目录
1.数据库约束
1.1 非空:not null
1.2 唯一:unique
1.3 默认值:default
1.4 列描述:comment
1.5 主键约束:primary key
1.6 外键约束
1.7 综合案例
2.插入查询结果
3.聚合函数
4.group by(分组查询)
1.数据库约束
关系型数据库的一个重要功能,就是需要保证数据的完整性,正确的数据~
可以通过人工的方式来观察确认数据的正确性,可以,但是不合适,这个事情可能会导致人的疏忽,把一些错误没检查出来。
约束,就是让数据库帮助程序员更好的检查数据是否正确。
1.1 非空:not null
create table student(id int not null);

1.2 唯一:unique
unique 的作用:规定这个值是唯一的,不能重复出现
create table student(id int unique);

数据库如何判定,当前这一条记录是重复的呢?
数据库会先查找,再插入,但是加上约束之后,数据库的执行过程可能就变了,很可能执行时间、执行效率就受到很大影响,但是这里的代价再大,也比你手工检查一遍代价小很多,而且准确率也高很多。
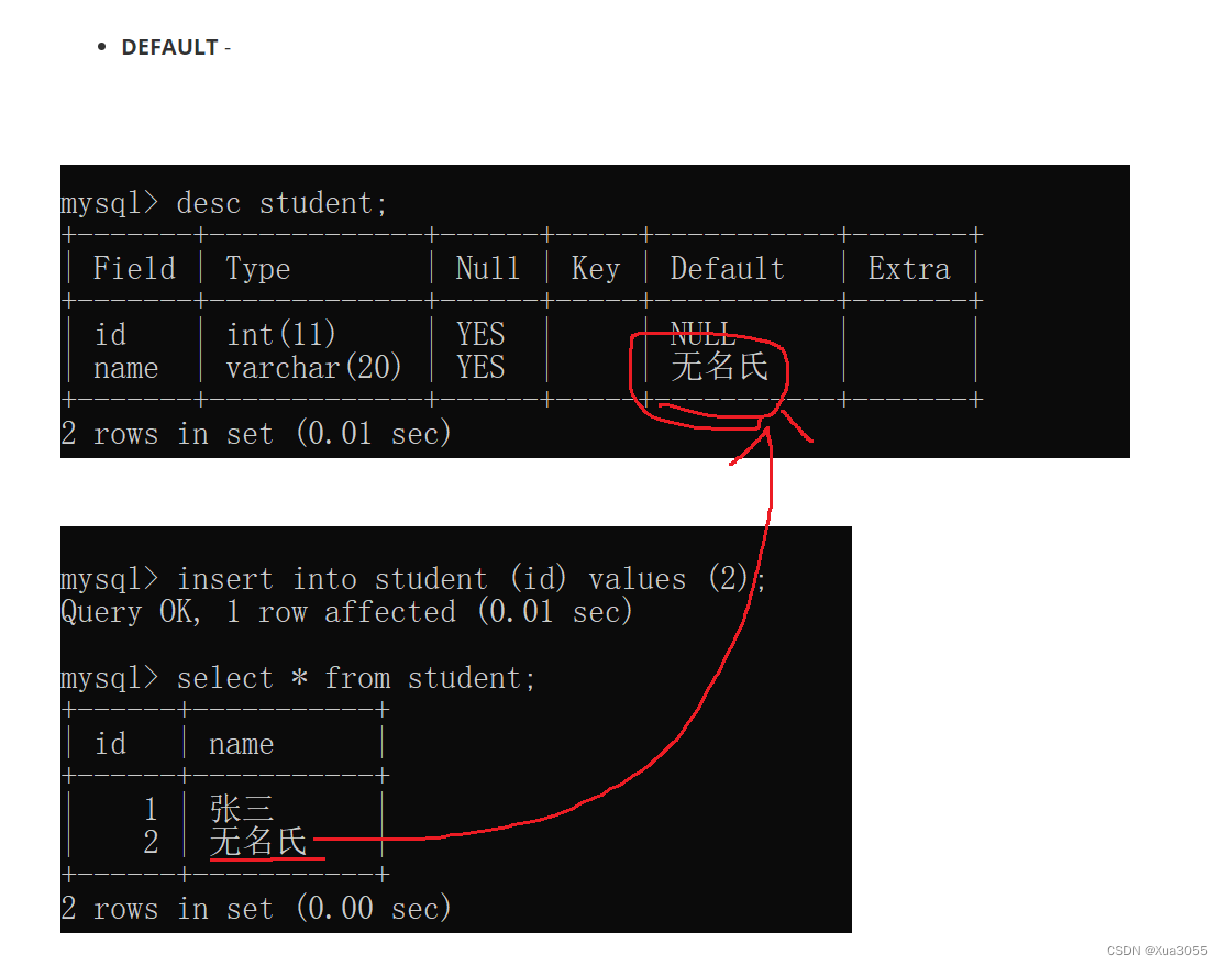
1.3 默认值:default
和前面的约束条件一样,只需要在添加的元素后加上即可
默认值的生效:数据在插入的时候不给该字段赋值,就使用默认值
create table student(id int,name varchar(20) default '无名氏');
1.4 列描述:comment
没有实际含义,专门用来描述字段,会根据表创建语句保存,用来给程序员或DBA 来进行了解。类似于注释。

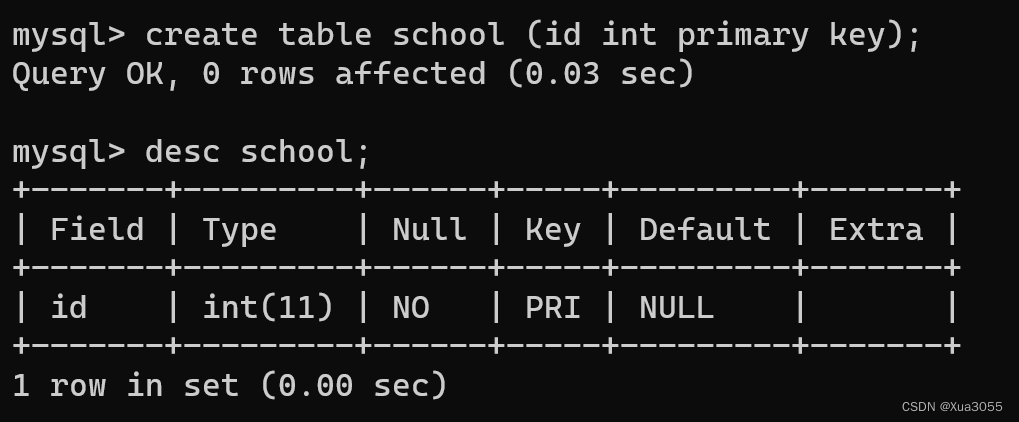
1.5 主键约束:primary key
实际开发中,大部分的表,一般都会带有一个主键,主键往往是一个整数表示的id,比如int id
主键约束,就是同时拥有not null + unique的约束
主键同样是在插入记录的时候,需要先查询,再插入
正因为主键和unique都有先查询的过程,mysql就会默认给primary key和unique这样的列,自动添加索引,来提高查询的速度~
