🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
迭代数据集
做数据科学
探索您的第一个数据集
高效,从小做起
洞察与产品
数据质量准则
数据格式
数据质量
数据量及分布
ML编辑器数据检查
用于查找数据趋势的标签
汇总统计
ML 编辑器的汇总统计
高效探索和标记
矢量化
降维
聚类
成为算法
数据趋势
让数据告知特征和模型
根据模式构建特征
原始日期时间
提取星期几和一个月中的某一天
特征交叉
给你的模型答案
ML 编辑器功能
Robert Munro:您如何查找、标记和利用数据?
结论
.一次如果您有解决产品需求的计划并且已经构建了初始原型来验证您提出的工作流程和模型是否合理,那么是时候更深入地研究您的数据集了。我们将使用我们的发现来为我们的建模决策提供信息。通常,充分了解您的数据会带来最大的性能改进。
在本章中,我们将从研究有效判断数据集质量的方法开始。然后,我们将介绍对数据进行矢量化的方法,以及如何使用所述矢量化表示更有效地标记和检查数据集。最后,我们将介绍这种检查将如何指导特征生成策略。
让我们从发现数据集并判断其质量开始。
迭代数据集
这构建 ML 产品的最快方法是快速构建、评估和迭代模型。数据集本身是模型成功的核心部分。这就是为什么数据收集、准备和标记应该被视为一个迭代过程,就像建模一样。从一个您可以立即收集的简单数据集开始,并根据您学到的知识对它进行改进。
这个数据的迭代方法起初似乎令人困惑。在 ML 研究中,性能通常在社区用作基准的标准数据集上报告,因此是不可变的。在传统的软件工程中,我们为我们的程序编写确定性规则,因此我们将数据视为要接收、处理和存储的东西。
ML 工程将工程和 ML 相结合以构建产品。因此,我们的数据集只是允许我们构建产品的另一种工具。在 ML 工程中,选择初始数据集、定期更新和扩充数据集通常是大部分工作。图 4-1说明了研究和工业之间工作流程的差异。
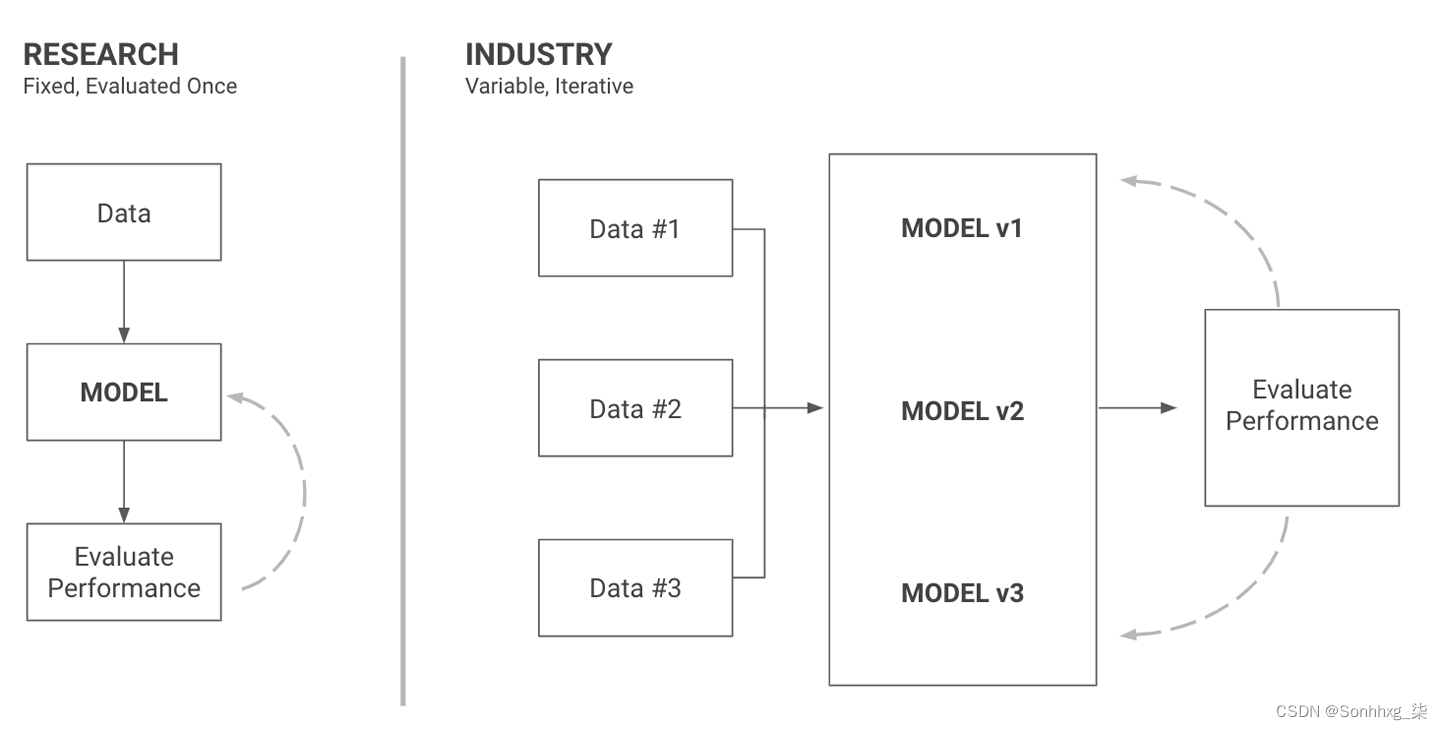
图 4-1。数据集在研究中是固定的,但在工业中是产品的一部分
将数据视为您可以(并且应该)迭代、更改和改进的产品的一部分,对于行业新手来说通常是一个重大的范式转变。然而,一旦你习惯了它,数据将成为你开发新模型的最佳灵感来源,以及当出现问题时你寻找答案的第一个地方。
探索您的第一个数据集
所以我们如何着手探索初始数据集?第一步当然是收集数据集。这是我看到从业者在搜索完美数据集时最常卡住的地方。请记住,我们的目标是获得一个简单的数据集以从中提取初步结果。与 ML 中的其他事物一样,从简单开始,然后从那里构建。
高效,从小做起
对于大多数 ML 问题,更多的数据可以产生更好的模型,但这并不意味着您应该从尽可能大的数据集开始。当开始一个项目时,一个小的数据集可以让你轻松地检查和理解你的数据以及如何更好地建模。您应该以易于使用的初始数据集为目标。只有在您确定了一项策略后,才有意义将其扩展到更大的规模。
如果您在一家公司工作,在集群中存储了数 TB 的数据,您可以从提取适合本地计算机内存的统一采样子集开始。例如,如果你想开始一个副项目,试图识别在你家门前行驶的汽车品牌,可以从几十张街道上的汽车图像开始。
一旦您了解了您的初始模型的执行情况以及它遇到的问题,您将能够以一种明智的方式迭代您的数据集!
你可以在Kaggle或Reddit等平台上在线找到许多现有数据集,或者通过抓取网络、利用大型开放数据集(例如在Common Crawl 站点上找到的)或生成数据来自己收集一些示例!有关详细信息,请参阅“开放数据”。
收集和分析数据不仅是必要的,而且会加快你的速度,尤其是在项目开发的早期。查看您的数据集并了解其特征是提出良好建模和特征生成管道的最简单方法。
大多数从业者都高估了处理模型的影响而低估了处理数据的价值,因此我建议始终努力纠正这种趋势并偏向于查看数据。
检查数据时,以探索的方式确定趋势是件好事,但您不应该就此止步。如果您的目标是构建 ML 产品,您应该问问自己以自动化方式利用这些趋势的最佳方式是什么。这些趋势如何帮助您为自动化产品提供动力?
洞察与产品
一次你有一个数据集,是时候深入研究它并探索它的内容了。当我们这样做时,让我们记住用于分析目的的数据探索和用于产品构建目的的数据探索之间的区别。虽然两者都旨在提取和理解数据中的趋势,但前者关注的是从趋势中创造洞察力(了解到大多数欺诈性登录网站发生在星期四,并且来自西雅图地区,例如),而后者是关于使用趋势构建功能(使用登录尝试的时间及其 IP 地址来构建防止欺诈性帐户登录的服务)。
虽然差异可能看起来很微妙,但它会导致产品构建案例的额外复杂性。我们需要确信我们看到的模式将适用于我们将来收到的数据,并量化我们正在训练的数据与我们期望在生产中收到的数据之间的差异。
为了欺诈预测,注意到欺诈登录的季节性是第一步。然后我们应该使用这个观察到的季节性趋势来估计我们需要多久根据最近收集的数据训练我们的模型。在本章后面更深入地探索数据时,我们将深入研究更多示例。
数据质量准则
在本节中,我们将介绍首次使用新数据集时要检查的一些方面。每个数据集都有自己的偏见和怪异,需要不同的工具才能理解,因此编写一个涵盖您可能想在数据集中寻找的任何内容的综合规则超出了本书的范围。然而,在首次处理数据集时,有几个类别值得关注。让我们从格式化开始。
数据格式
数据集是否已经格式化为具有清晰的输入和输出,或者是否需要额外的预处理和标记?
例如,在构建试图预测用户是否会点击广告的模型时,公共数据集将包含给定时间段内所有点击的历史日志。您需要转换此数据集,使其包含向用户展示的广告的多个实例以及用户是否点击。您还希望包括您认为您的模型可以利用的用户或广告的任何特征。
如果给你的数据集已经为你处理或聚合,你应该验证你了解数据处理的方式。例如,如果您获得的其中一列包含平均转化率,您能否自己计算该转化率并验证它是否与提供的值相匹配?
在某些情况下,您将无法访问复制和验证预处理步骤所需的信息。在这些情况下,查看数据的质量将帮助您确定您信任哪些特征以及最好忽略哪些特征。
数据质量
在开始建模之前检查数据集的质量至关重要。如果您知道某个关键特征的一半值缺失,您就不会花费数小时调试模型来尝试了解其性能不佳的原因。
数据质量低下的原因有很多。它可能丢失,可能不精确,甚至可能被损坏。准确了解其质量不仅可以让您估计哪个性能级别是合理的,还可以更轻松地选择要使用的潜在功能和模型。
如果您正在使用用户活动日志来预测在线产品的使用情况,您能估计丢失了多少记录的事件吗?对于您拥有的事件,有多少仅包含有关用户的信息子集?
如果您正在处理自然语言文本,您如何评价文本的质量?比如,是不是有很多看不懂的字?拼写是否非常错误或不一致?
如果你正在处理图像,它们是否足够清晰以至于你可以自己完成任务?如果您很难检测到图像中的物体,您认为您的模型会很难做到吗?
一般而言,您的数据中有哪一部分看起来有噪音或不正确?有多少输入是您难以解释或理解的?如果数据有标签,您是倾向于同意它们,还是经常发现自己质疑它们的准确性?
