前言
glob本质是Unix shell 风格的路径匹配规则。
该规则后续被其它语言支持。
?:匹配一个任意字符
*:匹配任意个任意字符
[sequence]:匹配出现在sequence里面的一个字符
[!sequence]:匹配没有出现在sequence里面的一个字符
[a-m]:匹配出现在abcdef...m中的字符
[A-M]:匹配出现在ABCDEF...M中的字符
[0-9]:匹配出现在0123...9中的字符
基础功能
匹配文件最经典的 *.txt
以反斜杠结尾,则只匹配目录(而非文件)。
后来的某个版本开始,bash支持 globstar ,即支持**运算符,匹配 “无” 或任意层级的目录。
bash4发布globstar的文章 May 11, 2010。
https://www.linuxjournal.com/content/globstar-new-bash-globbing-option
Normally when you use **, it works similar to *, but it’s recurses all the directories recursively (like a loop).
注意bash中这个功能需要主动开启。
Python
函数定义
def glob.glob(pathname, *, root_dir=None, dir_fd=None, recursive=False)
1.root_dir
其中root_dir可以省略。
如果不为None会拼在pathname前面。
即下面两种写法在搜索上是等价的
glob.glob('/home/user/*.txt')
glob.glob('*.txt',root_dir='/home/user')
区别:
glob.glob('/home/user/*.txt')
返回
[ '/home/user/1.txt', '/home/user/2.txt']
而
glob.glob('*.txt',root_dir='/home/user')
返回
[ '1.txt', '2.txt']
2. recursive
在python glob模块中,默认关闭递归模式。
当且仅当设置recursive=True时,才会识别**符号。
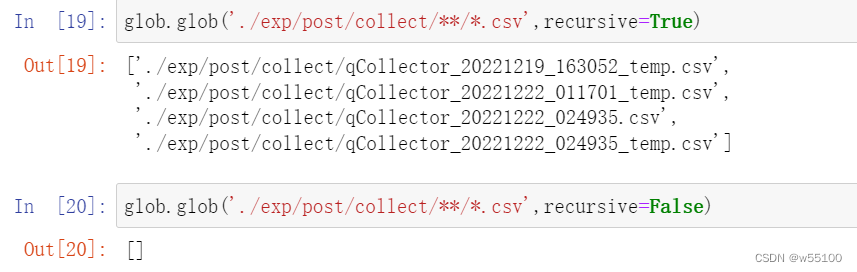
import glob
glob.glob('./exp/post/collect/**/*.csv',recursive=True)
glob.glob('./exp/post/collect/**/*.csv',recursive=False)
如图所示
在现代版本的node中, node-glob 模块默认开启对**的支持,无需任何其他设置。
注意**.py 只会匹配一级目录。
想递归任意深度得用**/*.py
3. with pathlib.Path
pathname部分仅支持string类型。
使用 pathlib库 会报错'PosixPath' object is not subscriptable.
可以用 PosixPath.glob(pattern)
即下面的写法是等价的
import glob
from pathlib import Path
#写法1
glob.glob('*.txt',root_dir='/home/user')
#写法2
root_dir = Path('/home/user')
root_dir.glob('*.txt') # 返回值是一个generator
list(root_dir.glob('*.txt')) # 我们熟悉的list
reference
https://unix.stackexchange.com/questions/49913/recursive-glob