文章目录
- 数据库设计规范
- ER图
- 物理模型
- 数据表
- 登录日志表
- 操作日志表
- 菜单表
- 角色表
- 企业表
- 门店表
- 省市区表
- 门店节日表
- 消息表
- 职位表
- 排班规则表
- 排班任务表
- 排班结果存储
- scheduling_date排班日表
- scheduling_shift排班班次表
- shift_user班次员工中间表
- 定时通知表
- 用户表
- 中间表
- role_menu角色菜单中间表
- user_message用户通知中间表
- user_position用户职位中间表
- user_role用户角色中间表
- 索引设计
- 建议设置索引的字段
- 不建议设置索引的字段
数据库设计规范
本项目的数据库设计符合以下规范:
- 表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint (1 表示是,0 表示否)
- 表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字
- 表名不使用复数名词
- 禁用保留字,如 desc、range、match、delayed 等
- 如果存储的字符串长度几乎相等,使用 char 定长字符串类型
- 每个表必备三字段:id, create_time(创建时间),
update_time(修改时间)。除此之外,还添加is_deleted来做逻辑删除,方便误删数据的恢复。 - 库名与应用名称尽量一致
- 如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释
- 字段允许适当冗余,以提高查询性能,但必须考虑数据一致
- 设置合适的字符存储长度,可以节约数据库表空间、节约索引存储,提升检索速度
更多的设计规范可以参考 《阿里巴巴java开发手册》
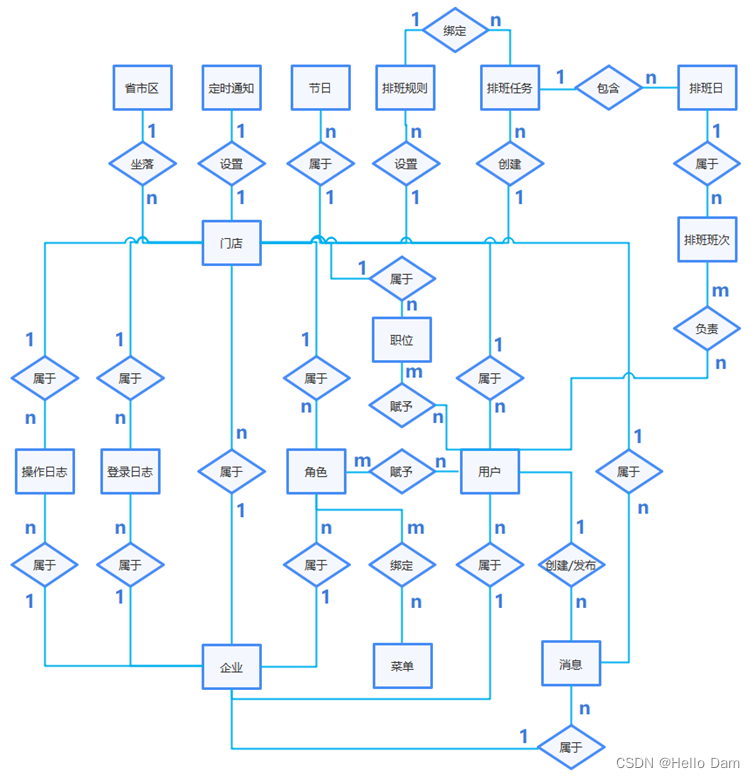
ER图
在ER图中,实体用矩形表示,属性用椭圆表示,关系用菱形表示,菱形上的线条说明不同实体之间的联系类型。当数据库中表较多时,为了ER图的视觉效果更好,可以省略实体的属性,本项目的ER图如下图。
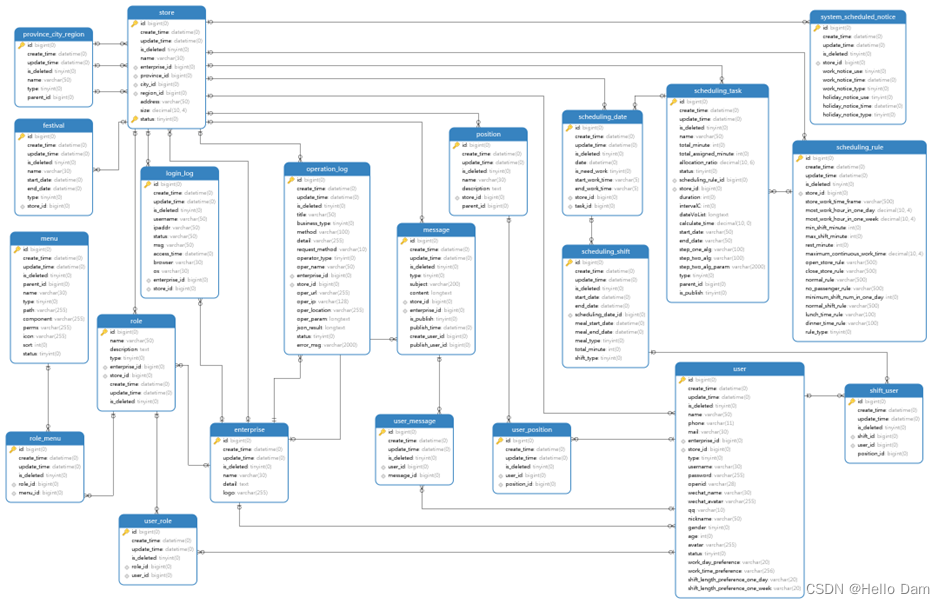
物理模型
数据库物理模型设计是为已确定的数据库逻辑模型研制出一个有效的、可实现的数据库物理结构。是对真实数据库的描述。从物理模型其中可以看到表、字段、数据类型、数据长度、主键、外键、索引……。下图为本项目的数据库物理模型。
数据表
登录日志表
为了帮助系统管理员分析用户的活跃状态,需要使用登录日志表记录每个用户的登录状态。除此之外,登录日志表还可以用于安全检查和异常检测,当出现异常登录行为时,可以通过登录日志表进行追溯和定位,及时采取应对措施,保障系统的安全性。
操作日志表
