实时高分辨率抠图,Real-Time High-Resolution Background Matting原论文地址
 图 1:当前的视频会议工具(如 Zoom)可以获取输入源(左)并替换背景,通常会引入伪影,如中间结果所示,头发和眼镜的特写仍然保留原始背景。 利用没有主题的视频帧(最左边的插图),我们的方法可以生成实时、高分辨率的背景抠图,而不会出现那些常见的伪影。 右边的图像是我们的结果,带有相应的特写镜头,来自我们的 Zoom 插件实现的屏幕截图。
图 1:当前的视频会议工具(如 Zoom)可以获取输入源(左)并替换背景,通常会引入伪影,如中间结果所示,头发和眼镜的特写仍然保留原始背景。 利用没有主题的视频帧(最左边的插图),我们的方法可以生成实时、高分辨率的背景抠图,而不会出现那些常见的伪影。 右边的图像是我们的结果,带有相应的特写镜头,来自我们的 Zoom 插件实现的屏幕截图。
摘要
我们介绍了一种实时、高分辨率的背景替换技术,该技术在 4K 分辨率下以 30fps 运行,在现代 GPU 上以 60fps 运行高清。 我们的技术基于背景遮罩,其中额外的背景帧被捕获并用于恢复 alpha 遮罩和前景层。 主要挑战是计算高质量的 alpha 遮罩,保留股线级别的头发细节,同时实时处理高分辨率图像。 为了实现这一目标,我们采用了两个神经网络; 一个基础网络计算一个低分辨率结果,该结果由第二个网络在选择性补丁上以高分辨率运行。 我们介绍了两个大型视频和图像抠图数据集:VideoMatte240K 和 PhotoMatte13K/85。 与之前最先进的背景抠图相比,我们的方法产生了更高质量的结果,同时显着提高了速度和分辨率。代码和数据集参见于Background Matting V2: Real-Time High-Resolution Background Matting (washington.edu)
1.介绍
背景替换是电影特效的中流砥柱,现在在 Zoom、Google Meet 和 Microsoft Teams 等视频会议工具中得到广泛使用。 除了增加娱乐价值之外,背景替换还可以增强隐私,特别是在用户可能不想在通话中与其他人分享他们的位置和环境细节的情况下。 此视频会议应用程序的一个关键挑战是用户通常无法访问绿屏,或其他用于促进电影特效中背景替换的物理道具。
虽然现在许多工具都提供了背景替换功能,但它们会在边界处产生伪影,尤其是在头发或眼镜等有精细细节的区域(图 1)。 相比之下,传统的图像抠图方法 [6, 16, 17, 30, 9, 2, 7] 提供了更高质量的结果,但不能以高分辨率实时运行,并且经常需要手动输入。 在本文中,我们介绍了第一个全自动、实时、高分辨率的抠图技术,在 4K (3840×2160、30fps) 和 HD (1920×1080、60fps) 下产生最先进的结果 。 我们的方法依赖于捕获额外的背景图像来计算 alpha 遮罩和前景层,这种方法称为背景遮罩。
设计一个可以在人的高分辨率视频上实现实时抠图的神经网络极具挑战性,尤其是当头发等细粒度的细节很重要时; 相比之下,之前最先进的方法 [28] 在 8fps 时限制为 512×512。在如此大的分辨率上训练深度网络会非常缓慢且内存密集。 它还需要大量具有高质量 alpha 遮罩的图像才能进行泛化; 公开可用的数据集 [33, 25] 太有限了
由于很难收集大量具有人工标注的 alpha matte 的高质量数据集,因此我们建议使用一系列数据集训练我们的网络,每个数据集具有不同的特征。 为此,我们介绍了 Video Matte240K 和 PhotoMatte13K/85,它们具有高分辨率的 al pha 遮罩和用色度键软件提取的前景层。 我们首先在这些更大的 alpha matte 数据库上训练我们的网络,这些数据库具有人类姿势的显着多样性,以学习强大的先验。 然后,我们在公开可用的数据集 [33、25] 上进行训练,这些数据集是手动管理的,以学习细粒度的细节。
为了设计一个可以实时处理高分辨率图像的网络,我们观察到图像中相对较少的区域需要细粒度的细化。 因此,我们引入了一个基础网络,该网络以较低的分辨率预测 alpha 遮罩和前景层,以及一个误差预测图,该图指定了可能需要高分辨率细化的区域。 然后,细化网络采用低分辨率结果和原始图像仅在选定区域生成高分辨率输出。
2.相关工作
背景替换可以通过分割或抠图来实现。 虽然二元分割快速有效,但生成的图像具有令人反感的假范围。 Alpha matting 可以产生视觉上令人愉悦的合成,但通常需要手动注释图像背景或拥有已知的背景图像。 在本节中,我们将讨论,通过分割或抠图执行背景替换的相关工作。
分割(Segmentation) 实例和语义分割方面的文献浩如烟海,超出了本文的讨论范围,因此我们将回顾最相关的作品。 Mask RCNN [11] 仍然是实例分割的首选,而 DeepLabV3+ [5] 是最先进的语义分割网络。 我们将来自 DeepLabV3 [4] 和 DeepLabV3+ 的 Atrous Spatial Pyramid Pooling (ASPP) 模块整合到我们的网络中。 由于分割算法往往会产生粗糙的边界,尤其是在更高的分辨率下,Kirillov 等人。 提出了 PointRend [15],它对边界附近的点进行采样并迭代地细化分割。 这可以为大图像分辨率产生高质量的分割,并且内存和计算成本要低得多。 我们的方法,通过学习精细区域选择和改进感受野的卷积细化架构,将这个想法应用于抠图领域。 人物分割和解析的具体应用在最近的工作中也受到了相当大的关注 [34, 19]。
基于三元图的抠图(Trimap-based matting) 传统的(非学习型的)抠图算法 [6, 16, 17, 30, 9, 2, 7] 需要人工标注(一个三元图)并解决三元图“未知区域”中的 alpha 遮罩。 Wang 和 Cohen [32] 在调查中回顾了不同的抠图技术。 Xu等人[33] 引入了一个抠图数据集,并使用带有 trimap 输入的深度网络来预测 alpha 抠图。 许多最近的方法依赖于这个数据集来学习抠图,例如,上下文感知抠图 [13]、索引抠图 [21]、基于采样的抠图 [31] 和基于不透明度传播的抠图 [18]。 尽管这些方法的性能取决于标注的质量,但最近的一些方法考虑粗略的 [20] 或存在错误的人工标注[3]的情况下 来预测 alpha 遮罩。
