前言
数据迁移时, 为了保证数据的一致性, 往往伴随着停服, 此期间无法给用户提供服务或只能提供部分服务. 同时, 为了确保迁移后业务及数据的正确性, 迁移后测试工作也要占用不少时间. 如此造成的损失是比较大的.
接下来, 本文将就如何在不停服的情况下进行数据迁移进行探讨.
案例
订单系统中存在这样一组订单表:
数据库: MySQL
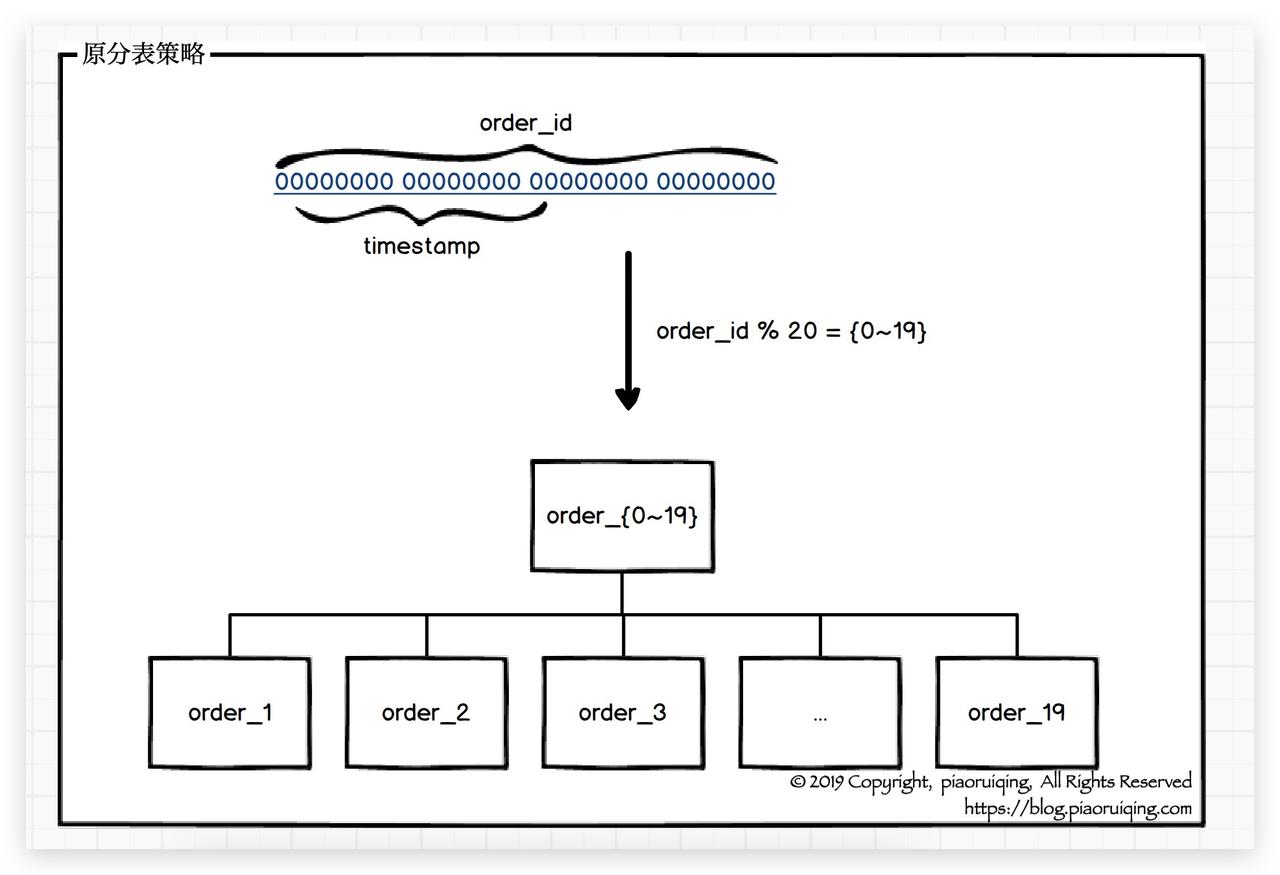
表名: order_{0~19}, 其中{0~19}为后缀, 合共20张表.
主键: order_id, 订单ID, 通过雪花算法获得, 可通过ID获取创建时间.
原分表策略: order_id % 20
伴随着业务量增长, 各分表的数据量已经破千万, 如此下去会产生严重的性能问题, 此时需要将原分表进行迁移.
要求:
将原20张分表数据迁移至新表
迁移全过程中不可停机, 须对外提供完整的服务.
提供完备的回退方案, 迁移过程中产生的数据不可丢, 不能人为修数据.
分析
有过分库分表经验的读者可能已经发现案例中原分表策略十分不合理, 其缘由不去追究(毕竟换了几波人之后已经没办法找到当年的人吊起来揍了).
分析一下原数据表: 订单数据肯定会伴随着时间和业务量直线上升, 固定的分表数量会导致随数据量增大性能下降. 所以, 数据迁移后, 分表的数量不能再固定, 即使从20改成100个总有一天也会达到瓶颈.
订单数据会伴随时间增长, 而且在超过退款期限后就变成了冷数据, 使用率会降低. 因此, 将订单按照创建时间来进行分表是一个不错的选择. 值得一提的是, orde





