MIT 6.S081 教材第八章内容 -- 文件系统 -- 01
- 引言
- 概述
- Buffer cache层
- 代码:Buffer cache
- 日志层
- 日志设计
- 代码:日志
- 代码:块分配器
引言
MIT 6.S081 2020 操作系统
本文为MIT 6.S081课程第八章教材内容翻译加整理。
本课程前置知识主要涉及:
- C语言(建议阅读C程序语言设计—第二版)
- RISC-V汇编
- 推荐阅读: 程序员的自我修养-装载,链接与库
文件系统的目的是组织和存储数据。文件系统通常支持用户和应用程序之间的数据共享,以及持久性,以便在重新启动后数据仍然可用。
xv6文件系统提供类似于Unix的文件、目录和路径名,并将其数据存储在virtio磁盘上以便持久化。文件系统解决了几个难题:
注:完整计算机中的CPU被支撑硬件包围,其中大部分是以I/O接口的形式。Xv6是以qemu的“-machine virt”选项模拟的支撑硬件编写的。这包括RAM、包含引导代码的ROM、一个到用户键盘/屏幕的串行连接,以及一个用于存储的磁盘。
- 文件系统需要磁盘上的数据结构来表示目录和文件名称树,记录保存每个文件内容的块的标识,以及记录磁盘的哪些区域是空闲的。
- 文件系统必须支持崩溃恢复(crash recovery)。也就是说,如果发生崩溃(例如,电源故障),文件系统必须在重新启动后仍能正常工作。风险在于崩溃可能会中断一系列更新,并使磁盘上的数据结构不一致(例如,一个块在某个文件中使用但同时仍被标记为空闲)。
- 不同的进程可能同时在文件系统上运行,因此文件系统代码必须协调以保持不变量。
- 访问磁盘的速度比访问内存慢几个数量级,因此文件系统必须保持常用块的内存缓存。
本章的其余部分将解释xv6如何应对这些挑战。
概述
xv6文件系统实现分为七层,如图8.1所示。
磁盘层读取和写入virtio硬盘上的块。缓冲区高速缓存层缓存磁盘块并同步对它们的访问,确保每次只有一个内核进程可以修改存储在任何特定块中的数据。日志记录层允许更高层在一次事务(transaction)中将更新包装到多个块,并确保在遇到崩溃时自动更新这些块(即,所有块都已更新或无更新)。索引结点层提供单独的文件,每个文件表示为一个索引结点,其中包含唯一的索引号(i-number)和一些保存文件数据的块。目录层将每个目录实现为一种特殊的索引结点,其内容是一系列目录项,每个目录项包含一个文件名和索引号。路径名层提供了分层路径名,如/usr/rtm/xv6/fs.c,并通过递归查找来解析它们。文件描述符层使用文件系统接口抽象了许多Unix资源(例如,管道、设备、文件等),简化了应用程序员的工作。
| 文件描述符(File descriptor) |
|---|
| 路径名(Pathname) |
| 目录(Directory) |
| 索引结点(Inode) |
| 日志(Logging) |
| 缓冲区高速缓存(Buffer cache) |
| 磁盘(Disk) |
图8.1 XV6文件系统的层级
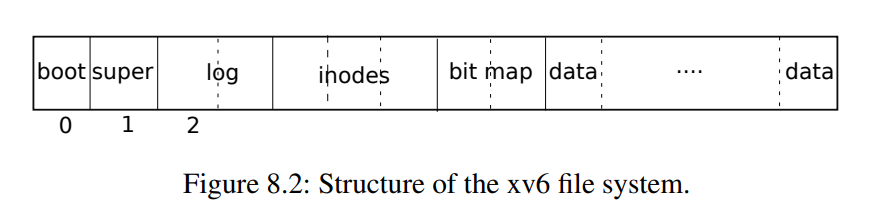
文件系统必须有将索引节点和内容块存储在磁盘上哪些位置的方案。为此,xv6将磁盘划分为几个部分,如图8.2所示。文件系统不使用块0(它保存引导扇区)。块1称为超级块:它包含有关文件系统的元数据(文件系统大小(以块为单位)、数据块数、索引节点数和日志中的块数)。从2开始的块保存日志。日志之后是索引节点,每个块有多个索引节点。然后是位图块,跟踪正在使用的数据块。其余的块是数据块:每个都要么在位图块中标记为空闲,要么保存文件或目录的内容。超级块由一个名为mkfs的单独的程序填充,该程序构建初始文件系统。
本章的其余部分将从缓冲区高速缓存层开始讨论每一层。注意那些在较低层次上精心选择的抽象可以简化较高层次的设计的情况。
Buffer cache层
Buffer cache有两个任务:
- 同步对磁盘块的访问,以确保磁盘块在内存中只有一个副本,并且一次只有一个内核线程使用该副本
- 缓存常用块,以便不需要从慢速磁盘重新读取它们。代码在bio.c中。
