一、问题原因
df.iterrows() 是用来遍历 Pandas DataFrame 的方法,它会把 DataFrame 中的每一行转换成一个元组,其中第一个元素是行号,第二个元素是该行的数据。行号从 0 开始。
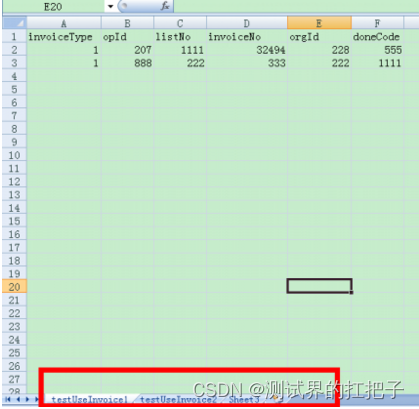
在使用 df.iterrows() 遍历 DataFrame 的时候发现表格第二行被当成了第0行,这是因为的DataFrame 中的第一行是列名,而不是数据。
例如,假设你的表格是这样的:
第1行表头:A B C
第2行:1 2 3
第3行:4 5 6
第4行:7 8 9
经过Pandas读取表格后的DataFrame会变成:
A B C
0 1 2 3
1 4 5 6
2 7 8 9
如果你使用 df.iterrows() 来遍历这个 DataFrame,你会得到以下的结果:
for index, row in df.iterrows():print(index, row)#打印结果
#行号 表格内容0 11 22 33 44 55 66 77 88 9 可以看到,就是DataFrame在转换时把表格第一行当成了列名,所以我们下意识想遍历表格所以内容时就无法读取到表格的第一行。
二、解决办法:
在读取表格的时候指定header为None
#header=None参数表示不将Excel文件中的任何行作为列名,而是将数据的第一行作为数据行处理。df = pd.read_csv('your_file.csv', header=None)df = pd.read_excel('your_file.xlsx',header=None)-----------------------------------------------------------------我是分割线--------------------------------------------------------------
看完了觉得不错就点个赞或者评论下吧,感谢!!!
如果本文哪里有误随时可以提出了,收到会尽快更正的