♥️作者:小刘在C站
♥️个人主页: 小刘主页
♥️努力不一定有回报,但一定会有收获加油!一起努力,共赴美好人生!
♥️学习两年总结出的运维经验,以及思科模拟器全套网络实验教程。专栏:云计算技术
♥️小刘私信可以随便问,只要会绝不吝啬,感谢CSDN让你我相遇!
前言上章讲到MySQL-分库分表(三)本章继续
目录
MySQL
5 MyCat分片
5.1 垂直拆分
5.1.1 场景
5.1.2 准备
5.1.3 配置
1). schema.xml
2). server.xml
5.1.4 测试
5.1.5 全局表
配置完毕后,重新启动MyCat。
MySQL
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型和大型网站的开发都选择 MySQL 作为网站数据库。
5 MyCat分片
5.1 垂直拆分
5.1.1 场景

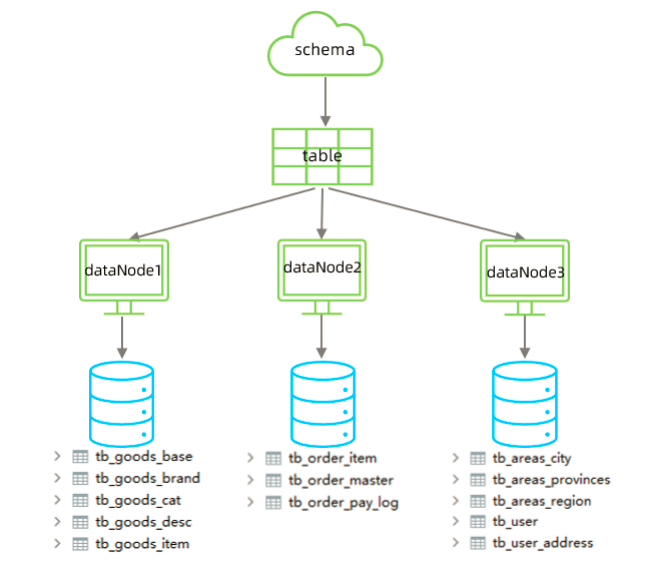
5.1.2 准备
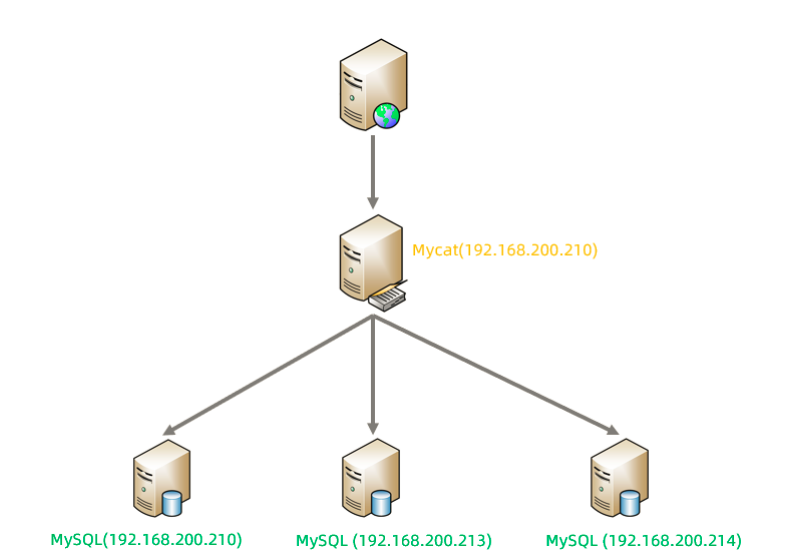
5.1.3 配置
1). schema.xml
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_goods_base" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_brand" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_cat" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id" />
<table name="tb_goods_item" dataNode="dn1" primaryKey="id" />
<table name="tb_order_item" dataNode="dn2" primaryKey="id" />
<table name="tb_order_master" dataNode="dn2" primaryKey="order_id" />
<table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no" />
<table name="tb_user" dataNode="dn3" primaryKey="id" />
<table name="tb_user_address" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_provinces" dataNode="dn3" primaryKey="id"/>
<table name="tb_areas_city" dataNode="dn3" primaryKey="id"/>
<table name="tb_areas_region" dataNode="dn3" primaryKey="id"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="shopping" />
<dataNode name="dn2" dataHost="dhost2" database="shopping" />
<dataNode name="dn3" dataHost="dhost3" database="shopping" />
