一、前言
与Hadoop1.x相比,Hadoop2.x中的NameNode不再是只有一个了,可以有多个(目前只支持2个)。每一个都有相同的职能。
这两个NameNode的地位如何哪?
答:一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为active状态的,就可以继续工作了,这就是高可靠。
当NameNode发生故障时,他们的数据如何保持一致哪?
在这里,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,JournalNode集群或者NFS进行共享。NFS是操作系统层面的,JournalNode是Hadoop层面的,我们这里使用JournalNode集群进行数据共享。
如何实现NameNode的自动切换呢?
这就需要使用ZooKeeper集群进行选择了。HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
HDFS Federation(HDFS联邦)是怎么回事?
答:联邦的出现是有原因的,我们知道NameNode是核心节点,维护着整个HDFS中的元数据信息,那么其容量是有限的,受制于服务器的内存空间。当NameNode服务器的内存装不下数据后,那么HDFS集群就装不下数据了,寿命也就到头了。因此其扩展性是受限的。HDFS联盟指的是有多个HDFS集群同时工作,那么其容量理论上就不受限了,夸张点说就是无限扩展。
二、安装前准备
1、在一台虚拟机搭建伪分布模式
http://blog.csdn.net/scgaliguodong123_/article/details/45288419/
2、使用VMware10 克隆虚拟机,这里我们假设克隆的虚拟机节点分别为hadoop1,hadoop2,hadoop3,hadoop4
3、配置各个主机的静态ip
vi /etc/sysconfig/network-scripts/ifcfg-eth0
4、修改各个节点的主机名分别为hadoop1,hadoop2,hadoop3,hadoop4
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop4重启:reboot
5、在各个主机上配置ip与hostname的映射关系
先在在hadoop1上设置
vim /etc/hosts172.18.50.101 hadoop1
172.18.50.102 hadoop2
172.18.50.103 hadoop3
172.18.50.104 hadoop4复制以上文件到hadoop2,hadoop3,hadoop4节点上面。
scp /etc/hosts hadoop2:/etc/hosts
6、重新生成密钥
删除目录/root/.ssh/下所有文件
[root@hadoop1 .ssh]# rm -rf *
[root@hadoop1 .ssh]# ssh-keygen -t rsa[root@hadoop1 .ssh]# cat id_rsa.pub >> authorized_keys测试是否成功ssh localhost
其他其他节点同上生成密钥。
7、设置两两结点间的免密码登录
hadoop2,hadoop3,hadoop4将自己的公钥复制给对方主机
[root@hadoop2 .ssh]# ssh-copy-id -i hadoop1
liguodong@ubuntu:~/.ssh$ cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCtqv04MmyCQ01WVqg/amwNTHAZFb8xadZZ15IBW8A5KVtxdQZi4Eyo4cSBYWmYTEwNkHLcXt6FTne6Sgnv1ONwY/yxPZAclyynpAWLmZijvVovoqDAcX42jZbNmPYQ0kX9KfCNX0dsLOhnZRuZd8mPfEiPaGkIUSEhwFHvHnN8edfxvK+4t9h9cBU0rc42xGviuOEBsBtJ3qWkRjRLN0OFUPYyrRM/rvoG9JVlChZ4j7qZplDTZ8TzbS2jMXrD15p3P7I0liesi5OL6tm7oA8dtL73Wxq1tei2U8U9x6buEAwYGKgZohs18viGcCnPP3A2F5u8wjl6jRUwox/Yk2m5 root@hadoop1
