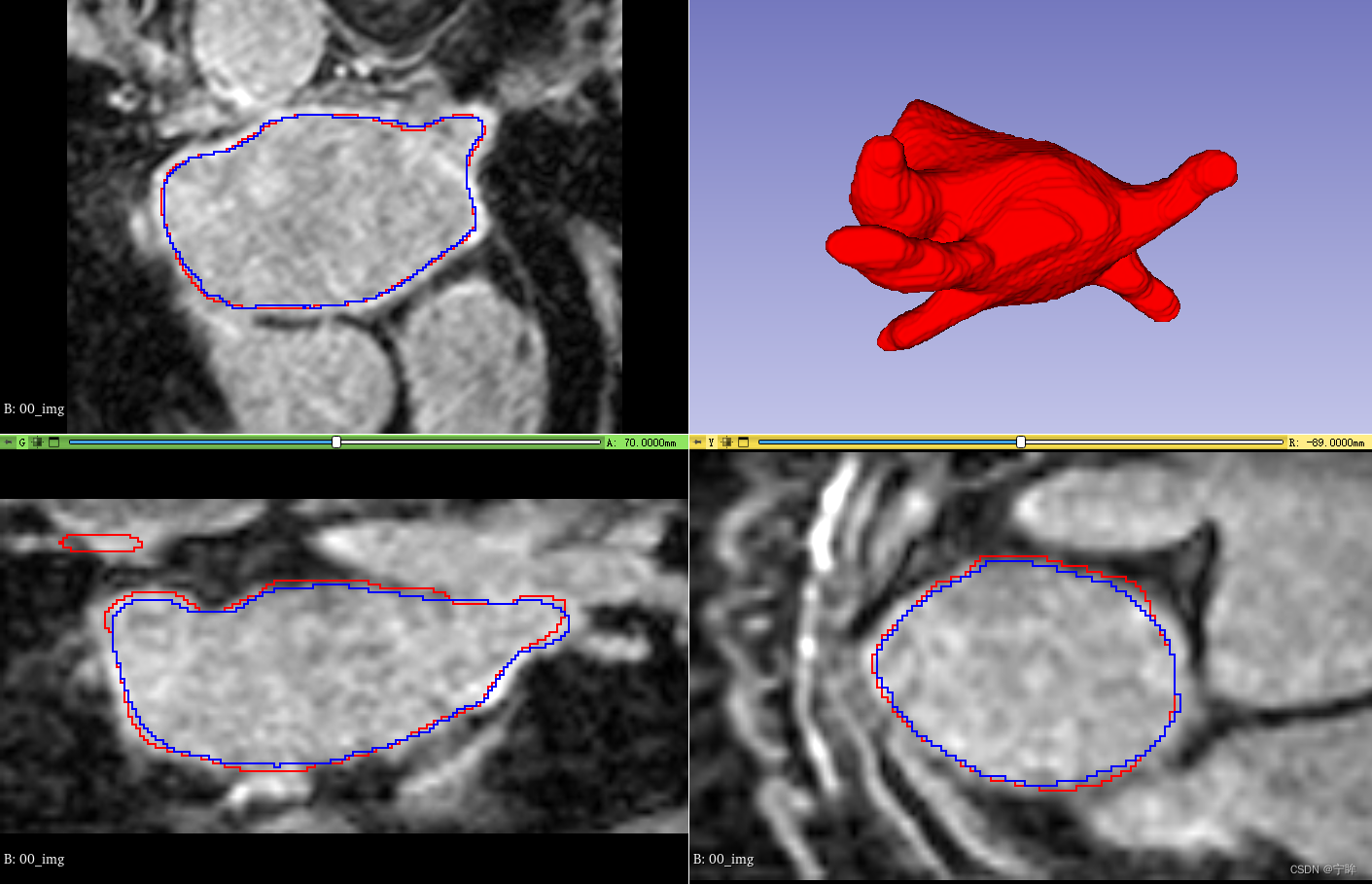
半监督方法:不确定性感知自增强模型
文献:Uncertainty-aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation(半监督方法:不确定性感知自增强模型)
原文:https://arxiv.org/abs/1907.07034
代码:https://github.com/yulequan/UA-MT
主题:semi-supervised, segmentation,Uncertainty estimation
文章目录
- 半监督方法:不确定性感知自增强模型
- Abstract(摘要)
- Introduction(研究背景/意义)
- Method(研究思路)
- 1.数据来源
- 2.研究方法和原理
- Experiments and Results(实验结果)
- 实验细节
- Conclusion(结论)
Abstract(摘要)
-
想解决什么问题?question
深度卷积神经网络的训练通常需要大量的标记数据。然而,在医学图像分割任务中注释数据是昂贵和费时。
-
通过什么理论/模型来解决这个问题?method
a uncertainty-aware semi-supervised framework
-
作者给出的答案是什么?answer
我们的框架通过鼓励对不同干扰下的相同输入进行一致的预测,可以有效地利用未标记数据。具体来说,该框架由学生模型和教师模型组成,学生模型通过最小化对教师模型目标的分割损失和一致性损失来对教师模型进行学习。
Introduction(研究背景/意义)
-
为什么研究这个课题?
从3D医学图像中描绘注释是昂贵而乏味的,未标记的数据是丰富的。
-
目前这个课题的研究进行到了哪一阶段?(存在问题、待解决问题)
Previous methods: a self-training-based method ,the weight-averaged consistency targets ,deep adversarial network (DAN),aversarial learning based semi-supervised method (ASDNet)
Shortcoming: 虽然经取得了可喜的进展,但这些方法没有考虑目标的可靠性,这可能导致毫无意义的指导.
Current method: 我们的方法遵循mean-teacher的相同精神,鼓励对同一输入在不同扰动下的分割预测保持一致。
-
理论是基于哪些假设?(看不明白也没关系,先抄下来)
我们的框架通过鼓励对不同干扰下的相同输入进行一致的预测,可以有效地利用未标记数据。更重要的是,我们探索模型的不确定性,以提高目标的质量。我们设计了不确定性感知平均教师(UA-MT)框架,利用教师模型的不确定性信息,学生模型逐渐从有意义和可靠的目标中学习。具体地说,除了生成目标输出,教师模型还通过蒙特卡罗抽样估计每个目标预测的不确定性。在估计不确定性的指导下,在计算一致性损失时,我们过滤掉不可靠的预测,只保留可靠的预测(低不确定性)。
Method(研究思路)
1.数据来源
Atrial Segmentation Challenge dataset4, GE-MRIs
2.研究方法和原理
(先看文章中的table,而不是理论的推导过程)
2.1 整体流程

