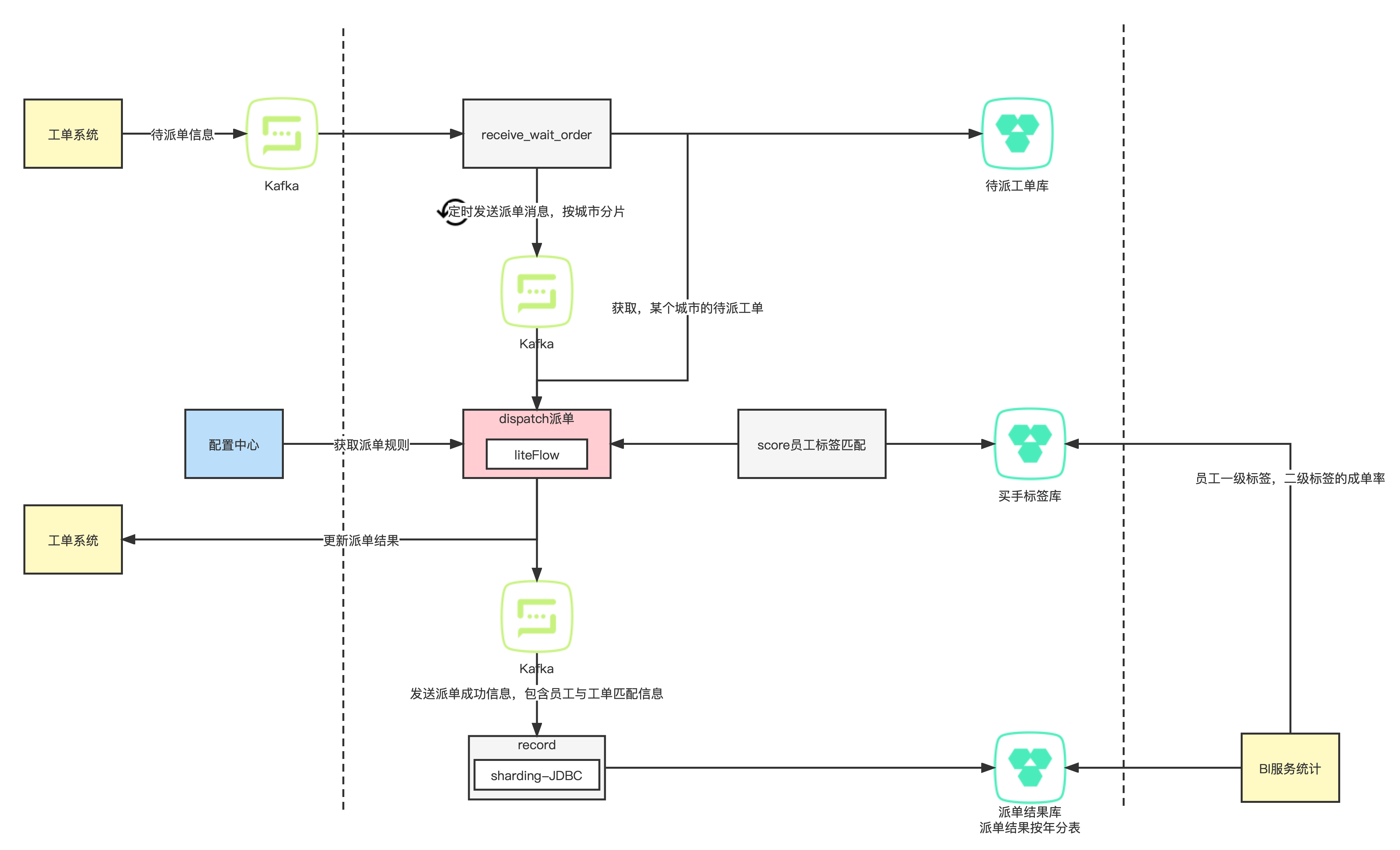
Prometheus是一个流行的开源监控系统,它可以帮助我们收集、存储和查询应用程序或系统的时间序列数据。在使用Prometheus进行监控时,通常需要根据服务水平指标(Service Level Objectives,简称SLO)来设置告警规则。
SLO是服务提供者与服务消费者之间所定义的一组协议,描述了对于服务的可用性、可靠性等方面的要求。基于SLO的告警是一种基于业务目标而非简单的指标阈值的告警方式,在实际中更贴近于真实的业务场景。
以下是基于Prometheus的SLO告警实战步骤:
-
定义SLO:首先需要定义服务水平指标(SLO),例如,某个系统的可用性要求为99.9%。这个SLO定义了系统的目标可用性水平。
-
计算目标指标:根据SLO,计算出目标指标的具体数值,例如,如果系统每天运行24小时,那么该系统每天最多允许有8.64秒的停机时间(即0.1% * 86,400秒 = 86.4秒)。这个目标指标将被用来确定告警规则中的阈值。
-
创建告警规则:使用Prometheus的规则语言(PromQL)创建告警规则。例如,下面的规则定义了一个告警,当目标指标大于等于目标值时触发:
- alert: ServiceUnavailable expr: 1 - (sum(rate(http_requests_total{status_code=~"5.."}[5m])) by (job) / sum(rate(http_requests_total[5m])) by (job)) > 0.999 for: 10m labels: severity: critical annotations: summary: "Service unavailable" -
在这个例子中,我们使用PromQL计算出服务不可用的比例,如果该比例大于等于0.001(即SLO的0.1%),就会触发告警。我们还设置了10分钟内连续满足条件后才触发告警,确保不会因为偶然误报而产生过多的告警。
-
创建报警接收器:创建报警接收器(receiver)来接收告警通知。例如,可以配置一个发送邮件的报警接收器:
receivers: - name: email-alerts email_configs: - to: admin@example.com from: alertmanager@example.com smarthost: smtp.example.com:587 auth_username: alertmanager auth_password: secret starttls_policy: Opportunistic -
在这个例子中,我们将告警发送到admin@example.com,并且使用smtp.example.com上的SMTP服务器进行邮件发送。需要提供用户名和密码以进行身份验证。
通过上述步骤,我们实现了基于Prometheus的SLO告警。当达到预设的SLO阈值时,系统将自动发送告警通知给管理员,帮助我们更及时地发现和解决问题,确保系统可用性和稳定性。
![linux学习[11]磁盘与文件系统(2):lsblkblkidpartedfdiskgdiskmkfs](https://img-blog.csdnimg.cn/f70ca8d5aab64e86a28ea065e3c78b01.png)