目录
什么是序列化和反序列化?
序列化
反序列化
为什么要序列化?
序列化的主要应用场景
MapReduce实现序列化
自定义bean对象实现Writable接口
1.实现Writable接口
2.无参构造
3.重写序列化方法
4.重写反序列化方法
5.顺序一致
6.重写toString
7.实现Comparable接口
MapReduce自定义序列化案例
案例
解决思路
Map阶段
Reduce阶段
Bean
Coding
1、编写Bean
2、编写Mapper类
3、编写Reducer类
4、编写Runner类
运行结果
断点设置技巧
什么是序列化和反序列化?
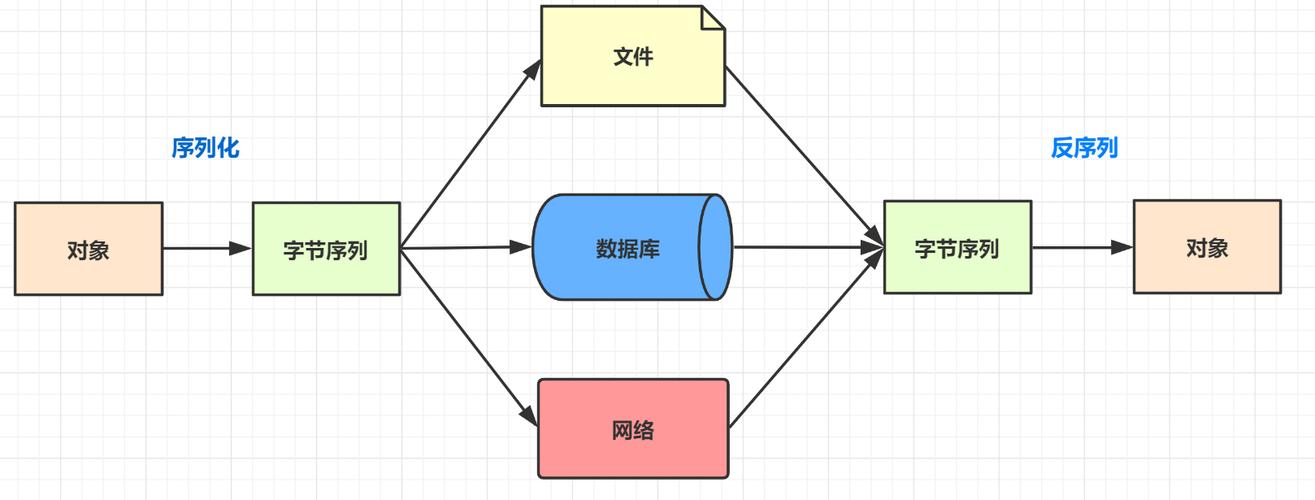
序列化
序列化是将对象的状态信息转化为可以存储或传输的形式的过程,通常指将对象在内存中的状态信息转换为可以被存储在外部介质上的二进制流或其他格式的数据,以便在需要时可以重新读取和还原对象的状态信息。
反序列化
反序列化则是将存储或传输的数据重新装配成对象的过程。
为什么要序列化?