Buffer cache层导出的主接口主要是bread和bwrite;前者获取一个buf,其中包含一个可以在内存中读取或修改的块的副本,后者将修改后的缓冲区写入磁盘上的相应块。内核线程必须通过调用brelse释放缓冲区。Buffer cache每个缓冲区使用一个睡眠锁,以确保每个缓冲区(因此也是每个磁盘块)每次只被一个线程使用;bread返回一个上锁的缓冲区,brelse释放该锁。
让我们回到Buffer cache。Buffer cache中保存磁盘块的缓冲区数量固定,这意味着如果文件系统请求还未存放在缓存中的块,Buffer cache必须回收当前保存其他块内容的缓冲区。Buffer cache为新块回收最近使用最少的缓冲区。这样做的原因是认为最近使用最少的缓冲区是最不可能近期再次使用的缓冲区。
代码:Buffer cache
Buffer cache是以双链表表示的缓冲区。main(kernel/main.c:27)调用的函数binit使用静态数组buf(kernel/bio.c:43-52)中的NBUF个缓冲区初始化列表:
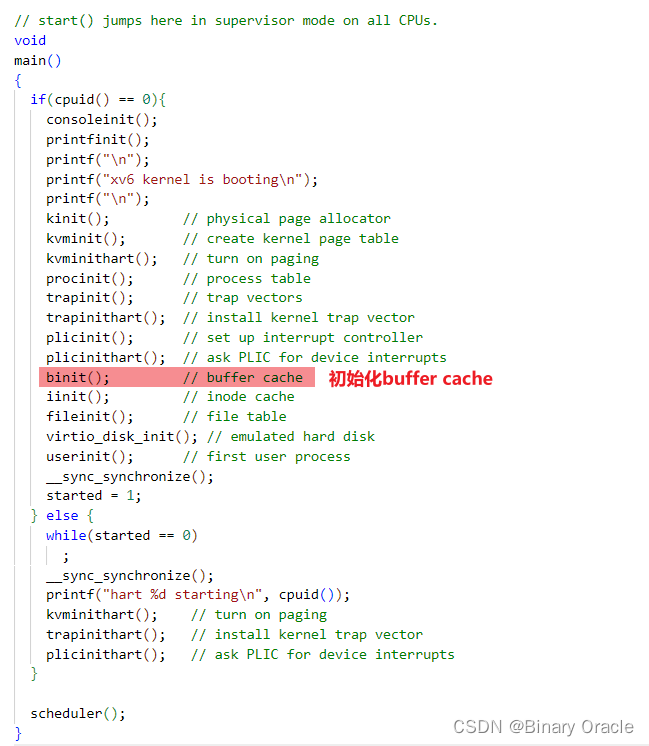
对Buffer cache的所有其他访问都通过bcache.head引用链表,而不是buf数组:
// kernel/param.h
#define MAXOPBLOCKS 10 // max # of blocks any FS op writes
#define NBUF (MAXOPBLOCKS*3) // size of disk block cache// kernel/bio.c
struct {// 保护buffer pool同一时刻只有一个内核线程访问struct spinlock lock;// buf数组 --- 大小为30struct buf buf[NBUF];// Linked list of all buffers, through prev/next.// Sorted by how recently the buffer was used.// head.next is most recent, head.prev is least.// 已分配buf串接而成的链表,按照最近最常使用进行排序struct buf head;
} bcache;// kernel/bio.cvoid
binit(void)
{struct buf *b;// 初始化buffer pool的锁资源initlock(&bcache.lock, "bcache");// Create linked list of buffers// 创建buf双向链表bcache.head.prev = &bcache.head;bcache.head.next = &bcache.head;// 组装buf链表,头插法for(b = bcache.buf; b < bcache.buf+NBUF; b++){b->next = bcache.head.next;b->prev = &bcache.head;// 初始化单个buf的锁资源initsleeplock(&b->lock, "buffer");bcache.head.next->prev = b;bcache.head.next = b;}
}
缓冲区有两个与之关联的状态字段。字段valid表示缓冲区是否包含块的副本。字段disk表示缓冲区内容是否已交给磁盘,这可能会更改缓冲区(例如,将数据从磁盘写入data):
// kernel/fs.h
#define BSIZE 1024 // block size// kernel/buf.h
struct buf {int valid; // has data been read from disk? 数据是否已经从磁盘读取到buf cache中int disk; // does disk "own" buf?uint dev;uint blockno; // block编号struct sleeplock lock; uint refcnt; // 引用计数struct buf *prev; // LRU cache list struct buf *next;uchar data[BSIZE]; // 数据缓冲区,大小为一个Block
};
Bread(kernel/bio.c:93)调用bget为给定扇区(kernel/bio.c:97)获取缓冲区。如果缓冲区需要从磁盘进行读取,bread会在返回缓冲区之前调用virtio_disk_rw来执行此操作:
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{struct buf *b;// 根据设备号和块号获取对应的bufb = bget(dev, blockno);// 如果当前buf还没有从磁盘读取,那么就进行读取if(!b->valid) {// 从磁盘读取block块内容到bufvirtio_disk_rw(b, 0);b->valid = 1;}return b;
}
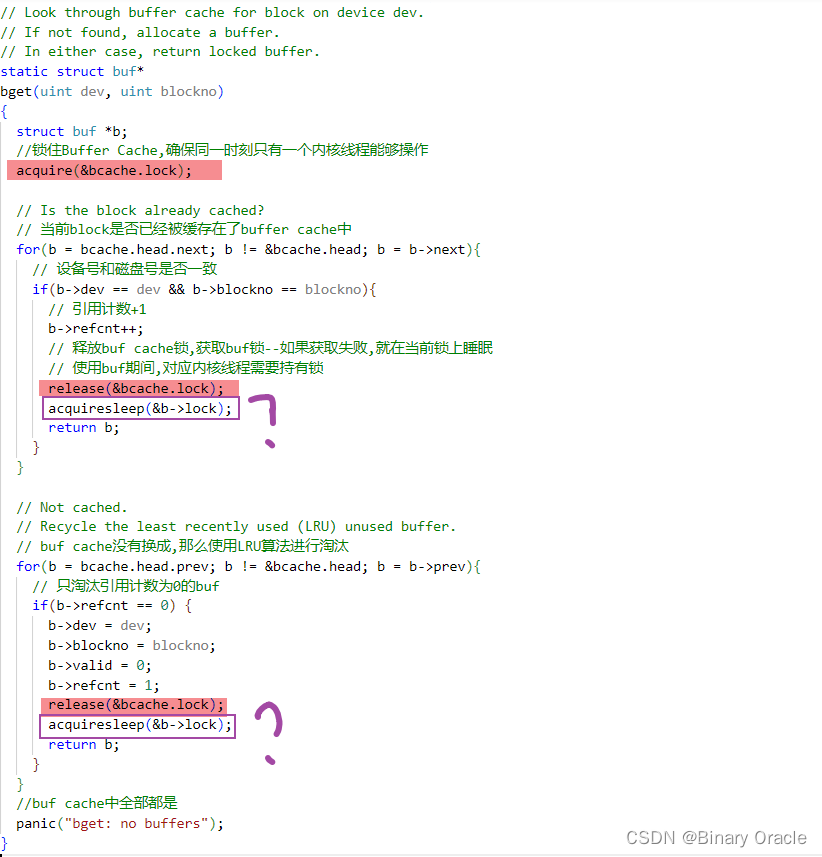
Bget(kernel/bio.c:59)扫描缓冲区列表,查找具有给定设备和扇区号(kernel/bio.c:65-73)的缓冲区。如果存在这样的缓冲区,bget将获取缓冲区的睡眠锁。然后Bget返回锁定的缓冲区。
如果对于给定的扇区没有缓冲区,bget必须创建一个,这可能会重用包含其他扇区的缓冲区。它再次扫描缓冲区列表,查找未在使用中的缓冲区(b->refcnt = 0):任何这样的缓冲区都可以使用。Bget编辑缓冲区元数据以记录新设备和扇区号,并获取其睡眠锁。注意,b->valid = 0的布置确保了bread将从磁盘读取块数据,而不是错误地使用缓冲区以前的内容。
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{struct buf *b;//锁住Buffer Cache,确保同一时刻只有一个内核线程能够操作acquire(&bcache.lock);// Is the block already cached?// 当前block是否已经被缓存在了buffer cache中for(b = bcache.head.next; b != &bcache.head; b = b->next){// 设备号和磁盘号是否一致if(b->dev == dev && b->blockno == blockno){// 引用计数+1b->refcnt++;// 释放buf cache锁,获取buf锁--如果获取失败,就在当前锁上睡眠// 使用buf期间,对应内核线程需要持有锁release(&bcache.lock);acquiresleep(&b->lock);return b;}}// Not cached.// Recycle the least recently used (LRU) unused buffer.// buf cache没有换成,那么使用LRU算法进行淘汰for(b = bcache.head.prev; b != &bcache.head; b = b->prev){// 只淘汰引用计数为0的bufif(b->refcnt == 0) {b->dev = dev;b->blockno = blockno;b->valid = 0;b->refcnt = 1;release(&bcache.lock);acquiresleep(&b->lock);return b;}}//buf cache中全部都是panic("bget: no buffers");
}
每个磁盘扇区最多有一个缓存缓冲区是非常重要的,并且因为文件系统使用缓冲区上的锁进行同步,可以确保读者看到写操作。Bget的从第一个检查块是否缓存的循环到第二个声明块现在已缓存(通过设置dev、blockno和refcnt)的循环,一直持有bcache.lock来确保此不变量。这会导致检查块是否存在以及(如果不存在)指定一个缓冲区来存储块具有原子性。
bget在bcache.lock临界区域之外获取缓冲区的睡眠锁是安全的,因为非零b->refcnt防止缓冲区被重新用于不同的磁盘块。睡眠锁保护块缓冲内容的读写,而bcache.lock保护有关缓存哪些块的信息。
如果所有缓冲区都处于忙碌,那么太多进程同时执行文件系统调用;bget将会panic。一个更优雅的响应可能是在缓冲区空闲之前休眠,尽管这样可能会出现死锁。
一旦bread读取了磁盘(如果需要)并将缓冲区返回给其调用者,调用者就可以独占使用缓冲区,并可以读取或写入数据字节。如果调用者确实修改了缓冲区,则必须在释放缓冲区之前调用bwrite将更改的数据写入磁盘。Bwrite(kernel/bio.c:107)调用virtio_disk_rw与磁盘硬件对话。