例如,我从事过一些旨在从卫星图像中提取信息的项目。在最好的情况下,这些项目可以访问带有相应注释的图像数据集,这些注释表示感兴趣的对象,例如场或平面。然而,在某些情况下,这些注释可能不准确甚至缺失。此类错误对任何建模方法都有重大影响,因此尽早发现它们至关重要。我们可以通过自己标记初始数据集或找到我们可以使用的弱标签来处理缺失的标签,但只有在我们提前注意到质量的情况下才能这样做。
在验证数据的格式和质量之后,一个额外的步骤可以帮助主动发现问题:检查数据数量和特征分布。
数据量及分布
让我们估计一下我们是否有足够的数据以及特征值是否在合理范围内。
我们有多少数据?如果我们有一个大数据集,我们应该选择一个子集来开始我们的分析。另一方面,如果我们的数据集太小或某些类别的代表性不足,我们训练的模型可能会像我们的数据一样存在偏差。避免这种偏见的最好方法是通过数据收集和扩充来增加我们数据的多样性。衡量数据质量的方法取决于您的数据集,但表 4-1涵盖了一些帮助您入门的问题。
| 质量 | 格式 | 数量及分布 | |
|---|---|---|---|
| 是否有任何相关字段为空? | 您的数据需要多少预处理步骤? | 你有多少个例子? | |
| 是否存在潜在的测量误差? | 您能否在生产中以相同的方式对其进行预处理? | 每个班级有多少个例子?有缺席的吗? |
举一个实际的例子,在构建一个模型来自动将客户支持电子邮件分类到不同的专业领域时,我与一位数据科学家 Alex Wahl 一起工作,他被赋予了九个不同的类别,每个类别只有一个示例。这样的数据集对于模型来说太小了,无法从中学习,因此他将大部分精力集中在数据生成策略上。他为九个类别中的每一个都使用了通用公式的模板,以产生数千个模型可以从中学习的示例。使用这种策略,他设法使管道达到比他试图建立一个足够复杂的模型以仅从九个示例中学习所达到的准确度更高的水平。
让我们将此探索过程应用于我们为 ML 编辑器选择的数据集并评估其质量!
ML编辑器数据检查
为了在我们的 ML 编辑器中,我们最初决定使用匿名的Stack Exchange 数据转储作为数据集。Stack Exchange 是一个问答网站网络,每个网站都专注于一个主题,例如哲学或游戏。数据转储包含许多档案,一个用于 Stack Exchange 网络中的每个网站。
对于我们的初始数据集,我们将选择一个网站,该网站看起来包含足够广泛的问题,可以从中构建有用的启发式方法。乍一看,写作社区似乎很合适。
每个网站档案都以 XML 文件的形式提供。我们需要构建一个管道来摄取这些文件并将它们转换为文本,然后我们可以从中提取特征。以下示例显示了datascience.stackexchange.comPosts.xml的文件:
<?xml version="1.0" encoding="utf-8"?>
<posts><row Id="5" PostTypeId="1" CreationDate="2014-05-13T23:58:30.457"
Score="9" ViewCount="516" Body="<p> "Hello World" example? "
OwnerUserId="5" LastActivityDate="2014-05-14T00:36:31.077"
Title="How can I do simple machine learning without hard-coding behavior?"
Tags="<machine-learning>" AnswerCount="1" CommentCount="1" /><row Id="7" PostTypeId="1" AcceptedAnswerId="10" ... />为了能够利用这些数据,我们需要能够加载 XML 文件,解码文本中的 HTML 标签,并以更易于分析的格式(例如 pandas DataFrame)表示问题和相关数据。下面的函数就是这样做的。提醒一下,此函数的代码以及本书中的所有其他代码都可以在本书的 GitHub 存储库中找到。
import xml.etree.ElementTree as ElTdef parse_xml_to_csv(path, save_path=None):"""Open .xml posts dump and convert the text to a csv, tokenizing it in theprocess:param path: path to the xml document containing posts:return: a dataframe of processed text"""# Use python's standard library to parse XML filedoc = ElT.parse(path)root = doc.getroot()# Each row is a questionall_rows = [row.attrib for row in root.findall("row")]# Using tdqm to display progress since preprocessing takes timefor item in tqdm(all_rows):# Decode text from HTMLsoup = BeautifulSoup(item["Body"], features="html.parser")item["body_text"] = soup.get_text()# Create dataframe from our list of dictionariesdf = pd.DataFrame.from_dict(all_rows)if save_path:df.to_csv(save_path)return df对于训练模型所需的任何预处理,这通常是推荐的做法。在模型优化过程之前运行的预处理代码会显着减慢实验速度。尽可能始终提前预处理数据并将其序列化到磁盘。
一旦我们有了这种格式的数据,我们就可以检查我们之前描述的方面。我们接下来详述的整个探索过程可以在本书 GitHub 存储库的数据集探索笔记本中找到。
首先,我们使用它df.info()来显示关于我们的 DataFrame 的摘要信息,以及任何空值。这是它返回的内容:
df.info()AcceptedAnswerId 4124 non-null float64
AnswerCount 33650 non-null int64
Body 33650 non-null object
ClosedDate 969 non-null object
CommentCount 33650 non-null int64
CommunityOwnedDate 186 non-null object
CreationDate 33650 non-null object
FavoriteCount 3307 non-null float64
Id 33650 non-null int64
LastActivityDate 33650 non-null object
LastEditDate 10521 non-null object
LastEditorDisplayName 606 non-null object
LastEditorUserId 9975 non-null float64
OwnerDisplayName 1971 non-null object
OwnerUserId 32117 non-null float64
ParentId 25679 non-null float64
PostTypeId 33650 non-null int64
Score 33650 non-null int64
Tags 7971 non-null object
Title 7971 non-null object
ViewCount 7971 non-null float64
body_text 33650 non-null object
full_text 33650 non-null object
text_len 33650 non-null int64
is_question 33650 non-null bool我们可以看到我们有超过 31,000 个帖子,其中只有大约 4,000 个有一个被接受的答案。此外,我们可以注意到Body表示帖子内容的 的某些值是 null,这看起来很可疑。我们希望所有帖子都包含文本。查看带有 null 的行Body很快就会发现它们属于一种在数据集提供的文档中没有引用的帖子,因此我们将它们删除。
让我们快速深入了解格式,看看我们是否理解它。每个帖子PostTypeId的问题值为 1,答案值为 2。我们希望看到哪种类型的问题获得高分,因为我们希望将问题的分数用作我们真实标签(问题的质量)的弱标签。
首先,让我们将问题与相关答案进行匹配。以下代码选择所有具有可接受答案的问题,并将它们与所述答案的文本连接起来。然后我们可以查看前几行并验证答案是否与问题匹配。这也将使我们能够快速浏览文本并判断其质量。
questions_with_accepted_answers = df[df["is_question"] & ~(df["AcceptedAnswerId"].isna())
]
q_and_a = questions_with_accepted_answers.join(df[["Text"]], on="AcceptedAnswerId", how="left", rsuffix="_answer"
)pd.options.display.max_colwidth = 500
q_and_a[["Text", "Text_answer"]][:5]在表 4-2中,我们可以看到问题和答案似乎是匹配的,并且文本似乎大部分是正确的。我们现在相信我们可以将问题与其相关的答案相匹配。
| ID | body_text | body_text_answer |
|---|---|---|
| 1 | I’ve always wanted to start writing (in a totally amateur way), but whenever I want to start something I instantly get blocked having a lot of questions and doubts.\nAre there some resources on how to start becoming a writer?\nl’m thinking something with tips and easy exercises to get the ball rolling.\n | When I’m thinking about where I learned most how to write, I think that reading was the most important guide to me. This may sound silly, but by reading good written newspaper articles (facts, opinions, scientific articles, and most of all, criticisms of films and music), I learned how others did the job, what works and what doesn’t. In my own writing, I try to mimic other people’s styles that I liked. Moreover, I learn new things by reading, giving me a broader background that I need when re… |
