系列文章目录
Flink第一章:环境搭建
Flink第二章:基本操作.
Flink第三章:基本操作(二)
Flink第四章:水位线和窗口
Flink第五章:处理函数
文章目录
- 系列文章目录
- 前言
- 一、基本处理函数(ProcessFunction)
- 二、按键分区处理函数(KeyedProcessFunction)
- 1.处理时间定时服务
- 2.事件时间定时服务
- 三、TopN案例
- 1.ProcessAllWindowFunction
- 2.KeyedProcessFunction
- 总结
前言
处理函数
简单来时就是比DataStream API更加底层的函数,能够处理更加复杂的问题
创建scala文件
一、基本处理函数(ProcessFunction)
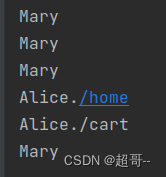
我们用它来实现一个简单的Map操作,如果点击用户是Marry就输出用户名,是Alice就输出用户名+url
ProcessFunction.scala
package com.atguigu.chapter04import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collectorobject ProcessFunction {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val stream: DataStream[Event] = env.addSource(new ClickSource).assignAscendingTimestamps(_.timestamp)stream.process(new ProcessFunction[Event,String] {override def processElement(value: Event, ctx: ProcessFunction[Event, String]#Context, out: Collector[String]): Unit = {if (value.user.equals("Mary"))out.collect(value.user)else if (value.user.equals("Alice")){out.collect(value.user+value.url)}}}).print()env.execute()}
}
二、按键分区处理函数(KeyedProcessFunction)
在 Flink 程序中,为了实现数据的聚合统计,或者开窗计算之类的功能,我们一般都要先用 keyBy()算子对数据流进行“按键分区”,得到一个 KeyedStream。而只有在 KeyedStream 中,才支持使用 TimerService 设置定时器的操作。所以一般情况下,我们都是先做了 keyBy()分区之后,再去定义处理操作;代码中更加常见的处理函数是 KeyedProcessFunction。
1.处理时间定时服务
主要是在数据到达一段时间后进行数据操作
ProcessingTimeTimerTest.scala
package com.atguigu.chapter04import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
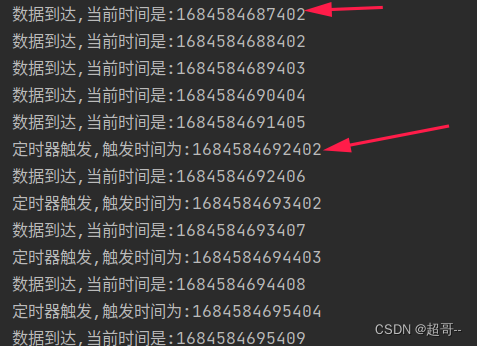
import org.apache.flink.util.Collectorobject ProcessingTimeTimerTest {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val stream: DataStream[Event] = env.addSource(new ClickSource).assignAscendingTimestamps(_.timestamp)stream.keyBy(data=>true).process(new KeyedProcessFunction[Boolean,Event,String] {override def processElement(value: Event, ctx: KeyedProcessFunction[Boolean, Event, String]#Context, out: Collector[String]): Unit = {val currenTime: Long = ctx.timerService().currentProcessingTime()out.collect("数据到达,当前时间是:"+currenTime)//注册一个5秒之后的定时器ctx.timerService().registerProcessingTimeTimer(currenTime+5*1000)}//执行逻辑override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Boolean, Event, String]#OnTimerContext, out: Collector[String]): Unit = {out.collect("定时器触发,触发时间为:"+timestamp)}}).print()env.execute()}
}
2.事件时间定时服务
在数据产生一段时间后进行处理
EventTimeTimeTest.scala
package com.atguigu.chapter04import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
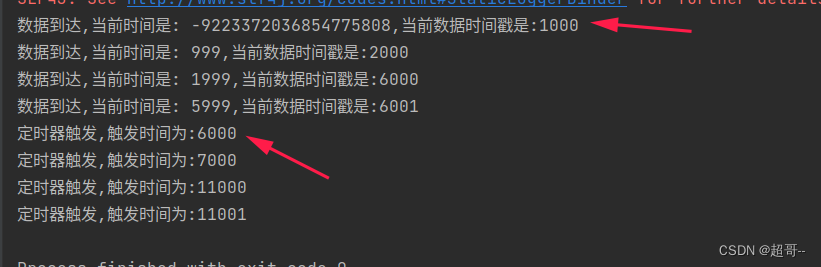
import org.apache.flink.util.Collectorobject EventTimeTimeTest {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val stream: DataStream[Event] = env.addSource(new CustomSource).assignAscendingTimestamps(_.timestamp)stream.keyBy(data=>true).process(new KeyedProcessFunction[Boolean,Event,String] {override def processElement(value: Event, ctx: KeyedProcessFunction[Boolean, Event, String]#Context, out: Collector[String]): Unit = {val currenTime: Long = ctx.timerService().currentWatermark()out.collect(s"数据到达,当前时间是: $currenTime,当前数据时间戳是:${value.timestamp}")//注册一个5秒之后的定时器ctx.timerService().registerEventTimeTimer(ctx.timestamp()+5*1000)}//执行逻辑override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Boolean, Event, String]#OnTimerContext, out: Collector[String]): Unit = {out.collect("定时器触发,触发时间为:"+timestamp)}}).print()env.execute()}class CustomSource extends SourceFunction[Event]{override def run(ctx: SourceFunction.SourceContext[Event]): Unit = {ctx.collect(Event("Mary","./home",1000L))Thread.sleep(5000)ctx.collect(Event("Mary","./home",2000L))Thread.sleep(5000)ctx.collect(Event("Mary","./home",6000L))Thread.sleep(5000)ctx.collect(Event("Mary","./home",6001L))Thread.sleep(5000)}override def cancel(): Unit = ???}