1.在MySQL中,一个表里只能有一个主键,不能有多个
2.虽然主键不能有多个,MySQL允许把多个列放到一起共同作为一个主键(联合主键)
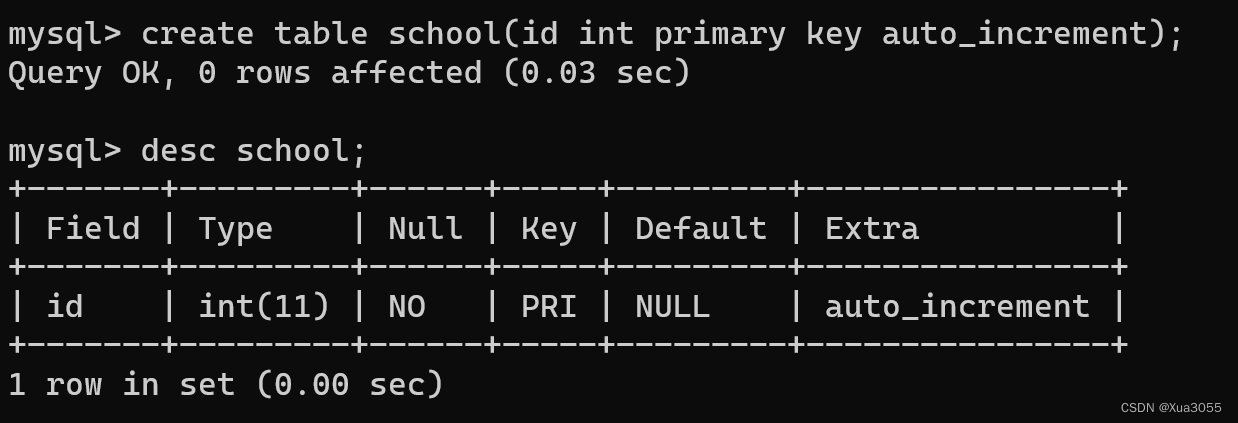
3.自增主键:
create table student(id int primary key auto_increment);
Extra中有auto_increment代表这个就是自增主键
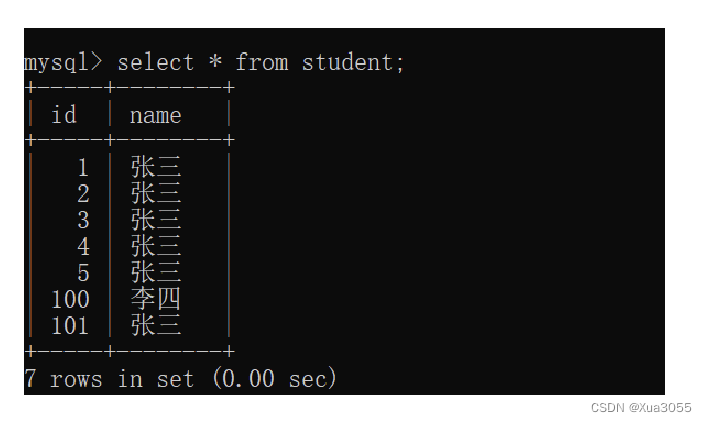
同时插入id的时候,可以手动指定,也可以不手动指定(null),后者会有mysql自动生成
同时自增主键,并不会重复利用中间的空隙,是依照之前的最大值来往后累加的
1.6 外键约束
外键约束是约束中较难的,因为涉及到两个表的约束。什么是外键约束呢?
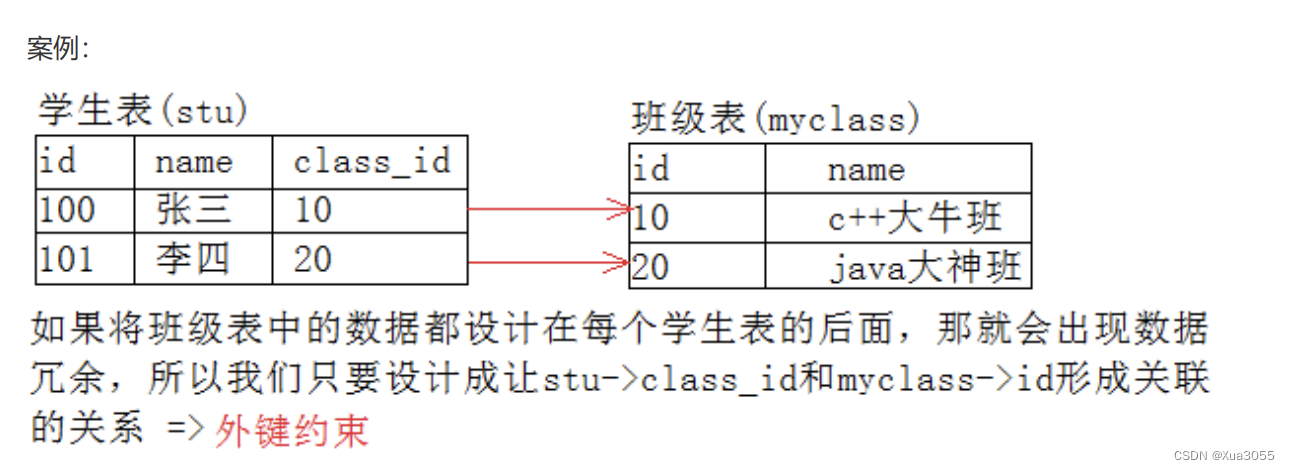
表1记录了学生信息,表2记录了班级信息,但是要保证表2的班级信息和表1的学生信息对得上,就需要外键来约束,防止某个学生出现在不存在的班级的情况出现。
要想完成这样一个外键约束,该怎么做呢?