| 2 | What kind of story is better suited for each point of view? Are there advantages or disadvantages inherent to them?\nFor example, writing in the first person you are always following a character, while in the third person you can “jump” between story lines.\n | With a story in first person, you are intending the reader to become much more attached to the main character. Since the reader sees what that character sees and feels what that character feels, the reader will have an emotional investment in that character. Third person does not have this close tie; a reader can become emotionally invested but it will not be as strong as it will be in first person.\nContrarily, you cannot have multiple point characters when you use first person without ex… |
| 3 | I finished my novel, and everyone I’ve talked to says I need an agent. How do I find one?\n | Try to find a list of agents who write in your genre, check out their websites!\nFind out if they are accepting new clients. If they aren’t, then check out another agent. But if they are, try sending them a few chapters from your story, a brief, and a short cover letter asking them to represent you.\nIn the cover letter mention your previous publication credits. If sent via post, then I suggest you give them a means of reply, whether it be an email or a stamped, addressed envelope.\nAgents… |
作为最后一次健全性检查,让我们看看有多少问题没有得到回答,有多少问题至少得到了一个答案,有多少答案被接受了。
has_accepted_answer = df[df["is_question"] & ~(df["AcceptedAnswerId"].isna())]
no_accepted_answers = df[df["is_question"]& (df["AcceptedAnswerId"].isna())& (df["AnswerCount"] != 0)
]
no_answers = df[df["is_question"]& (df["AcceptedAnswerId"].isna())& (df["AnswerCount"] == 0)
]print("%s questions with no answers, %s with answers, %s with an accepted answer"% (len(no_answers), len(no_accepted_answers), len(has_accepted_answer))
)# 3584 questions with no answers, 5933 with answers, 4964 with an accepted answer.我们在已回答、部分回答和未回答的问题之间的分配相对平均。这似乎是合理的,所以我们可以有足够的信心继续我们的探索。
我们了解数据的格式,并且有足够的数据可以开始使用。如果您正在处理一个项目并且您当前的数据集太小或包含大多数难以解释的特征,您应该收集更多数据或完全尝试不同的数据集。
用于查找数据趋势的标签
识别我们数据集中的趋势不仅仅是质量。这部分工作是让我们置身于我们的模型中,并试图预测它将采用哪种结构。我们将通过将数据分成不同的集群(我将在“集群”中解释集群)并尝试提取每个集群中的共性来做到这一点。
以下是在实践中执行此操作的分步列表。我们将从生成数据集的汇总统计开始,然后了解如何利用矢量化技术快速探索它。在矢量化和聚类的帮助下,我们将有效地探索我们的数据集。
汇总统计
什么时候当您开始查看数据集时,通常最好查看您拥有的每个功能的一些汇总统计数据。这有助于您对数据集中的特征有一个大致的了解,并确定任何简单的方法来分离您的类。
及早识别数据类别之间的分布差异对 ML 很有帮助,因为它要么使我们的建模任务更容易,要么防止我们高估可能仅利用一个特别有用的特征的模型的性能。
例如,如果你试图预测推文是表达正面还是负面意见,你可以从计算每条推文中的平均单词数开始。然后,您可以绘制此功能的直方图以了解其分布。
直方图可以让您注意到是否所有正面推文都比负面推文短。这可能会导致您添加字长作为预测变量,以使您的任务更轻松,或者相反,收集额外的数据以确保您的模型可以了解推文的内容,而不仅仅是它们的长度。
让我们为我们的 ML 编辑器绘制一些汇总统计数据来说明这一点。
ML 编辑器的汇总统计
为了在我们的示例中,我们可以绘制数据集中问题长度的直方图,突出显示高分和低分问题之间的不同趋势。以下是我们如何使用熊猫来做到这一点:
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle"""
df contains questions and their answer counts from writers.stackexchange.com
We draw two histograms:
one for questions with scores under the median score
one for questions with scores over
For both, we remove outliers to make our visualization simpler
"""high_score = df["Score"] > df["Score"].median()
# We filter out really long questions
normal_length = df["text_len"] < 2000ax = df[df["is_question"] & high_score & normal_length]["text_len"].hist(bins=60,density=True,histtype="step",color="orange",linewidth=3,grid=False,figsize=(16, 10),
)df[df["is_question"] & ~high_score & normal_length]["text_len"].hist(bins=60,density=True,histtype="step",color="purple",linewidth=3,grid=False,
)handles = [Rectangle((0, 0), 1, 1, color=c, ec="k") for c in ["orange", "purple"]
]
labels = ["High score", "Low score"]
plt.legend(handles, labels)
ax.set_xlabel("Sentence length (characters)")
ax.set_ylabel("Percentage of sentences")我们可以在图 4-2中看到分布基本相似,高分问题往往略长(这种趋势在 800 字符标记附近尤为明显)。这表明问题长度可能是模型预测问题分数的有用特征。
我们可以以类似的方式绘制其他变量以识别更多潜在特征。一旦我们确定了一些特征,让我们更仔细地查看我们的数据集,以便我们可以确定更细粒度的趋势。
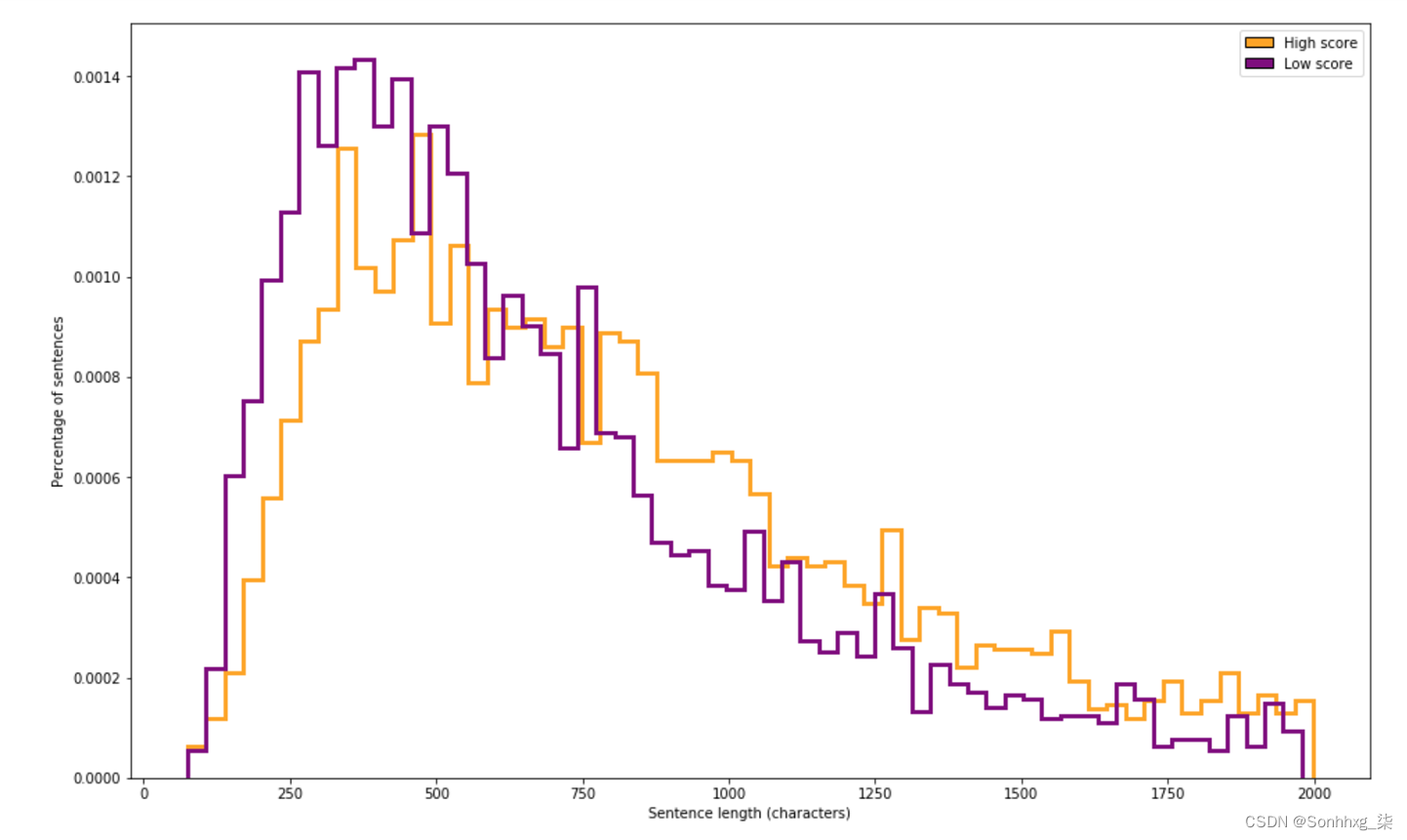
图 4-2。高分和低分问题的文本长度直方图
高效探索和标记
你目前只能查看描述性统计数据,例如平均值和图表,例如直方图。要培养对数据的直觉,您应该花一些时间查看各个数据点。然而,随机遍历数据集中的点是非常低效的。在本节中,我将介绍如何在可视化单个数据点时最大限度地提高效率。
许多聚类算法通过测量点之间的距离并将彼此接近的点分配到同一簇来对数据点进行分组。图 4-3显示了将数据集分成三个不同集群的聚类算法示例。聚类是一种无监督方法,通常没有单一正确的方法来对数据集进行聚类。在本书中,我们将使用聚类作为生成某种结构的方法来指导我们的探索。
因为聚类依赖于计算数据点之间的距离,所以我们选择用数字表示数据点的方式对生成哪些聚类有很大影响。我们将在下一节“向量化”中深入探讨这一点。
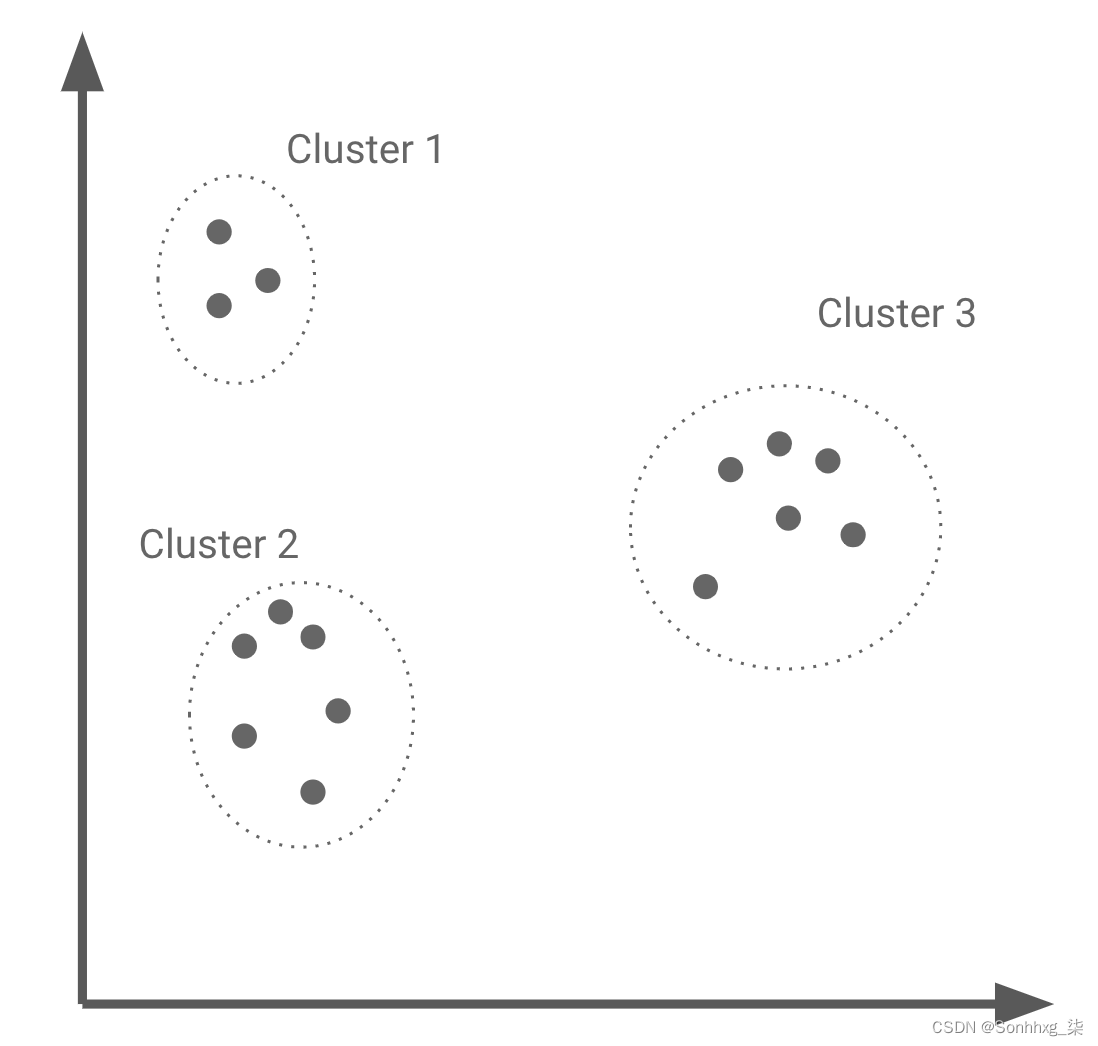
图 4-3。从数据集生成三个集群
绝大多数数据集都可以根据它们的特征、标签或两者的组合分成集群。单独检查每个集群以及集群之间的异同是识别数据集中结构的好方法。
这里有很多事情需要注意:
-
您在数据集中识别出多少个聚类?
-
您觉得这些集群中的每一个都不同吗?以何种方式?
