b站刘二大人《PyTorch深度学习实践》课程第十讲卷积神经网络(基础篇 + 高级篇)笔记与代码:
https://www.bilibili.com/video/BV1Y7411d7Ys?p=10&vd_source=b17f113d28933824d753a0915d5e3a90
https://www.bilibili.com/video/BV1Y7411d7Ys?p=11&vd_source=b17f113d28933824d753a0915d5e3a90
一、卷积神经网络(基础篇)
上一讲中MNIST数据集的例子采用的是全连接神经网络(Fully Connected Neural Nerwork)

- 所谓的全连接就是网络中使用的全都是线性层,每一个输入节点都要参与到下一层任意一个输出节点的计算上
Convolutional Neural Network:
-
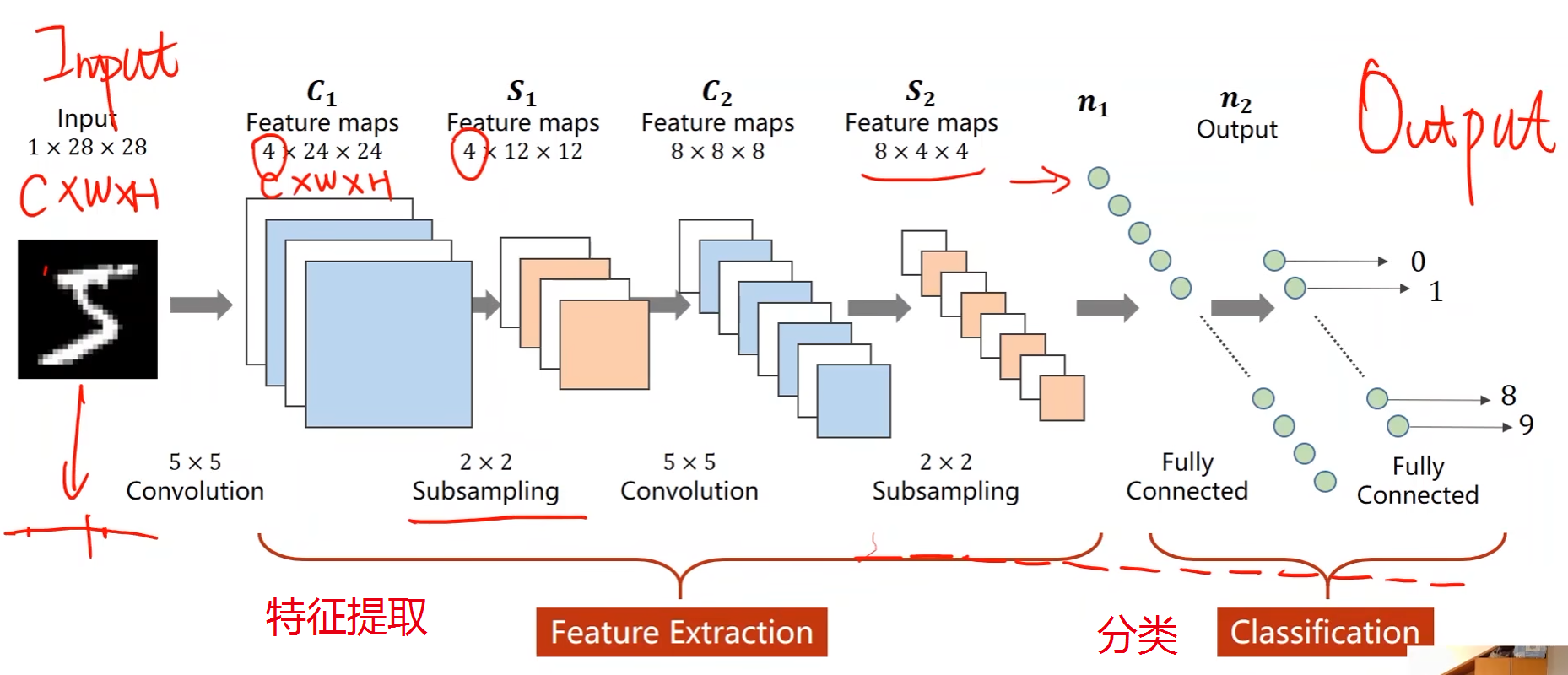
卷积神经网络可保存图像原本的空间结构,从而保留原始的空间信息
-
下采样(Subsampling)操作不改变通道数,宽高会减小
-
卷积 + 下采样 -> 特征提取;全连接层 -> 分类
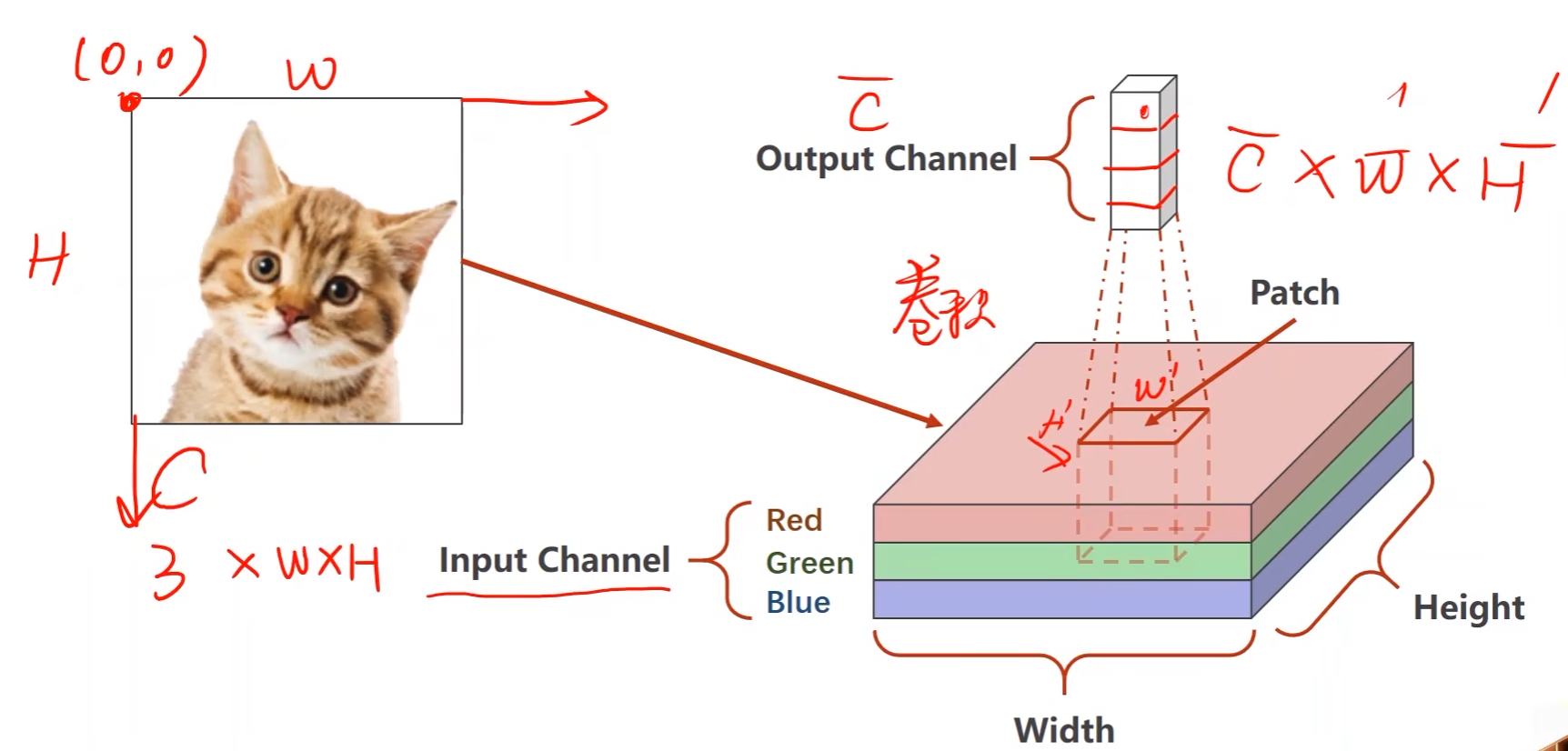
- RGB是三个通道
- patch取了3个通道
- 图像原点在左上角
- 卷积之后通道、宽和高都可变
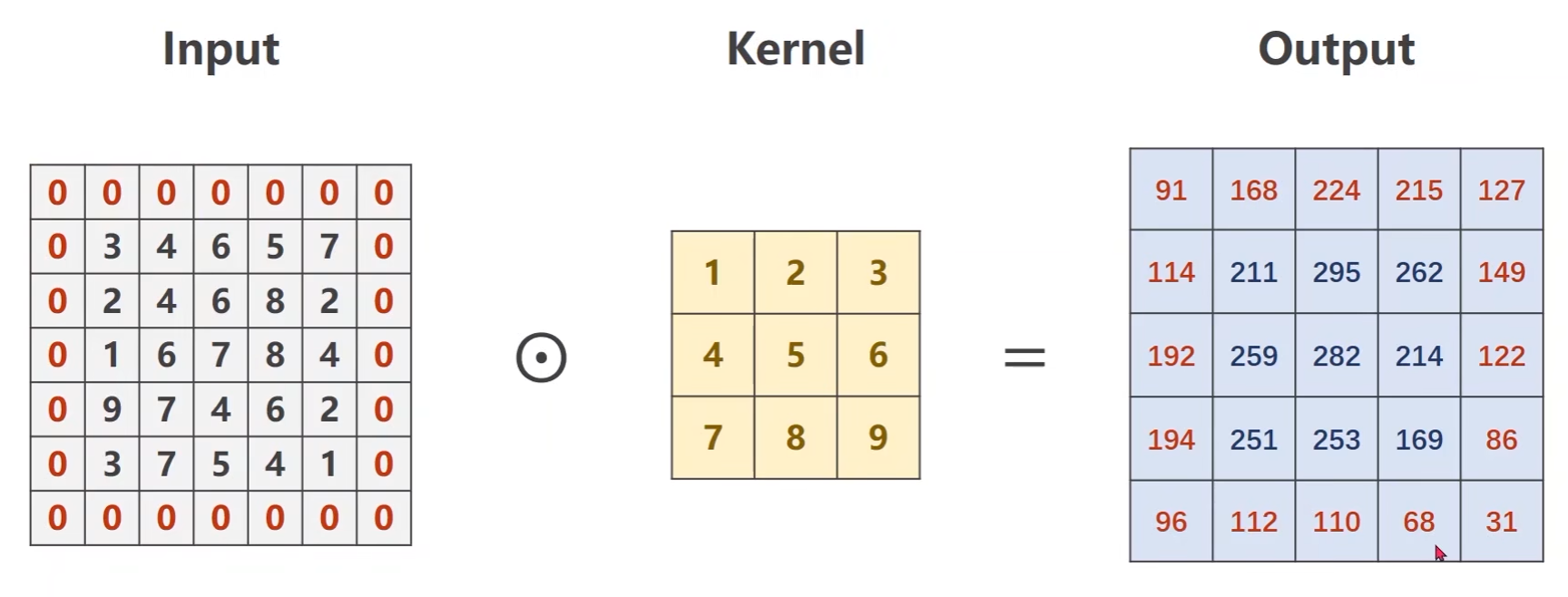
卷积的运算过程:
-
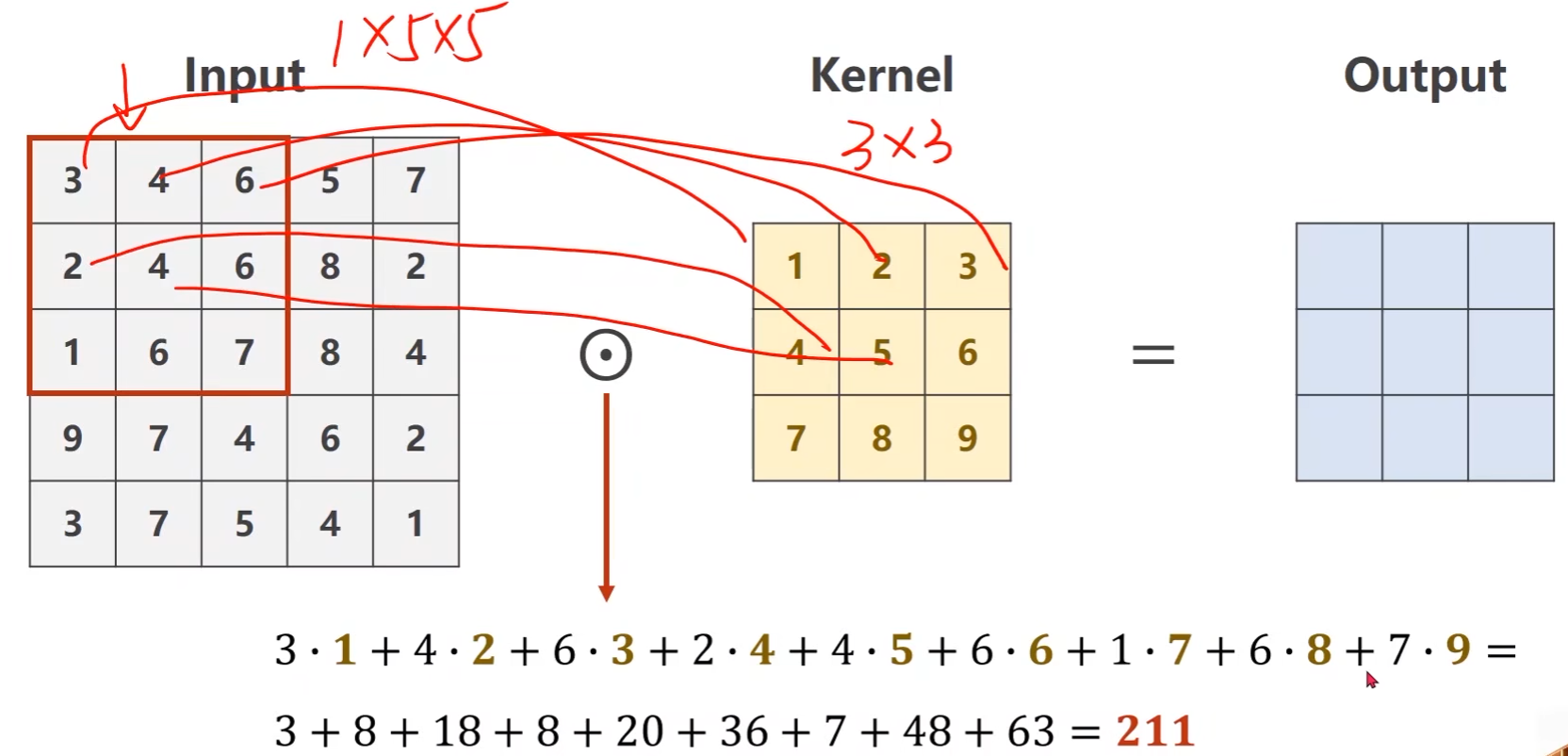
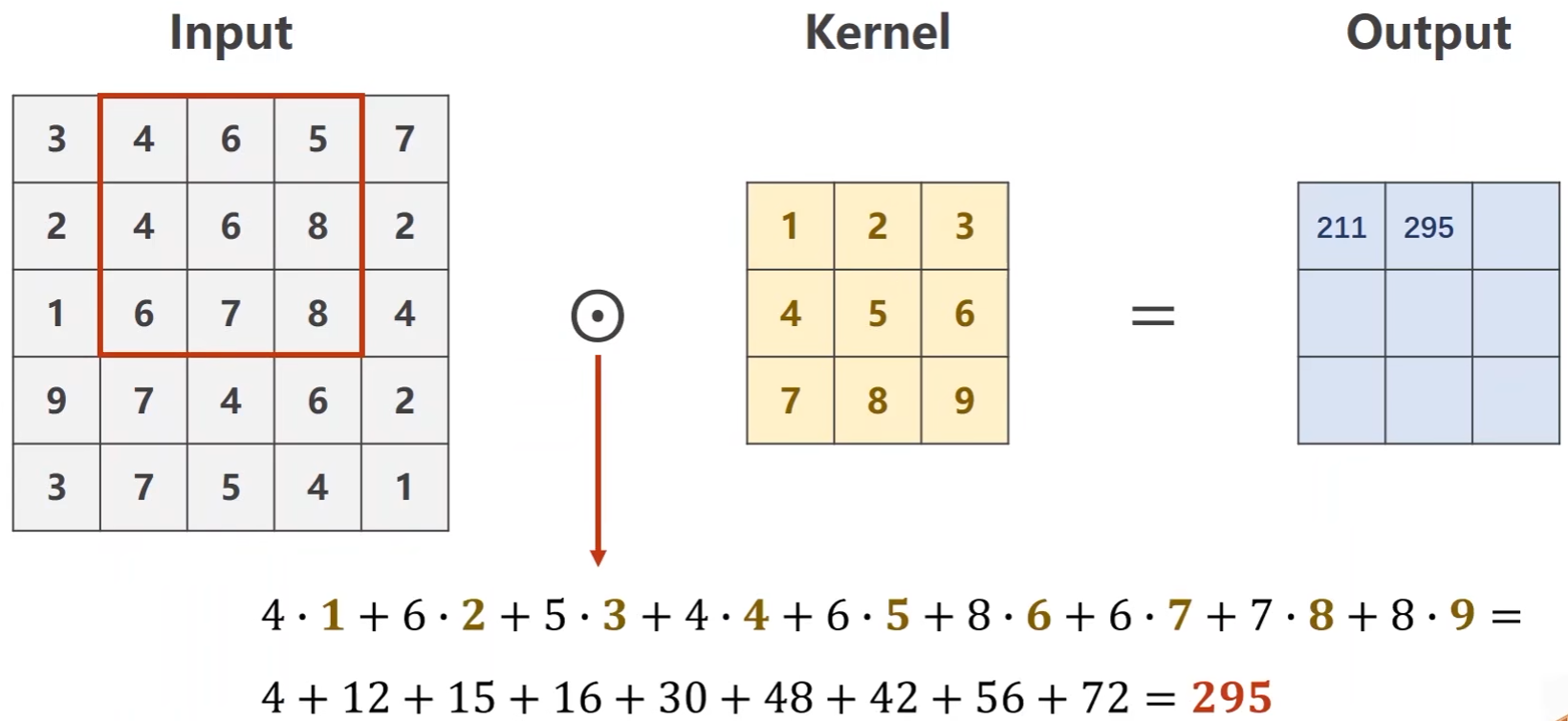
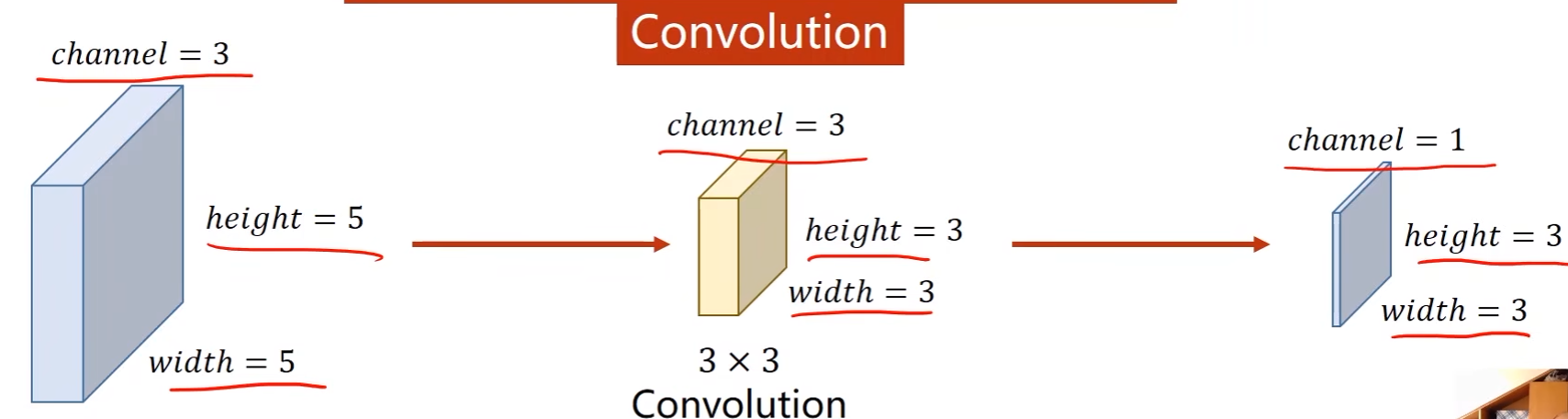
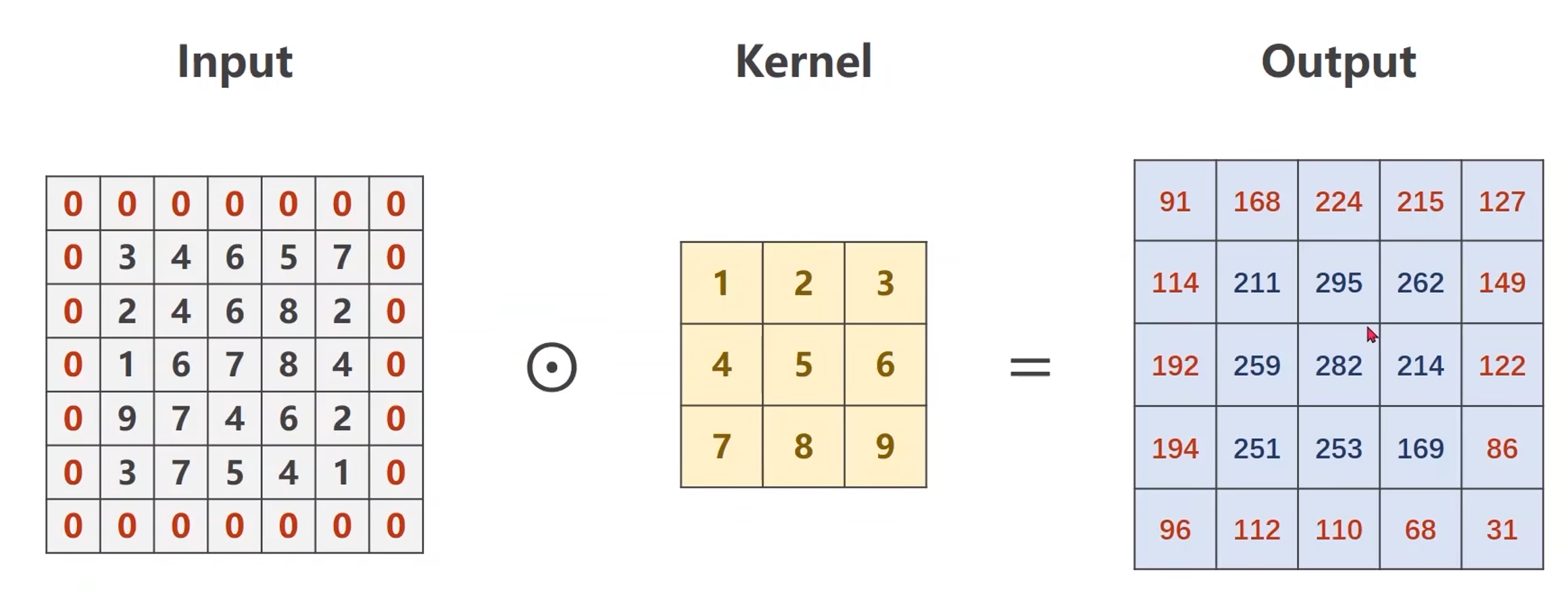
例子:输入是一个单通道的1 * 5 * 5的图像,卷积核是 3 * 3的
-
卷积核现在输入中画出一个3*3的区域,然后做数乘,将结果输出
-
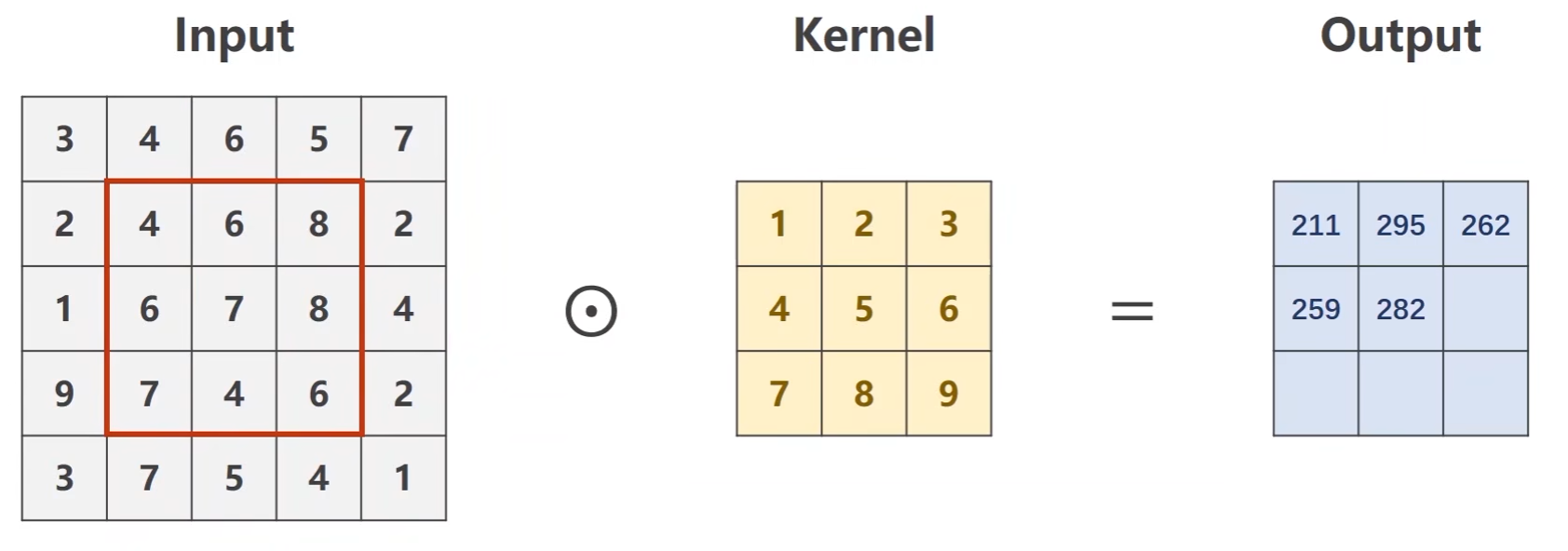
然后将块往右移一格,输入与卷积核做数乘求和
-
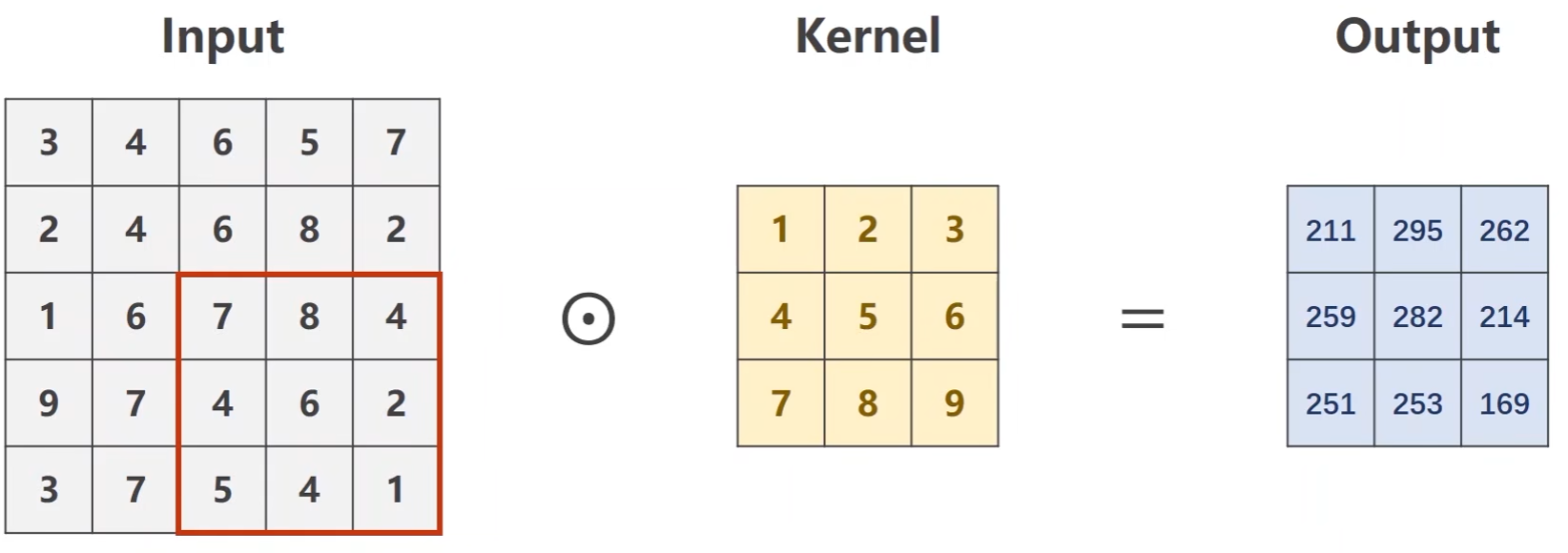
以此往复,直至遍历完整个图像
-
-
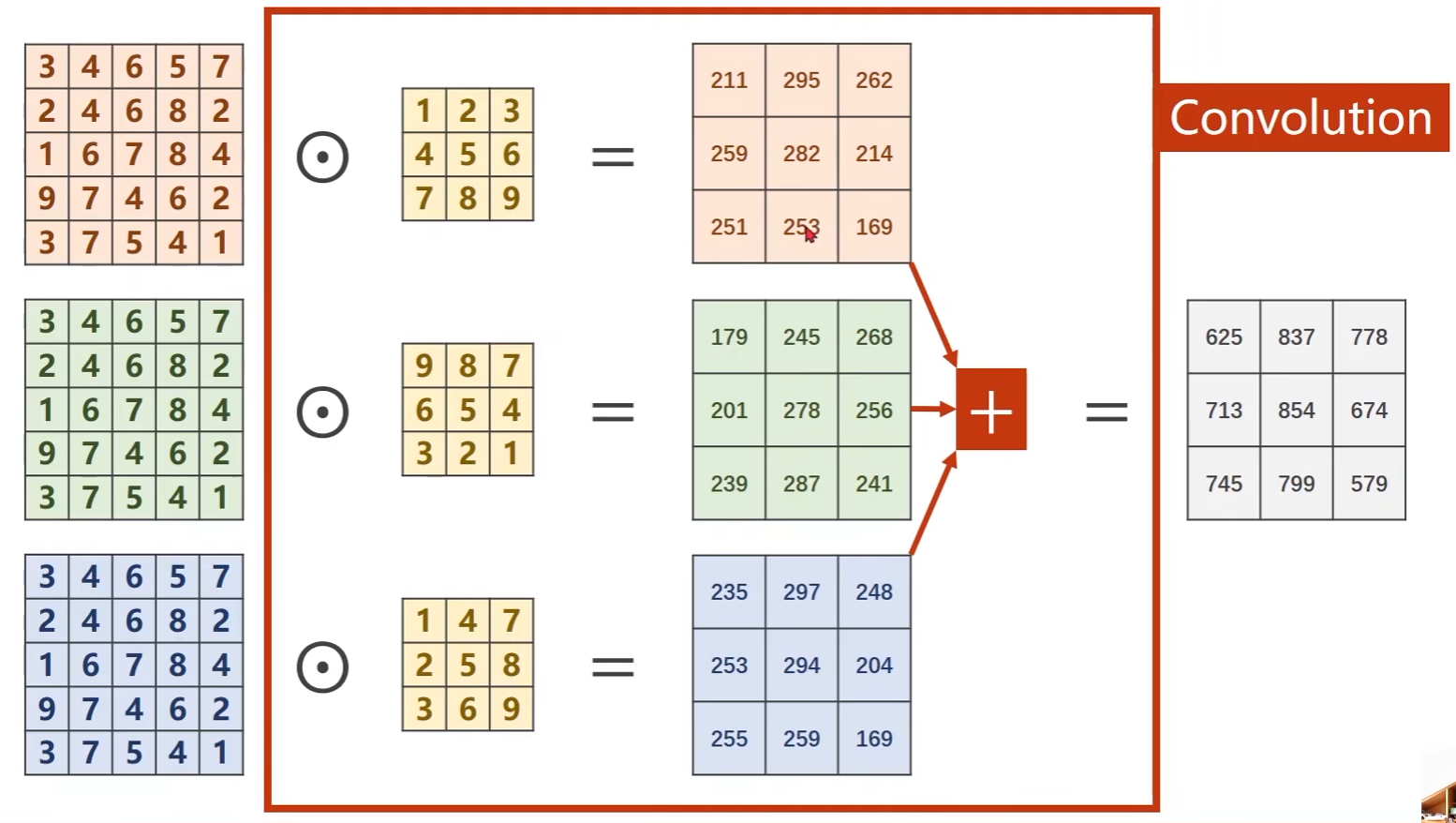
上述例子是单通道的,但实际中常见到的是多通道的
-
以3通道为例子,每个通道都要配一个卷积核
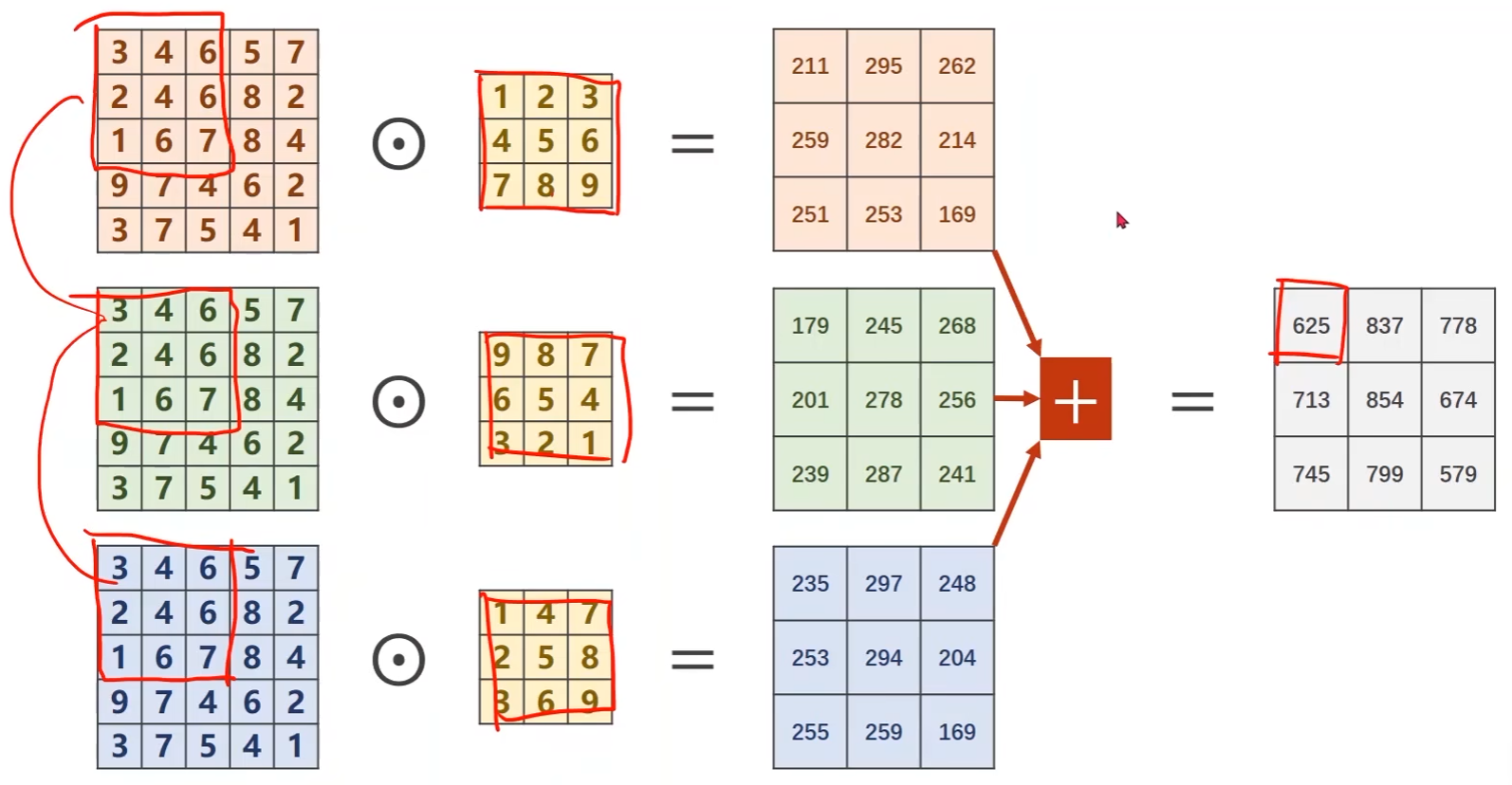
-
每个通道和一个核做卷积,然后将卷积的结果进行相加
-
-
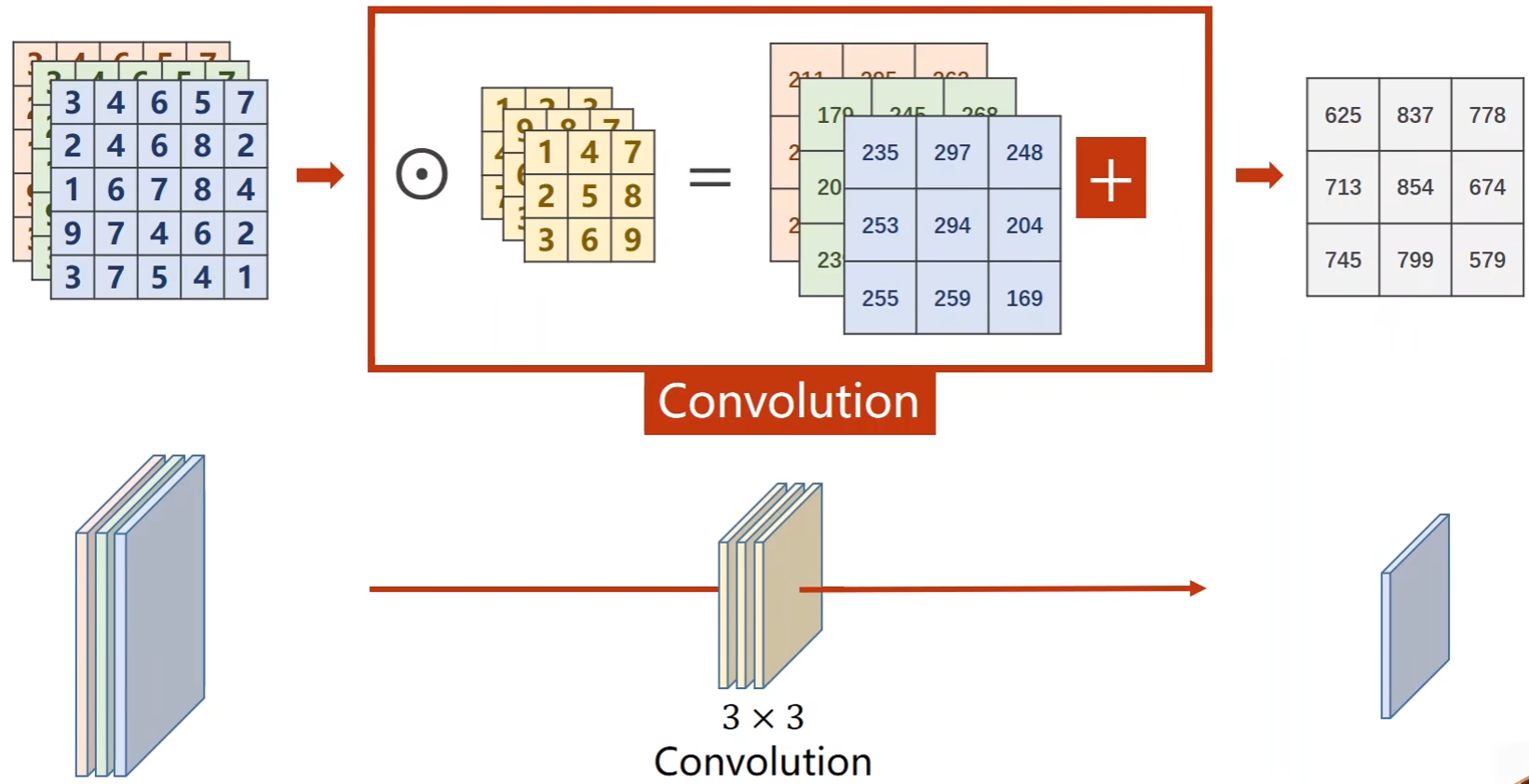
N通道:
- N个通道,M个输出:
- 一个卷积核得到一个通道,那么M个卷积核就能得到M个输出,然后再将M个输出拼接起来
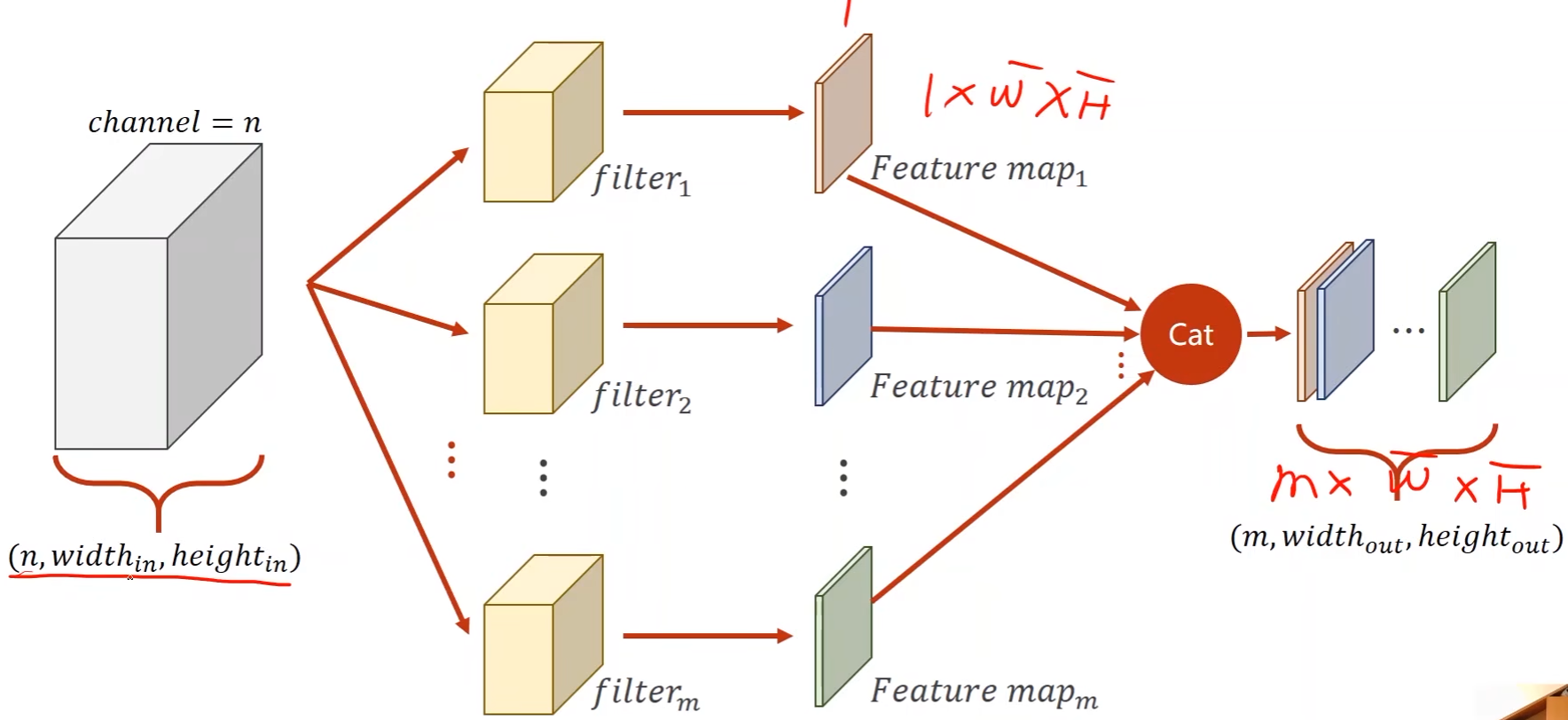
- N个通道,M个输出:
-
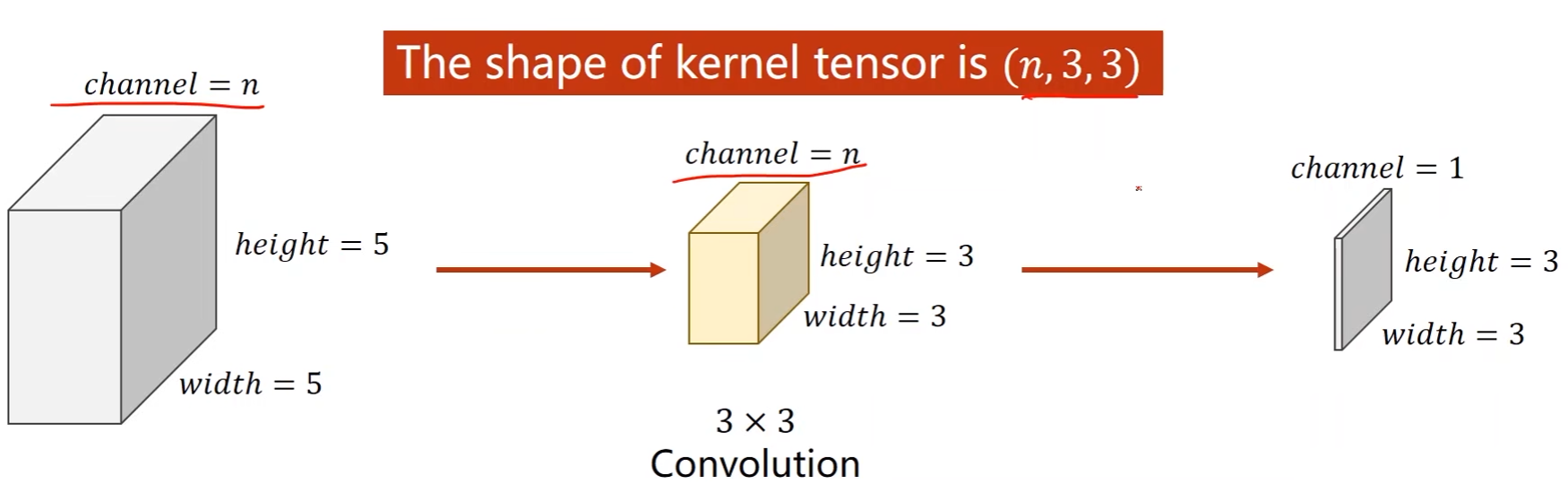
每一个卷积核的通道数和输入通道数一致,卷积核的总个数和输出通道数一致

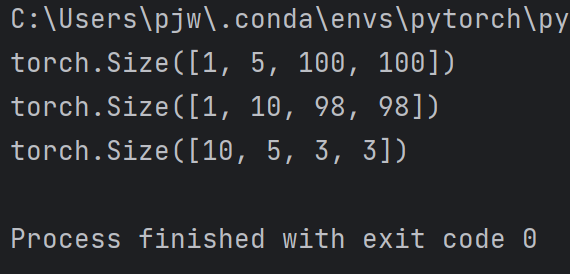
卷积层代码:

import torch
in_channels, out_channels = 5, 10 # 输入通道n,输出通道m
width, height = 100, 100 # 图像的宽和高
kernel_size = 3 # 卷积核大小
batch_size = 1 # pytorch中所有的输入数据必须是小批量的# 生成输入数据,这里是随便取一个随机数
input = torch.randn(batch_size,in_channels,width,height)# 创建卷积层
conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size)# 得到卷积输出
output = conv_layer(input)print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
卷积层中的几个重要参数:
