一、
一些基础术语:
util是utility的缩写,意思为实用工具。一般用于描述和业务逻辑没有关系的数据处理分析工具。
logger :日志
meter : 记录表
使用下划线 _ 表示不需要的变量是一种常见的开发者的约定,(Python 解释器本身对下划线并没有特殊处理,它不会自动忽略赋值给下划线的值或在未使用的情况下跳过它。下划线只是一个普通的变量名,与其他变量名没有区别。)
二、
N = len(trainloader.dataset),其中trainloader.dataset表示数据加载器所加载的数据集对象。这将返回训练数据集中的样本数量。
每次从trainloader中获取的是一个批次(batch)的数据。B = len(trainloader)返回的是trainloader中批次的数量,也就是数据集被分成了多少个批次。这个值可以用于迭代训练数据集,或者用于确定训练的总步数或迭代次数。
将N(全部数据集)分成B个batch,每次update(compute gradient & optimizer.step() )是update一个batch的参数量,所以这也就说明了为什么每个batch里面要先进行optimizer.zero_grad()。
而一个epoch是指把全部的数据集过了一遍,称为一个epoch
三、
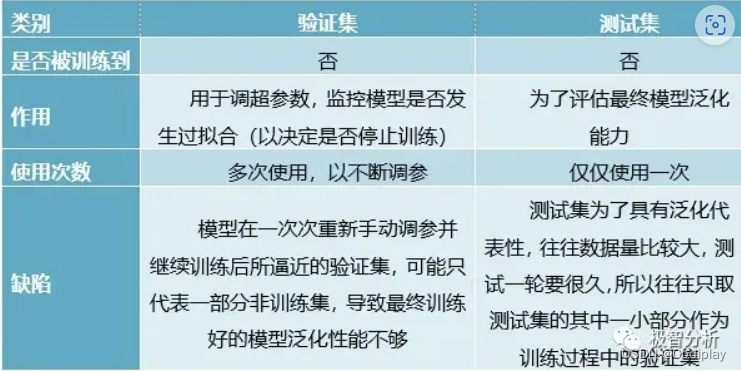
训练集、验证集、测试集的关系:
abbr:train、val、test
(1) 训练集相当于课后的练习题,用于日常的知识巩固。
(2) 验证集相当于周考,用来纠正和强化学到的知识。
(3) 测试集相当于期末考试,用来最终评估学习效果。
大部分时候,没有验证集,为了让测试集有更好的表现,不从训练集中抽取20%作为验证集。
四、
model.eval() 与with torch.no_grad()的配合:
model.eval() 是一种模型状态转换操作,用于将模型切换到评估模式。在评估模式下,模型的行为可能会有所不同,例如,对于某些层(如 Dropout)来说,它们可能会被禁用或修改。评估模式下的模型通常更接近实际应用场景,并用于计算测试集上的指标。
with torch.no_grad() 是一个上下文管理器,用于在代码块中临时关闭梯度计算。在这个代码块内部,所有的操作都不会被跟踪,也不会计算梯度。这对于在测试阶段或者不需要进行反向传播的代码段非常有用,可以提高代码的执行效率。
with torch.no_grad() 控制梯度计算,model.eval() 控制模型的行为模式,二者常常一起使用以确保测试阶段的有效评估。
五、
文件读写f.close() & f.flush()
f.close()关闭文件对象,执行一系列清理操作,使文件对象不再可用。一旦文件被关闭,无法再对其进行读取或写入操作。f.flush()刷新文件缓冲区,确保缓冲区中的数据被写入文件。文件对象仍然保持打开状态,可以继续对其进行读取或写入操作。
为了保险起见,建议在关闭文件对象之前手动调用 f.flush() 来刷新缓冲区,确保所有未写入的数据都被写入文件
通常情况下,在处理完文件操作后,应该调用 f.close() 来关闭文件,释放相关资源。而 f.flush() 则常用于在文件操作过程中手动刷新缓冲区,确保数据写入文件,特别是在需要保证数据实时写入的场景下。
虽然最后Python 解释器会在程序执行结束时自动关闭所有打开的文件对象。这是因为在程序退出时,Python 会清理和释放所有资源,包括打开的文件对象。但为了代码的可维护性和文件的完整性,建议在不再使用文件对象时显式地调用 f.close() 关闭文件。
或者,你也可以使用 with 语句来自动管理文件对象的关闭,它会在代码块执行完毕后自动关闭文件对象
with open('file.txt', 'r') as f:# 进行文件读取操作# 不需要手动关闭文件对象
六、文件& 文件路径操作
1、
如果想创建子目录,必须用参数-p,不然就会认为你的当前要创建的文件夹名字中有/
mkdir -p dir1/dir2/dir3
这将递归地创建 dir1、dir2 和 dir3 目录,无论它们是否已存在。
2、
if not os.path.exists(path) # 对于路径中的 /,它会被视为普通的字符,而不是路径的分隔符os.makedirs()
if not os.path.isdir(path) # 用这一套,会把 / 视为路径逐级创建文件夹os.makedirs()
使用 os.path.isdir() 函数来逐级检查路径中的目录。这样可以确保路径中的每个目录都存在,而不仅仅是最后一个目录或文件
在 os.makedirs 中,斜杠 / 不会被解释为文件夹名字的一部分。它只是用来表示目录结构的层次关系。
3、
下面两个的区别:
a = os.path.join(a, b) # 调用函数
a = a + b # 字符串拼接
二者效果一样,但推荐使用os.path.join,因为它可以正确处理路径分隔符,以适应不同的操作系统。即,你不需要在乎是用\还是/,会根据你操作系统自动给你创建,
4、
“w”:会覆盖之前的文件
“a”:追加
二者在文件不存在的时候都会自动创建文件