无外部输入的抠图(Matting without any external input) 最近的方法还侧重于在没有任何外部输入的情况下对人类进行抠图。 没有 trimap [36, 29] 的人像抠图是更成功的应用之一,因为与全身人体相比,人像图像的可变性更小。[1] 中也探索了自然图像的软分割。 最近的方法,如 Late Fusion Matting [35] 和 HAttMatting [25] 旨在直接从图像中求解 alpha 遮罩,但这些方法通常无法泛化,如 [28] 所示。
已知自然背景的抠图(Matting with a known natural background) 具有已知自然背景的抠图先前已在 [24]、贝叶斯抠图 [7] 和泊松抠图 [30, 10] 中进行了探索,这也需要三元图。 最近 Sengupta 等人[28] 引入了背景遮罩( Background Matting: BGM),其中捕获了额外的背景图像,它为预测 alpha 遮罩和前景层提供了重要线索。 虽然这种方法显示了高质量的抠图结果,但该架构仅限于 512×512 分辨率,并且只能以 8fps 运行。 相比之下,我们引入了实时统一抠图架构(real-time unified matting architecture),以 30fps 处理 4K 视频和以 60fps 处理高清视频,并产生比 BGM 更高质量的结果。
3.数据集
由于很难获得由人类手工标注 alpha 遮罩的大规模、高分辨率、高质量的抠图数据集,因此我们依赖于多个数据集,包括我们自己的收藏和公开可用的数据集。
公开可用的数据集 Adobe Image Matting (AIM) 数据集[33] 提供 269 个人类训练样本和 11 个测试样本,平均分辨率约为 1000×1000。 我们还使用了 Distinctions 646 [25] 的仅人类子集,由 362 个训练样本和 11 个测试样本组成,平均分辨率约为 1700×2000。 遮罩是手动标注的,因此质量很高。 然而,631 张训练图像不足以在高分辨率下学习人体姿势的巨大变化和更精细的细节,因此我们引入了 2 个额外的数据集。

VideoMatte240K 我们收集了484个高分辨率的绿幕视频,并通过Adobe After Effects生成了总共240,709帧单独的alpha 遮罩和前景。这些视频都是作为素材购买或在网上找到的免版税素材。384个视频为4K分辨率,100个为HD分辨率。我们将视频按479 : 5分割,形成训练集和验证集。数据集由大量的人类主体、服装和姿势组成,对训练鲁棒模型很有帮助。我们将把提取的 alpha mattes和前景作为数据集对外公布。据我们所知,到目前为止,我们的数据集比所有现有的公开的抠图数据集都要大,它是第一个公开的视频抠图数据集,其中包含了连续的帧序列而不是静止的图像,这可以在未来的研究中用来开发包含运动信息的模型。
PhotoMatte13K/85 我们获得了13665张用摄影棚质量的灯光和摄像机在绿屏前拍摄的图像集合,以及通过色度抠像(chromakey)算法提取的抠图,并进行手动调整与错误修复。我们将图像按13165 : 500分割,形成训练和验证集。这些抠图包含的姿势范围很窄,但分辨率很高,平均约为2000×2500,并包含诸如单簇发丝的细节。我们将这个数据集称为PhotoMatte13K。然而,隐私和许可问题使我们无法分享这套数据集;因此,我们还收集了另外一套85张质量类似的抠图作为测试集,我们将其作为PhotoMatte85进行公布。在图2中,我们展示了VideoMatte240K和PhotoMatte13K/85数据集的例子。
我们从 Flickr 和 Google 中抓取 8861 张高分辨率背景图片,并按 8636 : 200 : 25 分割,用于构建训练集、验证集和测试集。我们将公布测试集,其中所有图片都有CC授权(详见附录)。
4.方法
给定一个图像 I I I和捕捉到的背景 B B B ,我们预测alpha遮罩α和前景F,这将使我们可以通过 I ′ = α F + ( 1 − α ) B ′ I^′ = αF+(1−α)B' I′=αF+(1−α)B′ 在任何新的背景上合成,其中 B ′ B' B′是新的背景。我们不直接求解前景,而是求解前景残差 F R = F − I F^{R} = F-I FR=F−I,然后,可以通过将 F R F^{R} FR加入到输入图像 I I I中,并进行适当的收缩: F = m a x ( m i n ( F R + I , 1 ) , 0 ) F = max ( min ( F^R + I , 1 ) , 0 ) F=max(min(FR+I,1),0), 来恢复 F F F。 我们发现这个公式提高了学习效果,并允许我们通过上采样将低分辨率的前景残差应用到高分辨率的输入图像上,改善我们的架构,如后所述。
高分辨率下的抠图充满挑战,因为应用深度网络直接导致不切实际的计算和内存消耗。如 图4 所示,人像的抠图通常是非常稀疏的,其中大面积的像素属于背景(α = 0)或前景(α = 1),只有少数区域涉及更精细的细节,例如,头发、眼镜和人的轮廓周围。因此,我们没有只设计一个对高分辨率图像进行操作的网络,而是引入了两个网络,一个在较低分辨率下操作,另一个在原始分辨率下根据前一个网络的预测对选定的区域进行操作。
该架构由一个基础网络 G b a s e G_{base} Gbase和一个细化网络 G r e f i n e G_{refine} Grefine组成。给定原始图像 I I I和捕获的背景 B B B,我们首先对 I c I_c Ic和 B c B_c Bc进行系数为c的下采样。基础网络 G b a s e G_{base} Gbase将 I c I_c Ic和 B c B_c Bc作为输入,并预测粗粒度的alpha遮罩 α c α_c αc、前景残差 F c R F_c^R FcR、误差预测图 E c E_c Ec和隐藏特征 H c H_c Hc 。然后,细化网络 G r e f i n e G_{refine} Grefine利用 H c H_c Hc、 I I I和 B B B,只在预测误差 E c E_c Ec较大的区域,对 α c α _c αc 和 F c R F_c^R FcR进行细化,并在原始分辨率下产生α和前景残差 F R F^R FR。我们的模型是完全卷积的,并且经过训练可以在任意尺寸和长宽比上工作。


4.1.基础网络
基础网络(base network)是一个受DeepLabV3[4]和DeepLabV3+[5]架构启发的全卷积编码器-解码器(encoder-decoder)网络,它们在2017年和2018年的语义分割任务上取得了SOTA。我们的基础网络由三个模块组成:Backbone、ASPP和Decoder。
