一、分桶表
1.1分桶表的概念
分桶表也叫做桶表,源自建表语法中bucket单词。是一种用于==优化查询==而设计的表类型。该功能可以让数据分解为若干个部分易于管理。
在分桶时,我们要指定==根据哪个字段将数据分为几桶(几个部分)==。默认规则是:Bucket number = hash_function(bucketing_column) mod num_buckets。
id
10
11
12
算法:哈希求余,分桶字段(key)求hash值 => 10 11 12
(每个字段都有一个hash值,数字型就是它本身;字符串会hash算法求出一个数字)
(接着hash求余)
(字段完全相同的,一定在同一个筒中)
10 % 3 = 1 => 编号为1号桶
11 % 3 = 2 => 编号为2的桶
12 % 3 = 0 => 编号为0的桶
1亿条数据 => 10个桶 => 1000万条数据
意义:① 优化手段,比分区更加精细的划分,但是数据平均 ② 适合数据抽样
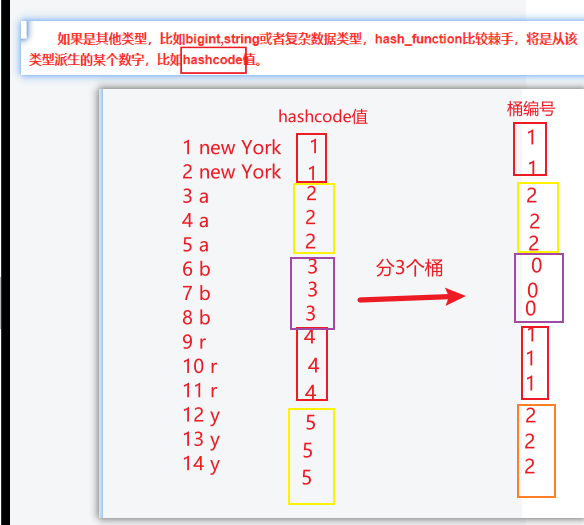
可以发现桶编号相同的数据会被分到同一个桶当中。hash_function取决于分桶字段bucketing_column的类型:
如果是int类型,hash_function(int) == int;
如果是其他类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。
1.2 分桶表的创建

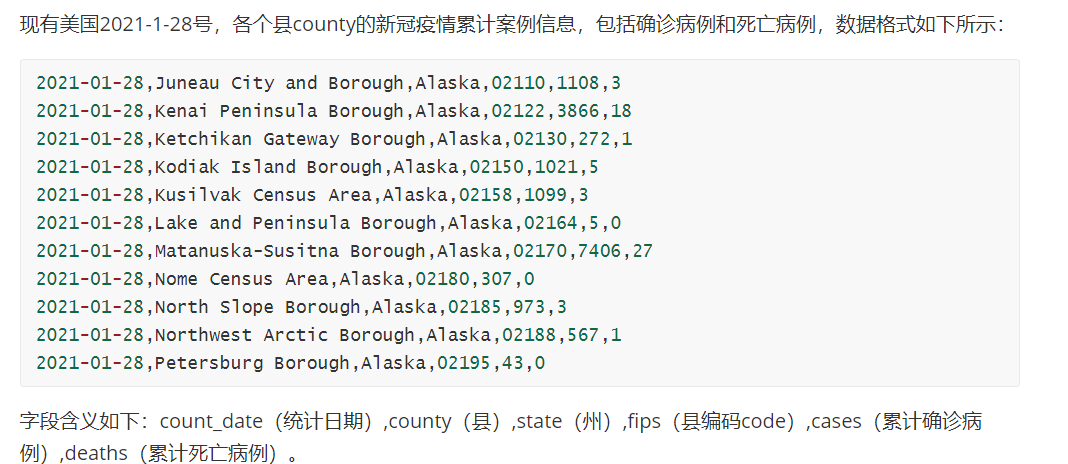
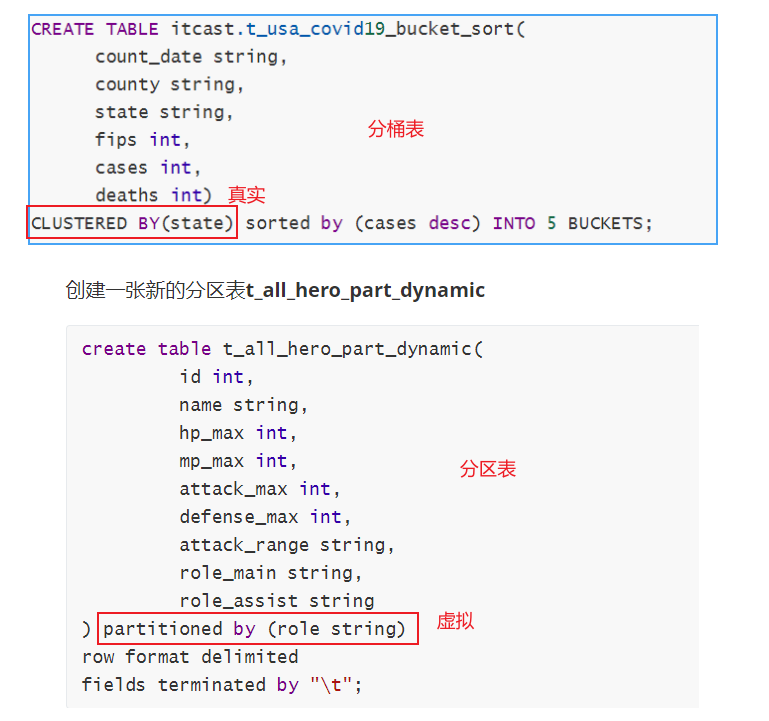