因为MapReduce是一个分布式计算框架,需要将数据在各个节点之间传输。而网络传输必须是二进制数据,所以不同节点之间的数据传输就需要将数据转换为二进制流进行传输,因此需要进行序列化。
序列化的主要应用场景
- 对象的持久化:将对象保存到磁盘或数据库中,以便在需要时可以重新读取和还原对象的状态信息。
- 远程方法调用(RPC):将对象转换为可以在网络上传输的格式,以便在不同的进程或计算机之间进行远程通信。

- 分布式计算:将对象转换为可以在分布式计算环境中进行传输和计算的格式,以便在不同的计算节点之间进行数据传输和计算。
MapReduce实现序列化
在实际开发中,基本的序列化类型往往不能满足实际开发需求,比如在Hadoop内部传递一个bean对象,Hadoop的基本序列化类型是没有这种类型的,所以这就需要我们自己去构造该序列化类型。
自定义bean对象实现Writable接口
Writable接口是Hadoop序列化框架的核心接口,用户可以通过实现该接口来实现自定义的序列化类型。Writable接口的实现类包括IntWritable、DoubleWritable、Text等,我们可以通过继承Writable接口来实现自定义的序列化类。
1.实现Writable接口
2.无参构造
反序列化需要反射调用无参构造函数,所以必须有无参构造
3.重写序列化方法
4.重写反序列化方法
5.顺序一致
序列化和反序列化的顺序必须完全一致,也就是说序列化的顺序为(a,b,c),那么反序列化的顺序也应该为(a,b,c)
6.重写toString
如果需要把结果显示在文件中,需要重写toString,不然对象输出就是一个地址值
7.实现Comparable接口
如果需要将我们自定义的bean放在key中传输,就必须重写Comparable接口,因为MapReduce框架中的Shuffle过程要求key必须能够排序。
MapReduce自定义序列化案例
案例
统计每一个用户耗费的总上行流量、总下行流量、总流量。
输入案例:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200输入格式:
时间戳、电话号码、基站的物理地址、访问网址的ip、网站域名、数据包、接包数、上行/传流量、下行/载流量、响应码
输出格式:
手机号码 上行流量 下行流量 总流量
解决思路
Map阶段
- 读取一行数据,切分字段
- 获取我们需要的值(手机号、上行流和下行流量)
- 以手机号为key,bean对象为value输出(即context.write(手机号,bean))
Map<KRYIN,VALUEIN,KEYOUT,VALUEOUT>
- KEYIN:map阶段key是文本偏移量,不需要设置。
- VALUEIN:同样value是文本中一行的数据,我们不需要设置。
- KEYOUT:我们希望对相同的手机号的流量进行累加,所以KEYOUT应该是手机号。
- VALUEOUT:map阶段我们希望输出一个手机号(KEY)对应三个值(上行流量、下行流量和总流量)。
Reduce阶段
累加上行流量和下行总流量得到总流量(合并相同手机号的上行流量和下行流量,即<手机号,bean1+bean2+...>)
- KEYIN:reduce阶段KEYIN就是map阶段的输出KEYOUT,上面设计好了我们就不需要设置了。
- VALUEIN:同样VALUEIN就是map阶段的输出VALUEOUT,我们不需要设置。
- KEYOUT:输出手机号。
- VALUEOUT:输出该手机号对应的bean对象(需要重写toString)。
Bean
我们这里的Bean是作为输出的Value,所以不需要继承Comparable接口,仅仅需要注意是就是重写toString方法。
Coding
1、编写Bean
- 我们这里的Bean不需要继承Comparable接口,因为它不作为Key,我们这里的Key是手机号,是一个字符串,它是Text序列化类型,在Hadoop中,它已经继承了Comparable接口。
- 下面的Bean中,我们重载了setSumFlow方法,因为sumFlow并不是原始数据中存在的,而是我们我们通过获取upFlow和downFlow计算和得来的。
- 我们重写了toString方法来满足输出格式的要求。
import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;/*** 1.实现Writable接口* 2.重写序列化接口和反序列化接口* 3.重写无参构造* 4.重写toString方法*/
public class FlowBean implements Writable {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量//3.无参构造public FlowBean(){}//2.1序列化方法@Overridepublic void write(DataOutput dataOutput) throws IOException {//序列化顺序无所谓,但是必须和反序列化顺序一致dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);dataOutput.writeLong(sumFlow);}//2.2反序列化方法@Overridepublic void readFields(DataInput dataInput) throws IOException {this.upFlow = dataInput.readLong();this.downFlow = dataInput.readLong();this.sumFlow = dataInput.readLong();}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}//重载setSumFlow方法public void setSumFlow() {this.sumFlow = this.upFlow+this.downFlow;}@Overridepublic String toString() {return upFlow + "\t" + downFlow + "\t" + sumFlow;}