我们采用ResNet-50[12]作为编码器主干,这可以用ResNet-101和MobileNetV2[27]替代,以在速度和质量之间进行权衡。我们按照DeepLabV3的方法,在主干后采用ASPP(Atrous Spatial Pyramid Pooling)模块。ASPP模块由多个膨胀卷积滤波器组成,分别使用3,6,9作为膨胀率。我们的解码器网络在每一步都应用了双线性上采样,与来自主干的跳连接并联,然后是3×3卷积、Batch Normalization[14]和ReLU激活[22] (最后一层除外)。解码器网络输出粗粒度的alpha matte α c α_c αc、前景残差 F c R F_c^R FcR、误差预测图 E c E_c Ec和一个32通道的隐藏特征 H c H_c Hc。隐藏特征 H c H_c Hc 包含了对细化网络有用的全局上下文。
4.2细化网络
细化网络(refinement network)的目标是减少冗余计算,恢复高分辨率的抠图细节。基础网络对整个图像进行操作,而细化网络只对误差预测图 E c E_c Ec选择的块进行操作。我们执行两阶段的细化,首先是原始分辨率的 1 2 \frac{1}{2} 21,然后再全分辨率。在推理过程中,我们对k个块进行细化,k可以事先设定,也可以根据阈值设定,在质量和计算时间之间进行权衡。
给定原始分辨率 1 c \frac{1}{c} c1的粗误差预测图 E c E_c Ec,我们首先将其重新采样到原始分辨率 E 4 E_4 E4的 1 4 \frac{1}{4} 41,即图上的每个像素对应原始分辨率上的一个4×4的块。我们从 E 4 E_4 E4中选取预测误差最大的k个像素来表示k个4×4块的位置,这些位置将被我们的细化模块细化。原始分辨率下的细化像素总数为16k。
我们执行一个两阶段的细化过程。首先,我们对粗输出,即alpha matte α c α_c αc、前景残差 F c R F_c^R FcR和隐藏特征 H c H_c Hc,以及输入图像I和背景B进行双线性重采样,使其达到原始分辨率的 1 2 \frac{1}{2} 21,并将其连成特征。然后我们在从 E 4 E_4 E4 中选取的误差位置周围裁剪出8×8的块,并分别通过两层3×3卷积(带valid padding)、Batch Normalization和ReLU,将块的维度降低到4×4。然后将这些中间特征再次上采样到8×8,并与从原始分辨率、输入I和相应位置的背景B中提取的8×8块进行连通。然后,我们应用额外的两层3×3卷积(带valid padding),Batch Normalization和ReLU(除了最后一层),以获得4×4的alpha matte和前景残差结果。最后,我们将粗alpha matte α c α_c αc和前景残差 F c R F_c^R FcR上采样到原始分辨率,并换入各自已经细化的4×4块,得到最终的alpha matteα和前景残差 F R F^R FR,整个架构如图3所示。具体实现方式见附录。
4.3.训练
所有的抠图数据集都提供了一个alpha 遮罩和一个前景层,我们将其合成到多个高分辨率背景上。我们采用了多种数据增强技术,以避免过拟合,并帮助模型泛化到具有挑战性的现实世界中。我们对前景层和背景层分别进行了非线性变换、水平翻转、亮度、色调和饱和度调整、模糊、锐化和随机噪声等数据增强。我们还略微移动背景以模拟错位,并创建人工阴影,以模拟主体如何在现实环境中投射阴影(详见附录)。我们随机裁剪每个minibatch中的图像,使高度和宽度分别均匀分布在1024和2048之间,以支持在任何分辨率和纵横比下进行推理。
为了学习α与ground-truth α ∗ α^∗ α∗,我们在整个alpha matte与其(Sobel)梯度上使用L1损失:
L α = ∥ α − α ∗ ∥ 1 + ∥ ∇ α − ∇ α ∗ ∥ 1 ( 1 ) L α=∥α−α^∗∥_1+∥∇α−∇α^∗∥_1 \quad (1) Lα=∥α−α∗∥1+∥∇α−∇α∗∥1(1)
我们从预测的前景残差 F R F^R FR中获得前景层,使用 F = m a x ( m i n ( F R + I , 1 ) , 0 ) F = max ( min ( F^R + I , 1 ) , 0 ) F=max(min(FR+I,1),0)。我们只对 α ∗ > 0 {\alpha ^ * >0} α∗>0的像素计算L1损失:
L F = ∥ ( α ∗ > 0 ) ∗ ( F − F ∗ ) ) ∥ 1 ( 2 ) \left.\mathcal{L}_{F}=\|\left(\alpha^{*}>0\right) *\left(F-F^{*}\right)\right) \|_{1} \quad (2) LF=∥(α∗>0)∗(F−F∗))∥1(2)
其中, α ∗ > 0 {\alpha ^ * >0} α∗>0是布尔表达式。对于细化区域的选择,我们将ground truth误差图定义为 E ∗ = ∣ α − α ∗ ∣ E^{*}=\left|\alpha-\alpha^{*}\right| E∗=∣α−α∗∣。然后我们计算预测误差图和ground truth误差图之间的均方误差作为损失:
L E = ∥ E − E ∗ ∥ 2 ( 3 ) \mathcal{L}_{E}=\left\|E-E^{*}\right\|_{2} \quad (3) LE=∥E−E∗∥2(3)
这种损失鼓励预测误差图拥有更大的值,在预测α和ground truth α之间的差异很大。在训练过程中,随着预测α的提高,ground truth误差图会也随着迭代而变化。随着时间的推移,误差图逐渐收敛,并预测复杂区域的高误差,例如头发。如果简单地进行上采样,会导致糟糕的合成。
基础网络 ( α c , F c R , E c , H c ) = G base ( I c , B c ) \left(\alpha_{c}, F_{c}^{R}, E_{c}, H_{c}\right)=G_{\text {base }}\left(I_{c}, B_{c}\right) (αc,FcR,Ec,Hc)=Gbase (Ic,Bc)在原始图像分辨率的 1 c \frac{1}{c} c1处工作,并用以下损失函数进行训练:
L base = L α c + L F c + L E c ( 4 ) \mathcal{L}_{\text{base}}=\mathcal{L}_{\alpha_{c}}+\mathcal{L}_{F_{c}}+\mathcal{L}_{E_{c}} \quad (4) Lbase=Lαc+LFc+LEc(4)