1.3分桶表的使用好处
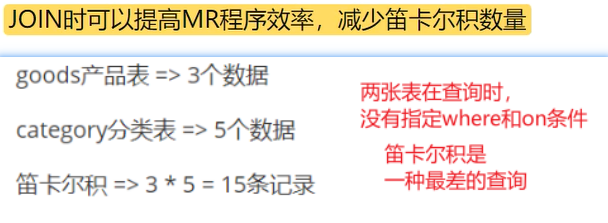
和非分桶表相比,分桶表的使用好处有以下几点:
① 优化手段,比分区更加精细的划分,但是数据平均 ② 适合数据抽样
1、==基于分桶字段查询时,减少全表扫描==
--基于分桶字段state查询来自于New York州的数据
--不再需要进行全表扫描过滤
--根据分桶的规则hash_function(New York) mod 5计算出分桶编号
--查询指定分桶里面的数据 就可以找出结果 此时是分桶扫描而不是全表扫描
select * from t_usa_covid19_bucket where state="New York";
2、==分桶表数据进行抽样==
1亿 => 10个桶 => 1g个桶进行抽样
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
二、总结
Hive分区表与分桶表区别:
1.语法不同,分区字段必须是虚拟的,分桶字段必须是实际存在的。
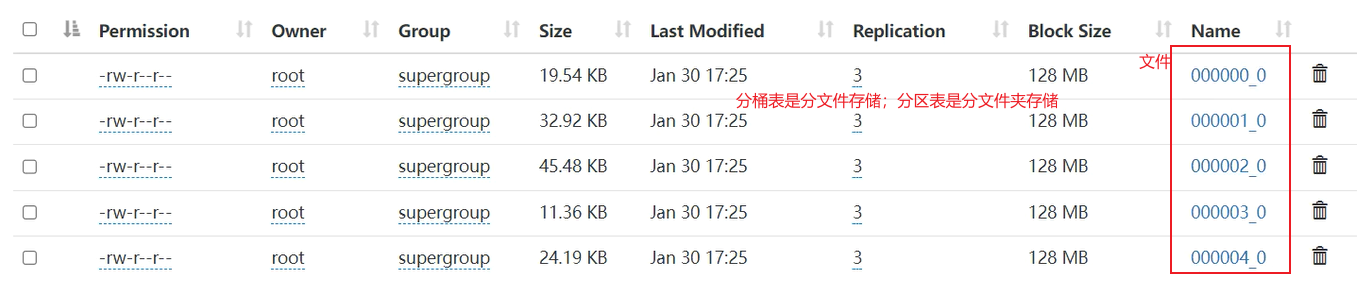
2.底层表现形式不同,分区是把数据集分文件夹存储,分桶是把数据集分文件存储。
3.分区表往往是能判断出数据分配在哪个区中
分桶表基于哈希求余,很难估算出数据具体分配在哪个桶中
4.分桶表相对于分区,是更加细粒度的划分
应用场景:
分区为了避免全表扫描,加快查询速度,分区裁剪
分桶虽然也有避免全表扫描,加快查询速度,还可以进行抽样查询
相同点:都是优化手段,都是建表可选操作。
在实际工作中,分区表相对来说使用更加多一些!!!