零、本讲学习目标
- 了解RDD容错机制
- 理解RDD检查点机制的特点与用处
- 理解共享变量的类别、特点与使用
一、RDD容错机制
- 当Spark集群中的某一个节点由于宕机导致数据丢失,则可以通过Spark中的RDD进行容错恢复已经丢失的数据。RDD提供了两种故障恢复的方式,分别是血统(Lineage)方式和设置检查点(checkpoint)方式。
(一)血统方式
- 根据RDD之间依赖关系对丢失数据的RDD进行数据恢复。若丢失数据的子RDD进行窄依赖运算,则只需要把丢失数据的父RDD的对应分区进行重新计算,不依赖其他节点,并且在计算过程中不存在冗余计算;若丢失数据的RDD进行宽依赖运算,则需要父RDD所有分区都要进行从头到尾计算,计算过程中存在冗余计算。
(二)设置检查点方式
- 本质是将RDD写入磁盘存储。当RDD进行宽依赖运算时,只要在中间阶段设置一个检查点进行容错,即Spark中的sparkContext调用setCheckpoint()方法,设置容错文件系统目录作为检查点checkpoint,将checkpoint的数据写入之前设置的容错文件系统中进行持久化存储,若后面有节点宕机导致分区数据丢失,则以从做检查点的RDD开始重新计算,不需要从头到尾的计算,从而减少开销。
二、RDD检查点
(一)RDD检查点机制
- RDD的检查点机制(Checkpoint)相当于对RDD数据进行快照,可以将经常使用的RDD快照到指定的文件系统中,最好是共享文件系统,例如HDFS。当机器发生故障导致内存或磁盘中的RDD数据丢失时,可以快速从快照中对指定的RDD进行恢复,而不需要根据RDD的依赖关系从头进行计算,大大提高了计算效率。
(二)与RDD持久化的区别
