目录
1.什么是索引?
PS:数据库引擎简介(InnoDB VS MyISAM)
2.为什么需要索引?
PS:存储数据模组
PS:查询数据存储的目录:
3.索引的作用
PS:索引 VS 书的目录
4.索引的优缺点和使用场景
4.1.索引优点
4.2.索引缺点
4.3.适合建索引的使用场景
4.4.不适合建索引的使用场景
4.5.注意事项
5.索引使用
5.1.索引分类
5.2.查看索引
5.3.创建索引
5.3.1.创建普通索引(联合索引)
--->PS:索引命名规则
5.3.2.创建唯一索引
5.3.3.添加主键索引
5.4.删除索引
6.索引实现原理
①二叉树阶段
②B树阶段
③B+树阶段
PS:索引和约束的区别
①定义和作用不同:
②可以相互创建和删除:
PS:聚簇索引和非聚簇索引有什么区别?
PS:联合索引有什么问题?
1.什么是索引?
索引是⼀种特殊的⽂件,包含着对数据表⾥所有记录的引用指针(相当于一个内存地址,指向一个对象)。
可以对表中的⼀列或多列创建索引,并指定索引的类型,各类索引有各⾃的数据结构实现。
注:MySQL 数据库专栏所讲的所有知识点都是基于 InnoDB 引擎的,包括接下来要讲的索引和事务。
PS:数据库引擎简介(InnoDB VS MyISAM)
MySQL 数据库有很多引擎,MySQL 和引擎的关系就像汽⻋⼚商和汽⻋⻋型的关系,⼀个⼚商 (MySQL)可以有多种⻋型(引擎)。
