Mycat的简单使用(三)【分库分表】
- 为什么分库分表
- 什么是分库分表?
- 为什么要分库分表?
- 从性能上看
- 从可用性上看
- 如何分库分表
- 分库?分表?还是既分库又分表?
- 如何选择我们自己的切分方案?
- 如果需要分库,那么分多少库合适?
- 如何对数据进行切分?
- 分库
- 数据库准备
- 停止之前的数据库
- 安装两个数据库服务(容器)
- 创建数据库
- 配置mycat
- 启动mycat
- 验证
- Mycat客户端验证
- dn1节点验证
- dn2节点验证
- 分表
- 需求
- 分表实现(取模)
- 原则
- 安装数据库
- 创建数据库、表
- mycat实现分表
- Mycat 的分片 join
- ER分片
- 全局表
- 介绍
- 实现
- 验证全局表
为什么分库分表
如果觉得理论啰嗦直接跳到第二个一级标题分库开始看。
什么是分库分表?
其实就是字面意思,很好理解:
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
为什么要分库分表?
关键字:提升性能、增加可用性。
从性能上看
随着单库中的数据量越来越大、数据库的查询QPS越来越高,相应的,对数据库的读写所需要的时间也越来越多。数据库的读写性能可能会成为业务发展的瓶颈。对应的,就需要做数据库性能方面的优化。本文中我们只讨论数据库层面的优化,不讨论缓存等应用层优化的手段。
如果数据库的查询QPS过高,就需要考虑拆库,通过分库来分担单个数据库的连接压力。比如,如果查询QPS为3500,假设单库可以支撑1000个连接数的话,那么就可以考虑拆分成多个个库,来分散查询连接压力。
如果单表数据量过大,当数据量超过一定量级后,无论是对于数据查询还是数据更新,在经过索引优化等纯数据库层面的传统优化手段之后,还是可能存在性能问题。这是量变产生了质变,这时候就需要去换个思路来解决问题,比如:从数据生产源头、数据处理源头来解决问题,既然数据量很大,那我们就来个分而治之,化整为零。这就产生了分表,把数据按照一定的规则拆分成多张表,来解决单表环境下无法解决的存取性能问题。
从可用性上看
单个数据库如果发生意外,很可能会丢失所有数据。尤其是云时代,很多数据库都跑在虚拟机上,如果虚拟机/宿主机发生意外,则可能造成无法挽回的损失。因此,除了传统的 Master-Slave、Master-Master 等部署层面解决可靠性问题外,我们也可以考虑从数据拆分层面解决此问题。
此处我们以数据库宕机为例:
- 单库部署情况下,如果数据库宕机,那么故障影响就是100%,而且恢复可能耗时很长。
- 如果我们拆分成2个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是50%,还有50%的数据可以继续服务。
- 如果我们拆分成4个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是25%,还有75%的数据可以继续服务,恢复耗时也会很短。
当然,我们也不能无限制的拆库,这也是牺牲存储资源来提升性能、可用性的方式,毕竟资源总是有限的。
如何分库分表
分库?分表?还是既分库又分表?
从第一部分了解到的信息来看,分库分表方案可以分为下面3种:
| 切分方案 | 解决的问题 |
|---|---|
| 只分库部分表 | 数据库读/写QPS过高,数据库连接不足 |
| 只分表部分库 | 单表数据量过大,存储性能遇到瓶颈 |
| 即分库又分表 | 连接数不足+数据量过大引起的存储性能瓶颈 |
如何选择我们自己的切分方案?
如果需要分表,那么分多少张表合适?
由于所有的技术都是为业务服务的,那么,我们就先从数据方面回顾下业务背景。
比如,我们这个业务系统是为了解决会员的咨询诉求,通过我们的XSpace客服平台系统来服务会员,目前主要以同步的离线工单数据作为我们的数据源来构建自己的数据。
假设,每一笔离线工单都会产生对应一笔会员的咨询问题(我们简称:问题单),如果:
在线渠道:每天产生 3w 笔聊天会话,假设,其中50%的会话会生成一笔离线工单,那么每天可生成 3w * 50% = 1.5w 笔工单;
热线渠道:每天产生 2.5w 通电话,假设,其中80%的电话都会产生一笔工单,那么每天可生成 2.5w * 80% = 2w 笔/天;
离线渠道:假设离线渠道每天直接生成 3w 笔;
合计共 1.5w + 2w + 3w = 6.5w 笔/天
考虑到以后可能要继续覆盖的新的业务场景,需要提前预留部分扩展空间,这里我们假设为每天产生 8w 笔问题单。
除问题单外,还有另外2张常用的业务表:用户操作日志表、用户提交的表单数据表。
其中,每笔问题单都会产生多条用户操作日志,根据历史统计数据来可以看到,平均每个问题单大约会产生8条操作日志,我们预留一部分空间,假设每个问题单平均产生约10条用户操作日志。
如果系统设计使用年限5年,那么问题单数据量大约 = 5年 365天/年 8w/天 = 1.46亿,那么估算出的表数量如下:
问题单需要:1.46亿/500w = 29.2 张表,我们就按 32 张表来切分;
操作日志需要 :32 10 = 320 张表,我们就按 32 16 = 512 张表来切分。
如果需要分库,那么分多少库合适?
分库的时候除了要考虑平时的业务峰值读写QPS外,还要考虑到诸如双11大促期间可能达到的峰值,需要提前做好预估。
根据我们的实际业务场景,问题单的数据查询来源主要来自于阿里客服小蜜首页。因此,可以根据历史QPS、RT等数据评估,假设我们只需要3500数据库连接数,如果单库可以承担最高1000个数据库连接,那么我们就可以拆分成4个库。
如何对数据进行切分?