为了记录系统中发生的各种操作和事件,以便于监控用户行为、排查问题,需要设计操作日志表对用户的操作进行记录。
菜单表
为了让不同身份的用户登录系统使能使用不同的功能,需要使用动态路由,因此需要设计菜单表来记录不同菜单所对应的路由。除此之外,还可以根据用户携带的权限标识来判断用户是否有操作某个按钮的权限。
角色表
如果直接将权限绑定到用户身上,对于拥有相同权限的用户,也需要反复绑定,这样会增加管理员的操作负担。若将权限与角色绑定,给用户赋权时,只需要将其绑定角色,这样不但给管理员带来了便利,还可以减少数据库的数据存储量。
企业表
门店表
省市区表
在存储门店信息的时候,需要存储门店的地理位置,为了方便管理员进行位置选择,本作品设计了省市区表来存储中国的所有省市区数据,用户在设置门店地区时只需要选择级联选择器的数据。
门店节日表
为了让门店管理员在设置任务的工作日时可以更加方便区分节假日,系统需要知道门店的节假日数据。
- 日期类型:在中国,拥有各种各样的节日,有的节日是新历的(如国庆节、元旦节),有的节日是农历的(如中秋节、春节),因此需要字段“日期类型”来进行区分。在判断一个日期对应的节日时,需要将农历转化为新历进行判断,我们使用开源工具calendarist来进行对日期的农历格式、新历格式转换。
消息表
消息表用于存储企业、门店在系统上面给员工发送的通知,以及定时提醒上班、休假的通知。
- 通知类型:企业管理员发布的通知,整个企业的人员都可以看到。门店管理员发送的通知只有门店的员工才能看见。除了企业管理员、门店管理员发送的通知之外,还有系统定时发送的上班提醒通知,对于上班通知,可能部分员工的上班时间是一样的,因此上班通知内容也一样,这种类型的通知是指定用户才能看,使用中间表来将两者进行绑定。
- 是否发布:通知在编辑期间不允许提前被用户看到,因此给通知提供一个发布状态,让管理员来决定是否将通知公开。
职位表
为了让门店管理员可以指定特定职位的员工来进行指定类型的班次工作(比如门店收尾工作需要清洁人员),系统需要设计职位表来存储门店的工作人员职位。
排班规则表
下面是排班规则表的部分字段的详细解释
- 门店工作时间段:为了门店工作时间段设置可以有更高的灵活性,本系统提供一个星期每天的时间段设置,字段值存储方式为{“Mon”:[“开始时间”,“结束时间”],“Tue”:[“开始时间”,“结束时间”],“Wed”:[“开始时间”,“结束时间”],“Thur”:[“开始时间”,“结束时间”],“Fri”:[“开始时间”,“结束时间”],“Sat”:[“开始时间”,“结束时间”],“Sun”:[“开始时间”,“结束时间”]}。
- 开店规则:开店规则需要规定开店工作的提前时间、开店所需人数、以及可执行相应工作的职位。人数=门店面积/ variableParam,字段值存储方式为{“variableParam”:50,“prepareMinute”:30,“positionIdArr”:[7,8,9,10,11,12,13]}。