MySQL 最著名的引擎有两个:InnoDB 和 MyISAM,它们的区别如下:
- 版本号:MySQL 5.5 之后的默认引擎是 InnoDB;MySQL 5.5 之前的默认引擎是 MyISAM。
- 稳定性:InnDB ⽀持事务,保证数据的稳定性;MyISAM 不⽀持事务,所以有很⼤的数据不完整性⻛险(也就是数据的业务执⾏了⼀半)。MyISAM 的稳定性不如 InnoDB 好。
- 性能:MyISAM 的性能⽐ InnoDB ⾼。
然⽽对于使⽤者来说牺牲⼀些性能换取更⾼的稳定性是⾮常明智的选择。
它们更多的区别详⻅:
MyISAM与InnoDB 的区别(9个不同点)
https://blog.csdn.net/qq_35642036/article/details/82820178
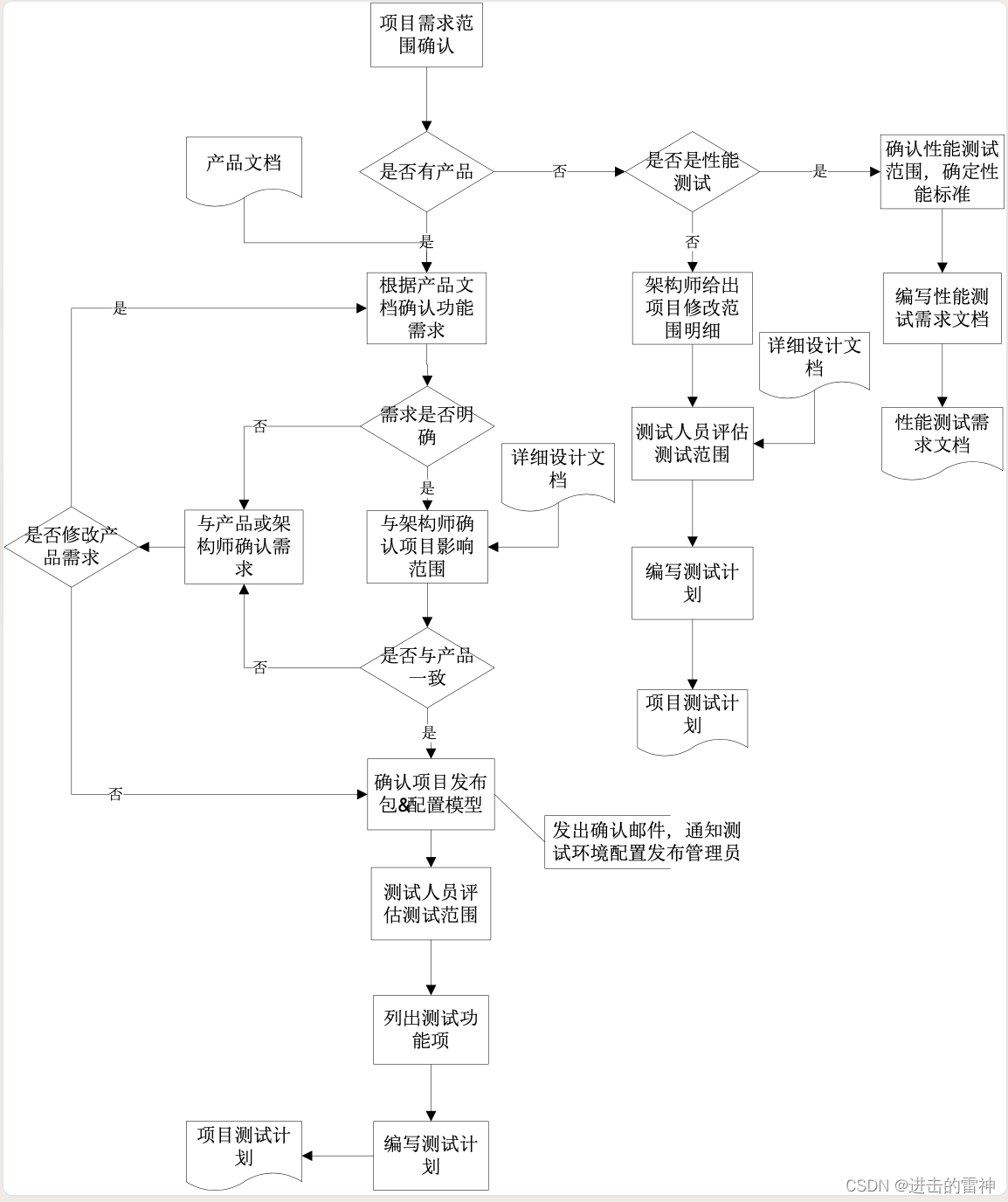
可以使用以下命令查询当前数据库的引擎:
可以针对一张表设置一个数据库引擎。(引擎的最小单位是表)
2.为什么需要索引?
- 索引可以避免顺序查询,直接将查询的范围定位出来。
- 索引可以将数据库中的关键索引信息存储到内存中,内存的操作速度远比磁盘快。
- so索引能快速找到数据,提高MySQL查询性能。所以每个表中都会有索引。(索引也不要建的太多)
数据库中数据存储在磁盘,磁盘的顺序查询速度是很慢的。顺序查询指的是读取磁盘中的数据⼀条⼀条的进⾏查找。
PS:存储数据模组