细化网络 ( α , F R ) = G refine ( α c , F c R , E c , H c , I , B ) (\alpha ,{F^R}) = {G_{{\text{refine }}}}\left( {{\alpha _c},F_c^R,{E_c},{H_c},I,B} \right) (α,FR)=Grefine (αc,FcR,Ec,Hc,I,B)的训练方法是:
L refine = L α + L F ( 5 ) \mathcal{L}_{\text {refine }}=\mathcal{L}_{\alpha}+\mathcal{L}_{F} \quad (5) Lrefine =Lα+LF(5)
我们在ImageNet和Pascal VOC数据集上初始化我们模型的主干和ASPP模块,并使用DeepLabV3权重进行语义分割的预训练。我们首先训练基础网络,直到收敛,然后添加细化模块并联合训练。在训练过程全程,我们使用Adam优化器,并c=4,k=5000。在只训练基础网络时,我们对主干、ASPP和解码器设置batch size为8,学习率分别为[1e-4,5e-4,5e-4]。当联合训练时,主干、ASPP、解码器和细化模块分别设置batch size为4,学习率为[5e-5、5e-5、1e-4、3e-4]。
我们按照以下顺序在多个数据集上训练我们的模型。首先,我们只在VideoMatte240K上训练基础网络 G b a s e G_{base} Gbase,然后在VideoMatte240K上联合训练整个模型 G b a s e G_{base} Gbase 和 G r e f i n e G_{refine} Grefine ,这使得模型对各种主体和姿势都很鲁棒。接下来,我们在PhotoMatte13K上联合训练我们的模型,以增加高分辨率的细节。最后,我们在Distinctions-646上联合训练我们的模型。该数据集只有362个独一无二的训练样本,但它的质量是最高的,并且包含了人工标注的前景,这对提高我们模型产生的前景质量非常有帮助。我们省略了在AIM数据集上的训练,作为可能的第四阶段,其最终只用于测试;因为使用它会导致质量下降,正如我们在第6节的消融研究中所显示的那样。
5.实验评估
我们将我们的方法与两种基于三元图的方法:深度图像抠图(Deep Image Matting,DIM)[33]和FBA抠图(FBA)[8],以及一种基于背景的方法:背景抠图(Background Matting,BGM)[28]进行比较。DIM的输入分辨率被固定为320×320,而FBA的输入分辨率由于内存限制,我们将其设置为HD左右。我们另外在数据集上训练BGM模型,并将其表示为BGMa(BGM改)。
我们的评估,对照片采用c=4,k=20000,对HD视频采用c=4,k=5000,对4K视频采用c=8,k=20000,其中c是基础网络的下采样因子,k是得到细化的块数量。
5.1.在合成数据集上的评估
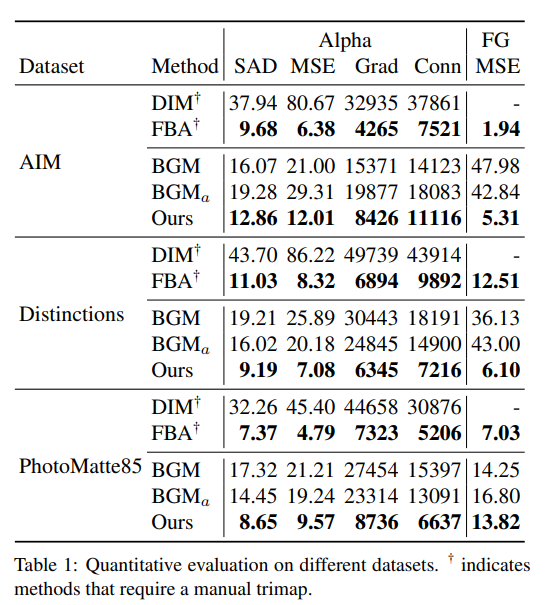
我们通过将AIM、Distinctions和PhotoMatte85数据集的测试样本分别合成到每个样本的5张背景图像上,构建测试基准。我们应用轻微的背景错位、颜色调整和噪声来模拟有缺陷的背景捕捉。我们使用阈值和形态学操作从ground truth α生成三元图。我们使用[26]中的指标来评估抠图输出:α和前景的MSE(均方误差),SAD(绝对差之和),Grad(空间梯度度量),以及仅α的Conn(连通性)。所有的MSE值都是以 1 0 3 10^3 103为尺度,所有的指标都只在未知区域的trimap上计算,如上所述。前景MSE仅在ground truth α ∗ > 0 {\alpha ^ * >0} α∗>0的地方额外度量。
表1显示,在所有数据集中,我们的方法都优于现有的基于背景的BGM方法。我们的方法比SOTA基于trimap的FBA方法稍差,但后者需要仔细标注手工trimap,比我们的方法慢得多,在后面的性能比较中可以看出。

5.2.在录制视频上的评估
虽然在上述数据集上的定量评估达到了量化不同算法性能的目的,但评估这些方法在无约束的真实数据上的表现是很重要的。为了在真实数据上进行评估,我们采集了一些包含不同姿势和周围环境的主体的照片和视频。这些视频是在三脚架上用消费级智能手机(三星S10+和iPhone X)与专业相机(索尼α7s II)拍摄的,分辨率为HD和4K。照片的拍摄分辨率为4000×6000。我们还使用了一些在BGM论文中公开的HD视频,来与我们的方法进行比较。
为了在实时场景下进行公平的比较,在无法制作手工trimap的情况下,我们按照[28]的建议,通过DeepLabV3+的变形分割结果来构建trimap。我们展示了两种trimap的结果,将使用这种全自动trimap的FBA记做为FBAauto。
图5显示,与其他方法相比,我们的方法在头发和边缘周围产生了更清晰、更细致的结果。由于我们的细化是在原生分辨率下操作的,所以质量相对于BGM要好得多,因为BGM调整了图像的大小,只能在512×512的分辨率下进行处理。FBA与人工trimap一起,在头发细节周围产生了出色的结果,然而无法在标准GPU上评估高于HD左右的分辨率。当FBA应用在用分割生成的自动trimap上时,经常会出现较大的伪像,主要是由于分割有问题。
我们从BGM论文分享的测试视频和我们采集的视频和照片中提取34帧来创建一个用户研究。40名参与者被呈现在一个互动界面上,以随机顺序显示每个输入图像以及由BGM和我们的方法产生的抠图。他们被鼓励放大细节,并要求评价其中一个抠图为 “好得多”,“稍好”,或 “类似”。结果,如表2所示,展示出相比BGM显著的质的改进。59%的情况下参与者认为我们的算法更好,而BGM只有23%。对于4K和更大的锐利样本,我们的方法在75%的情况下比BGM的15%更受欢迎。

5.3.性能比较
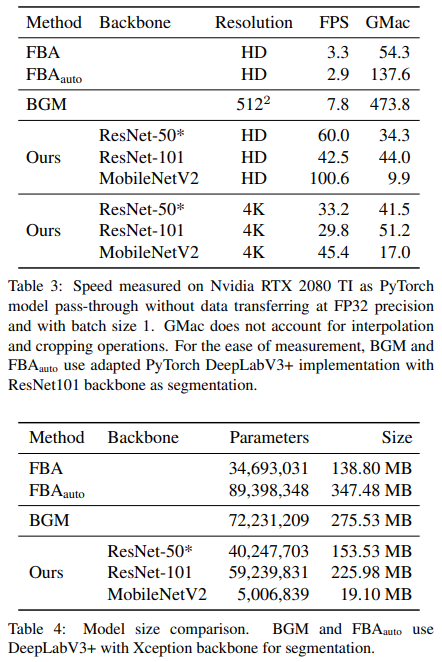
表3和表4显示,我们的方法比BGM更小、更快。与BGM相比,我们的方法只包含55.7%的参数。我们的方法可以在Nvidia RTX 2080 TI GPU上实现HD 60fps和4K 30fps(batch size为1),这对许多应用被认为是实时的。与只能以7.8fps处理512×512分辨率的BGM相比,这是一个显著的加速。如果换成MobileNetV2作为主干,性能可以进一步提升,达到4K 45fps和HD 100fps。更多的性能结果,如调整细化选择参数k和使用更大的batch size,都包含在消融研究和附录中。