-
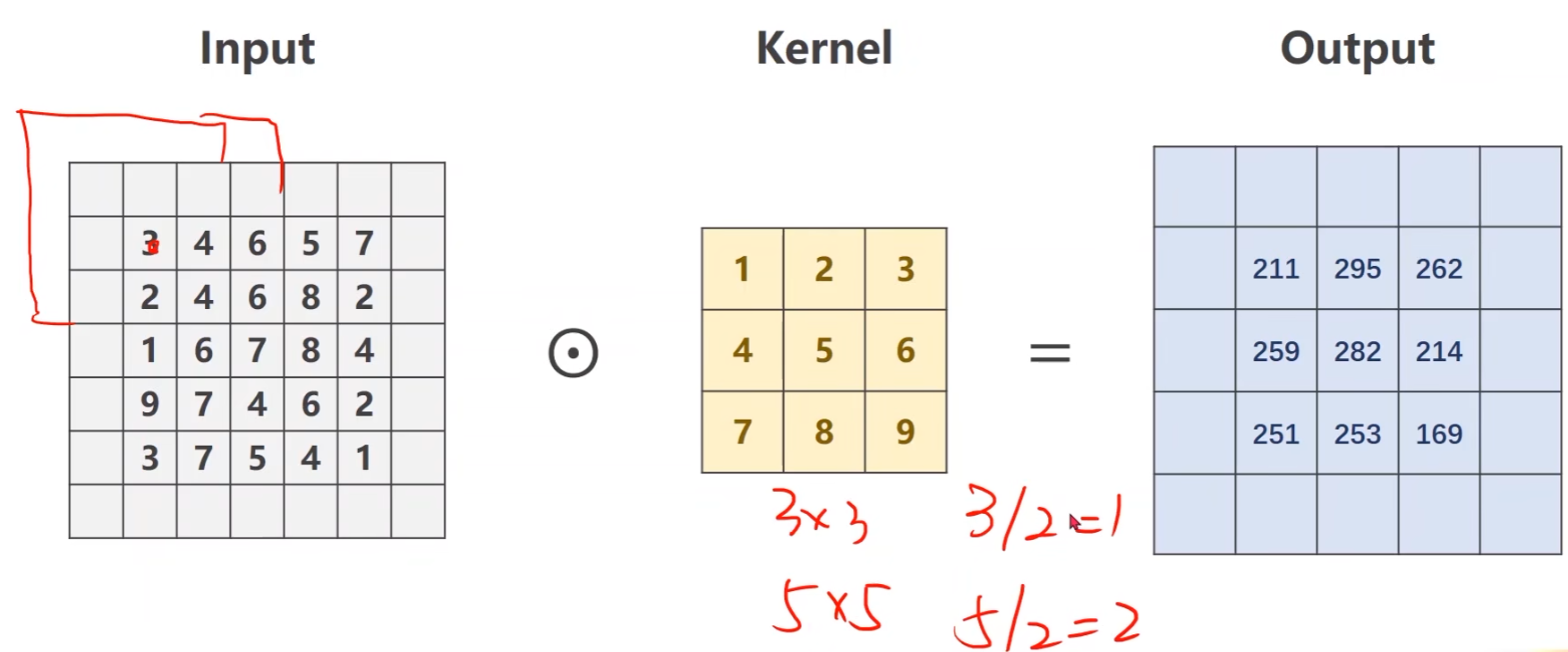
填充padding
-
想要输出的图像宽高保持不变,那么可以对输入进行填充0
-
例如padding = 1
import torch# 输入图像 input = [3, 4, 6, 5, 7,2, 4, 6, 8, 2,1, 6, 7, 8, 4,9, 7, 4, 6, 2,3, 7, 5, 4, 1] # 将输入转成张量 input = torch.Tensor(input).view(1, 1, 5, 5) # 四个参数分别对应batch_size,C,W,H# 创建卷积层 conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)# 创建卷积核 # view用来改变形状,四个参数分别对应输出通道数,输入通道数,宽和高 kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3)# 将卷积核数据赋给卷积层的权重,对卷积层的权重进行初始化 conv_layer.weight.data = kernel.dataoutput = conv_layer(input)print(output)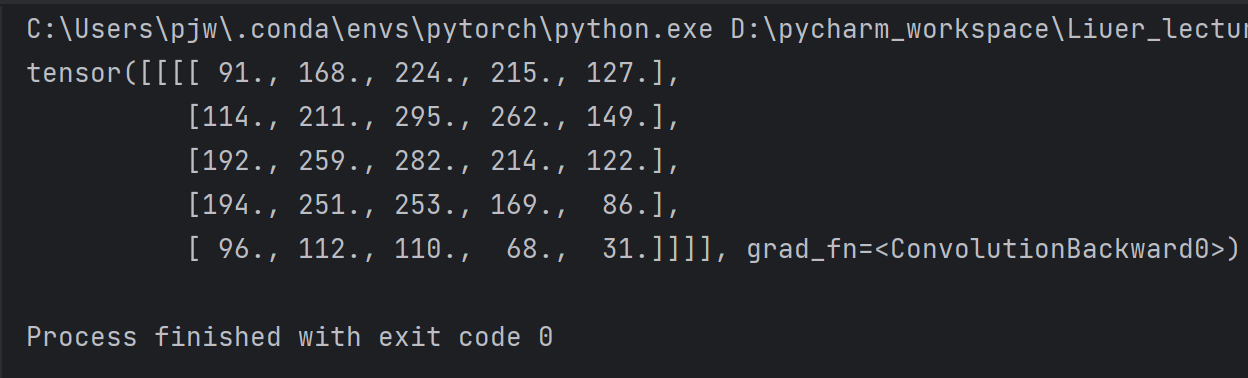
-
-
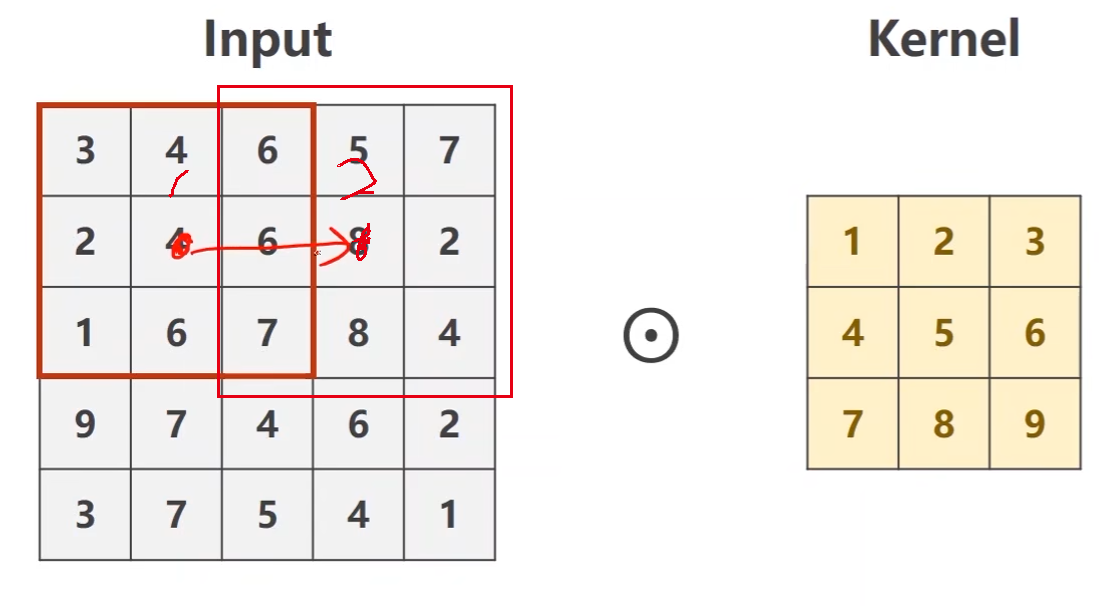
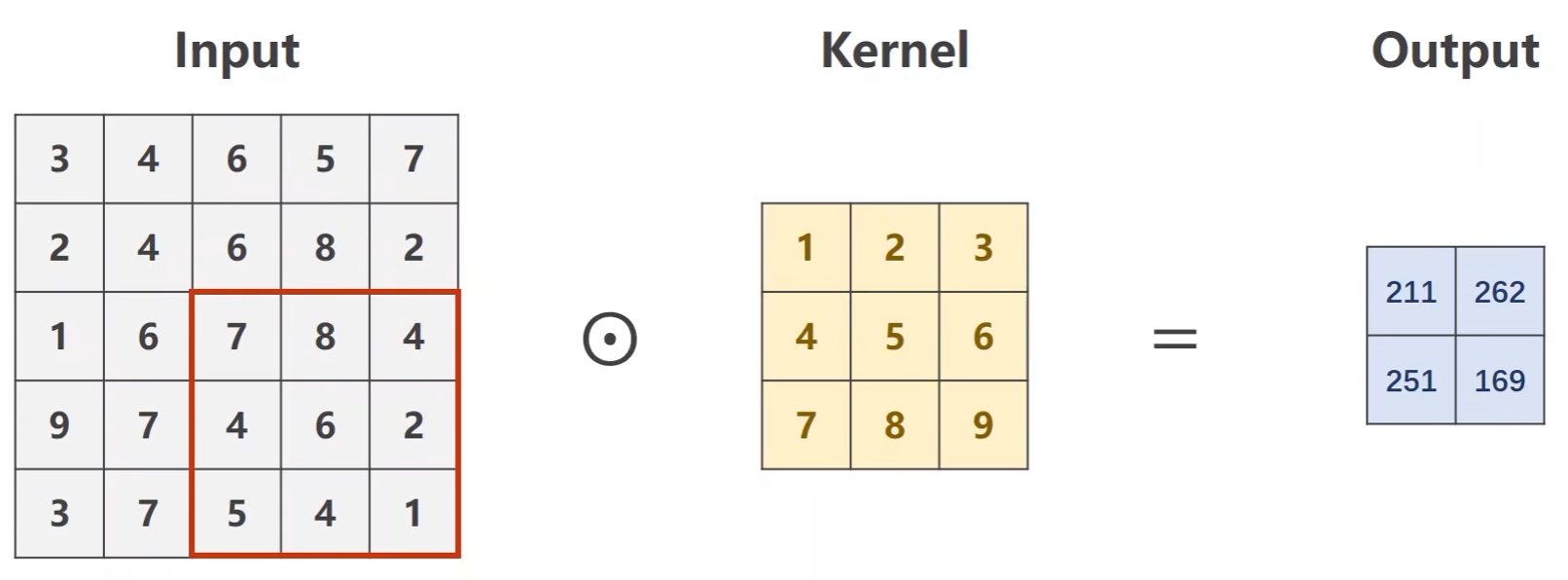
步长stride
-
遍历步长
- 例如stride=2,第一次中心在第二行第二列的4,下一次的中心就直接跳到第二行第四列的8
-
可以有效降低图像的宽度和高度
''' 和前面padding的代码相比,仅在conv_layer = torch.nn.Conv2d()中将padding换成stride ''' import torch# 输入图像 input = [3, 4, 6, 5, 7,2, 4, 6, 8, 2,1, 6, 7, 8, 4,9, 7, 4, 6, 2,3, 7, 5, 4, 1] # 将输入转成张量 input = torch.Tensor(input).view(1, 1, 5, 5) # 四个参数分别对应batch_size,C,W,H# 创建卷积层 conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)# 创建卷积核 # view用来改变形状,四个参数分别对应输出通道数,输入通道数,宽和高 kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3)# 将卷积核数据赋给卷积层的权重,对卷积层的权重进行初始化 conv_layer.weight.data = kernel.dataoutput = conv_layer(input)print(output)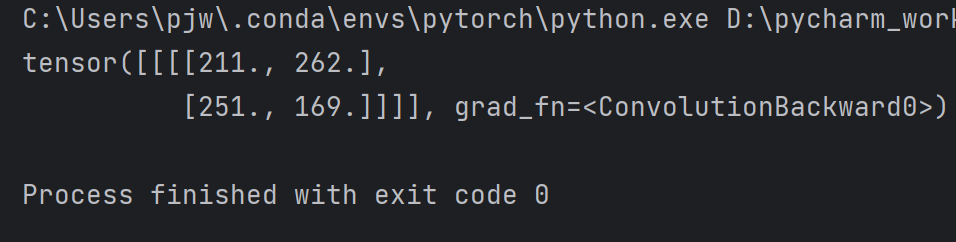
-
下采样 —— 最大池化层(Max Pooling Layer)
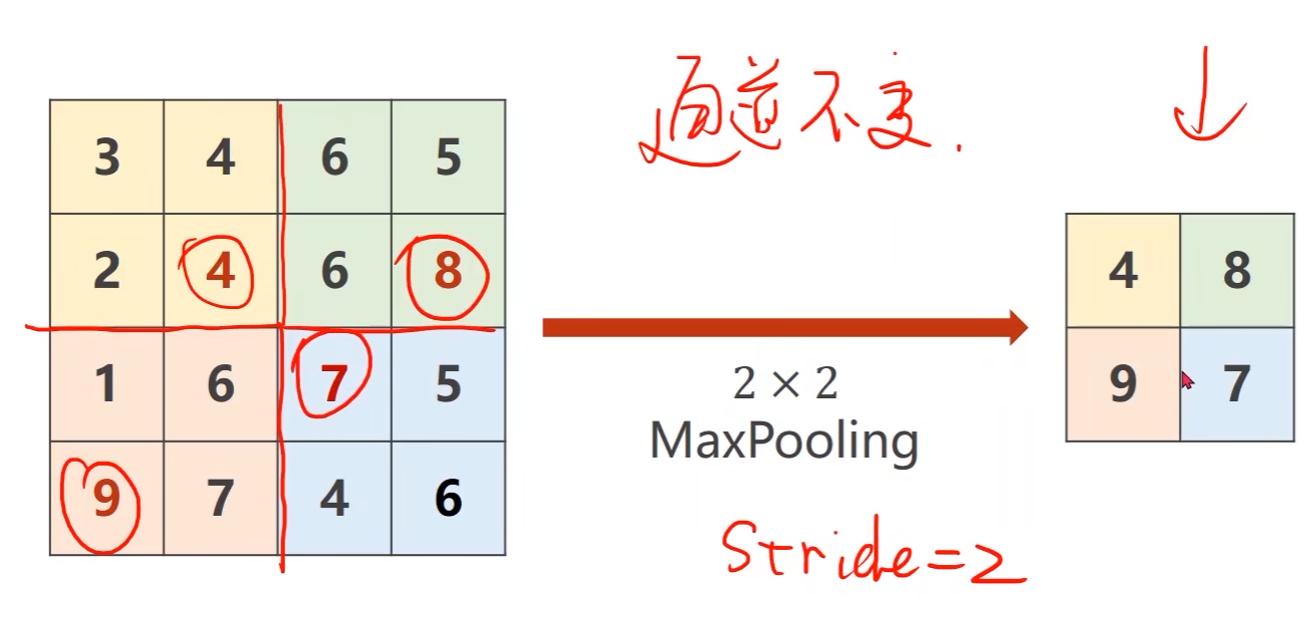
例如使用一个2*2的最大池化层,它默认的stride=2,图像是4*4的
这个池化层会将图像按照2*2一组来分,然后将每组中的最大值提取出来拼成一个2*2的输出
操作是在同一个通道内,通道之间不会,因此通道数不会变
import torch# 输入图像
input = [3, 4, 6, 5,2, 4, 6, 8,1, 6, 7, 8,9, 7, 4, 6]
# 将输入转成张量
input = torch.Tensor(input).view(1, 1, 4, 4) # 四个参数分别对应batch_size,C,W,Hmaxpooling_layer = torch.nn.MaxPool2d(kernel_size=2) # kernel_size被设成2,那么stride会默认为2output = maxpooling_layer(input)print(output)

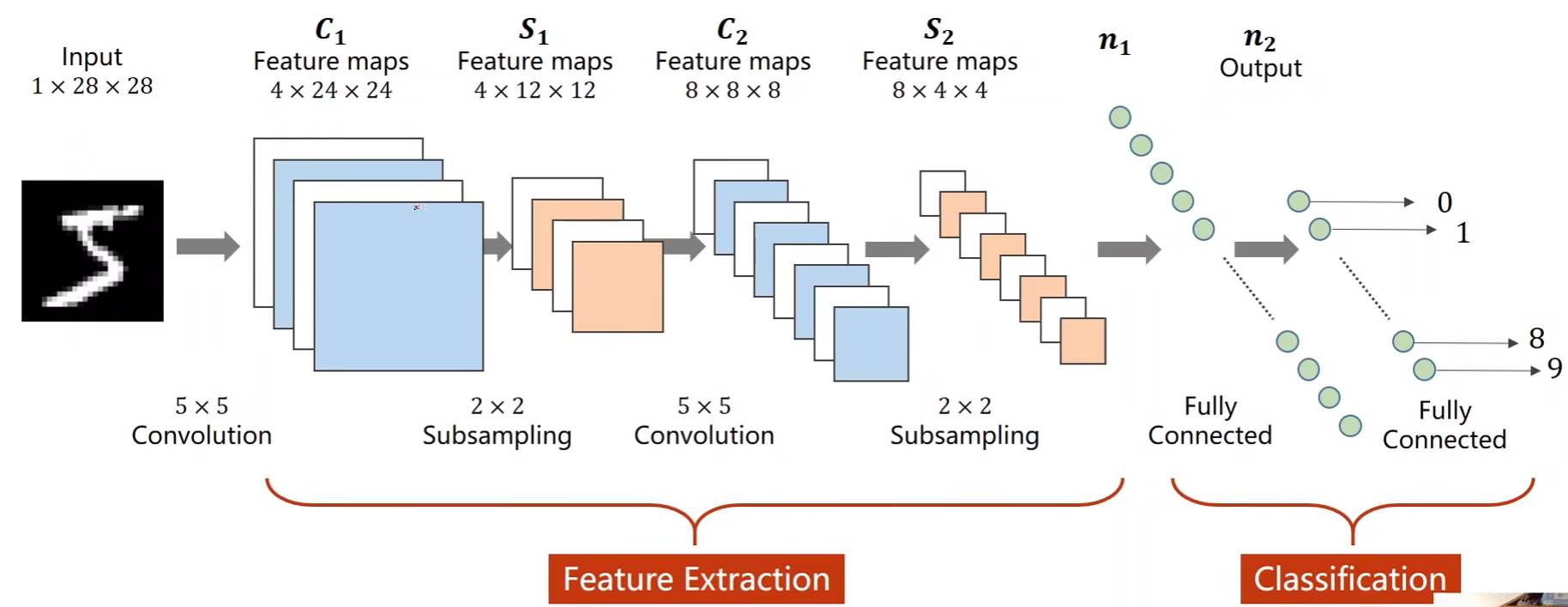
实现一个简单的CNN来处理MNIST数据集:
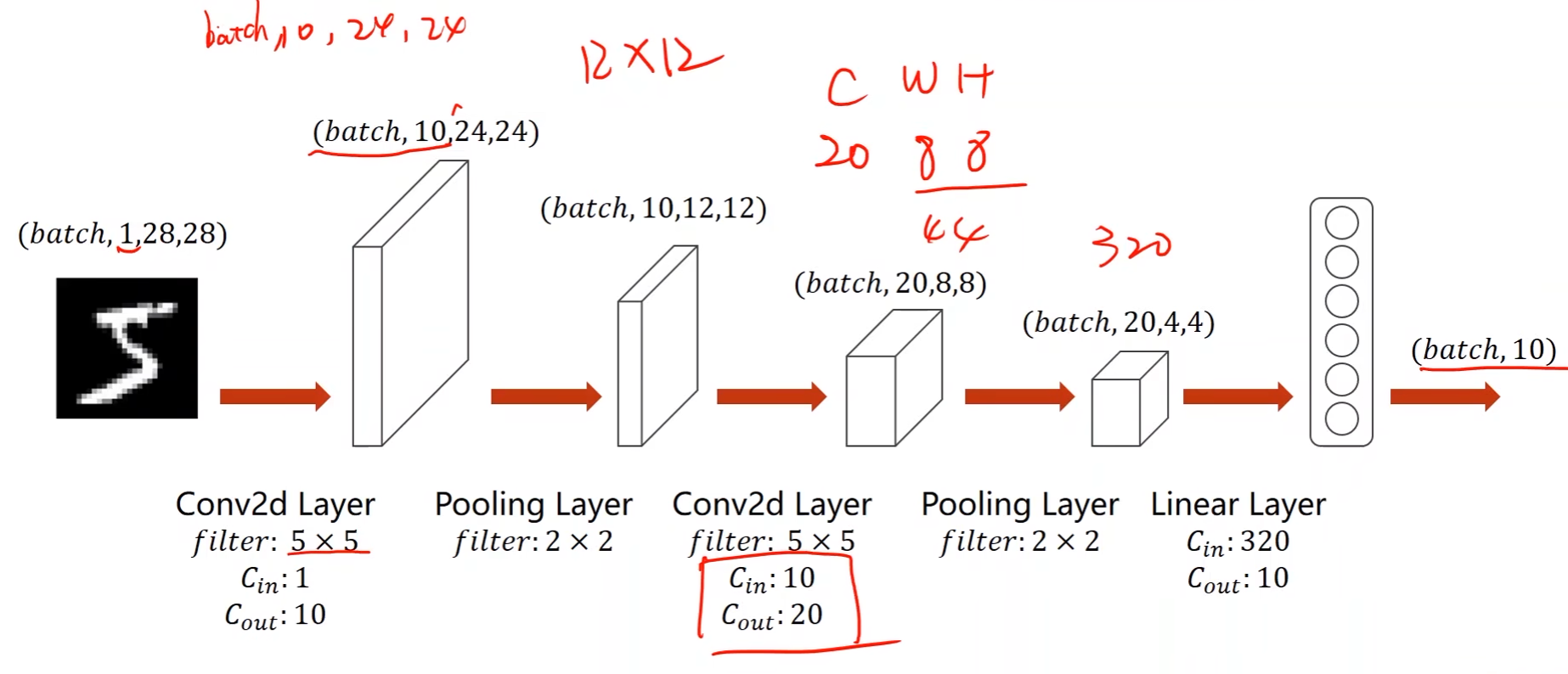
