血缘关系在人类社会中扮演着重要角色。大多数家庭是基于血缘关系形成的,而家庭作为社会的基本单元,对维系社会稳定发挥着重要关系。其实,数据之间也存在类似的血缘关系。数据从产生、加工、流转,一直到消亡,每个环节必然存在一定的联系,这种联系就是数据的血缘关系。
数据血缘关系(Data Lineage) 是对数据在系统内、系统间、业务线之间的流动和转换过程的记录,通过这份记录可以追溯数据的源头,跟踪数据的流转历史,查看数据在某一时刻的状态,寻找数据的最终去向等。数据血缘关系相当于旅游线路图和家谱的结合,既能详细记录数据的出发点、每一个途径点和最终的目的,又能体现数据之间的派生谱系。
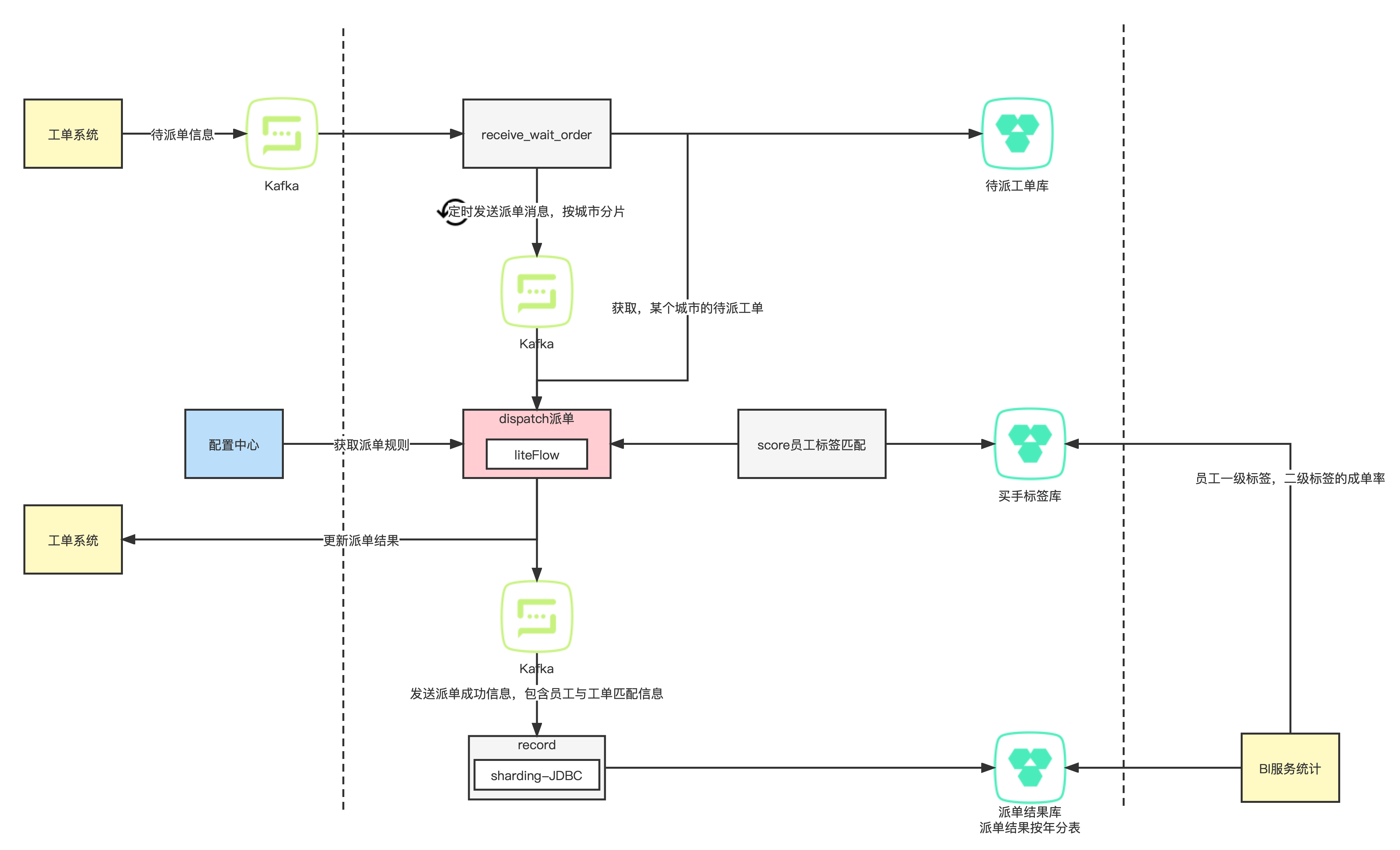
 数据在节点之间的移动称为一跳。上图展示了数据从 A1 到 D2 的路线和所经节点,即数据的血缘路径。 第一跳从 A1 到 B, 第二跳从 B 到 C,第三跳从 C 到 D2,其中 A1 是数据的源头,D2 是数据的最终归宿。
数据在节点之间的移动称为一跳。上图展示了数据从 A1 到 D2 的路线和所经节点,即数据的血缘路径。 第一跳从 A1 到 B, 第二跳从 B 到 C,第三跳从 C 到 D2,其中 A1 是数据的源头,D2 是数据的最终归宿。
特征与构成
数据血缘关系和人类的血缘关系相似,但也存在一些不同。数据血缘关系主要具有以下特点:
- 归属性:特定的数据通常归属于某个组织或个人
- 多元性:一个数据可能是由多个不同的数据经过加工合成而来的,例如营业收入来自销量和单价两种数据。
- 可追溯性:数据血缘关系记录了数据的生命旅途,所以能通过血缘关系追溯数据的来源和加工过程以及最终目的地。