根据行业惯例,通常按照 水平切分、垂直切分 两种方式进行切分,当然,有些复杂业务场景也可能选择两者结合的方式。
(1)水平切分
这是一种横向按业务维度切分的方式,比如常见的按会员维度切分,根据一定的规则把不同的会员相关的数据散落在不同的库表中。由于我们的业务场景决定都是从会员视角进行数据读写,所以,我们就选择按照水平方式进行数据库切分。
(2)垂直切分
垂直切分可以简单理解为,把一张表的不同字段拆分到不同的表中。
比如:假设有个小型电商业务,把一个订单相关的商品信息、买卖家信息、支付信息都放在一张大表里。可以考虑通过垂直切分的方式,把商品信息、买家信息、卖家信息、支付信息都单独拆分成独立的表,并通过订单号跟订单基本信息关联起来。
也有一种情况,如果一张表有10个字段,其中只有3个字段需要频繁修改,那么就可以考虑把这3个字段拆分到子表。避免在修改这3个数据时,影响到其余7个字段的查询行锁定。
分库
数据库准备
此处模拟云医院管理系统当数据库连接压力过大时进行数据库的拆分,计划拆分成两个数据库。
数据库设计关系如下:
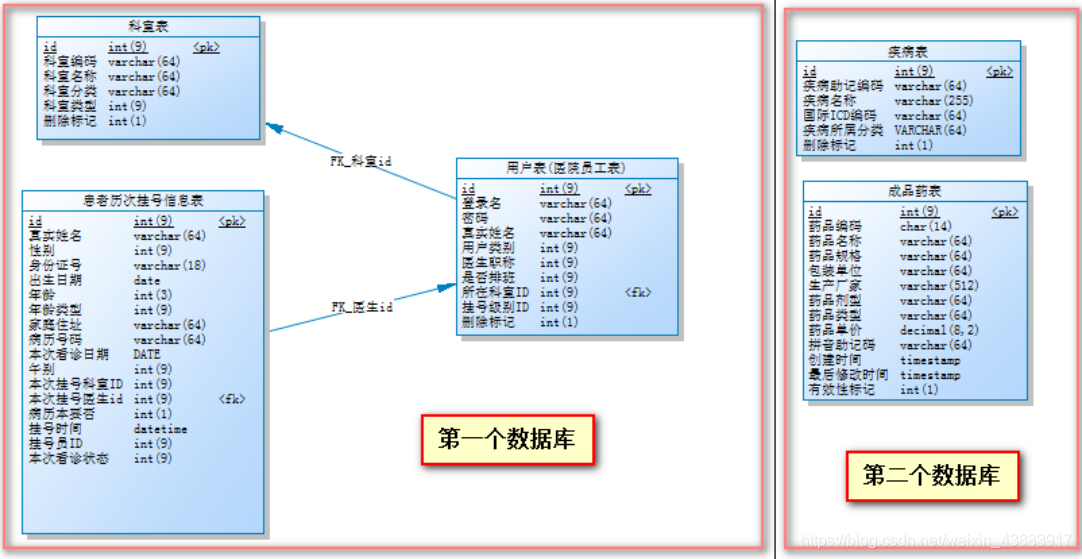
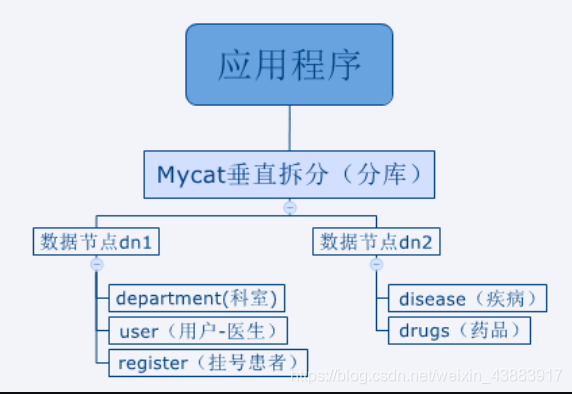
根据上述业务表关联关系科室、用户表、挂号信息表三个表之间是有关联关系的所以应该放到一个数据节点上,另外两张表为了测试放到另外一个数据节点上,表示成如下形式:
停止之前的数据库
分库一定要在新的数据库上准备,此处抛弃上述数据库重新创建干净的数据库
删除掉原来的数据库(容器),可以仅停止不删除容器用于测试之前的逻辑
[root@mycat ~]# docker stop m1 && docker stop m2 && docker stop s1 && docker stop s2
m1
m2
s1
s2
[root@mycat ~]# docker rm m1 && docker rm m2 && docker rm s1 && docker rm s2
m1
m2
s1
s2
[root@mycat ~]# 安装两个数据库服务(容器)
创建两个数据库,此处暂时不配置主从数据库复制(Master-Slave模式)所以不需要在docker宿主机上单独映射配置文件,执行如下命令直接创建2个MySQL数据库容器
docker run --name dn1 -p 3316:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 docker run --name dn2 -p 3326:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
具体执行过程如下:
[root@mycat ~]# docker run --name dn1 -p 3316:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 &&\
> docker run --name dn2 -p 3326:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
b9b3297b30ae82cd25889414e76e16c0fa20c186535a1c6b0d2d15469163b40e
e61487a76ef284927f031897ac38d7c6d00c88c191265f946fcf6bb237f04f54
[root@mycat ~]#
查看两个数据库机器(容器)的ip
[root@mycat ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fd2bea0b1f01 mysql:5.7 "docker-entrypoint.s…" 5 seconds ago Up 3 seconds 33060/tcp, 0.0.0.0:3326->3306/tcp, :::3326->3306/tcp dn2
6ae712c5f59c mysql:5.7 "docker-entrypoint.s…" 6 seconds ago Up 5 seconds 33060/tcp, 0.0.0.0:3316->3306/tcp, :::3316->3306/tcp dn1[root@mycat ~]# docker inspect --format '{{ .NetworkSettings.IPAddress }}' dn1 &&\
> docker inspect --format '{{ .NetworkSettings.IPAddress }}' dn2
172.17.0.2
172.17.0.3
[root@mycat ~]#
ip地址分别是:
| 容器 | IP |
|---|---|
| dn1 | 172.17.0.2 |
| dn2 | 172.17.0.3 |
创建数据库
在两个空白数据库机器(容器)上创建数据库语句如下:
CREATE DATABASE his_mycat DEFAULT CHARACTER SET utf8mb4;
在dn1上创建数据库
[root@mycat ~]# mysql -u root -proot -h 172.17.0.2 -P3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.7.34 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> CREATE DATABASE his_mycat DEFAULT CHARACTER SET utf8mb4;
Query OK, 1 row affected (0.01 sec)MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| his_mycat |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)MySQL [(none)]> exit
Bye
[root@mycat ~]#
在dn2上创建数据库
[root@mycat ~]# mysql -u root -proot -h 172.17.0.3 -P3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> CREATE DATABASE his_mycat DEFAULT CHARACTER SET utf8mb4;
Query OK, 1 row affected (0.00 sec)MySQL [(none)]>
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| his_mycat |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)MySQL [(none)]> exit
Bye
[root@mycat ~]#
配置mycat
分库规则:
- dn1:department部门表、user用户表、register患者挂号表
- dn2:drugs 药品表、disease 疾病表
修改mycat的schema.xml重新配置分库规则:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="drugs" dataNode="dn2"></table><table name="disease" dataNode="dn2"></table></schema><dataNode name="dn1" dataHost="host1" database="his_mycat"/><dataNode name="dn2" dataHost="host2" database="his_mycat"/><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root"></writeHost></dataHost></mycat:schema>
启动mycat
在mycat/bin目录中执行
./mycat console
登录mycat创建表结构
/****dn1****/CREATE TABLE `department` (`id` int(9) NOT NULL AUTO_INCREMENT COMMENT 'id',`DeptCode` varchar(64) NOT NULL COMMENT '科室编码',`DeptName` varchar(64) NOT NULL COMMENT '科室名称',`DeptCategory` varchar(64) DEFAULT NULL COMMENT '科室分类',`DeptTypeID` int(9) NOT NULL COMMENT '科室类型',`DelMark` int(1) DEFAULT NULL COMMENT '删除标记',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `user` (`id` int(9) NOT NULL COMMENT 'id',`UserName` varchar(64) NOT NULL COMMENT '登录名',`Password` varchar(64) DEFAULT NULL COMMENT '密码',`RealName` varchar(64) NOT NULL COMMENT '真实姓名',`UserTypeID` int(9) DEFAULT NULL COMMENT '1 - 挂号人员 2 - 门诊医生 3 - 医技医生 4 - 药房人员 5 - 财务人员 6 - 行政人员 ',`DocTitleID` int(9) DEFAULT NULL COMMENT '医生职称',`IsScheduling` int(9) DEFAULT NULL COMMENT '是否排班',`DeptId` int(9) NOT NULL COMMENT '所在科室ID',`RegistId` int(9) DEFAULT NULL COMMENT '挂号级别ID',`DelMark` int(1) DEFAULT NULL COMMENT '删除标记',PRIMARY KEY (`id`),KEY `FK_科室id` (`DeptId`),CONSTRAINT `FK_科室id` FOREIGN KEY (`DeptId`) REFERENCES `department` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `register` (`id` int(9) NOT NULL COMMENT 'id',`RealName` varchar(64) DEFAULT NULL COMMENT '真实姓名',`Gender` int(9) DEFAULT NULL COMMENT '性别',`IDnumber` varchar(18) DEFAULT NULL COMMENT '身份证号',`BirthDate` date DEFAULT NULL COMMENT '出生日期',`Age` int(3) DEFAULT NULL COMMENT '年龄',`AgeType` int(9) DEFAULT NULL COMMENT '年龄类型',`HomeAddress` varchar(64) DEFAULT NULL COMMENT '家庭住址',`CaseNumber` varchar(64) DEFAULT NULL COMMENT '一名患者在同一医院看诊多次,根据患者是否使用同一个病历本,确定该患者的“病历号码”是否相同。',`VisitDate` date NOT NULL COMMENT '本次看诊日期',`Noon` int(9) NOT NULL COMMENT '午别',`DeptId` int(9) DEFAULT NULL COMMENT '本次挂号科室ID',`UserId` int(9) DEFAULT NULL COMMENT '本次挂号医生id',`IsBook` int(1) NOT NULL COMMENT '病历本要否',`RegisterTime` datetime DEFAULT NULL COMMENT '挂号时间',`RegisterID` int(9) NOT NULL COMMENT '挂号员ID',`VisitState` int(9) DEFAULT NULL COMMENT '本次看诊状态',PRIMARY KEY (`id`),KEY `FK_医生id` (`UserId`),CONSTRAINT `FK_医生id` FOREIGN KEY (`UserId`) REFERENCES `user` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;/****dn2****/
CREATE TABLE `disease` (`id` int(9) NOT NULL COMMENT 'id',`DiseaseCode` varchar(64) DEFAULT NULL COMMENT '疾病助记编码',`DiseaseName` varchar(255) DEFAULT NULL COMMENT '疾病名称',`DiseaseICD` varchar(64) DEFAULT NULL COMMENT '国际ICD编码',`DiseaseType` varchar(64) DEFAULT NULL COMMENT '疾病所属分类',`DelMark` int(1) DEFAULT NULL COMMENT '删除标记',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `drugs` (`id` int(9) NOT NULL COMMENT 'id',`Drugs_Code` char(14) DEFAULT NULL COMMENT '药品编码',`Drugs_Name` varchar(64) DEFAULT NULL COMMENT '药品名称',`Drugs_Format` varchar(64) DEFAULT NULL COMMENT '药品规格',`Drugs_Unit` varchar(64) DEFAULT NULL COMMENT '包装单位',`Manufacturer` varchar(512) DEFAULT NULL COMMENT '生产厂家',`Drugs_Dosage` varchar(64) DEFAULT NULL COMMENT '药品剂型',`Drugs_Type` varchar(64) DEFAULT NULL COMMENT '药品类型',`Drugs_Price` decimal(8,2) DEFAULT NULL COMMENT '药品单价',`Mnemonic_Code` varchar(64) DEFAULT NULL COMMENT '拼音助记码',`Creation_Date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',`DelMark` int(1) DEFAULT NULL COMMENT '有效性标记',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
验证
创建完成后分别在mycat客户端、dn1节点、dn2节点查看表存储情况
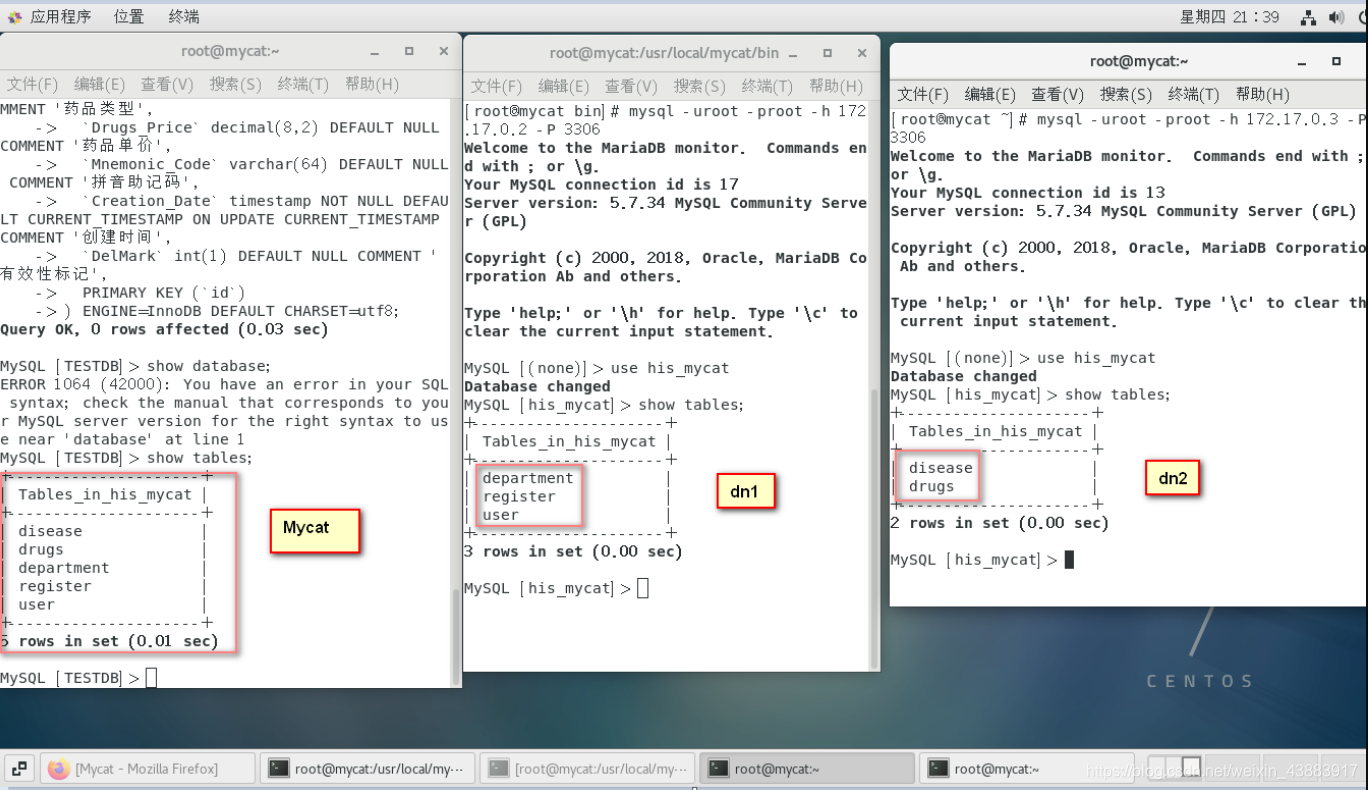
Mycat客户端验证
执行过程如下:
[root@mycat ~]# mysql -umycat -p123456 -h 127.0.0.1 -P8066
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.29-mycat-1.6-RELEASE-20161028204710 MyCat Server (OpenCloundDB)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> use TESTDB
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changedMySQL [TESTDB]> CREATE TABLE `department` (-> `id` int(9) NOT NULL AUTO_INCREMENT COMMENT 'id',-> `DeptCode` varchar(64) NOT NULL COMMENT '科室编码',-> `DeptName` varchar(64) NOT NULL COMMENT '科室名称',-> `DeptCategory` varchar(64) DEFAULT NULL COMMENT '科室分类',-> `DeptTypeID` int(9) NOT NULL COMMENT '科室类型',-> `DelMark` int(1) DEFAULT NULL COMMENT ' 删除标记',-> PRIMARY KEY (`id`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.02 sec)MySQL [TESTDB]>
MySQL [TESTDB]> CREATE TABLE `user` (-> `id` int(9) NOT NULL COMMENT 'id',-> `UserName` varchar(64) NOT NULL COMMENT '登录名',-> `Password` varchar(64) DEFAULT NULL COMMENT '密码',-> `RealName` varchar(64) NOT NULL COMMENT '真实姓名',-> `UserTypeID` int(9) DEFAULT NULL COMMENT '1 - 挂号人员 2 - 门诊医生 3 - 医技医生 4 - 药房人员 5 - 财务人员 6 - 行政人员 ',-> `DocTitleID` int(9) DEFAULT NULL COMMENT '医生职称',-> `IsScheduling` int(9) DEFAULT NULL COMMENT '是否排班',-> `DeptId` int(9) NOT NULL COMMENT '所在科室ID',-> `RegistId` int(9) DEFAULT NULL COMMENT '挂号级别ID',-> `DelMark` int(1) DEFAULT NULL COMMENT ' 删除标记',-> PRIMARY KEY (`id`),-> KEY `FK_科室id` (`DeptId`),-> CONSTRAINT `FK_科室id` FOREIGN KEY (`DeptId`) REFERENCES `department` (`id`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.06 sec)MySQL [TESTDB]>
MySQL [TESTDB]>