-
是否有任何簇比其他簇密集得多?如果是这样,您的模型可能很难在稀疏区域执行。添加特征和数据可以帮助缓解这个问题。
-
是否所有集群都代表似乎“难以”建模的数据?如果某些集群似乎代表更复杂的数据点,请记下它们,以便在我们评估模型性能时重新访问它们。
正如我们提到的,聚类算法对向量起作用,所以我们不能简单地将一组句子传递给聚类算法。为了让我们的数据准备好进行聚类,我们首先需要对其进行矢量化。
矢量化
矢量化数据集是从原始数据到表示它的向量的过程。图 4-4显示了文本和表格数据的矢量化表示示例。
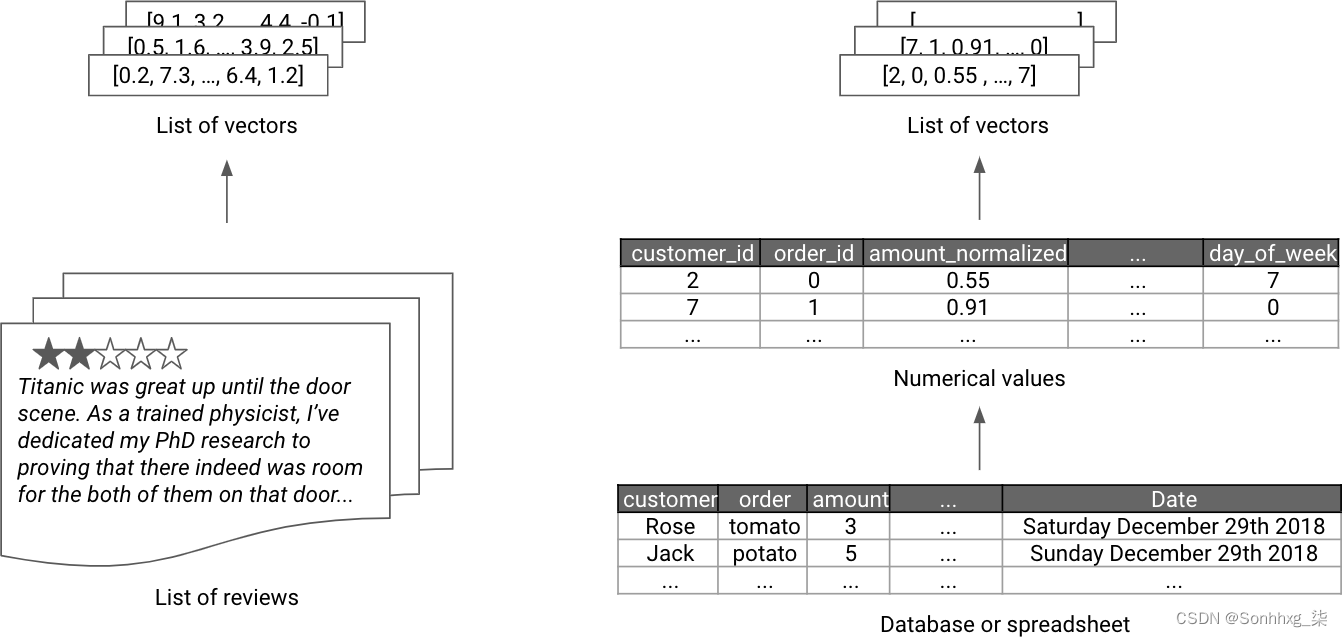
图 4-4。矢量化表示的例子
向量化数据的方法有很多种,因此我们将重点介绍一些适用于一些最常见数据类型(例如表格数据、文本和图像)的简单方法。
表格数据
为了对于由分类特征和连续特征组成的表格数据,可能的向量表示只是每个特征的向量表示的串联。
连续特征应该是归一化到一个共同的尺度,这样具有较大尺度的特征不会导致较小的特征被模型完全忽略。有多种方法可以对数据进行归一化,但是从转换每个特征开始,使其均值为零,方差为一通常是很好的第一步。这个通常称为标准分数。
颜色等分类特征可以转换为one-hot encoding:一个列表,只要特征的不同值的数量只包含零和一个单一的,其索引代表当前值(例如,在包含四种不同颜色的数据集中,我们可以将红色编码为[1, 0, 0, 0] 和蓝色为 [0, 0, 1, 0])。您可能很好奇为什么我们不简单地为每个潜在值分配一个数字,例如 1 代表红色,3 代表蓝色。这是因为这样的编码方案将暗示值之间的排序(蓝色大于红色),这对于分类变量通常是不正确的。
one-hot 编码的一个特性是任意两个给定特征值之间的距离始终为一个。这通常可以很好地表示模型,但在某些情况下,例如一周中的几天,某些值可能比其他值更相似(周六和周日都在周末,因此理想情况下它们的向量会比周三更接近和星期天,例如)。神经网络已开始证明自己在学习此类表示方面很有用(参见 C. Guo 和 F. Berkhahn 的论文“分类变量的实体嵌入”)。这些表示已被证明可以提高使用它们而不是其他编码方案的模型的性能。
最后,应该将更复杂的特征(例如日期)转换为一些捕捉其显着特征的数字特征。
让我们来看一个表格数据矢量化的实际例子。您可以在本书的 GitHub 存储库中的表格数据矢量化笔记本中找到该示例的代码。
假设我们不想查看问题的内容,而是想预测问题将从其标签、评论数量和创建日期获得的分数。在表 4-3中,您可以看到这个数据集对于writers.stackexchange.com数据集的外观示例。
| ID | Tags | CommentCount | CreationDate | Score |
|---|---|---|---|---|
| 1 | <resources><first-time-author> | 7 | 2010-11-18T20:40:32.857 | 32 |
| 2 | <fiction><grammatical-person><third-person> | 0 | 2010-11-18T20:42:31.513 | 20 |
| 3 | <publishing><novel><agent> | 1 | 2010-11-18T20:43:28.903 | 34 |
| 5 | <plot><short-story><planning><brainstorming> | 0 | 2010-11-18T20:43:59.693 | 28 |
| 7 | <fiction><genre><categories> | 1 | 2010-11-18T20:45:44.067 | 21 |
每个问题都有多个标签,以及一个日期和一些评论。让我们对每一个进行预处理。首先,我们规范化数字字段:
def get_norm(df, col):return (df[col] - df[col].mean()) / df[col].std()tabular_df["NormComment"]= get_norm(tabular_df, "CommentCount")
tabular_df["NormScore"]= get_norm(tabular_df, "Score")然后,我们从日期中提取相关信息。例如,我们可以选择发布的年、月、日和小时。其中每一个都是我们的模型可以使用的数值。
# Convert our date to a pandas datetime
tabular_df["date"] = pd.to_datetime(tabular_df["CreationDate"])# Extract meaningful features from the datetime object
tabular_df["year"] = tabular_df["date"].dt.year
tabular_df["month"] = tabular_df["date"].dt.month
tabular_df["day"] = tabular_df["date"].dt.day
tabular_df["hour"] = tabular_df["date"].dt.hour我们的标签是分类特征,每个问题都可能被赋予任意数量的标签。正如我们之前看到的,表示分类输入的最简单方法是对它们进行单热编码,将每个标签转换成它自己的列,只有当该标签与该问题相关联时,每个问题的给定标签特征的值为 1 .
因为我们的数据集中有三百多个标签,所以这里我们选择只为五百多个问题中使用的五个最受欢迎的标签创建一个列。我们可以添加每个标签,但是因为它们中的大多数只出现一次,所以这对识别模式没有帮助。
# Select our tags, represented as strings, and transform them into arrays of tags
tags = tabular_df["Tags"]
clean_tags = tags.str.split("><").apply(lambda x: [a.strip("<").strip(">") for a in x])# Use pandas' get_dummies to get dummy values
# select only tags that appear over 500 times
tag_columns = pd.get_dummies(clean_tags.apply(pd.Series).stack()).sum(level=0)
all_tags = tag_columns.astype(bool).sum(axis=0).sort_values(ascending=False)
top_tags = all_tags[all_tags > 500]
top_tag_columns = tag_columns[top_tags.index]# Add our tags back into our initial DataFrame
final = pd.concat([tabular_df, top_tag_columns], axis=1)# Keeping only the vectorized features
col_to_keep = ["year", "month", "day", "hour", "NormComment","NormScore"] + list(top_tags.index)
final_features = final[col_to_keep]在表 4-4中,您可以看到我们的数据现在已完全向量化,每一行仅包含数值。我们可以将此数据提供给聚类算法或受监督的 ML 模型。
| ID | Year | Month | Day | Hour | Norm-Comment | Norm-Score | Creative writing | Fiction | Style | Char-acters | Tech-nique | 小说 | 出版 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2010 | 11 | 18 | 20 | 0.165706 | 0.140501 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2010 | 11 | 18 | 20 | -0.103524 | 0.077674 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 2010 | 11 | 18 | 20 | -0.065063 | 0.150972 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 5 | 2010 | 11 | 18 | 20 | -0.103524 | 0.119558 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 2010 | 11 | 18 | 20 | -0.065063 | 0.082909 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
矢量化和数据泄漏
例如,在规范化数据时,您应该仅在训练集(使用相同的值规范化验证数据)和生产推理期间计算平均值和标准差等汇总统计数据。
使用验证数据和训练数据进行归一化,或者决定将哪些类别保留在单热编码中,会导致数据泄漏,因为您会利用来自训练集外部的信息来创建训练特征。这会人为地提高模型的性能,但会使其在生产中表现更差。我们将在“数据泄露”中更详细地介绍这一点。
文本数据
这矢量化文本的最简单方法就是用一个count vector,相当于one-hot encoding的词。首先构建一个由数据集中唯一单词列表组成的词汇表。将我们词汇表中的每个单词关联到一个索引(从 0 到我们词汇表的大小)。然后,您可以用与我们的词汇量一样长的列表来表示每个句子或段落。对于每个句子,每个索引处的数字表示给定句子中相关单词的出现次数。
