时隔2年多,偶然看到自己的这篇文章,看到下面好多求数据的同学,实在抱歉,一方面之前数据已经丢失,一方面个人博客许久未关注,故没有及时答复。
现在重新发送数据给各位同学,仅作学习使用,需要数据做美赛等数学建模的可以加Q群231436610。
想要完整代码 具体看我的项目 https://gitee.com/yzlit/tianyancha 天眼查爬虫程序,如果你需要更多数据,请帮我在Github点个star就行,可以免费发送行业TOP100企业信息数据和超过3万条的企业数据。
如果不会用git可以在这里下载 代码和数据
注意,上面的项目可以爬取天眼查全部企业数据和 行业TOP100的企业信息,clone下来按wiki指导就能正常运行,由于会定时更新,保证可用。
其他想要商业数据可能要抱歉了,一是数据量肯定达不到你们的要求,另一个本人只是给学习做数据分析的同学使用,。
好,话不多说,直接上代码.
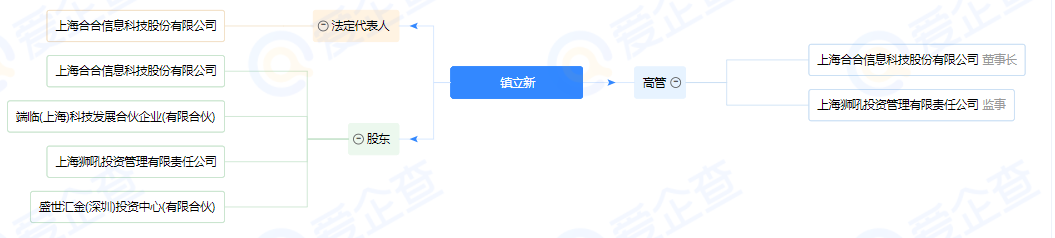
爬取效果如图

先看普通的请求代码,这里应该是爬虫都会用的通用模块,
# -*- coding: utf-8 -*-
import requests
import timecursor = 0
get_proxy_url = "http://这里是获取代理IP的网址,具体改refresh_proxy_ip()方法实现刷新代理IP"
proxy_id = ""# 请求url的html内容
def get_html(url):time.sleep(3)print(proxy_id)# 代理 IP ,具体刷新获取代理IP需要自己实现下面的refresh_proxy_ip() 函数proxy = {'http': 'http://'+proxy_id,'https': 'https://'+proxy_id}headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Encoding": "gzip, deflate, br","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "max-age=0","Connection": "keep-alive","Host": "www.tianyancha.com","Sec-Fetch-Dest": "document","Sec-Fetch-Mode": "navigate","Sec-Fetch-Site": "none","Sec-Fetch-User": "?1","Upgrade-Insecure-Requests": "1","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"}try:# response = requests.get(url, headers=headers, proxies=proxy)response = requests.get(url,headers=headers, proxies=proxy)except BaseException:print("异常发生")# 这里没有对异常情况作具体处理,只是直接换代理IP 重新请求 就完事昂refresh_proxy_ip()return get_html(url)if response.status_code is not 200:print("不正常")refresh_proxy_ip()return get_html(url)else:return response.textdef refresh_proxy_ip():global proxy_idtime.sleep(1)proxy_id = requests.get(get_proxy_url).text.replace(" ", "")print('代理ip请求异常,更换代理IP:http://' + proxy_id + "/")
然后才是对公司url的html内容进行解析,这个没有技巧,一个一个看html结构,有时候天眼查也会反爬做更新,需要及时修改,2020-09-06生效代码如下
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from mysql import *
from get_html import *def get_info(url):html = get_html(url, 1)soup = BeautifulSoup(html, 'html.parser')# print(html)# # 企业logo# logdiv = soup.find('div', class_="logo -w100")# imgsrc = ""# if logdiv is not None:# img = logdiv.find('img', class_="img")# if img is not None:# imgsrc = img.get('data-src')# # print(html)# else:# print("此页查找不到公司log logo -w100:", url)# 企业简介div = soup.find('div', id="nav-main-stockNum")if div is None:print("此页查找不到公司内容nav-main-stockNum:", url)# print(html)# refresh_proxy_ip()# return get_info(url)else:table = div.find('table', class_="table -striped-col")if table is None:print("此页查找不到公司内容 table -striped-col:", url)# refresh_proxy_ip()# return get_info(url)else:tds = table.find_all('td')if len(tds) <= 31:print("估计界面有问题:len(tds) <= 31", url)return TruecompCh = tds[1].get_text() # 公司全称compEn = tds[3].get_text() # 英文名称sscym = tds[5].get_text() # 上市曾用名gsdj = tds[7].get_text() # 工商登记zczb = tds[9].get_text() # 注册资本sshy = tds[11].get_text() # 所属行业dsz = tds[13].get_text() # 董事长dm = tds[15].get_text() # 董秘fddbr = tds[17].get_text() # 法定代表人zjl = tds[19].get_text() # 总经理ygrs = tds[21].get_text() # 员工人数glryrs = tds[23].get_text() # 管理人员人数kggd = tds[25].get_text().replace(" ", "") # 控股股东sjkzr = tds[27].get_text().replace(" ", "") # 实际控制人zzkzr = tds[29].get_text().replace(" ", "") # 最终控制人zyyw = tds[31].get_text().replace(" ", "") # 主营业务'desc = (compCh, compEn, sscym, gsdj, zczb, sshy, dsz, dm, fddbr, zjl, ygrs, glryrs, kggd, sjkzr, zzkzr, zyyw, url)print(desc)update_company_qyjj(desc)# 证券信息div = soup.find('div', id="nav-main-secBasicInfoCount")if div is None or len(div) is 0:print("此页查找不到公司内容nav-main-secBasicInfoCount:", url)# print(html)# refresh_proxy_ip()# return get_info(url)else:table = div.find('table', class_="table -striped-col")if table is None or len(div) is 0:print("此页查找不到公司内容table -striped-col:", url)# print(html)else:tds2 = table.find_all('td')if len(tds) <= 13:print("估计界面有问题:len(tds) <= 13", url)return Trueagdm = tds2[1].get_text() # A股代码agjc = tds2[3].get_text() # A股简称bgdm = tds2[5].get_text() # B股代码bgjc = tds2[7].get_text() # B股简称hgdm = tds2[9].get_text() # H股代码hgjc = tds2[11].get_text() # H股简称zqlb = tds2[13].get_text() # 证券类别sec_info = (agdm, agjc, bgdm, bgjc, hgdm, hgjc, zqlb, url)print(sec_info)update_company_zqxx(sec_info)# 联系信息div = soup.find('div', id="_container_corpContactInfo")if div is None or len(div) is 0:print("此页查找不到公司内容 _container_corpContactInfo:", url)# print(html)# refresh_proxy_ip()# return get_info(url)else:table = div.find('table', class_="table -striped-col -breakall")if table is None or len(table) is 0:print("此页查找不到公司内容 table -striped-col -breakall:", url)# print(html)# refresh_proxy_ip()# return get_info(url)else:tds = table.find_all('td')if len(tds) <= 15:print("估计界面有问题:len(tds) <= 15", url)return Truelxdh = tds[1].get_text() # 联系电话dzyx = tds[3].get_text().replace(" ", "") # 电子邮箱cz = tds[5].get_text() # 传真gswz = tds[7].get_text() # 公司网址qy = tds[9].get_text() # 区域yzbm = tds[11].get_text() # 邮政编码bgdz = tds[13].get_text().replace(" ", "") # 办公地址zcdz = tds[15].get_text().replace(" ", "") # 注册地址contact_info = (lxdh, dzyx, cz, gswz, qy, yzbm, bgdz, zcdz, url)print(contact_info)update_company_lxxx(contact_info)# 公司背景div = soup.find('div', id="_container_baseInfo")if div is None:print("此页查找不到公司内容 _container_baseInfo:", url, "注意这个必须要查到哦哦哦哦哦哦哦!!!!!!!!!!!")# print(html)refresh_proxy_ip()return get_info(url)else:compChdiv = soup.find('div', class_="header")if compChdiv is None:print("此页查找不到公司全称呼 class_=header:", url, "注意这个必须要查到哦哦哦哦哦哦哦!!!!但先不刷新IP!")compCh= ""else:compCh = compChdiv.find('h1', class_="name").get_text()print(compCh)frdiv=div.find('div', class_="humancompany")if frdiv is None:print("此页查找不到公司法人 humancompany:", url, "注意这个必须要查到哦哦哦哦哦哦哦!!!!!!!!!!!")