MySQL [TESTDB]> CREATE TABLE `register` (-> `id` int(9) NOT NULL COMMENT 'id',-> `RealName` varchar(64) DEFAULT NULL COMMENT '真实姓名',-> `Gender` int(9) DEFAULT NULL COMMENT '性别',-> `IDnumber` varchar(18) DEFAULT NULL COMMENT '身份证号',-> `BirthDate` date DEFAULT NULL COMMENT ' 出生日期',-> `Age` int(3) DEFAULT NULL COMMENT '年龄',-> `AgeType` int(9) DEFAULT NULL COMMENT ' 年龄类型',-> `HomeAddress` varchar(64) DEFAULT NULL COMMENT '家庭住址',-> `CaseNumber` varchar(64) DEFAULT NULL COMMENT '一名患者在同一医院看诊多次,根据患者是否使用同一个病历本,确定该患者的“病历号码”是否相同。',-> `VisitDate` date NOT NULL COMMENT '本次 看诊日期',-> `Noon` int(9) NOT NULL COMMENT '午别',-> `DeptId` int(9) DEFAULT NULL COMMENT '本次挂号科室ID',-> `UserId` int(9) DEFAULT NULL COMMENT '本次挂号医生id',-> `IsBook` int(1) NOT NULL COMMENT '病历本要否',-> `RegisterTime` datetime DEFAULT NULL COMMENT '挂号时间',-> `RegisterID` int(9) NOT NULL COMMENT '挂号员ID',-> `VisitState` int(9) DEFAULT NULL COMMENT '本次看诊状态',-> PRIMARY KEY (`id`),-> KEY `FK_医生id` (`UserId`),-> CONSTRAINT `FK_医生id` FOREIGN KEY (`UserId`) REFERENCES `user` (`id`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)MySQL [TESTDB]>
MySQL [TESTDB]>
MySQL [TESTDB]> /****dn2****/
MySQL [TESTDB]> CREATE TABLE `disease` (-> `id` int(9) NOT NULL COMMENT 'id',-> `DiseaseCode` varchar(64) DEFAULT NULL COMMENT '疾病助记编码',-> `DiseaseName` varchar(255) DEFAULT NULL COMMENT '疾病名称',-> `DiseaseICD` varchar(64) DEFAULT NULL COMMENT '国际ICD编码',-> `DiseaseType` varchar(64) DEFAULT NULL COMMENT '疾病所属分类',-> `DelMark` int(1) DEFAULT NULL COMMENT ' 删除标记',-> PRIMARY KEY (`id`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)MySQL [TESTDB]>
MySQL [TESTDB]>
MySQL [TESTDB]> CREATE TABLE `drugs` (-> `id` int(9) NOT NULL COMMENT 'id',-> `Drugs_Code` char(14) DEFAULT NULL COMMENT '药品编码',-> `Drugs_Name` varchar(64) DEFAULT NULL COMMENT '药品名称',-> `Drugs_Format` varchar(64) DEFAULT NULL COMMENT '药品规格',-> `Drugs_Unit` varchar(64) DEFAULT NULL COMMENT '包装单位',-> `Manufacturer` varchar(512) DEFAULT NULL COMMENT '生产厂家',-> `Drugs_Dosage` varchar(64) DEFAULT NULL COMMENT '药品剂型',-> `Drugs_Type` varchar(64) DEFAULT NULL COMMENT '药品类型',-> `Drugs_Price` decimal(8,2) DEFAULT NULL COMMENT '药品单价',-> `Mnemonic_Code` varchar(64) DEFAULT NULL COMMENT '拼音助记码',-> `Creation_Date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',-> `DelMark` int(1) DEFAULT NULL COMMENT ' 有效性标记',-> PRIMARY KEY (`id`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)MySQL [TESTDB]> show tables;
+---------------------+
| Tables_in_his_mycat |
+---------------------+
| disease |
| drugs |
| department |
| register |
| user |
+---------------------+
5 rows in set (0.01 sec)MySQL [TESTDB]>
dn1节点验证
[root@mycat bin]# mysql -uroot -proot -h 172.17.0.2 -P 3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 17
Server version: 5.7.34 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> use his_mycat
Database changed
MySQL [his_mycat]> show tables;
+---------------------+
| Tables_in_his_mycat |
+---------------------+
| department |
| register |
| user |
+---------------------+
3 rows in set (0.00 sec)MySQL [his_mycat]>
dn2节点验证
[root@mycat ~]# mysql -uroot -proot -h 172.17.0.3 -P 3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 13
Server version: 5.7.34 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> use his_mycat
Database changed
MySQL [his_mycat]> show tables;
+---------------------+
| Tables_in_his_mycat |
+---------------------+
| disease |
| drugs |
+---------------------+
2 rows in set (0.00 sec)MySQL [his_mycat]>
分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中。
需求
在电信行业有电信计费系统(BOSS系统),假设其中存储如下信息:
- 客户手机账户(手机号)信息
- 手机通话记录信息
- 字典表(如存储常用的码表信息,例如 通话类型,01:呼出,02:呼入等)
简单ER图如下:
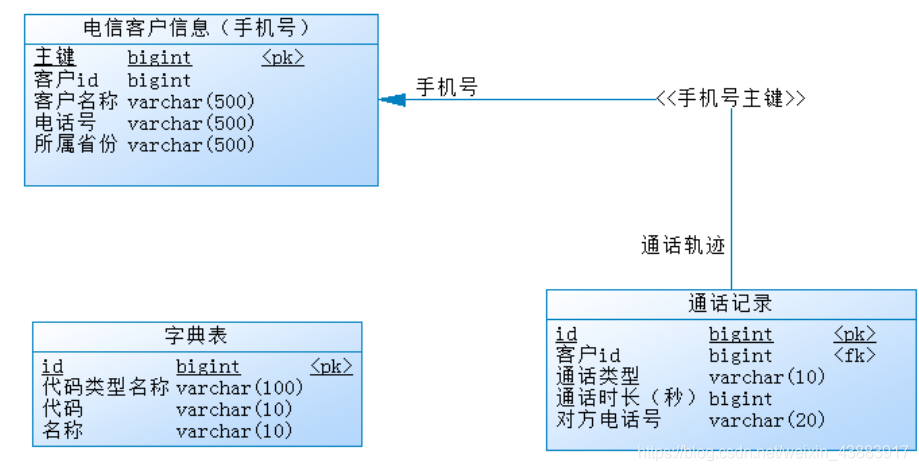
MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率,
需要进行水平拆分(分表)进行优化。BOSS系统预测5年内客户手机账户表5000万条以上。解决方案是将手机号表进行水平拆分。
表结构sql语句如下:
/* 创建数据库 */
CREATE DATABASE boss;USE boss;/* 客户手机号表 */
CREATE TABLE customer (id bigint(20) NOT NULL COMMENT '主键',cid bigint(20) DEFAULT NULL COMMENT '客户id',name varchar(500) DEFAULT NULL COMMENT '客户名称',phone varchar(500) DEFAULT NULL COMMENT '电话号',provice varchar(500) DEFAULT NULL COMMENT '所属省份',PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电信客户信息(手机号)';/* 手机号通话记录 */
CREATE TABLE calllog (id bigint(20) NOT NULL COMMENT 'id',phone_id bigint(20) DEFAULT NULL COMMENT '主键',type varchar(10) DEFAULT NULL COMMENT '通话类型',duration bigint(20) DEFAULT NULL COMMENT '通话时长(秒)',othernum varchar(20) DEFAULT NULL COMMENT '对方电话号',PRIMARY KEY (id),KEY FK_Reference_1 (phone_id),CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='通话记录';/* 字典表 */
