysql://xxx:3306/数据库", "table": ["表名"]"querySql":["这里可以写查询数据的sql语句,但是如果这里写了,则不允许再配置table,否则会报错(非必须,table和querySql只能存在一个)"]}], "where":"过滤条件","password": "数据库密码", "username": "数据库账号"}}}], "setting": {"speed": {"channel": "并发数", # "byte":1048576, # 同步速率(byte)/s"record":10000 # 同步速率(记录数)/s byte、record 满足其一条件即可}, "errorLimit": { # 对于脏数据的监控 record:脏数据条数,percentage 脏数据比例,满足其一条件即可"record": 5, "percentage": 0.01}}}
}
配置文件
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","name","time"],"connection": [{"jdbcUrl": ["jdbc:mysql://host_ip:3306/test"],"table": ["table_a"]}],"password": "123456","username": "root"}},"writer": {"name": "mysqlwriter","parameter": {"print": true,"column": ["id","name","time"],"connection": [{"jdbcUrl": "jdbc:mysql://host_ip:3306/test_bck","table": ["table_b"]}],"password": "123456","username": "root"}}}],"setting": {"speed": {"channel": "1","byte":1048576,"record":10000},"errorLimit": {"record": 1,"percentage": 0.01}}}
}
执行脚本(部分日志)
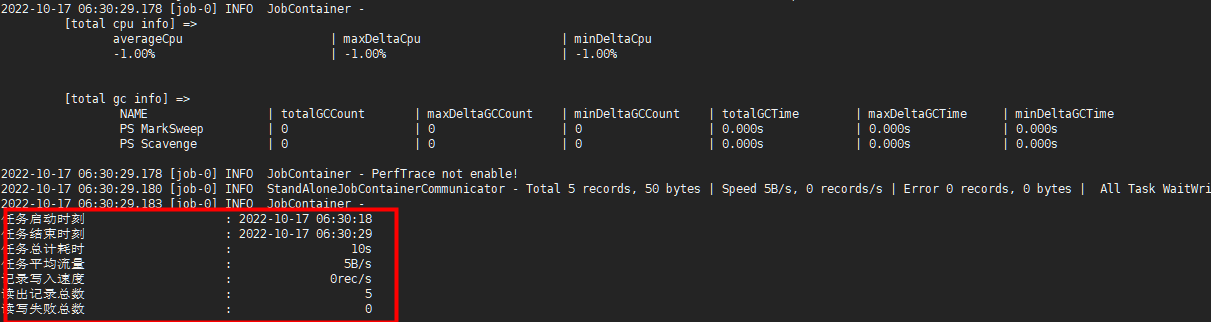
MySQL的参数介绍

三 DataX-Web安装使用
简介
Datax-web基于datax,增加了web界面
Datax-web把Datax基于命令行任务通过java代码串联了起来,并提供了可视化的任务管理
环境准备
- MySQL (推荐5.5+) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库
- JDK(推荐1.8)
- Python(2.x)(支持Python3需要修改替换datax/bin下面的三个python文件)
- datax:data-web执行任务时需要依赖datax中的python脚本
3.1 下载安装
下载
下载链接 提取码: cpsk
安装
- 解压
tar -zxvf datax-web-2.1.2.tar.gz -C /opt/module/
- 安装:执行datax-web-2.1.2/bin/install.sh脚本,安装datax-web
./datax-web-2.1.2/bin/install.sh
- 根据提示进行安装,安装时有两种情况
- 第一种:安装datax-web的服务器已经具备mysql的服务。以下代码中我将中间的日志信息省略掉,只保留的需要用户输入的信息,按照下图一步步进行即可
Do you want to decompress this package: [datax-admin_2.1.2_1.tar.gz]? (Y/N)Y Do you want to decompress this package: [datax-executor_2.1.2_1.tar.gz]? (Y/N)Y Do you want to confiugre and install [datax-admin]? (Y/N)Y Do you want to initalize database with sql: [/opt/apps/datax-web-2.1.2/bin/db/datax_web.sql]? (Y/N)Y Please input the db host(default: 127.0.0.1): localhost # mysql所在服务器的ip地址,默认是127.0.0.1,这里localhost填与不填没有任何意义,只作为举例 Please input the db port(default: 3306): 3306 # mysql端口默认3306,如果是3306可以直接点击enter键,如果不是输入对应端口号 Please input the db username(default: root): root # 默认msyql用户是root,根据实际情况填写 Please input the db password(default: ): 123456 # 输入mysql用户对应的密码 Please input the db name(default: dataxweb)dataxweb # 输入作为datax-web的系统数据库,默认为dataxweb Do you want to confiugre and install [datax-executor]? (Y/N)Y
执行完上面步骤,datax-web的基础安装就完成了,安装过程如下图所示:

- 第二种,安装datax-web的服务器没有msyql服务,这个时候还是正常执行install.sh安装脚本,步骤按照第一种的情况往下执行就可以,不过因为当前服务器没有msyql的服务,所示在安装过程中,不会有下图中的提示

其他步骤同第一种情况相同,在安装完成后,可以通过配置文件自由配置所要连接的Mysql数据库,修改datax-web-2.1.2/modules/datax-admin/conf目录下的bootstrap.properties文件,在此文件中可以自由配置Mysql的连接,命令如下所示:
vi bootstrap.properties # 配置文件中内容如下所示: #Database #DB_HOST= #DB_PORT= #DB_USERNAME= #DB_PASSWORD= #DB_DATABASE= # 根据实际情况进行配置即可
配置完Mysql的数据库连接后,在mysql对应的数据库中执行datax-web-2.1.2/bin/db目录下的datax-web.sql脚本即可,执行完成后,会在该库中生成datax-web所需要的系统数据表。
3.2 配置文件修改
安装完成后,还需要配置datax-web-2.1.2/modules/datax-executor/bin/env.properties 指定PYTHON_PATH的路径,命令如下:
vi env.properties# 在配置文件中编辑内容如下:PYTHON脚本执行位置 PYTHON_PATH=/opt/apps/datax/bin/datax.py
3.3 启动服务
执行datax-web-2.1.2/bin目录下的start-all.sh命令即可,命令如下图所示
./start-all.sh
启动完成后,通过jps命令查看,服务器上是否存在data-web的服务,命令如下:
[root@node1 bin]# jps 4741 DataXExecutorApplication 4478 DataXAdminApplication 4783 Jps # 执行完jps命令后出现以上两个服务证明datax-web已经启动
启动完成后就可以通过页面进行访问了,默认端口号是9527,形式如:127.0.0.1:9527/index.html,进入页面后进行登录默认用户:admin,默认密码:123456,如下图所示:
登录成功后,页面如下所示:
3.4 任务配置
- 点击项目管理,添加项目
- 创建执行器
- 创建数据源
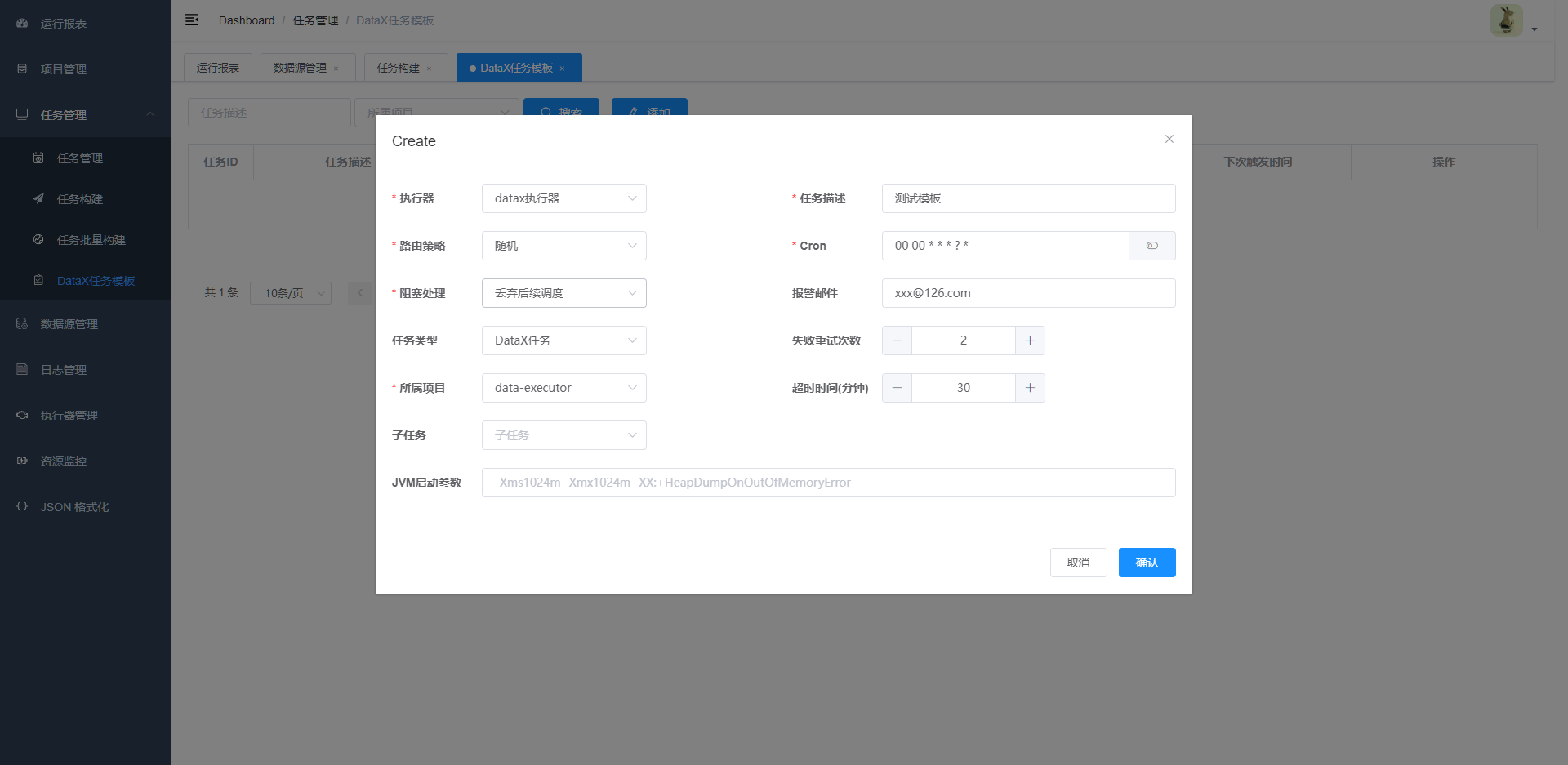
- 创建任务模板(此步骤是主要是为了后边构建任务的时候,为任务指定执行器)
- 创建任务
- 构建reader

- 构建writer
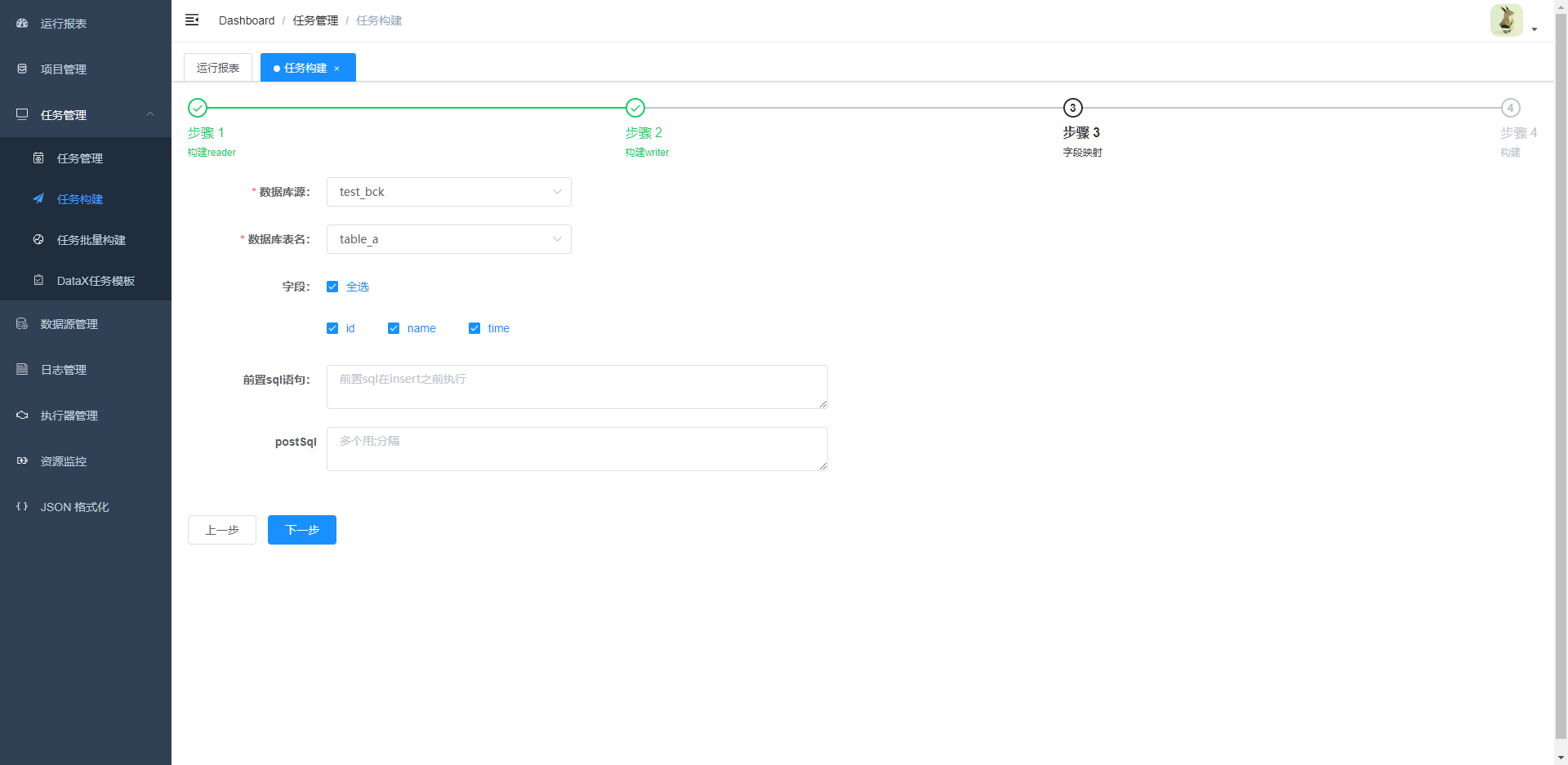
- 字段映射

- 任务构建

到这里任务已经构建完成了
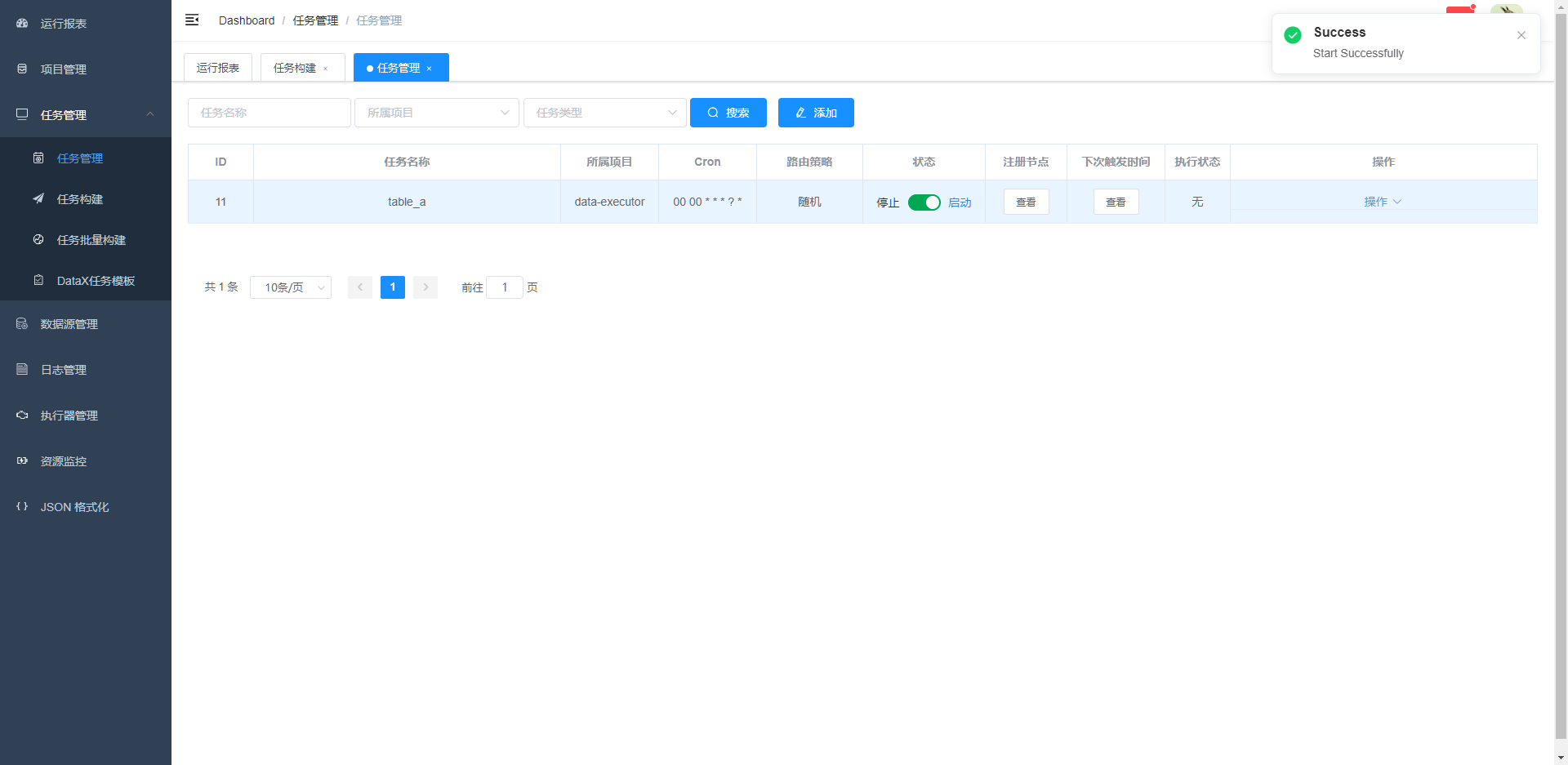
3.5 启动任务
在任务管理界面,可以将配置好的任务启动,以及可以查看 注册节点、触发时间、执行状态等情况
3.6 日志查看

3.7 资源监控
Datax使用总结
优点
- 速度较快,相关网友做过测试:并发数量为5的情况下,3000万的数据量比sqoop快4倍以上
- Datax的同步速率可以根据我们的实际情况进行配置
- 日志比较完善和人性化
- 对于脏数据的处理:在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,提供多种的脏数据处理模式
- 健壮的容错机制:DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性
- 丰富的数据转换功能:数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。
- 界面化配置:基于DataX开发的DataX-web,其拥有可视化界面,省去重复配置的麻烦,任务管理、资源监控一目了然
缺点
DataX非分布式,单节点运行任务,对服务器压力较大
从现有调研结果来看,使用DataX可以满足全量同步数据的需求;
后面会对DataX进行大数据量、多任务、多场景的测试!