5.4.实际应用
Zoom实现: 我们构建了一个Zoom插件,它可以拦截网络摄像头的输入,收集一个无人(背景)镜头,然后进行实时视频抠图和合成,将结果流回Zoom调用中。我们在Linux中使用720p网络摄像头进行测试。该升级在实际会议中引起了好评,证明了其在实际环境中的实用性。
与绿幕的比较: 使用绿幕进行色度抠像是创造高质量抠图的最常用方法。然而,它要求整个屏幕的光照均匀,背景和主体分离,以避免投射阴影。在图6中,我们将我们的方法与在相同照明下使用业余绿幕设置的色度抠像进行比较。我们发现,在光线不均匀的环境下,我们的方法优于为绿幕设计的方法。
6.消融研究
数据集的作用: 我们在多个数据集上进行训练,每个数据集都带来了独特的特征,帮助我们的网络在高分辨率下产生高质量的结果。表5显示了我们的方法在从训练流水线中添加或删除一个数据集下的指标。我们发现添加AIM数据集作为可能的第4阶段会造成指标恶化,即使在使用AIM本身进行测试的情况下也会恶化。我们认为这是因为AIM数据集中的样本与Distinctions相比,分辨率和质量都较低,样本数量少可能造成了过拟合。从训练流水线中移除VideoMatte240K、PhotoMatte13K和Distinctions数据集都会导致更差的指标,证明这些数据集对提高模型的质量有帮助。
基础网络的作用: 我们实验用ResNet-101和MobileNetV2代替ResNet-50作为基础网络中的编码器主干。表6中的指标显示,ResNet-101在某些指标上比ResNet-50有轻微的改进,而在其他指标上表现较差。这说明ResNet-50通常足以获得最佳质量。而MobileNetV2在所有指标上都比ResNet-50差,但如表3和表4所示,它比ResNet-50快得多,体积也小得多,而且仍能获得比BGM更好的指标。
细化网络的作用: 我们的细化网络图7中的粗结果中提高了细节清晰度,即使在4K分辨率下也是有效的。图8显示了增加和减少细化区域的效果。只在图像分辨率的5%到10%的范围内进行细化,就可以实现大部分的改善。表7显示,与细化整个图像相比,只细化选定的块可以提供显著的加速。
基于块的细化与基于点的细化: 我们的细化模块使用3×3的卷积核栈,为每个输出像素创建一个13×13的接受野。另一种方法是只使用1×1的卷积核对点进行细化,这将导致我们的方法产生2×2的接受野。表6显示,3×3的核由于接受野较大,可以达到比基于点的核更好的指标。
局限性: 我们的方法可以通过在每一帧的背景上应用同构对齐来用于手持输入,但它被限制在小运动上。其他常见的限制如图 9 所示。我们建议使用我们的方法时使用一个简单的纹理背景,固定的曝光/焦距/白平衡设置和三脚架,以获得最佳效果。
7.结论
我们提出了一种实时、高分辨率的背景替换技术,它可以在4K 30fps和HD 60fps下运行。我们的方法只需要一个输入图像和一个预先捕获的背景图像,这在许多应用中很容易获得。我们提出的架构在高分辨率下只有效地细化容易出错的区域,从而减少了冗余计算,使实时高分辨率抠图成为可能。我们引入了两个新的大规模抠图数据集,帮助我们的方法推广到现实生活中的场景。我们的实验表明,我们的方法在背景抠图上创造了新的SOTA。我们通过将我们的结果以流式传输到Zoom来证明我们方法的实用性,并实现了更真实的虚拟电话会议。
道德声明: 我们的首要目标是通过视频通话中的背景替换,实现创造性的应用,给用户提供更多的隐私选择。然而,我们意识到图像编辑也可能被用于负面目的,这可以通过水印和其他商业应用中的安全技术得到缓解。
附录
A.综述
我们在本附录中提供了更多细节。在Sec.B中,我们描述了我们的网络架构和实现细节。在Sec.C中,我们阐明了我们使用哪些关键字来抓取背景图像。在Sec.D中,我们解释了我们如何训练我们的模型,并展示了我们数据增强的细节。在Sec.E中,我们展示了关于我们方法性能的额外指标。在Sec.F中,我们展示了我们用户研究中使用的所有定性结果,以及每个样本的平均得分。
B.网络
B.1.结构
主干: ResNet和MobileNetV2都采用了原始的实现方式,但做了一些小的修改。我们改变了第一个卷积层,使输入和背景图像都接受6个通道。我们遵循DeepLabV3的方法,将最后一个下采样块用膨胀卷积来维持16的输出步长。为了简单起见,我们不使用DeepLabV3中提出的多网格膨胀技术。
ASPP: 我们遵从DeepLabV3中提出的ASPP模块的原始实现。我们的实验表明,将膨胀率设置为(3,6,9)会产生更好的结果。
解码器:
C B R 128 − C B R 64 − C B R 48 − C 37 CBR128 - CBR64 - CBR48 - C37 CBR128−CBR64−CBR48−C37
"CBRk"表示k kk个3×3卷积滤波器,具有相同的填充,无偏置,然后进行Batch Normalization和ReLU。"Ck "表示k个具有相同填充和偏置的3×3卷积滤波器。在每一次卷积之前,解码器使用规模因子为2的双线性上采样,并与主干网进行相应跳连接。37个通道的输出包括1个通道的 α c \alpha _c αc、3个通道的前景残差 F c R F_c^R FcR、1个通道的误差图 E c E_c Ec和32个通道的隐藏特征 H c H_c Hc。我们将 α c \alpha _c αc和 E c E_c Ec收缩到0至1,对 H c H_c Hc应用ReLU。
细化器:
F i r s t s t a g e : C ∗ B R 24 − C ∗ B R 16 Firststage: C∗BR24 − C∗BR16 Firststage:C∗BR24−C∗BR16
S e c o n d s t a g e : C ∗ B R 12 − C ∗ 4 {\text{ }}{Secondstage}:{\text{ }}C*BR12{\text{ }} - {\text{ }}C*4 Secondstage: C∗BR12 − C∗4
“ C∗BRk “ 和 " C∗k "遵循上述相同的定义,只是卷积不使用填充。