CREATE TABLE dict (id bigint(20) NOT NULL COMMENT 'id',caption varchar(100) DEFAULT NULL COMMENT '代码类型名称',code varchar(10) DEFAULT NULL COMMENT '代码',name varchar(10) DEFAULT NULL COMMENT '名称',PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='字典表';分表实现(取模)
此规则为对分片字段求摸运算
<tableRule name="mod-long"><rule><columns>user_id</columns><algorithm>mod-long</algorithm></rule>
</tableRule><function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">3</property>
</function>
上面 columns 标识将要分片的表字段,algorithm 分片函数,
此种配置非常明确即根据 id 进行十进制求模预算,相比固定分片 hash,此种在批量插入时可能存在批量插入单
事务插入多数据分片,增大事务一致性难度(因此种方式实现最简单所以优先说明)。
原则
以客户表(customer)为例可以采用不同字段进行分表:
| 序号 | 分表字段 | 说明 |
|---|---|---|
| 1 | id(主键、或创建时间) | 从业务上来看同一个客户的不同手机号分布在不同的数据节点上,可能造成查询效率降低 |
| 2 | cid(客户 id)、provice(省份) | 根据客户 id 去分,两个节点访问平均,一个客户所有的手机号都在同一个数据节点上。 |
安装数据库
此处同上述过程一样采用docker容器模拟不同的数据节点。此处为测试方便创建两个MySQL数据库容器。
docker run --name spt1 -p 3416:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 docker run --name spt2 -p 3426:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
执行过程如下:
[root@mycat ~]# docker run --name spt1 -p 3416:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 && docker run --name spt2 -p 3426:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
c9273c38f676aaf09321c6b117cf9445d5a15a632694480daf02db8cc9352bf6
5b19f22dbefbd00a65aaa6185a0c493518b4d71a5ff10b63f0bef6404efbb9bc
[root@mycat ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5b19f22dbefb mysql:5.7 "docker-entrypoint.s…" 4 seconds ago Up 2 seconds 33060/tcp, 0.0.0.0:3426->3306/tcp, :::3426->3306/tcp spt2
c9273c38f676 mysql:5.7 "docker-entrypoint.s…" 6 seconds ago Up 4 seconds 33060/tcp, 0.0.0.0:3416->3306/tcp, :::3416->3306/tcp spt1
[root@mycat ~]# 创建数据库、表
分别连接两个容器,并执行上述sql脚本用于创建数据库、数据库表。
1、查询两个容器的ip地址
[root@mycat ~]# docker inspect --format '{{ .NetworkSettings.IPAddress }}' spt1 | awk '{print "spt1:",$1}' && docker inspect --format '{{ .NetworkSettings.IPAddress }}' spt2 | awk '{print "spt2:",$1}'spt1: 172.17.0.2
spt2: 172.17.0.3
[root@mycat ~]# 2、连接容器spt1,执行数据库脚本
[root@mycat ~]# mysql -uroot -proot -h172.17.0.2 -P 3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> /* 创建数据库 */
MySQL [(none)]> CREATE DATABASE boos;
Query OK, 1 row affected (0.00 sec)MySQL [(none)]>
MySQL [(none)]> USE boos;phone varchar(500) DEFAULT NULL COMMENT '电话号',provice varchar(500) DEFAULT NULL COMMENT '所属省份',PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电信客户信息(手机号)';/* 手机号通话记录 */
CREATE TABLE calllog (id bigint(20) NOT NULL COMMENT 'id',phone_id bigint(20) DEFAULT NULL COMMENT '客户手机号外键',type varchar(10) DEFAULT NULL COMMENT '通话类型',duration bigint(20) DEFAULT NULL COMMENT '通话时长(秒)',othernum varchar(20) DEFAULT NULL COMMENT '对方电话号',PRIMARY KEY (id),KEY FK_Reference_1 (phone_id),CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='通话记录';/* 字典表 */
CREATE TABLE dict (id bigint(20) NOT NULL COMMENT 'id',caption varchar(100) DEFAULT NULL COMMENT '代码类型名称',code varchar(10) DEFAULT NULL COMMENT '代码',name varchar(10) DEFAULT NULL COMMENT '名称',PRIMARY KEY (id)
) ENGINE=InnoDB DEFDatabase changed
MySQL [boos]>
MySQL [boos]> /* 客户手机号表 */
MySQL [boos]> CREATE TABLE customer (-> id bigint(20) NOT NULL COMMENT '主键',-> cid bigint(20) DEFAULT NULL COMMENT '客户id',-> name varchar(500) DEFAULT NULL COMMENT '客户名称',-> phone varchar(500) DEFAULT NULL COMMENT '电话号',-> provice varchar(500) DEFAULT NULL COMMENT '所属省份',-> PRIMARY KEY (id)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电信客户信息(手机号)';
AULT CHARSET=utf8mb4 COMMENT='字典表';Query OK, 0 rows affected (0.04 sec)MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* 手机号通话记录 */
MySQL [boos]> CREATE TABLE calllog (-> id bigint(20) NOT NULL COMMENT 'id',-> phone_id bigint(20) DEFAULT NULL COMMENT '主键',-> type varchar(10) DEFAULT NULL COMMENT '通话类型',-> duration bigint(20) DEFAULT NULL COMMENT '通话时长(秒)',-> othernum varchar(20) DEFAULT NULL COMMENT '对方电话号',-> PRIMARY KEY (id),-> KEY FK_Reference_1 (phone_id),-> CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='通话记录';
Query OK, 0 rows affected (0.03 sec)MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* 字典表 */
MySQL [boos]> CREATE TABLE dict (-> id bigint(20) NOT NULL COMMENT 'id',-> caption varchar(100) DEFAULT NULL COMMENT '代码类型名称',-> code varchar(10) DEFAULT NULL COMMENT '代码',-> name varchar(10) DEFAULT NULL COMMENT '名称',-> PRIMARY KEY (id)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='字典表';