cache()或者persist()是将数据存储于机器本地的内存或磁盘,当机器发生故障时无法进行数据恢复,而检查点是将RDD数据存储于外部的共享文件系统(例如HDFS),共享文件系统的副本机制保证了数据的可靠性。- 在Spark应用程序执行结束后,cache()或者persist()存储的数据将被清空,而检查点存储的数据不会受影响,将永久存在,除非手动将其移除。因此,检查点数据可以被下一个Spark应用程序使用,而cache()或者persist()数据只能被当前Spark应用程序使用。
(三)RDD检查点案例演示
- 在
net.cl.rdd包里创建day06子包,然后在子包里创建CheckPointDemo对象
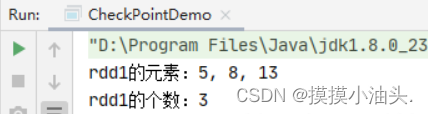
package net.cl.rdd.day06import org.apache.spark.{SparkConf, SparkContext}object CheckPointDemo {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("CheckPointDemo") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 设置检查点数据存储路径(目录会自动创建的)sc.setCheckpointDir("hdfs://master:9000/spark-ck")// 基于集合创建RDDval rdd = sc.makeRDD(List(1, 1, 2, 3, 5, 8, 13))// 过滤大于或等于5的数据,生成新的RDDval rdd1 = rdd.filter(_ >= 5)// 