ChatGPT使用门槛高,需要科学上网短信接码等,不如直接选择国产ZelinAI,使用超简单轻轻松松从0到1零代码创建自己的AI应用。目前模型仅支持GPT-3.5-turbo,后续应该会接入文心一言、GPT-4、GPT-4.5和Bard,新手站长分享国产的ChatGPT ZelinAI及专业版Pro获得方法:
目录
ZelinAI
ZelinAI专业版Pro获得方法
ZelinAI使用参数说明
Model_avatar
Model_name
Key
Model_type
Temperature
Top_p
Presence_penalty
Frequency_penalty
N
Stream
Stop
Logit_bias
Role
Output_format
Keep_context
ZelinAI
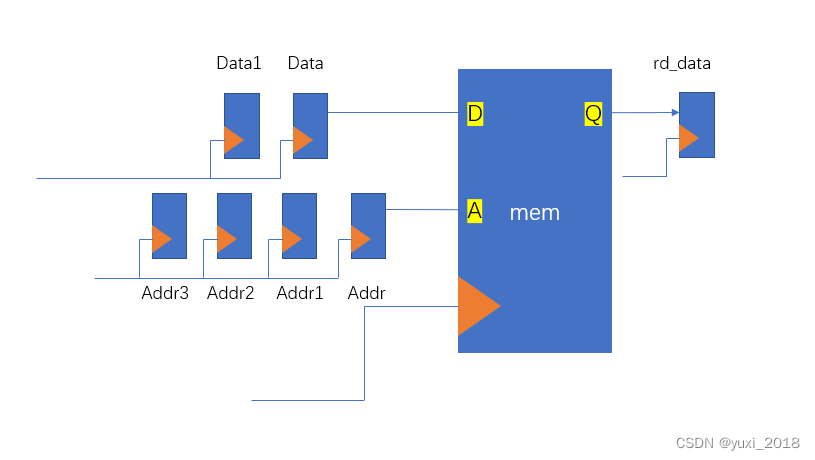
ZelinAI版本支持基础版(免费)、专业版、旗舰版和企业版,直接注册是免费版,使用填写邀请码119340可以获得2天的专业版Pro使用时长。目前ZelinAI进支持GPT-3.5-turbo,对于一般应用场景足够了,后续ZelinAI应该会接入文心一言、GPT-4、GPT-4.5和Bard,期待一下吧,如下图:

ZelinAI模型支持GPT-3.5-turbo
使用方法也超简单,参数都有解释,没有特殊要求可以先保持默认设置,然后随着后续的应用调试来修改合适的参数值。
ZelinAI专业版Pro获得方法
在ZelinAI官网:zelinai.com 注册,注册时填写【119340】可以获得2天的专业版Pro使用时长,用于大家测试,普通注册方式直接是免费版,如下图:
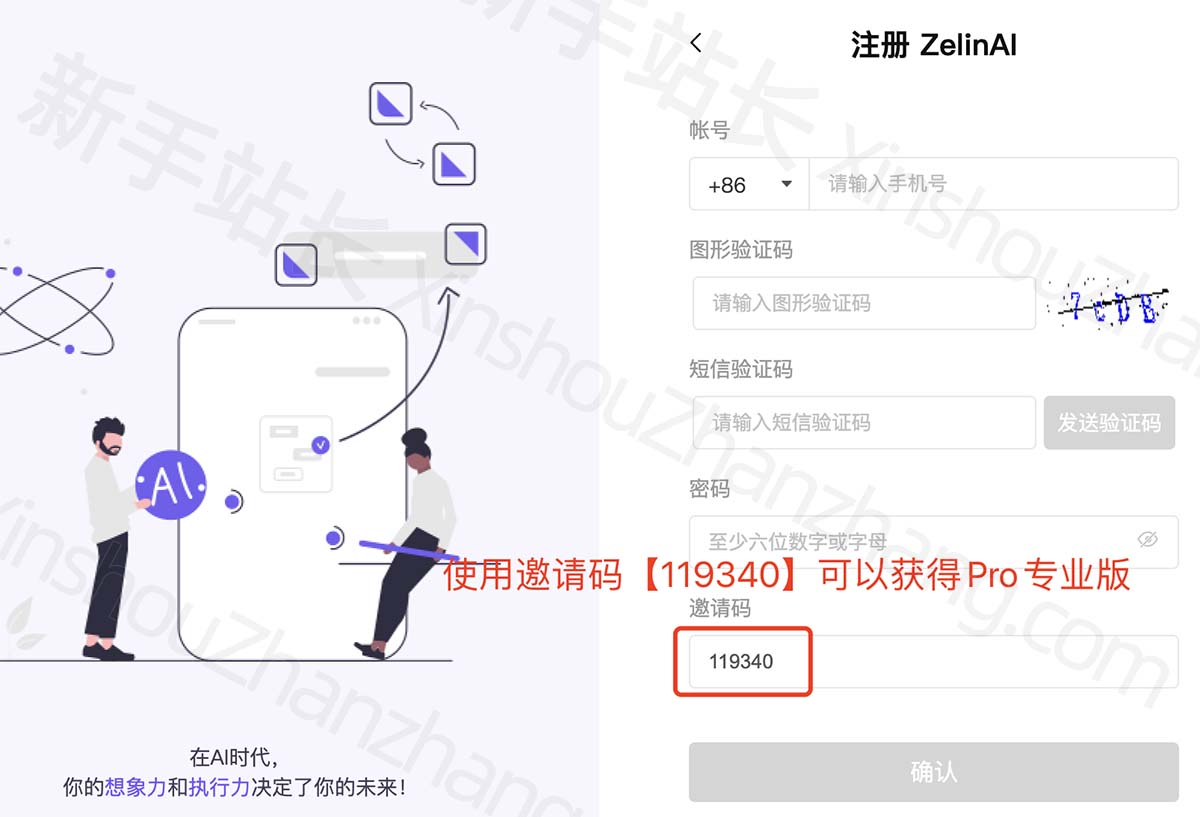
ZelinAI专业版Pro邀请码【119340】
ZelinAI不同版本的区别:免费版支持创建1个模型、专业版可以创建10个模型、旗舰版模型数量不限制,新手站长整理了ZelinAI不同版本对照表:
| ZelinAI版本 | 基础版(免费0元) | 专业版 | 旗舰版 |
|---|---|---|---|
| 模型 | 创建模型(个):1 Key:公共 支持参数(个):3 | 创建模型(个):10 Key:公共 支持参数(个):12 | 创建模型(个):不限量 Key:私有+公共 支持参数(个):12 |
| 对话 | 每日次数:10次 | 每日次数:100次 | 每日次数:200次 |
| 赠送体验金 | 10元 | 20元 | 100元 |
| 训练 | 支持 训练集数量(个):1 | 支持 训练集数量(个):10 | 支持 训练集数量(个):不限量 |