Query OK, 0 rows affected (0.02 sec)MySQL [boos]> show tables;
+----------------+
| Tables_in_boos |
+----------------+
| calllog |
| customer |
| dict |
+----------------+
3 rows in set (0.00 sec)MySQL [boos]> 3、连接容器spt1,执行数据库脚本
[root@mycat ~]# mysql -uroot -proot -h172.17.0.3 -P 3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34 MySQL Community Server (GPL)Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]> /* 创建数据库 */
MySQL [(none)]> CREATE DATABASE boos;
Query OK, 1 row affected (0.00 sec)MySQL [(none)]>
MySQL [(none)]> USE boos;phone varchar(500) DEFAULT NULL COMMENT '电话号',provice varchar(500) DEFAULT NULL COMMENT '所属省份',PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电信客户信息(手机号)';/* 手机号通话记录 */
CREATE TABLE calllog (id bigint(20) NOT NULL COMMENT 'id',phone_id bigint(20) DEFAULT NULL COMMENT '主键',type varchar(10) DEFAULT NULL COMMENT '通话类型',duration bigint(20) DEFAULT NULL COMMENT '通话时长(秒)',othernum varchar(20) DEFAULT NULL COMMENT '对方电话号',PRIMARY KEY (id),KEY FK_Reference_1 (phone_id),CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='通话记录';/* 字典表 */
CREATE TABLE dict (id bigint(20) NOT NULL COMMENT 'id',caption varchar(100) DEFAULT NULL COMMENT '代码类型名称',code varchar(10) DEFAULT NULL COMMENT '代码',name varchar(10) DEFAULT NULL COMMENT '名称',PRIMARY KEY (id)
) ENGINE=InnoDB DEFDatabase changed
MySQL [boos]>
MySQL [boos]> /* 客户手机号表 */
MySQL [boos]> CREATE TABLE customer (-> id bigint(20) NOT NULL COMMENT '主键',-> cid bigint(20) DEFAULT NULL COMMENT '客户id',-> name varchar(500) DEFAULT NULL COMMENT '客户名称',-> phone varchar(500) DEFAULT NULL COMMENT '电话号',-> provice varchar(500) DEFAULT NULL COMMENT '所属省份',-> PRIMARY KEY (id)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电信客户信息(手机号)';
AULT CHARSET=utf8mb4 COMMENT='字典表';Query OK, 0 rows affected (0.04 sec)MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* 手机号通话记录 */
MySQL [boos]> CREATE TABLE calllog (-> id bigint(20) NOT NULL COMMENT 'id',-> phone_id bigint(20) DEFAULT NULL COMMENT '主键',-> type varchar(10) DEFAULT NULL COMMENT '通话类型',-> duration bigint(20) DEFAULT NULL COMMENT '通话时长(秒)',-> othernum varchar(20) DEFAULT NULL COMMENT '对方电话号',-> PRIMARY KEY (id),-> KEY FK_Reference_1 (phone_id),-> CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='通话记录';
Query OK, 0 rows affected (0.03 sec)MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* 字典表 */
MySQL [boos]> CREATE TABLE dict (-> id bigint(20) NOT NULL COMMENT 'id',-> caption varchar(100) DEFAULT NULL COMMENT '代码类型名称',-> code varchar(10) DEFAULT NULL COMMENT '代码',-> name varchar(10) DEFAULT NULL COMMENT '名称',-> PRIMARY KEY (id)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='字典表';
Query OK, 0 rows affected (0.02 sec)MySQL [boos]> show tables;
+----------------+
| Tables_in_boos |
+----------------+
| calllog |
| customer |
| dict |
+----------------+
3 rows in set (0.00 sec)MySQL [boos]> mycat实现分表
根据需求此处需要将customer 进行水平拆分,并分布到两个数据节点spt1、spt2上。需要做如下修改
1、修改schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="spt1"><!-- rule="customer_rule" 使用的 分片规则,需要在rule.xml中配置--><table name="customer " dataNode="spt1,spt2" rule="customer_rule" ></table></schema><dataNode name="spt1" dataHost="host1" database="boos"/><dataNode name="spt2" dataHost="host2" database="boos"/><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root"></writeHost></dataHost></mycat:schema>
2、修改rule.xml配置customer_rule规则
在 rule 配置文件里新增分片规则 customer_rule,并指定规则适用字段为cid,
<tableRule name="customer_rule"><rule><!-- 分片字段--><columns>cid</columns><!-- 分片算法名 --><algorithm>mod-long</algorithm></rule></tableRule>
还有选择分片算法 mod-long(对字段求模运算),cid对两个节点求模,根据结果分片
配置算法 mod-long 参数 count 为 2,两个节点
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function>
配置完的完整的rule.xml如下
