目标网址:豆瓣网
'https://movie.douban.com/subject/27605698/comments?status=P'
使用工具:python+selenium
首先,很简单的,我们得使用selenium的webdriver去打开网址,自动实现打开网页,并且翻页:
selenium环境确保搭建完毕(如果没有搭建好,公众号python乱炖回复:selenium)
那我们就开始吧!
我们的目标网址:
url = 'https://movie.douban.com/subject/27605698/comments?status=P'
首先将selenium的webdriver导入:
from selenium import webdriver
然后使用webdriver打开浏览器:
browser = webdriver.Chrome()
打开网址:
browser.get(url)
这样就简单的打开网址了。
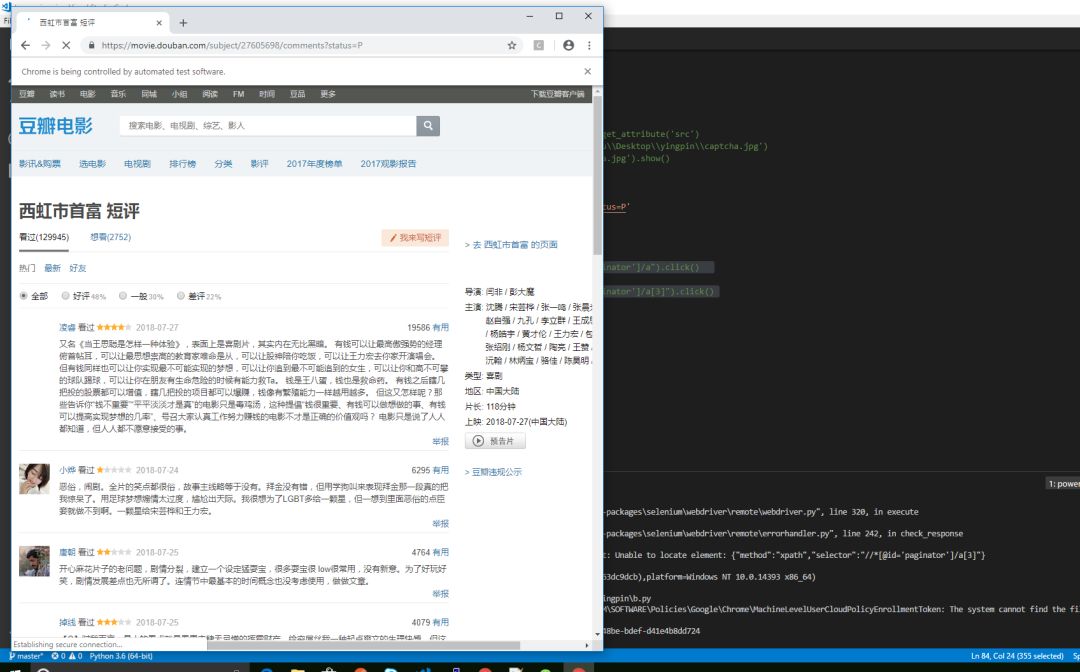
但是只能看到20条,如果想看到后面的,就必须进行翻页,这个时候,我们就需要进行元素定位了
我们打开网页,查看翻页元素的位置:
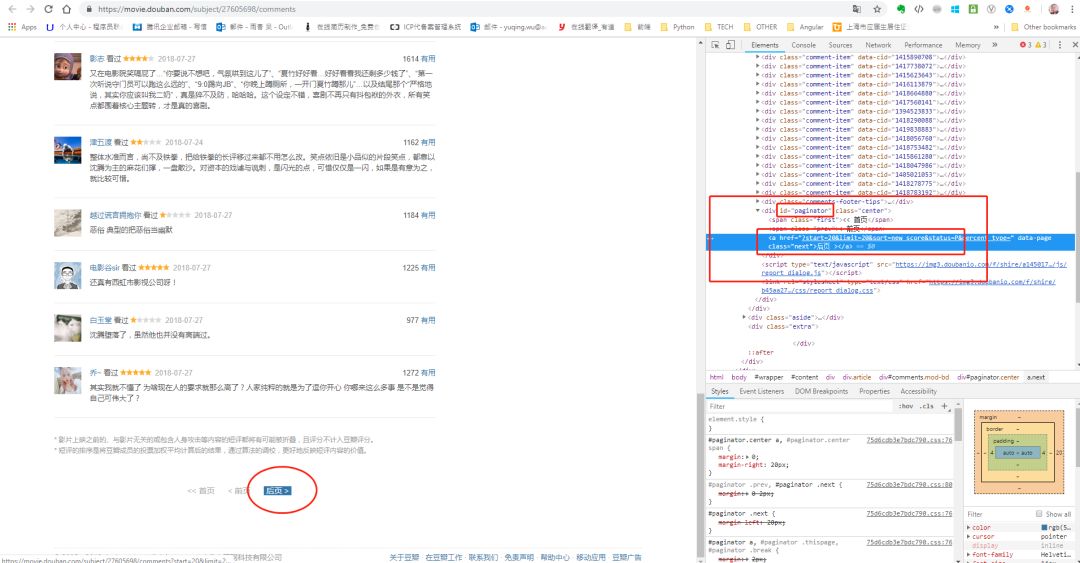
经过审查元素,我们发现,“后页”这个点击的其实是隶属于一个id=“paginator”的div标签里的a标签,所以我们可以使用简单的xpath来进行定位就可以了:
"//*[@id='paginator']/a"
先找到id=“paginator”,这样就可以定位到这个a标签了。
然后我们加入代码:
browser.find_element_by_xpath("//*[@id='paginator']/a").click()
(加个while循环,因为要翻多页)
但是我们发现操作结果,只操作了一次就停在第二页不动了,这是为什么呢?
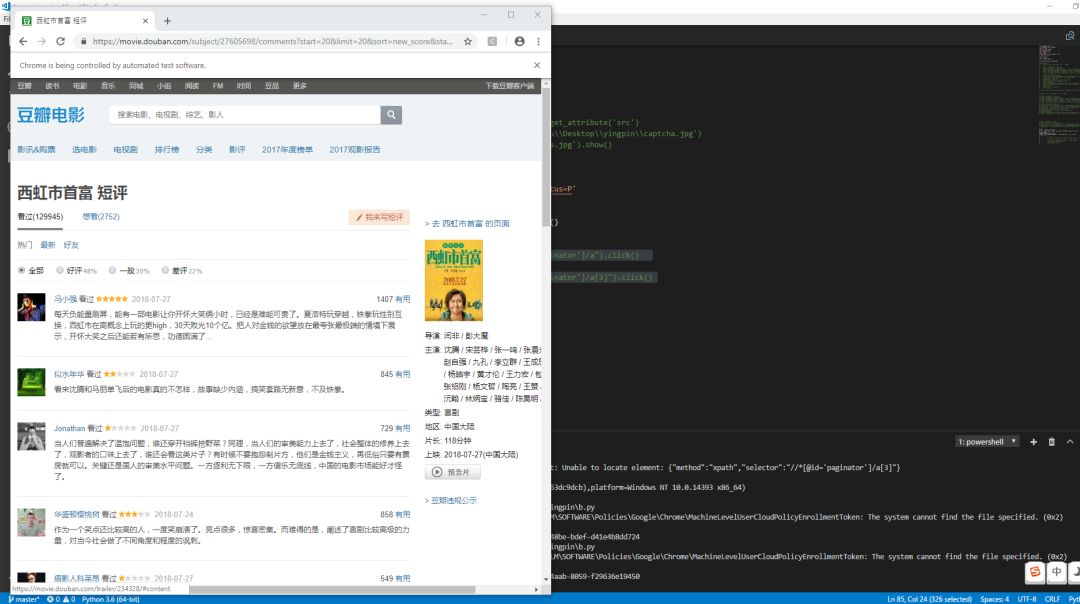
我们检查一下页面的元素:
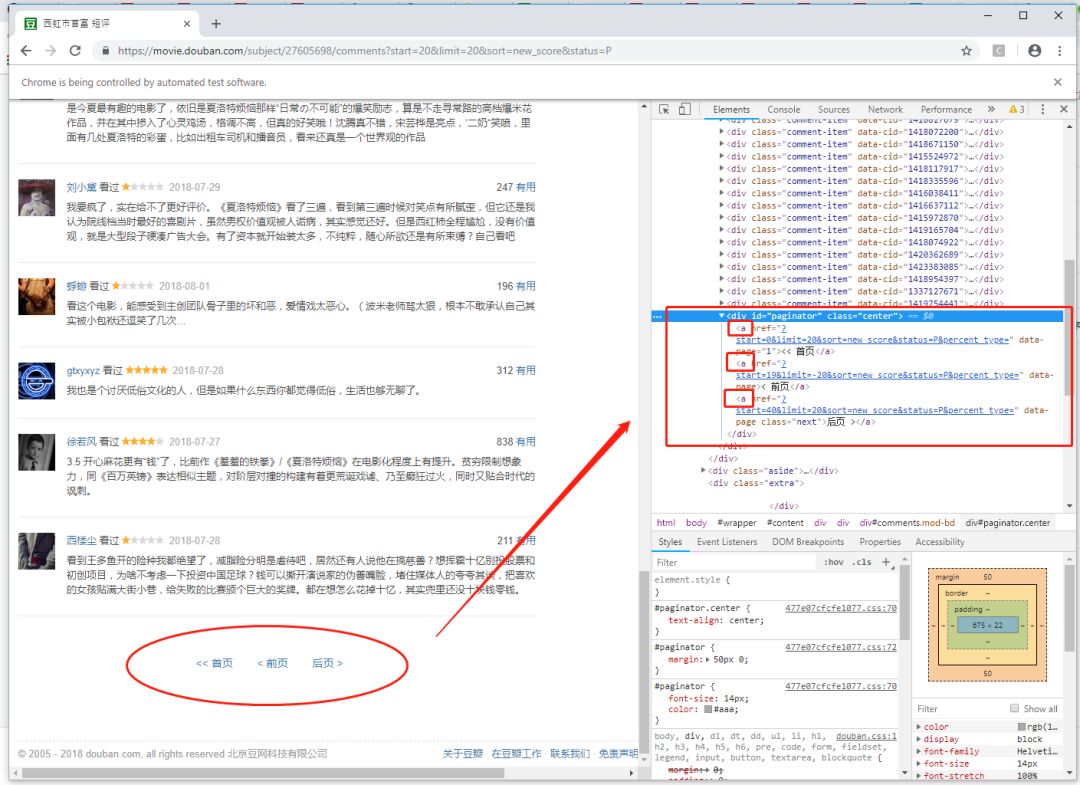
我们发现,这个div标签里竟然三个都变成的a标签,怪不得我们刚才的代码不管用了!
这个时候我们只需要取第三个标签,我们使用xpath取a的第三个元素a[3]就够啦:
browser.find_element_by_xpath("//*[@id='paginator']/a[3]").click()
这样和上面第一页的代码整合起来写就是:
i = 1
while True:
if i==1:
browser.find_element_by_xpath("//*[@id='paginator']/a").click()
else:
browser.find_element_by_xpath("//*[@id='paginator']/a[3]").click()
browser.implicitly_wait(10)
time.sleep(1) # 暂停1秒
i = i + 1
这样我们就能让页面翻到最后一页啦!
我们试试看!
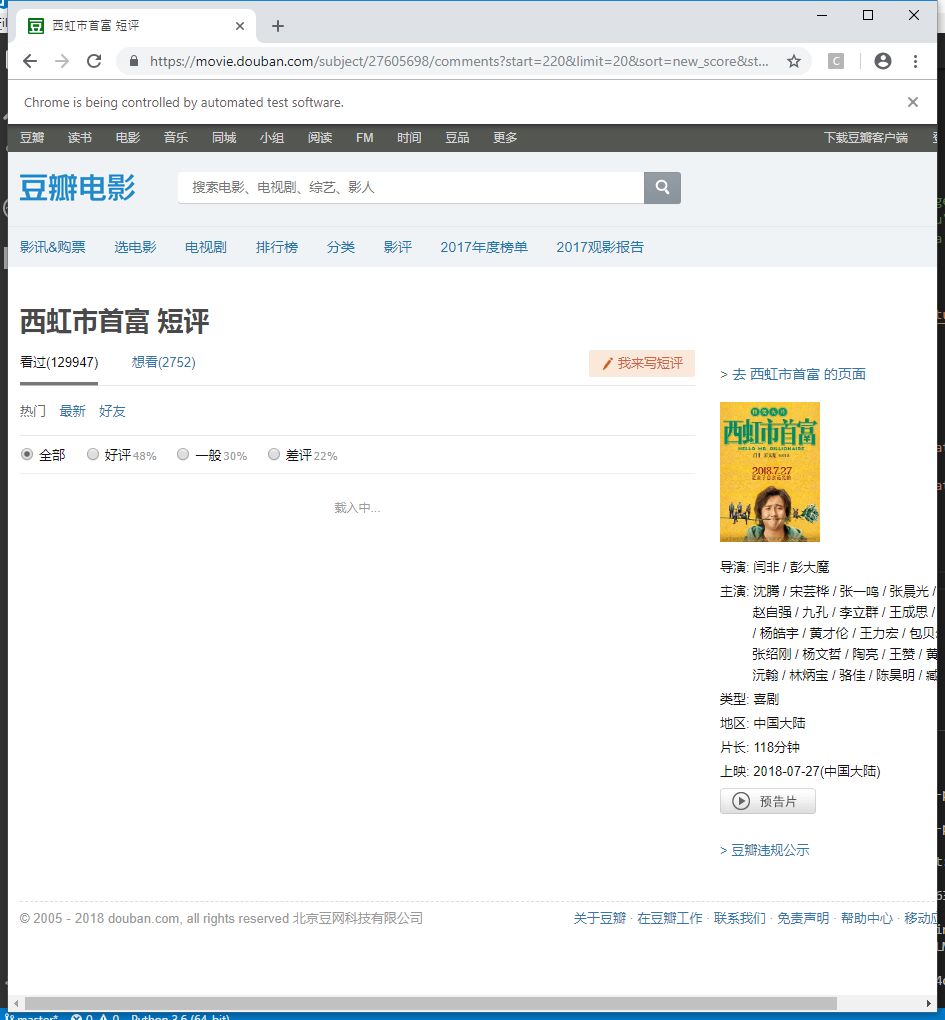
出问题了!
我们发现读取到11页的时候就死在那了,不能再往后跳了,到底是什么问题!
之后我就自己去翻豆瓣,结果发现也是一样的,看来不是代码的问题。
一段时间后......
一柱香后.......
一觉之后.........
发现问题了,原来是没登录导致的无法查看。
那就意味着我们就要开始自动登录豆瓣了哦!
首先打开登录页进行登录,登录完切换到评论页,获取评论。
登录的loginurl:https://www.douban.com/
loginurl='https://www.douban.com/'
browser = webdriver.Chrome()
browser.get(loginurl)
打开登录页之后我们需要输入用户名和密码,审查一下输入框的元素:
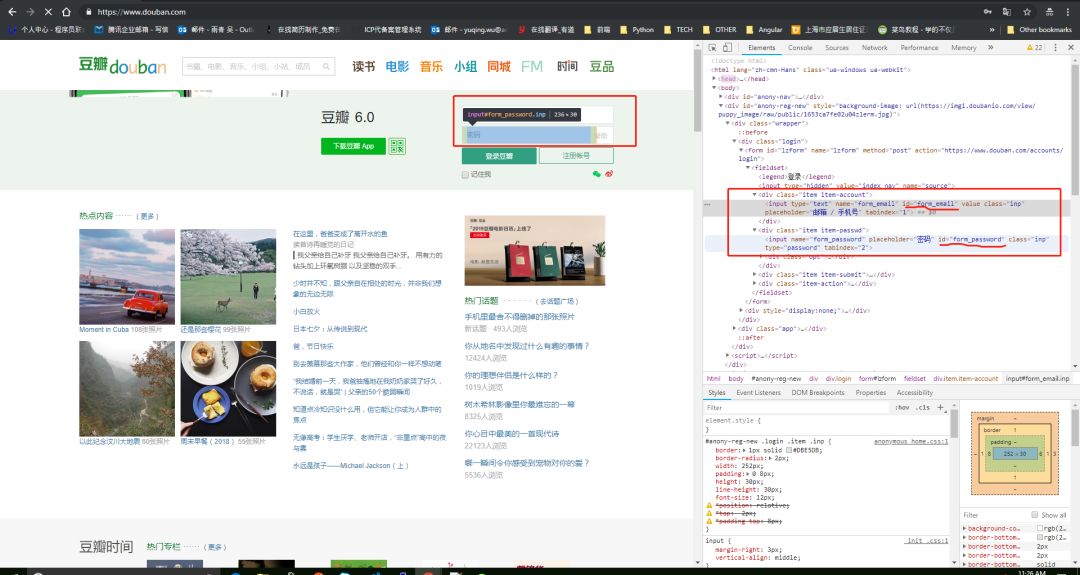
看到了元素的id之后我们就可以获取他们并且传值了:
# 获取用户名输入框,并先清空
browser.find_element_by_name('form_email').clear()