- 层次性:不同层级的数据描述信息体现了数据血缘的层次性。例如,对数据 A 进行描述可以形成新的数据 B, 数据 A 和 B 就构成了简单的二级层次关系。
数据血缘关系的粒度可以分为字段、数据表、服务器、域名、应用程序、业务线等。一个完整的数据血缘系统需要包括以下元素:
- 代码扫描器,连接到各种代码仓库
- 语言解析器,解析语法、词汇、令牌等
- 图论算法,例如遍历、最短路径等
- 消费端,将得到血缘关系进行可视化处理或者提供相关报告
方式与工具
数据血缘的获取主要有两种方式:人工收录和程序自动解析。人工采集费时费力,而且容易出错,而程序解析则能很好地避免这些问题,因此自动获取数据血缘的解决方案越来越受到用户的青睐,市场呈现欣欣向荣之态。目前市场上的数据血缘关系解决方案主要有 Collibra MANTA、ASG becubic、Informatica Metadata Manager、Gudu SQLFlow 等。当然也可以基于代码解析器或注解自行研发相应的工具。
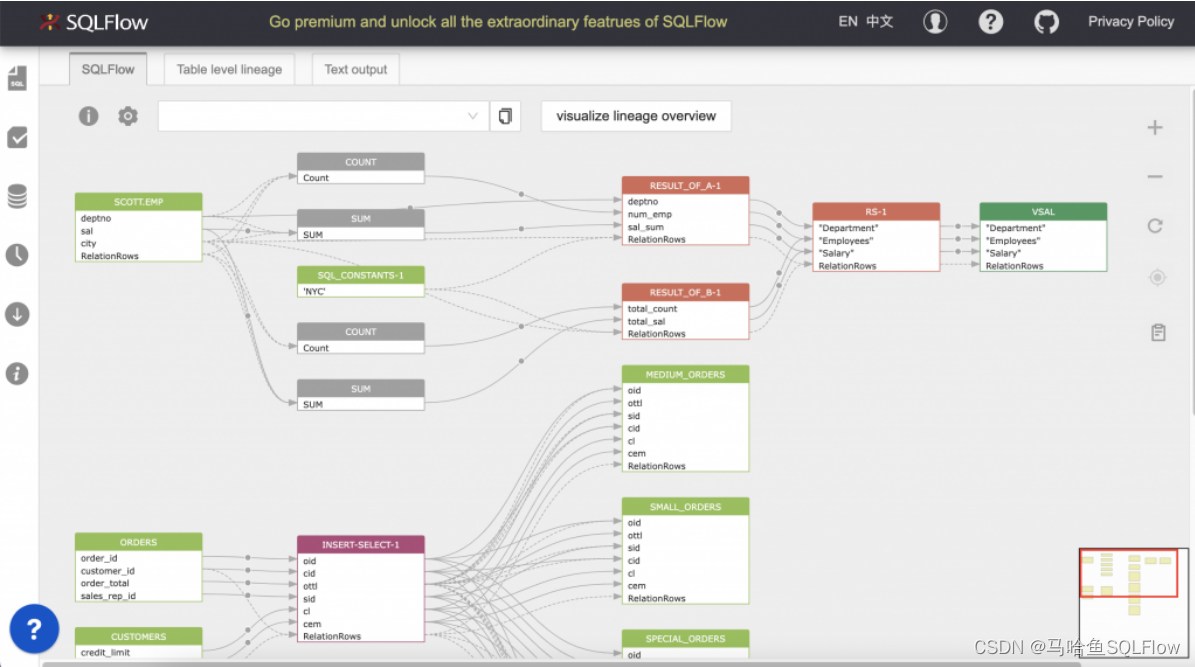
功能与用途
最初需要耗费大量的资源采集数据血缘关系,但这并未阻止数据血缘市场的蓬勃发展。随着大数据时代的来临,数据血缘分析变得愈加重要,推动着相应解决方案的更新迭代,向着自动化方向发展。各种企业机构出于各种各样的原因需要分析数据血缘关系,主要可以概括为以下几方面:
满足数据合规要求
很多数据管理机构以及各种数据治理法规都要求追溯数据的来源,确保数据的合法性。涉及敏感信息的行业需要严格遵守数据合规要求,例如银行、医疗卫生、汽车、社交通信等行业,否则将就会面临巨额罚款。通过数据血缘分析,可以追溯数据源头,确保数据收集的合理合法性。
分析数据变更影响
