目录
前言
你好,认识一下,我是树
二叉树与二叉排序树
二叉排序树特点
为什么说二叉排序树查询效率要高于链表呢?
元素的类型
比较器
手写二叉排序树
定义一棵二叉树
增加元素
查询元素
修改元素
删除元素
遍历二叉树
重写toString
二叉排序树的极端情况
平衡二叉树
红黑树
保证平衡
红黑树的规则
红黑树的应用
散列表
向散列表中存数据
hashCode()方法特点
链表的产生原因
链表存在的问题
数组的扩容
结语
前言
学习是一个渐进的过程,如果还没看过我前面写的有关数据结构的文章可以先去看完再回来看这篇,在写这篇之前,我已经预见到了这篇博客会比较长,而且概念性的东西会比较多,如果你对树真的有兴趣,想要一看究竟,那么欢迎你继续读下去,如果你只是临时起意,劝你三思。树在各个语言领域都可谓谈之色变,九成九的程序员在开发中根本就没用过树,但实际上又在不知不觉间用了。那么树是什么?树在Java开发中又有哪些代言人,让我们通过这篇博客来认识下吧。
你好,认识一下,我是树
树,我们在数据库索引的数据结构中已经给大家介绍过,为了方便大家理解,这里给没看过的小伙伴重新写一下:
Tree就是树,顾名思义,像树一样的结构,只要是树,就一定拥有四个属性:
- 根结点:位于顶端且仅有一个
- 高度:整个树的层次
- 度:树中最大子节点数
- 叶子结点:位于最底层且没有子节点,或者说度为0的节点
看到这里,想必你已经知道了什么是树,下面,我给出一张图让大家看看树的基本数据结构:
看上去很赏心悦目,这是一棵平衡二叉树,也是二叉树的一种,仅做展示,没其他意义,请不要额外联想。在写之前,我们要先明白一件事,集合中是不能添加重复元素的,先不要问,后面你就知道为什么了。
二叉树与二叉排序树
顾名思义,度为2的树就是二叉树,上面的图就是一个二叉树,那什么是二叉排序树呢?二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。是数据结构中的一类。在一般情况下,查询效率比链表结构要高。如我先前所言,这里我们又提到了链表,如果看过前面文章的小伙伴可以加深对链表的理解。
二叉排序树特点
- 元素不能重复
- 左子树中节点均小于根结点
- 右子树中节点均大于根节点
这一点从此图也能看的出来:
为什么说二叉排序树查询效率要高于链表呢?
如果是一个长度为n的链表,最差的结果就是查n次(单向链表,双向链表查询方式可查看前面关于链表的博客),在二叉排序树中,看图,每次比较后都会排除总量一半的数据,所以查询的效率非常高。这个二叉排序树中有7个元素,假设n为7,链表最多要查7次,这里最多也就是3次,如果数据量翻倍,差别会更大。
元素的类型
二叉排序树中的元素的类型可以是其他的引用类型,但是他们之间要能比较大小,这就需要他们都实现comparable接口,在类中定义比较的规则,这样,对象也是可以比较大小的。
比较器
比较器分为两种:
- comparable:内比较器,实现该接口后,需要重写内部抽象方法,在类内部定义比较规则,Collections.sort(list)就是如此
- comparator:外比较器,比较规则定义在类的外部,通常用于在不改变类原有比较规则的情况下,使用新的/临时的比较规则,此时可以在类的外部实现该接口,定义新的比较规则。Collections.sort(list,comparator)
对集合排序有一个机制,这是前提: sort方法内部会自动调用集合中元素的compareTo方法
没有这个前提,我们接下来讲的就没有意义!