# print(html)refresh_proxy_ip()return get_info(url)table = div.find('table', class_="table -striped-col -border-top-none -breakall")if table is None:print("此页查找不到公司内容 table -striped-col -border-top-none -breakall:", url, "注意这个必须要查到哦哦哦哦哦哦哦!!!!!!!!!!!")# print(html)refresh_proxy_ip()return get_info(url)else:tds = table.find_all('td')fddbrr = frdiv.find('a', class_="link-click").get_text() # 法定代表人if len(tds) <= 40:print("估计界面有问题:len(tds) <= 40", url)exit(1)zczb1 = tds[1].get_text() # 注册资本sjzb1 = tds[3].get_text() # 实缴资本clrq1 = tds[6].get_text() # 成立日期jyzt1 = tds[8].get_text() # 经营状态tyshxxdm1 = tds[10].get_text() # 统一社会信用代码gszc1 = tds[12].get_text() # 工商注册号nsrsbh1 = tds[14].get_text() # 纳税人识别号zzjgdm1 = tds[16].get_text() # 组织机构代码gslx1 = tds[18].get_text().replace('\"', "") # 公司类型hy1 = tds[20].get_text() # 行业hzrq1 = tds[22].get_text() # 核准日期djjg1 = tds[24].get_text() # 登记机关yyqx1 = tds[26].get_text() # 营业期限nsrzz1 = tds[28].get_text() # 纳税人资质rygm1 = tds[30].get_text() # 人员规模cbrs1 = tds[32].get_text() # 参保人数cym1 = tds[34].get_text() # 曾用名ywmc1 = tds[36].get_text() # 英文名称zcdz1 = tds[38].get_text() # 注册地址jyfw1 = tds[40].get_text() # 经营范围 需要很大的空间 2000data = (compCh, fddbrr, zczb1, sjzb1, clrq1, jyzt1, tyshxxdm1, gszc1, nsrsbh1, zzjgdm1, gslx1, hy1, hzrq1, djjg1, yyqx1, nsrzz1, rygm1, cbrs1, cym1, ywmc1, zcdz1, jyfw1, True, url)print(data)update_company_qybj(data)return True
代码注释已经打的比较详细,可以直接看。
上面的代码对异常情况的处理并没有太细致,爬取结果还需要数据预处理,尤其是天眼查煞笔的数据加密,
上面加密的数据有,注册资本,注册时间,营业期限,加密方法贼原始,
我遇到的加密是,
数字加密方式密文 明文7 4
5 8
4 .
3 9
0 1
. 5
9 2
6 0
1 3
8 6
2 7就这么简单,哈哈哈,发现这个时没笑死我。这个解码的操作较为简单,小伙伴自己去操练去吧。
有人说,为啥不去爬国家企业信用信息公示系统,原因只有一个,我实在懒得去搞什么滑动验证码,文字点击验证码,看着就烦,(注定无法成为爬虫工程师)需要的伙伴可以看这位老兄的博客,他的说已经失效了,可以借鉴点经验,【爬虫】关于企业信用信息公示系统-加速乐最新反爬虫机制
另外,如果有小伙伴实在不想自己爬数据的,只想要数据的,可以私信或者找我要,这次消息我都会收到,
没错我还真的想过去买点数据应付一下建模,不过看到价格,基本就放弃了

关于如何爬取天眼查90%企业爬虫思路:
就是根据天眼查的条件不断细化,如下细化到行业—》行业子类—》省—》市—》区、县—》分页,基本数据量也5页左右100个公司左右,当然你也可以更细化


如图上条件,已经剩6页,而天眼查不登录请款下只能看5页。
首先是行业,行业有96个:url都是类似:https://www.tianyancha.com/search/oc06 也就是oc+两位数字。

接下来是省:类似吉林省 jl:https://www.tianyancha.com/search/oc06?base=jl
接下来是市:吉林省四平市: https://www.tianyancha.com/search/oc06?base=siping
接下来是区:吉林省四平市铁西区:https://www.tianyancha.com/search/oc06?base=siping&areaCode=220302
接下来是分页:比如第四页p4:https://www.tianyancha.com/search/oc01/p4?base=guangzhou&areaCode=440106
接下来就是每一页的公司url:一般一页有20个公司:https://www.tianyancha.com/company/2782669177
最后就是爬取每一个公司的信息并保存起来了:
把上面每一步爬到先保存到数据库作为准备爬取的页面,即可:
如我上面项目提到的main.py,以下方法你可以用多进程按省1:市区5:分页:25-》公司50来规划分布式机器爬虫。 当然你得够有钱,买得起这么多服务器和代理IP池。
if __name__ == '__main__':# 一步 一步 爬取所有天眼查所有公司,极其变态# 把数据库表建好,然后跑这个程序,下面五个可以分五条线程 按先后顺序启动 即可get_city_to_mysql() # 爬取行业-》省份 urlget_qu_to_mysql() # 爬取行业-》省份-》市 -》区 urlget_page_to_mysql() # 爬取行业-》省份-》市 -》区-》分页 urlget_company_to_mysql() # 爬取行业-》省份-》市 -》区-》分页->公司列表 urlget_company_info_to_mysql() # 爬取公司信息 url