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{// 首先获取到对于buf的lockif(!holdingsleep(&b->lock))panic("bwrite");// 将block写入磁盘virtio_disk_rw(b, 1);
}
当调用方使用完缓冲区后,它必须调用brelse来释放缓冲区(brelse是b-release的缩写,这个名字很隐晦,但值得学习:它起源于Unix,也用于BSD、Linux和Solaris)。brelse(kernel/bio.c:117)释放睡眠锁并将缓冲区移动到链表的前面(kernel/bio.c:128-133)。移动缓冲区会使列表按缓冲区的使用频率排序(意思是释放):
- 列表中的第一个缓冲区是最近使用的,最后一个是最近使用最少的。
bget中的两个循环利用了这一点:在最坏的情况下,对现有缓冲区的扫描必须处理整个列表,但首先检查最新使用的缓冲区(从bcache.head开始,然后是下一个指针),在引用局部性良好的情况下将减少扫描时间。选择要重用的缓冲区时,通过自后向前扫描(跟随prev指针)选择最近使用最少的缓冲区。
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{// 首先拿到buf对应的lockif(!holdingsleep(&b->lock))panic("brelse");// 释放buf对应的lockreleasesleep(&b->lock);// 获取buf cache的锁 acquire(&bcache.lock);// 引用计数减一,判断是否完全被释放了b->refcnt--;if (b->refcnt == 0) {// no one is waiting for it.// 将当前buf移动到LRU列表开头b->next->prev = b->prev;b->prev->next = b->next;b->next = bcache.head.next;b->prev = &bcache.head;bcache.head.next->prev = b;bcache.head.next = b;}release(&bcache.lock);
}
bpin和bunpin分别用于增加某个buf的引用计数和减少某个buf的引用计数:
void
bpin(struct buf *b) {acquire(&bcache.lock);b->refcnt++;release(&bcache.lock);
}void
bunpin(struct buf *b) {acquire(&bcache.lock);b->refcnt--;release(&bcache.lock);
}
日志层
文件系统设计中最有趣的问题之一是崩溃恢复。出现此问题的原因是,许多文件系统操作都涉及到对磁盘的多次写入,并且在完成写操作的部分子集后崩溃可能会使磁盘上的文件系统处于不一致的状态。例如,假设在文件截断(将文件长度设置为零并释放其内容块)期间发生崩溃。根据磁盘写入的顺序,崩溃可能会留下对标记为空闲的内容块的引用的inode,也可能留下已分配但未引用的内容块。
后者相对来说是良性的,但引用已释放块的inode在重新启动后可能会导致严重问题。重新启动后,内核可能会将该块分配给另一个文件,现在我们有两个不同的文件无意中指向同一块。如果xv6支持多个用户,这种情况可能是一个安全问题,因为旧文件的所有者将能够读取和写入新文件中的块,而新文件的所有者是另一个用户。
Xv6通过简单的日志记录形式解决了文件系统操作期间的崩溃问题。xv6系统调用不会直接写入磁盘上的文件系统数据结构。相反,它会在磁盘上的log(日志)中放置它希望进行的所有磁盘写入的描述。一旦系统调用记录了它的所有写入操作,它就会向磁盘写入一条特殊的commit(提交)记录,表明日志包含一个完整的操作。此时,系统调用将写操作复制到磁盘上的文件系统数据结构。完成这些写入后,系统调用将擦除磁盘上的日志。
如果系统崩溃并重新启动,则在运行任何进程之前,文件系统代码将按如下方式从崩溃中恢复。如果日志标记为包含完整操作,则恢复代码会将写操作复制到磁盘文件系统中它们所属的位置。如果日志没有标记为包含完整操作,则恢复代码将忽略该日志。恢复代码通过擦除日志完成。
