1. 概述
ASN.1 – Abstract Syntax Notation dot one,抽象记法1。数字1被ISO加在ASN的后边,是为了保持ASN的开放性,可以让以后功能更加强大的ASN被命名为ASN.2等,但至今也没有出现。
ASN.1描述了一种对数据进行表示、编码、传输和解码的数据格式。它提供了一整套正规的格式用于描述对象的结构,而不管语言上如何执行及这些数据的具体指代,也不用去管到底是什么样的应用程序。
ASN.1的目的是借助于该标准中记法(Notation),让我们如何一一中精确、无歧义去描述我们的数据。当然,我们的数据是一定要被存储、传输的,而BER/CER/DER/PER/XER就是为了编码我们的数据而制定的。
1.1. 标准
描述ASN.1记法的标准:
ITU-T Rec. X.680 | ISO/IEC 8824-1
ITU-T Rec. X.681 | ISO/IEC 8824-2
ITU-T Rec. X.682 | ISO/IEC 8824-3
ITU-T Rec. X.683 | ISO/IEC 8824-4
描述ASN.1编码规则的标准
ITU-T Rec. X.690 | ISO/IEC 8825-1 (BER, CER and DER)
ITU-T Rec. X.691 | ISO/IEC 8825-2 (PER)
ITU-T Rec. X.692 | ISO/IEC 8825-3 (ECN)
ITU-T Rec. X.693 | ISO/IEC 8825-4 (XER)
2. 基本语法规则
在ASN.1中,符号的定义没有先后次序:只要能够找到该符号的定义即可,而不必关心在使用它之前是否被定义过。
所有的标识符、参考、关键字都要以一个字母开头,后接字母(大、小写都可以)、数字或者连字符“-”。不能出现下划线“_”。不能以连字符“-”结尾,不能出现两个连字符(注释格式)。
- 关键字一般都是全部大写的,除了一些字符串类型(如
PrintableString,UTF8String,等。因为这些都是由原类型OCTET STRING衍生出来的)。 - 在标识符中,只有类型和模块名字是以大写字母开头的,其它标识符都是以小写字母开头的。
- 带小数点的小数形式不能在ASN.1中直接使用,在ASN.1中实数实际定义为三个整数:
尾数、基数和指数。 - 注释以两个连字符“–”开始,结束于行的结尾或者该行中另一个双连字符。
- 如同大多数计算机语言,ASN.1不对空格、制表符、换行符和注释做翻译。但是在定义符号(或者分配符号Assignment)“
::=”中不能有分隔符,否则不能正确处理。
3. 类型定义
3.1. 新类型
<新类型的名字> ::= <类型描述>
- <新类型的名字>是一个以大写字母开头的标识符;
- <类型描述>是基于内建类型或在其它地方定义的类型。
3.2. 值定义
<新的值的名字> <该值的类型> ::= <值描述>
- <新的值的名字>是以小写字母开头的标识符;
- <该值的类型>可以是一个类型的名字,也可以是类型描述;
- <值描述>是基于整数、字符串、标识符的组合。
4. 编码格式
ASN.1的编码格式有很多种: BER、CER、DER、XER,可以编码成XML格式,不仅仅是常用的二进制流。BER、CER、DER,是ASN.1的三种最常用的编码格式。
- BER:基本编码规则;
- CER:正则编码规则;
- DER:非典型编码规则;
4.1. CER、DER、CRT、PEM的关系
所有X.509都是DER编码,DER是指ASN.1的编码规则,.der证书文件一般是二进制文件。
CER可用于PKCS#7证书(p7b)的编码,但一般是指证书的文件后缀,.cer证书可以是纯BASE64文件或二进制文件。
PEM通常也是指文件的后缀,为内容使用BASE64编码且带头带尾的特定格式,二进制的文件不应该命名为pem。
CRT是微软的证书后缀名,和.CER是一回事。
微软的CryptAPI很强大,证书的各种格式都可以识别,比如纯BASE64编码的、标准PEM格式的、非标识PEM格式的(不是64字节换行、没有头尾等)、二进制格式的
4.2. BER编码
描述了如何将ASN.1 类型的值编码成字节串的方法。
BER的语法传输格式一直是TLV三元组:<Type, Length, Value>
tag(标志域): 指明数据类型,占用一个字节常见的类型有
BER_TYPE_BOOLEAN 0x01
BER_TYPE_INTEGER 0x02
BER_TYPE_BIT_STRING 0x03
BER_TYPE_OCTET_STRING 0x04
BER_TYPE_NULL 0x05
BER_TYPE_OID 0x06
BER_TYPE_SEQUENCE 0x30
BER_TYPE_SNMP_SET 0xA3
4.2.1. 长度域(length)
指明值域的长度,长度不等,一般为一到三个字节。
其格式可分为短格式(后面的值域长度<=127),长格式.