细化器首先将粗输出 α c \alpha _c αc 、 F c R F_c^R FcR、 H c H_c Hc和输入图像I、B重新采样为 1 2 \frac{1}{2} 21分辨率,并将它们连成 [ n × 42 × h 2 × w 2 ] \left[n \times 42 \times \frac{h}{2} \times \frac{w}{2}\right] [n×42×2h×2w]特征。根据误差预测Ec,我们裁剪出前k个最容易出错的块 [ n k × 42 × 8 × 8 ] [n k \times 42 \times 8 \times 8] [nk×42×8×8]。应用第一阶段后,块维度变成 [ n k × 16 × 4 × 4 ] [n k \times 16 \times 4 \times 4] [nk×16×4×4]。我们用最近邻上采样法对块进行上采样,并与I和 B中相应位置的块进行连接,形成 [ n k × 22 × 8 × 8 ] [n k \times 22 \times 8 \times 8] [nk×22×8×8]特征。经过第二阶段,块维度变成 [ n k × 4 × 4 × 4 ] [n k \times 4 \times 4 \times 4] [nk×4×4×4]个通道分别是α和前景残差。最后,我们对粗 α c \alpha _c αc和 F c R F_c^R FcR进行双线性上采样,使其达到全分辨率,并将细化后的块替换到相应位置,形成最终的输出α和 F R F^R FR。
B.2.实现
我们在PyTorch[23]中实现了我们的网络。块的提取和替换可以通过原生的向量化操作来实现,以获得最大的性能。我们发现,PyTorch的最近邻上采样操作在小分辨率块上比双线性上采样快得多,所以我们在上采样块时使用它。
C.数据集
VideoMatte240K 该数据集包含484个视频片段,共240709帧。每段视频的平均帧数为497.3,中位数为458.5。最长的片段有1500帧,最短的片段有124帧。图10显示了VideoMatte240K数据集的更多例子。
背景: 我们用来爬取背景图片的关键词是:机场内部、阁楼、酒吧内部、浴室、海滩、城市、教堂内部、教室内部、空城、森林、车库内部、健身房内部、房子户外、内部、厨房、实验室内部、景观、演讲厅、商场内部、夜总会内部、办公室、雨林、屋顶、体育场内部、剧院内部、火车站、仓库内部、工作场所内部。
D.训练
表8记录了我们最终模型在不同数据集上的训练顺序、epoch和小时数。我们在只训练基础网络时使用1张RTX 2080 TI,在联合训练网络时使用2张RTX 2080 TI。

此外,我们还使用混合精度训练,以实现更快的计算速度和更少的内存消耗。当使用多个 GPU 时,我们会应用数据并行技术将 minibatch 分割到多个 GPU 上,并切换到使用 PyTorch 的同步Batch Normalization来跟踪跨 GPU 的batch统计数据。
D.1.数据增强
对于每一个alpha和前景训练样本,我们以"zip"的方式旋转与背景进行合成,形成一个epoch。例如,如果有60个训练样本和100张背景图像,那么一个epoch就是100张图像,其中60个样本首先与前60张背景图像配对,然后前40个样本再与其余40张背景图像配对。当一组图像用完后,旋转就停止了。由于我们使用的数据集大小差别很大,所以用这种策略来概括一个epoch的概念。
我们对每个样本的前景和背景分别应用随机旋转(±5deg)、缩放(0.3∼1)、平移(±10%)、剪切(±5deg)、亮度(0.85∼1.15)、对比度(0.85∼1.15)、饱和度(0.85∼1.15)、色调(±0.05)、高斯噪声(σ2≤0.03)、盒状模糊和锐化。然后我们使用 I = α F + ( 1 − α ) I=\alpha F+(1-\alpha) I=αF+(1−α)对输入图像进行合成。
我们另外应用随机旋转(±1deg)、平移(±1%)、亮度(0.82~1.18)、对比度(0.82~1.18)、饱和度(0.82~1.18)和色调(±0.1),只在背景上应用30%次。这种输入 I I I和背景 B B B之间的小错位增加了模型在现实生活捕捉上的鲁棒性。
我们还发现创建人工阴影可以提高模型的鲁棒性,因为现实生活中的主体经常会在环境中投射阴影。在I上创建阴影的方法是,按照被摄体的轮廓30%的范围,将被摄体后面的一些图像区域变暗。合成图像的例子如图11所示。最下面一行是阴影增强的例子。

D.2.测试增强
对于AIM和Distinctions,它们各有11个人类测试样本,我们将每个样本与背景测试集的5个随机背景配对。对于有85个测试样本的PhotoMatte85,我们只用1个背景对每个样本进行配对。我们使用[26]中描述的方法和指标来评估55、55和85图像的结果集。
我们仅对背景B应用随机子像素平移(±0.3像素)、随机伽玛(0.85~1.15)和高斯噪声( μ \mu μ=±0.02,0.08≤σ2≤0.15),以模拟错位。
用作基于trimap的方法的输入和定义误差度量区域的trimap是通过在0.06和0.96之间对grouth truth alpha进行阈值化,然后使用3×3的圆核对其进行10次迭代的膨胀,再进行10次迭代的腐蚀得到的。
E.性能
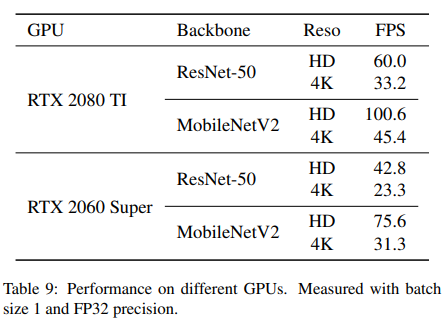
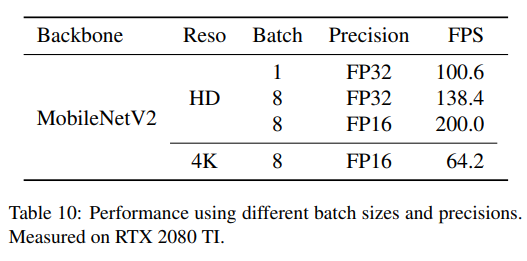
表9显示了我们的方法在两个Nvidia RTX 2000系列GPU上的性能:旗舰级RTX 2080 TI和入门级RTX 2060 Super。入门级GPU产生的FPS较低,但对于许多实时应用来说,仍在可接受的范围内。此外,表10显示,切换到更大的batch size和更低的精度可以显著提高FPS。
F.额外结果
在图13、14、15中,我们展示了用户研究中所有34个例子,以及他们的平均评分和不同方法的结果。图12显示了我们用户研究的Web UI。

References
[1] Yagiz Aksoy, Tae-Hyun Oh, Sylvain Paris, Marc Pollefeys, and Wojciech Matusik. Semantic soft segmentation. ACM Transactions on Graphics (TOG), 37(4):72, 2018. 2
[2] Yagiz Aksoy, Tunc Ozan Aydin, and Marc Pollefeys. Designing effective inter-pixel information flow for natural image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 29–37, 2017. 1,2
