Go语言 解析Excel csv/xls/xlsx格式
- 解析不同格式的excel,并统一返回值
- 解析csv
- 解析xls
- 解析xlsx
- 代码块
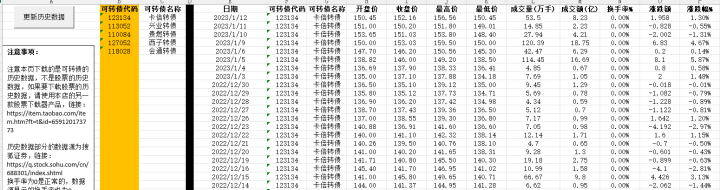
解析不同格式的excel,并统一返回值
解析csv
相关包:“encoding/csv”
解析xls
相关包:“github.com/extrame/xls”
解析xlsx
相关包:“github.com/tealeg/xlsx”
代码块
package utilsimport ("encoding/csv""fmt""os""strings""github.com/extrame/xls""github.com/forging2012/gogb2312""github.com/tealeg/xlsx"
)func ReadCsv(file_path string) (res [][]string) {file, err := os.Open(file_path)if err != nil {Logger.Errorf("open_err:", err)return}defer file.Close()// 初始化csv-readerreader := csv.NewReader(file)// 设置返回记录中每行数据期望的字段数,-1 表示返回所有字段reader.FieldsPerRecord = -1// 允许懒引号(忘记遇到哪个问题才加的这行)reader.LazyQuotes = true// 返回csv中的所有内容record, read_err := reader.ReadAll()if read_err != nil {Logger.Errorf("read_err:", read_err)return}for i, value := range record {record_utf := valueif !ValidUTF8([]byte(record_utf)) {record_utf, _, _, _ = gogb2312.ConvertGB2312String(record_utf)}record_utf = strings.TrimSpace(record_utf)record[i] = record_utf}return record
}func ReadXls(file_path string) (res [][]string) {if xlFile, err := xls.Open(file_path, "utf-8"); err == nil {fmt.Println(xlFile.Author)//第一个sheetsheet := xlFile.GetSheet(0)if sheet.MaxRow != 0 {temp := make([][]string, sheet.MaxRow)for i := 0; i < int(sheet.MaxRow); i++ {row := sheet.Row(i)data := make([]string, 0)if row.LastCol() > 0 {for j := 0; j < row.LastCol(); j++ {col := row.Col(j)data = append(data, col)}temp[i] = data}}res = append(res, temp...)}} else {Logger.Errorf("open_err:", err)}return res
}func ReadXlsx(file_path string) (res [][]string) {if xlFile, err := xlsx.OpenFile(file_path); err == nil {for index, sheet := range xlFile.Sheets {//第一个sheetif index == 0 {temp := make([][]string, len(sheet.Rows))for k, row := range sheet.Rows {var data []stringfor _, cell := range row.Cells {data = append(data, cell.Value)}temp[k] = data}res = append(res, temp...)}}} else {Logger.Errorf("open_err:", err)}return res
}// 校验中文编码
func ValidUTF8(buf []byte) bool {nBytes := 0for i := 0; i < len(buf); i++ {if nBytes == 0 {if (buf[i] & 0x80) != 0 { //与操作之后不为0,说明首位为1for (buf[i] & 0x80) != 0 {buf[i] <<= 1 //左移一位nBytes++ //记录字符共占几个字节}if nBytes < 2 || nBytes > 6 { //因为UTF8编码单字符最多不超过6个字节return false}nBytes-- //减掉首字节的一个计数}} else { //处理多字节字符if buf[i]&0xc0 != 0x80 { //判断多字节后面的字节是否是10开头return false}nBytes--}}return nBytes == 0
}