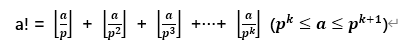四、数学知识
1、分解质因数
1、目标:把一个整数分解成若干质数,输出每个质数以及它的次数。
2、思路:首先判定一个数是否是质数,即用大于等于2的因数去试除,如果余零则说明不是质数,则用该因数累除直到余数不为零,同时创建一个变量来记录次数(幂)。总之,是基于试除法判定因数的。
3、代码注意点:
(1)1 到 n 中最多只包含一个大于 n \sqrt n n 的质因子,所以不要忘记如果最后得到的数依然大于1的话要输出他和相应的次数
(2)试除法不推荐采用 i <= sqrt(n)因为每次循环都要执行一次,速度慢;也不推荐i * i <= n因为 i * i可能会溢出。试除法的时间复杂度是 O ( n ) O(\sqrt n) O(n)
2、埃拉托斯特尼筛素数法 (sieve of Eratosthenes)
1、目标:筛选出从1 到 n之内的所有素数。
2、思路:依次把 1 到 n 之间的素数的倍数都筛出去。
3、时间复杂度:它的时间复杂度是 O ( n l o g l o g n ) O(nloglogn) O(nloglogn)
3、线性筛素数法
1、目标:线性地筛出从 1 到 n之间的所有素数
2、思路:埃拉托斯特尼筛法中一些数会被重复地筛,比如6既是2的倍数又是3的倍数,所以会被筛两次,不是线性的。因此线性筛素数法的思想就是保证从 1 到 n 的每个合数都被它们最小的质数筛掉并且只筛一次。
3、代码注意点:
(1)在筛素数时,因为要把 prime[j] * i筛掉,所以循环的条件里应该是 prime[j] <= n / i
(2)和埃拉托斯特尼筛法的代码模板不同的是,在线性筛法中如果 st[j] = true则执行筛选的循环体,但是在埃拉托斯特尼筛法中当 st[j] = true时会进行 continue操作。st[i]存储的是 i 是否已经被筛掉了。
(3)在筛选循环体内应该最后判断 prime[ j ] 是否是 i 的最小质数,如果是则break。因为线性筛法正是要让每个合数都被它们的最小质数筛掉。如果提前break了,则只筛掉了小于 i 的最小质数的数的倍数。
4、约数的个数
1、目标:求一个正整数的约数(不是质因子)的个数
2、思路:一个正整数可以表示成:
N = P 1 C 1 ⋅ P 2 C 2 ⋅ P 3 C 3 . . . ⋅ P n C n P i : 质 因 子 , C i : 质 因 子 的 次 数 N = P_{1}^{C_{1}} \cdot P_{2}^{C_{2}} \cdot P_{3}^{C_{3}} \quad ... \quad \cdot P_{n}^{C_{n}}\\ P_i: 质因子,\quad C_i: 质因子的次数 N=P1C1⋅P2C2⋅P3C3...⋅PnCnPi:质因子,Ci:质因子的次数
那么由于每一个质因子的次数可以取 [ 0 , C i ] [0, C_i] [0,Ci] 所以约数的个数显然是:
∑ i = 0 n ( C i + 1 ) \sum_{i=0}^{n}(C_{i} + 1) i=0∑n(Ci+1)
3、代码注意点:
(1)最后的答案可能很大,最好用 long long 来存储。
(2)利用哈希表来存储约数和约数的个数会比较方便。
(3)res = res * (x.second + 1) % M;这一句话不能写成 res *= (x.second + 1) % M
5、约数之和
1、目标:求一个正整数的约数(不是质因子)的和
2、思路:一个正整数可以表示成
N = P 1 C 1 ⋅ P 2 C 2 ⋅ P 3 C 3 . . . ⋅ P n C n P i : 质 因 子 , C i : 质 因 子 的 次 数 N = P_{1}^{C_{1}} \cdot P_{2}^{C_{2}} \cdot P_{3}^{C_{3}} \quad ... \quad \cdot P_{n}^{C_{n}}\\ P_i: 质因子,\quad C_i: 质因子的次数 N=P1C1⋅P2C2⋅P3C3...⋅PnCnPi:质因子,Ci:质因子的次数
那么由于每一个质因子的次数可以取 [ 0 , C i ] [0, C_i] [0,Ci] 所以,所有约数的和显然是:
∑ i = 1 i = n ∑ j = 0 j = n P i j \sum_{i=1}^{i=n}\sum_{j=0}^{j=n}P_{i}^{j} i=1∑i=nj=0∑j=nPij
3、代码注意点:
(1) ∑ j = 0 j = n P j \sum_{j=0}^{j=n}P_j ∑j=0j=nPj 可以用一句话写出来:int t = 1; while(c--) t = (t * p + 1)
(2)同样这道题的答案也有可能爆int,所以用 long long 来存储。
6、欧几里得算法
1、目标:求一个正整数的最大公约数
2、思路: g c d ( a , b ) = g c d ( b , a m o d b ) gcd(a, b) = gcd(b, \ a \mod b) gcd(a,b)=gcd(b, amodb) 证明需要用到一些简单的性质。如果 d ∣ a , d ∣ b → d ∣ ( x a + y b ) d | a, d|b \to d|(xa+yb) d∣a,d∣b→d∣(xa+yb)
∵ a m o d b = a − ⌊ a b ⌋ ⋅ b l e t c = ⌊ a b ⌋ ∴ a m o d b = a − c ⋅ b ∴ i f g c d ( b , a m o d b ) = t t ∣ b , t ∣ ( a − c ⋅ b ) ∴ t ∣ b , t ∣ a ∴ g c d ( b , a m o d b ) = g c d ( a , b ) \begin{aligned} &\because a \mod b = a - \lfloor \frac{a}{b} \rfloor \cdot b \\ &\ \ \ \ \ let \ \ c=\lfloor \frac{a}{b} \rfloor\\ &\therefore a \mod b = a - c\cdot b \\ &\therefore if \ gcd(b, a \mod b)=t\\ & \ \ \ \ \ t|b, \ t|(a-c\cdot b)\\ &\therefore t|b ,\ t|a\\ &\therefore gcd(b, a\mod b) = gcd(a,b) \end{aligned} ∵amodb=a−⌊ba⌋⋅b let c=⌊ba⌋∴amodb=a−c⋅b∴if gcd(b,amodb)=t t∣b, t∣(a−c⋅b)∴t∣b, t∣a∴gcd(b,amodb)=gcd(a,b)
7、欧拉 ϕ \phi ϕ 函数(Euler’s totient function)
1、目标:求 1 到 N 之间与 N 互质的数的个数
2、结论:
N = p 1 a 1 p 2 a 2 … p m a m ϕ ( N ) = N ∗ p 1 − 1 p 1 ∗ p 2 − 1 p 2 ∗ … ∗ p m − 1 p m N=p_{1}^{a_{1}} p_{2}^{a_{2}} \ldots p_{m}^{a_{m}}\\ \phi(N)=N * \frac{p_{1}-1}{p_{1}} * \frac{p_{2}-1}{p_{2}} * \ldots * \frac{p_{m}-1}{p_{m}} N=p1a1p2a2…pmamϕ(N)=N∗p1p1−1∗p2p2−1∗…∗pmpm−1
上式每一项都向下取整。
3、证明:可以利用容斥原理,大致思路是从 n 个数当中减去一个质数的倍数,则有些数可能同时是两个质数的公倍数,那么它们就被减去了两次,在把它们的数量加回来,再减去三个质数的公倍数,再加上四个质数的公倍数的个数……
4、代码注意点:
(1)需要写成res = res / i * (i - 1),不能写成 res = res * (i - 1) / i防止溢出
8、线性筛法求欧拉 ϕ \phi ϕ 函数
1、目标:求出从 1 到 N之间每一个数的欧拉函数
2、思路:如果只是在普通的欧拉函数外面套一层循环,时间复杂度过高。所以想到借鉴线性筛素数法,能否线性地求出1到 N 的欧拉函数呢?首先,一个质数 P 的欧拉函数显然是 P - 1。接下来根据线性筛素数法的模板,需要根据 i % primes[j]是否等于0来分情况讨论 primes[j]*i 的欧拉函数是多少。
如果等于0,则说明 primes[ j ] 是 i 的一个质因子,因为 primes[j]*i 的欧拉函数只和它的质因子有关, primes[j]*i 的质因子比 i 的质因子多了一个 primes[ j ],并且 primes[ j ] 还是一个质数,所以 primes[j]*i 的欧拉函数显然应该是: p r i m e s [ j ] ⋅ ϕ ( i ) primes[j] \cdot \phi(i) primes[j]⋅ϕ(i)