这个方法忽略了句子中单词的顺序,因此被称为词袋。图 4-5显示了两个句子及其词袋表示。两个句子都被转换为包含有关单词在句子中出现次数的信息的向量,但不包含单词在句子中出现的顺序。

图 4-5。从句子中获取词袋向量
使用使用 scikit-learn 可以很简单地使用 scikit-learn 来表示词袋或其规范化版本 TF-IDF(术语频率 - 逆文档频率的缩写),如您所见:
# Create an instance of a tfidf vectorizer,
# We could use CountVectorizer for a non normalized version
vectorizer = TfidfVectorizer()# Fit our vectorizer to questions in our dataset
# Returns an array of vectorized text
bag_of_words = vectorizer.fit_transform(df[df["is_question"]]["Text"])具体来说,这个通过学习每个单词的向量并训练模型使用周围单词的单词向量来预测句子中缺失的单词来完成。要考虑的相邻单词的数量称为窗口大小。在图 4-6中,您可以看到窗口大小为 2 时此任务的描述。在左边,目标前后两个词的词向量被馈送到一个简单的模型。然后优化这个简单的模型和词向量的值,使输出匹配缺失词的词向量。
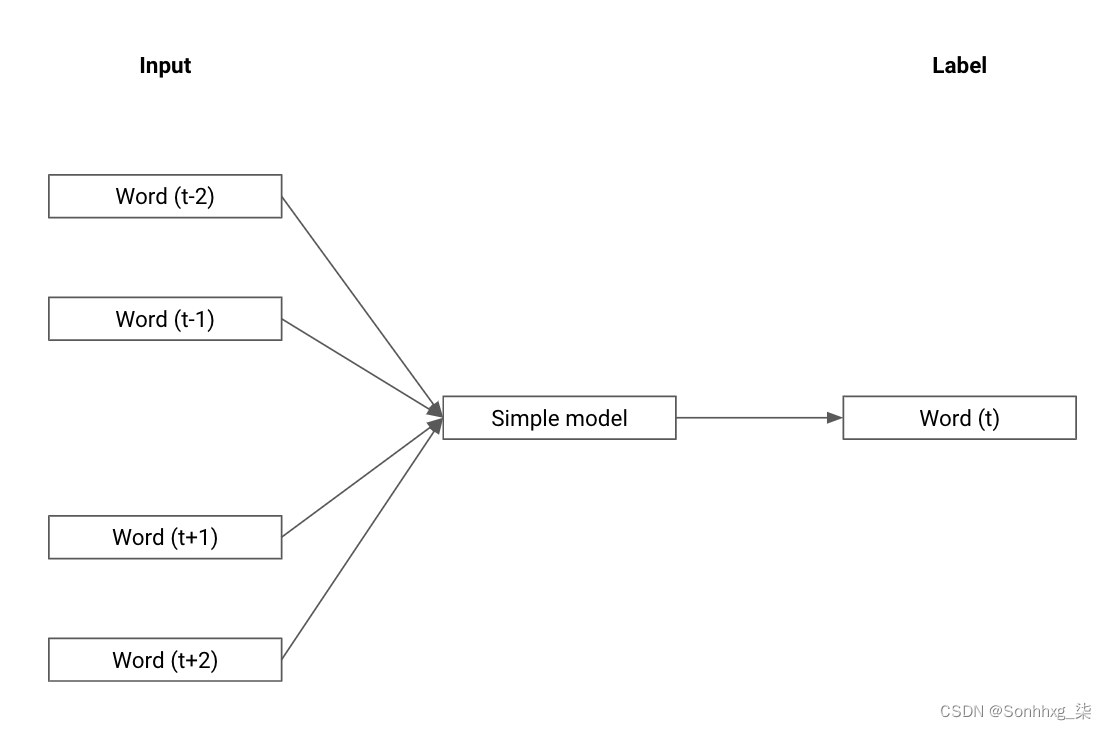
图 4-6。学习词向量,来自Mikolov 等人的 Word2Vec 论文“Efficient Estimation of Word Representations in Vector Space”。
存在许多开源的预训练词向量化模型。使用由在大型语料库(通常是维基百科或新闻故事档案)上预训练的模型生成的向量可以帮助我们的模型更好地利用常用词的语义。
例如,Joulin 等人提到的词向量。fastText文件可以在一个独立的工具中在线获得。为了更个性化方法,spaCy是一个 NLP 工具包,可为各种任务提供预训练模型,以及构建您自己的模型的简单方法。
下面是一个使用 spaCy 加载预训练词向量并使用它们得到语义上有意义的句子向量的示例。在引擎盖下,spaCy 检索我们数据集中每个单词的预训练值(如果它不是其预训练任务的一部分,则忽略它)并对问题中的所有向量进行平均以获得问题的表示。
import spacy# We load a large model, and disable pipeline unnecessary parts for our task
# This speeds up the vectorization process significantly
# See https://spacy.io/models/en#en_core_web_lg for details about the model
nlp = spacy.load('en_core_web_lg', disable=["parser", "tagger", "ner","textcat"])# We then simply get the vector for each of our questions
# By default, the vector returned is the average of all vectors in the sentence
# See https://spacy.io/usage/vectors-similarity for more
spacy_emb = df[df["is_question"]]["Text"].apply(lambda x: nlp(x).vector)查看 TF-IDF 模型与预训练模型的比较我们数据集的词嵌入,请参考本书 GitHub 存储库中的矢量化文本笔记本。
自从2018 年,在更大的数据集上使用大型语言模型的词向量化已经开始产生最准确的结果(参见 J. Howard 和 S. Ruder 的论文“Universal Language Model Fine-Tuning for Text Classification”和“BERT: Pre-用于语言理解的深度双向变换器的训练”,J. Devlin 等人)。然而,这些大型模型确实存在比简单的词嵌入更慢、更复杂的缺点。
最后,让我们检查另一种常用数据类型图像的矢量化。
图像数据
图片数据已经矢量化,因为图像只不过是一个多维数字数组,在 ML 社区中通常称为张量。最标准的三通道例如,RGB 图像被简单地存储为一个长度等于图像高度(以像素为单位)乘以其宽度再乘以三(对于红色、绿色和蓝色通道)的数字列表。在图 4-7中,您可以看到我们如何将图像表示为数字张量,代表三种原色中每一种的强度。
虽然我们可以按原样使用这种表示,但我们希望我们的张量能够捕捉到更多关于图像语义的信息。为此,我们可以使用一种类似于文本的方法,并利用大型预训练神经网络。
最后,倒数第二层被传递给一个函数,为每个类生成分类概率。因此,倒数第二层包含图像的表示,足以对其包含的对象进行分类,这使其成为其他任务的有用表示。

图 4-7。将 3 表示为从 0 到 1 的值矩阵(仅显示红色通道)
事实证明,提取该表示层在为图像生成有意义的向量方面非常有效。除了加载预训练模型外,这不需要任何自定义工作。在图 4-8中,每个矩形代表其中一个预训练模型的不同层。突出显示了最有用的表示。它通常位于分类层之前,因为这是需要最好地总结图像以使分类器表现良好的表示。
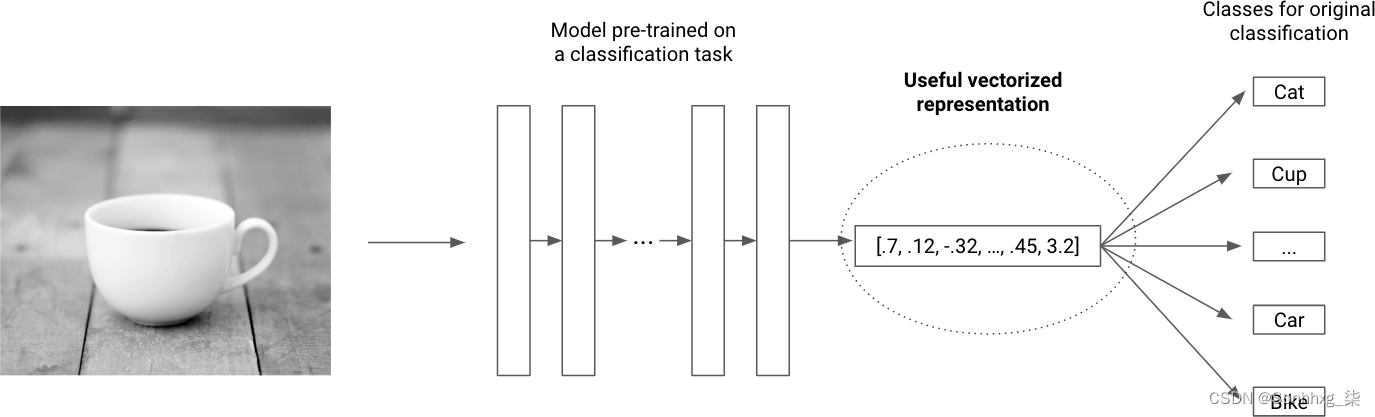
图 4-8。使用预训练模型对图像进行矢量化
使用Keras 等现代库使这项任务变得更加容易。这是一个函数,它使用 Keras 中可用的预训练网络从文件夹加载图像并将它们转换为具有语义意义的向量以供下游分析:
import numpy as npfrom keras.preprocessing import image
from keras.models import Model
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_inputdef generate_features(image_paths):"""Takes in an array of image pathsReturns pretrained features for each image:param image_paths: array of image paths:return: array of last-layer activations,and mapping from array_index to file_path"""images = np.zeros(shape=(len(image_paths), 224, 224, 3))# loading a pretrained modelpretrained_vgg16 = VGG16(weights='imagenet', include_top=True)# Using only the penultimate layer, to leverage learned featuresmodel = Model(inputs=pretrained_vgg16.input,outputs=pretrained_vgg16.get_layer('fc2').output)# We load all our dataset in memory (works for small datasets)for i, f in enumerate(image_paths):img = image.load_img(f, target_size=(224, 224))x_raw = image.img_to_array(img)x_expand = np.expand_dims(x_raw, axis=0)images[i, :, :, :] = x_expand# Once we've loaded all our images, we pass them to our modelinputs = preprocess_input(images)images_features = model.predict(inputs)return images_features迁移学习
预训练模型对于向量化我们的数据很有用,但有时它们也可以完全适应我们的任务。迁移学习是将先前在一个数据集或任务上训练过的模型用于不同的数据集或任务的过程。迁移学习不仅仅是简单地重复使用相同的架构或管道,它还使用先前学习的训练模型的权重作为新任务的起点。
转移学习在理论上可以从任何任务工作到任何其他任务,但它通常用于提高较小数据集的性能,方法是从大型数据集转移权重,例如用于计算机视觉的ImageNet或用于 NLP 的 WikiText。
虽然迁移学习通常会提高性能,但它也可能会引入额外的有害偏见来源。即使您仔细清理当前的数据集,如果您使用的模型是在整个维基百科上预训练的,例如,它可能会携带那里显示的性别偏见(参见文章“神经自然语言处理中的性别偏见” ”,作者:K. Lu 等人)。
有了矢量化表示后,您可以对其进行聚类或将数据传递给模型,但您也可以使用它来更有效地检查数据集。通过将具有相似表示的数据点分组在一起,您可以更快地查看数据集中的趋势。接下来我们将看看如何做到这一点。
降维
有矢量表示对于算法来说是必需的,但我们也可以利用这些表示来直接可视化数据!这似乎具有挑战性,因为我们描述的向量通常在两个以上的维度上,这使得它们很难在图表上显示。我们如何显示一个 14 维向量?