借助数据血缘分析结果可以分析数据变更的影响,根据血缘分析图中的链路关系可以预测某项变更将影响到下游的哪些数据,以及最终会产生什么样的结果,从而帮助使用者做出更合理的数据决策。
调试/定位/解决业务问题
数据血缘分析详细展示了数据在各个节点之间的路径,提供了数据的观测性。数据出现问题时,可以追踪数据链路,快速定位问题环节。此外,通过分析数据链路也能发现潜在的数据问题。
提升数据透明性
数据治理人员、使用者、以及其他相关人员可以通过血缘分析结果清楚地了解数据的来龙去脉,确保每一次数据变更都符合预期,从而确保数据的产出质量。
提供数据预警
通过数据血缘关系可以监控数据加工链条中的各个节点,并对下油数据产出进行预测分析。一旦发现可能存在延迟或其他问题,就能及时提供预警,便于尽早处理,减少损失。
未来与挑战
目前数据血缘分析仍面临着诸多挑战。例如,没有通用的统一方案可以有效扫描所有技术代码,这进一步导致目前的数据血缘分析系统多是由数种技术综合搭建而成,加剧了整体的复杂性。一些自研技术还需要定制化的解决方案,而开发人员有时又未能遵循相应的代码标准。这些都提升了数据血缘分析的难度。此外,目前很多人对数据血缘的功能认知仅限于监管需要,认识不到其在数据迁移、数据影响分析、数据可靠性、透明性等方面的巨大作用。因此,缺乏足够的投资,严重制约了数据血缘分析行业的发展。
但是随着大数据、深度学习、机器学习、链路预测等技术的发展,数据血缘分析未来会变得更加智能,更广泛地支持实时分析。相应地,更健壮的数据血缘分析体系也必然能推动数据治理的进一步发展,赋能更多的数据治理方案。



![linux学习[11]磁盘与文件系统(2):lsblkblkidpartedfdiskgdiskmkfs](https://img-blog.csdnimg.cn/f70ca8d5aab64e86a28ea065e3c78b01.png)