如果不等于0,那么在计算 primes[j]*i 的欧拉函数时除了要再乘上一个 primes[ j ] 还要再乘一项 1 − 1 p r i m e s [ j ] 1 - \frac{1}{primes[j]} 1−primes[j]1 ,所以 primes[j]*i 的欧拉函数应该是: ( p r i m e s [ j ] − 1 ) ⋅ ϕ ( i ) (primes[j] - 1)\cdot\phi(i) (primes[j]−1)⋅ϕ(i)
综上,就可以线性地求得 1 到 N 之间每个数的欧拉函数。
9、快速幂
1、目标:快速地求出 a k m o d p , 1 ≤ a , k , p ≤ 1 0 9 a^{k} \mod p, 1 \leq a, k, p \leq 10^9 akmodp,1≤a,k,p≤109 它的时间复杂度为 O ( l o g k ) O(logk) O(logk)
2、思路:首先预处理出来:
a 2 0 m o d p a 2 1 m o d p a 2 2 m o d p ⋮ a 2 l o g k m o d p \begin{aligned} &a^{2^0} \mod p\\ &a^{2^1}\mod p\\ &a^{2^2}\mod p\\ &\vdots\\ &a^{2^{logk}}\mod p\\ \end{aligned} a20modpa21modpa22modp⋮a2logkmodp
然后把 a k a^k ak 组合出来, a k = a 2 x 1 ⋅ a 2 x 2 ⋅ a 2 x 3 ⋯ ⋅ a 2 x k a^{k} = a^{2^{x_1}}\cdot a^{2^{x_2}} \cdot a^{2^{x_3}} \cdots \cdot a^{2^{x_k}} ak=a2x1⋅a2x2⋅a2x3⋯⋅a2xk ,显然实质上就是要让: k = 2 x 1 + 2 x 2 + ⋯ + 2 x k k = 2^{x_1} + 2^{x_2} + \cdots + 2^{x_k} k=2x1+2x2+⋯+2xk ,要达到这种目标只需要把 k 转换成二进制表示就行了。
预处理这一步可以采用反复平方法。
10、求逆元
1、目标:找到一个整数 x x x 使得 a b ≡ a ⋅ x ( m o d m ) \frac{a}{b} \equiv a\cdot x(mod \ \ m) ba≡a⋅x(mod m) ,其中 b b b 和 m m m 互质。记 x = b − 1 x=b^{-1} x=b−1,这么做的好处是可以把除法转换成乘法。对该式子稍作变形即可得到: b ⋅ x ≡ 1 ( m o d m ) b\cdot x \equiv 1 (mod \ \ m) b⋅x≡1(mod m),这个式子较为简单可以用来方便地求逆元。
2、欧拉定理与费马小定理:
- 欧拉定理:当 n n n 和 a a a 互质时:
a φ ( n ) ≡ 1 ( m o d n ) a^{\varphi(n)} \equiv 1 \ (\bmod n) aφ(n)≡1 (modn)
提供一种证明思路:
已知 ϕ ( n ) \phi(n) ϕ(n) 的含义是 1 到 n 中和 n 互质的个数。假设这些数是 x 1 , x 2 , ⋯ , x ϕ ( n ) x_1, x_2, \cdots, x_{\phi(n)} x1,x2,⋯,xϕ(n) ,因为 a a a 又和 n n n 互质所以 a x 1 , a x 2 , ⋯ , a x ϕ ( n ) ax_1, ax_2, \cdots, a_{x_{\phi(n)}} ax1,ax2,⋯,axϕ(n) 也和 n n n 互质。所以 x 1 , x 2 , ⋯ , x ϕ ( n ) x_1, x_2, \cdots, x_{\phi(n)} x1,x2,⋯,xϕ(n) 和 a x 1 , a x 2 , ⋯ , a x ϕ ( n ) ax_1, ax_2, \cdots, a_{x_{\phi(n)}} ax1,ax2,⋯,axϕ(n) 其实是同一堆数,所以应该有:
$$
\begin{aligned}
&x_1x_2\cdots x_{\phi(n)} \equiv ax_1ax_2\cdots ax_{x_{\phi(n)}} \ \ (mod \ \ n)\
&x_1x_2\cdots x_{\phi(n)} \equiv a^{\phi(n)}x_1x_2\cdots x_{x_{\phi(n)}} \ \ (mod \ \ n)\
&\because
\left{
\begin{array}{lr}
x \equiv y \ \ (mod \ \ t)\
x\cdot z \equiv y \ \ (mod \ \ t)
\end{array}
\right.
