一、HTTP缓存有什么作用?
缓存是为了重复使用而被存储的,可以减少浏览器和服务器之间通信的次数、降低网络延迟、加速页面加载、提高用户体验性等。不但能网页打开速度更快,还能减少服务器的压力。
二、 浏览器的缓存策略有哪些?
浏览器每次发起请求时,先在本地缓存中查找结果以及缓存标识,根据缓存标识来判断是否使用本地缓存。如果缓存有效,则使用本地缓存;否则,则向服务器发起请求并携带缓存标识。
根据是否需向服务器发起请求,将缓存过程划分为两个部分:强缓存和协商缓存,强缓存优先于协商缓存。
1、强缓存(Expires、Cache-control)
服务器通知浏览器一个缓存时间,在缓存时间内,下次请求直接使用缓存。不在时间内,执行比较缓存策略。
在没有失效的情况下,浏览器只访问自己的缓存。

2、协商缓存(Last-Modified、ETag)
当缓存过期后,浏览器会咨询服务器是否可以继续使用缓存?服务器会返回可以使用或者不可以使用。
让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,将缓存信息中的Etag和 Last-Modified 通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
3、缓存过程
HTTP缓存都是从第二次请求开始的:
第一次请求资源时:
服务器返回资源,并在response header(响应头)中回传资源的缓存策略;
第二次请求时:
浏览器判断这些请求参数,击中强缓存就直接200;
否则就把请求参数加到request header头中传给服务器,看是否击中协商缓存,击中则返回304,否则服务器会返回新的资源。
三、浏览器缓存控制机制有哪些?
浏览器缓存控制机制有两种:HTML Meta标签 和 HTTP头信息
1、使用HTML Meta 标签
HTML Meta标签是应用在HTML文件中的head头部分。
主要作用就是告诉浏览器此HTML页面不被缓存,每次访问都去服务器上下载。
使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持。因为代理不解析HTML内容本身。
所以我们常说的浏览器缓存还是通过HTTP头信息来控制缓存。
2、使用HTTP头信息控制缓存
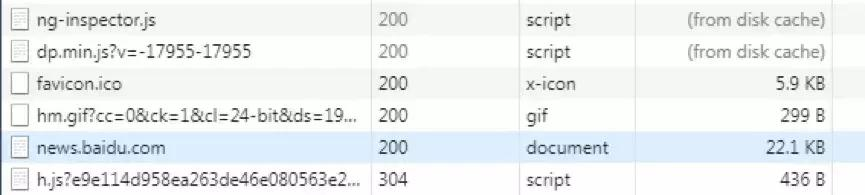
通过浏览器开发者工具我们可以看到,浏览器请求服务器静态资源的响应状态码主要就是下图的三种:
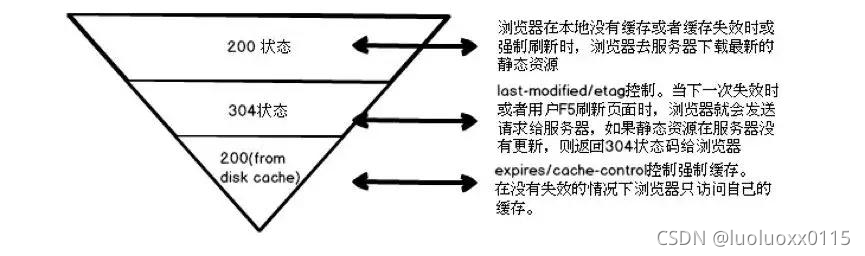
页面的缓存状态是由HTTP协议中关于缓存的信息头决定的,主要的控制关键字有4种:
Last-Modified、Etag、Cache-Control、Expires
Cache-Control 和 Expires首部用于指定缓存时间,Last-Modified 和 ETag 首部提供验证机制
① Expires:缓存过期时间
浏览器可以通过这个时间判断缓存是否过期
(问题:服务端与客户端时间不一致怎么办?也就是缓存不一致)。