将rdd1持久化到内存rdd1.cache(); // 相当于无参persist()方法// 将rdd1标记为检查点rdd1.checkpoint();// 第一次行动算子 - 采集数据,将标记为检查点的RDD数据存储到指定位置val result = rdd1.collect.mkString(", ")println("rdd1的元素:" + result)// 第二次行动算子 - 计算个数,直接从缓存里读取rdd1的数据,不用从头计算val count = rdd1.countprintln("rdd1的个数:" + count)// 停止Spark容器sc.stop()}
}
- 上述代码使用checkpoint()方法将RDD标记为检查点(只是标记,遇到行动算子才会执行)。在第一次行动计算时,被标记为检查点的RDD的数据将以文件的形式保存在setCheckpointDir()方法指定的文件系统目录中,并且该RDD的所有父RDD依赖关系将被移除,因为下一次对该RDD计算时将直接从文件系统中读取数据,而不需要根据依赖关系重新计算。
-
Spark建议,在将RDD标记为检查点之前,最好将RDD持久化到内存,因为Spark会单独启动一个任务将标记为检查点的RDD的数据写入文件系统,如果RDD的数据已经持久化到了内存,将直接从内存中读取数据,然后进行写入,提高数据写入效率,否则需要重复计算一遍RDD的数据。
-
运行程序,在控制台查看结果
-
利用Hadoop WebUI查看HDFS检查点目录

-
查看红色框里的目录
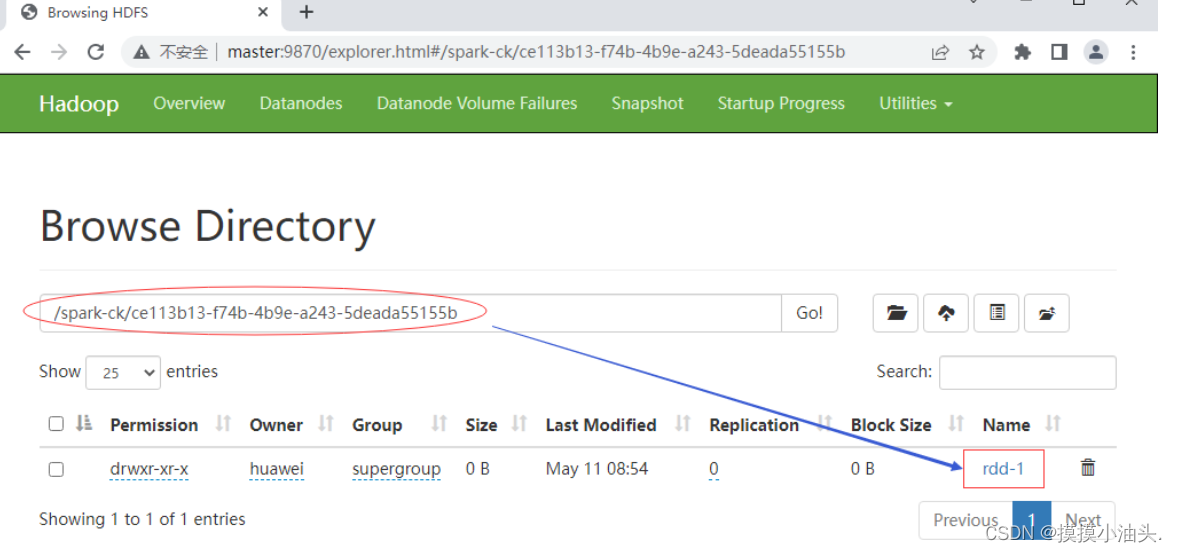
-
查看
rdd-1目录

-
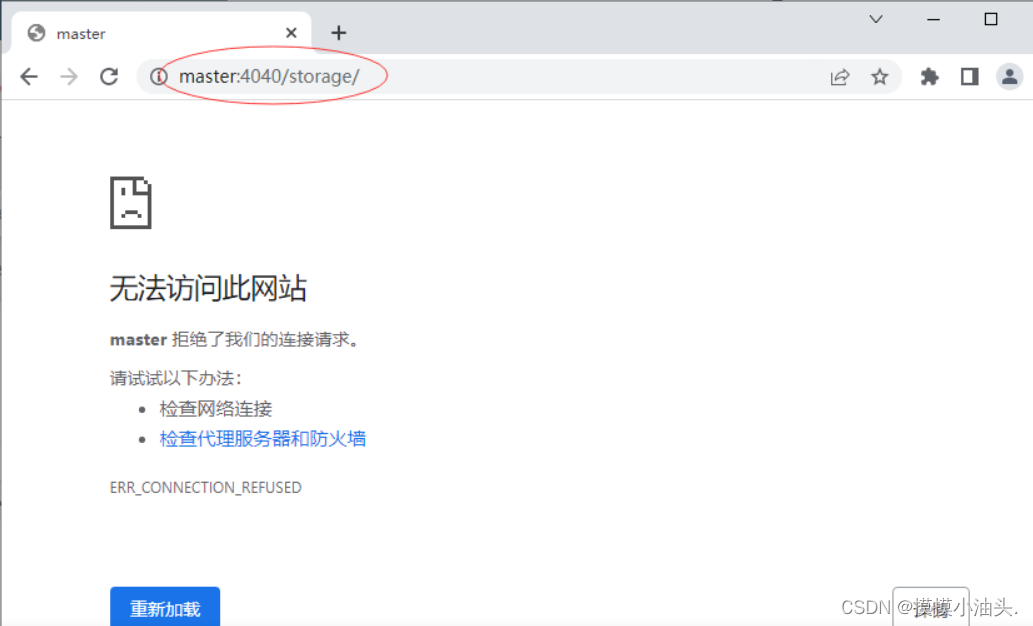