# 输入用户名
browser.find_element_by_name('form_email').send_keys(u'25xxxx@qq.com')
# 获取密码框,并清空
browser.find_element_by_name('form_password').clear()
# 输入密码
browser.find_element_by_name('form_password').send_keys(u'xxxxxx')
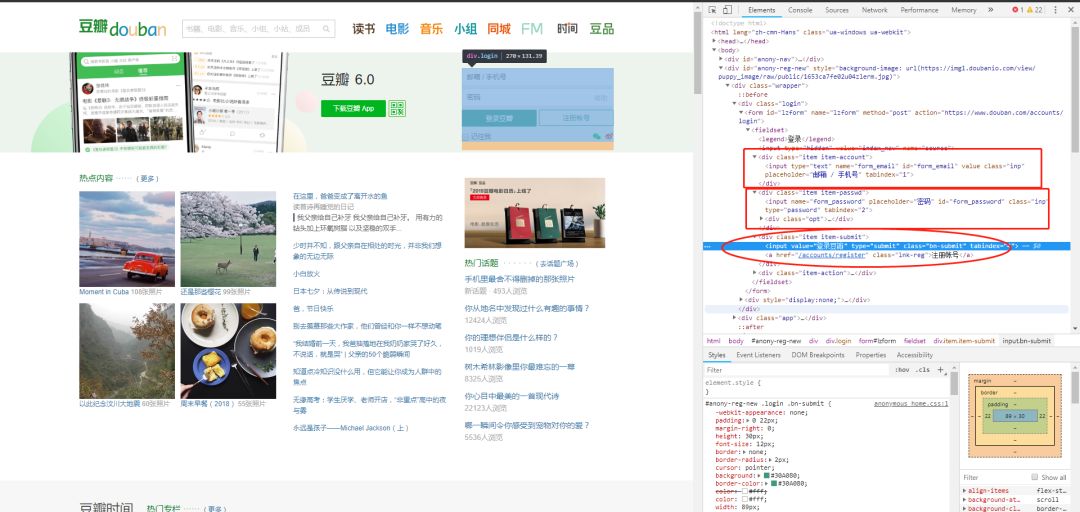
然后点击提交就可以了:
browser.find_element_by_css_selector('input[class="bn-submit"]').click()
但是我们发现,就这样点击提交是无法登陆的,因为它还会跳出一个验证码,必须要把这个验证码输进去才能登陆。
这就很烦了,先不管了,手动输入吧,后面有空再去识别这个验证码。
那我们就看着网页,在验证码的框输入验证码:
captcha_code = input('Input code:')
browser.find_element_by_id('captcha_field').send_keys(captcha_code)
这样就可以了。