说起来很笼统,所以我们通过代码来说明:
我们先定义一个学生类,并重写抽象方法:
public class Student implements Comparable<Student>{private Integer id;private String name;private Integer age;@Overridepublic int compareTo(Student o) {return this.id-o.getId();}
}接着我们来把学生按照id升序排列:
List<Student> list = new ArrayList<>();
for (int i=2;i<=10;i++){Student student = new Student(i,"student"+i,20+i);list.add(student);
}
Student student1 = new Student(1,"Ammy",20);
list.add(student1);
list.forEach(student -> System.out.println(student));
//对list按id升序排列
Collections.sort(list);
list.forEach(student -> System.out.println(student));可以看到,在学生中我们已经重写了compareTo方法,这里我们就可以直接通过sort方法来处理。
上面我们采用的是内比较器,接下来我们改变规则,采用外比较器来处理:
//按age升序排列
Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o1.getAge() - o2.getAge();}
});
list.forEach(student -> System.out.println(student));如果要比较name,因为name肯定是String类型,使用String默认的比较器就可以,和age是不一样的,还是写一下吧:
//按照name升序排列
Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o2.getName().compareTo(o1.getName());}
});
list.forEach(student -> System.out.println(student));手写二叉排序树
接下来是我们的重点,手写二叉排序树,带大家理解排序的逻辑和原理。
定义一棵二叉树
其本质上是数据结构,是用来存储数据的,所以我们一般用泛型,让外部告知具体类型,而不能把类型写死。
public class BinarySearchTree<E extends Comparable<E>> {}而为了让传入的类型支持比较,必须要对泛型继承Comparable,这也是一个难点,很多人在这里容易写错。
定义完了类,那接着就需要定义根节点:
public class BinarySearchTree<E extends Comparable<E>> {//根节点private Node root;//定义内部类表示节点private class Node{private E ele; //节点中保存的元素对象private Node left; //左子树指向的节点private Node right; //右子树指向的节点//定义有参构造方法,用于创建节点Node(E ele){this.ele = ele;}}
}这时,一棵树的基本元素就定义好了,接下来就是我们所熟悉的增删改查方法,但写起来,可能并没那么简单。
增加元素
1. 判断root是否为null-为null,则将元素封装成节点,称为root,返回true-不为null,和root进行比较,比较的目的是将元素尝试添加为root的left/right子树- 和root相等,添加失败,返回false,结束- 大于>root,尝试添加为root的right;判断right是否为null,- 为null,则让新元素封装成节点,称为right,添加成功,返回true- 不为null,继续和right的节点进行比较,尝试将元素添加为right的left/right子树- 小于,同理增加元素需要先判断root是否为null
- 为null,将元素封装成根结点,返回true;
- 非null,和root进行比较,这是为了判断新元素是添加左子树还是右子树,但不一定添加成功
- 和root相等,那么添加失败,返回false,结束
- 大于root,尝试添加为root的右子树,判断right是否为null;
- 为null,将新元素封装成节点,成为右子树right,添加完成,返回true;
- 不为null,和right节点进行比较,尝试将该元素添加为right的left/right子树(这里递归就出现了)