因为执行了
sc.stop()语句,关闭了Spark容器,缓存的数据就被清除了,当然也无法访问Spark的存储数据。
三、共享变量
- 通常情况下,Spark应用程序运行的时候,Spark算子(例如map(func)或filter(func))中的函数func会被发送到远程的多个Worker节点上执行,如果一个算子中使用了某个外部变量,该变量就会复制到Worker节点的每一个Task任务中,各个Task任务对变量的操作相互独立。当变量所存储的数据量非常大时(例如一个大型集合)将增加网络传输及内存的开销。因此,Spark提供了两种共享变量:广播变量和累加器。
(一)广播变量
- 广播变量是将一个变量通过广播的形式发送到每个Worker节点的缓存中,而不是发送到每个Task任务中,各个Task任务可以共享该变量的数据。因此,广播变量是只读的。
- 准备工作:在
/home目录里创建data.txt
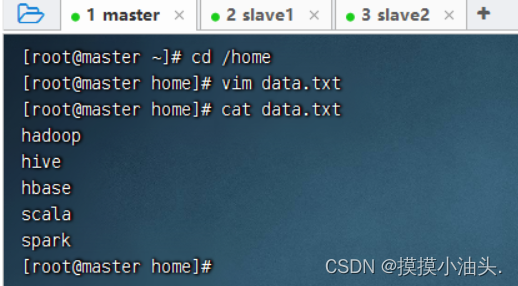
- 上传到HDFS的
/park目录

1、默认情况下变量的传递
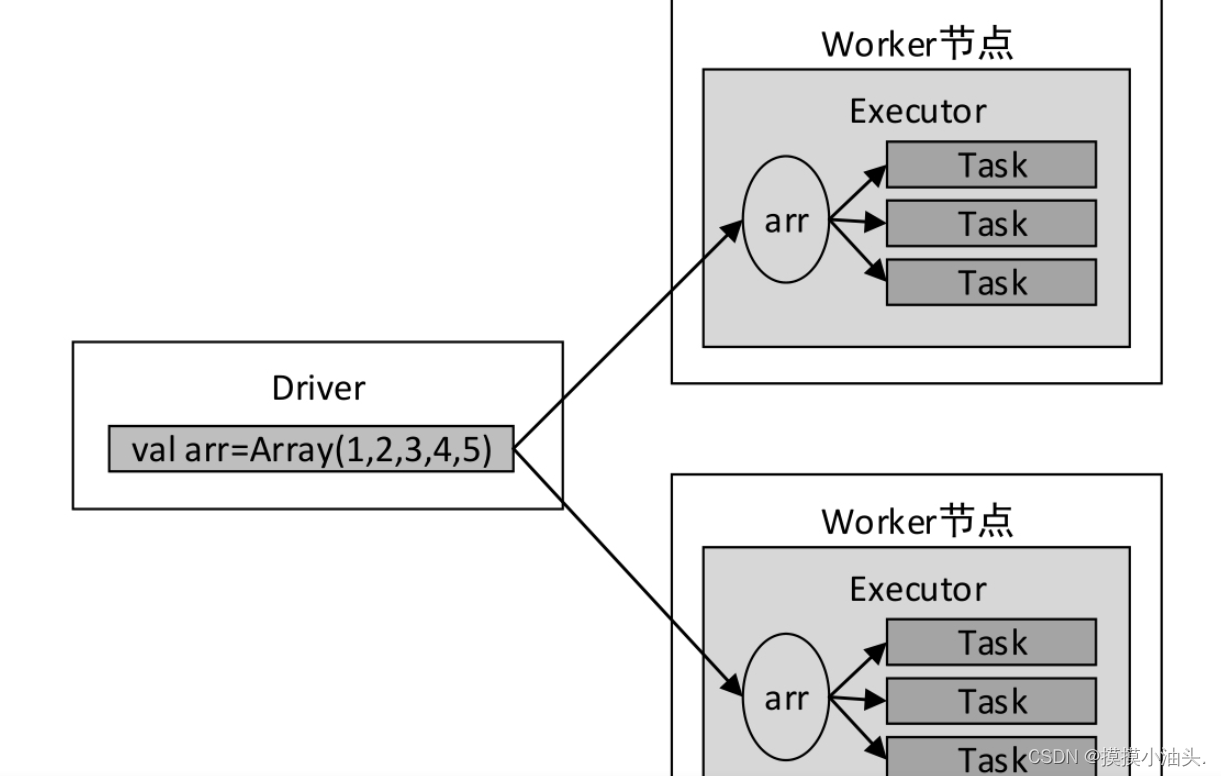
map()算子传入的函数中使用外部变量arr
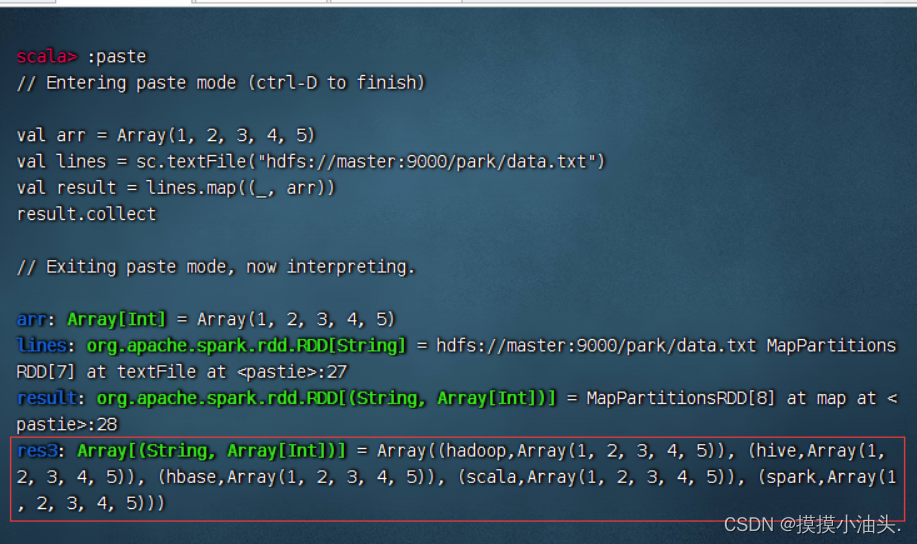
val arr = Array(1, 2, 3, 4, 5)
val lines = sc.textFile("hdfs://master:9000/park/data.txt")
val result = lines.map((_, arr))
result.collect
- 上述代码中,传递给map()算子的函数