这样我们就能顺利爬取所有的评论了,我们现在只需要把每个页面上的评论保存下来即可:
这里我们为了保证格式工整,我们把评论做成表的形式,可以借用一下pandas的DataFrame这样一个数据格式,之后再保存为csv,所以需要导入pandas。
那么第一步,去页面检索评论的元素样式:
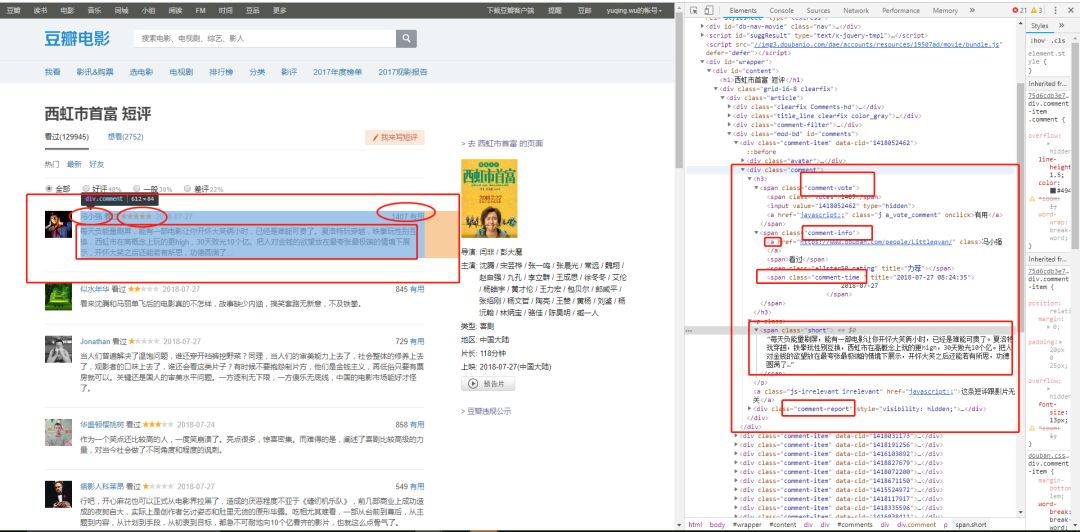
接下来我们提取内容了:
利用apply方法,将数据加入到DataFrame里。
AllComments = pd.DataFrame()
s = browser.find_elements_by_class_name('comment-item')
articles = pd.DataFrame(s,columns = ['web'])
articles['uesr'] = articles.web.apply(lambda x:x.find_element_by_tag_name('a').get_attribute('title'))
articles['comment'] = articles.web.apply(lambda x:x.find_element_by_class_name('short').text)
articles['star'] = articles.web.apply(lambda x:x.find_element_by_xpath("//*[@id='comments']/div[1]/div[2]/h3/span[2]/span[2]").get_attribute('title'))