\to
z \equiv 1 \ \ (mod \ \ t)\
&\therefore
a^{\phi(n)} \equiv 1 \ \ (mod \ \ n)
\end{aligned}
$$
-
费马小定理:当 n n n 是质数时,不妨设 n = p n = p n=p 则有 ϕ ( p ) = p − 1 \phi(p) = p - 1 ϕ(p)=p−1,则有:
a p − 1 ≡ 1 ( m o d p ) a^{p - 1} \equiv 1 \ \ (mod \ \ p) ap−1≡1 (mod p)
3、逆元求解思路: b ⋅ x ≡ 1 ( m o d m ) b\cdot x \equiv 1 (mod \ \ m) b⋅x≡1(mod m) ,当 m m m 是质数时,根据费马小定理有: b m − 1 ≡ 1 ( m o d m ) b^{m - 1} \equiv 1 \ \ (mod \ \ m) bm−1≡1 (mod m) ,进一步可以得到:
b ⋅ b p − 2 ≡ 1 ( m o d m ) b \cdot b^{p - 2} \equiv 1 \ \ (mod \ \ m) b⋅bp−2≡1 (mod m)
所以得到一个结论: b b b 存在乘法逆元的充要条件是 b b b 与模数 m m m 互质。当模数 m m m 为质数时, b m − 2 b^{m - 2} bm−2 即为 b b b 的乘法逆元。
所以,当 m m m 为质数时,要求 b b b 模 m m m 的逆元只要求 b m − 2 ( m o d m ) b^{m - 2} \ \ (mod \ \ m) bm−2 (mod m) 即可,此时问题就转化为了快速幂!
当 m m m 不是质数时,可以用扩展欧几里得方法解一个线性同余方程: a x ≡ 1 ( m o d m ) ax \equiv 1 \ \ (mod \ \ m) ax≡1 (mod m)
4、代码注意点:
(1)所有模数的倍数都不存在逆元
11、扩展欧几里得算法
1、裴蜀定理:对 ∀ a , b ∈ Z , ∃ x , y ∈ Z s . t . a x + b y = g c d ( a , b ) \forall a, b \in Z, \exist \ x, y \in Z \ \ s.t.\ \ ax+by=gcd(a, b) ∀a,b∈Z,∃ x,y∈Z s.t. ax+by=gcd(a,b)
2、目标:对给出的一对 ( a , b ) (a, b) (a,b) 求出符合裴蜀定理的 ( x , y ) (x, y) (x,y)
3、思路:在欧几里得算法的基础上加以改进。
首先当 b = 0 b = 0 b=0 时, g c d ( a , b ) = a gcd(a, b) = a gcd(a,b)=a 所以显然 x = 1 , y = 0 x = 1, y = 0 x=1,y=0 可以是一组解;
当 b ≠ 0 b \neq 0 b=0 时,则变成了 d = g c d ( b , a m o d b ) d = gcd(b, a \ mod \ b) d=gcd(b,a mod b) ,又 a m o d b = a − ⌊ a b ⌋ ⋅ b a\ mod \ b = a - \lfloor \frac{a}{b}\rfloor \cdot b a mod b=a−⌊ba⌋⋅b ,所以需要求:
y b + x ( a − ⌊ a b ⌋ ⋅ b ) = d x a + ( y − ⌊ a b ⌋ ⋅ x ) b = d \begin{aligned} &yb + x(a - \lfloor \frac{a}{b}\rfloor \cdot b) = d\\ &xa + (y - \lfloor \frac{a}{b} \rfloor \cdot x) b = d \end{aligned} yb+x(a−⌊ba⌋⋅b)=dxa+(y−⌊ba⌋⋅x)b=d
与最初的等式: x a + y b = d xa + yb=d xa+yb=d 相比, a a a 的系数不用更新, y y y 的系数进行更新即可。
4、代码注意点:
(1)迭代的时候,对调 x , y x, \ y x, y 的位置可以方便计算。
12、线性同余方程
1、目标:求解形如: a x ≡ b ( m o d m ) ax \equiv b \ \ (mod \ \ m) ax≡b (mod m) 的方程,其中 x x x 是未知数。
2、思路:将方程变形后可以用扩展欧几里得法求解。原式可变为:
a x = y m + b a x − y m = b l e t y ′ = − y , a x + m y ′ = b ax = ym + b \\ ax - ym = b\\ let\ \ y\prime = -y, \\ ax + my\prime= b ax=ym+bax−ym=blet y′=−y,ax+my′=b