- 磁盘:容量大、价格低廉、操作速度慢、可以持久化【重启后数据还存在】(现在的磁盘已经不是机械磁盘,是SSD固态磁盘)
- 内存:容量小、价格比较贵、操作速度快、不可持久化。
- CPU缓存:【L1/L2/L3:即一级缓存(速度最快)、二级缓存(速度次之)、三级缓存(速度最慢)】容量更小、价格更贵、操作速度极快、不可持久化。
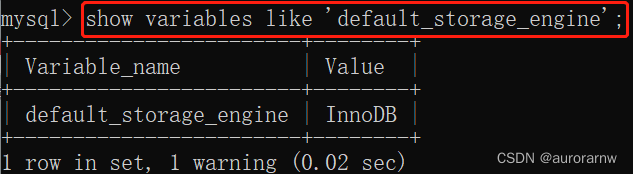
PS:查询数据存储的目录:
3.索引的作用
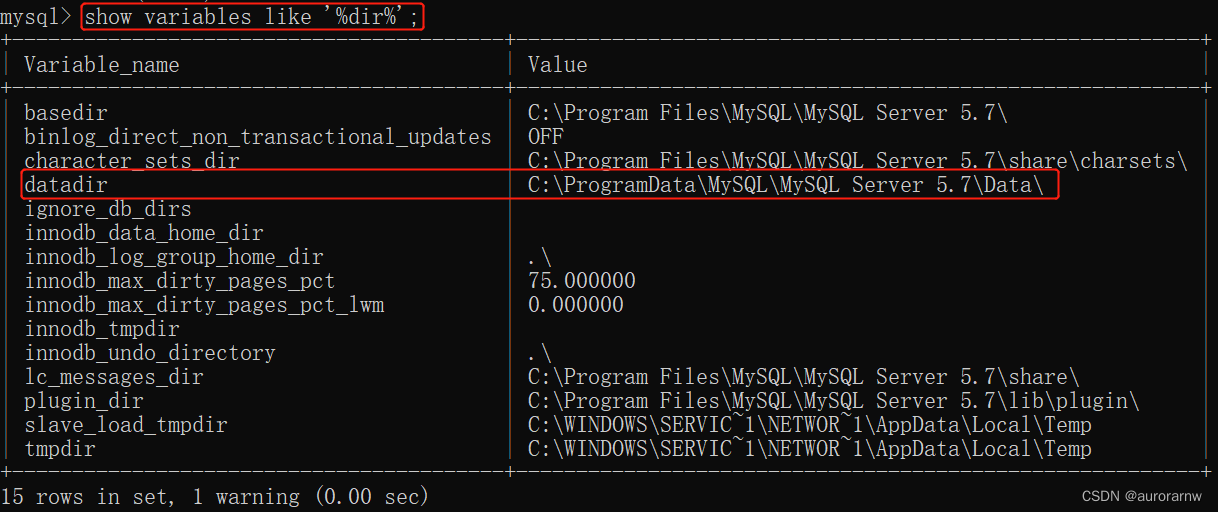
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容、书籍⽬录的关系。
- 索引所起的作⽤类似书籍⽬录,可⽤于快速定位、检索数据。
- 索引对于提⾼数据库的性能有很⼤的帮助。
PS:索引 VS 书的目录
- 从宏观的角度来看,可以认为索引就是书的目录。
- 从微观的角度来看,索引并不等于书的目录。因为一本书的目录只有一个,而一张表可以有多个索引。
4.索引的优缺点和使用场景
4.1.索引优点
- 提⾼数据库查询效率。
- 减少主从复制从库的延迟时间。
4.2.索引缺点
- 索引维护成本很⾼,因为它使⽤的是 B+ 树,每次新增、删除数据都需要整理树结构。
- 占⽤更多的存储空间(磁盘和内存):每个索引都对应⼀个 B+ 树。