| 应用 | 支持 AI应用数量(个):1 | 支持 AI应用数量(个):10 | 支持 AI应用数量(个):不限量 |
| 不同版本费用 | 免费0元 | 49元/月,399元/年 | 99元/月,699元/年 |
ZelinAI还支持企业版,企业版直接联系ZelinAI的官方客服,模型、训练及应用是可以定制的,需要调参及Prompt培训和私有化部署可以申请企业版。
ZelinAI使用参数说明
Model_avatar
Model_avatar:AI应用头像。
Model_name
Model_name:AI应用名称,中英文均可。
Key
Key:免费版和专业版模式是公共Key,旗舰版可以使用私有Key,出于合规需求考量,当前仅支持输入微软OpenAI的Key;
Model_type
Model_type目前仅支持GPT-3.5-turbo,后续期待文心一言、GPT-4、GPT-4.5和Bard。
Temperature
- Temperature:默认值1,通常用于生成有趣、创意性的文本。
- 设置范围:0到2之间的浮点数。
作用:控制生成文本的多样性。较高的 Temperature 值会导致生成的文本更具有创造性和多样性,但是也可能会导致生成的文本不够准确和不可信。较低的 Temperature 值则会导致生成的文本更加保守和保险,但是可能会过于死板和缺乏新意。因此,在设置 Temperature 值时需要权衡准确性和多样性之间的平衡。
Top_p
- Top_p:默认值1,Top_p通常用于生成技术文档、科学论文等需要准确性的文本。
- 设置范围:0到1之间的浮点数。
作用:Top_p用于控制生成文本的多样性和保真度。Top_p 会根据生成文本的概率分布,只保留前面概率之和达到一定阈值的词语,然后再从中随机选择一个词语作为下一个生成的词语。较高的 Top_p 值会导致生成的文本更具有多样性,但是会牺牲一定的准确性和保真度。较低的 Top_p 值则会导致生成的文本更加保险和准确,但是可能会过于死板和缺乏新意。在设置 Top_p 值时,需要根据生成文本的任务类型和需求进行权衡。
Presence_penalty
- 设置范围:-2.0 和 2.0
作用:控制文本同一词汇重复情况。当此参数值大于0时,将鼓励模型生成不同的单词,并尽可能避免使用已经在之前生成的文本中出现过的单词。如果presence_penalty值越大,生成的文本中不同单词的数量可能越多。如果presence_penalty值为0,则不会考虑之前生成的单词,并且每次生成的单词概率分布都是相同的。 例如,在文本生成任务中,如果需要鼓励生成不同的单词,并且避免使用相同的单词,可以增大presence_penalty的值;