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/"><tableRule name="customer_rule"><rule><columns>cid</columns><algorithm>mod-long</algorithm></rule></tableRule><tableRule name="rule1"><rule><columns>id</columns><algorithm>func1</algorithm></rule></tableRule><tableRule name="rule2"><rule><columns>user_id</columns><algorithm>func1</algorithm></rule></tableRule><tableRule name="sharding-by-intfile"><rule><columns>sharding_id</columns><algorithm>hash-int</algorithm></rule></tableRule><tableRule name="auto-sharding-long"><rule><columns>id</columns><algorithm>rang-long</algorithm></rule></tableRule><tableRule name="mod-long"><rule><columns>id</columns><algorithm>mod-long</algorithm></rule></tableRule><tableRule name="sharding-by-murmur"><rule><columns>id</columns><algorithm>murmur</algorithm></rule></tableRule><tableRule name="crc32slot"><rule><columns>id</columns><algorithm>crc32slot</algorithm></rule></tableRule><tableRule name="sharding-by-month"><rule><columns>create_time</columns><algorithm>partbymonth</algorithm></rule></tableRule><tableRule name="latest-month-calldate"><rule><columns>calldate</columns><algorithm>latestMonth</algorithm></rule></tableRule><tableRule name="auto-sharding-rang-mod"><rule><columns>id</columns><algorithm>rang-mod</algorithm></rule></tableRule><tableRule name="jch"><rule><columns>id</columns><algorithm>jump-consistent-hash</algorithm></rule></tableRule><function name="murmur"class="io.mycat.route.function.PartitionByMurmurHash"><property name="seed">0</property><!-- 默认是0 --><property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 --><property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 --><!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 --><!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 --></function><function name="crc32slot"class="io.mycat.route.function.PartitionByCRC32PreSlot"><property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 --></function><function name="hash-int"class="io.mycat.route.function.PartitionByFileMap"><property name="mapFile">partition-hash-int.txt</property></function><function name="rang-long"class="io.mycat.route.function.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property></function><function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function><function name="func1" class="io.mycat.route.function.PartitionByLong"><property name="partitionCount">8</property><property name="partitionLength">128</property></function><function name="latestMonth"class="io.mycat.route.function.LatestMonthPartion"><property name="splitOneDay">24</property></function><function name="partbymonth"class="io.mycat.route.function.PartitionByMonth"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2015-01-01</property></function><function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod"><property name="mapFile">partition-range-mod.txt</property></function><function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash"><property name="totalBuckets">3</property></function>
</mycat:rule>
启动Mycat,登录Mycat插入数据进行验证
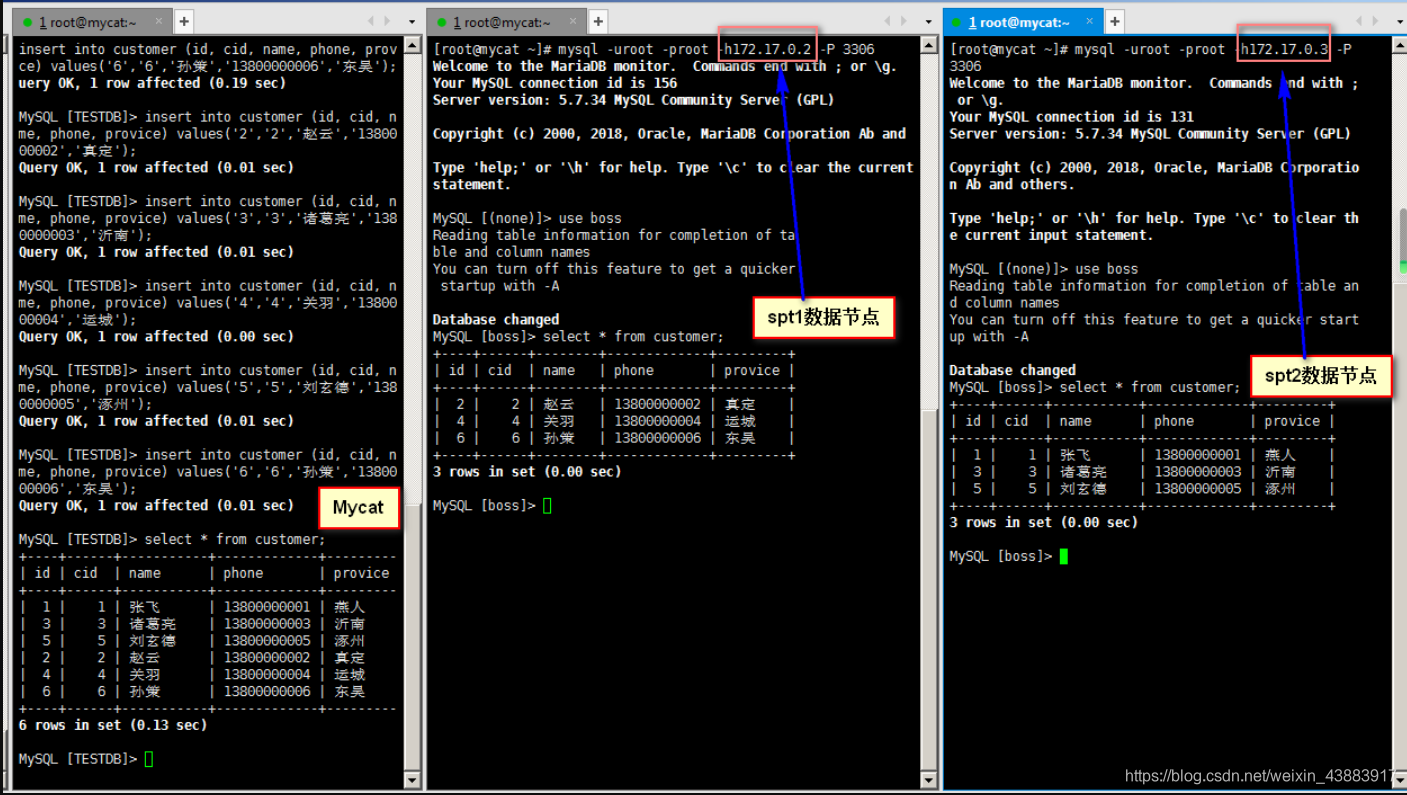
insert into customer (id, cid, name, phone, provice) values('1','1','张飞','13800000001','燕人');
insert into customer (id, cid, name, phone, provice) values('2','2','赵云','13800000002','真定');
insert into customer (id, cid, name, phone, provice) values('3','3','诸葛亮','13800000003','沂南');
insert into customer (id, cid, name, phone, provice) values('4','4','关羽','13800000004','运城');
insert into customer (id, cid, name, phone, provice) values('5','5','刘玄德','13800000005','涿州');
insert into customer (id, cid, name, phone, provice) values('6','6','孙策','13800000006','东吴');插入数据后在Mycat客户端、数据节点spt1、sp2上分别执行查询发现
- 数据节点spt1、spt2分别保存一部分数据
- mycat客户端可以查询出所有数据
需要注意的点,mycat插入时根据字段分片,需要提供字段枚举
正确的插入sql
insert into customer (id, cid, name, phone, provice) values('5','5','刘玄德','13800000005','涿州');
错误的sql
insert into customer values('6','6','孙策','13800000006','东吴');
不提供列的枚举会报如下错误:
MySQL [TESTDB]> insert into customer values('6','6','孙策','13800000006','东吴');
ERROR 1064 (HY000): partition table, insert must provide ColumnList
Mycat 的分片 join
Join 绝对是关系型数据库中最常用一个特性,然而在分布式环境中,跨分片的 join 确是最复杂的,最难解决一个问题。
Mycat性能建议
尽量避免使用 Left join 或 Right join,而用 Inner join
在使用 Left join 或 Right join 时,ON 会优先执行,where 条件在最后执行,所以在使用过程中,条件尽
可能的在 ON 语句中判断,减少 where 的执行
少用子查询,而用 join。
Mycat 目前版本支持跨分片的 join,主要实现的方式有四种。
全局表,ER 分片,catletT(人工智能)和 ShareJoin,ShareJoin 在开发版中支持,前面三种方式 1.3.0.1 支持。
ER分片
MyCAT 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提出了 TableGroup 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了 JION 的效率和性能问题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
customer(客户手机账户表) 采用 按照客户id取模 这个分片策略,分片在 spt1,spt2 上,calllog(呼叫记录表) 依赖父表进行分片,两个表的关联关系为 customer.id =calllog.phone_id。于是数据分片和存储的示意图如下:

这样一来,分片 spt1 上的的 customer 与 spt1 上的 calllog 就可以进行局部的 JOIN 联合,spt2(…sptn) 上也如此,再合并两个节点的数据即可完成整体的 JOIN,基于 E-R 映射的数据分片模式,基本上解决了 80%以上的企业应用所面临的问题。
实现
修改schema.xml文件,在上次配置基础上修改table标签,在customer 表下添加子标签
<childTable name="calllog" primaryKey="id" joinKey="id" parentKey="phone_id" />
完整的schema.xml文件如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="spt1"><!-- rule="customer_rule" 自定义的 分片规则,需要在rule.xml中配置--><table name="customer" dataNode="spt1,spt2" rule="customer_rule" ><!-- name="calllog" 子表(从表)名称primaryKey="id" 子表(从表)主键joinKey="id" 主表主键(customer.id)parentKey="phone_id" 从表中记录的外键(calllog.phone_id)--><childTable name="calllog" primaryKey="id" joinKey="id" parentKey="phone_id" /></table></schema><dataNode name="spt1" dataHost="host1" database="boss"/><dataNode name="spt2" dataHost="host2" database="boss"/><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root"></writeHost></dataHost></mycat:schema>
重新启动mycat(加载配置),登录mycat插入数据
insert into calllog (id, phone_id, type, duration, othernum) values('1','1','01','77','15800000001');
insert into calllog (id, phone_id, type, duration, othernum) values('2','1','02','45','15800000002');
insert into calllog (id, phone_id, type, duration, othernum) values('3','2','01','38','15800000003');
insert into calllog (id, phone_id, type, duration, othernum) values('4','2','02','64','15800000004');
insert into calllog (id, phone_id, type, duration, othernum) values('5','3','01','57','15800000005');
insert into calllog (id, phone_id, type, duration, othernum) values('6','3','02','88','15800000006');
insert into calllog (id, phone_id, type, duration, othernum) values('7','4','01','88','15800000007');
insert into calllog (id, phone_id, type, duration, othernum) values('8','4','02','69','15800000008');
insert into calllog (id, phone_id, type, duration, othernum) values('9','5','01','23','15800000009');
insert into calllog (id, phone_id, type, duration, othernum) values('10','5','02','46','15800000010');
insert into calllog (id, phone_id, type, duration, othernum) values('11','6','01','45','15800000011');
insert into calllog (id, phone_id, type, duration, othernum) values('12','6','02','77','15800000012');分别在mycat、数据节点spt1、spt2使用join查询
SELECT cus.id,cus.name '客户名称',log.type '通话类型',log.othernum '对方电话号'
FROMcustomer cus INNER JOIN calllog logON cus.id = log.phone_id
ORDER BY cus.id ;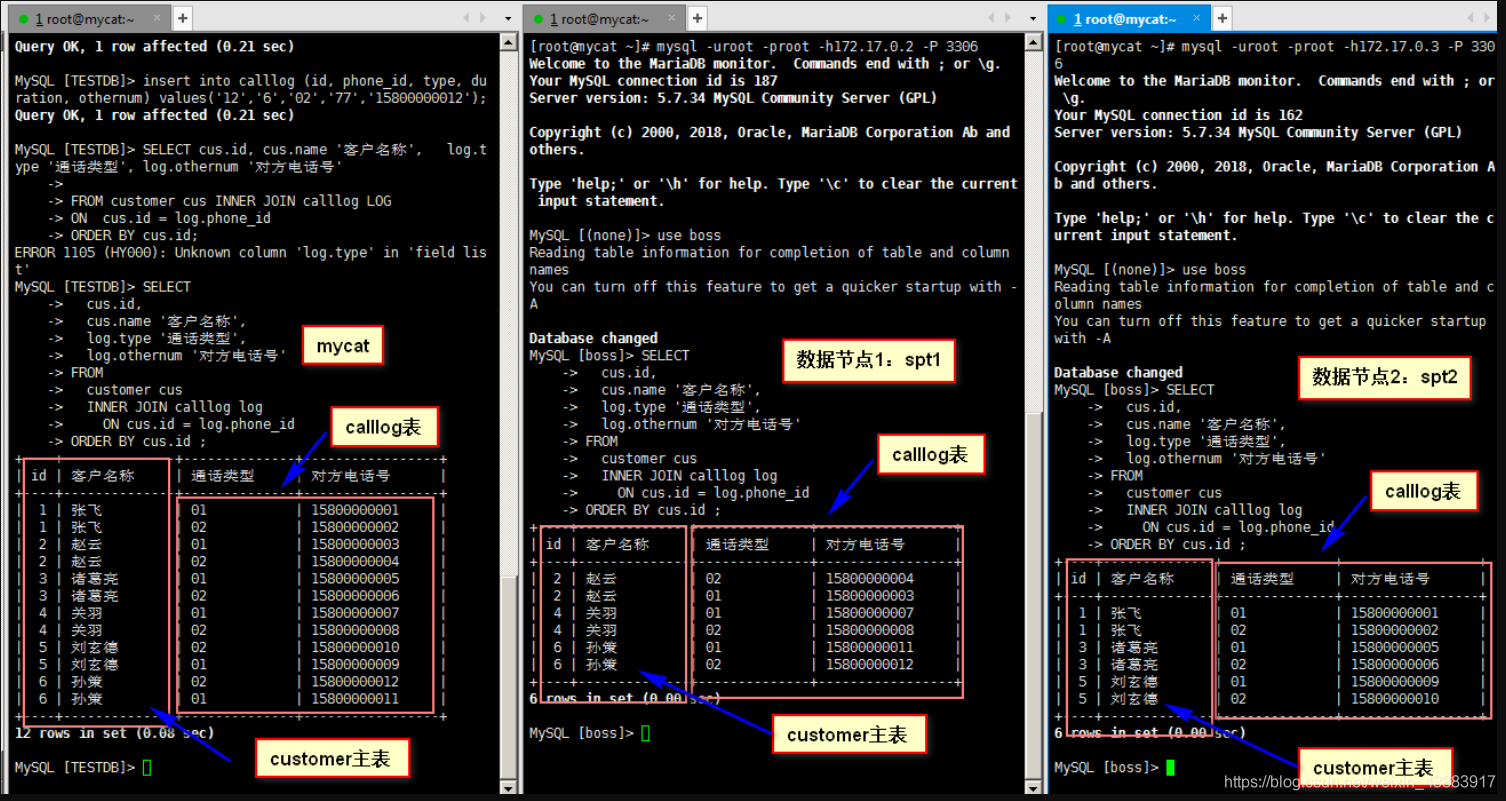
全局表
介绍
前几章节已经实现了表的的水平划分(分表)。上述表中还有一个dict(字典表)存储的是一些系统中常用的数据字典,如代表通话类型的代码(01:呼入,02:呼出),这张表如果单独在某一个数据节点(如:spt1)上,会导致另外数据节点(如:spt2)上的数据无法关联查询
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特性:
• 变动不频繁;
• 数据量总体变化不大;
• 数据规模不大,很少有超过数十万条记录。
对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以 Mycat 中通过数据冗余来解决这类表的 join,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。
数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
实现
修改 schema.xml 配置文件,添加table节点并设置为global类型
<table name="dict" dataNode="spt1,spt2" type="global" ></table>
全量配置文件如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="spt1"><!-- rule="customer_rule" 自定义的 分片规则,需要在rule.xml中配置--><table name="customer" dataNode="spt1,spt2" rule="customer_rule" ><!-- name="calllog" 子表(从表)名称primaryKey="id" 子表(从表)主键joinKey="phone_id" 从表中记录的外键(calllog.phone_id)parentKey="id" 主表主键(customer.id)--><childTable name="calllog" primaryKey="id" joinKey="phone_id" parentKey="id" /></table><!-- 设置 dict表为 global全局表,并在spt1、spt2两个数据节点冗余(内容重复)存在--><table name="dict" dataNode="spt1,spt2" type="global" ></table></schema><dataNode name="spt1" dataHost="host1" database="boss"/><dataNode name="spt2" dataHost="host2" database="boss"/><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root"></writeHost></dataHost></mycat:schema>
验证全局表
登录mycat插入字典表的数据
insert into dict (id, caption, code, name) values('1','ptype','01','呼出');
insert into dict (id, caption, code, name) values('2','ptype','02','呼入');分别在mycat客户端、数据节点spt1、spt2中查询关联dict表的sql
SELECT cus.id,cus.name '客户名称',dict.name '通话类型', log.othernum '对方电话号'
FROMcustomer cus INNER JOIN calllog logON cus.id = log.phone_id INNER JOIN dict ON dict.caption='ptype' AND dict.code = log.type
ORDER BY cus.id ;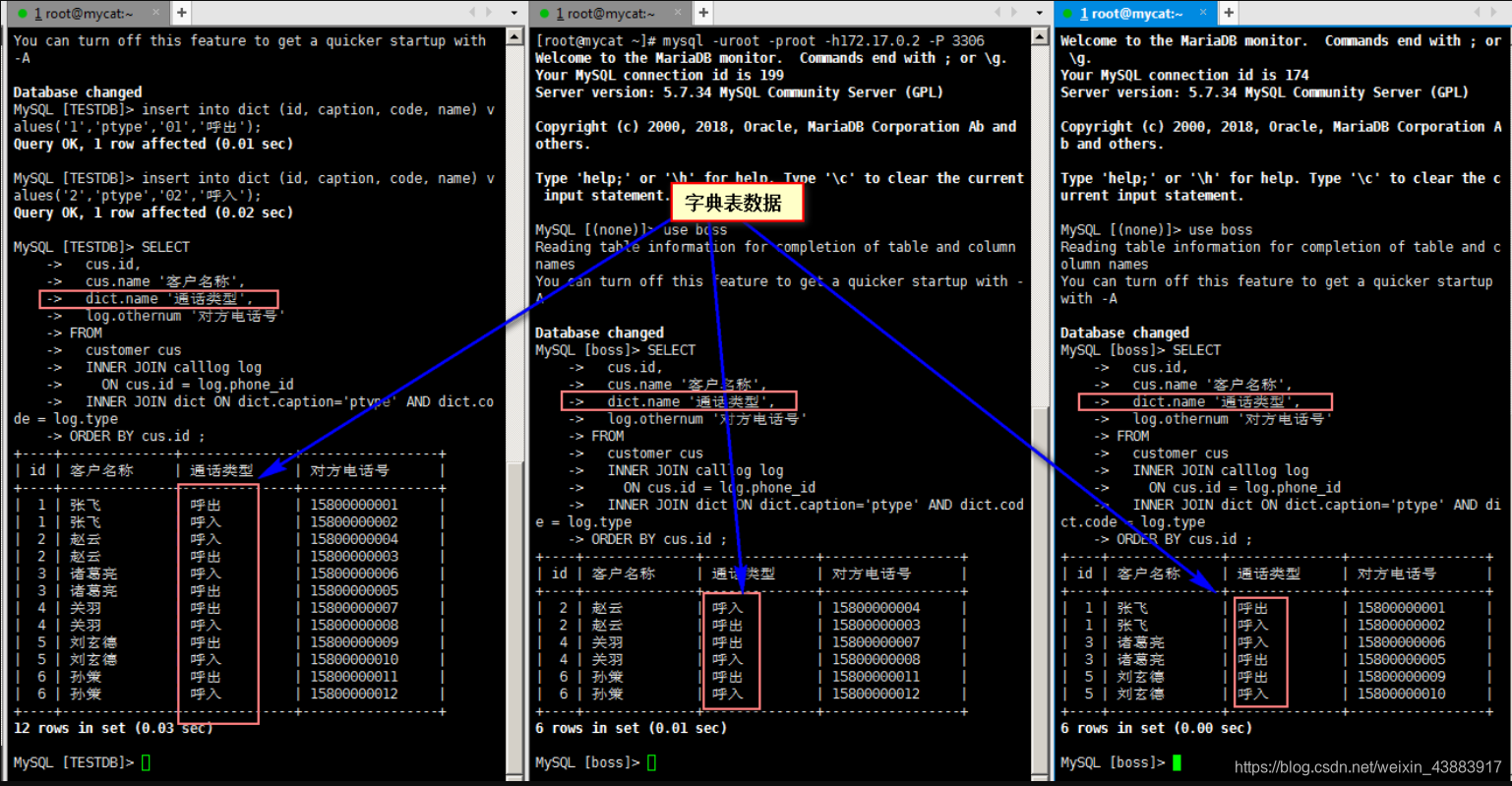
由于篇幅已经挺长了,就写一篇【Mycat的简单使用(四)【其它分片规则】】继续介绍
版权声明:
原创博主:牛哄哄的柯南
博主原文链接:https://keafmd.blog.csdn.net/
看完如果对你有帮助,感谢点赞支持!
如果你是电脑端,看到右下角的 “一键三连” 了吗,没错点它[哈哈]

加油!
共同努力!
Keafmd