- 索引过多会对 MySQL 的优化器造成⼀定的负担。(在查询时MySQL会自动帮我们选择使用哪个索引查询效率更高)
4.3.适合建索引的使用场景
对数据库表的某列或某⼏列创建索引要考虑的因素:
- 数据量是否足够大,查询速度是否比较慢。
- 创建索引的列是否是经常使用的查询条件。
满⾜以上条件可对表中的这些字段创建索引,以提⾼查询效率。
4.4.不适合建索引的使用场景
- 读比较低频,而添加、修改、删除比较高频的业务,不适合使用索引。因为添加、修改、删除需要重新整理索引,速度很慢。比如日志表。
- MySQL服务器本身安装的电脑上磁盘空间或内存空间不足的情况下,不要用索引。索引会占⽤额外的磁盘空间。
4.5.注意事项
如果对已经存在很多数据的表新增索引时,不要在线上生产环境随意创建索引,创建索引会锁表,线上数量⼤,会导致其他所有接⼝不可⽤,从⽽造成重⼤事故。(其他业务场景只能排队等待,造成雪崩。)
可以在半夜没人用时,创建索引。
5.索引使用
注:一个表中的索引名不能重复。
5.1.索引分类
索引的分类有以下⼏种:
- 主键索引(聚簇索引/聚集索引):⼀种特殊的唯⼀索引,不允许有空值,⼀般是在建表的时候同时创建主键索引(通过 primary key)
- 非主键索引(非聚簇索引/非聚集索引/二级索引):除主键索引之外的其他索引。
- 唯⼀索引:不能重复的索引。 创建索引的字段,能保证唯一性。
- 普通索引:可以重复,也可以为 NULL 的索引。