articles['date'] = articles.web.apply(lambda x:x.find_element_by_class_name('comment-time').get_attribute('title'))
articles['vote'] = articles.web.apply(lambda x:np.int(x.find_element_by_class_name('votes').text))
del articles['web']
AllComments = pd.concat([AllComments,articles],axis = 0)
print ('The ' + str(i) + ' page finished!')
提取的时候要把它放到while循环里,保证每页都提取到。
提取完了之后,我们把最后的数据保存到csv里面:
result.to_csv('C:\\Users\\yuqing.wu\\Downloads\\yuqing.csv',index=False,header=False)
代码:
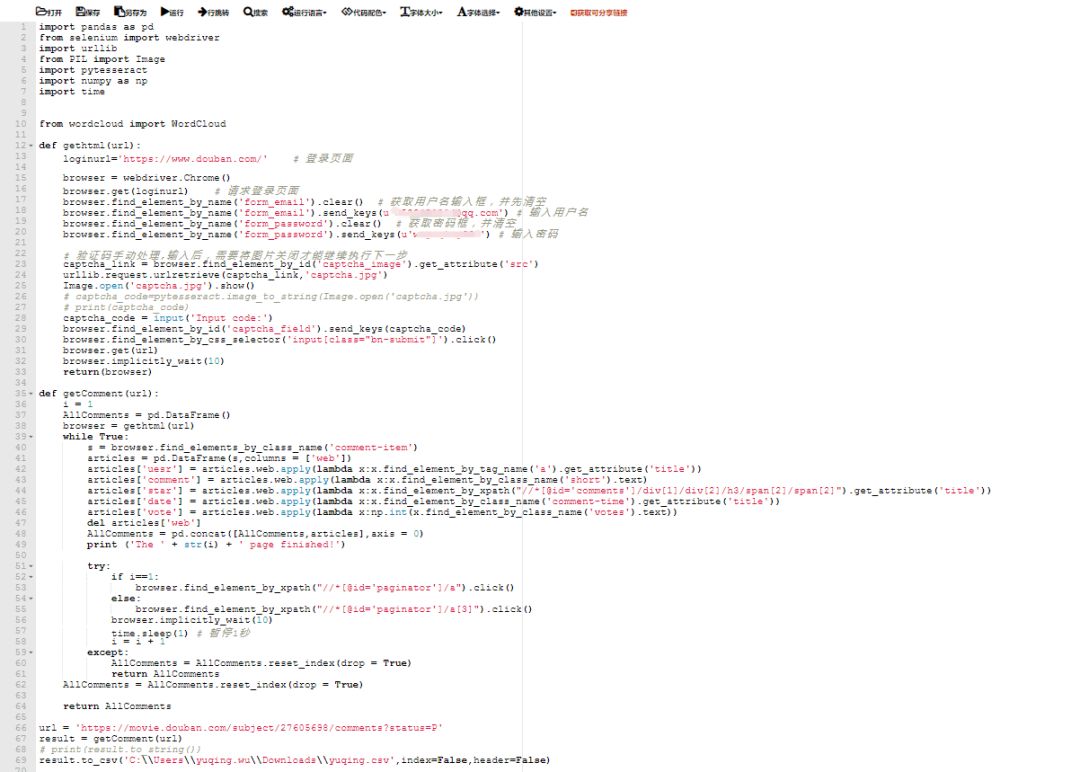
完整代码见阅读原文。

求关注!