- 关店规则:关店规则需要规定关店收尾工作的工作时间,工作人数以及可执行相应工作的职位。人数=门店面积/ variableParam1+ variableParam2,字段值存储方式为{“varia-bleParam1”:50,“variableParam2”:2,“closeMinute”:30,“positionIdArr”:[7,8,9,10,11,12,13]}。
- 正常班规则:正常班规则需要规定正常班的人数、可执行正常班工作的职位。人数=预测客流/ variableParam ,字段值存储方式为{“variableParam”:3.8,“positionIdArr”:[7,8,9,10,11,12,13]}
- 午餐时间规则:值样式为{“timeFrame”:[“11:00”,“13:00”],“needMinute”:30},解释为需要将午餐安排在[11:00,13:00]这个时间范围内,午餐时间为30分钟。
- 晚餐时间规则:同上
- 规则类型:因为在进行排班计算的时候,门店管理员有时候需要对任务的规则进行微调,但是又不影响门店的排班规则,例如四月份门店地板受潮,顾客在门店留下较多脚印,需要更多的清洁人员来进行门店收尾工作。为了实现该功能,本系统为每个任务绑定一个排班规则,该规则由门店排班规则拷贝而来,因此其规则类型为从规则,用于和门店规则进行区分。通过修改从规则,可以根据任务需要对规则重新定义,同时不会影响门店规则数据。
排班任务表
下面是排班任务表的部分字段的详细解释
- 时间段长:本系统将时间离散化成M段,时间段长表示每一段的时间长度(单位:分钟),时间段长越小,模型精度越高,求解难度越大,求解时间越长
- 班次时长因子:约束了班次时长必须是M 倍时间段长的整数倍,其中 M就是班次时长因子。例如 M 为2,时间段长为 15,表示班次时长必须为 30 分钟的整数倍
- 排班工作日及其客流量:值样式为
[{"date": "2023/2/1","isNeedWork": true,"passengerFlowVoList": [{"endTime": "0:30","startTime": "0:0","passengerFlow": 22.14121066020128},…]},…
]
date表示日期,isNeedWork表示门店在当天是否需要上班,passengerFlowVoList表示当天的所有客流量。startTime表示时间段的开始时间,endTime表示时间段的结束时间,passengerFlow表示对应时间段的客流量。