[3] Shaofan Cai, Xiaoshuai Zhang, Haoqiang Fan, Haibin Huang, Jiangyu Liu, Jiaming Liu, Jiaying Liu, Jue Wang,and Jian Sun. Disentangled image matting. International Conference on Computer Vision (ICCV), 2019. 2
[4] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017. 2, 3
[5] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018. 2, 3
[6] Qifeng Chen, Dingzeyu Li, and Chi-Keung Tang. Knn matting. IEEE transactions on pattern analysis and machine intelligence, 35(9):2175–2188, 2013. 1, 2
[7] Yung-Yu Chuang, Brian Curless, David H Salesin, and Richard Szeliski. A bayesian approach to digital matting. In CVPR (2), pages 264–271, 2001. 1, 2
[8] Marco Forte and Franc¸ois Pitie. F,b, alpha matting. ´ arXiv preprint arXiv:2003.07711, 2020. 5
[9] Eduardo SL Gastal and Manuel M Oliveira. Shared sampling for real-time alpha matting. In Computer Graphics Forum, volume 29, pages 575–584. Wiley Online Library, 2010. 1,2
[10] Minglun Gong and Yee-Hong Yang. Near-real-time image matting with known background. In 2009 Canadian Conference on Computer and Robot Vision, pages 81–87. IEEE, 2009. 2
[11] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir-shick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017. 2
[12] Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 3
[13] Qiqi Hou and Feng Liu. Context-aware image matting for simultaneous foreground and alpha estimation. International Conference on Computer Vision (ICCV), 2019. 2
[14] S. Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ArXiv, abs/1502.03167, 2015. 4
[15] Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Girshick. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9799–9808, 2020. 2
[16] Anat Levin, Dani Lischinski, and Yair Weiss. A closed-form solution to natural image matting. IEEE transactions on pattern analysis and machine intelligence, 30(2):228–242, 2007. 1, 2
[17] Anat Levin, Alex Rav-Acha, and Dani Lischinski. Spectral matting. IEEE transactions on pattern analysis and machine intelligence, 30(10):1699–1712, 2008. 1, 2
[18] Yaoyi Li, Qingyao Xu, and Hongtao Lu. Hierarchical opacity propagation for image matting. arXiv preprint arXiv:2004.03249, 2020. 2
[19] Xiaodan Liang, Ke Gong, Xiaohui Shen, and Liang Lin. Look into person: Joint body parsing & pose estimation network and a new benchmark. IEEE transactions on pattern analysis and machine intelligence, 41(4):871–885, 2018. 2
[20] Jinlin Liu, Yuan Yao, Wendi Hou, Miaomiao Cui, Xuansong Xie, Changshui Zhang, and Xian-sheng Hua. Boosting semantic human matting with coarse annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8563–8572, 2020. 2
[21] Hao Lu, Yutong Dai, Chunhua Shen, and Songcen Xu. Indices matter: Learning to index for deep image matting. International Conference on Computer Vision (ICCV), 2019.2
[22] V. Nair and Geoffrey E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010. 4