- 联合索引:使⽤一个表中的多个字段联合组成的索引。
注意:
- 创建主键约束(PRIMARY KEY)、唯⼀约束(UNIQUE)、外键约束(FOREIGN KEY)时, 会⾃动创建对应列的索引。
- 创建主键索引、唯一索引、外键索引时,会自动创建对应列的约束。
5.2.查看索引
show index from 表名;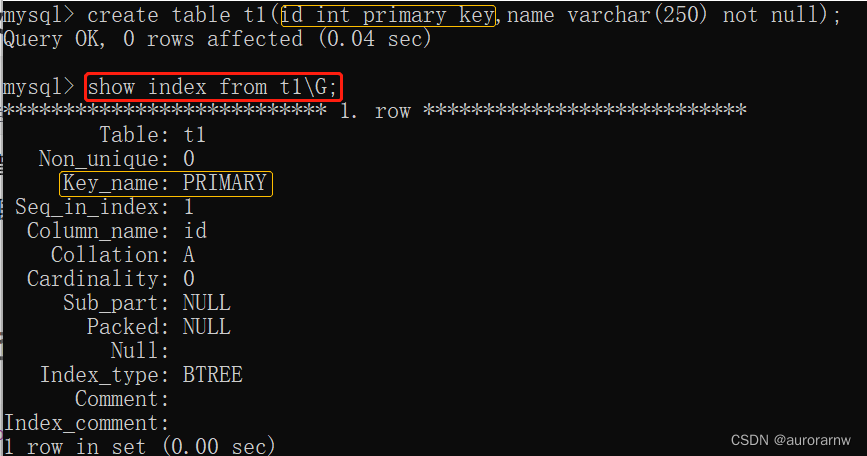

5.3.创建索引
在创建主键 primary key/unique/foreign key 时会⾃动创建索引,⽽对于⾮主键、⾮唯⼀约束、⾮外键的字段,可以⼿动创建索引。
注意:每个索引都会对应⼀个 B+ 树。
假设,我们有⼀个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。这个表的建表语句是:
create table T (id int primary key,k int not null,name varchar(16),index (k)
) engine=InnoDB;
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下:

5.3.1.创建普通索引(联合索引)
create index 索引名 on 表名(字段名 [,字段名...]);
-- 若创建联合索引,添加多个字段名即可--->PS:索引命名规则