- 第一个卷积层的卷积核是5*5的,输入通道为1,输出通道为10
- 由此可知输出的通道为10,图像大小变成24*24
- 卷积核是5,那么中心就在第三行第三列,这意味着输入图像少了两圈,那就是要减掉4,即24
- 因此参数为(batch_size,10,24,24)
- 由此可知输出的通道为10,图像大小变成24*24
- 上一步输出做一个最大池化,池化层为2*2的
- 最大池化层是2*2的,那么就是对图像按照2*2一组进行划分然后取每组的最大值出来进行拼接
- 上一步输出的图像是24*24的,因此经过池化后就变成了12*12的
- 通道数不影响,即保持不变
- 即(batch_size,10,12,12)
- 接下去再加第二个卷积层,卷积核是5*5的,输入通道为10(和池化层输出通道保持一样),输出通道为20
- 同理得(batch_size,20,8,8)
- 然后再做一个池化层,2*2的
- (batch_size,20,4,4)
- 这一步最大池化处理后一共有320个数据(20*4*4)
- 最后经过一个全连接层将上一步池化层输出的数据映射成一个向量

- 添加了ReLU做非线性激活
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) # 第一个卷积层self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) # 第二个卷积层self.pooling = torch.nn.MaxPool2d(2) # 池化层self.fc = torch.nn.Linear(320, 10) # 线性层def forward(self, x):# Flatten data from (n, 1, 28, 28) to (n, 320)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x))) # 先做卷积,再做池化,最后ReLUx = F.relu(self.pooling(self.conv2(x))) # 第二次x = x.view(batch_size, -1) # 用view将x转成全连接网络所需要的输入形式x = self.fc(x)return xmodel = Net()
完整的代码:
import torch# 构造Dataloader
from torchvision import transforms # 用于对图像进行一些处理
from torchvision import datasets
from torch.utils.data import DataLoaderimport torch.nn.functional as F # 使用更流行的激活函数Relu
import torch.optim as optim # 构造优化器
import matplotlib.pyplot as pltbatch_size = 64# 存储训练轮数以及对应的accuracy用于绘图
epoch_list = []
acc_list = []# Compose的实例化
transform = transforms.Compose([transforms.ToTensor(), # 将PIL图像转成Tensortransforms.Normalize((0.1307, ), (0.3081, )) # 归一化。0.1307是均值,0.3081是标准差
])# 训练集
train_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',train=True,download=True,transform=transform) # 读取到某个数据后就直接进行transform处理
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