[23] Adam Paszke, S. Gross, Francisco Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L.Antiga, Alban Desmaison, Andreas Kopf, E. Yang, Zach De- ¨Vito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, B. Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. ArXiv, abs/1912.01703, 2019. 11
[24] Richard J Qian and M Ibrahim Sezan. Video background replacement without a blue screen. In Proceedings1999 International Conference on Image Processing (Cat.99CH36348), volume 4, pages 143–146. IEEE, 1999. 2
[25] Yu Qiao, Yuhao Liu, Xin Yang, Dongsheng Zhou, Mingliang Xu, Qiang Zhang, and Xiaopeng Wei. Attention-guided hierarchical structure aggregation for image matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13676–13685, 2020. 1, 2
[26] Christoph Rhemann, Carsten Rother, Jue Wang, Margrit Gelautz, Pushmeet Kohli, and Pamela Rott. A perceptually motivated online benchmark for image matting. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 1826–1833. IEEE, 2009. 5, 12
[27] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018. 3
[28] Soumyadip Sengupta, Vivek Jayaram, Brian Curless, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Background matting: The world is your green screen. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2291–2300, 2020. 1, 2, 5, 6
[29] Xiaoyong Shen, Xin Tao, Hongyun Gao, Chao Zhou, and Jiaya Jia. Deep automatic portrait matting. In European Conference on Computer Vision, pages 92–107. Springer, 2016. 29
[30] Jian Sun, Jiaya Jia, Chi-Keung Tang, and Heung-Yeung Shum. Poisson matting. In ACM Transactions on Graphics (ToG), volume 23, pages 315–321. ACM, 2004. 1, 2
[31] Jingwei Tang, Yagiz Aksoy, Cengiz Oztireli, Markus Gross, and Tunc Ozan Aydin. Learning-based sampling for natural image matting. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[32] Jue Wang, Michael F Cohen, et al. Image and video matting: a survey. Foundations and Trends® in Computer Graphics and Vision, 3(2):97–175, 2008. 2
[33] Ning Xu, Brian Price, Scott Cohen, and Thomas Huang.Deep image matting. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, pages 2970–2979, 2017. 1, 2, 5
[34] Song-Hai Zhang, Ruilong Li, Xin Dong, Paul Rosin, Zixi Cai, Xi Han, Dingcheng Yang, Haozhi Huang, and Shi-Min Hu. Pose2seg: Detection free human instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 889–898, 2019. 2
[35] Yunke Zhang, Lixue Gong, Lubin Fan, Peiran Ren, Qixing Huang, Hujun Bao, and Weiwei Xu. A late fusion cnn for digital matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7469–7478, 2019. 2
[36] Bingke Zhu, Yingying Chen, Jinqiao Wang, Si Liu, BoZhang, and Ming Tang. Fast deep matting for portrait animation on mobile phone. In Proceedings of the 25th ACM international conference on Multimedia, pages 297–305. ACM, 2017. 2