4.2.1.1. 定长方式

length=30 表示为1E(16进制),30长度域为 0001 1110 没有超过127;
**长格式 **
表示方法为1(bit)K(7bit)K个八位长度(K Byte)

length = 169 转换为 81 A9(169长度超过127,长度域为1000 0001 1010 1001;169是后8位的值,前8位的第一个1表示这是一个长格式的表示方法,前8位的后7位表示后面有多少个字节表示针对的长度000 0001后面有一个字节表示真正的长度 1010 1001是表示长度为169);
length=1500转换为 82 05 DC(1000 0010 0000 0101 1101 1100,先看第一个字节,表示长格式,后面有2 个字节表示长度,这两个字节是0000 0101 1101 1100 表示1500);
4.2.1.2. 不定长方式
TLV三元组:<Type, Length, Value>
Length所在八位组固定编码为0x80,但在Value编码结束后以两个0x00结尾。
这种方式使得可以在编码没有完全结束的情况下,可以先发送部分消息给对方。
Length所在八位组固定编码为0x80,但在Value编码结束后以两个0x00结尾。这种方式使得可以在编码没有完全结束的情况下,可以先发送部分消息给对方。

4.2.2. 值域(value)
TLV三元组:<Type, Length, Value>
整型Integer的编码 integer::=0x02 length{byte} (表示重复)
最高位代表符号位,去掉多余的0。
对于正数,如果最高比特位为0则直接编码;如果为1,则在最高比特位之前增加一个全0的八位组。
最高位为0:0BBBBBBB
最高位为1:00000000|1BBBBBBB
例: 对于负数,先取绝对值进行编码,再取反,最后加1
1500=>02 02 05 DC
40000=>02 03 00 9C 40
-129=>129=>0000 0000 1000 0001->1111 1111 0111 1110 ->(加1)->FF 7F 最终为02 02 FF 7F
布尔值的编码由1个字节组成。FALSE为00; TRUE为FF。
- TRUE的编码: 01 01 FF
- FALSE 的编码: 01 01 00
字符串类型的编码
string::=0x04 length{byte}*
例如:04 06 70 75 62 6c 69 63表示字符串public
位串(BITSTRING)类型
编码规则:
- 位串的第一位放到第一个负载字节的第8位;
- 位串的第二位放到第一个负载字节的第7位;
- 依此类推.
填充满第一个负载字节,就继续填充第二个负载字节.
如果最后一个负载字节未被填充满,空的位用0来填充, 0的个数存放到头部用来表示填充数据的那个字节里.
例
位串{1,0,0,0,1,1,1,0,1,0,0,1}
开始填充负载字节.
第一个字节填充后为10001110= 0x8E;
第 二个字节填充后为10010000 = 0x90, 低位4个0为填充的空位.
则,负载为2个字节加上表示填充0个数的一个字节0x04总共3个字节.
则完整的编码为:0x03 03 04 8E 90.
空类型的编码 null::=0x05 0x00
objectID::=0x06 length {subidentifier}*
首两个ID被合并为一个字节X*40+Y
每个字首先被分割为最少数量的没有头零数字的7位数字。
这些数字以big-endian格式进行组织,并且一个接一个地组合成字节.
举例:
30331 = 1* 128^2 + 108 * 128 + 123
分割成7位数字(0x80)后为{1,108,123}
除了编码的最后一个字节外,其他所有字节的最高位(位8)都为1.
设置最高位后变成{129,236,123}.如果该字只有一个7位数字,那么最高为0
MD5 OID的编码:
- 将
1.2.840.113549.2.5转换成字数组{42, 840, 113549, 2, 5}. - 然后将每个字分割为带有最高位的7位数字,
{{0x2A},{0x86,0x48},{0x86,0xF7,0x0D},{0x02},{0x05}} - 最后完整的编码为
0x06 08 2A 86 48 86 F7 0D 02 05.
sequence组合类型的编码
sequence::=0x30 length{asndata}*
如:30 05 02 01 10 05 00表示一个sequence结构,内含两个成员,其中一个为整型16,另一个为空类型(NULL)。
例:考虑如下序列
User ::== SEQUENCE{
ID INTEGER,
Active BOOLEAN
}
当取值为{32,TRUE}时,编码为 0x30 06 02 01 20 01 01 FF
在ASN.1文档里,使用空格来表示编码的属性.
