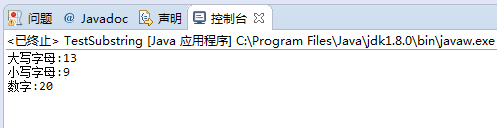
利用的是Unicode编码,Unicode 编码并不只是为某个字符简单定义了一个编码,而且还将其进行了归类。
\pP 其中的小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。
大写 P 表示 Unicode 字符集七个字符属性之一:标点字符。
其他六个是
L:字母;
M:标记符号(一般不会单独出现);
Z:分隔符(比如空格、换行等);
S:符号(比如数学符号、货币符号等);
N:数字(比如阿拉伯数字、罗马数字等);
C:其他字符
Java 中用于 Unicode 的正则表达式数据都是由 Unicode 组织提供的。
转:https://blog.csdn.net/tian330726/article/details/50906318
例:
public class main {public static void main(String[] argc) {String s="s!#!@#12 41 2;.>]] [tr哈哈哈i12321~!@~!¥#……*……ng";//String s0=s.substring(0, 1)+s.substring(2, s.length());String s0=s.replaceAll("\\pP|\\pS|\\pC|\\pN|\\pZ", "");System.out.println(s0);}}
输出:
str哈哈哈ing
过滤出字母:
[^(A-Za-z)]
过滤出中文:
[^(\\u4e00-\\u9fa5)]
过滤出数字:
[^(0-9)]
实例:
String s="12asdsa23哈哈12";String s1=s.replaceAll("[^(A-Za-z)]", "");String s2=s.replaceAll("[^(\\u4e00-\\u9fa5)]", "");String s3=s.replaceAll("[^(0-9)]", "");System.out.println(s1+" "+s2+" "+s3);
结果:
asdsa 哈哈 122312
转:https://www.cnblogs.com/shihaiming/p/6978517.html
删除中文:
String s2=s.replaceAll("[^(u4e00-u9fa5)]", "");