为什么xv6的日志解决了文件系统操作期间的崩溃问题?如果崩溃发生在操作提交之前,那么磁盘上的登录将不会被标记为已完成,恢复代码将忽略它,并且磁盘的状态将如同操作尚未启动一样。如果崩溃发生在操作提交之后,则恢复将重播操作的所有写入操作,如果操作已开始将它们写入磁盘数据结构,则可能会重复这些操作。在任何一种情况下,日志都会使操作在崩溃时成为原子操作:恢复后,要么操作的所有写入都显示在磁盘上,要么都不显示。
数据库中也有对应的WAL(预写日志)来进行奔溃恢复。
日志设计
日志驻留在超级块中指定的已知固定位置。它由一个头块(header block)和一系列更新块的副本(logged block)组成。头块包含一个扇区号数组(每个logged block对应一个扇区号)以及日志块的计数。磁盘上的头块中的计数或者为零,表示日志中没有事务;或者为非零,表示日志包含一个完整的已提交事务,并具有指定数量的logged block。在事务提交(commit)时Xv6才向头块写入数据,在此之前不会写入,并在将logged blocks复制到文件系统后将计数设置为零。因此,事务中途崩溃将导致日志头块中的计数为零;提交后的崩溃将导致非零计数。
注:logged block表示已经记录了操作信息的日志块,而log block仅表示日志块
每个系统调用的代码都指示写入序列的起止,考虑到崩溃,写入序列必须具有原子性。为了允许不同进程并发执行文件系统操作,日志系统可以将多个系统调用的写入累积到一个事务中。因此,单个提交可能涉及多个完整系统调用的写入。为了避免在事务之间拆分系统调用,日志系统仅在没有文件系统调用进行时提交。
同时提交多个事务的想法称为组提交(group commit)。组提交减少了磁盘操作的数量,因为成本固定的一次提交分摊了多个操作。组提交还同时为磁盘系统提供更多并发写操作,可能允许磁盘在一个磁盘旋转时间内写入所有这些操作。Xv6的virtio驱动程序不支持这种批处理,但是Xv6的文件系统设计允许这样做。
Xv6在磁盘上留出固定的空间来保存日志。事务中系统调用写入的块总数必须可容纳于该空间。这导致两个后果:
- 任何单个系统调用都不允许写入超过日志空间的不同块。
这对于大多数系统调用来说都不是问题,但其中两个可能会写入许多块:write和unlink。一个大文件的write可以写入多个数据块和多个位图块以及一个inode块;unlink大文件可能会写入许多位图块和inode。Xv6的write系统调用将大的写入分解为适合日志的多个较小的写入,unlink不会导致此问题,因为实际上Xv6文件系统只使用一个位图块。
- 日志空间有限的另一个后果是,除非确定系统调用的写入将可容纳于日志中剩余的空间,否则日志系统无法允许启动系统调用。
代码:日志
在系统调用中一个典型的日志使用就像这样:
//1. 开启日志事务begin_op();//2. 不断记录日志数据--暂时保存再内存中...bp = bread(...);bp->data[...] = ...;log_write(bp);...//3.提交本次日志事务end_op();
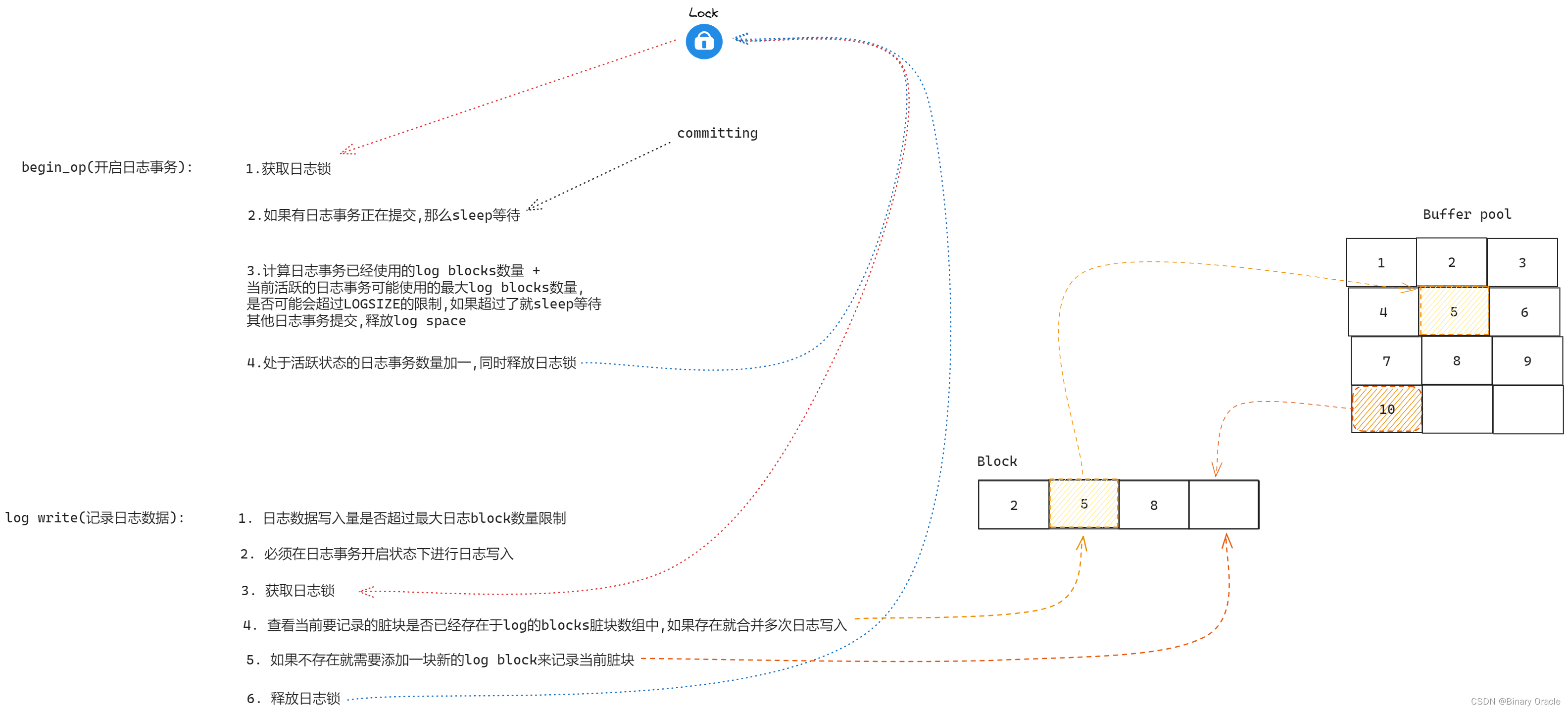
begin_op(kernel/log.c:126)等待直到日志系统当前未处于提交中,并且直到有足够的未被占用的日志空间来保存此调用的写入。

log.outstanding统计预定了日志空间的系统调用数;为此保留的总空间为log.outstanding乘以MAXOPBLOCKS。递增log.outstanding会预定空间并防止在此系统调用期间发生提交。代码保守地假设每个系统调用最多可以写入MAXOPBLOCKS个不同的块:
// kernel/param.h
#define MAXOPBLOCKS 10 // max # of blocks any FS op writes
#define LOGSIZE (MAXOPBLOCKS*3) // max data blocks in on-disk log // kernel/log.c
// Contents of the header block, used for both the on-disk header block
// and to keep track in memory of logged block# before commit.