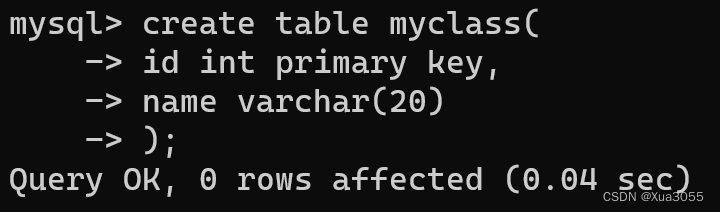
先创建父表:
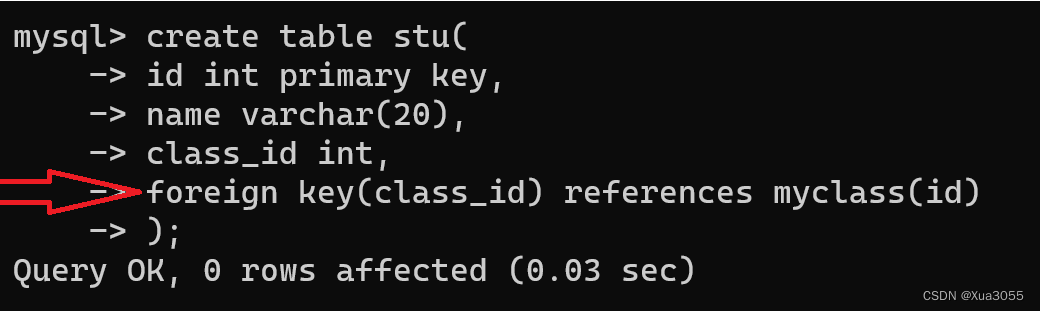
再创建子表:
注意这条语句,这就是创建外键的语句,基本格式为:
foreign key (子表中需要被约束的元素) references 父表(父表中对应的列);在这个案例中,代表着stu中的class_id要在myclass表中的id列中存在!
此时如果只有两个班级,那么插入30班的时候就会报错!
需要注意的点:
1.若要创建外键,那么父表中对应的列要有主键或者unique约束
2.当我们删除被外键约束的元素时,会提示删除失败,只有将父表和子表同时删除才能删除这个元素。

如何理解外键约束:
首先我们承认,这个世界是数据很多都是相关性的。 理论上,上面的例子,我们不创建外键约束,就正常建立学生表,以及班级表,该有的字段我们都有。 此时,在实际使用的时候,可能会出现什么问题? 有没有可能插入的学生信息中有具体的班级,但是该班级却没有在班级表中? 比如学校只开了1班,但是在上课的学生里面竟然有2班的学生(这个班目前并不存在),这很明显是有问题的。 因为此时两张表在业务上是有相关性的,但是在业务上没有建立约束关系,那么就可能出现问题。 解决方案就是通过外键完成的。建立外键的本质其实就是把相关性交给mysql去审核了,提前告诉mysql表之间的约束关系,那么当用户插入不符合业务逻辑的数据的时候,mysql不允许你插入。
1.7 综合案例
- 有一个商店的数据,记录客户及购物情况,有以下三个表组成:
- 商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供应商 provider)
- 客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证card_id)
- 购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
- 要求需要有:
- 每个表的主外键
- 客户的姓名不能为空值
- 邮箱不能重复
- 客户的性别(男,女)
create datebase mall;use mall;create table goods(goods_id int primary key auto_increment,goods_name varchar(32),unitprice int,category varchar(12),provider varchar(64) );create table customer(customer_id int primary key auto_increment,name