根据裴蜀定理,当且仅当 g c d ( a , m ) ∣ b gcd(a, m) | b gcd(a,m)∣b 时方程才有解。
3、代码注意点:
(1)在数学意义上 a ≡ b ( m o d m ) → b = a − ⌊ a m ⌋ ⋅ m a \equiv b \ \ (mod \ \ m) \to b = a - \lfloor \frac{a}{m} \rfloor \cdot m a≡b (mod m)→b=a−⌊ma⌋⋅m 对于负数也是一样的。
13、中国剩余定理
1、目标:用来求一种特殊的线性同余方程组。
{ x ≡ a 1 ( m o d m 1 ) x ≡ a 2 ( m o d m 2 ) ⋮ x ≡ a n ( m o d m n ) \left\{\begin{array}{c} x \equiv a_{1}\left(\bmod m_{1}\right) \\ x \equiv a_{2}\left(\bmod m_{2}\right) \\ \vdots \\ x \equiv a_{n}\left(\bmod m_{n}\right) \end{array}\right. ⎩⎪⎪⎪⎨⎪⎪⎪⎧x≡a1(modm1)x≡a2(modm2)⋮x≡an(modmn)
假设 m 1 , m 2 , ⋯ , m n m_1, m_2, \cdots , m_n m1,m2,⋯,mn 两两互质,那么对于任意整数 a 1 , a 2 , ⋯ , a n a_1, a_2, \cdots, a_n a1,a2,⋯,an 上述方程有解。令 M = ∏ i = 1 n m i M= \prod_{i=1}^{n} m_{i} M=∏i=1nmi , M i = M m i , i ∈ { 1 , 2 , ⋯ , n } M_i = \frac{M}{m_i}, i \in \{1,2,\cdots, n \} Mi=miM,i∈{1,2,⋯,n} ,设 t i = M i − 1 t_i = M_i ^ {-1} ti=Mi−1 为 M i M_i Mi 模 m i m_i mi 的逆元。则解为:
x = a 1 t 1 M 1 + a 2 t 2 M 2 + ⋯ + a n t n M n + k M = k M + ∑ i = 1 n a i t i M i , k ∈ Z x=a_{1} t_{1} M_{1}+a_{2} t_{2} M_{2}+\cdots+a_{n} t_{n} M_{n}+k M=k M+\sum_{i=1}^{n} a_{i} t_{i} M_{i}, \ \ k \in \mathbb{Z} x=a1t1M1+a2t2M2+⋯+antnMn+kM=kM+i=1∑naitiMi, k∈Z
如果再模上 M M M 则方程的解为: x = ( ∑ i = 1 n a i t i M i ) m o d M x=\left(\sum_{i=1}^{n} a_{i} t_{i} M_{i}\right) \bmod M x=(∑i=1naitiMi)modM ,可以这样求得最小正整数解。
2、应用:最经典的例子就是韩信点兵:有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二。问物几何?即,一个整数除以三余二,除以五余三,除以七余二,求这个整数。
由题意得:
{ x ≡ 2 ( m o d 3 ) x ≡ 3 ( m o d 5 ) x ≡ 2 ( m o d 7 ) \left\{\begin{array}{c} x \equiv 2 \ \ (mod \ \ 3)\\ x \equiv 3 \ \ (mod \ \ 5)\\ x \equiv 2 \ \ (mod \ \ 7) \end{array}\right. ⎩⎨⎧x≡2 (mod 3)x≡3 (mod 5)x≡2 (mod 7)
| a i a_{i} ai | 2 2 2 | 3 3 3 | 2 2 2 |
|---|---|---|---|
| M i M_i Mi | $3$5 | 21 21 21 | 15 15 15 |
| t i t_i ti | 2 2 2 | 1 1 1 | 1 1 1 |
则 x = 2 × 35 × 2 + 3 × 21 × 1 + 2 × 15 × 1 + 105 k = 105 k + 233 , k ∈ Z x = 2 \times 35 \times 2 + 3 \times 21 \times 1 + 2 \times 15 \times 1 + 105k=105k + 233, k\in \mathbb{Z} x=2×35×2+3×21×1+2×15×1+105k=105k+233,k∈Z 所以最小的正整数解应该是23
3、变形:中国剩余定理只有当 m 1 , m 2 , ⋯ , m n m_1, m_2, \cdots , m_n m1,m2,⋯,mn 两两互质 时才成立。如果没有这样的限制条件该如何处理?