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCT0tthMGl1cHHbf+c8nBR9PU7kwOUfNX4IKmr+eJCy9VPIwHKMj+dCEmM+aysY4f2haUaShnKkRL20KWcqPJwQYj0rJ1xgcPLFD4xPH3APiifgIChqz/4ZHq6CJv/MU0QN7dl4iItcfCUUwuWSJRqLLj/4eEcn2kGPqZjf0R72UbKrQcCrvUZAHHuSQE3/wjq9TDHKLmQ63auibIYtrfm+uOy9AVUQuhS1KlHgbXtBaRftfx3g7X4JwC+tfWRbY5QftOp+EGrSfDtS1JHFAMZ1JeZnYp8Fz++QleZf0Se2/G170JvBh0OgkNyALMjeUqi1IZw64XzhCXD8ntCGv5Sl root@hadoop2
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDxVTC6bpRxqFtNQlE/dGIAOkQANlGgcE+tm+EOduNoCjBqiRNxQb5WKAw10lI/wdmEvCJnZ7RbIs3sL/ZqAi5pmXDwreAVaQYmbcwIAHl2Rwh09bW8zFeNm8x9+YUQKg/fzUz1ad5yfKsI6jXT3IKuAOURuiFTR9KgHWNvld4ffbUG2UXv0l1amcPbL0D0ZtR9YJyUACM3DMBuLjhU14Xm5xlQy1LgfAhGcJuE2G1YY0uH0BVC2lCvlu9OOowoykq1ilDAO6+llddwme94FLH8RIlsk99oFNReDRn7rYWSxw9jg5cC+Frmbbwq5LqBA69Q/G7R5n/cuyB2uJrgZ3St root@hadoop3
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCtqv04MmyCQ01WVqg/amwNTHAZFb8xadZZ15IBW8A5KVtxdQZi4Eyo4cSBYWmYTEwNkHLcXt6FTne6Sgnv1ONwY/yxPZAclyynpAWLmZijvVovoqDAcX42jZbNmPYQ0kX9KfCNX0dsLOhnZRuZd8mPfEiPaGkIUSEhwFHvHnN8edfxvK+4t9h9cBU0rc42xGviuOEBsBtJ3qWkRjRLN0OFUPYyrRM/rvoG9JVlChZ4j7qZplDTZ8TzbS2jMXrD15p3P7I0liesi5OL6tm7oA8dtL73Wxq1tei2U8U9x6buEAwYGKgZohs18viGcCnPP3A2F5u8wjl6jRUwox/Yk2m5 root@hadoop4至此,hadoop2,hadoop3,hadoop4都能够访问hadoop1了
hadoop1复制自己的authorized_keys给其他主机 ,都可以互相免密码登录了。
scp /root/.ssh/authorized_keys hadoop2:/root/.ssh/
http://blog.csdn.net/scgaliguodong123_/article/details/45331771
8、安装Zookeeper
http://blog.csdn.net/scgaliguodong123_/article/details/45332877
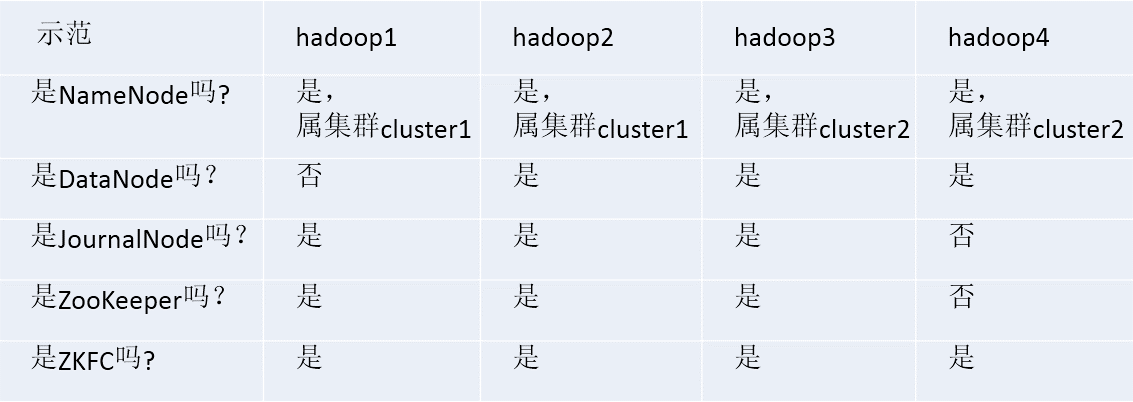
9、各个节点的职责如下图所示
三、搭建自动切换HA及Federation
1、在hadoop1上面修改配置文件
core-site.xml
<configuration>【这里的值指的是默认的HDFS路径。当有多个HDFS集群同时工作时,用户如果不写集群名称,那么默认使用哪个哪?