(_, arr)会被发送到Executor端执行,而变量arr将发送到Worker节点的所有Task任务中。变量arr传递的流程如下图所示。

- 假设变量
arr存储的数据量大小有100MB,则每一个Task任务都需要维护100MB的副本,若某一个Executor中启动了3个Task任务,则该Executor将消耗300MB内存。
2、使用广播变量时变量的传递
-
广播变量其实是对普通变量的封装,在分布式函数中可以通过Broadcast对象的
value方法访问广播变量的值
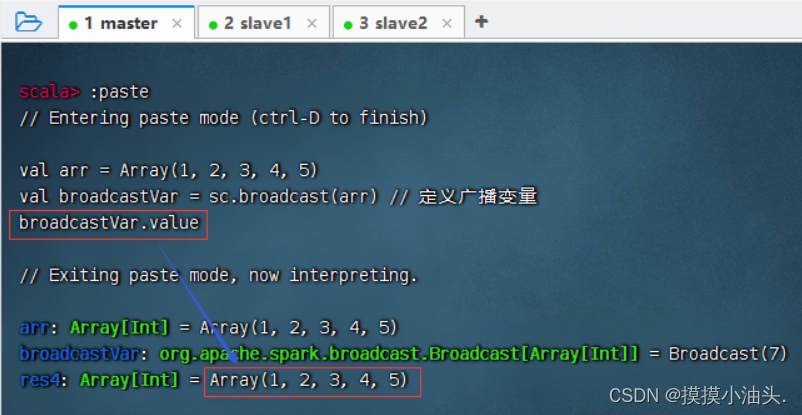
-
使用广播变量将数组
arr传递给map()算子
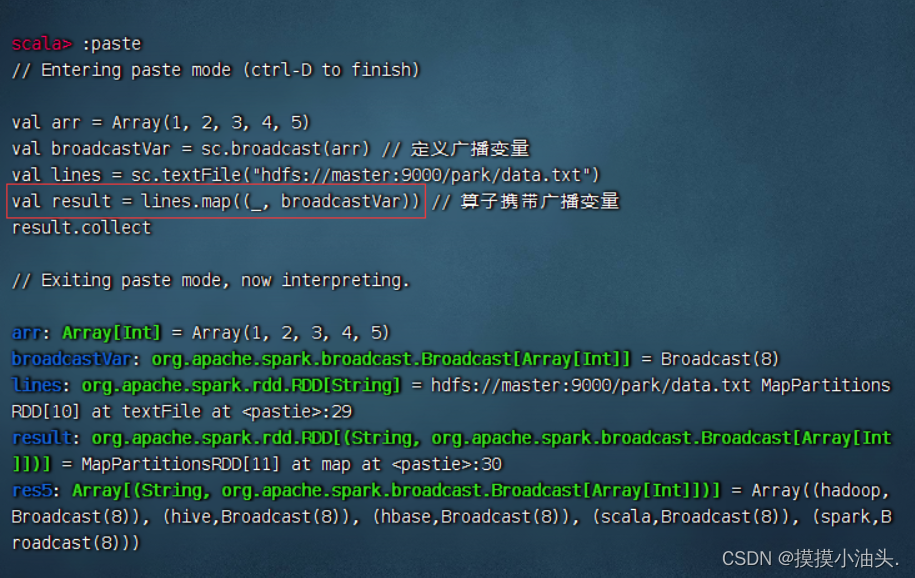
val arr = Array(1, 2, 3, 4, 5)
val broadcastVar = sc.broadcast(arr) // 定义广播变量
val lines = sc.textFile("hdfs://master:9000/park/data.txt")
val result = lines.map((_, broadcastVar)) // 算子携带广播变量
result.collect-
上述代码使用broadcast()方法向集群发送(广播)了一个只读变量,该方法只发送一次,并返回一个广播变量broadcastVar,该变量是一个org.apache.spark.broadcast.Broadcast对象。Broadcast对象是只读的,缓存在集群的每个Worker节点中。使用广播变量进行变量传递的流程如下图所示。
- Worker节点的每个Task任务共享唯一的一份广播变量,大大减少了网络传输和内存开销。