Geoffrey Hinton 因其在深度学习方面的工作而获得图灵奖,他在演讲中承认了这个问题并给出了以下提示:“要处理 14 维空间中的超平面,请想象一个 3D 空间,然后对自己说14高声。每个人都这样做。” (参见 G. Hinton 等人的演讲中的幻灯片 16,“神经网络架构的主要类型概述”在这里。)如果这对你来说似乎很难,你会很高兴听到降维,这是以更少的维度表示向量同时尽可能多地保留其结构的技术。
维数减少技术,例如 t-SNE(参见 L. van der Maaten 和 G. Hinton 的论文,PCA,“使用 t-SNE 可视化数据”)和UMAP(参见 L. McInnes 等人的论文,“UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction”)允许您在二维平面上投影高维数据,例如代表句子、图像或其他特征的向量。
这些投影有助于发现您随后可以调查的数据模式。但是,它们是真实数据的近似表示,因此您应该通过使用其他方法查看此类图来验证您所做的任何假设。例如,如果您看到所有属于一个类的点簇似乎具有共同特征,请检查您的模型是否确实利用了该特征。
首先,使用降维技术绘制数据,并根据您要检查的属性为每个点着色。对于分类任务,首先根据其标签为每个点着色。例如,对于无监督任务,您可以根据您正在查看的给定特征的值对点进行着色。这使您可以查看是否有任何区域看起来很容易让您的模型分离,或者更棘手。
以下是如何使用 UMAP 轻松完成此操作,将我们在“矢量化”中生成的嵌入传递给它:
import umap# Fit UMAP to our data, and return the transformed data
umap_emb = umap.UMAP().fit_transform(embeddings)fig = plt.figure(figsize=(16, 10))
color_map = {True: '#ff7f0e',False:'#1f77b4'
}
plt.scatter(umap_emb[:, 0], umap_emb[:, 1],c=[color_map[x] for x in sent_labels],s=40, alpha=0.4)提醒一下,我们决定开始时只使用来自 Stack Exchange 作者社区的数据。该数据集的结果显示在图 4-9中。乍一看,我们可以看到一些我们应该探索的区域,比如左上角未回答问题的密集区域。如果我们能够确定它们具有哪些共同特征,我们可能会发现有用的分类特征。
在对数据进行矢量化和绘图后,开始系统地识别相似数据点组并探索它们通常是个好主意。我们可以简单地通过查看 UMAP 图来做到这一点,但我们也可以利用聚类。
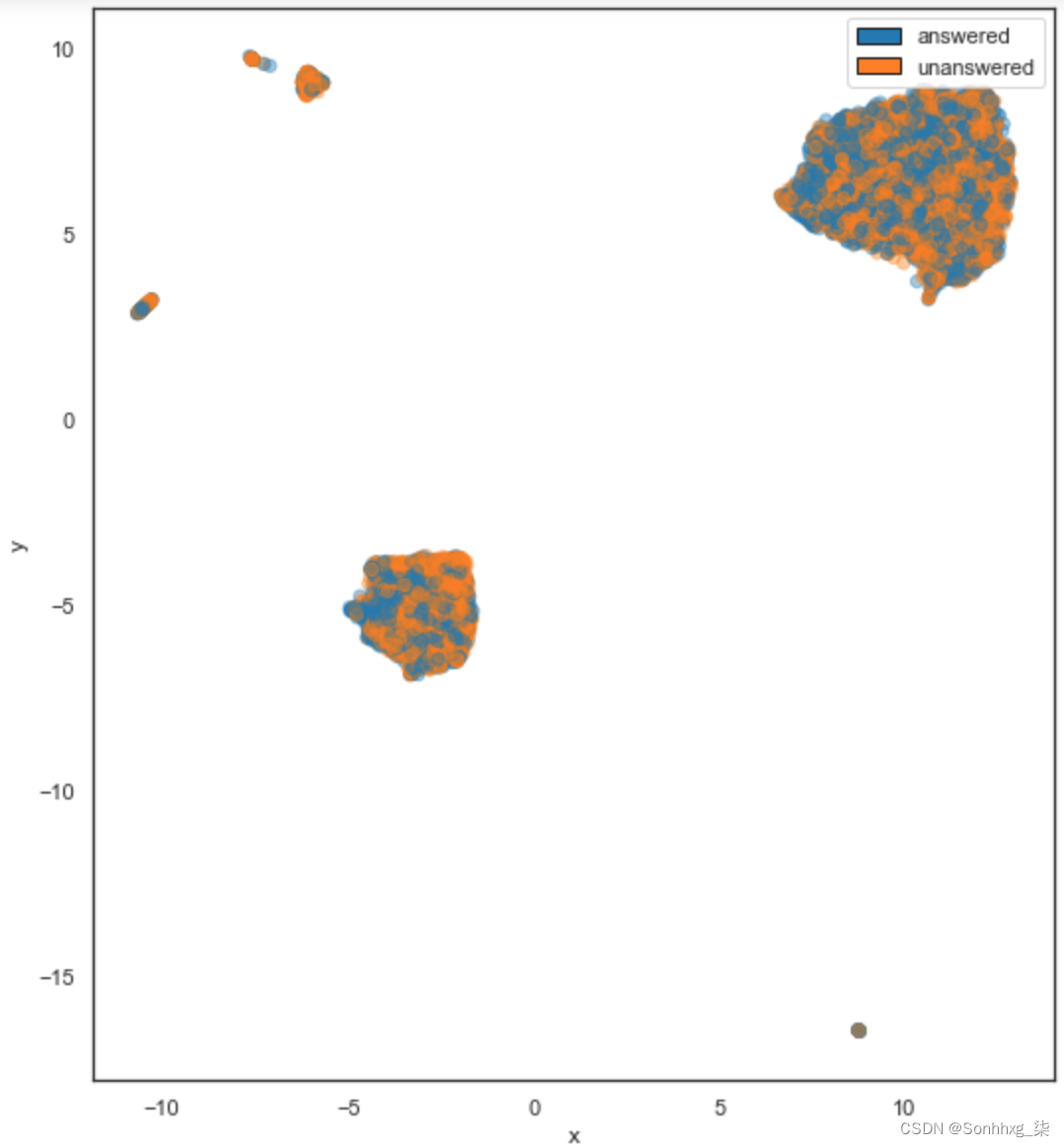
图 4-9。根据给定问题是否已成功回答着色的 UMAP 图
聚类
一个在实践中对数据进行聚类的简单方法是从尝试一些简单的算法(例如k-means )开始,然后调整它们的超参数(例如聚类数量),直到达到令人满意的性能。
聚类性能很难量化。在实践中,结合使用数据可视化和肘部方法或剪影图等方法就足以满足我们的用例,这不是为了完美地分离我们的数据,而是为了识别我们的模型可能存在问题的区域。
以下是一个示例代码片段,用于对我们的数据集进行聚类,以及使用我们之前描述的维数技术 UMAP 可视化我们的聚类。
from sklearn.cluster import KMeans
import matplotlib.cm as cm# Choose number of clusters and colormap
n_clusters=3
cmap = plt.get_cmap("Set2")# Fit clustering algorithm to our vectorized features
clus = KMeans(n_clusters=n_clusters, random_state=10)
clusters = clus.fit_predict(vectorized_features)# Plot the dimentionality reduced features on a 2D plane
plt.scatter(umap_features[:, 0], umap_features[:, 1],c=[cmap(x/n_clusters) for x in clusters], s=40, alpha=.4)
plt.title('UMAP projection of questions, colored by clusters', fontsize=14)正如您在图 4-10中所见,我们本能地对 2D 表示进行聚类的方式并不总是与我们的算法在矢量化数据上找到的聚类相匹配。这可能是因为我们的降维算法中的伪影或复杂的数据拓扑。事实上,将点的分配集群添加为特征有时可以通过利用所述拓扑来提高模型的性能。
拥有集群后,检查每个集群并尝试确定每个集群的数据趋势。为此,您应该为每个聚类选择几个点,就好像您是模型一样,从而用您认为正确答案应该是什么来标记这些点。在下一节中,我将描述如何进行此标记工作。
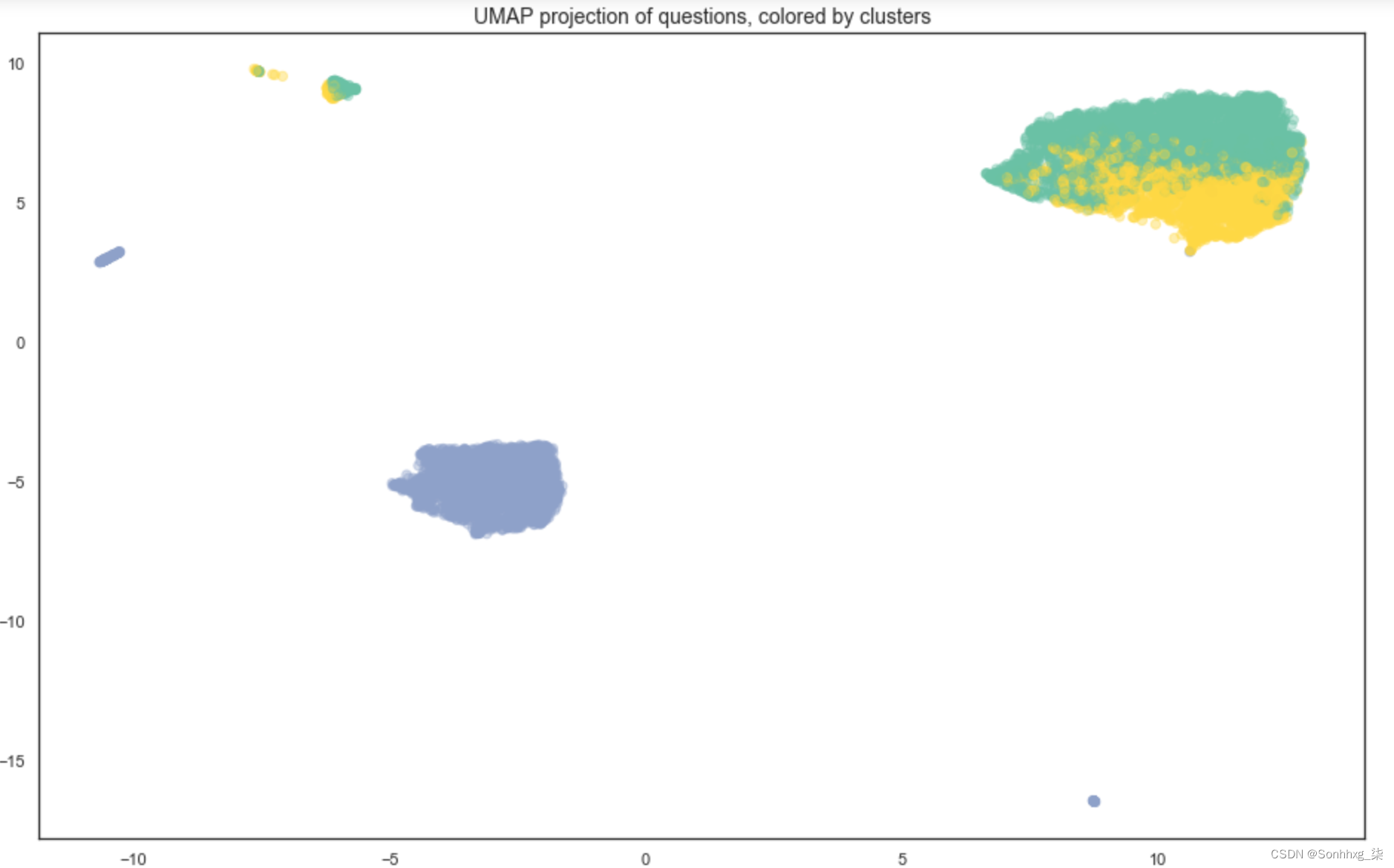
图 4-10。可视化我们的问题,按集群着色
成为算法
一次您已经查看了聚合指标和集群信息,我鼓励您遵循“Monica Rogati :如何选择 ML 项目并确定其优先级”中的建议,并尝试通过以下方式完成模型的工作用您希望模型产生的结果标记每个集群中的几个数据点。
如果您从未尝试执行您的算法的工作,将很难判断其结果的质量。另一方面,如果您花一些时间自己标记数据,您通常会注意到一些趋势,这些趋势将使您的建模任务变得更加容易。
您可能会从我们之前关于启发式的部分中认识到这个建议,您应该不会感到惊讶。选择建模方法涉及对我们的数据做出几乎与构建启发式方法一样多的假设,因此这些假设由数据驱动是有意义的。
即使您的数据集包含标签,您也应该标记数据。这使您可以验证您的标签确实捕获了正确的信息并且它们是正确的。在我们的案例研究中,我们使用问题的分数来衡量其质量,这是一个弱标签。我们自己标记几个例子将使我们能够验证这个标签是合适的假设。