}
2、编写Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {//尽可能节省内存,不要每次读取一行就新建对象private String phone; //手机号private long upFlow; //上行流量private long downFlow; //下行流量private Text outKey = new Text();private FlowBean outValue = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1.获取一行//1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200String line = value.toString();//2.切割String[] words = StringUtils.split(line,'\t');//3.获取想要的数据phone = words[1];upFlow = Long.parseLong(words[words.length-3]);downFlow = Long.parseLong(words[words.length-2]);//4.封装outKey.set(phone);outValue.setUpFlow(upFlow);outValue.setDownFlow(downFlow);outValue.setSumFlow();//5.写出context.write(outKey,outValue);}}
3、编写Reducer类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {private FlowBean outValue = new FlowBean();//reduce方法每次只计算相同的key,所以totalUp和totalDown必须放在reduce方法内部,否则会把所有key的上行流量和下行流量加在一起@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {//1.遍历集合,累加值long totalUp = 0; //上行流量long totalDown = 0; //下行流量for (FlowBean value : values) {totalUp += value.getUpFlow();totalDown += value.getDownFlow();}//2.封装outKey,outValueoutValue.setUpFlow(totalUp);outValue.setDownFlow(totalDown);outValue.setSumFlow();//3. 写出context.write(key,outValue);}
}
4、编写Runner类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;public class FlowRunner extends Configured implements Tool {public static void main(String[] args) throws Exception {ToolRunner.run(new Configuration(),new FlowRunner(),args);}@Overridepublic int run(String[] args) throws Exception {//1.获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf, "flow compu");//2.配置jar包路径job.setJarByClass(FlowRunner.class);//3.关联mapper和reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);//4.设置map、reduce输出的k、v类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//5.设置数据输入的路径FileInputFormat.setInputPaths(job,new Path("D:\\MapReduce_Data_Test\\writable\\input1"));//6.设置输出路径-输出目录不可存在FileOutputFormat.setOutputPath(job,new Path("D:\\MapReduce_Data_Test\\writable\\output1"));//7.提交jobreturn job.waitForCompletion(true) ? 0 : 1;//verbose:是否监控并打印job的信息}
}
运行结果
计算正确 !

断点设置技巧
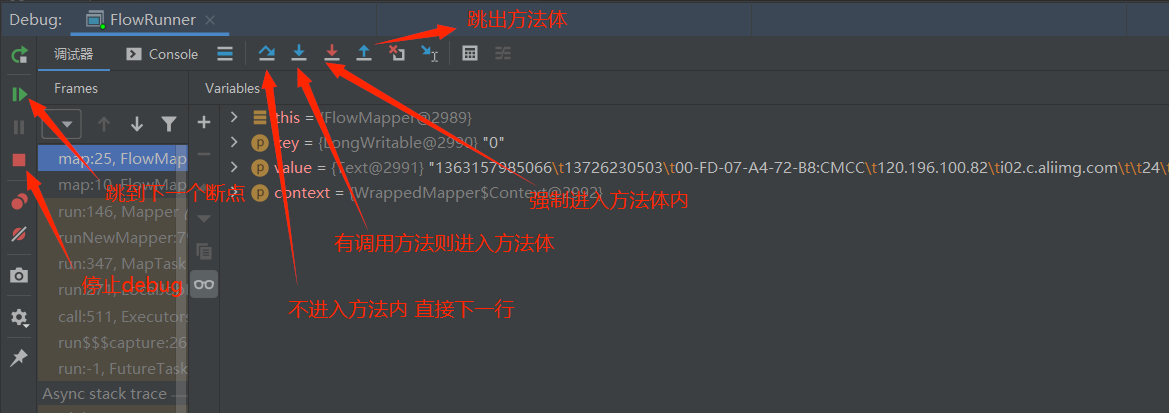
调试MapReduce程序的时候,我们一般把断点设置在map和reduce方法内部。