struct logheader {int n;int block[LOGSIZE];
};struct log {struct spinlock lock;int start;int size;int outstanding; // how many FS sys calls are executing. int committing; // in commit(), please wait. int dev; struct logheader lh;
};
struct log log;// called at the start of each FS system call.
void
begin_op(void)
{acquire(&log.lock);while(1){if(log.committing){sleep(&log, &log.lock);}else if(log.lh.n + (log.outstanding+1)*MAXOPBLOCKS > LOGSIZE){// this op might exhaust log space; wait for commit.sleep(&log, &log.lock);} else {log.outstanding += 1;release(&log.lock);break;}}

log_write(kernel/log.c:214)充当bwrite的代理。它将块的扇区号记录在内存中,在磁盘上的日志中预定一个槽位,并调用bpin将缓存固定在block cache中,以防止block cache将其逐出:
// Caller has modified b->data and is done with the buffer.
// Record the block number and pin in the cache by increasing refcnt.
// commit()/write_log() will do the disk write.
//
// log_write() replaces bwrite(); a typical use is:
// bp = bread(...)
// modify bp->data[]
// log_write(bp)
// brelse(bp)
void
log_write(struct buf *b)
{int i;if (log.lh.n >= LOGSIZE || log.lh.n >= log.size - 1)panic("too big a transaction");if (log.outstanding < 1)panic("log_write outside of trans");acquire(&log.lock);for (i = 0; i < log.lh.n; i++) {if (log.lh.block[i] == b->blockno) // log absorbtionbreak;}log.lh.block[i] = b->blockno;if (i == log.lh.n) { // Add new block to log?bpin(b);log.lh.n++;}release(&log.lock);
}
注:固定在block cache是指在缓存不足需要考虑替换时,不会将这个block换出,因为事务具有原子性:假设块45被写入,将其换出的话需要写入磁盘中文件系统对应的位置,而日志系统要求所有内存必须都存入日志,最后才能写入文件系统。
bpin是通过增加引用计数防止块被换出的,之后需要再调用bunpin
在提交之前,块必须留在缓存中:
- 在提交之前,缓存的副本是修改的唯一记录;
- 只有在提交后才能将其写入磁盘上的位置;
- 同一事务中的其他读取必须看到修改。
log_write会注意到在单个事务中多次写入一个块的情况,并在日志中为该块分配相同的槽位。这种优化通常称为合并(absorption)。
- 例如,包含多个文件inode的磁盘块在一个事务中被多次写入是很常见的。通过将多个磁盘写入合并到一个磁盘中,文件系统可以节省日志空间并实现更好的性能,因为只有一个磁盘块副本必须写入磁盘。
注:日志需要写入磁盘,以便重启后读取,但日志头块和日志数据块也会在block cache中有一个副本
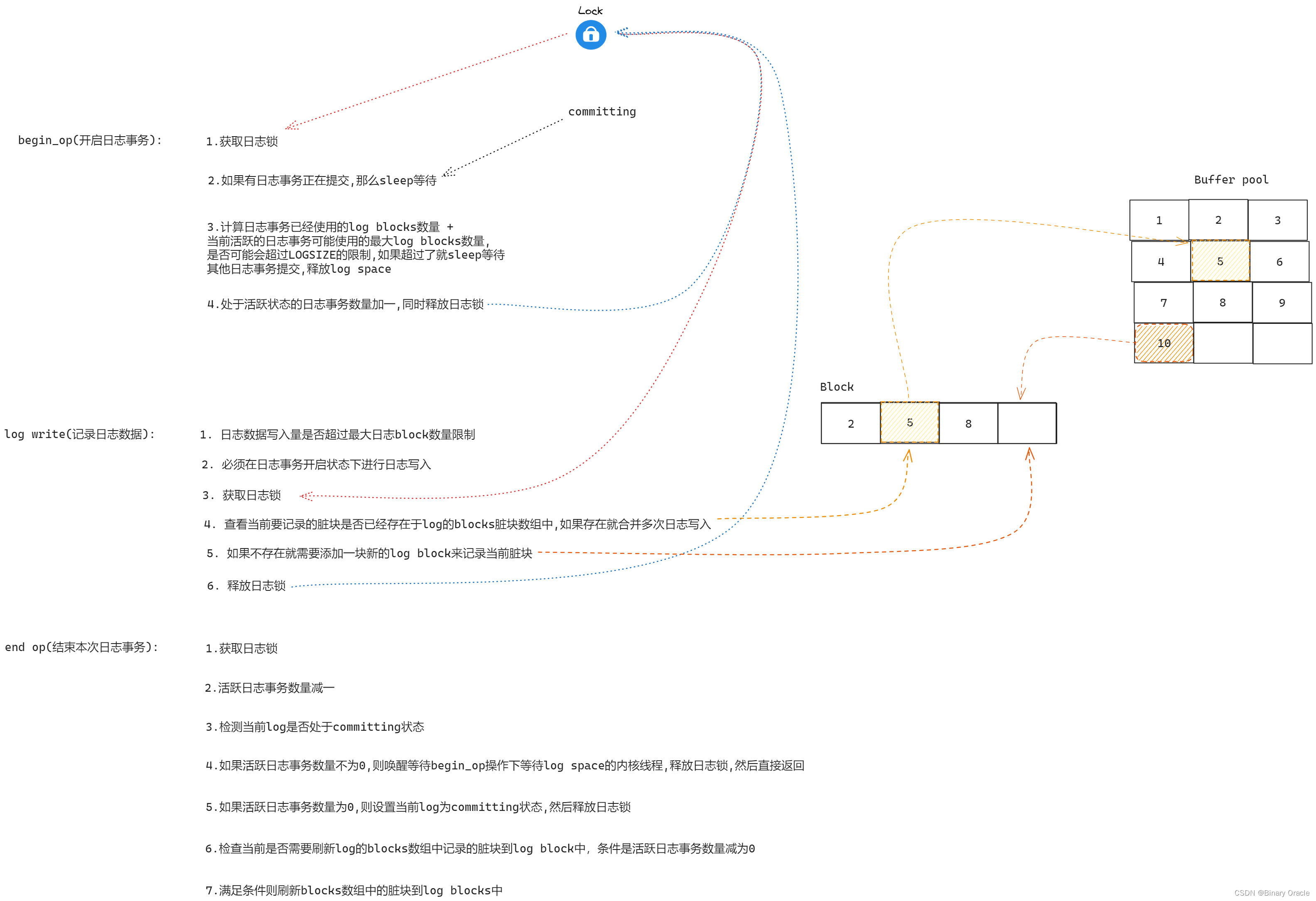
end_op(kernel/log.c:146)首先减少未完成系统调用的计数。如果计数现在为零,则通过调用commit()提交当前事务。这一过程分为四个阶段:
// called at the end of each FS system call.