标记了几个示例后,请随时通过添加您发现的任何功能来更新您的矢量化策略,以帮助使您的数据表示尽可能提供信息,然后返回标记。这是一个迭代过程,如图 4-11 所示。
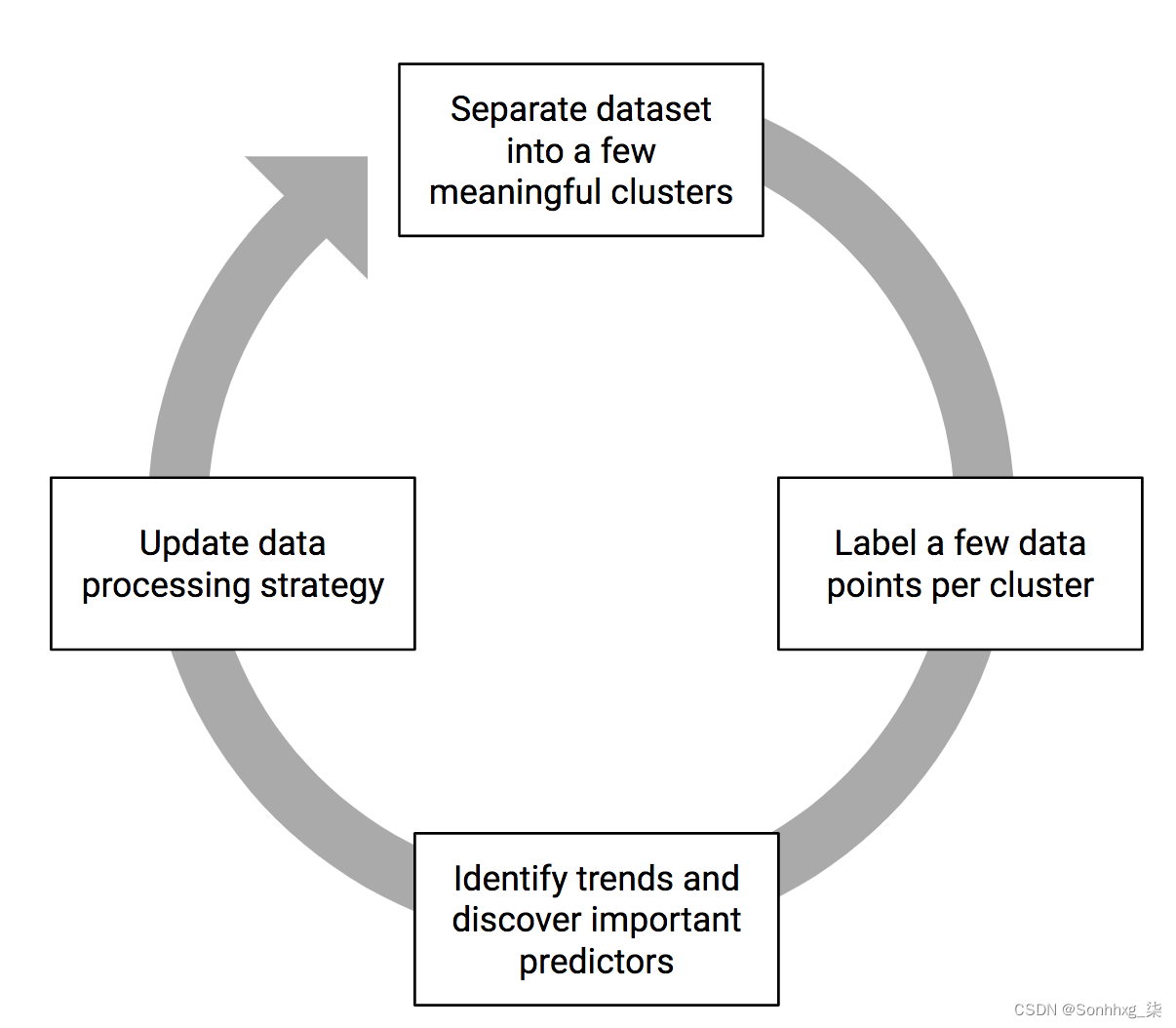
图 4-11。标注数据的过程
要加快标记速度,请确保通过标记您已识别的每个集群中的几个数据点以及特征分布中的每个公共值来利用您之前的分析。
一种方法是利用可视化库以交互方式探索您的数据。Bokeh提供了制作交互式绘图的能力。标记数据的一种快速方法是浏览我们的矢量化示例图,为每个集群标记几个示例。
图 4-12显示了一组大多数未回答的问题中的一个代表性个体示例。该集群中的问题往往非常模糊,难以客观回答,因此没有得到答案。这些被准确地标记为糟糕的问题。至查看此图的源代码及其在 ML 编辑器中的使用示例,导航至本书 GitHub 存储库中的探索数据以生成特征笔记本。
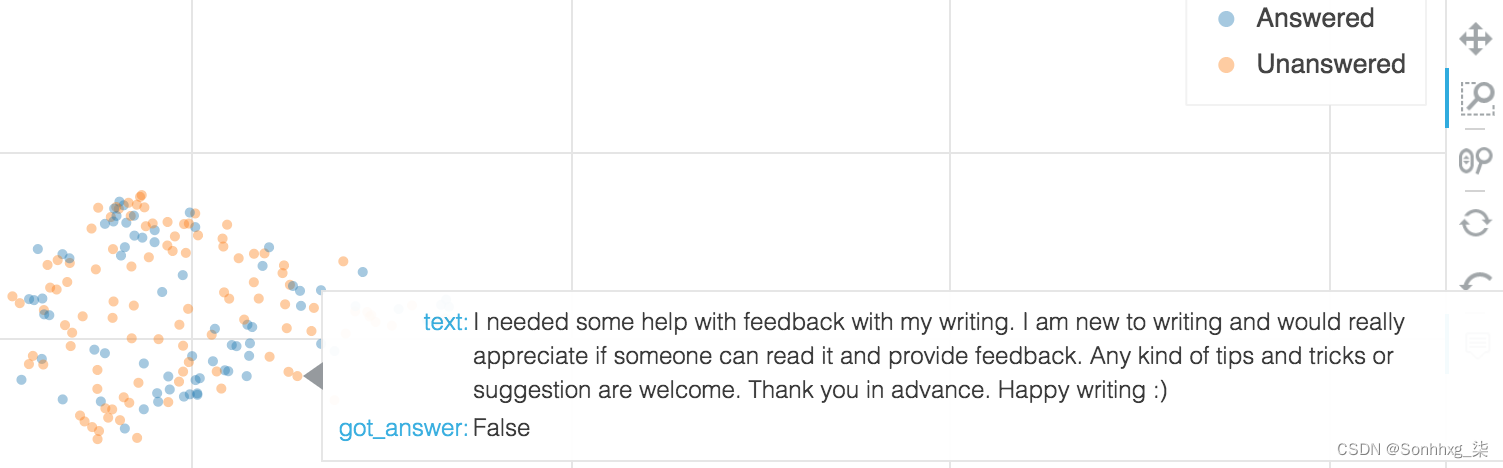
图 4-12。使用 Bokeh 检查和标记数据
标记数据时,您可以选择将标签与数据本身一起存储(例如,作为 DataFrame 中的附加列)或单独使用从文件或标识符到标签的映射。这纯粹是偏好问题。
当你标记例子时,试着注意你正在使用哪个过程来做出你的决定。这将有助于识别趋势并生成有助于您的模型的特征。
数据趋势
后标记数据一段时间后,您通常会发现趋势。有些可能会提供信息(简短的推文往往更容易分类为正面或负面)并指导您为模型生成有用的特征。由于收集数据的方式,其他可能是不相关的相关性。
也许我们收集的所有法语推文恰好都是负面的,这可能会导致模型自动将法语推文归类为负面推文。我会让你决定在更广泛、更具代表性的样本上可能有多不准确。
如果您发现任何此类情况,请不要绝望!在开始构建模型之前识别这些趋势至关重要,因为它们会人为地提高训练数据的准确性,并可能导致您将性能不佳的模型投入生产。
处理这种有偏见的例子的最好方法是收集额外的数据,使你的训练集更具代表性。您也可以尝试从训练数据中消除这些特征以避免模型产生偏差,但这在实践中可能并不有效,因为模型经常通过利用与其他特征的相关性来识别偏差(参见第 8 章)。
一旦确定了一些趋势,就该使用它们了。大多数情况下,您可以通过以下两种方式之一来做到这一点:创建一个表征该趋势的特征或使用一个可以轻松利用它的模型。
让数据告知特征和模型
我们希望使用我们在数据中发现的趋势来告知我们的数据处理、特征生成和建模策略。首先,让我们看看如何生成有助于捕捉这些趋势的特征。
根据模式构建特征
这就是为什么 ML 的许多实际收益来自于生成额外的功能,这些功能将帮助我们的模型识别有用的模式。模型识别模式的难易程度取决于我们表示数据的方式以及我们拥有的数据量。您拥有的数据越多,数据的噪声越小,您通常需要做的特征工程工作就越少。
然而,从生成特征开始通常是有价值的;首先是因为我们通常会从一个小数据集开始,其次是因为它有助于编码我们对数据的信念并调试我们的模型。
季节性是受益于特定特征生成的普遍趋势。假设一家在线零售商注意到他们的大部分销售发生在该月的最后两个周末。在构建预测未来销售的模型时,他们希望确保它有可能捕捉到这种模式。
正如您将看到的,根据它们表示日期的方式,这项任务对于他们的模型来说可能非常困难。大多数模型只能接受数字输入(有关将文本和图像转换为数字输入的方法,请参阅“矢量化”),所以让我们研究几种表示日期的方法。
原始日期时间
这表示时间的最简单方法是使用Unix 时间,它表示“自 1970 年 1 月 1 日星期四 00:00:00 以来经过的秒数”。
虽然这种表示很简单,但我们的模型需要学习一些相当复杂的模式来识别该月的最后两个周末。例如2018年最后一个周末(29日00:00:00到12月30日23:59:59),Unix时间表示范围为1546041600到1546214399(你可以验证如果你取两个数字之间的差值,表示以秒为单位的 23 小时 59 分 59 秒间隔)。
这个范围并没有使它特别容易与其他月份的其他周末相关联,因此当使用 Unix 时间作为输入时,模型很难将相关周末与其他周末区分开来。我们可以通过生成特征来简化模型的任务。
提取星期几和一个月中的某一天
使我们的日期表示更清晰的一种方法是将星期几和月份中的某一天提取到两个单独的属性中。
例如,我们表示 2018 年 12 月 30 日 23:59:59 的方式将使用与之前相同的数字,以及表示星期几(例如 0 表示星期日)和 day 的两个附加值月 (30)。
这种表示形式将使我们的模型更容易了解与周末相关的值(星期日和星期六为 0 和 6)以及该月较晚的日期对应于更高的活动。
同样重要的是要注意,表征通常会给我们的模型带来偏差。例如,通过将星期几编码为数字,星期五(等于五)的编码将比星期一(等于一)的编码大五倍。这个数字尺度是我们表示的产物,并不代表我们希望我们的模型学习的东西。
特征交叉
尽管以前的表示使我们的模型的任务更容易,他们仍然必须学习星期几和一个月中的一天之间的复杂关系:高流量不会发生在月初的周末或工作日的晚些时候月。
一些模型(例如深度神经网络)利用特征的非线性组合,因此可以利用这些关系,但它们通常需要大量数据。解决此问题的常用方法是使任务更简单并引入功能组合。
特征交叉是通过将两个或多个特征相互相乘(交叉)而生成的特征。这种非线性特征组合的引入使我们的模型能够根据来自多个特征的值的组合更容易地进行区分。
在表 4-5中,您可以看到我们描述的每个表示如何寻找一些示例数据点。
| Human representation | Raw data (Unix datetime) | Day of week (DoW) | Day of month (DoM) | Cross (DoW / DoM) |
|---|---|---|---|---|
| 2018 年 12 月 29 日星期六 00:00:00 | 1,546,041,600 | 7 | 29 | 174 |
| 2018 年 12 月 29 日星期六 01:00:00 | 1,546,045,200 | 7 | 29 | 174 |
| … | … | … | … | … |
| 2018年12月30日,星期日,23:59:59 | 1,546,214,399 | 1 | 30 | 210 |