- 第二阶段算法参数:当第二阶段算法为启发式算法时,需要设置相应的算法参数。参数值样式为{“sa_T”:100,“sa_a”:0.1,“sa_timer”:“10000”,“ts_tabuLen”:20,“ts_N”:25,“ts_timer”:2000,“ils_maxLocalSearch-NoLiftCnt”:50,“ils_disturbanceCnt”:5,“ils_groupCnt”:10,“ils_timer”:2000,“alns_T”:100,“alns_a”:0.1,“alns_ro”:0.6,“alns_N”:25,“alns_tabuLen”:20,“alns_score1”:1.5,“alns_score2”:1.2,“alns_score3”:0.8,“alns_score4”:0.1,“alns_timer”:2000,“aga_popSize”:20,“aga_mutationRateBoundArr”:[0.4,0.6],“aga_crossoverRateBoundArr”:[0.9,0.98],“aga_timer”:2000,“vns_timer”:0},具体参数所代表的意义可以参考算法模块的介绍。
- 任务类型:值样式为0或1。0表示真实任务、1表示虚拟任务。因为系统开发了单个任务的多算法计算功能,为了存储每种算法组合的计算结果,需要将克隆真实任务(即创建虚拟任务)来进行任务参数存储、任务结果存储。
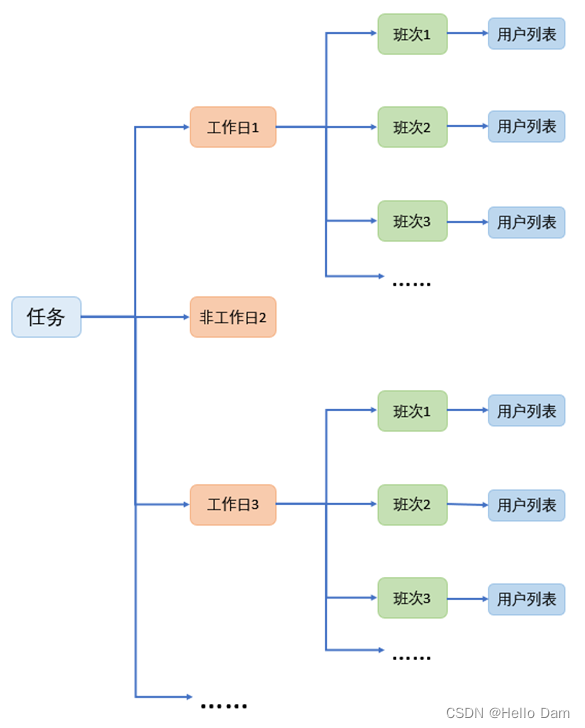
排班结果存储
本系统对排班结果的存储结构如下图
scheduling_date排班日表
scheduling_shift排班班次表
shift_user班次员工中间表
定时通知表
为了更好地辅助门店管理员进行管理,减少门店管理员的工作负担。本系统使用定时任务的方式来定时给门店内的员工发送工作通知、休假通知。因为每间门店使用定时通知的方式可能会有所不同,例如定时不同,或者发送通知的方式不同,需要对每间门店的定时规则进行存储,因此设计了定时通知表。
用户表
中间表
role_menu角色菜单中间表
user_message用户通知中间表
user_position用户职位中间表
user_role用户角色中间表
索引设计
为了尽可能减少对整张表进行扫描的次数,通常需要为字段添加索引,因为添加索引之后使用的数据结构为B+树,B+树的结构非常适合在有序数据中进行快速查找,且B+树能更好地利用磁盘块的存储空间。
一般来说,通过为查询频率高、数据量大的字段设置索引可以提高查询效率、加快查询速度。但是过度使用索引会带来一些负面影响。比如,索引会占用更多存储空间。而且,在更新或者插入数据的时候,因此需要更新索引,会消耗更多的时间。
建议设置索引的字段
- 经常需要搜索的字段
- 主键 (创建表的时候会默认设置)
- 经常用在连接的字段,这些字段通常是外键
- 经常需要根据范围进行搜索的字段
- 经常需要排序的字段
- 经常需要在where子句上使用的字段
- 经常需要用于进行统计的字段
不建议设置索引的字段
- 查询中很少用到的字段
- 只具有很少数据值的字段,如性别
- 数据量相当大的字段,如text类型的字段
- 经常需要修改的字段