Frequency_penalty
- 设置范围:-2.0 和 2.0。
作用:控制文本罕见词汇出现情况。当此参数值大于0时,将抑制模型生成频繁出现的单词,并鼓励生成罕见的单词。如果frequency_penalty值越大,生成的文本中罕见单词的数量可能越多。如果frequency_penalty值为0,则不会考虑单词的频率,并且每次生成的单词概率分布都是相同的。 如果需要鼓励生成罕见的单词,可以增大frequency_penalty的值。
N
- 默认值:1
- 设置范围:1到5之间的整数。
作用:这个参数可以用于控制生成文本的连贯性和自然程度。指定使用n-gram模型进行文本生成的n的值。当n的值较小时,生成的文本会更加流畅和自然,但是可能会出现过多的复制文本。当n的值较大时,生成的文本会更加接近原始文本,但可能会出现矛盾或不连贯的情况。
Stream
- 默认值:true
- 设置范围:true或false
作用:用于控制生成文本的输出方式。如果将stream参数设置为True,则文本将以流的方式输出,即在生成文本的同时输出文本,而不是等待文本生成完成后再输出。这个参数适用于需要及时输出文本的场景。
Stop
作用:用于停止生成并返回结果。这个参数可以是单词或短语列表,当模型生成包含这些单词/短语的文本时,它将。这通常用于在生成过程中控制输出内容。用户可以自定义 "stop"参数, 具体应用能够节省比返回文本之后对结果进行筛选所需的时间更长时间和资源。
词与词之间用#隔开
Logit_bias
作用:接受一个 json 对象,该对象将标记(由标记器中的标记 ID 指定)映射到从 -100 到 100 的关联偏差值。从数学上讲,偏差会在采样之前添加到模型生成的 logits 中。确切的效果因模型而异,但 -1 和 1 之间的值应该会减少或增加选择的可能性;像 -100 或 100 这样的值应该导致相关令牌的禁止或独占选择。
Role
作用:定义该模型的角色,有助于获得更加准确的内容。
Output_format
作用:定义输出内容的格式或要求,有助于获得格式化的内容
Keep_context
- 默认值:false
- 设置范围:true或false
作用:关联上下文,如果是对话式的内容,需要AI更理解语境则可将其设置为True,如果是问答式内容,则可设置为False。
更多关于ZelinAI的说明,请以ZelinAI官方为准。
原文:https://www.xinshouzhanzhang.com/zelinai.html