// commits if this was the last outstanding operation.
void
end_op(void)
{int do_commit = 0;acquire(&log.lock);log.outstanding -= 1;if(log.committing)panic("log.committing");if(log.outstanding == 0){do_commit = 1;log.committing = 1;} else {// begin_op() may be waiting for log space,// and decrementing log.outstanding has decreased// the amount of reserved space.wakeup(&log);}release(&log.lock);if(do_commit){// call commit w/o holding locks, since not allowed// to sleep with locks.commit();acquire(&log.lock);log.committing = 0;wakeup(&log);release(&log.lock);}
}

write_log()(kernel/log.c:178)将事务中修改的每个块从缓冲区缓存复制到磁盘上日志槽位中。
// Copy modified blocks from cache to log.
// 将缓存中脏的block copy一份到log block中
static void
write_log(void)
{int tail;// 遍历所有待写入磁盘块的log blockfor (tail = 0; tail < log.lh.n; tail++) {// 从磁盘中读取中对应的log blockstruct buf *to = bread(log.dev, log.start+tail+1); // log block// 从buf cache中获取脏blockstruct buf *from = bread(log.dev, log.lh.block[tail]); // cache block// 将数据从from copy到tomemmove(to->data, from->data, BSIZE);// 将log block to写入磁盘bwrite(to); // write the log// 递减引用计数brelse(from);brelse(to);}
}
write_head()(kernel/log.c:102)将头块写入磁盘:这是提交点,写入后的崩溃将导致从日志恢复重演事务的写入操作。
// Write in-memory log header to disk.
// This is the true point at which the
// current transaction commits.
static void
write_head(void)
{// log block区域第一个log block是log header blockstruct buf *buf = bread(log.dev, log.start);struct logheader *hb = (struct logheader *) (buf->data);int i;// 将内存中保持的log header信息写入磁盘保存hb->n = log.lh.n;for (i = 0; i < log.lh.n; i++) {hb->block[i] = log.lh.block[i];}bwrite(buf);brelse(buf);
}
install_trans(kernel/log.c:69)从日志中读取每个块,并将其写入文件系统中的适当位置。
// Copy committed blocks from log to their home location
static void
install_trans(int recovering)
{int tail;// 将log.lh.block数组中记录的所有脏块刷到磁盘上的log block区域保存for (tail = 0; tail < log.lh.n; tail++) {struct buf *lbuf = bread(log.dev, log.start+tail+1); // read log blockstruct buf *dbuf = bread(log.dev, log.lh.block[tail]); // read dstmemmove(dbuf->data, lbuf->data, BSIZE); // copy block to dstbwrite(dbuf); // write dst to diskif(recovering == 0)bunpin(dbuf);brelse(lbuf);brelse(dbuf);}
}
- 最后,
end_op写入计数为零的日志头;
这必须在下一个事务开始写入日志块之前发生,以便崩溃不会导致使用一个事务的头块和后续事务的日志块进行恢复。

recover_from_log(kernel/log.c:116)是由initlog(kernel/log.c:55)调用的,而它又是在第一个用户进程运行(kernel/proc.c:539)之前的引导期间由fsinit(kernel/fs.c:42)调用的。它读取日志头,如果头中指示日志包含已提交的事务,则模拟end_op的操作。
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void
forkret(void)
{static int first = 1;// Still holding p->lock from scheduler.release(&myproc()->lock);//第一个用户进程运行之前的引导期间由`fsinit`调用的if (first) {// File system initialization must be run in the context of a// regular process (e.g., because it calls sleep), and thus cannot// be run from main().first = 0;fsinit(ROOTDEV);}usertrapret();
}// Init fs
void
fsinit(int dev) {// 读取super blockreadsb(dev, &sb);if(sb.magic != FSMAGIC)panic("invalid file system");// 初始化日志系统 initlog(dev, &sb);
}// there should be one superblock per disk device, but we run with
// only one device
// Disk layout:
// [ boot block | super block | log | inode blocks |
// free bit map | data blocks]
//
// mkfs computes the super block and builds an initial file system. The
// super block describes the disk layout:
struct superblock {uint magic; // Must be FSMAGICuint size; // Size of file system image (blocks)uint nblocks; // Number of data blocksuint ninodes; // Number of inodes.uint nlog; // Number of log blocksuint logstart; // Block number of first log blockuint inodestart; // Block number of first inode blockuint bmapstart; // Block number of first free map block
};// Read the super block.