在这里指定!该值来自于hdfs-site.xml中的配置。在节点hadoop1和hadoop2中使用cluster1,在节点hadoop3和hadoop4中使用cluster2】<property><name>fs.defaultFS</name><value>hdfs://cluster1</value></property>【这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。】<property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property>【这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点】<property><name>ha.zookeeper.quorum</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value></property></configuration>hdfs-site.xml
该文件只配置在hadoop1和hadoop2上。
<configuration>【指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可。】<property><name>dfs.replication</name><value>2</value></property>【使用federation时,使用了2个HDFS集群。这里抽象出两个NameService实际上就是给这2个HDFS集群起了个别名。名字可以随便起,相互不重复即可】 <property><name>dfs.nameservices</name><value>cluster1,cluster2</value></property>【指定NameService是cluster1时的namenode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可】<property><name>dfs.ha.namenodes.cluster1</name><value>hadoop1,hadoop2</value></property>【指定hadoop1的RPC地址】<property><name>dfs.namenode.rpc-address.cluster1.hadoop1</name><value>hadoop1:9000</value></property> 【指定hadoop1的http地址】<property><name>dfs.namenode.http-address.cluster1.hadoop1</name><value>hadoop1:50070</value></property>【指定hadoop2的RPC地址】<property><name>dfs.namenode.rpc-address.cluster1.hadoop2</name><value>hadoop2:9000</value></property>【指定hadoop2的http地址】<property><name>dfs.namenode.http-address.cluster1.hadoop2</name><value>hadoop2:50070</value></property>【指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息】<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/cluster1</value></property>【指定cluster1是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode】<property><name>dfs.ha.automatic-failover.enabled.cluster1</name><value>true</value></property>【指定cluster1出故障时,哪个实现类负责执行故障切换】<property><name>dfs.client.failover.proxy.provider.cluster1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property>【指定NameService是cluster2时,两个NameNode是谁,这里是逻辑名称,不重复即可。以下配置与cluster1几乎全部相似,不再添加注释】<property><name>dfs.ha.namenodes.cluster2</name><value>hadoop3,hadoop4</value></property><property><name>dfs.namenode.rpc-address.cluster2.hadoop3</name><value>hadoop3:9000</value></property><property><name>dfs.namenode.http-address.cluster2.hadoop3</name><value>hadoop3:50070</value></property><property><name>dfs.namenode.rpc-address.cluster2.hadoop4</name><value>hadoop4:9000</value></property><property><name>dfs.namenode.http-address.cluster2.hadoop4</name><value>hadoop4:50070</value></property><!--<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/cluster2</value></property>【在cluster1中,这段代码是注释掉的,不要打开,在cluster2中则反过来。】--><property><name>dfs.ha.automatic-failover.enabled.cluster2</name><value>true</value></property><property><name>dfs.client.failover.proxy.provider.cluster2</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property>【指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的磁盘路径】<property><name>dfs.journalnode.edits.dir</name><value>/install/hadoop/tmp/journal</value></property>【一旦需要NameNode切换,使用ssh方式进行操作】<property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property>【如果使用ssh进行故障切换,使用ssh通信时用的密钥存储的位置】<property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property></configuration>2、slave
hadoop2
hadoop3
hadoop42、把hadoop1上配置的内容分别复制到hadoop2、hadoop3、hadoop4节点上
[root@hadoop1 etc]# pwd
/install/hadoop/etc
[root@hadoop1 etc]# scp -r hadoop/ hadoop3:/install/hadoop/etc/3、修改hadoop2、hadoop3、hadoop4上的配置文件内容
(1)修改hadoop3、hadoop4上的core-site.xml内容
fs.defaultFS的值改为hdfs://cluster2
<property><name>fs.defaultFS</name><value>hdfs://cluster2</value>
</property>(2)修改hadoop3、hadoop4上的hdfs-site.xml内容
把cluster1中关于journalnode的配置项删除,如下所示:
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster1</value>
</property>增加如下内容:
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster2</value>
</property>4、启动
(1)启动journalnode(启动之前先启动Zookeeper)
在hadoop1、hadoop2、hadoop3上分别执行hadoop-daemon.sh start journalnode
[root@hadoop1 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /install/hadoop/logs/hadoop-root-journalnode-hadoop1.out
[root@hadoop1 ~]# jps
6281 Jps
3696 QuorumPeerMain
6251 JournalNode
(2)格式化ZooKeeper
在hadoop1、hadoop3上执行hdfs zkfc -formatZK
[root@hadoop1 ~]# hdfs zkfc -formatZK
15/04/28 20:24:56 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at hadoop1/172.18.50.101:9000
...