# 测试集
test_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(train_dataset,shuffle=False,batch_size=batch_size)class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) # 第一个卷积层self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) # 第二个卷积层self.pooling = torch.nn.MaxPool2d(2) # 池化层self.fc = torch.nn.Linear(320, 10) # 线性层def forward(self, x):# Flatten data from (n, 1, 28, 28) to (n, 320)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x))) # 先做卷积,再做池化,最后ReLUx = F.relu(self.pooling(self.conv2(x))) # 第二次x = x.view(batch_size, -1) # 用view将x转成全连接网络所需要的输入形式x = self.fc(x)return xmodel = Net()criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 带冲量的梯度下降# 一轮训练
def train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = data # inputs输入x,target输出yoptimizer.zero_grad()# forward + backward + updateoutputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item() # loss累加# 每300轮输出一次,减少计算成本if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300))running_loss = 0.0# 测试函数
def test():correct = 0total = 0with torch.no_grad(): # 让后续的代码不计算梯度for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy on test set: %d %%' % (100 * correct / total))acc_list.append(correct / total)if __name__ == '__main__':for epoch in range(10):train(epoch)test()epoch_list.append(epoch)# loss曲线绘制,x轴是epoch,y轴是loss值
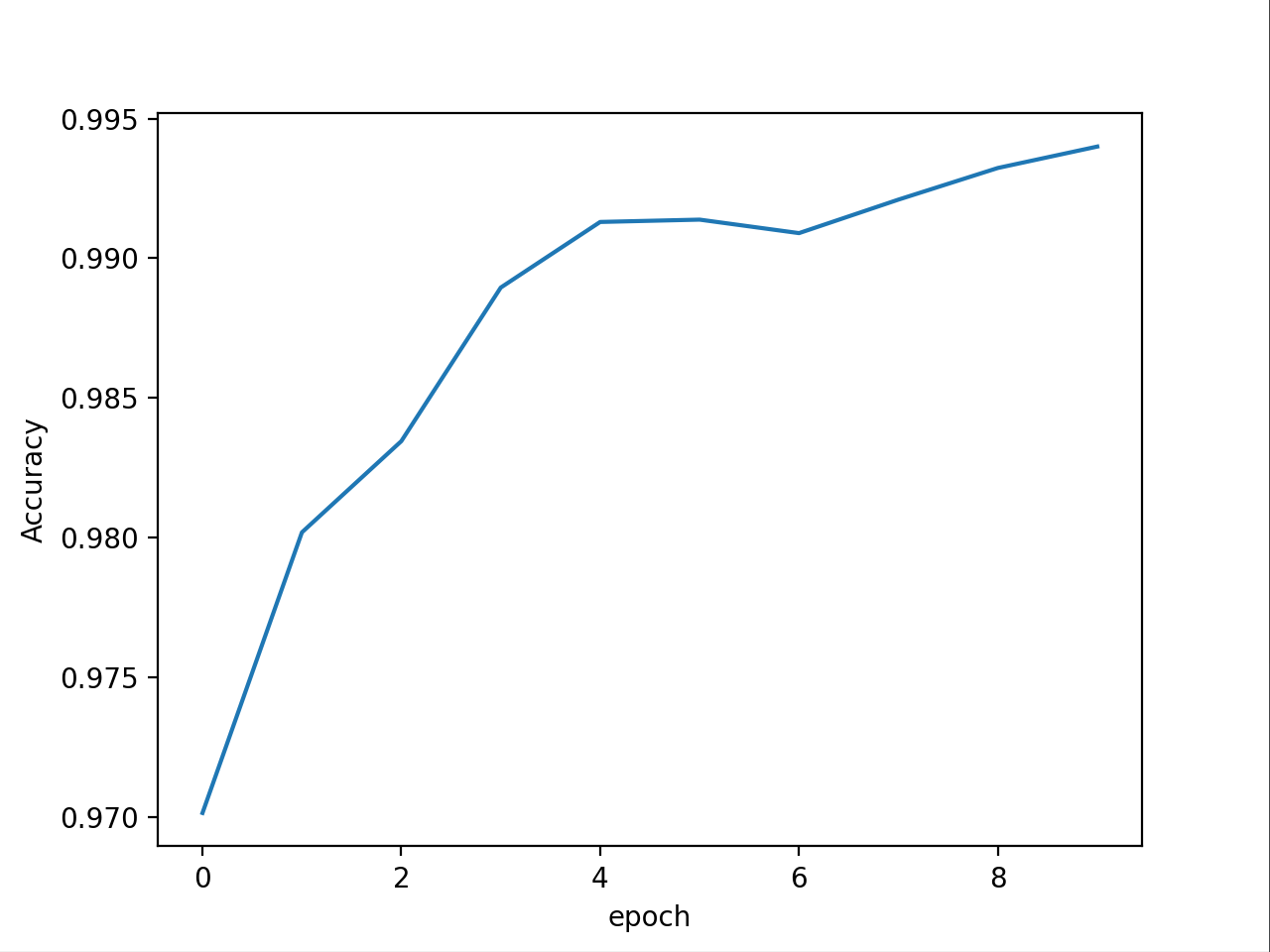
plt.plot(epoch_list, acc_list)
plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.show()
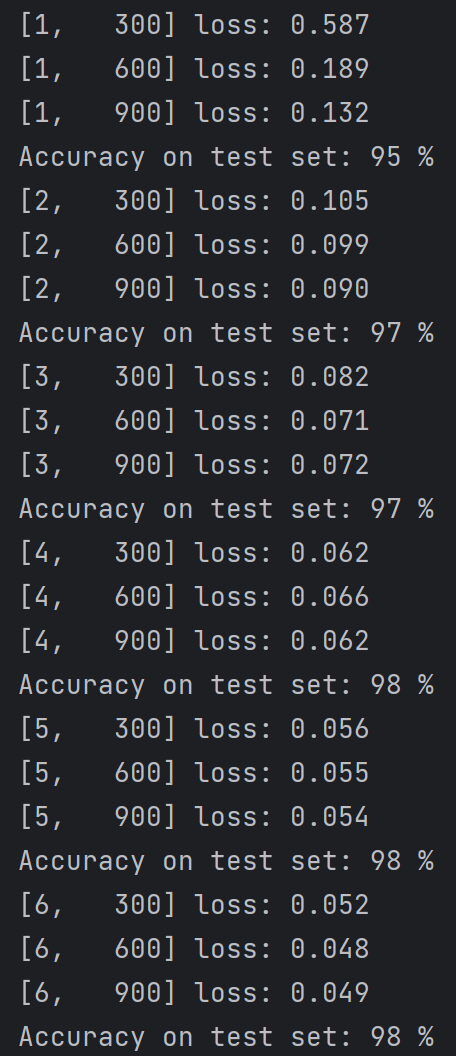
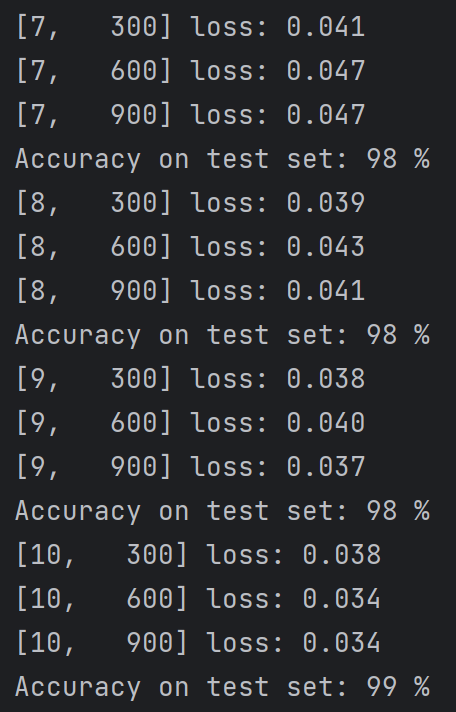
如何使用GPU进行训练:
- Move Model to GPU

# “cuda:0”表示使用第一块GPU
# if - else表达式:
# 如果当前的cuda可用那么torch.cuda.is_available()=true,则使用gpu,不可用即false,则使用cpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 将模型迁移到GPU上
model.to(device)
-
Move Tensor to GPU
-
将用于计算的张量迁移到GPU,注意要在同一块显卡
-
训练的时候:
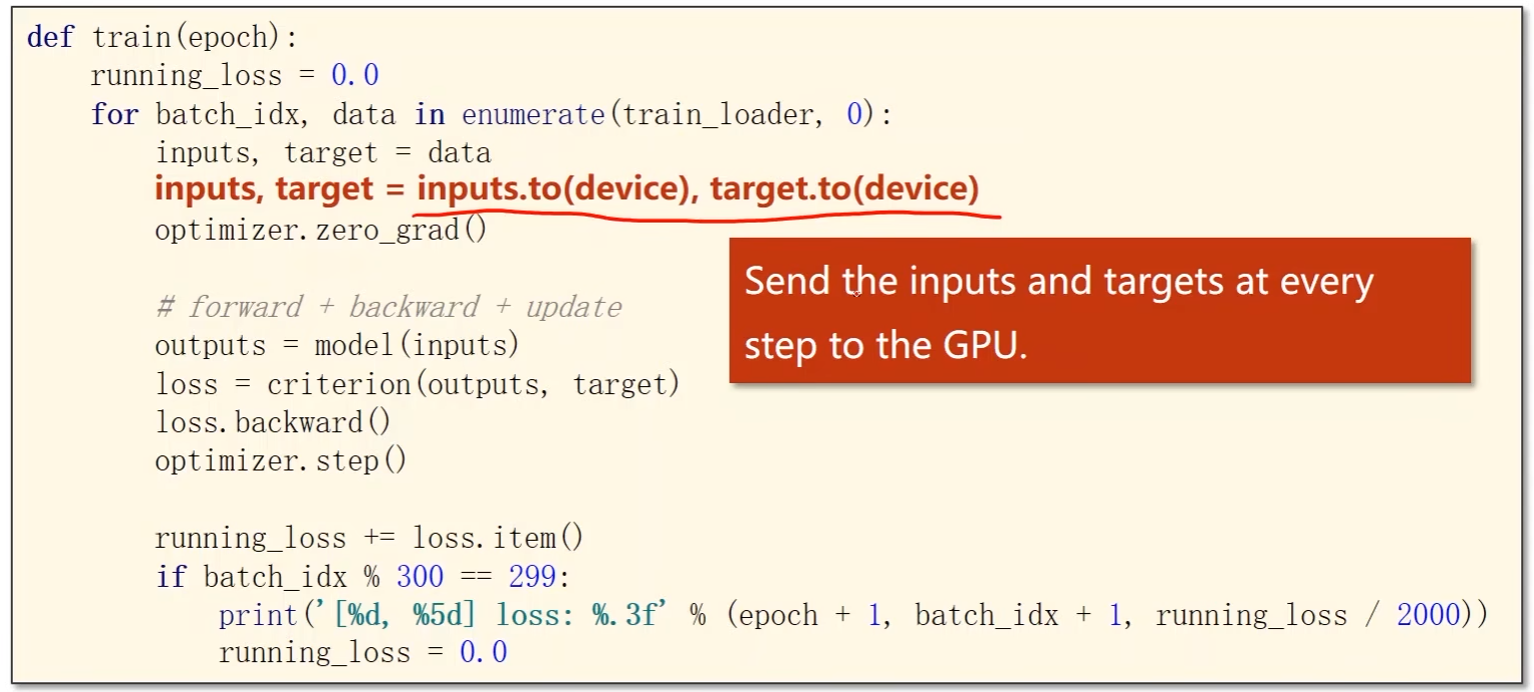
-
测试的时候:

-
-
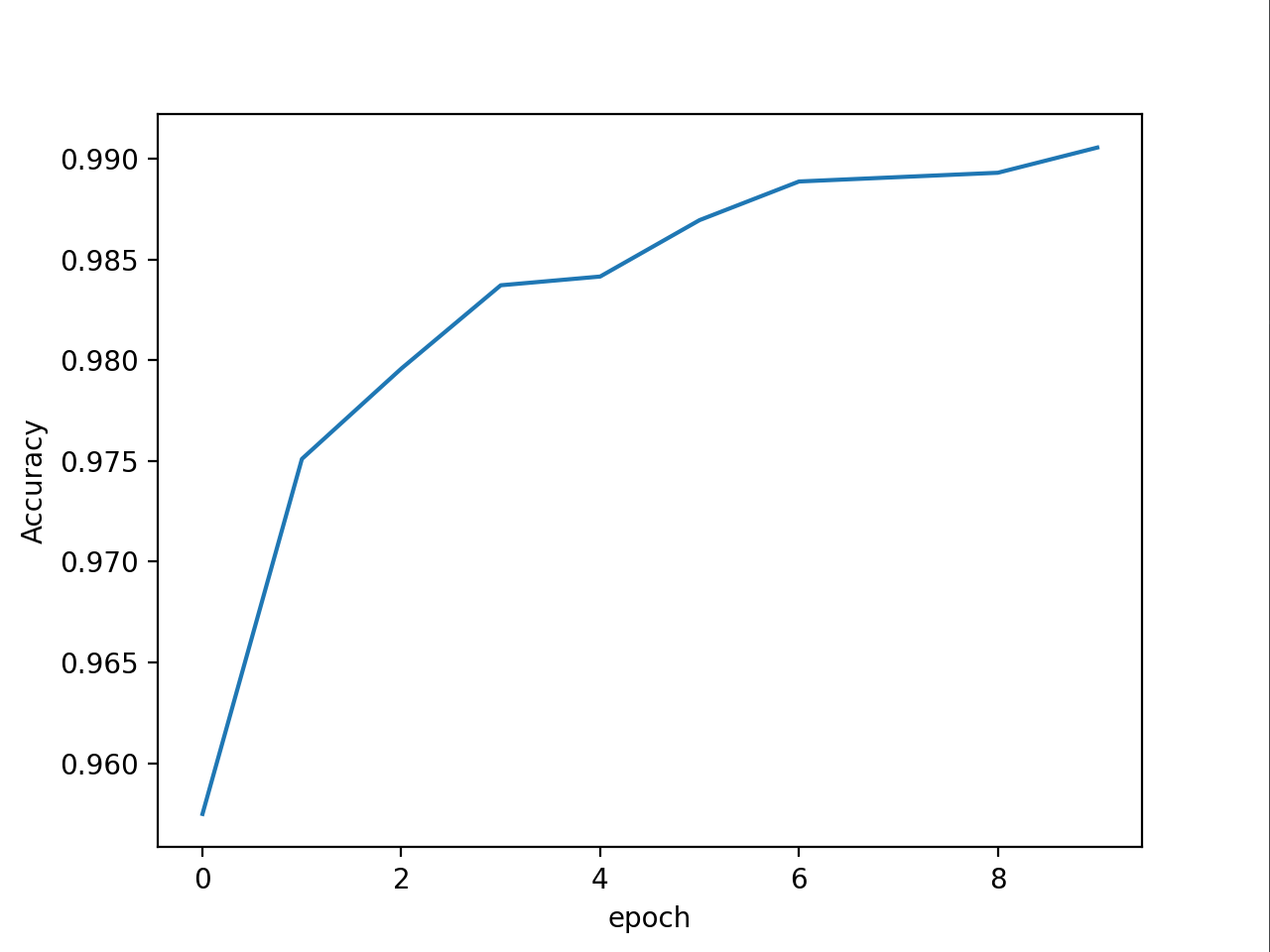
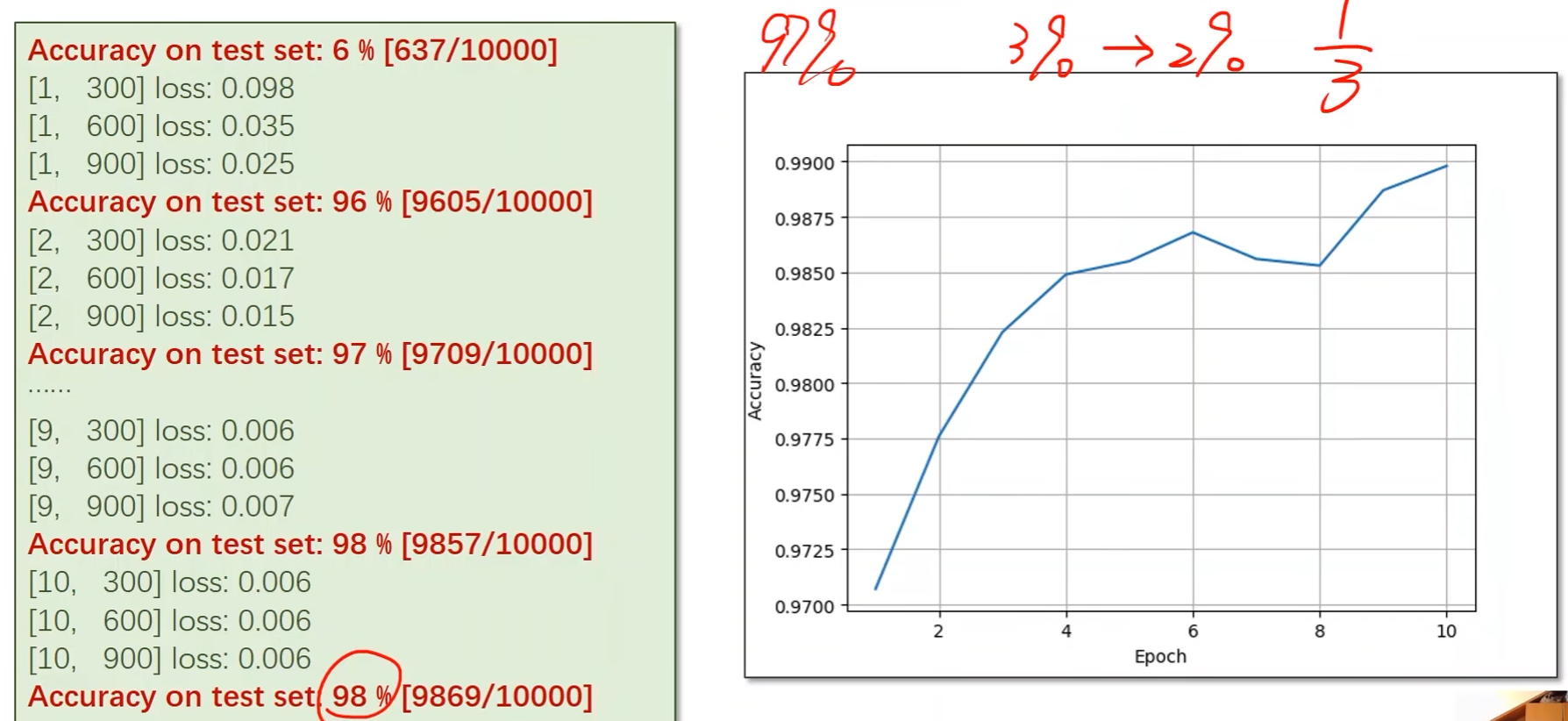
课程中经过10轮训练后准确率从97%提升到98%,从错误率的角度来看是从3%降到了2%,即降低了三分之一
二、卷积神经网络(高级篇)
上一讲中的卷积神经网络以及之前的多层感知机(全连接网络)在结构上都是串行的