static void
readsb(int dev, struct superblock *sb)
{struct buf *bp;// 读取第一个block bp = bread(dev, 1);memmove(sb, bp->data, sizeof(*sb));brelse(bp);
}void
initlog(int dev, struct superblock *sb)
{if (sizeof(struct logheader) >= BSIZE)panic("initlog: too big logheader");initlock(&log.lock, "log");// 从sb中获取log系统相关信息log.start = sb->logstart;log.size = sb->nlog;log.dev = dev;// 判断是否需要进行奔溃恢复过程recover_from_log();
}static void
recover_from_log(void)
{//读取log header block到log.lh结构体中read_head();// 尝试重放已经提交的日志事务,但是对应的脏块还没有刷新到磁盘上的任务install_trans(1); // if committed, copy from log to disklog.lh.n = 0;// 将磁盘上log header区域中的n设置为0write_head(); // clear the log
}// Read the log header from disk into the in-memory log header
static void
read_head(void)
{struct buf *buf = bread(log.dev, log.start);struct logheader *lh = (struct logheader *) (buf->data);int i;log.lh.n = lh->n;for (i = 0; i < log.lh.n; i++) {log.lh.block[i] = lh->block[i];}brelse(buf);
}
日志的一个示例使用发生在filewrite(kernel/file.c:135)中。事务如下所示:
begin_op(); ilock(f->ip); r = writei(f->ip, ...); iunlock(f->ip); end_op();
这段代码被包装在一个循环中,该循环一次将大的写操作分解为几个扇区的单个事务,以避免日志溢出。作为此事务的一部分,对writei的调用写入许多块:文件的inode、一个或多个位图块以及一些数据块。
代码:块分配器
文件和目录内容存储在磁盘块中,磁盘块必须从空闲池中分配。xv6的块分配器在磁盘上维护一个空闲位图,每一位代表一个块。0表示对应的块是空闲的;1表示它正在使用中。程序mkfs设置对应于引导扇区、超级块、日志块、inode块和位图块的比特位。
块分配器提供两个功能:balloc分配一个新的磁盘块,bfree释放一个块。
Balloc中位于kernel/fs.c:71的循环从块0到sb.size(文件系统中的块数)遍历每个块。它查找位图中位为零的空闲块。如果balloc找到这样一个块,它将更新位图并返回该块。为了提高效率,循环被分成两部分。外部循环读取位图中的每个块。内部循环检查单个位图块中的所有BPB位。由于任何一个位图块在buffer cache中一次只允许一个进程使用,因此,如果两个进程同时尝试分配一个块,可能会发生争用。
// Allocate a zeroed disk block.
static uint
balloc(uint dev)
{int b, bi, m;struct buf *bp;bp = 0;// 遍历所有bitmap block -- bitmap block数量随着磁盘大小而浮动for(b = 0; b < sb.size; b += BPB){// 从磁盘读取出当前bitmap blockbp = bread(dev, BBLOCK(b, sb));// 遍历bitmap block中每一位for(bi = 0; bi < BPB && // 可能当前bitmap block前面100位就足以表示完所有磁盘块了b + bi < sb.size; bi++){m = 1 << (bi % 8);// 位图当前位是否为0,为0表示位图处于空闲状态if((bp->data[bi/8] & m) == 0){ // Is block free?// 标记位图当前位位1,正在使用bp->data[bi/8] |= m; // Mark block in use.// 当前位图块修改了,所以记录到log block中log_write(bp);// 引用计数减一,只保留log block中的引用计数brelse(bp);// 将当前空闲block清空为0bzero(dev, b + bi);// 返回当前空闲block的块号return b + bi;}}brelse(bp);}panic("balloc: out of blocks");
}// Zero a block.
// 将当前空闲块从磁盘读取出来,然后清空为0,然后写入log block
static void
bzero(int dev, int bno)
{struct buf *bp;bp = bread(dev, bno);memset(bp->data, 0, BSIZE);log_write(bp);brelse(bp);
}
Bfree(kernel/fs.c:90)找到正确的位图块并清除正确的位。同样,bread和brelse隐含的独占使用避免了显式锁定的需要。
// Free a disk block.
static void
bfree(int dev, uint b)
{struct buf *bp;int bi, m;// 找到要free的block在哪个bitmap blocks上bp = bread(dev, BBLOCK(b, sb));bi = b % BPB;m = 1 << (bi % 8);// 设置bitmap block对应要释放的block bit位为0if((bp->data[bi/8] & m) == 0)panic("freeing free block"); bp->data[bi/8] &= ~m;// 将修改的bitmap block记录到log block中等待落盘log_write(bp);brelse(bp);
}
与本章其余部分描述的大部分代码一样,必须在事务内部调用balloc和bfree。