以 idx 为前缀,后跟"_",再加字段名,若有多个字段名,之间以"_"相连。
如:idx_id_name
索引命名规则参考:
- idx_字段名
- idx_表名_字段名
- idx_类型_字段名
- idx_类型_表名_字段名
 5.3.2.创建唯一索引
5.3.2.创建唯一索引
唯一索引在创建时,要确保原先的数据符合唯一约束,才能成功创建唯一索引。
create unique index 索引名 on 表名(字段名);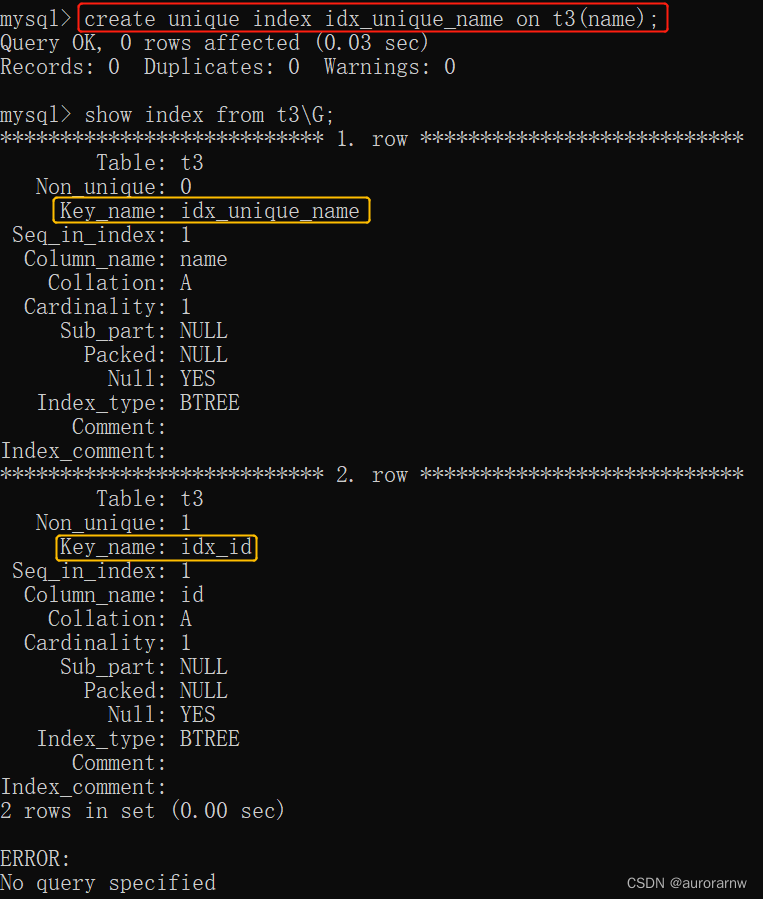
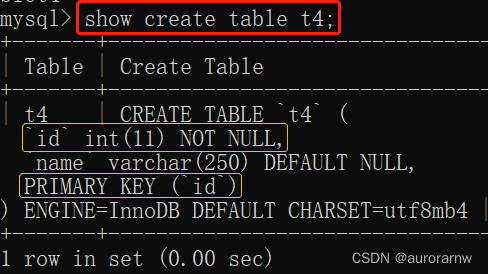
5.3.3.添加主键索引
alter table 表名 add primary key(字段名);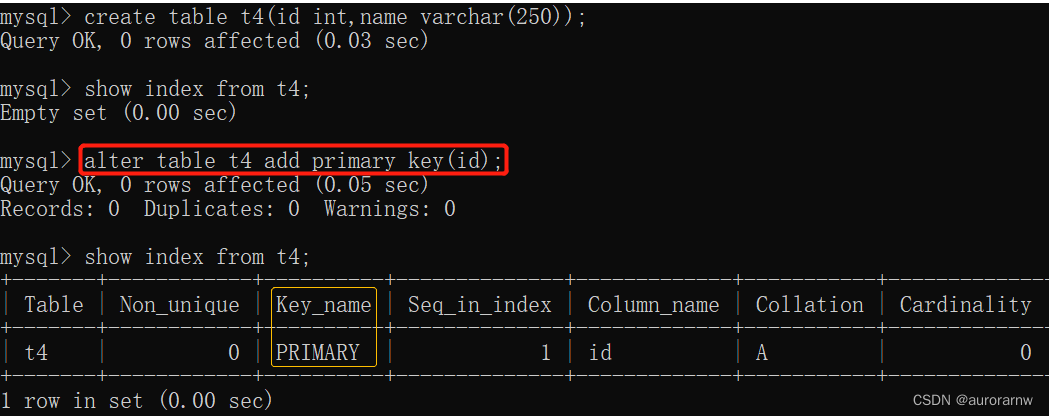
5.4.删除索引
drop index 索引名 on 表名;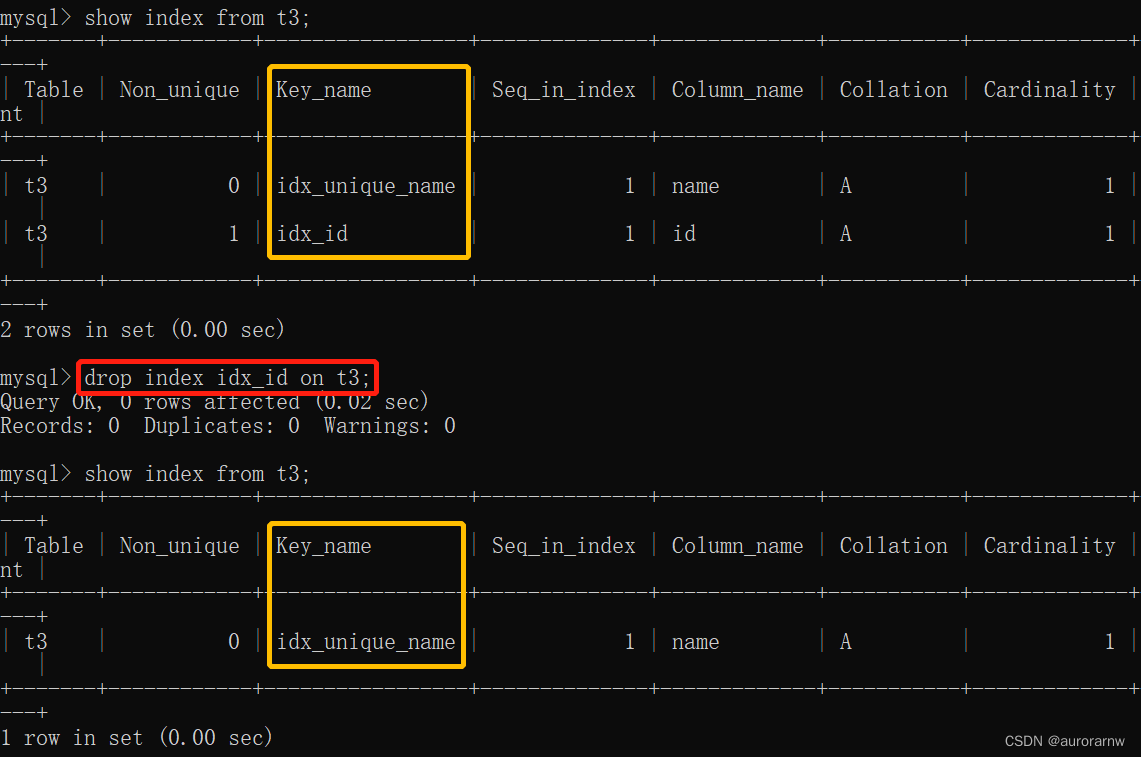
删除对应的索引,也会删除对应的约束。
6.索引实现原理
索引的实现经历了 3 个阶段的升级:
- ⼆叉树
- B 树(B-树,不是B减树!多叉树)
- B+ 树(MySQL5.7之后版本多使用)
①二叉树阶段
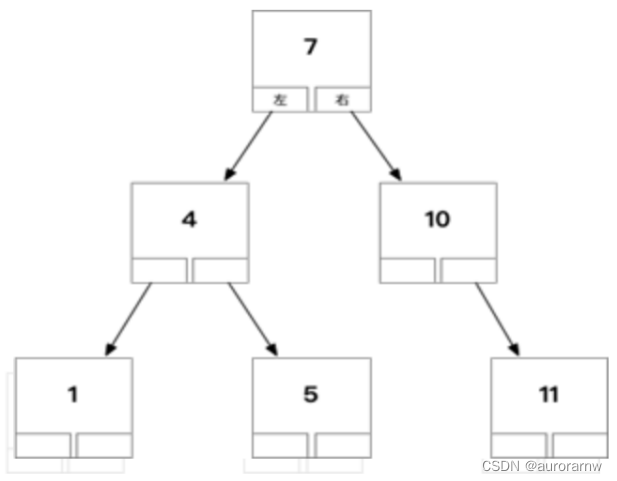
二叉树的根节点上半部分存储id,要查的数据和根节点数据比较,若比根节点小,去左子树继续查询,否则。去右子树继续查询。