- 即上一层的输出是这一层的输入,这一层的输出是下一层的输入
在卷积神经网络中还有更复杂的结构
GoogLeNet:
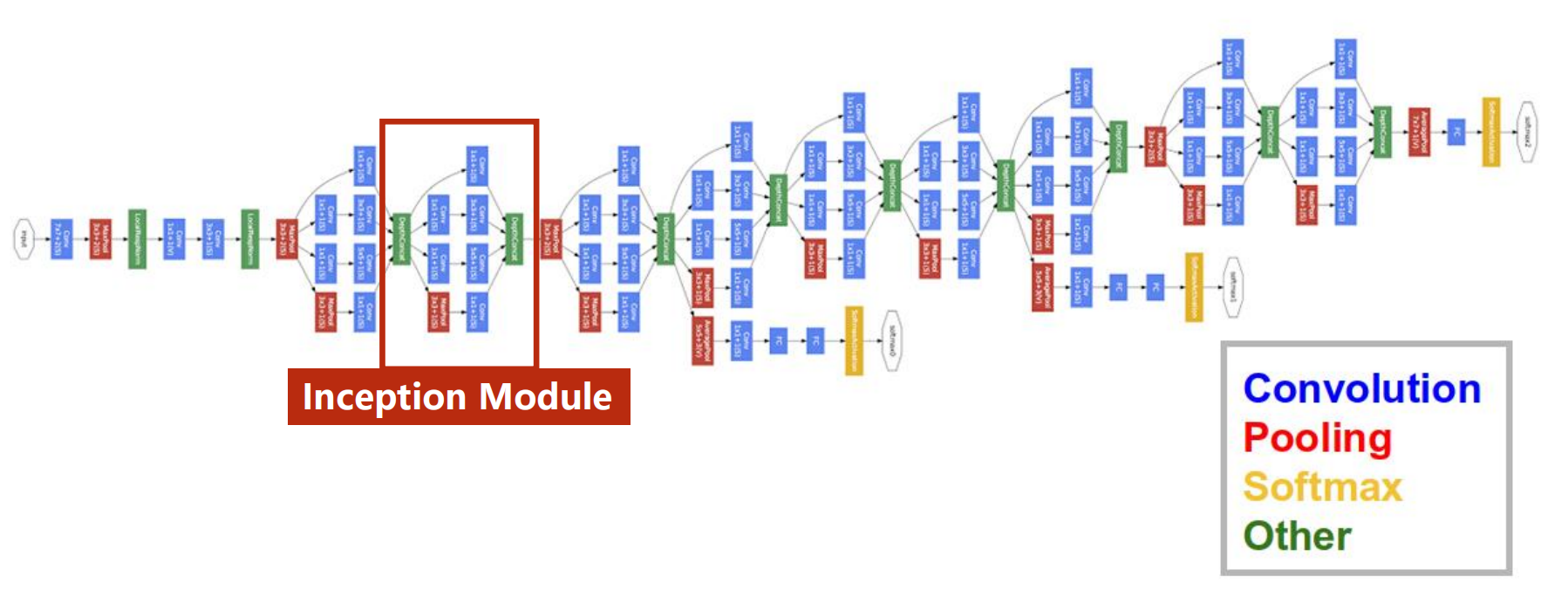
- 存在相似的结构
- 减少代码冗余:函数 / 类(封装)
GoogLeNet —— Inception Module的实现
-
在构造神经网络的时候有一些超参数不好选择,例如卷积核的大小kernel,不好确定什么大小比较好用
-
GoogLeNet的出发点就是如果不知道哪个卷积核好用,那么在一个块中把几种卷积都用上,再将它们的结果放在一起。将来如果3*3的卷积核好用,那么它的权重就会变得比较大,其他卷积核的权重就会相应的变小
- 提供几种候选的卷积神经网络配置,通过训练自动找到最优的卷积组合
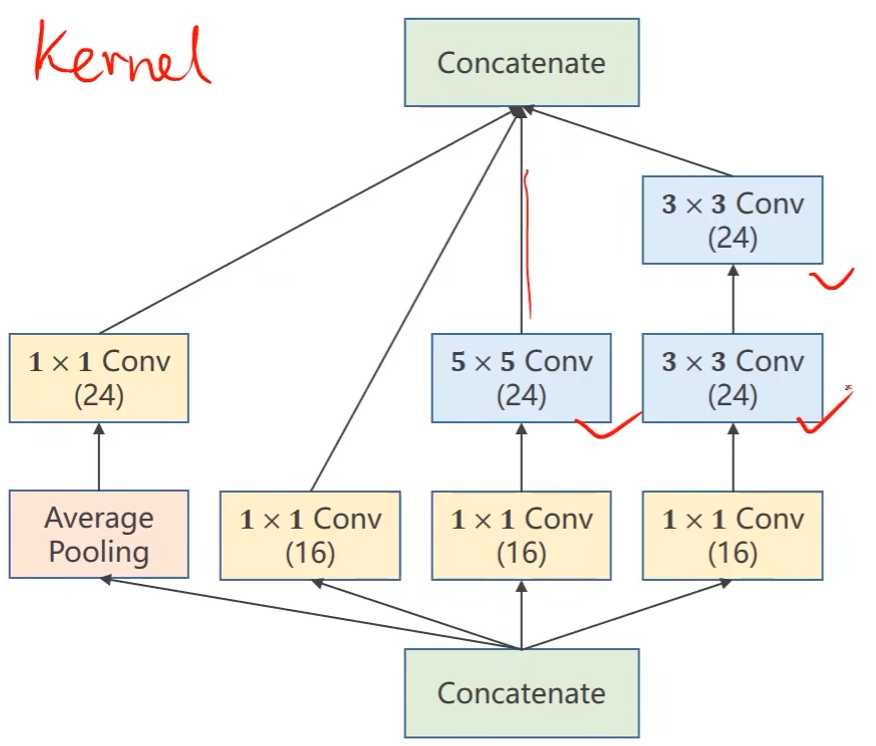
-
括号里的数字是输出通道数
-
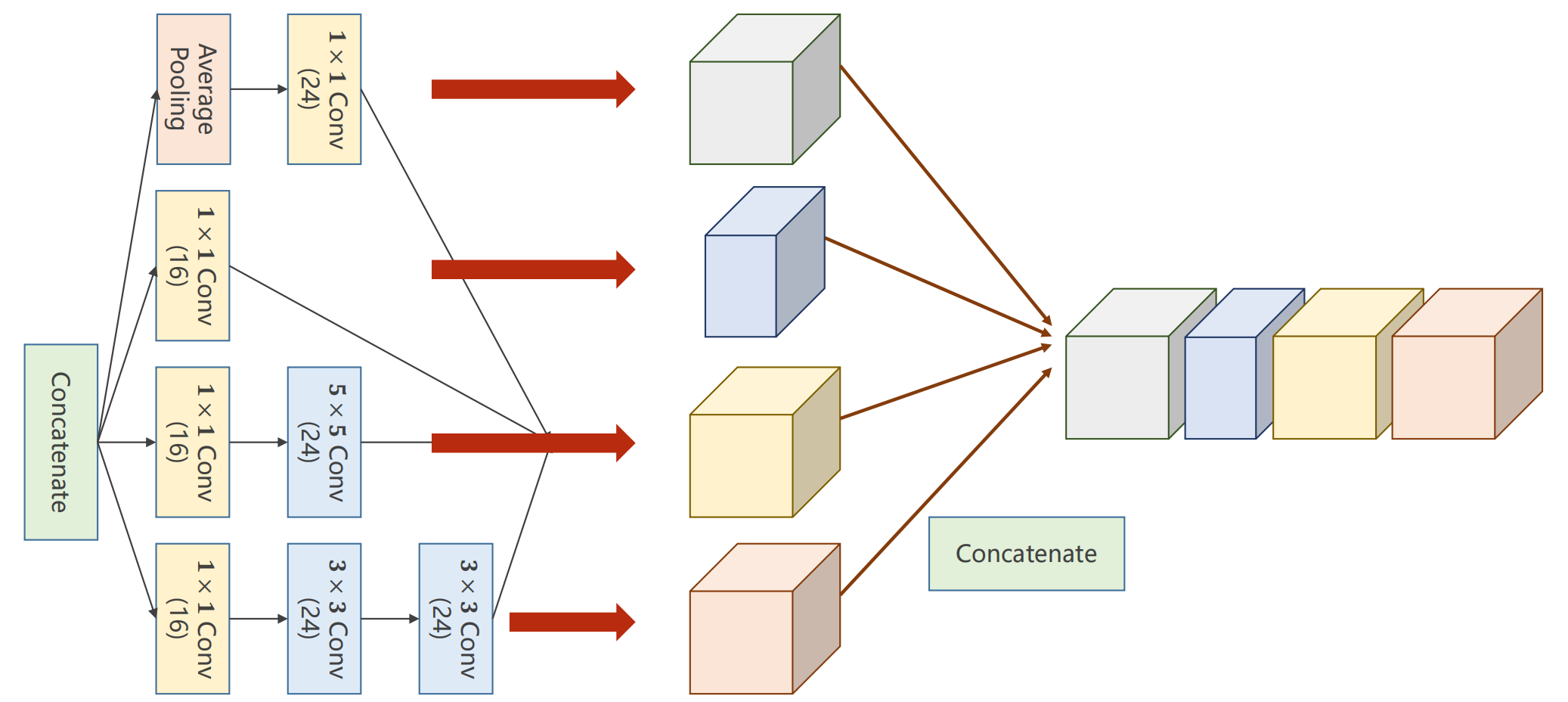
Concatenate:将张量沿着通道方向拼接到一块
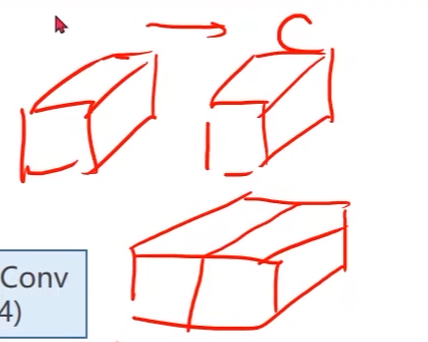
-
Average Pooling:均值池化,求平均值
- 通过设置padding和stride来保证输入输出的图像大小一样
-
1 x 1 Conv:
-
就是1*1的卷积核
-
1 x 1 Conv的数量取决于输入张量的通道**
- 融合了不同通道相同位置的信息
- 例如图中最终输出的正中间的5,是三个通道正中间那个数据(2.5,1.5,1.0)的均值,也没有包含其他位置的信息
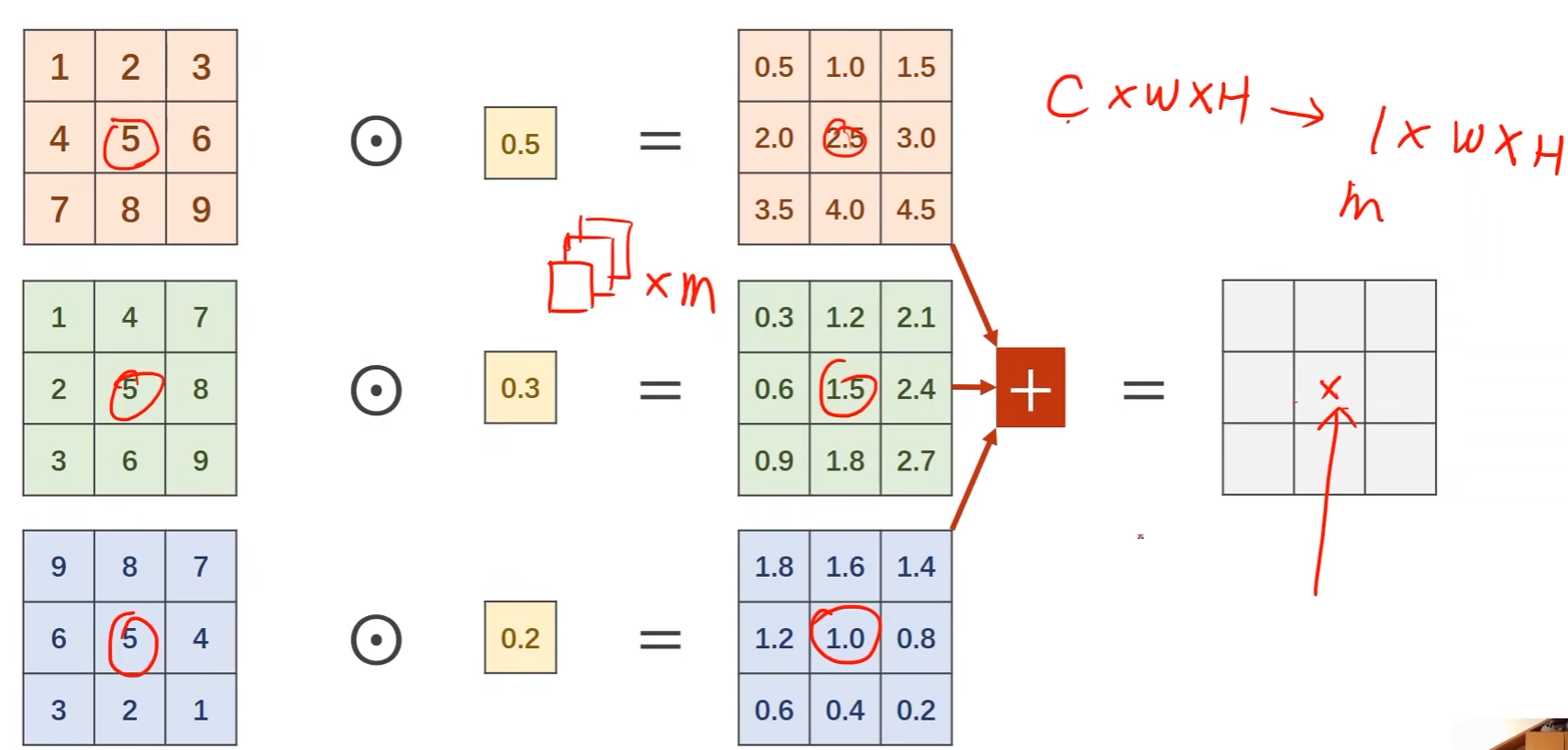
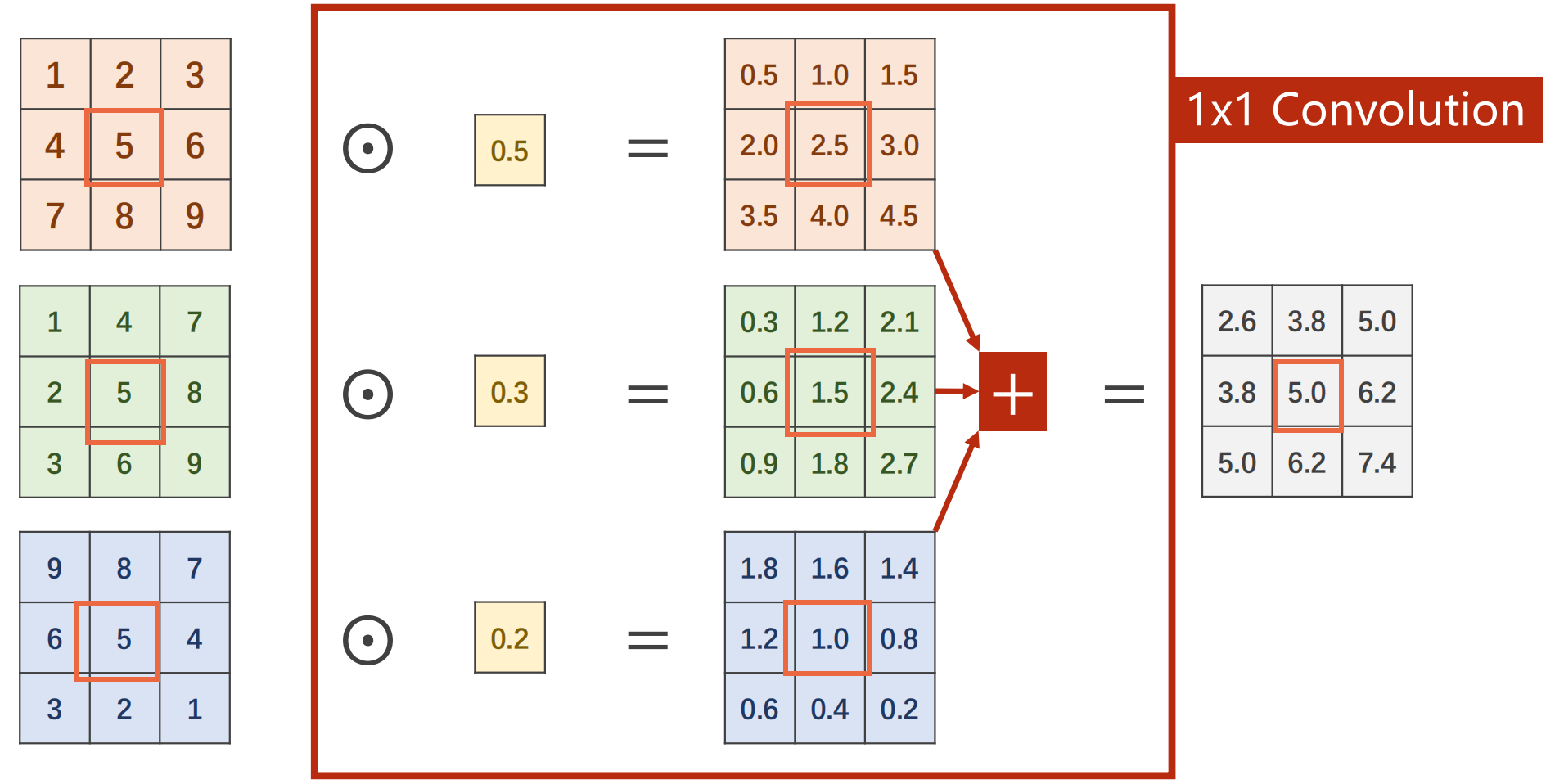
- 融合了不同通道相同位置的信息
-
作用:降低计算量
-
假设输入张量有192个通道,图像大小是28*28,使用5*5的卷积
- 运算量很大
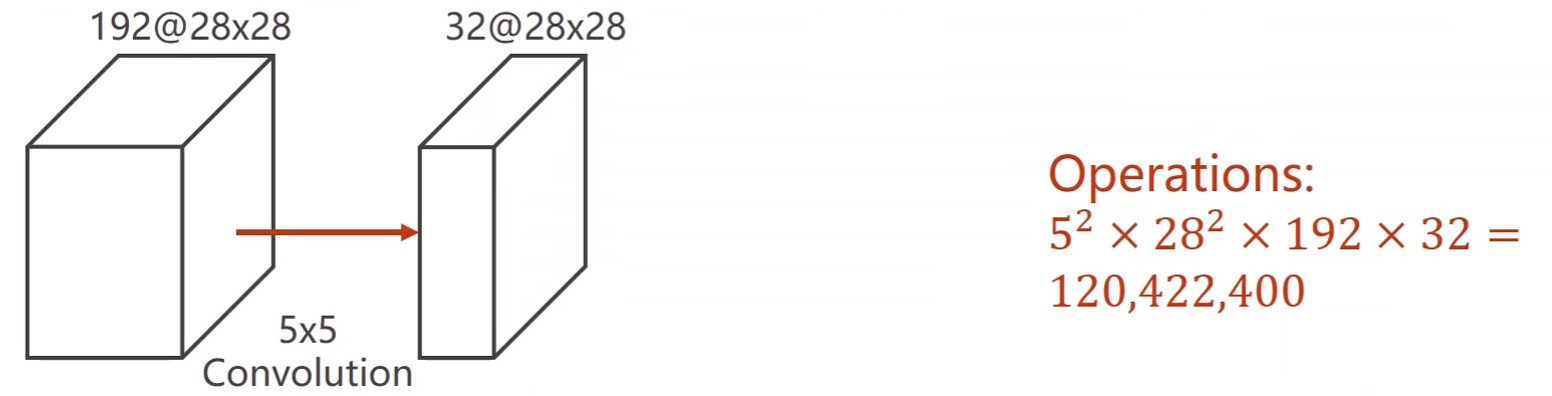
-
使用1 x 1的卷积可以直接改变通道的数量
- 运算量缩小了10倍
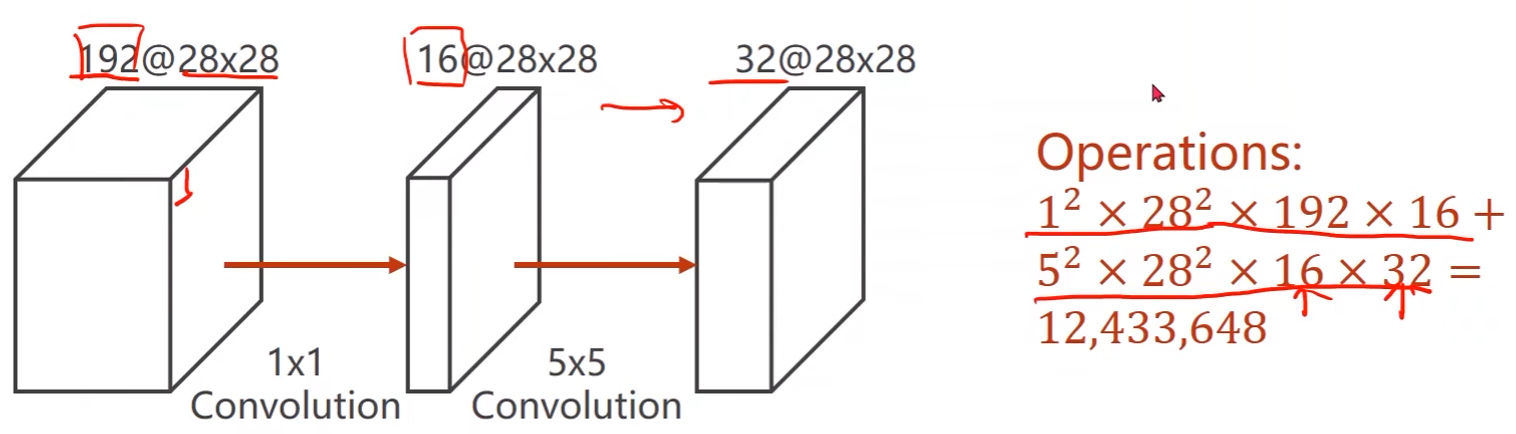
-
-
代码实现:
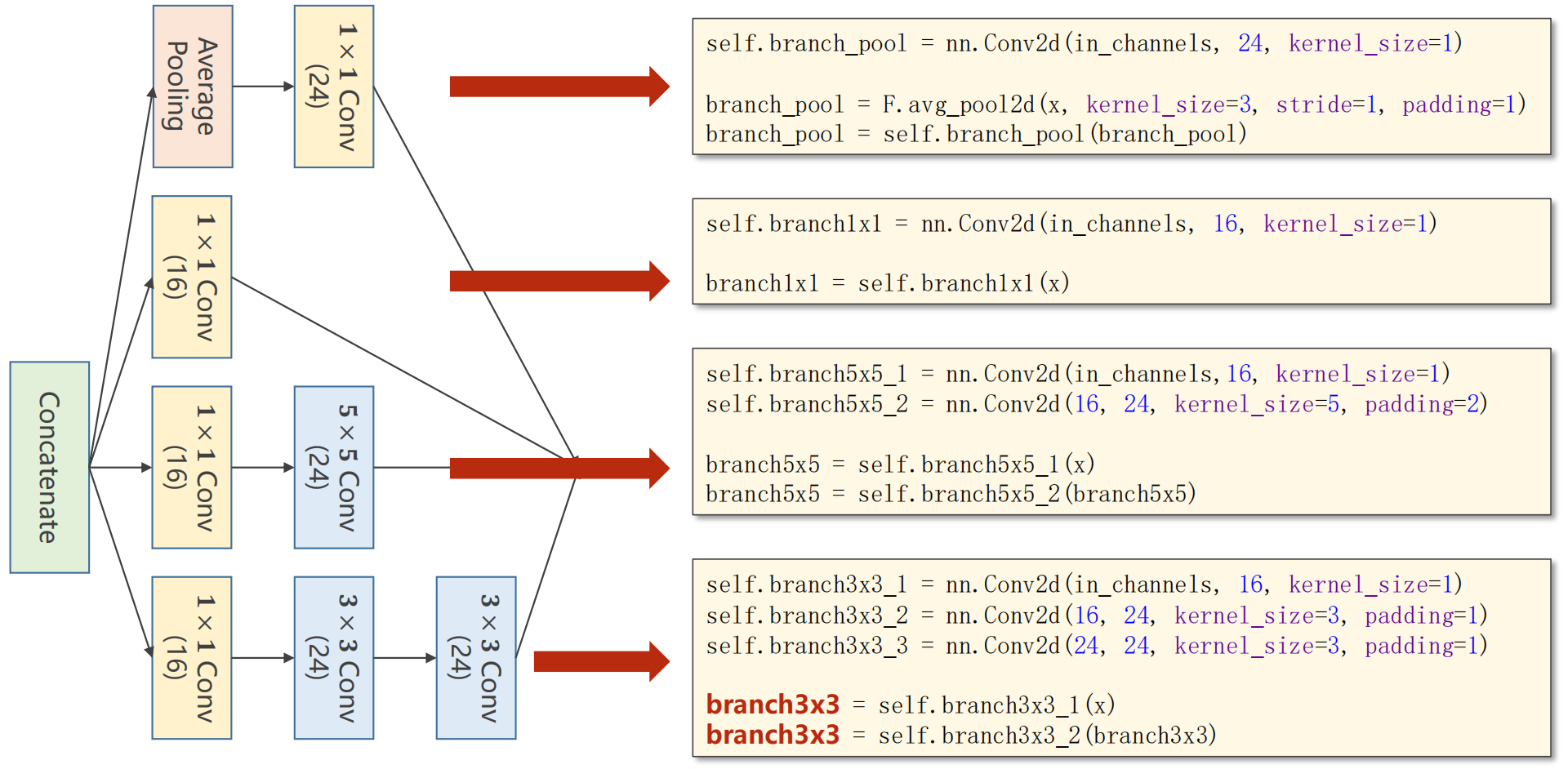
-
-
接下去将输出拼接起来(torch.cat())
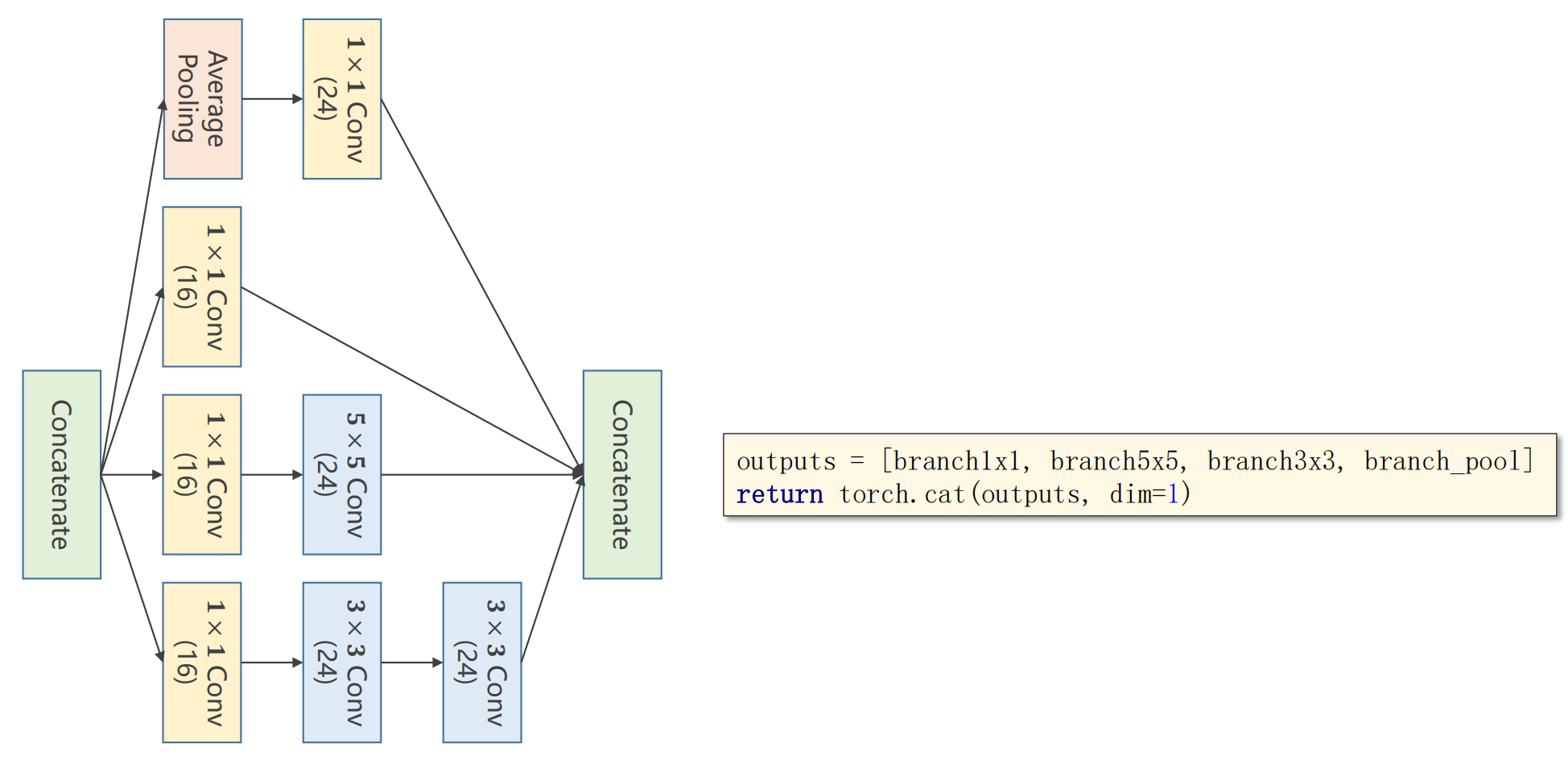
class InceptionA(torch.nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2)self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1)
完整代码:
import torch# 构造Dataloader
from torchvision import transforms # 用于对图像进行一些处理
from torchvision import datasets
from torch.utils.data import DataLoaderimport torch.nn.functional as F # 使用更流行的激活函数Relu
import torch.optim as optim # 构造优化器
import matplotlib.pyplot as pltbatch_size = 64# 存储训练轮数以及对应的accuracy用于绘图
epoch_list = []
acc_list = []# Compose的实例化
transform = transforms.Compose([transforms.ToTensor(), # 将PIL图像转成Tensortransforms.Normalize((0.1307, ), (0.3081, )) # 归一化。0.1307是均值,0.3081是标准差
])# 训练集
train_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',train=True,download=True,transform=transform) # 读取到某个数据后就直接进行transform处理