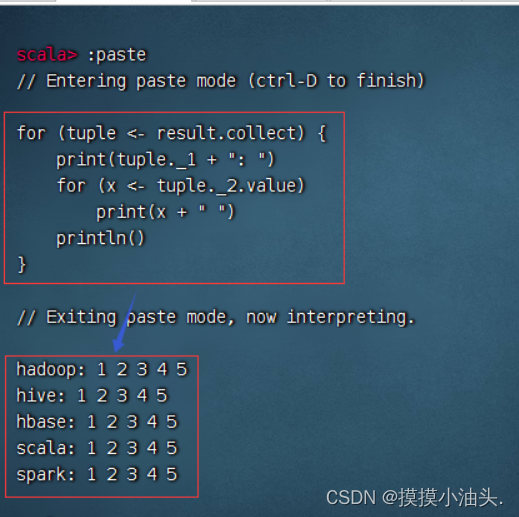
- 通过遍历算子输出
arr结果
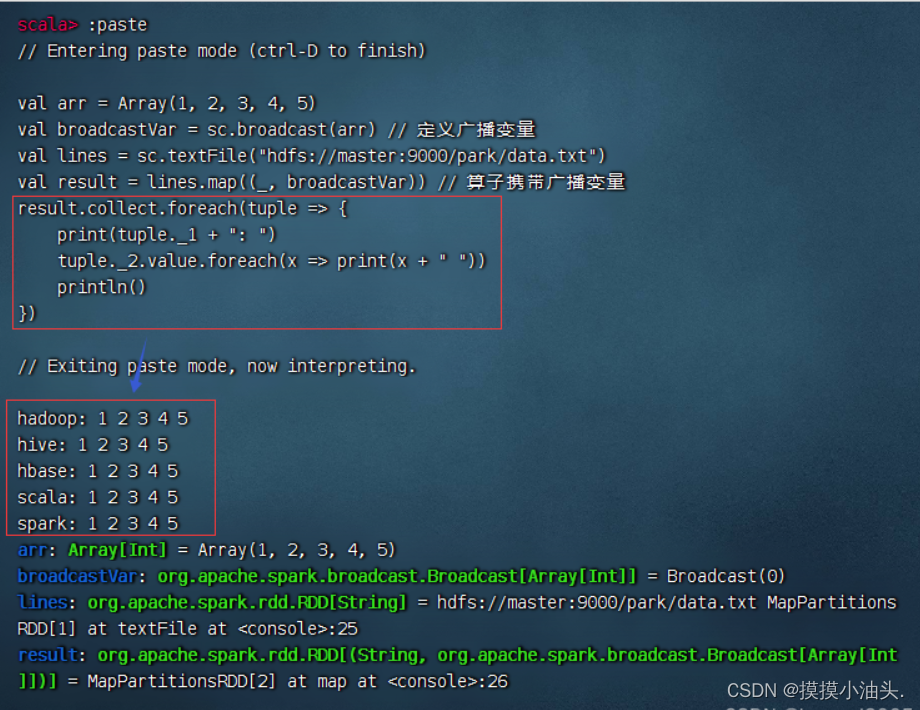
- 通过双重循环输出
result的数据
(二)累加器
1、累加器功能
- 累加器提供了将Worker节点的值聚合到Driver的功能,可以用于实现计数和求和。
2、不使用累加器
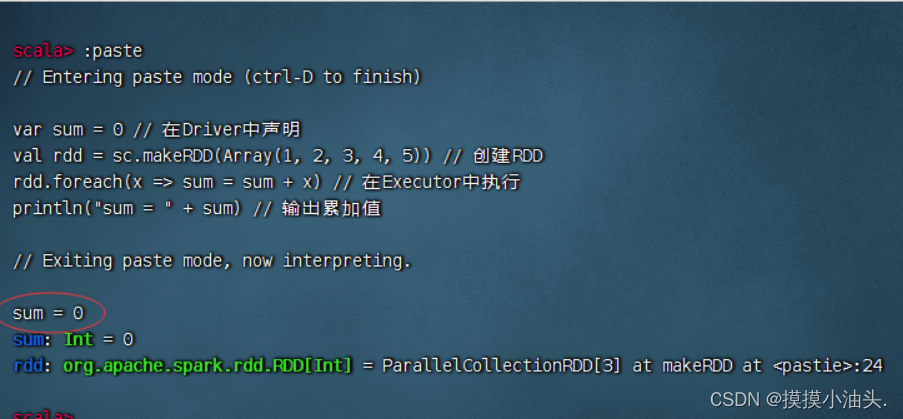
-
对一个整型数组求和
-
上述代码由于
sum变量在Driver中定义,而累加操作sum = sum + x会发送到Executor中执行,因此输出结果不正确。
3、使用累加器
- 对一个整型数组求和

val myacc = sc.longAccumulator("acc") // 在Driver里声明累加器
val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5)) // 创建RDD
rdd.foreach(x => myacc.add(x)) // 在Executor里向累加器添加值
println("sum = " + myacc.value) // 在Driver里输出累加结果
- 上述代码通过调用SparkContext对象的
longAccumulator ()方法创建了一个Long类型的累加器,默认初始值为0。也可以使用doubleAccumulator()方法创建Double类型的累加器。 - 累加器只能在
Driver端定义,在Executor端更新。Executor端不能读取累加器的值,需要在Driver端使用value属性读取。