找到id后,去二叉树下半部分(整行的数据)查到数据。
缺点:数据⼤之后树层级很⾼,维护和查询的性能不好。
②B树阶段
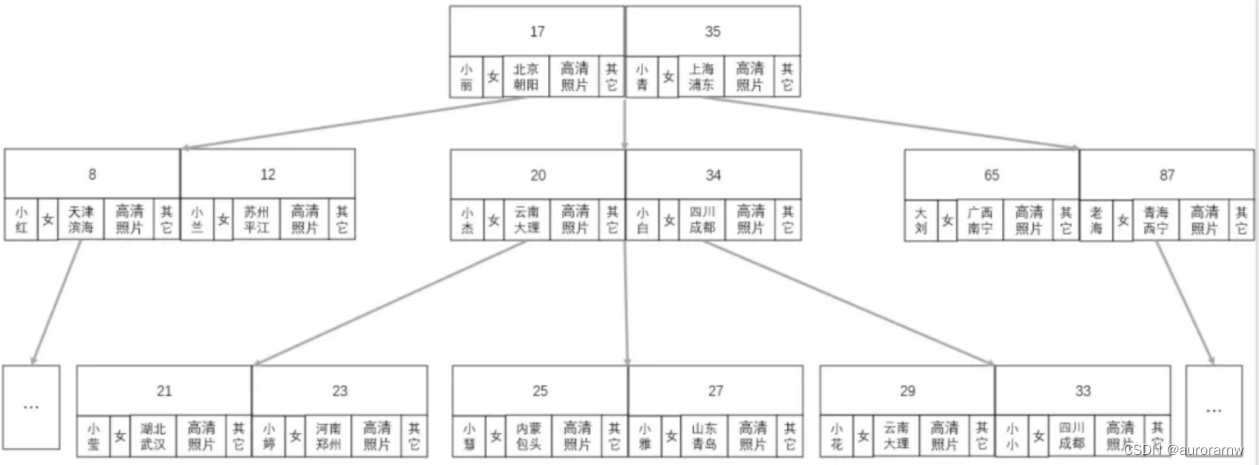
缺点:所有节点都保存了数据,加载需要很⻓的时间。
③B+树阶段
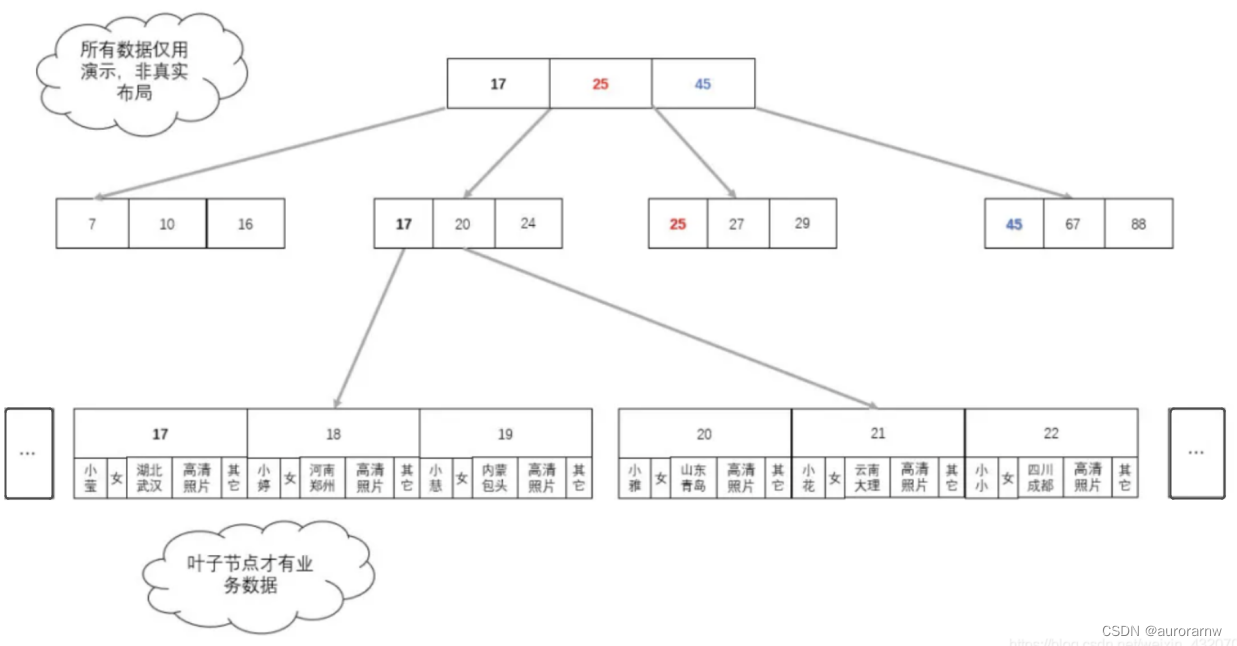
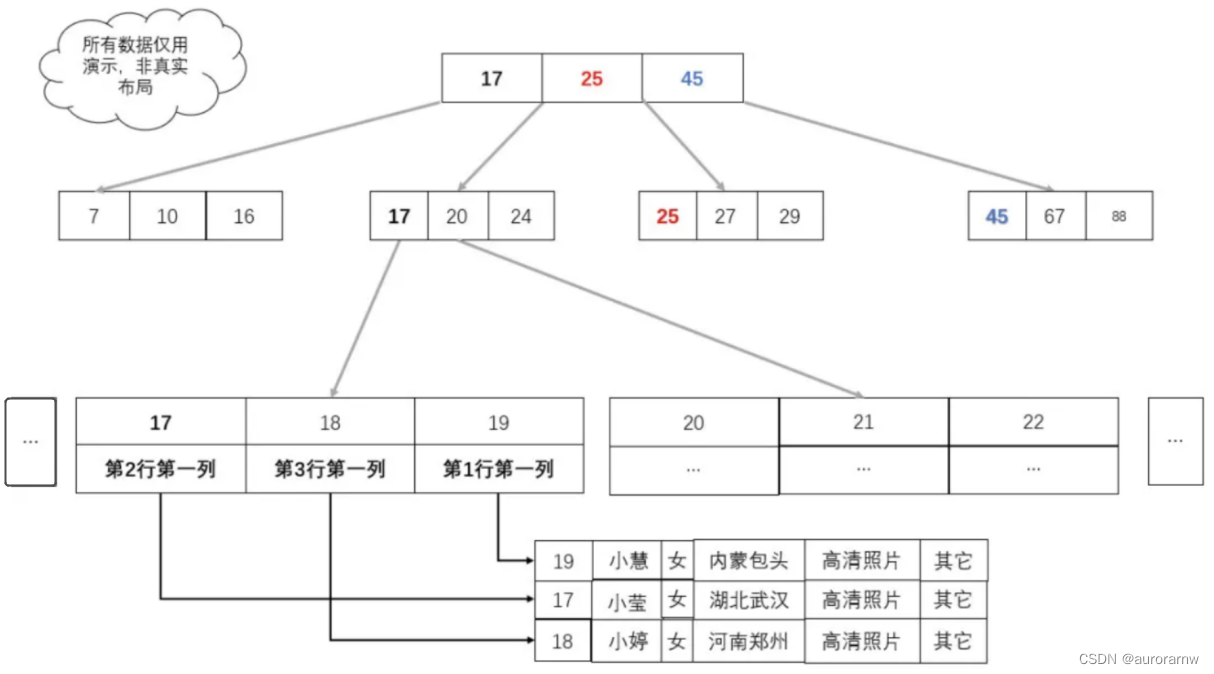
优化:非叶子节点不再存储数据,只有叶⼦节点才存储数据;且数据和索引是分离的,所谓的存储的数据,其实是指向数据的地址,数据量变的⾮常⼩。
索引实现原理-更多详情![]() https://blog.csdn.net/weixin_43207025/article/details/110389677
https://blog.csdn.net/weixin_43207025/article/details/110389677
PS:索引和约束的区别
①定义和作用不同:
- 约束是保证数据的可靠性的;
- 索引是加速查询的。
- 不是⼀回事。
②可以相互创建和删除:
- 当创建了主键、外键、唯⼀约束,也就创建了对应的索引;当创建了索引,也就创建了对应的约束。
- 当删除了索引,也会删除对应的约束。
- 部分索引和约束是共生的关系,如主键、外键、唯一。创建非空约束是不会创建非空索引的。