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" />
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" />
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" />
</dataHost>2). server.xml
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">SHOPPING</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="true">
<schema name="DB01" dml="0110" >
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">SHOPPING</property>
<property name="readOnly">true</property>
</user>5.1.4 测试
source /root/shopping-table.sql
source /root/shopping-insert.sql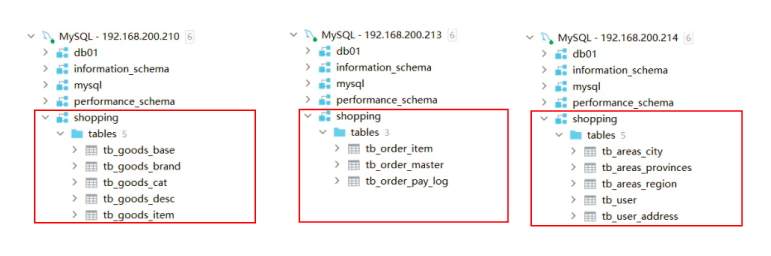
3). 查询用户的收件人及收件人地址信息(包含省、市、区)。
select ua.user_id, ua.contact, p.province, c.city, r.area , ua.address from
tb_user_address ua ,tb_areas_city c , tb_areas_provinces p ,tb_areas_region r
where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id =
r.areaid ;
4). 查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o
, tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE
o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND
o.receiver_region = r.areaid ;
5.1.5 全局表
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/> 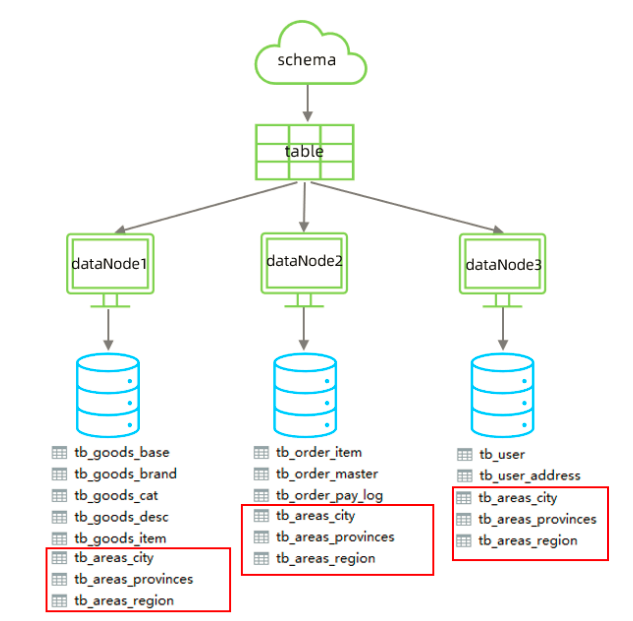
配置完毕后,重新启动MyCat。
source /root/shopping-table.sql
source /root/shopping-insert.sqlSELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o
, tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE
o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND
o.receiver_region = r.areaid ;
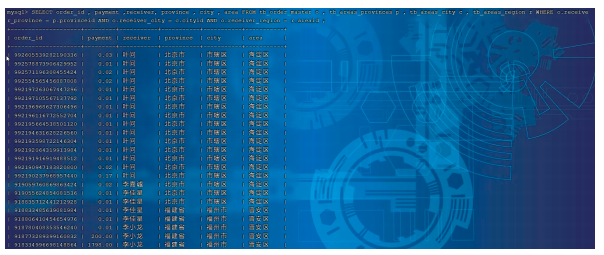
是可以正常执行成功的。
♥️关注,就是我创作的动力
♥️点赞,就是对我最大的认可
♥️这里是小刘,励志用心做好每一篇文章,谢谢大家