15/04/28 20:24:59 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/cluster1 in ZK.[root@hadoop3 hadoop]# hdfs zkfc -formatZK15/04/28 20:26:29 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at hadoop3/172.18.50.103:900015/04/28 20:26:31 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/cluster2 in ZK.进入zookeeper命令行 zkCli.sh
[zk: localhost:2181(CONNECTED) 3] ls /
[hadoop-ha, zookeeper][zk: localhost:2181(CONNECTED) 4] ls /hadoop-ha
[cluster2, cluster1](3)对hadoop1节点namenode进行格式化和启动
删除hadoop1,hadoop2节点上的日志和格式化文件不然可能会有错误
rm -rf logs/
rm -rf data/tmp/dfs/
[root@hadoop1 ~]# hdfs namenode -format
15/04/28 20:34:32 INFO common.Storage: Storage directory /install/hadoop/data/tmp/dfs/name has been successfully formatted.[root@hadoop1 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /install/hadoop/logs/hadoop-root-namenode-hadoop1.out
[root@hadoop1 ~]# jps
6590 NameNode
3696 QuorumPeerMain
6251 JournalNode
6627 Jps
(4) 对hadoop2节点namenode进行格式化和启动
[root@hadoop2 hadoop]# hdfs namenode -bootstrapStandby=====================================================
About to bootstrap Standby ID hadoop2 from:Nameservice ID: cluster1Other Namenode ID: hadoop1Other NN's HTTP address: http://hadoop1:50070Other NN's IPC address: hadoop1/172.18.50.101:9000Namespace ID: 1073431967Block pool ID: BP-675437258-172.18.50.101-1430278472815Cluster ID: CID-39f596f8-ab19-45ce-830c-ddc2e9d3e2abLayout version: -60
=====================================================15/04/28 20:39:16 INFO common.Storage: Storage directory /install/hadoop/data/tmp/dfs/name has been successfully formatted.[root@hadoop2 hadoop]# hadoop-daemon.sh start namenode
starting namenode, logging to /install/hadoop/logs/hadoop-root-namenode-hadoop2.out
[root@hadoop2 hadoop]# jps
3113 QuorumPeerMain
5782 NameNode
5819 Jps
5549 JournalNode
此时hadoop1与hadoop2的namanode都是处于standby状态。
。
(5)在hadoop1、hadoop2上分别启动zkfc
[root@hadoop2 hadoop]# hadoop-daemon.sh start zkfc
starting zkfc, logging to /install/hadoop/logs/hadoop-root-zkfc-hadoop2.out
[root@hadoop2 hadoop]# jps
3113 QuorumPeerMain
5782 NameNode
6078 DFSZKFailoverController
6104 Jps
5549 JournalNode我们的hadoop1、hadoop2有一个节点就会变为active状态。
(6)对于cluster2执行以上类似操作
删除hadoop3,hadoop4上的日志和格式化文件不然可能会有错误
rm -rf logs/
rm -rf data/tmp/dfs/
hadoop3
hdfs namenode -format
hadoop-daemon.sh start namenode
hadoop4
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
hadoop3,hadoop4
hadoop-daemon.sh start zkfc
(7)启动datanode
在hadoop1上执行命令hadoop-daemons.sh start datanode
[root@hadoop1 ~]# hadoop-daemons.sh start datanode
hadoop4: starting datanode, logging to /install/hadoop/logs/hadoop-root-datanode-hadoop4.out
hadoop3: starting datanode, logging to /install/hadoop/logs/hadoop-root-datanode-hadoop3.out
hadoop2: starting datanode, logging to /install/hadoop/logs/hadoop-root-datanode-hadoop2.out8、测试
在hadoop4节点上,默认上传到cluster2,如果在hadoop1或hadoop上,默认上传到cluster1。
[root@hadoop4 hadoop]# hdfs dfs -put ~/test /
[root@hadoop4 hadoop]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 2 root supergroup 19 2015-04-28 22:16 /test
[root@hadoop4 hadoop]# hdfs dfs -text /test
hello you
hello me
[root@hadoop4 hadoop]# hdfs dfs -put ~/test hdfs://cluster1/input
[root@hadoop4 hadoop]# hdfs dfs -put ~/test hdfs://cluster2/input
[root@hadoop4 hadoop]# hdfs dfs -put ~/test hdfs://hadoop2:9000/input
四、配置Yarn
(1)修改文件mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property> (2)修改文件yarn-site.xml
【自定ResourceManager的地址,还是单点,这是隐患】
<property><name>yarn.resourcemanager.hostname</name><value>hadoop1</value>
</property> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>复制以上两个文件到hadoop2,hadoop3,hadoop4上
[root@hadoop1 logs]# scp /install/hadoop/etc/hadoop/mapred-site.xml /install/hadoop/etc/hadoop/yarn-site.xml hadoop2:/install/hadoop/etc/hadoop/
mapred-site.xml 100% 857 0.8KB/s 00:00
yarn-site.xml 100% 893 0.9KB/s 00:00(3)启动yarn
在hadoop1上执行start-yarn.sh
[root@hadoop1 logs]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /install/hadoop/logs/yarn-root-resourcemanager-hadoop1.out
hadoop4: starting nodemanager, logging to /install/hadoop/logs/yarn-root-nodemanager-hadoop4.out
hadoop2: starting nodemanager, logging to /install/hadoop/logs/yarn-root-nodemanager-hadoop2.out
hadoop3: starting nodemanager, logging to /install/hadoop/logs/yarn-root-nodemanager-hadoop3.out
[root@hadoop1 logs]# jps
7003 DFSZKFailoverController
3696 QuorumPeerMain
7984 ResourceManager
6251 JournalNode
8053 Jps
五、测试
[root@hadoop4 mapreduce]# pwd
/install/hadoop/share/hadoop/mapreduce
[root@hadoop4 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /test /output