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
# 测试集
test_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(train_dataset,shuffle=False,batch_size=batch_size)class InceptionA(torch.nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2)self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1)class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) # 第一个卷积层self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5) # 第二个卷积层self.incep1 = InceptionA(in_channels=10)self.incep2 = InceptionA(in_channels=20)self.mp = torch.nn.MaxPool2d(2) # 池化层self.fc = torch.nn.Linear(1408, 10) # 线性层def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))x = self.incep2(x)x = x.view(in_size, -1)x = self.fc(x)return xmodel = Net()criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 带冲量的梯度下降# 一轮训练
def train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = data # inputs输入x,target输出yoptimizer.zero_grad()# forward + backward + updateoutputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item() # loss累加# 每300轮输出一次,减少计算成本if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300))running_loss = 0.0# 测试函数
def test():correct = 0total = 0with torch.no_grad(): # 让后续的代码不计算梯度for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy on test set: %d %%' % (100 * correct / total))acc_list.append(correct / total)if __name__ == '__main__':for epoch in range(10):train(epoch)test()epoch_list.append(epoch)# loss曲线绘制,x轴是epoch,y轴是loss值
plt.plot(epoch_list, acc_list)
plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.show()
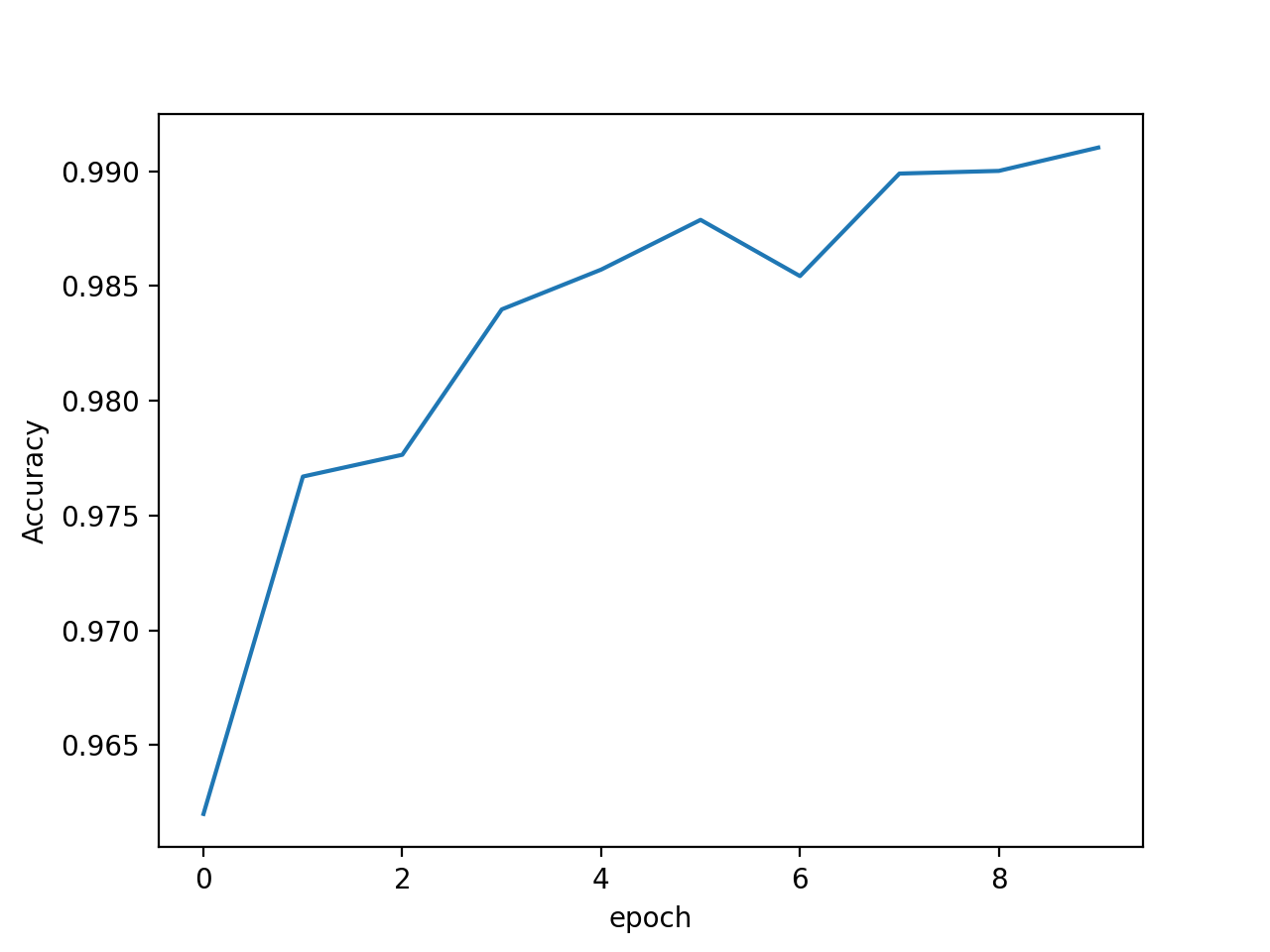
残差网络(ResNet)
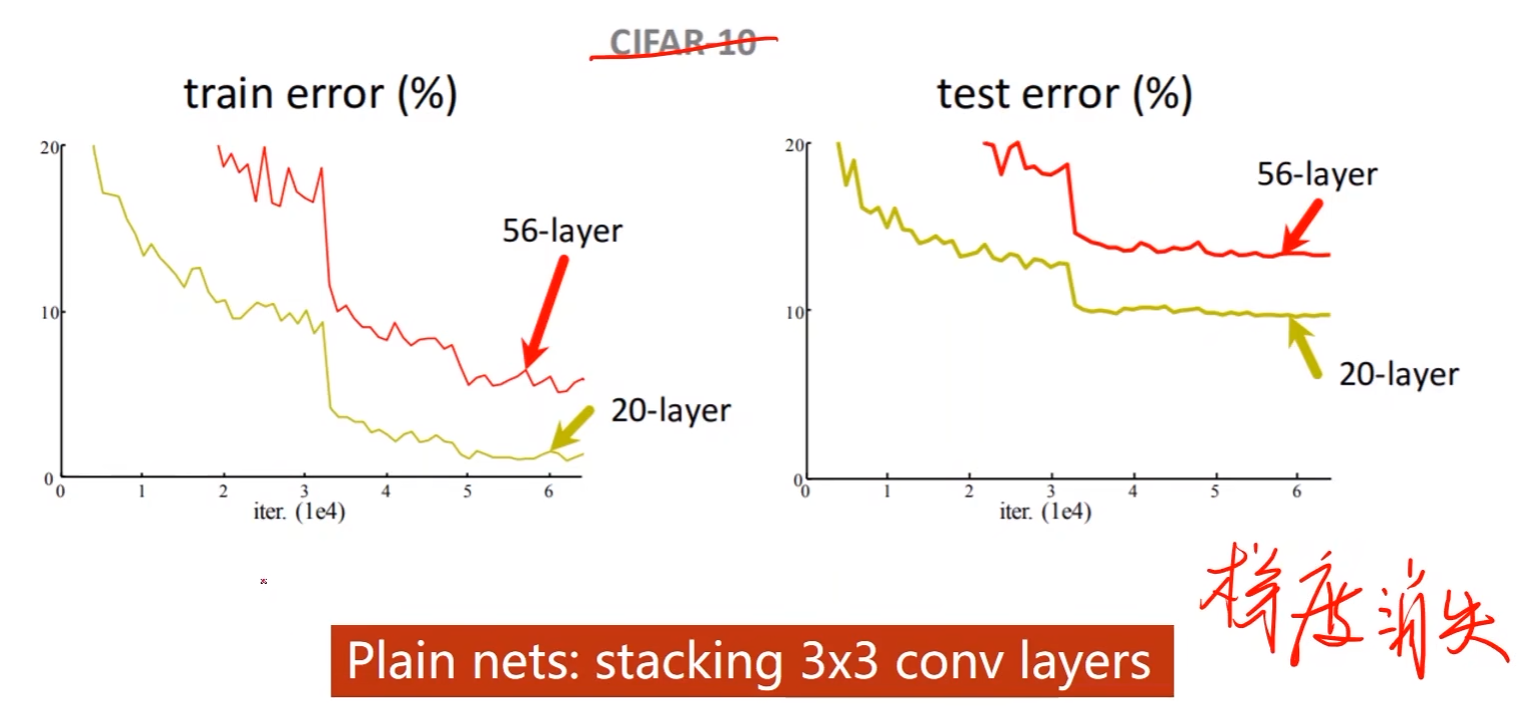
-
网络层数增多,性能反而变差
- 其中一种可能是梯度消失
- 做反向传播,要用链式法则将一连串的梯度乘起来,假设每一处的梯度都小于1,那么将这些值相乘则会越来越小,使得梯度趋近与零
- 权重更新公式: w = w − α g w = w-\alpha g w=w−αg,梯度 g g g趋于零的时候,权重 w w w就得不到更新了,从而造成离输入比较近的一些块没办法得到充分的训练
- 其中一种可能是梯度消失
-
Residual Net就是为了解决梯度消失的问题