② Cache-Control:缓存控制
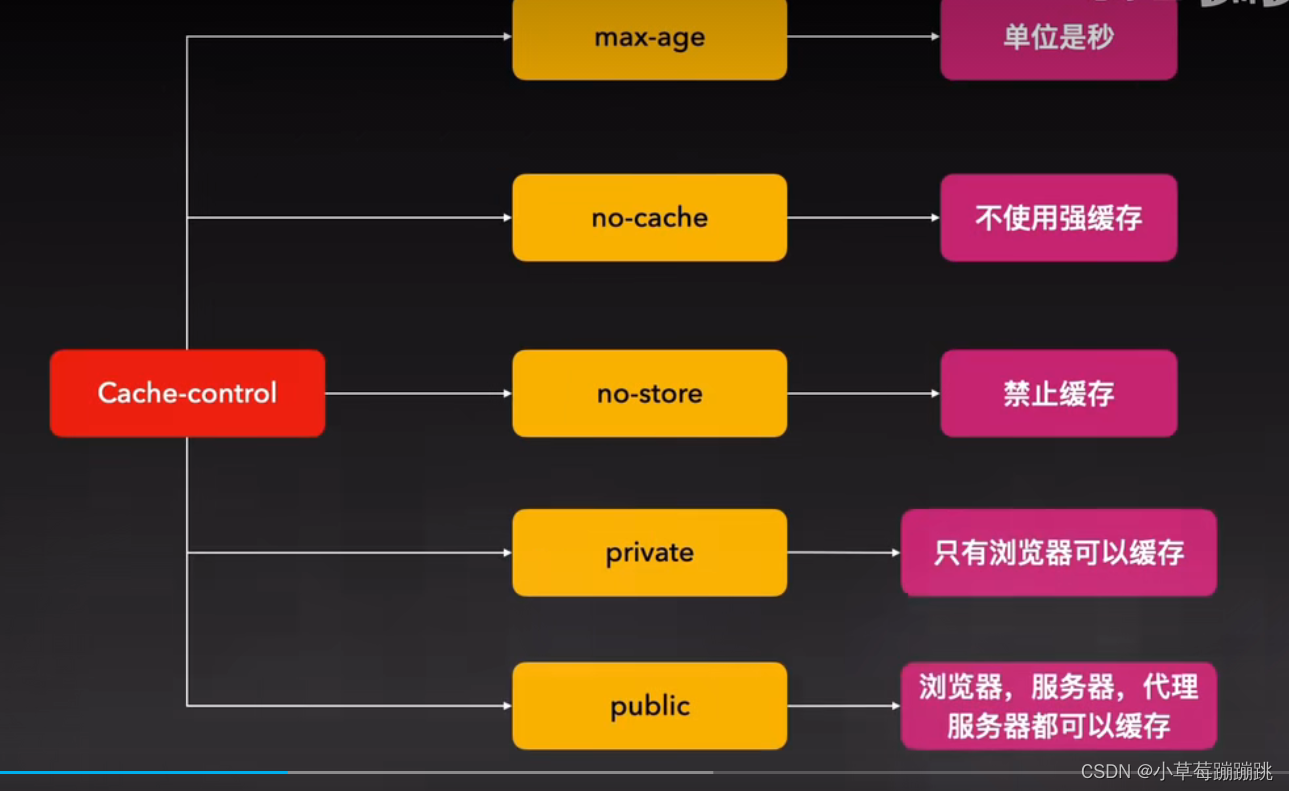
1) max-age
可以用来表示过期时长,单位是秒。表达式是这样子的:Cache-Control: max-age=31536000;例如这个时间就是表示还有1年有效,那就可以直接使用浏览器缓存。
2) no-cache
不是表示不要缓存,而是不使用强缓存,每次使用前都需要跟服务器确认。同时,代理服务器也不能对资源进行缓存。一般用于长期不变的资源,客户端只需要发送很小的信息跟服务端进行确认。
3)no-store
浏览器和代理服务器禁止缓存,每次只能去服务器请求最新资源。
4)private
只有浏览器可以缓存,代理服务器不能缓存。
③ Last-Modified:资源最后修改时间
服务器在响应头返回 Last-Modified,以后每次请求,请求头都会都带上 if-Modified-Since,值就是Last-Modified的值。
服务器拿到这个值后会跟服务器当前的最后修改时间做对比,如果比对结果是不过时,那么说明可以使用缓存,会返回304;如果过时了,服务器会返回200状态,带上最新的资源给浏览器。
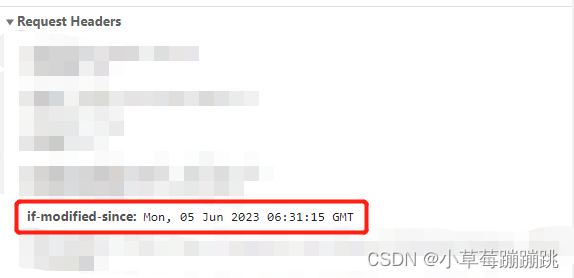
(问题:有新资源服务端却返回304,因为Last-Modified是以秒级为记录的,如果资源在1秒内改变的话,Last-Modified是无感的)
④ ETag:文件内容唯一标识
服务器在响应头返回ETag给浏览器,以后每次请求,请求头都会带上 if-None-Match,值就是ETag的值。
服务器拿到这个值后会跟服务器当前的ETag的值做对比,如果比对结果是没有变化,那么说明可以使用缓存,会返回304;如果不对,服务器会返回200状态,带上最新的资源给浏览器。

四、哪些请求不能被缓存?
① HTTP 信息头中包含 Cache-Control:no-cache,pragma:no-cache,或 Cache-Control:max-age=0 等告诉浏览器不用缓存的请求
② POST 请求无法被缓存
③ HTTP响应头中不包含Last-Modified/ETag,也不包含Cache-Control/Expires的请求无法被缓存
④ 需要根据 Cookie,认证信息等决定输入内容的动态请求是不能被缓存的
⑤ 经过 HTTPS 安全加密的请求(有人也经过测试发现,ie 其实在头部加入 Cache-Control:max-age 信息,firefox 在头部加入 Cache-Control:Public 之后,能够对 HTTPS 的资源进行缓存,参考《HTTPS 的七个误解》)
五、部署时缓存的问题
1、我们不仅要缓存代码,还需要更新代码。如果静态资源名字不变,怎么让浏览器既能缓存,又能在有新代码时更新?
最简单的解决方式就是静态资源路径添加一个版本值
版本不变就走缓存策略,版本变了就加载新资源。如下:
<script src="xx/xx.js?v=24334452"></script>
然而这种处理方式在部署时有问题。
背景:静态资源和页面是分开部署的。
先部署页面,再部署静态资源,会出现用户访问到旧的资源;
先部署静态资源,再部署页面,会出现没有缓存用户加载到新资源而报错。
这些问题的本质是以上的部署方式是“覆盖式发布”,解决方式是“非覆盖式发布”。
即用静态资源的文件摘要信息给文件命名,这样每次更新资源不会覆盖原来的资源,先将资源发布上去。
这时候存在两种资源,用户用旧页面访问旧资源,然后再更新页面,用户变成新页面访问新资源,就能做到无缝切换。
简单来说就是给静态文件名加hash值。
那如何实现呢?使用webpack持久化缓存
现在前端代码都用webpack之类的构建工具打包。浏览器有其缓存机制,想要既能缓存又能在部署时没有问题,需要给静态文件名添加hash值。在webpack中,有些配置能让我们实现持久化缓存。