varchar(32),address varchar(256),email varchar(64) unique key,sex enum('男','女') not null,card_id char(18) unique key );create tablepurchase(order_id int primary key auto_increment,customer_id int,goods_id int,nums int,foreign key (customer_id) references customer(customer_id),foreign key (goods_id) references goods(goods_id) );
2.插入查询结果
在SQL中,还可以把查询的结果,插入到另一个表中~
insert into (student1) select * from student2;在这个例子中,就是把student2插入到了student1中
同时要求student2和student1 列数和列的类型要匹配~
3.聚合函数
聚合查询本质上是在行与行之间进行运算,通常我们用SQL中的内置函数来完成:
同时这些操作都是针对某个列的所有行来进行运算的
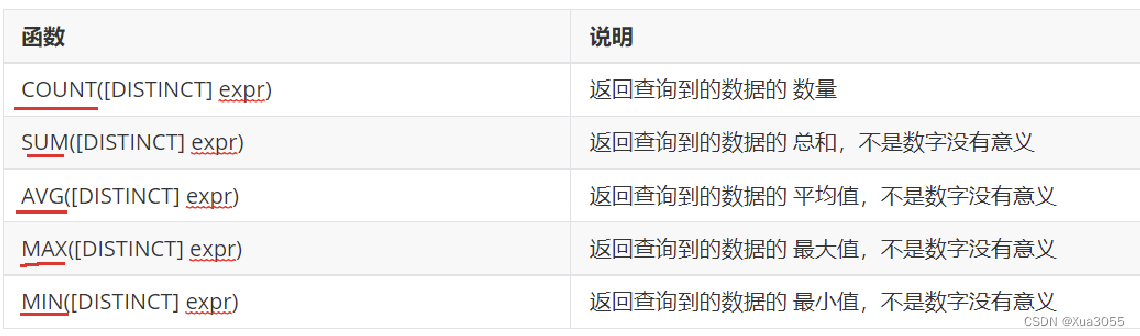
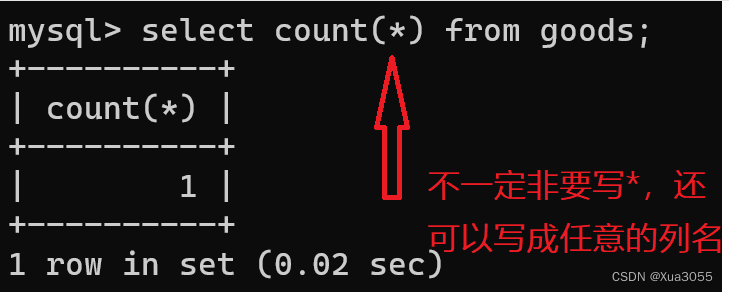
eg:count (返回查询到的数据的数量)
select count(*) from exam_result;这个操作就相当于先进行select*,然后针对返回的结果,再进行count运算,求结果集合的行数
4.group by(分组查询)
在select中使用group by 子句可以对指定列进行分组查询
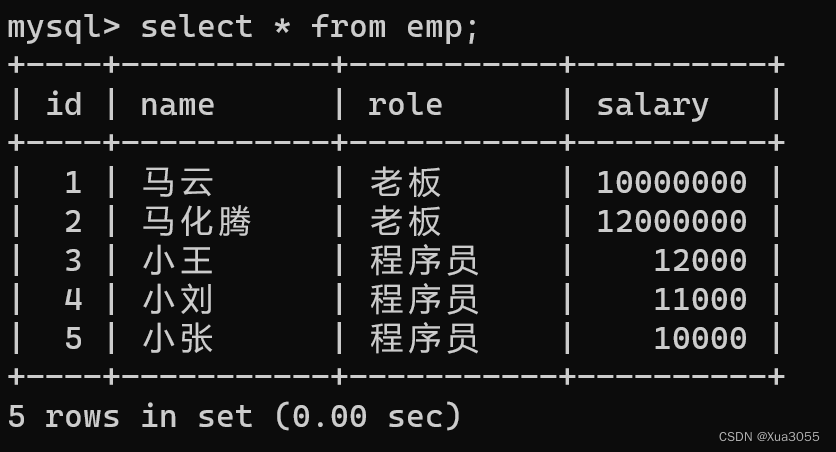
现在有这样的一群数据:
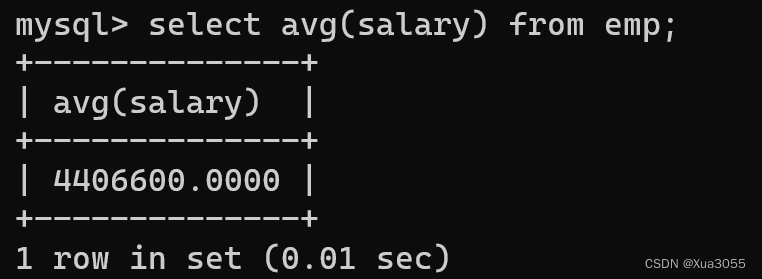
现在要求算平均工资:
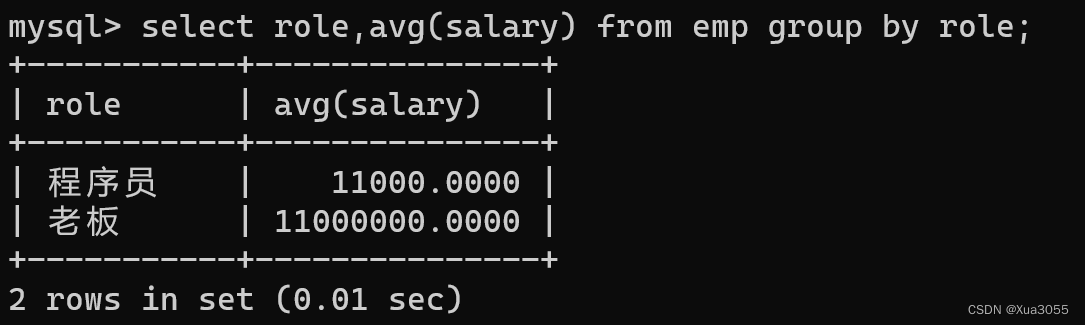
但是我们可以发现,所有人的平均工资都被平均下来了,参考价值不大,我们需要的是程序员的平均工资,这个时候我们就需要用到group by来对role这一个条件进行分类:
这样我们就能得到程序员和老板分别的平均工资,这也就是group by 的用法~
把某一列,相同的行分成一组,再进行下一步计算,并且group by 默认是升序排序。
having和group by配合使用 对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
本章完~