}
三、TopN案例
1.ProcessAllWindowFunction
TopNProcessAllWindowExample.scala
package com.atguigu.chapter04import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collectorimport scala.collection.mutableobject TopNProcessAllWindowExample {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val stream: DataStream[Event] = env.addSource(new ClickSource).assignAscendingTimestamps(_.timestamp)// 直接开窗统计stream.map(_.url).windowAll(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).process(new ProcessAllWindowFunction[String, String, TimeWindow] {override def process(context: Context, elements: Iterable[String], out: Collector[String]): Unit = {// 1.统计每个url的访问次数// 初始化Map (url,count)val urlCountMap: mutable.Map[String, Long] = mutable.Map[String, Long]()elements.foreach(data => urlCountMap.get(data) match {case Some(count) => urlCountMap.put(data, count + 1)case None => urlCountMap.put(data, 1)})//2.对数据进行排序提取val urlCountList: List[(String, Long)] = urlCountMap.toList.sortBy(-_._2).take(2)//3.包装信息打印输出val result = new mutable.StringBuilder()result.append(s"=========窗口: ${context.window.getStart} - ${context.window.getEnd}=======\n")for (i <- urlCountList.indices){val tuple: (String, Long) = urlCountList(i)result.append(s"浏览量TopN ${i+1}").append(s"url: ${tuple._1} ").append(s"浏览量是: ${tuple._2} \n")}out.collect(result.toString())}}).print()env.execute()}
}

2.KeyedProcessFunction
TopNkeyProcessFunctionExample.scala
package com.atguigu.chapter04import com.atguigu.chapter02.Source.{ClickSource, Event}
import com.atguigu.chapter03.UrlViewCount
import com.atguigu.chapter03.UrlViewCountExample.{UrlViewCountAgg, UrlViewCountResult}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collectorimport scala.collection.convert.ImplicitConversions.`iterable AsScalaIterable`
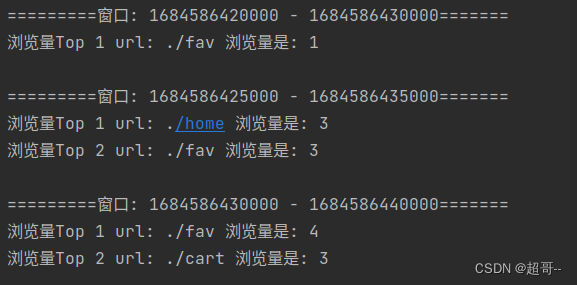
import scala.collection.mutableobject TopNkeyProcessFunctionExample {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val stream: DataStream[Event] = env.addSource(new ClickSource).assignAscendingTimestamps(_.timestamp)// 1.结合使用增量聚合函数和全窗口函数,统计每个url的访问频次val urlCountStream: DataStream[UrlViewCount] = stream.keyBy(_.url).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))).aggregate(new UrlViewCountAgg, new UrlViewCountResult)// 2.按照窗口信息进行分组提取,排序输出val resultStream: DataStream[String] = urlCountStream.keyBy(_.windowEnd).process(new TopN(2))resultStream.print()env.execute()}class TopN(n: Int) extends KeyedProcessFunction[Long, UrlViewCount, String] {// 声明列表状态var urlViewCountListState: ListState[UrlViewCount] = _override def open(parameters: Configuration): Unit = {urlViewCountListState = getRuntimeContext.getListState(new ListStateDescriptor[UrlViewCount]("list-state", classOf[UrlViewCount]))}override def processElement(value: UrlViewCount, ctx: KeyedProcessFunction[Long, UrlViewCount, String]#Context, out: Collector[String]): Unit = {//每来一个数据,就直接放入ListState中urlViewCountListState.add(value)//注册一个窗口结束时间1ms之后的定时器ctx.timerService().registerEventTimeTimer(value.windowEnd + 1)}override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, UrlViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {// 先把数据提取出来放到List里val urlViewCountList: List[UrlViewCount] = urlViewCountListState.get().toListval topnList: List[UrlViewCount] = urlViewCountList.sortBy(-_.count).take(n)//结果包装输出val result = new mutable.StringBuilder()result.append(s"=========窗口: ${timestamp - 1 - 10000} - ${timestamp - 1}=======\n")for (i <- topnList.indices) {val urlViewCount = topnList(i)result.append(s"浏览量Top ${i + 1} ").append(s"url: ${urlViewCount.url} ").append(s"浏览量是: ${urlViewCount.count} \n")}out.collect(result.toString())}}
}
总结
有关Flink底层处理函数的Api就到这里.