0x30 06
02 01 20
01 01 FF
5. ASN.1/C
本章内容来自https://www.oss.com/asn1/products/documentation/asn1_c/asn1c-runtime-advanced.html
5.1. 内存、文件、套接字和 PDU 处理
PDU 编码或解码需要大量使用内存来存储源和目标数据缓冲区。编码的 PDU 始终存储为单个字节流,而未编码(解码)的 PDU 作为其各个字段(结构、数组和链表的组合)的 C 表示分配在内存中。
根据 PDU 和内存大小、您的性能需求以及您选择的编码器或解码器运行时间(SOED 或 TOED),以下选项可用:
- 将未编码和编码的 PDU 存储在常规内存中(可用于 SOED 和 TOED)。
- 将未编码的 PDU 的单个字段(大数组)存储在文件中(可用于 SOED)。
- 将编码的 PDU 流式传输到文件或套接字(可用于 SOED)/从文件或套接字传输。
此外,您可以组合上述选项。例如,您可以从内存编码到文件或从套接字解码到内存,同时将大 OCTET STRING 字段(未解码 PDU 的)存储在临时文件中。此外,您可以解码在内存缓冲区中开始并在文件或套接字中继续的 PDU。请注意,只有 SOED 库支持文件和套接字。
5.1.1. 处理常规内存中的 PDU(TOED 和 SOED)
如下图所示,编码器或解码器通过 OssGlobal 结构中包含的低级函数(默认情况下:malloc(), realloc(), free())分配和释放内存。
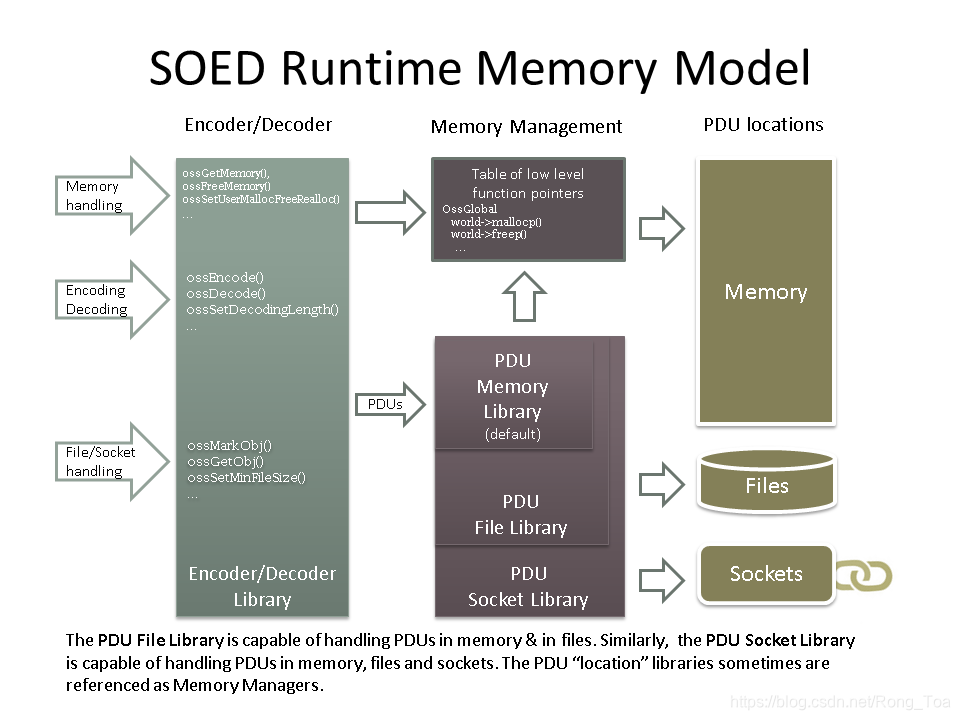
要优化内存使用,请考虑以下选项:
- 使用默认的编码器或解码器内存处理来动态分配输出 PDU 缓冲区(使用ossFreePDU()和ossFreeBuf()来解除分配)。
- 手动预分配输出 PDU 缓冲区(重用预先分配的缓冲区以获得更好的性能)。
- 使用https://www.oss.com/asn1/products/documentation/asn1_c/asn1c-compiler-directives-reference.html#OBJHANDLE标记某些 PDU 字段(字符串)。因此,解码器会将它们视为指针,并且不会将大块内存从编码的 PDU 复制到解码的 PDU。
- 使用 OSS 专用内存管理器覆盖默认内存函数(请参阅ossCreateMemoryHandle())。这可用于 SOED。
- 通过提供您自己的低级实现来自定义默认内存函数(请参阅ossSetUserMallocFreeRealloc())。
该部分内容较多,详情请参见https://www.oss.com/asn1/products/documentation/asn1_c/asn1c-runtime-advanced.html。
6. asn1c
上一张介绍了ASN.1/C,本章介绍其C语言工具(不包含其他语言的工具,如java)asn1c的编译与使用。参考链接为:http://lionet.info/asn1c/blog/。
为了能更加详细的介绍,我将在单独的一篇中进行讲解。
7. 参考链接
7.1. 文章链接
- http://zh.wikipedia.org/wiki/ASN.1
- ASN.1编码方式详解
- https://www.oss.com/asn1/resources/books-whitepapers-pubs/larmouth-asn1-book.pdf
- https://www.oss.com/asn1/products/documentation/asn1_c/asn1c-runtime-advanced.html#Partial_Decoding
- https://www.oss.com/asn1/products/documentation/asn1_c/asn1c-runtime-advanced.html
- 道格巴巴文档;
- http://lionet.info/asn1c/blog/
7.2. 链接
- http://gitlab.opensource5g.org:8888/5G/asn1c
- http://lionet.info/asn1c/examples.html
- http://lionet.info/asn1c/download.html
- http://lionet.info/soft/asn1c-0.9.28.tar.gz