- 小于root,尝试添加为root的左子树,判断left是否为null;
- 为null,将新元素封装成节点,成为左子树left,添加完成,返回true;
- 不为null,和left节点进行比较,尝试将该元素添加为left的left/right子树(这里递归就出现了)
思路理清了,那我们就开始写代码:
//添加元素public boolean add(E e){//判断root是否为null,为null,成为根节点if (root==null) {root = new Node(e);return true;}//root不为null,添加return root.append(e);}Node内的添加方法:
//向某个节点上添加给定的元素,尝试让新元素称为其左/右子树public boolean append(E e) {if (e.compareTo(ele) == 0) {return false;} else if (e.compareTo(ele) < 0) {if (left == null) {left = new Node(e);return true;}return left.append(e);} else {if (right == null) {right = new Node(e);return true;}return right.append(e);}}查询元素
查询元素也需要先判断root是否为null
- 为null,树中没有节点,返回null;
- 非null,判断root节点是否为需要查找的元素
- 相等,root节点就是需要的元素,返回root节点,结束;
- 大于ele,就到节点的right去查找相等节点,判断right节点是否存在
- 为null,说明查询的元素不在此树中,返回null
- 非null,判断right节点是不是要找的节点,往后一直重复上述操作,直到找到或找不到为止
- 小于ele,就到节点的left去查找相等节点,判断left节点是否存在
- 为null,说明查询的元素不在此树中,返回null
- 非null,判断left节点是不是要找的节点,往后一直重复上述操作,直到找到或找不到为止
用代码来写下这个过程:
//根据元素查询对应的节点对象public Node get(E e){//判断root是否为nullif (root==null)return null;//root不为空,则判断root是否为目标节点return root.isDestNode(e);}Node内的查询:
//用于判断调用方法的节点是否为目标节点public Node isDestNode(E e) {//判断e是否和当前节点的元素相等,若相等,说明为目标节点,返回当前节点即可if (e.compareTo(ele)==0)return this;else if (e.compareTo(ele)>0){ //e大于当前节点,到right上继续查找//若right为null,说明目标元素不存在树中,返回nullif (right==null)return null;return right.isDestNode(e);}else { //e小于当前节点,到left上继续查找if (left==null)return null;return left.isDestNode(e);}}修改元素
修改其实很简单,首先是查找,查找到之后,直接将新的元素指向那个节点。
我们可以定义这个方法如下:
set(E ele, E newEle)修改理论上是可行的,但是在修改的时候,会不会引起重新排序呢?这对整个树结构是有影响的,代码似乎也没有刚开始说的那么简单了,重新排序对性能也有影响,所以二叉树可不提供修改方法。
删除元素
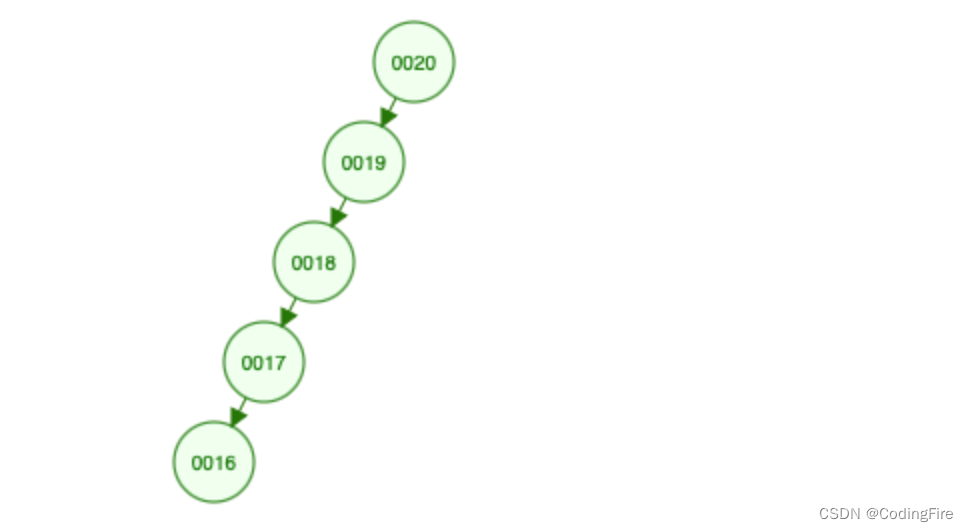
这要看删的是谁,如果删除的是叶子结点,那直接删了就好,不需要做什么判断,也不存在排序问题。一旦删除的是中间的节点,看下图:
假如删的是2或者6,这时候就要考虑谁上去的问题了。
所以删除分为三种情况:
- 删除叶子结点:将其父节点指向它的引用置为null;
- 删除有一棵子树的节点:将其父节点的指向变更为被删除的节点的子节点;
- 删除有两颗子树的节点:让被删除节点的前驱节点或者后继节点上来替换此节点;
- 前驱节点和后继节点是指升序排列后,删除节点的前一个元素叫做前驱节点,删除节点的后一个元素叫做后继节点
代码写起来会非常复杂,体验很差,所以就不写了,理解了就行,有兴趣的同学可自行尝试。
遍历二叉树
遍历的方式分为三种:
- 先序遍历:根 左 右
- 中序遍历:左 根 右
- 后序遍历:左 右 根
什么意思呢?我们根据一棵树来说:
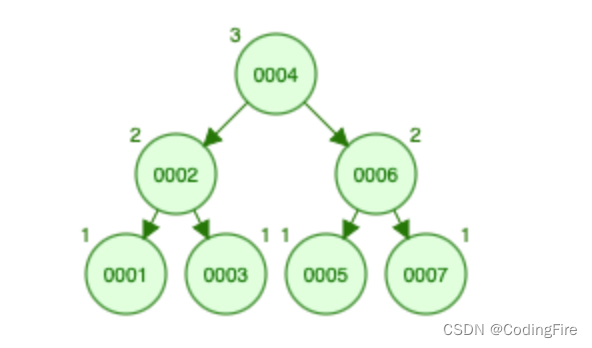
先序遍历:4,2,1,3,6,5,7(即先根,后左,再右)