在图 4-13中,您可以看到这些特征值如何随时间变化,以及哪些特征值使模型更容易将特定数据点与其他数据点分开。
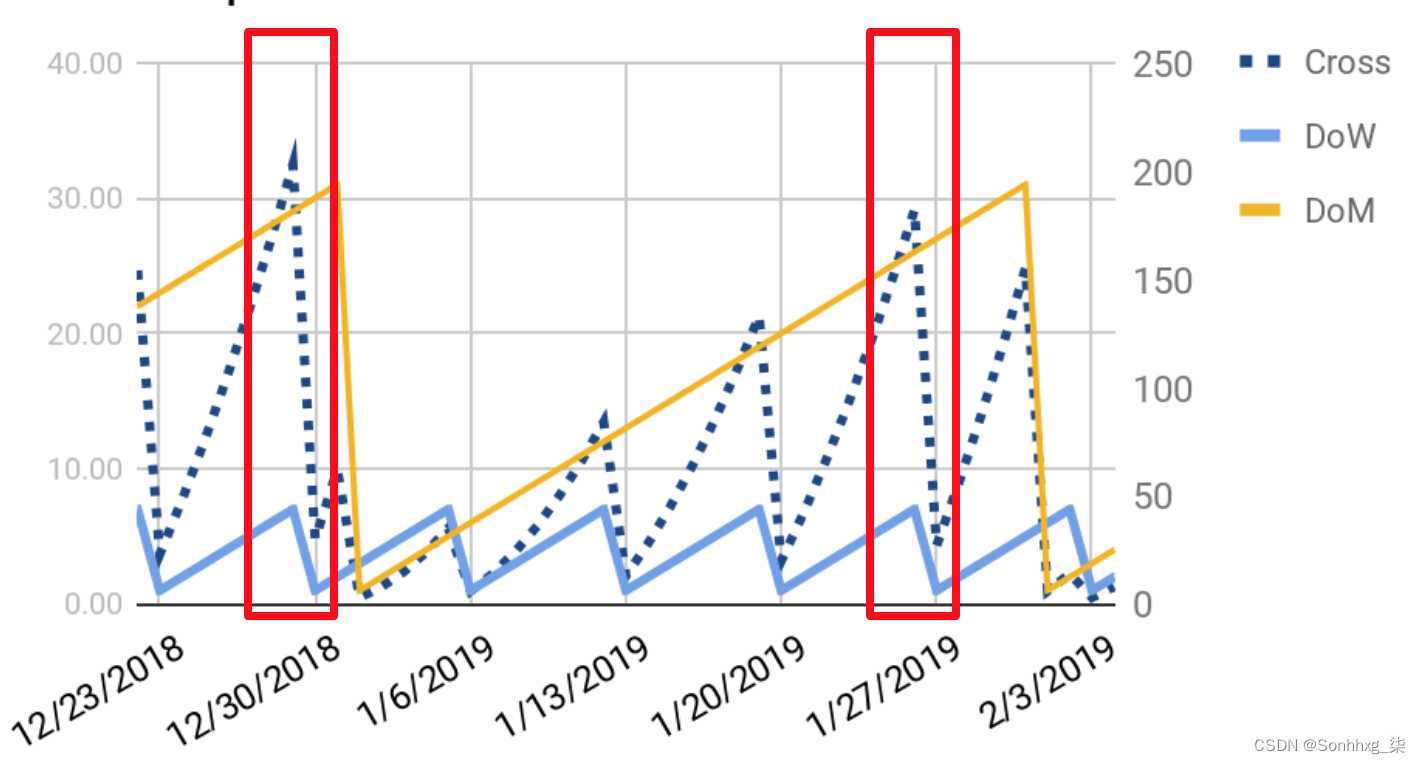
图 4-13。使用特征交叉和提取的特征更容易分离本月的最后一个周末
最后一种表示我们数据的方法将使我们的模型更容易学习该月最后两个周末的预测值。
给你的模型答案
这看起来像是作弊,但如果您知道某个特征值组合特别具有预测性这一事实,您可以创建一个新的二元特征,仅当这些特征采用相关值组合时才采用非零值。在我们的例子中,这意味着添加一个名为“is_last_two_weekends”的功能,例如,该功能将仅在该月的最后两个周末设置为一个。
如果最后两个周末像我们想象的那样具有预测性,该模型将简单地学习利用此功能并且会更加准确。在构建 ML 产品时,请毫不犹豫地简化模型的任务。最好有一个模型来处理更简单的任务,而不是一个在复杂任务上苦苦挣扎的模型。
特征生成是一个广泛的领域,大多数类型的数据都有方法。讨论为不同类型的数据生成有用的每个特征不在本书的范围之内。如果您想查看更多实用示例和方法,我建议您阅读 Alice Zheng 和 Amanda Casari 合着的机器学习特征工程(O'Reilly)。
通常,生成有用特征的最佳方法是使用我们描述的方法查看您的数据,并问自己最简单的方法是什么以一种能让您的模型学习其模式的方式来表示它。在下一节中,我将描述我使用此过程为 ML Editor 生成的几个特征示例。
ML 编辑器功能
为了我们的 ML 编辑器使用前面描述的技术来检查我们的数据集(请参阅本书的 GitHub 存储库中探索数据以生成特征笔记本中探索的详细信息),我们生成了以下特征:
-
诸如can和should之类的动作动词可以预测正在回答的问题,因此我们添加了一个二进制值来检查它们是否出现在每个问题中。
-
问号也是很好的预测指标,因此我们生成了一个
has_question特征。 -
有关正确使用英语的问题往往得不到答案,因此我们添加了一项
is_language_question功能。 -
问题文本的长度是另一个因素,非常短的问题往往没有答案。这导致增加了标准化问题长度特征。
-
在我们的数据集中,问题的标题也包含关键信息,并且在标记时查看标题使任务变得更加容易。这导致将标题文本包含在所有早期的特征计算中。
一旦我们有了一组初始特征,我们就可以开始构建模型。构建第一个模型是下一章第 5章的主题。
在继续学习模型之前,我想深入探讨如何收集和更新数据集这一主题。为此,我与该领域的专家罗伯特·蒙罗 (Robert Munro) 坐了下来。我希望您喜欢我们在这里讨论的总结,它让您兴奋地继续我们的下一部分,构建我们的第一个模型!
Robert Munro:您如何查找、标记和利用数据?
罗伯特·芒罗创办了多家人工智能公司,打造了一些人工智能领域的顶尖团队。他是 Figure Eight 的首席技术官,这是一家领先的数据标签公司,正处于其最大的增长时期。在此之前,罗伯特为 AWS 的第一个本地自然语言处理和机器翻译服务运行产品。在我们的谈话中,罗伯特分享了他在为 ML 构建数据集时学到的一些经验教训。
问:您如何开始 ML 项目?
答:最好的方法是从业务问题着手,因为它会给你工作的界限。在您的 ML 编辑器案例研究示例中,您是在编辑其他人提交后编写的文本,还是建议在其他人编写时实时编辑?第一个可以让您使用较慢的模型批处理请求,而第二个则需要更快的模型。
就模型而言,第二种方法会使序列到序列模型失效,因为它们太慢了。此外,如今的序列到序列模型无法超越句子级别的推荐,并且需要大量的平行文本进行训练。更快的解决方案是利用分类器并将其提取的重要特征用作建议。您希望从这个初始模型中得到的是一个简单的实现和您可以放心的结果,例如,从词袋特征上的朴素贝叶斯开始。
最后,您需要花一些时间查看一些数据并自己对其进行标记。这将使您对问题的难易程度以及哪些解决方案可能是合适的有一个直觉。
问:您需要多少数据才能开始?
答:收集数据时,您希望确保拥有具有代表性和多样性的数据集。首先查看您拥有的数据,看看是否有任何类型未被表示,以便您可以收集更多。对数据集进行聚类并查找异常值有助于加快此过程。
对于标记数据,在常见的分类情况下,我们已经看到在您的稀有类别的大约 1,000 个示例上进行标记在实践中效果很好。您至少会获得足够的信号来告诉您是否继续使用当前的建模方法。在大约 10,000 个示例中,您可以开始相信您正在构建的模型的信心。
随着您获得更多数据,您的模型的准确性将慢慢提高,从而为您提供性能如何随数据扩展的曲线。在任何时候你只关心曲线的最后一部分,它应该给你更多数据会给你的当前值的估计。在绝大多数情况下,通过标记更多数据获得的改进将比迭代模型更显着。
问:您使用什么过程来收集和标记数据?
答:您可以查看当前最好的模型,看看是什么导致了它失败。不确定性抽样是一种常见的方法:确定您的模型最不确定的示例(最接近其决策边界的示例),并找到类似的示例以添加到训练集中。
你还可以训练一个“错误模型”来找到更多你当前模型难以处理的数据。使用您的模型所犯的错误作为标签(将每个数据点标记为“预测正确”或“预测错误”)。一旦你在这些例子上训练了一个“错误模型”,你就可以在你的未标记数据上使用它,并标记它预测你的模型将失败的例子。
或者,您可以训练“标记模型”以找到接下来要标记的最佳示例。假设您有一百万个示例,您只标记了其中的 1,000 个。您可以创建一个包含 1,000 个随机抽样的标记图像和 1,000 个未标记图像的训练集,并训练一个二元分类器来预测您标记了哪些图像。然后,您可以使用此标记模型来识别与您已标记的内容最不同的数据点并标记它们。
问:您如何验证您的模型正在学习有用的东西?
答:一个常见的陷阱是最终将标记工作集中在相关数据集的一小部分上。您的模型可能难以处理有关篮球的文章。如果你继续注释更多的篮球文章,你的模型可能会变得擅长篮球,但在其他方面都很糟糕。这就是为什么虽然您应该使用策略来收集数据,但您应该始终从测试集中随机抽样以验证您的模型。
最后,最好的方法是跟踪已部署模型的性能何时发生漂移。您可以跟踪模型的不确定性,或者理想情况下将其带回业务指标:您的使用指标是否逐渐下降?这可能是由其他因素引起的,但这是调查和可能更新训练集的一个很好的触发因素。