{ x ≡ a 1 ( m o d m 1 ) x ≡ a 2 ( m o d m 2 ) ⋮ x ≡ a n ( m o d m n ) \left\{\begin{array}{c} x \equiv a_{1}\left(\bmod m_{1}\right) \\ x \equiv a_{2}\left(\bmod m_{2}\right) \\ \vdots \\ x \equiv a_{n}\left(\bmod m_{n}\right) \end{array}\right. ⎩⎪⎪⎪⎨⎪⎪⎪⎧x≡a1(modm1)x≡a2(modm2)⋮x≡an(modmn)
首先只研究前两个方程:
{ x ≡ a 1 ( m o d m 1 ) x ≡ a 2 ( m o d m 2 ) \left\{\begin{array}{c} x \equiv a_1 \ \ (mod \ \ m1)\\ x \equiv a_2 \ \ (mod \ \ m_2) \end{array}\right. {x≡a1 (mod m1)x≡a2 (mod m2)
可以转化为:
{ x = k 1 ⋅ m 1 + a 1 x = k 2 ⋅ m 2 + a 2 \left\{\begin{array}{c} x = k_1\cdot m_1 + a_1 \\ x = k_2 \cdot m_2 + a_2 \end{array}\right. {x=k1⋅m1+a1x=k2⋅m2+a2
整理得:
k 1 ⋅ m 1 + a 1 = k 2 ⋅ m 2 + a 2 k 1 ⋅ m 1 − k 2 ⋅ m 2 = a 2 − a 1 k_1\cdot m_1 + a_1 = k_2 \cdot m_2 + a_2\\ k_1\cdot m_1 - k_2 \cdot m_2 = a_2 - a_1\\ k1⋅m1+a1=k2⋅m2+a2k1⋅m1−k2⋅m2=a2−a1
上式中, m 1 , m 2 , a 1 , a 2 m_1, m_2, a_1, a_2 m1,m2,a1,a2 已知,根据扩展欧几里得法我们知道,要想此方程有解需要满足: g c d ( m 1 , m 2 ) ∣ a 2 − a 1 gcd(m_1, m_2)|a_2 - a_1 gcd(m1,m2)∣a2−a1 ,记 d = g c d ( m 1 , m 2 ) d = gcd(m_1, m_2) d=gcd(m1,m2),接下来一步比较关键,采用了一个简单的构造法,令 k 1 = k 1 + λ ⋅ m 2 d , k 2 = k 2 + λ ⋅ m 1 d k_1 = k_1 + \lambda \cdot \frac{m_2}{d}, \ \ k_2 = k_2 + \lambda \cdot \frac{m_1}{d} k1=k1+λ⋅dm2, k2=k2+λ⋅dm1 ,代入原方程得:
x ′ = ( k 1 + λ ⋅ m 2 d ) ⋅ m 1 + a 1 = k 1 ⋅ m 1 + a 1 + λ ⋅ m 1 ⋅ m 2 d = x + λ ⋅ m 1 ⋅ m 2 d x\prime = (k_1 + \lambda \cdot \frac{m_2}{d}) \cdot m_1 + a_1 = k_1 \cdot m_1 + a_1 + \lambda \cdot \frac{m_1\cdot m_2}{d} = x + \lambda \cdot \frac{m_1\cdot m_2}{d} x′=(k1+λ⋅dm2)⋅m1+a1=k1⋅m1+a1+λ⋅dm1⋅m2=x+λ⋅dm1⋅m2
也就是说我们能够把两个方程合并成一个方程!如果记 λ ⋅ m 1 ⋅ m 2 d = m ′ \lambda\cdot \frac{m_1\cdot m_2}{d} = m\prime λ⋅dm1⋅m2=m′那么依次类推最终 n n n 个方程将会合并成一个方程: x = x 0 + λ ⋅ m ′ x = x_0 + \lambda \cdot m\prime x=x0+λ⋅m′ ,要求最小非负 x x x ,根据之前中国剩余定理解的形式,要求最小非负的解只要求: x 0 m o d m ′ x_0 \mod m\prime x0modm′
4、代码注意点:
(1)代码中要求最小正整数解的常用操作是: x = (x % M + M) % M
14、高斯消元解线性方程组
1、目标:求解线性方程组
2、思路:首先找到最大的列主元,将其所在行换到首行,并将改行每个元素除以列主元,然后用当前行把剩下行的列主元所在列都消成0,重复此过程,如果最后有效方程的个数小于未知数的个数则有无穷多组解,如果出现了 0 = n , n ≠ 0 0 = n, n \neq 0 0=n,n=0 则无解。否则再从最后一行开始向上迭代求出每个解。
3、代码注意点:
(1)注意esp的类型是 double !!!