中序遍历:1,2,3,4,5,6,7(即先左,后根,再右,也叫升序排列)
后序遍历:1,3,2,5,7,6 ,4(即先左,后右,再根)
重写toString
目的是为了实现输出引用,将二叉树中的元素遍历,并以此格式输出:[1,2,3,4,5,6,7]输出,没有节点,返回[]。
//重写toString@Overridepublic String toString() {//判断root是否为null,为null,返回"[]"if (root==null)return "[]";//进行中序遍历StringBuilder builder = new StringBuilder("[");return root.middleOrder(builder).replace(builder.length()-1,builder.length(),"]").toString();Node内的方法:
public StringBuilder middleOrder(StringBuilder builder) {//左if (left!=null){left.middleOrder(builder);}//取根的值builder.append(ele).append(",");//取右if (right!=null){right.middleOrder(builder);}//以上三步操作结束,得到遍历树后的元素拼接结果,将最后的逗号替换为]return builder;}中序遍历这里有个递归,我们要明白的是,最终所有的代码都要取到根的值,这个节点是相对的,每个节点都会是这个根,这样才能拼接出字符串。大家可以动手尝试下其他遍历方式的写法,这里不再赘述。
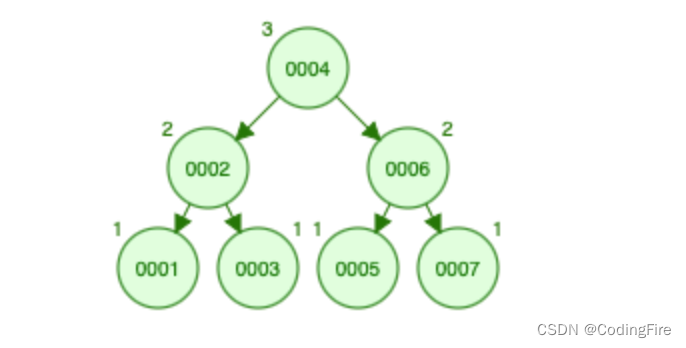
二叉排序树的极端情况
这就是失衡二叉树,失衡二叉树是不希望存在的,因为它失去了二叉树本身的优势特点,这种状态和单向链表一样,单向链表的效率如何,想必大家都是知道的。
所以在设计数据结构的时候,已经考虑了这种情况,出现了两种新的数据结构,他们都基于二叉排序树,保留了其优势,又避免了这个缺点。
他们是平衡二叉树和红黑树。
平衡二叉树
平衡二叉树又称为AVL树,AVL树通过旋转(左旋/右旋)来保证二叉排序树的平衡状态,AVL树会保证树的左右子树高度差始终是<=1,AVL树达到的平衡状态是绝对平衡(左右子树的高度差<=1),看下图查看旋转变化:
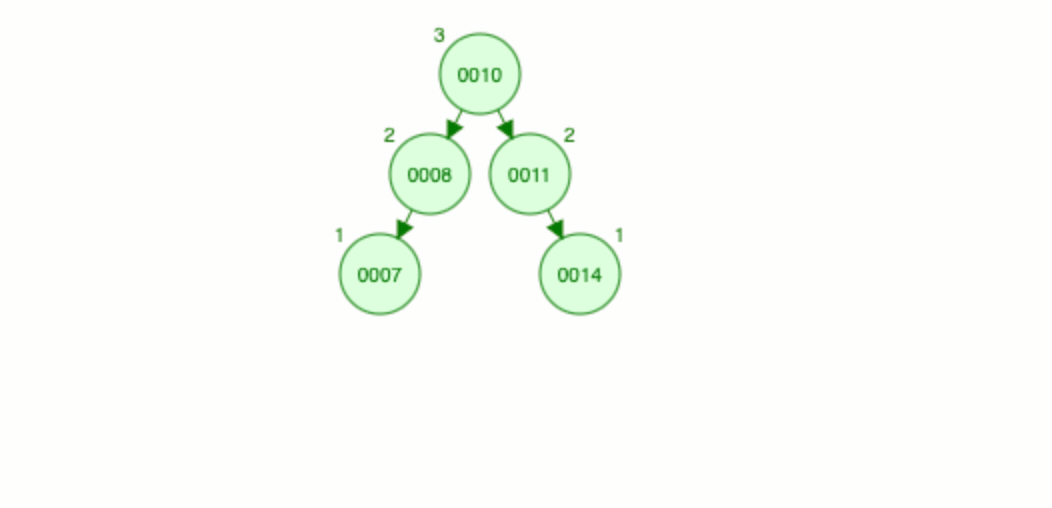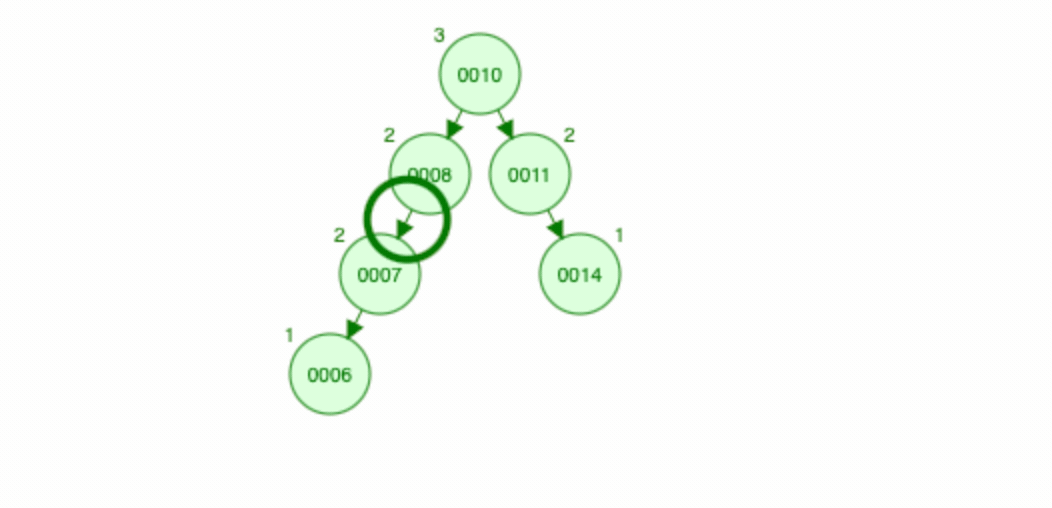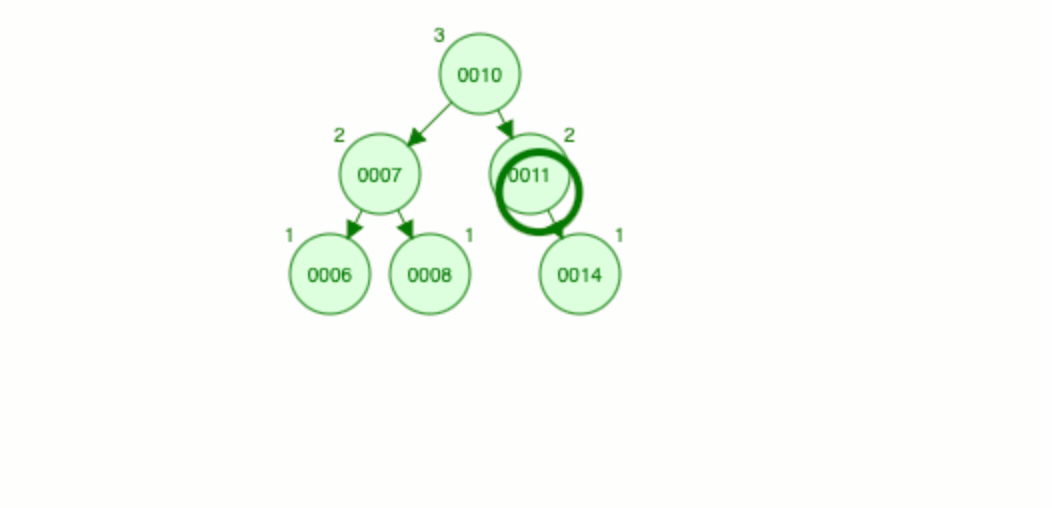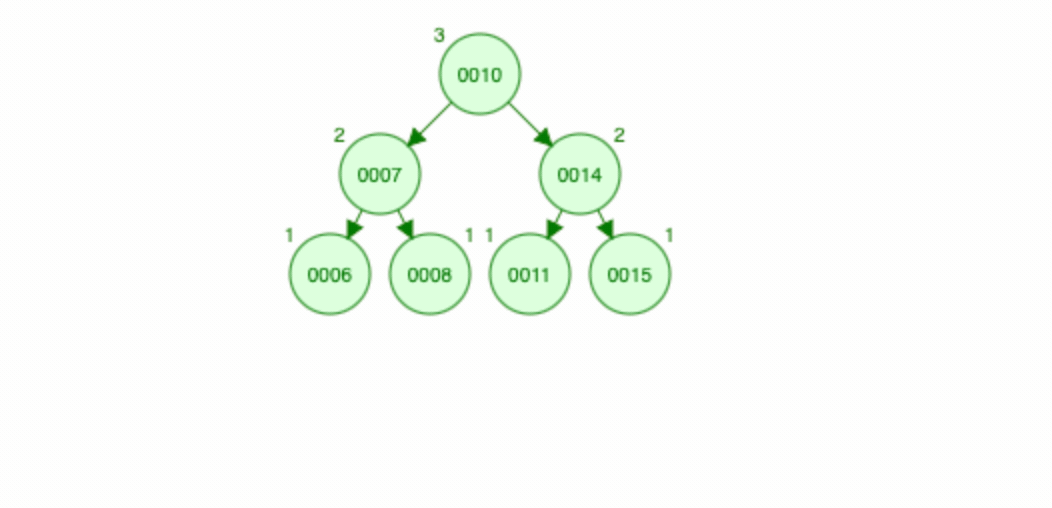
红黑树
红黑树是实现了自平衡的二叉排序树,但并不是平衡二叉树那样的绝对平衡,它的左右子树相差可以大于1,正如其名,所有的节点要么红色,要么黑色。
保证平衡
- 旋转
- 调整节点颜色
- 根结点必须为黑色
- 新添加的节点必然是红色,但是添加成功后由于旋转,可能会变为黑色
红黑树的规则
- 节点为红色或者黑色
- 根结点为黑色
- 所有叶子结点是黑色
- 每个红色节点的左右子树为黑色,也就是说,每个叶子结点到根结点的路径上不能出现两个连续的红色节点
- 任意叶子结点到根节点的黑色节点数量相同,称作黑高相同
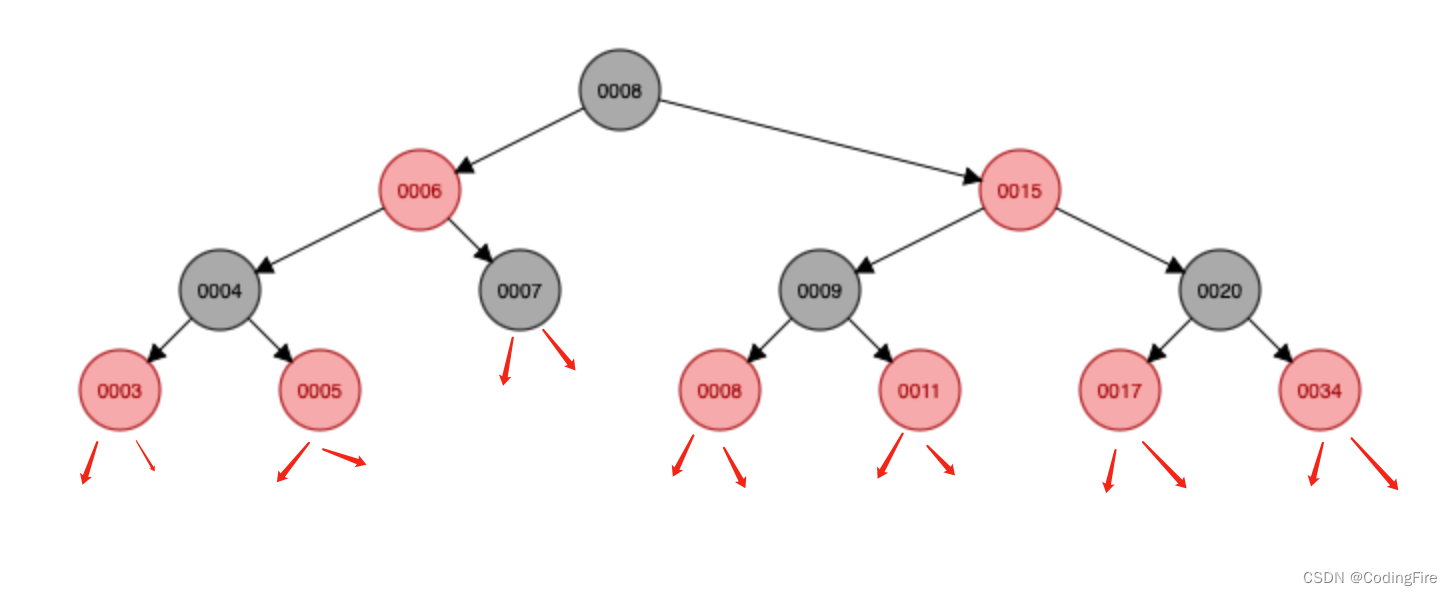
这里说明下叶子结点都为黑色的原因,图中看到的有红色,有黑色,大家应该看到我标出来的红色箭头,每个箭头默认还指着一个隐藏的黑色的为null节点 。
红黑树的应用
- TreeMap
- TreeSet
由于TreeSet底层调用了TreeMap,所以,我们猜测出,所有的set和map都有这样的关系:
- HashSet/HashMap 数据结构为散列表,输出引用,得到的结果为无序结果
- TreeSet/TreeMap 数据结构为红黑树 输出引用,得到的结果为中序遍历的结果 -- 升序排列
- LinkedHashSet/LinkedHashMap 输出引用,得到的结果为有序的结果
所以,set集合是不可重复的集合,并不是无序的集合,实现类不同,可能就会出现有序的时候。
散列表
散列表其实算是红黑树的范畴,但是其涉及内容太多,所以就单独拉一个大标题来写一些,东西比较多,也是最后一个知识点,看到这里了,不妨继续看下去吧。
应用类为HashMap,散列表是一种数据结构,它的底层实现如下:
- JDK1.8之前,散列表的数据结构为数组+链表
- JDK1.8开始,散列表的数据结构为数组+链表+红黑树
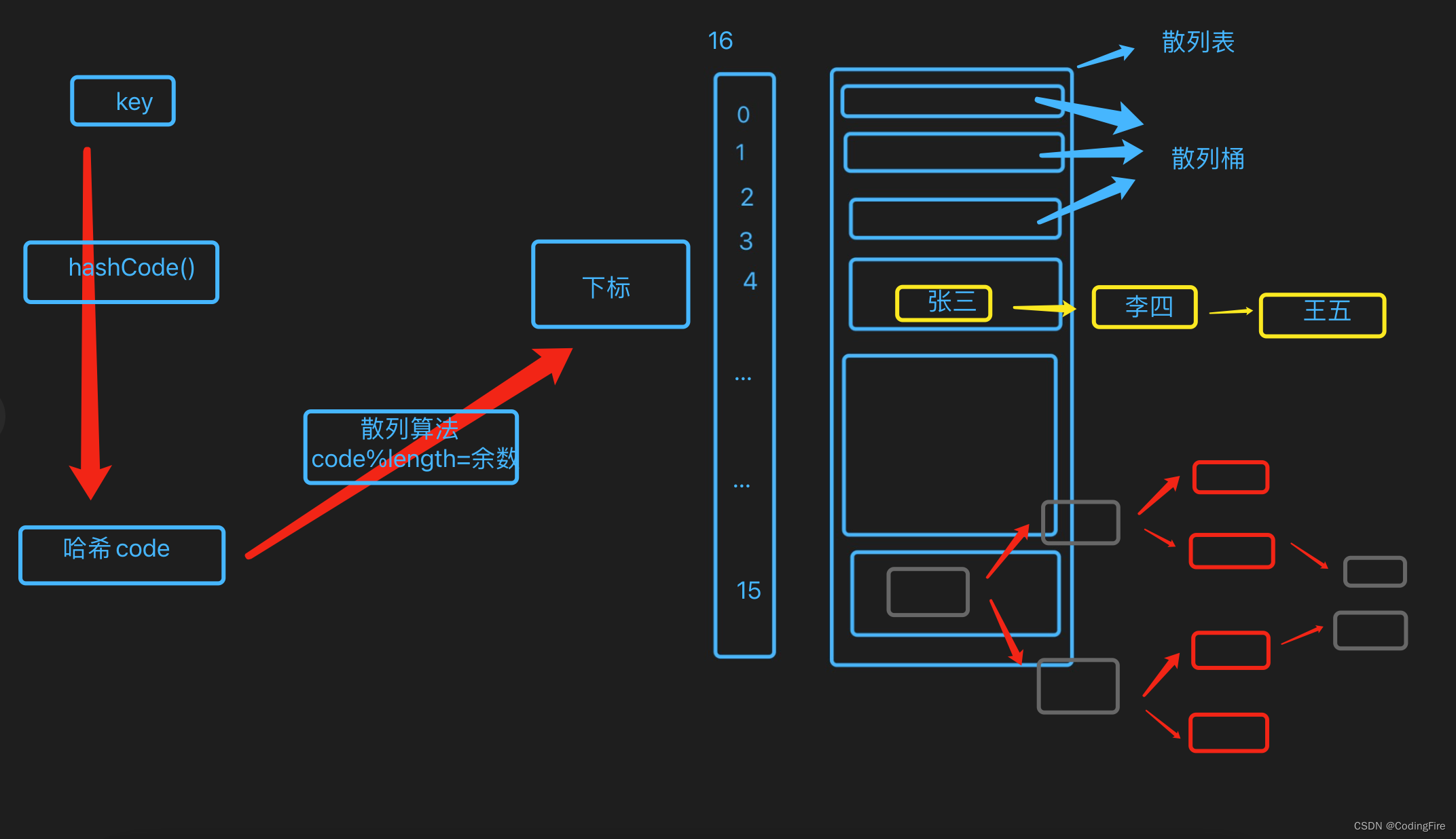
向散列表中存数据
- 根据key调用hashCode()方法,得到哈希码值;