- 输入 x x x经过两个权重层输出 F ( x ) F(x) F(x),然后这个 F ( x ) F(x) F(x)还要和 x x x进行相加,即输入 x x x经过两层输出结果为 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
- 有了 x x x的存在,在求梯度的时候即便梯度越来越小,但最终也只是趋近于1
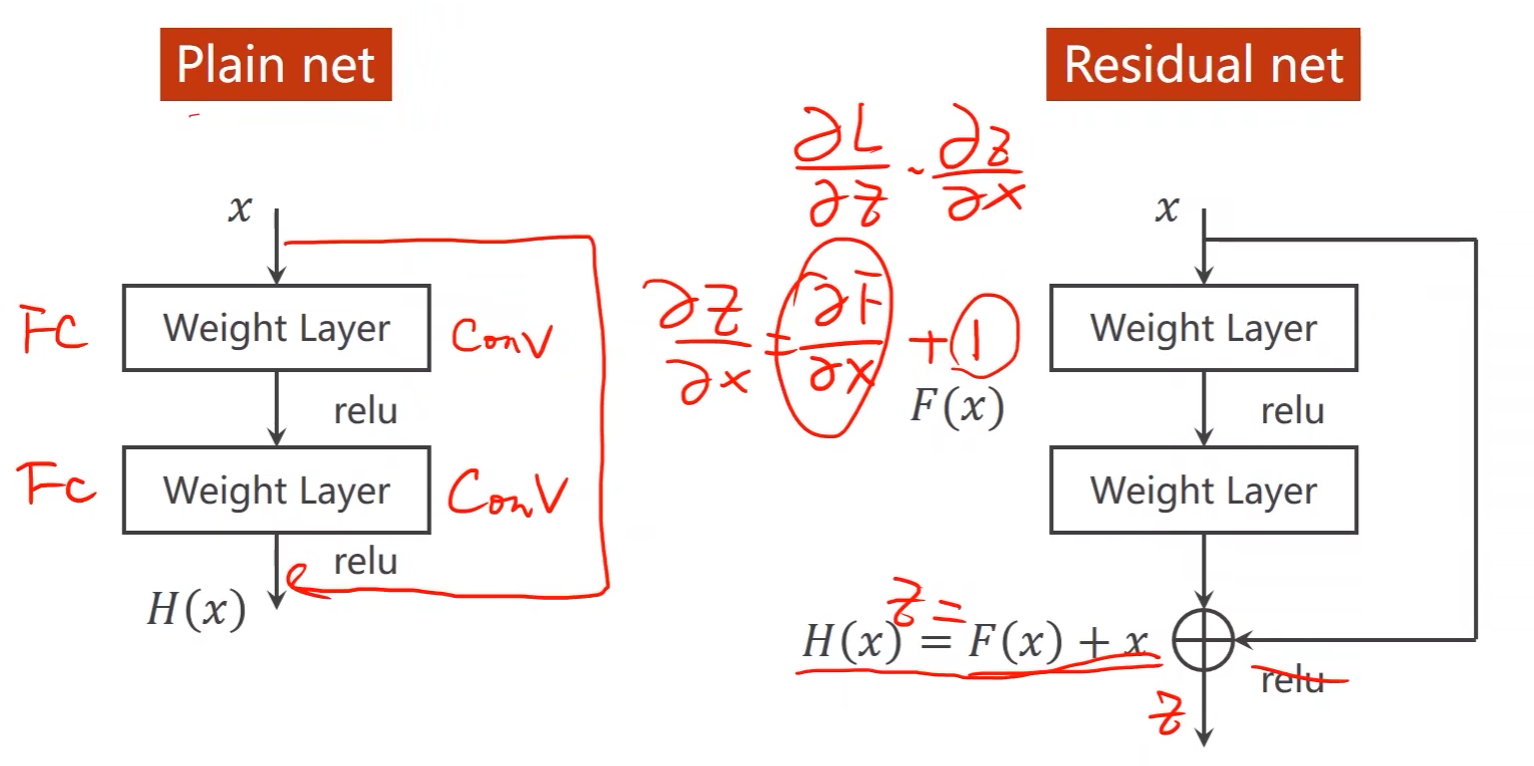
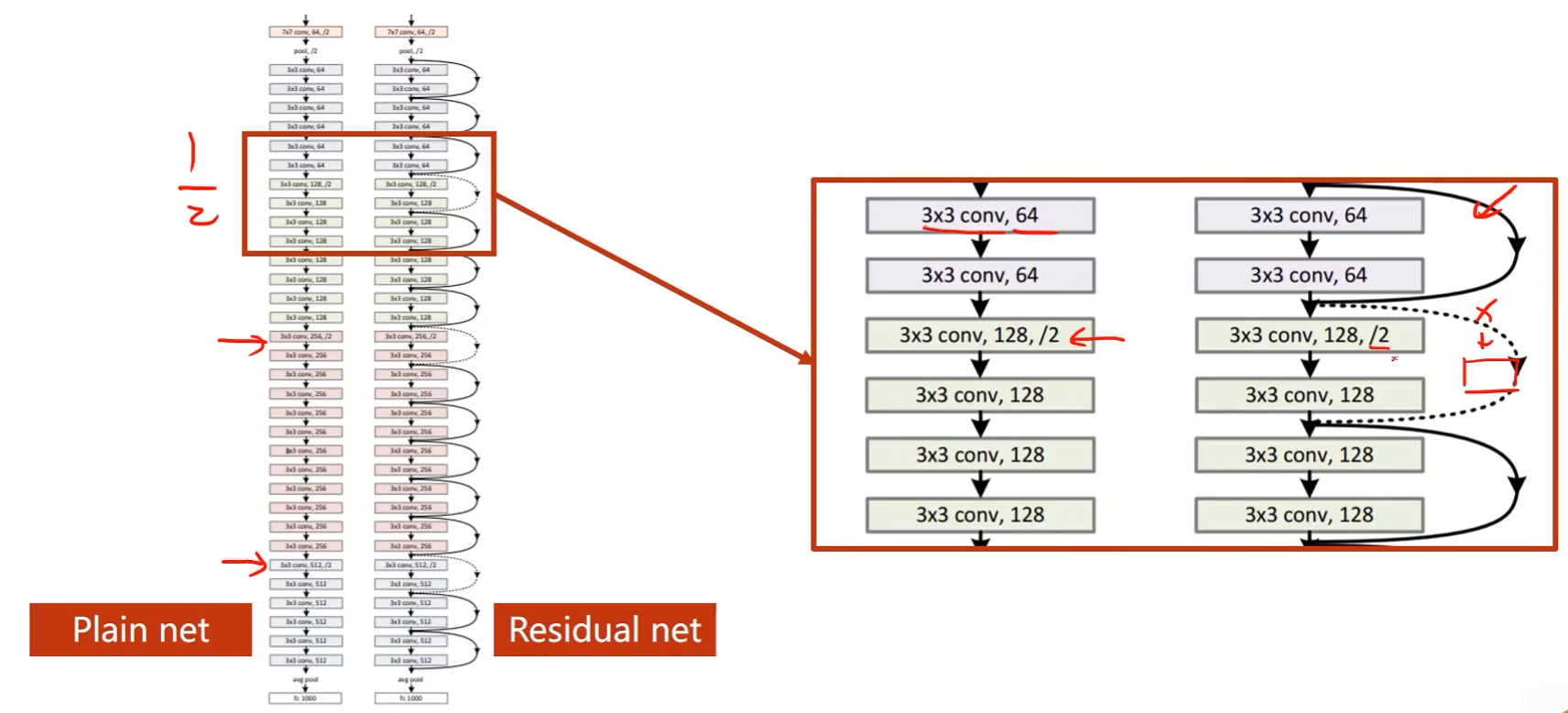
- 中间那个跳接是虚线,原因是该块的输入和输出的张量维度不同,需要进行单独处理
代码实现:

Residual Block:
- 假设两个权重层是卷积神经网络,用的3*3的卷积核
- 为了保证输出图像大小不变,那么就要将padding设置为1
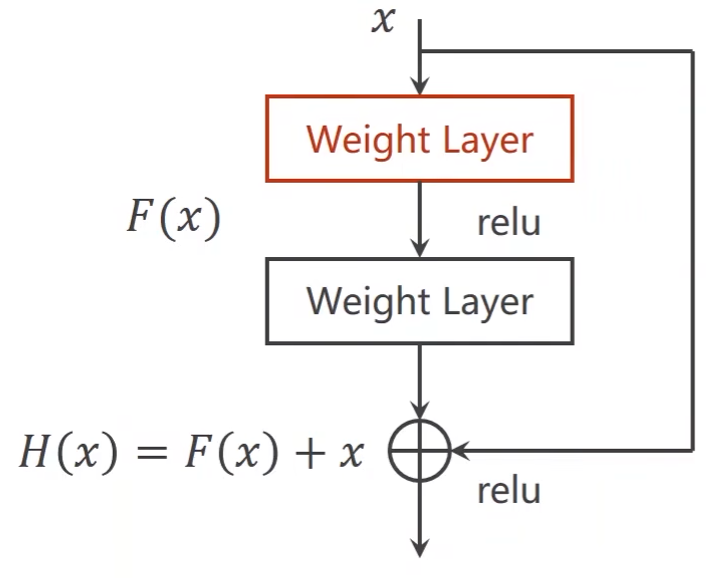
class ResidualBlock(torch.nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.channels = channelsself.conv1 = torch.nn.Conv2d(channels, channels,kernel_size=3, padding=1)self.conv2 = torch.nn.Conv2d(channels, channels,kernel_size=3, padding=1)def forward(self, x):y = F.relu(self.conv1(x)) # 先做第一次卷积,然后reluy = self.conv2(y) # F(x),第二次卷积return F.relu(x + y) # H(x) = F(x) + x
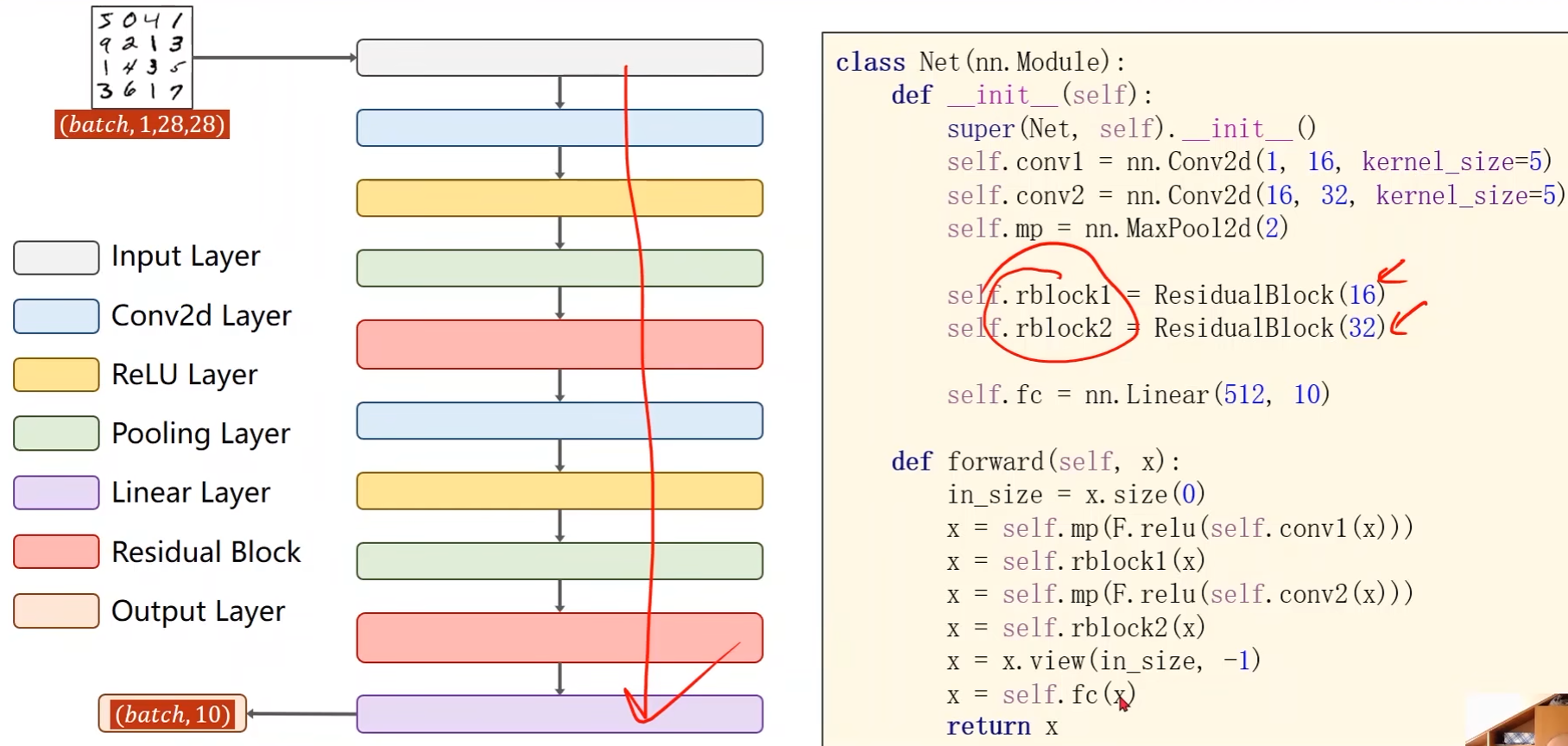
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5) # 第一个卷积层self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5) # 第二个卷积层self.mp = torch.nn.MaxPool2d(2) # 池化层self.rblock1 = ResidualBlock(16)self.rblock2 = ResidualBlock(32)self.fc = torch.nn.Linear(512, 10) # 线性层def forward(self, x):in_size = x.size(0)x = self.mp(F.relu(self.conv1(x)))x = self.rblock1(x)x = self.mp(F.relu(self.conv2(x)))x = self.rblock2(x)x = x.view(in_size, -1)x = self.fc(x)return x
完整的代码:
import torch# 构造Dataloader
from torchvision import transforms # 用于对图像进行一些处理
from torchvision import datasets
from torch.utils.data import DataLoaderimport torch.nn.functional as F # 使用更流行的激活函数Relu
import torch.optim as optim # 构造优化器
import matplotlib.pyplot as pltbatch_size = 64# 存储训练轮数以及对应的accuracy用于绘图
epoch_list = []
acc_list = []# Compose的实例化
transform = transforms.Compose([transforms.ToTensor(), # 将PIL图像转成Tensortransforms.Normalize((0.1307, ), (0.3081, )) # 归一化。0.1307是均值,0.3081是标准差
])# 训练集
train_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',train=True,download=True,transform=transform) # 读取到某个数据后就直接进行transform处理