with open(file_path, 'a') as file:if file.tell() != 0:file.write('\n') # 写入空行file.write(data) # 追加数据
file.tell() 方法用于获取当前文件指针的位置。如果文件指针位置为 0,表示文件为空
七、
几个参数:
- batch_size 你自己设置的一个batch的数量
labels.size(0)等价于len(labels),它表示理想情况下一个批次中的样本数量。一个批次中的样本数量不一定等于batch_size,因为可能有整除不了的情况。- total += labels.size(0) 这样获得的是精确的样本的数量。
len(trainloader)是一共有多少个batch
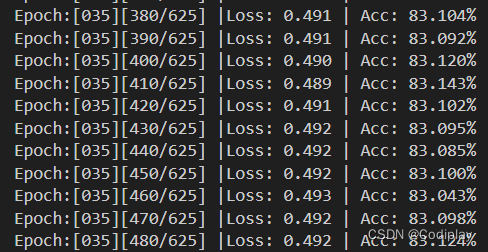
第35 / 200(epoch)轮:选的batch_size=64,所以一个dataset划分为642(len(trainloader))个小的batch
一个epoch下来要把整个dataset跑一遍,不过最小单位是batch
total += labels.size(0)
用于累积所有批次中的样本数量。通过每个批次的样本数量相加,可以得到总样本数量。
八、
1、准确率计算
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
# correct += (predicted == labels).sum()
outputs 是模型的输出,通常是一个张量,其形状为 [batch_size, num_classes],其中 batch_size 是当前批次的大小,num_classes 是分类的类别数。
torch.max(outputs.data, 1) 是一个函数调用,它对 outputs.data 张量沿着指定的维度进行最大值的计算。第二个参数 1 表示沿着第二个维度(即列维度,即num_classes!)进行计算。
返回:
第一个张量是最大值的张量,不需要使用,用 ‘_’ 忽略
第二个张量是最大值的索引张量,表示每个样本在输出类别上的最大值的索引。它是一个形状为 [batch_size] 的张量(一维张量same as labels,一共有bs个样本,就有bs个最大值),其中每个元素表示相应样本的预测类别。
total += labels.size(0)total 的作用是跟踪训练过程中已处理的样本总数,用于(实时args.print_freq)计算训练准确率,它是根据每个批次中处理的样本数进行累加的,因此它不等于数据集的总样本数量。
correct += predicted.eq(labels.data).cpu().sum() 将预测结果与真实标签进行逐元素比较,返回一个布尔张量(最简单的一维数组,size:(batch_size,) ),其中相等的位置为 True,不相等的位置为 False。(将布尔张量转移到 CPU 上,因为默认情况下模型和数据可能在 GPU 上。)sum()计算布尔张量中 True 的数量,也就是预测正确的样本数量(scalar标量)。
最后,将预测正确的样本数量累加到 correct 中,以便在训练过程中跟踪正确的样本数量。
2、loss计算
loss = criterion(outputs, labels)
loss.backward()
sum_loss += loss.item()
平均损失的计算是基于每个批次的损失值
def train_one_epoch(args,model,epoch,trainloader,optimizer,criterion,f2):print('\nEpoch: %d' % (epoch + 1))model.train()sum_loss = 0.0correct = 0.0total = 0.0for i, (inputs, labels) in enumerate(tqdm(trainloader), 0): # 1.准备数据length = len(trainloader)if args.cuda == True:inputs, labels = inputs.cuda(), labels.cuda()# 2.前向传播+计算损失outputs = model(inputs)loss = criterion(outputs, labels)# 3.清零梯度反向传播更新参数optimizer.zero_grad()loss.backward()optimizer.step()sum_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += predicted.eq(labels.data).cpu().sum()if i % args.print_freq == 0:f2.write('Epoch:[%03d][%03d/%03d] |Loss: %.03f | Acc: %.3f%%\n'% (epoch + 1, i, length, sum_loss / (i + 1), 100. * correct / total))f2.flush()