(2)注意gauss( )函数内的 c, r,不要定义在循环体内。
15、组合数
1、题型分类:
2、递归法
1、思路: C a b = C a − 1 b + C a − 1 b − 1 C^b_a = C_{a-1}^{b} + C_{a - 1} ^{b - 1} Cab=Ca−1b+Ca−1b−1 它的含义是,假如从 a a a 个苹果中选 b b b 个,我们可以先挑出来一个苹果,然后就有两种情况:一是我们决定要选择这个,那么接下来就在剩下的 a − 1 a - 1 a−1 个苹果中再选择 b − 1 b-1 b−1 个,二是我们决定不选这个,那么就在剩下的 a − 1 a-1 a−1 个中选择 b b b 个。所以我们可以创建一个二维数组来存储每一种组合数的值。
2、代码注意点:
(1)记得初始化一个都不取的情况为 1
3、预处理逆元
1、思路:根据求组合数的公式: C a b = A a b b ! = a ! b ! ( a − b ) ! C_{a}^{b}=\frac{A_{a}^{b}}{b !}=\frac{a !}{b !(a-b) !} Cab=b!Aab=b!(a−b)!a! ,可以预处理出分子分母,这里需要注意,由于最后要求的其实是 C a b m o d m C_a^b \mod \ m Cabmod m 但是
$ (\frac{x}{y}\mod m) \neq \frac{x\mod m}{y\mod m}$ ,所以要求分母对模数的逆元,这样可以把除法转换成乘法并且不影响结果。
2、代码注意点:
(1)注意 fact[0] = infact[0] = 1
4、Lucas 定理
1、公式:若 p p p 是质数,则对 ∀ 1 ≤ b ≤ a \forall 1 \leq b \leq a ∀1≤b≤a 有 C a b = C a m o d p b m o d p ⋅ C a / p b / p m o d p C_a^b = C_{a\ mod \ p}^{b \ mod \ p} \cdot C^{b /p}_{a/p} \mod p Cab=Ca mod pb mod p⋅Ca/pb/pmodp
2、代码注意点:
(1)根据定义求组合数的模板要记住!