- 哈希码值再调用散列算法,得到一个整数,这个整数就是保存在数组中的下标;
- 如果散列桶为空,将键值对直接存入,否则用这个准备存入的值和已经存在散列桶中的值进行比较
- 相等,则新的value覆盖原来的value
- 否则,在该散列桶中形成链表
hashCode()方法特点
该方法的目的是尽可能的为不同的对象分配不同的整数,其特点如下:
- 一次程序运行期间,同一个对象多次调用次方法,哈希码值一定相等;
- 两个对象调用equals方法结果为true,这两个方法调用hashCode()方法生成的整数一定相等;
- 两个对象调用equals方法结果为true,这两个方法调用hashCode()方法生成的整数可能相等,也可能不同;
链表的产生原因
- 不同的对象调用hashCode(),可能会形成相同的整数,最终导致下标一致;
- 不同的对象调用hashCode(),可能会形成不同的整数,不同的整数再调用散列算法后得到相同的下标;
以上这种现象叫做哈希冲突或者哈希碰撞,要降低这种概率的发生,散列表可通过扩容的方式降低发生概率。
链表存在的问题
我们都知道,链表的查询效率是比较低的,若散列桶中只有一个键值对,那直接就能通过下标找到,但是若有多个的时候,通过下标找到后还需要对链表进行查询,这就降低了查询的效率。
所以我们做的就是尽可能减少链表的产生,怎么做呢?
没错,扩容!当数组中元素达到一定的数量后就对数组进行扩容,一般为原长度的两倍。所以要找一个扩容依据。
扩容因数=可保存最大数/总容量
初始状态总容量16,可保存最大数12,当第13个元素出现时,数组就扩容为原来的2倍。
数组的扩容
当数组中元素达到一定的数量后就对数组进行扩容,一般为原长度的两倍,特别注意,此时数组中的元素会重新进行散列。
散列表的初始容量为2的n次方,如果初始值给的不是2的n次方,则会自动给出相近的且大于设置值的2的n次方的值。比如给9,则容量为16,给17,容量为32。
前面说过,JDK1.8之后,散列表的数据结构变为数组+链表+红黑树,所以自JDK1.8开始,当散列表中元素数量超过64,或者散列桶中链表长度等于8时,会将链表转化为红黑树,红黑树的查询效率更高,可提高整体的查询效率。
结语
到这里,这篇博客就要和大家说再见了,基本知识点都有涵盖,如有遗漏或者讲的不对的地方,欢迎指正,也欢迎留言一起探讨数据结构,写作不易,觉得不错就点赞收藏来鼓励下博主吧。