PS:聚簇索引和非聚簇索引有什么区别?
索引的存储数据不同,⽐如以下建表语句:
create table T (-- 创建主键(索引)id int primary key,k int not null,name varchar(16),-- 创建普通索引index (k)
) engine=InnoDB;表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下:
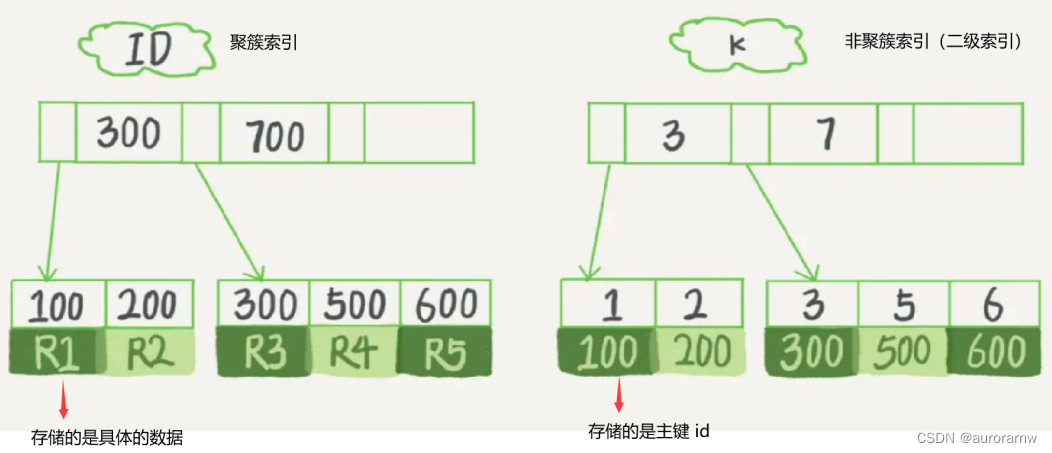
- 聚簇索引叶⼦节点存储的是表的⾏数据,所以可以直接返回结果;
- ⾮聚簇索引叶⼦节点存储的是主键 id,需要使⽤主键 id 再去聚簇索引中获取表的相关信息,所以执⾏效率没有聚簇索引⾼,⽽这个查询的过程就叫做回表查询。
聚簇索引和⾮聚簇索引的区别主要体现在两⽅⾯:
- 执⾏效率:聚簇索引查询速度更快,因为聚簇索引存储的是数据,⽽⾮聚簇索引存储的是主键 ID, 需要进⾏回表查询。
- 数量上:聚簇索引⼀个表只能有⼀个,⽽⾮聚簇索引可以有多个。
PS:联合索引有什么问题?
联合索引想要触发索引一定要遵循最左匹配原则。
最左匹配原则![]() https://www.cnblogs.com/-mrl/p/13230006.html
https://www.cnblogs.com/-mrl/p/13230006.html