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
# 测试集
test_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(train_dataset,shuffle=False,batch_size=batch_size)# residual block
class ResidualBlock(torch.nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.channels = channelsself.conv1 = torch.nn.Conv2d(channels, channels,kernel_size=3, padding=1)self.conv2 = torch.nn.Conv2d(channels, channels,kernel_size=3, padding=1)def forward(self, x):y = F.relu(self.conv1(x)) # 先做第一次卷积,然后reluy = self.conv2(y) # F(x),第二次卷积return F.relu(x + y) # H(x) = F(x) + xclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5) # 第一个卷积层self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5) # 第二个卷积层self.mp = torch.nn.MaxPool2d(2) # 池化层self.rblock1 = ResidualBlock(16)self.rblock2 = ResidualBlock(32)self.fc = torch.nn.Linear(512, 10) # 线性层def forward(self, x):in_size = x.size(0)x = self.mp(F.relu(self.conv1(x)))x = self.rblock1(x)x = self.mp(F.relu(self.conv2(x)))x = self.rblock2(x)x = x.view(in_size, -1)x = self.fc(x)return xmodel = Net()criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 带冲量的梯度下降# 一轮训练
def train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = data # inputs输入x,target输出yoptimizer.zero_grad()# forward + backward + updateoutputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item() # loss累加# 每300轮输出一次,减少计算成本if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300))running_loss = 0.0# 测试函数
def test():correct = 0total = 0with torch.no_grad(): # 让后续的代码不计算梯度for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy on test set: %d %%' % (100 * correct / total))acc_list.append(correct / total)if __name__ == '__main__':for epoch in range(10):train(epoch)test()epoch_list.append(epoch)# loss曲线绘制,x轴是epoch,y轴是loss值
plt.plot(epoch_list, acc_list)
plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.show()