如上图(Fig.1)所示,对于有标签数据,学生模型 (student model)进行有监督学习。对于无标签数据,通过教师模型 (teacher model)预测分割图,作为学生模型 (student model)的学习目标,并同时评估学习目标的不确定性。基于学习目标的不确定性,采用一致性损失函数提高学生模型的性能。
下面的数学理论翻译来自: [Python编程和深度学习]



Experiments and Results(实验结果)



参数:
Dice:不同样本的相似度
Jaccard:
Hausdorff distance(HD):描述了两组点之间的相似性
ASD:平均表距离
MT: 原平均教师法,MT- dice:改进平均教师法
UA-MT-UN:为了分析一致性丢失对标记数据和未标记数据的重要性,仅对未标记数据进行一致性损失。
实验细节
数据预处理:
1、数据nrrd形式,归一化后转为h5py形式封装起来,构造Dataset类,Dataloader加载
2、数据集 train:test = 8 : 2
3、train data: Random crop ,Random flip、rotate
test data:Center Crop
V-net:
1、Dice loss与Cross entropy loss结合
2、2个dropout层,上采样和下采样的最后一层
Conclusion(结论)
使用未标记的数据、模型的不确定性,可以提高目标的质量
未来的工作研究:不同不确定性估计方式的影响
![[渝粤教育] 中国地质大学 会计专业英语 复习题 (2)](/images/no-images.jpg)