int c(int a, int b, int p){if(b > a) return 0;int res = 1;for(int i = a, j = 1; j <= b; i--, j++){res = (LL)res * i % p;res = (LL)res * qmi(j, p - 2, p) % p;}return res;
}
5、分解质因数 + 高精度
1、思路:当我们需要求出组合数的真实值,而非对某个数的余数时,我们可以转换思路,组合数的真实值可以表达成若干个素数的乘积,所以我们只需要做如下几件事:
- 用线性筛法求出范围内的所有质数
- 通过 C a b = a ! b ! ( a − b ) ! C_{a}^{b}=\frac{a !}{b !(a-b) !} Cab=b!(a−b)!a! 这个公式求出每个质因子的次数。 n ! n! n! 中 p p p 的次数是 n / p + n / p 2 + n / p 3 + ⋯ n / p + n / p^2 + n / p^3 +\cdots n/p+n/p2+n/p3+⋯
- 用高精度乘法将所有质因子相乘
2、代码注意点:
(1)用高精度乘法将所有质因子相乘的时候是两层循环,第一层遍历所有质因子,第二层的作用相当于是求质因子的对应次方的值。
16、明安图-卡特兰数
1、公式:
C n = C 2 n n − C 2 n n − 1 = C 2 n n n + 1 C_n = C_{2n}^n - C_{2n}^{n - 1}=\frac{C_{2n}^n}{n + 1} Cn=C2nn−C2nn−1=n+1C2nn
17、容斥原理
1、公式:
∣ ⋃ i = 1 n A i ∣ = ∑ i = 1 n ∣ A i ∣ − ∑ 1 ⩽ i < j ⩽ n ∣ A i ∩ A j ∣ + ∑ 1 ⩽ i < j < k ⩽ n ∣ A i ∩ A j ∩ A k ∣ − ⋯ + ( − 1 ) n − 1 ∣ A 1 ∩ ⋯ ∩ A n ∣ \left|\bigcup_{i=1}^{n} A_{i}\right|=\sum_{i=1}^{n}\left|A_{i}\right|-\sum_{1 \leqslant i<j \leqslant n}\left|A_{i} \cap A_{j}\right|+\sum_{1 \leqslant i<j<k \leqslant n}\left|A_{i} \cap A_{j} \cap A_{k}\right|-\cdots+(-1)^{n-1}\left|A_{1} \cap \cdots \cap A_{n}\right| ∣∣∣∣∣i=1⋃nAi∣∣∣∣∣=i=1∑n∣Ai∣−1⩽i<j⩽n∑∣Ai∩Aj∣+1⩽i<j<k⩽n∑∣Ai∩Aj∩Ak∣−⋯+(−1)n−1∣A1∩⋯∩An∣
∣ ⋃ i = 1 n A i ∣ = ∑ k = 1 n ( − 1 ) k + 1 ( ∑ 1 ⩽ i 1 < ⋯ < i k ⩽ n ∣ A i 1 ∩ ⋯ ∩ A i k ∣ ) \left|\bigcup_{i=1}^{n} A_{i}\right|=\sum_{k=1}^{n}(-1)^{k+1}\left(\sum_{1 \leqslant i_{1}<\cdots<i_{k} \leqslant n}\left|A_{i_{1}} \cap \cdots \cap A_{i_{k}}\right|\right) ∣∣∣∣∣i=1⋃nAi∣∣∣∣∣=k=1∑n(−1)k+1(1⩽i1<⋯<ik⩽n∑∣Ai1∩⋯∩Aik∣)
2、时间复杂度: O ( 2 n ) O(2^n) O(2n)
3、代码注意点:
(1)根据组合恒等式: ∑ i = 0 n C n i = 2 n \sum_{i=0}^{n} C_{n}^{i}=2^{n} ∑i=0nCni=2n , k k k 个集合共有 2 k − 1 2^{k} - 1 2k−1 种选法,排除了一个集合都不选的情况。针对这种类型的枚举,一个常用的技巧是位运算。枚举从 1 到 2 k − 1 2^k - 1 2k−1 的每个数的形式,如 果第 n n n 位是0,就代表不选第 n n n 个集合,如果是 1 就代表选择这个集合。
比如有三个集合 S 1 , S 2 , S 3 S_1, S_2, S_3 S1,S2,S3 ,显然共有 7 种组合方式: S 1 , S 2 , S 3 , S 1 ∩ S 2 , S 1 ∩ S 3 , S 2 ∩ S 3 , S 1 ∩ S 2 ∩ S 3 S_1, S_2, S_3, S_1\cap S_2, S_1 \cap S_3, S_2 \cap S_3, S_1\cap S_2 \cap S_3 S1,S2,S3,S1∩S2,S1∩S3,S2∩S3,S1∩S2∩S3 ,1 到 7 的二进制数正好能够不重不漏地包含这些情况。001,010, 011, 100, 101, 110,111
(2)一个 n n n 为的二进制数能够左移的范围应该是 0 ~ n - 1 位。
(3) [ 1 , n ] , n > 1 , n ∈ Z [1, n], n > 1 , n \in \mathbb{Z} [1,n],n>1,n∈Z 的区间内,能被 t , t ∈ [ 1 , n ] t, t \in [1, n] t,t∈[1,n] 整除的数的个数是 ⌊ n t ⌋ \lfloor \frac{n}{t} \rfloor ⌊tn⌋